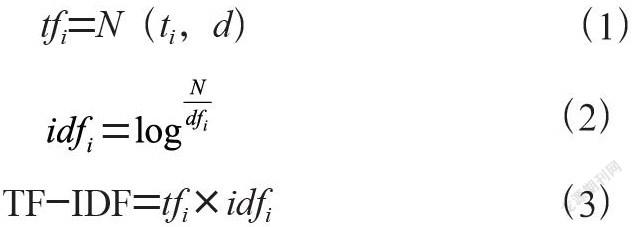辛瑞昊 王甜甜 李英瑞 冯欣
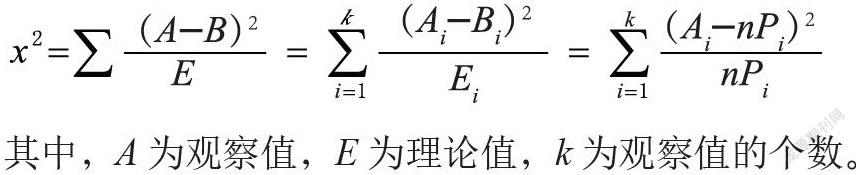
摘 要:癌症是一种严重威胁人类健康和生命的疾病。文章以TCGA公开数据库中的乳腺癌数据作为研究样本,基于机器学习中T-test检验和卡方检验方法对乳腺癌数据进行特征筛选和特征提取,保留有效的特征信息,剔除冗余信息。采用5种分类器对乳腺癌的分类进行研究,筛选出排在前10位的乳腺癌生物标志物进行深入研究,实验结果有助于探索遗传信息和自然因素在乳腺癌致病机理中的角色,并为预后评估的精准医疗提供科学依据。
关键词:乳腺癌;特征筛选;特征提取
中图分类号:TP391.4 文献标识码:A文章编号:2096-4706(2021)22-0095-03
Abstract: Cancer is a disease that seriously threatens human health and life. Taking breast cancer data in TCGA open database as the research sample, the T-test test and chi-square test method in machine learning are used to perform feature selection and feature extraction for breast cancer data, retaining effective feature information and eliminating redundant information. Five classifiers are used to study the classification of breast cancer, screening the top 10 breast cancer biomarkers for further study. The experimental results will help to explore the role of genetic information and natural factors in the pathogenesis of breast cancer, and provide scientific evidence for precision medical treatment on prognosis evaluation.
Keywords: breast cancer; feature selection; feature extraction
0 引 言
近些年,各种癌症发病率持续上升(如乳腺癌、肺癌等),严重威胁着人们的身体健康和生命安全。随着我国人口老龄化进程的不断加快,各种传染病的不断突发,居民不健康生活方式和不利环境因素的累加,致使癌症已经演变为严重威胁中国人群健康的公共健康问题之一。
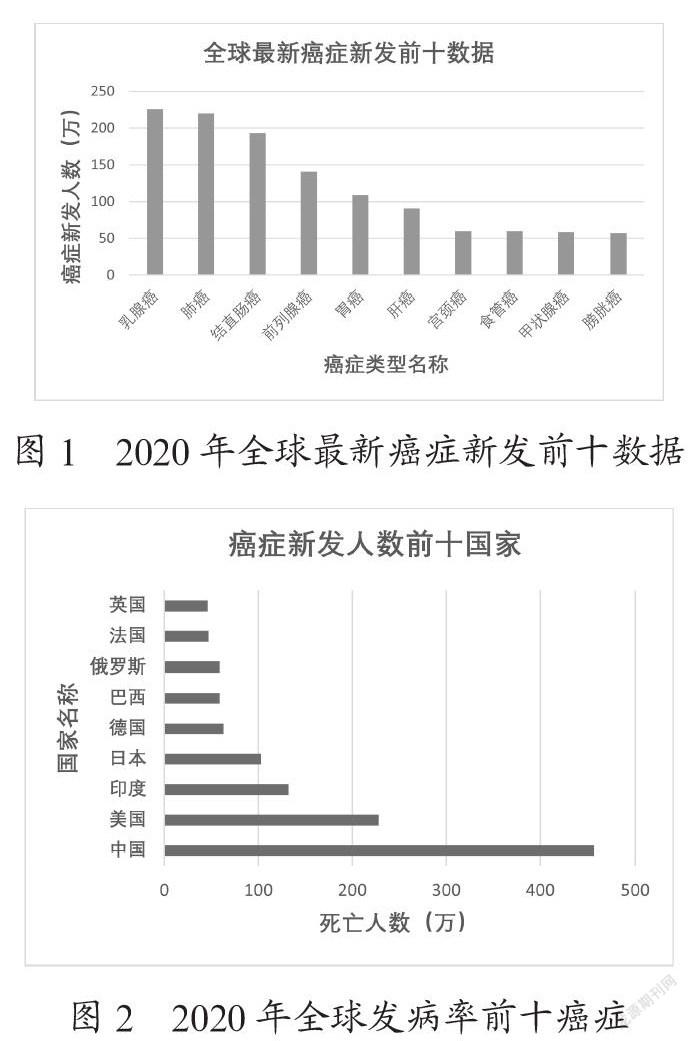
世界卫生组织研究表明,2020年全球乳腺癌发病率达到226万例,肺癌为220万例,乳腺癌发病率已经逐渐超过肺癌,变为全球第一大癌症。除此之外,我国癌症新发人数超过美国,成为癌症新发人数最多的国家[1],相关数据如图1、图2所示。
大数据在医疗健康领域发挥着重要作用,信息化时代的到来使得医学数据的收集更为方便,医疗大数据的研究和应用成为信息化时代医学研究的关键因素。为了给患者提供更好的治疗方案和预后效果,多种形式的医疗信息系统已经在国内医疗机构中被大量采用。利用数据分析技术对这些医学数据进行分析,可以帮助医生更加便捷高效地掌握病人的身体状况,有效提升乳腺癌的预后效果。
本文研究了基于机器学习的乳腺癌分类标志物检测方法,将基因的转录特征与统计学方法相结合,利用特征选择方法对乳腺癌早晚期特征基因进行筛选分类。首先,采用T检验(T-test)进行基因筛选,将P_value<0.05作为特征筛选条件;然后,采用卡方检验(Chi-square Test)对T检验结果进行特征选择;最后,在卡方检验后特征选择结果基础上,分别采用Logistic Regression(LR)、GaussianNB、DecisionTreeClassifier、K-Nearest Neighbors(KNN)和Support Vector Machine(SVM)五种机器学习分类器进行乳腺癌分类研究,并分析其重要分期标志物。
1 数据来源
研究所采用的乳腺癌患者病例数据来自TCGA公开数据库。TCGA的全称为癌症基因组图谱(The cancer genome atlas),它是由美国国家癌症研究所(NCI)联合美国国家人类基因组研究所(NHGRI)进行的研究项目,癌症基因组图谱收录了人类多种癌症类型(包括亚型在内的肿瘤)的临床数据以及基因组变异,例如mRNA表达、miRNA表达、甲基化等数据,给癌症研究人员提供了丰富的数据资源[2]。
本文实验数据采用的是TCGA乳腺癌转录组组学数据,其中样本数572例,包含早期癌症样本数436例以及晚期癌症样本数136例,样本特征数共有17 814个。
2 数据特征选择和筛选
实验选用的样本数据有限,使用全部特征来设计分类器则会浪费大量计算资源且分类器的分类性能不佳。任何一个特定的机器学习算法都无法做到精准剔除所有无效特征,因此需要从所有特征中筛选出有利于机器学习算法的相关特征。利用部分高表达性的特征构建模型可以大大缩减机器学习算法的运行时间,节省计算资源,而且模型的可解释性也会更高。特征选择算法可以从原始特征中自动筛选出对模型表达最为重要的特征,使得筛选后的特征子集尽可能小。在这个过程中,原始特征数据集与筛选后的特征子集之间存在一种包含的关系,原始特征空间没有改变,分类精度也没有显著降低,同时类分布以及特征子集还具有强鲁棒性和高适应性等特点。
实验中所采用的特征选择方法为Filter(过滤式)特征选择方法,其大致思想是先对数据集进行特征筛选,之后再训练学习器。特征选择过程中利用机器学习T-test检验和卡方检验集成的检验算法对乳腺癌数据特征进行特征筛选和特征提取。特征选择过程与后续学习器无关,这相当于先对初始特征进行“过滤”,再用过滤后的特征训练模型[3],保留有效的特征信息,剔除冗余信息,为后续癌症分期预测提供数据资源。
2.1 T-test检验
T检验用于对两个总体均值差的检验,因为当F分布在自由度趋向于无穷大的区间时,近似于正态分布,所以T检验通常用于两个正态分布均值差的检验。其在特征选择的过程中通过计算检验统计量值,比较特征之间统计量的大小,并进行降序排列,选取统计值较高的特征,去除差别不大的特征。实验中经过T检验筛选后,特征数由17 814个减少为2 549个。
2.2 卡方检验
卡方检验,也就是x2检验,是一种用途广泛的计数资料的假设检验方法。它通常用来验证两个总体的某个比率之间是否存在显著性差异[4],比较两个或两个以上样本率(构成比)以及进行两个分类变量的关联性分析。其根本思想在于比较理论频数和实际频数的相似程度或者是拟合优度问题。实验中利用卡方检验选择并保留T检验结果中前1%的样本特征,因此最终筛选出来的特征数由2 549个减少为26个。
卡方检验公式为:
其中,A为观察值,E为理论值,k为观察值的个数。
3 乳腺癌分期预测
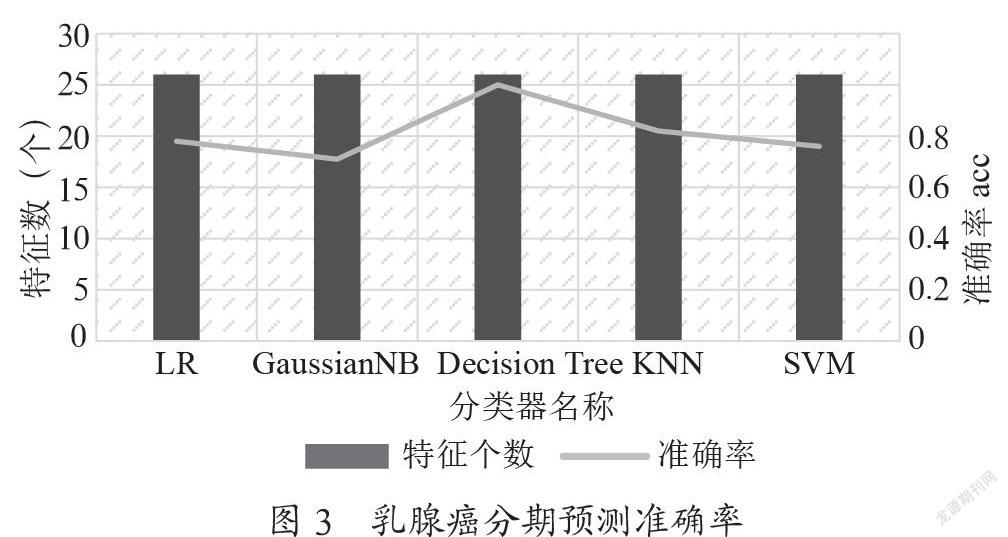
癌症分期是临床诊断的重要指标之一,不同分期(stage)癌症的预后效果存在着显著差异,临床医生往往通过预后来判断癌症治疗的效果[5]。如果可以检测出癌症分期的精准标志物,有助于在临床中确诊癌症发展阶段、评估预后结果以及理解癌症发生发展机理,由此提出实现乳腺癌分期识别的最佳方案。本文设置五种分类器用于乳腺癌分期预测,诊断为早期(I或II期)的乳腺癌患者通常具有较好的预后,而晚期(III或IV期)乳腺癌患者的死亡率较高[6]。可以通过工具栏按键选择切换分类器,系统可以根据分类器预测结果,显示最佳分类准确率。如图3所示为五种分类器下五倍交叉验证的乳腺癌分期预测准确率。经过T-test检验与卡方检验进行特征筛选之后,在五种分类器中对特征样本进行训练,并且将特征样本放入独立验证集中进行验证。从图3中可以看出,在五种分类器中使用决策树分类器验证的准确率能够达到100%,这是因为决策树分类器通常是采用递归的方法来选择最优特征,然后依据该特征对训练数据进行分割。这一过程中各个子数据集都有一个最好的分类过程,为特征空间的划分提供依据,同时也进一步支撑决策树的构建。
4 致癌基因特征排序
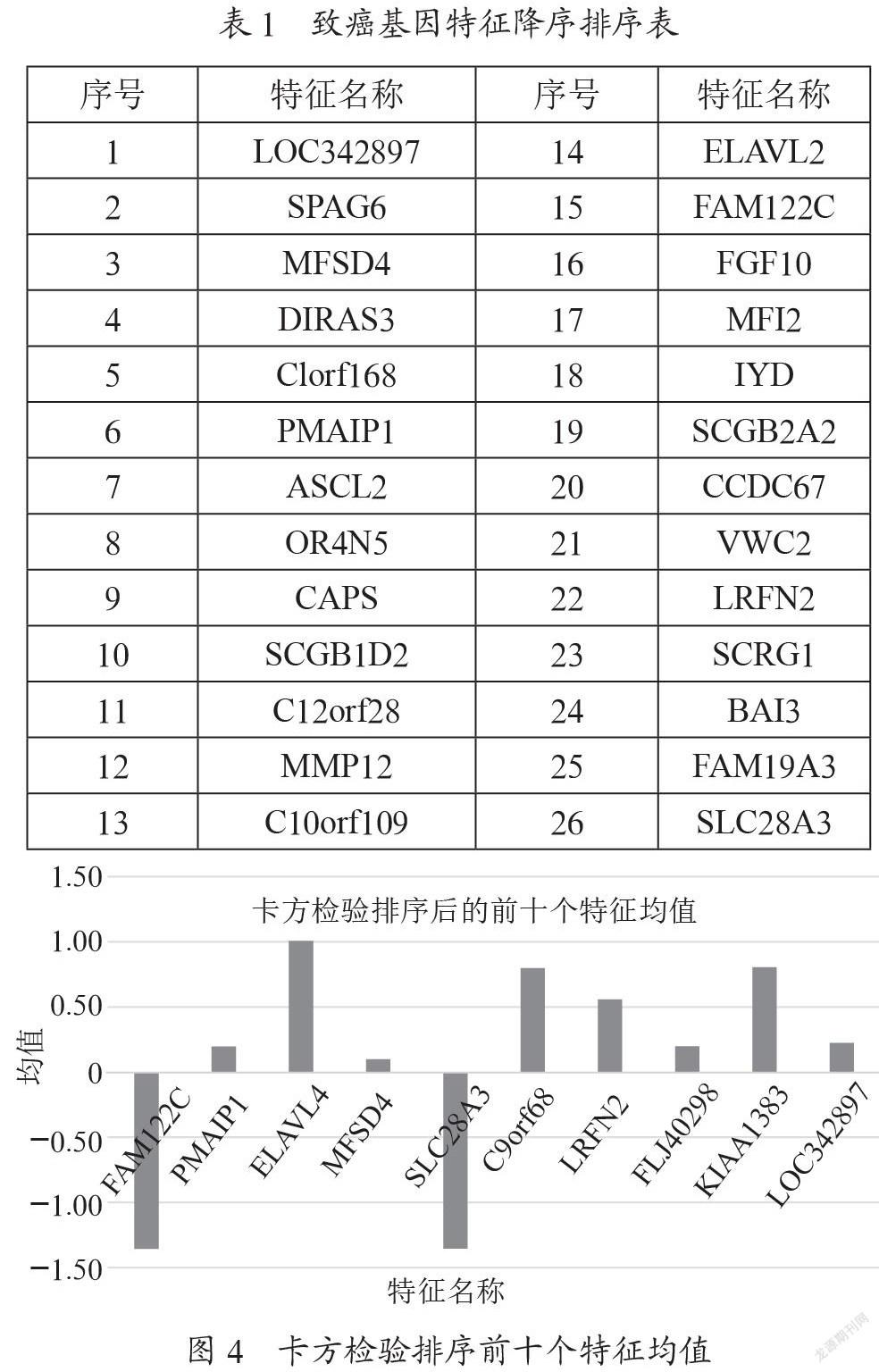
在癌症分期预测过程中采用决策树模型的准确率可以达到100%,但是对转录组学中影响因子的作用还不够直观,本文列出了通过卡方检验排序的前十个特征,致癌基因特征排序是根据值的大小对处理过的特征数据进行特征排序,致癌基因特征降序排序如表1所示。将前十个最优特征的均值结果进行可视化展示,如图4所示为通过卡方检验排序的前十个特征均值,通过样本分析可以看出,前十个特征的样本分布具有非常明显的差异性,各个特征之间的样本均值有着不同的数值,这对模型的学习具有很大的帮助(尤其是对于癌症患者的早晚期划分),特征的差异性越大愈能让模型学习到独有的信息。从可视化图中可以清晰直观地看出影响乳腺癌分期准确率排名前十的特征(具有明显的乳腺癌分期生物标志物),进而可以更有效精确地对个体的预后风险进行预测[7],并且为控制乳腺癌患病风险以及临床个性化治疗方案的制定提供了参考。
5 结 论
本文采用基于机器学习算法研究了乳腺癌癌症分期问题,采用T-test检验和卡方检验的方法进行特征筛选和排序,之后使用五种分类器进行分类,实现了决策树算法模型准确率达到100%的分类效果,筛选出排名前10位的乳腺癌致癌生物标志物。研究结果有助于从新的角度探索人类医学疾病诊断方法和计算机科学临床应用机制。检测癌症分期的精准标志物,分析遗传信息和自然因素对癌症发生和发展的影响,有助于临床确诊癌症发展阶段、评估预后结果以及理解癌症发生发展机理,为癌症诊断以及实现精准医疗提供科学依据。
参考文献:
[1] 刘青,张英,周馨,等.2009—2018年北京地区单中心乳腺癌临床流行病学及病理特征回顾性分析 [J].肿瘤,2020,40(6):431-439.
[2] TSAI C J,RIAZ N,GOMEZ S. Big Data in Cancer Research: Real-World Resources for Precision Oncology to Improve Cancer Care Delivery [J].2019,29(4):306-310.
[3] 杨剑锋,乔佩蕊,李永梅,等.机器学习分类问题及算法研究综述 [J].统计与决策,2019,35(6):36-40.
[4] 朱军,胡文波.贝叶斯机器学习前沿进展综述 [J].计算机研究与发展,2015,52(1):16-26.
[5] 孟小琴,屠俊标,魏萍萍.乳腺癌相关血清肿瘤标志物的临床研究进展 [J].癌症进展,2021,19(4):334-338.
[6] 陈冬灵.基于Qt和Wi-Fi的室内环境监测系统设计 [J].信息技术与信息化,2019(11):22-25.
[7] 李佳圆,郝宇,吴雪瑶.基于多组学数据的流行病学研究策略及其在乳腺癌研究中的应用 [J].中国普外基础与临床杂志,2020,27(11):1344-1347.
作者简介:辛瑞昊(1989—),男,汉族,吉林梅河口人,讲师,工学博士,研究方向:先进控制理论及应用、大数据分析等;王甜甜(1997—),女,汉族,陕西咸阳人,硕士研究生在读,研究方向:大数据分析与挖掘;李瑞英(1998—),男,汉族,陕西西安人,硕士研究生在读,研究方向:大数据分析与挖掘;通讯作者:冯欣(1989—),女,满族,吉林吉林人,讲师,博士,研究方向:大数据分析与挖掘。