周维 曹扬 谢红韬 胡建
收稿日期:2023-08-17
基金项目:国家自然科学基金(U19B2027)
DOI:10.19850/j.cnki.2096-4706.2024.06.007
摘 要:当今,数据的规模和复杂性不断增加,对数据处理平台的要求也越来越高。传统的批处理和实时处理技术各有优缺点,很难满足大规模数据处理的需求。因此,流批一体化的数据处理平台应运而生。文章在讨论流批一体核心架构设计的基础上,提出一种基于有状态实时流的流批一体数据处理方法,并通过平台化的方式实现流批一体数据的处理与计算。该平台先后在四川高速集团、贵阳政府单位示范应用,应用结果表明平台不仅统一了批处理和流处理框架,而且具有高效、可靠、可扩展等优点,同时能够满足大规模数据处理的需求。该平台的实现对于提高数据处理效率和准确性具有重要意义。
关键词:批处理;有状态实时流;平台化;流批一体
中图分类号:TP311.1 文献标识码:A 文章编号:2096-4706(2024)06-0029-06
Design and Research of a Flow Batch Integration Data Processing Platform
Based on Stateful Real-time Flow
ZHOU Wei1, 2, CAO Yang1, 2, XIE Hongtao1, 2, HU Jian1, 2
(1.CETC Big Data Research Institute Co., Ltd., Guiyang 550081, China; 2.National Engineering Research Center for Big Data Application Technology to Improve Government Governance, Guiyang 550081, China)
Abstract: Today, the scale and complexity of data are constantly increasing, and the requirements for data processing platforms are also increasing. Traditional batch processing and real-time processing technologies have their own advantages and disadvantages, making it difficult to meet the needs of large-scale data processing. Therefore, a data processing platform that integrates flow processing and batch processing has emerged. On the basis of discussing the core architecture design of flow batch integration, this paper proposes a data processing method for flow batch integration based on stateful real-time flow, and implements the processing and calculation of flow batch integration data through a platform based approach. This platform has been demonstrated application in Sichuan Expressway Group and Guiyang government units. The application results show that the platform not only unifies batch processing and flow processing frameworks, but also has the advantages of efficiency, reliability, scalability, and can meet the needs of large-scale data processing. The implementation of this platform is of great significance for improving data processing efficiency and accuracy.
Keywords: batch processing; stateful real-time flow; platformization; flow batch integration
0 引 言
数据为数字经济的发展提供了不可或缺的动力支持,一是数据量井喷式增长。根据国际数据公司(IDC)预测,2025年全球数据量将达到163 ZB。随着数据量指数级增长,数据分析算法和技术迭代更新,数据管理与治理手段升级,数据创新应用和产业优化升级,数据对社会变革的影响更加深远。二是数据产业规模持续扩张。据IDC预测,2019—2023年全球大数据市场相关收益将实现13.1%的复合年均增长率,2023年总收益将达到3 126.7亿美元。三是数据技术产品不断创新发展。当前数据底层技术框架日趋成熟,数据技术产品不断分层细化,覆盖数据存储、计算、分析、集成、管理、运维等各个方面的技术有了长足的进步。以大数据和数据技术为基础发展起来的云计算、物联网、人工智能、区块链等新技术对社会发展产生颠覆影响,同时,这些新技术的发展也促使流批一体数据处理技术的需求日益增加[1]。一是云计算技术的普及,越来越多的企业将数据处理任务转移到云端,使得流批一体数据处理技术的需求不断增加[2]。二是物联网设备的广泛应用,海量的实时数据不断涌现,需要流批一体数据处理技术来实时处理这些数据。三是人工智能和机器学习技术的发展,越来越多的企业需要处理实时数据来支持这些技术的应用。
随着智慧城市[3]、电子政务的发展,以及物联网、人工智能、边缘计算等技术的演进,传统批数据的处理架构难以满足企事业单位的需求,分开搭建批数据和流数据的架构造成运维、学习成本陡增[4]。因此有必要从性能、安全容错、便捷使用等方面对流批一体的数据处理架构展开调研、分析与研究,孵化出流批一体化的数据处理新模式与数据处理新技术,新技术不仅可以提供低延迟的实时数据处理能力,而且能提供高效的批处理能力,从而能满足新技术领域带来的应用需求。
1 平台设计
1.1 平台架构设计
以Spark [5,6]为代表的批处理框架和以Flink [7]为代表的流处理框架,两者各有特点,现实生产中既有批处理任务又有流处理任务,如果同时维护这两套处理框架,就会造成以下问题:一是需同时维护两套计算架构,造成大量管理成本和资源浪费;二是两套计算架构的处理代码并不统一,需维护两套加工代码;三是两套并行的架构容易导致数据处理结果不一致[8]。本文平台架构设计过程中,均采用Flink作为计算处理框架,进而来实现流批一体的数据处理[9]。
1.1.1 系统架构
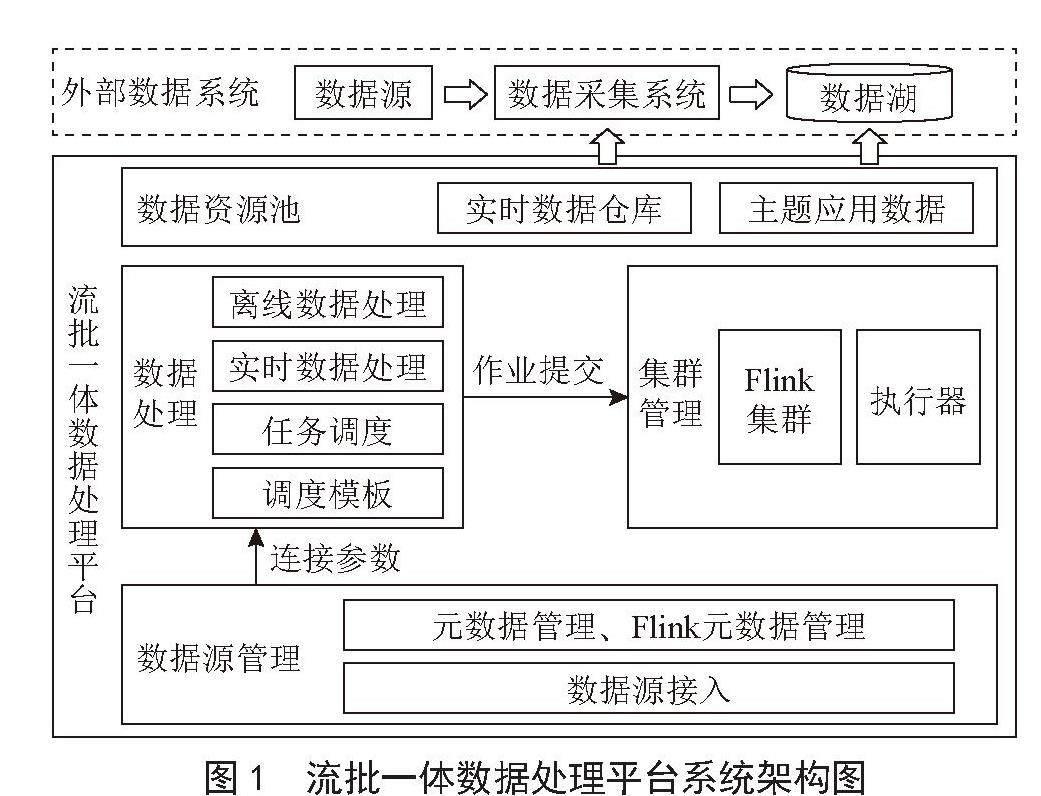
系统架构图主要将流批一体数据处理平台分为4个部分:数据源管理、数据处理、集群管理、数据资源池,如图1所示。
图1 流批一体数据处理平台系统架构图
数据源管理:数据源管理能将各类不同的数据源接入进系统并进行统一管理,数据源的接入可以获取到数据源的元数据以及Flink的元数据,这些元数据为数据处理过程中提供连接参数。
数据处理:数据处理分为实时数据处理任务和离线数据处理任务。实时数据处理任务直接将任务提交到Flink集群;离线数据处理任务是任务调度工具根据配置的调度模板信息,即调度时间,进行任务执行,其中重要的是任务调度工具的实现,调度工具中只需要模拟Flink的任务执行即可完成离线数据任务的处理。数据处理中最关键的设计是统一了实时数据处理和离线数据处理的统一表达,即实现了同一套FlinkSQL代码能兼容处理流数据和批数据的问题。
集群管理:提交Flink任务时,首先要保证安装了Flink集群,其中Flink当前支持的集群模式包括Standalone集群、Yarn集群、Kubernetes集群;其次,Flink集群是利用Flink中的执行器来处理提交过来的任务。
数据资源池:数据资源池是数据统一集中管理的位置,将数据分为主题应用数据、实时数仓等部分。经过Flink任务处理之后,处理的数据就能写入到数据资源池中的数据表或其他数据系统中。
另外,流批一体数据处理平台中处理后的数据,可为其他外部系统中的数据采集环节提供离线数据采集和实时数据采集的支撑,同时也可以为数据湖中的数据预处理、清洗加工、挖掘分析提供离线和实时的数据加工任务执行引擎。
1.1.2 技术架构
流批一体数据处理平台技术架构包含4层,如图2所示。
图2 流批一体数据处理平台技术架构图
前端采用Vue作为开发框架,开发B/S架构的软件系统,Vue不仅易于上手,还便于与第三方库或既有项目整合。
服务端使用基于Java的Spring Boot框架进行开发,它基于Spring 4.0设计,不仅继承了Spring框架原有的优秀特性,而且还通过简化配置来进一步简化了Spring应用的整个搭建和开发过程。另外SpringBoot通过集成大量的框架使得依赖包的版本冲突,以及引用的不稳定性等问题得到了很好的解决。流批一体数据处理平台需要对数据加工处理任务进行周期调度和实时调度,此处需要突破的关键技术是实现XXL-JOB任务调度引擎与Flink结合,进而实现流任务和批任务的定时调度。
流批一体数据处理平台的任务执行都通过Flink Client向Flink集群提交任务。
流批一体数据处理平台理论上是与Flink完全解耦的,因此流批一体数据处理平台需要通过可配置的方式接入Flink集群,需要实现对原生Flink、CDH、HDP等不同Flink的接入。
1.1.3 功能架构
流批一体数据处理平台功能架构包括作业管理、集群管理、函数管理、连接器管理等主要模块,功能架构图如图3所示。其中作业管理是整个系统的核心,提供SQL、JAR包、图形组件三种作业开发模式,方便不同层次的数据开发工程师使用。为满足不同数据规模、资源条件的应用场景,支持Local、Standalone、Session、Yarn四种模式的作业提交方式。
1.2 平台功能设计
基于有状态实时流的流批一体数据处理平台以“框架统一、处理高效、操作便捷”为指导思想,构建满足于流批一体的数据计算的需求。系统分为9个部分:数据源管理、连接器管理、函数管理、集群管理、执行器管理、调度模板管理、任务管理、作业管理、运维中心。其功能概述如下:
1)数据源管理。将需进行数据处理的外部数据源进行统一接入和管理,通过数据列表将数据源进行分门别类,方便进行查询和检索。数据源类型支持关系型数据库(MySQL、ClickHouse)、消息中间件Kafka、缓存数据库Redis、非关系型数据库MongoDB等数据源的接入。所有外部数据源的密码进行加密存储,保证数据安全。数据源管理功能如表1所示。
2)连接器管理。Flink Connector是Flink与外部系统集成和连接的桥梁,流批一体数据处理平台作为一个共性的、应用工具软件,需要满足不同场景的数据库适配需求。连接器管理提供对Flink Connector的统一管理功能,包括Flink Connector的上传到本地和上传到集群的功能等。连接器管理功能如表2所示。
3)函数管理。函数管理是任务开发工作的基础,旨在建立统一的Flink函数管理入口,方便FlinkSQL任务开发时调用,其中函数类型包括比较函数、逻辑函数、字符串函数、Streaming、Batch等。具体功能如表3所示。
表1 数据源管理功能项
功能项名称 功能项描述
数据源列表 支持数据源目录的新增、删除、修改、查询,支持数据源和数据源目录的绑定,支持按照数据源目录筛选数据源列表
关系型
数据库 支持MySQL、ClickHouse数据源的新增、删除、修改、查询和连接、心跳检测、Flink连接配置
非关系型
数据库 支持MongoDB数据库的接入的新增、删除、修改、查询和连接、心跳检测、Flink连接配置
消息中间件 支持Kafka数据库的接入的新增、删除、修改、查询和连接、心跳检测、Flink连接配置
缓存数据库 支持Redis数据源的新增、删除、修改、查询和连接、心跳检测、Flink连接配置
表2 连接器管理功能项
功能项名称 功能项描述
官方连接器管理 支持连接器的新增、删除、修改、查询,同步
自定义连接器管理 支持连接器的新增、删除、修改、查询,下载、同步
表3 函数管理功能项
功能项名称 功能项描述
函数管理 支持函数的新增、删除、修改和查询、启用、调用
4)集群管理。集群管理也是任务开发工作的基
础,建立统一的集群管理界面,方便FlinkSQL或FlinkJar任务开发时,能选择任务的提交集群,集群管理包括Flink集群管理和Hadoop集群管理,其中Flink集群又可以分为Standalone、Yarn Session、Yarn Per-job、Yarn Application等。集群管理功能如表4所示。
表4 集群管理功能项
功能项名称 功能项描述
Flink集群
管理 支持集群的新增、删除、修改和查询、启用、调用、心跳检测、回收功能;支持跳转到Flink集群的Dashboard界面
Hadoop集群管理 支持集群的新增、删除、修改和查询、测试;支持指定Hadoop集群的配置文件路径和Flink集群的配置文件路径以及Flink Lib包路径
5)执行器管理。执行器是批处理任务执行和调度的工具,批处理任务提交后,任务会提交给执行器去处理。执行器管理的主要功能是提供执行器的注册,便于执行器的统一管理。执行器管理功能如表5所示。
表5 执行器管理功能项
功能项名称 功能项描述
执行器管理 支持执行器的新增、删除、修改和查询;支持执行器的自动注册和手动录入
6)调度模板管理。调度模板是批处理任务的调度配置信息,便于执行器按照调度配置信息去执行任务,另外,调度模板的管理也方便多个任务同时使用同一个调度模板信息,这样就不会每一个任务都需要配置调度信息。调度模板管理提供执行器路由策略、阻塞处理策略、调度周期等参数配置。调度模板管理功能如表6所示。
表6 调度模板管理功能项
功能项名称 功能项描述
调度模板管理 支持调度模板的新增、删除、修改和查询;支持注册节点、下次触发时间查询;支持执行器选择
调度周期管理 支持分钟、小时、天、周、月等调度周期
7)任务管理。任务管理是编排流批一体任务的管理界面,为满足数据规模大、实时性高、数据类型多样的数据处理要求,流批一体数据处理平台需要具备实时计算和批计算两种功能,且需要具备定时调度的功能。具体功能如表7所示。
8)作业管理。作业管理是流批一体数据处理平台的核心功能。作业管理是流批一体作业的开发、执行、部署等操作进行管理;作业开发包括FlinkSQL、Flink图形化组件、Flink Jar开发三种模式;作业执行包括作业发布、作业提交到集群、作业停止、作业恢复等操作功能;作业部署是将作业提交到集群进行执行,作业的执行模式包括Local、Standalone、Session、YarnApplication等模式。具体功能如表8所示。
表7 任务管理功能项
功能项名称 功能项描述
周期任务管理 支持周期任务的新增、删除、修改和查询,支持多种数据类型的数据处理
周期任务编排 支持周期任务拖拽式任务编排
周期任务调度 周期处理任务支持周期性调度和手动执行,支持分钟、小时、天、周、月等调度周期
周期任务启动 支持周期任务按照任务调度配置调度执行任务
周期任务停止 支持周期任务按照任务停止执行
周期任务执行一次 支持周期任务手动执行一次操作
实时任务管理 支持实时流计算任务的新增、删除、修改和查询,支持实时计算引擎
实时任务编排 支持实时流计算拖拽式任务编排
实时任务启动 支持实时任务启动执行
实时任务停止 支持周期任务停止执行
表8 作业管理功能项
功能项名称 功能项描述
作业开发 支持保存SQL、语法检测、调试、会话、元数据获取、数据源获取、环境配置、作业配置、执行配置功能
作业执行 支持执行当前SQL、异步提交、发布、上线、下线功能
作业部署 支持不同模式的作业部署,包括Local、Standalone、Session、YarnApplication
作业日志 支持查看Flink启动日志和执行日志的查看
Jar管理 支持Flink jar包的上传、下载、删除功能
9)运维中心。运维中心提供任务操作与状态等多方位的运维能力。当开发完成并提交和发布至集群后,即可在运维中心对任务进行运维操作,包括作业实例运行详情查看、作业任务的关键指标查看、集群信息、作业快照、异常信息、作业日志、自动调优、配置信息、FlinkSQL、数据地图、即席查询、历史版本、告警记录。具体功能如表9所示。
表9 运维中心功能项
功能项名称 功能项描述
作业实例 支持查看Flink作业实例状态
作业总览 支持查看Flink作业的各监控指标,包括作业状态、重启次数等指标
集群信息 支持查看集群实例信息
作业快照 支持查看 该任务的CheckPoint SavePoint,并且可以基于某一个CheckPoint/SavePoint重启该任务
异常信息 支持查看Flink作业启动及运行时的异常
历史版本 支持对比查看Flink作业发布后的多个版本
告警记录 支持查看Flink作业提交和发布后的告警信息
一键上下线 支持已发布的作业进行一键上下线操作
1.3 平台关键设计和关键技术
1.3.1 关键设计
1)批数据和流数据的统一表达和查询设计。针对企业数字化转型建设过程中对离线数据和实时数据的融合处理需求,将业务数据化,数据算子化,设计可复制、可扩展的UDF算子和连接器,通过引入动态表概念,把离线表、动态流都表达为表,设计了批处理和流处理在操作对象表达方式上的统一,保证对流式数据查询的连续性。同时,支持对流式计算的撤销操作,避免相同键值的数据参与多次计算,实现在流批一体数据处理过程中对持续增长和持续输出的流数据的正确操作。形成一套将任意标准的SQL转化成实时计算程序的技术方案,采用SQL作为统一的编程语言,通过可视化的人机交互式方式,完整的使用SQL语义来表达流计算任务,达到对批数据和流数据的查询使用同一套SQL语句的目的,实现批流一体计算平台中批数据和流数据的统一查询。
2)多版本多模式兼容的Flink SQL执行引擎设计。为了满足不同数据规模、不同资源环境的数据开发需求,流批一体数据处理平台设计了Local、Standalone、Yarn、Session四种不同的任务运行模式,同时也支持在不同版本Flink集群中执行。
流批一体数据处理平台设计了集群管理功能,用于管理不同版本的集群。另外,在Flink SQL作业开发过程可以选择不同的执行模式,这样就满足了多版本多模式兼容的执行引擎。
3)自定义函数设计。流批一体数据处理平台研制的目的是满足用户对数据加工处理的需求,因此,在设计过程中预置了常用的函数,这样在数据开发过程中就可以直接使用预置的函数;另外,对于不满足的函数需求,平台设计了自定义函数管理功能,即可以通过配置自定义函数的相关数据,就能满足开发过程中调用的需求,这样能够大大提高系统的可用性,提高数据开发的效率。
1.3.2 关键技术
1)XxlJob调度引擎与Flink引擎适配技术。XxlJob中有执行器和调度器两个功能组件,调度器负责按照调度周期调度任务,执行器负责执行任务,流批一体数据处理平台中用到的关键技术是XxlJob调度引擎与Flink引擎适配技术,即实现XxlJob执行器功能,XxlJob执行器具备Flink引擎执行任务功能。
执行器能解析批数据处理任务参数,其中任务参数包括SQL语句、Flink集群信息、批处理任务等参数信息,然后调用Flink引擎统一的API接口方法,进而批数据处理任务就以任务参数的形式提交给Flink引擎去处理了。
2)基于Checkpoint和SavePoint的实时流状态管理技术。Flink是一个有状态的分布式流式计算引擎,Flink中的每个Function或者是Operator都可以是有状态的,有状态的Function在处理流数据或事件的同时会存储一部分用户自定义的数据,这使得Flink的状态可以作为任何更精细操作的基础。然而总会有一些原因使流任务出现异常(如网络故障、代码bug等),为了使得状态可以容错,流批一体数据处理平台中引入了Checkpoint机制。Checkpoint使得Flink能够恢复流任务的状态和位置,从而为流任务提供与无故障执行相同的语义。Savepoint在底层使用的代码和Checkpoint的代码是一样的,因为Savepoint可以看作Checkpoint在特定时期的一个状态快照[10]。
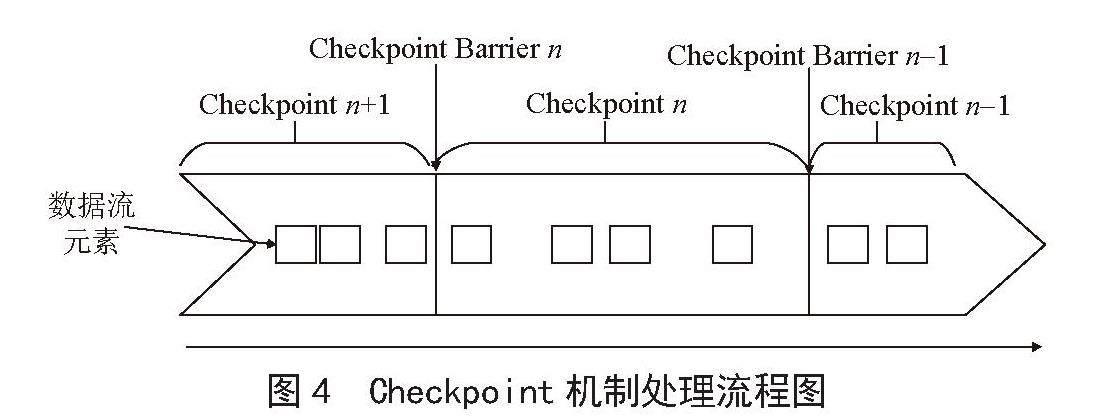
流批一体数据处理平台定期保存状态数据到存储上,故障发生后从之前的备份中恢复,整个被称为Checkpoint机制,它为Flink提供了Exactly-Once的保障。流批一体数据处理平台中提供Checkpoint和SavePoint的实时流状态管理技术,任务在失败或出现异常的情况下,可以通过Checkpoint和SavePoint的实时流状态管理中的一键恢复功能达到任务从失败点开始继续执行的效果。具体流程如图4所示。
图4 Checkpoint机制处理流程图
由图4可知,Checkpoint Barrier被插入到数据流中,它将数据流切分成段。Flink的Checkpoint逻辑是:一段新数据流入导致状态发生了变化,Flink的算子接收到Checkpoint Barrier后,对状态进行快照。每个Checkpoint Barrier有一个ID,表示该段数据属于哪次Checkpoint。当ID为n的Checkpoint Barrier到达每个算子后,表示要对n-1和n之间状态的更新做快照。Checkpoint Barrier有点像Event Time中的Watermark,它被插入到数据流中,但并不影响数据流原有的处理顺序[11]。
2 平台应用
平台部分截图如图5所示。
平台现已应用于四川高速集团、贵阳政府单位示范应用,主要解决数据采集、流批一体数据处理问题,有效支撑企事业单位的数据处理需求,提高数据处理效率,赋能企事业单位的运行管理。
3 结 论
本文针对流数据和批数据等特性,突破了批数据和流数据的统一表达和查询关键技术,设计了一种流批一体的数据处理方法,并通过平台化研制流批一体数据处理核心模块,性能与成熟度达到国内先进水平。该平台先后在四川高速集团、贵阳政府单位示范应用,应用表明平台不仅统一了流批计算框架和引擎,而且明显减少了部署成本,提高了数据处理效率。
参考文献:
[1] 郑阳婷.数字化技术在城市管理中的应用 [J].电子技术,2023,52(3):274-275.
[2] 郭亚楠,肖菡.云计算在计算机数据处理中的应用 [J].电子技术,2023,52(2):198-199.
[3] 周林兴,崔云萍.智慧城市视域下政府数据开放共享机制研究 [J].现代情报,2021,41(8):147-159.
[4] 黄春,姜浩,全哲,等.面向深度学习的批处理矩阵乘法设计与实现 [J].计算机学报,2022,45(2):225-239.
[5] 李硕,梁毅.面向Spark的批处理应用执行时间预测模型 [J].计算机工程与应用,2021,57(5):79-87.
[6] ZAHARIA M,XIN R S,WENDELL P,et al. Apache Spark: a unified engine for big data processing [J].COMMUNICATIONS OF THE ACM,2016,59(11):56-65.
[7] CARBONE P,EWEN S,HARIDI S,et al. Apache Flink?: Stream and Batch Processing in a Single Engine [EB/OL].[2023-07-16].https://xdxk.cbpt.cnki.net/EditorDN/EditorWorkPlace/ReferParallel.aspx.
[8] 陈氢,宋仕伟.数据治理视角下的湖仓一体架构研究 [J].数字图书馆论坛,2023,19(4):19-28.
[9] 王玉真.基于Flink的实时计算平台的设计与实现 [D].南昌:南昌大学,2020.
[10] 于志良.基于Flink的鲸鱼优化K-Means算法 [J].互联网周刊,2023(4):83-85.
[11] 庆骁.面向FLINK流处理框架的容错策略优化研究 [D].哈尔滨:哈尔滨工业大学,2019.
作者简介:周维(1990—),男,汉族,贵州贵阳人,工程师,硕士,主要研究方向:数据治理、数据挖掘、数据开发。