摘 要:为了改善有监督学习的泛化性较差,只能较好地识别已经见过的用于训练的信道数据属于哪种信道场景的问题,文章提出了一种基于伪标签半监督学习方法的无线信道场景识别方法,仿真结果表明,在识别新的信道数据(来源不同但属于模型中的某一类信道场景)所对应的信道场景时,半监督学习方法的识别准确率远高于有监督学习方法的识别准确率。由此可见,半监督学习的方法可以提高无线信道场景识别模型的泛化能力。
关键词:信道场景识别;半监督;伪标签
中图分类号:TN92;TP183 文献标识码:A 文章编号:2096-4706(2024)08-0001-05
DOI:10.19850/j.cnki.2096-4706.2024.08.001
0 引 言
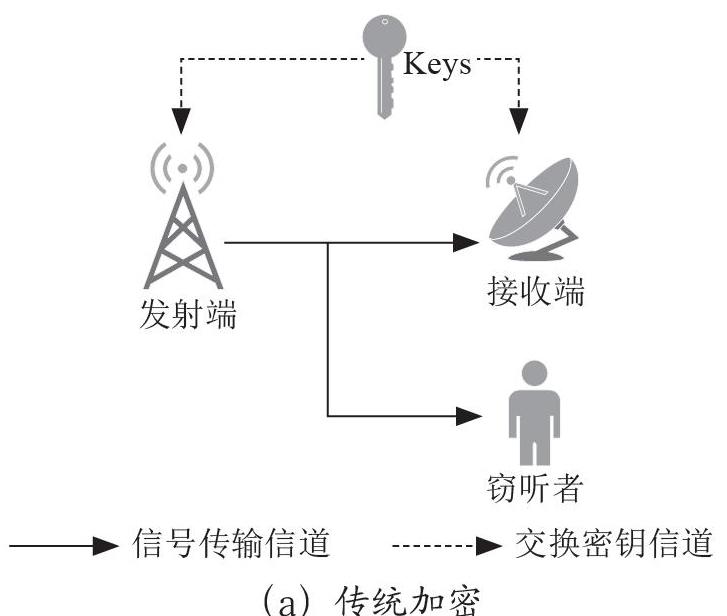
如今,随着技术的快速发展,手机、电脑等无线智能设备的使用在很大程度上依赖无线通信。电磁波在无线通信中的传播会通过无线信道,对信道特性的分析对提高通信性能具有重要意义。以前对信道的研究主要集中在信道特征提取和信道建模上,而近年来,如何对信道场景进行分类的研究也越来越受到关注。信道场景识别对于许多应用都是重要和有益的,例如智能交通系统(ITS)[1]、定位和信道建模[2]。此外,准确地对无线信道场景进行分类以满足无线通信系统的专用需求成为一个挑战[3]。无线信道的建模离不开信道测量,而对无线信道进行场景识别,既可以使信道建模更加精确,又可以对测量得到的信道数据进行更细致的分析。
信道的场景识别依据信道数据,即信道的各种特征。信道数据的采集是通过信道测量得到的。进行信道测量需要精密的仪器以及详细的计划,人力物力成本较高,所以不易获取信道实测数据,目前也没有公开的信道数据集[4]。目前国内外有多个团队为了进行信道的场景识别测量了多种信道场景下的信道,这些场景大多数为室外的场景。文献[5]在包括城市地区、高速公路、隧道、NLOS在内的四种典型的车辆通信场景中进行了信道测量,反向传播神经网络(Back Propagation Network, BPNN)作为场景识别模型。文献[6]在美国南加州大学校园和校园附近的公共道路上进行了测量,获取了LOS和NLOS场景的信道数据,比较了三种不同的机器学习方法,即支持向量机、随机森林和人工神经网络的性能。文献[7]测量了乡村场景、车站场景、郊区场景、多链路场景的信道数据,并用长短时记忆(Long Short-Term Memory, LSTM)网络进行识别。也有针对室内信道场景的识别研究,文献[8]对包括实验室、狭窄走廊、大厅、体育馆在内的四种环境进行了信道测量,通过不同的机器学习算法:决策树、支持向量机和K近邻算法,对室内场景进行分类。文献[9]使用卷积神经网络基于常见的室内障碍物对NLOS场景进行细分,并在真实的室内多场景环境中进行了测试。
但以上采用的都是有监督学习的方法,其存在的一个普遍的问题为训练得到的识别模型的泛化性较差,泛化性指在面对未曾见过的数据时的表现能力。在信道的场景识别中,有监督学习的方法的该局限性表现为,用多种信道场景的信道数据训练得到的信道场景识别模型,只在输入为用于训练的信道数据时达到良好的识别效果,而对于新的未用于模型训练信道数据,即使该信道数据属于该信道场景识别模型中的一类信道场景,但由于信道测量的地点不完全相同,即与用于模型训练的信道数据不同源,有监督学习得到的模型的信道识别结果表现不佳。
而半监督学习可以改善这一问题,本文提出了一种基于伪标签半监督学习方法的信道场景识别方法,使得信道场景识别模型不再局限于识别已经见过的用于训练的信道数据属于哪种信道场景,实现能较准确地识别不同源但属于模型中的某一类信道场景的信道数据所对应的信道场景的效果。本文首先证明原本的监督学习不适用于新信道数据的信道场景识别,然后用伪标签的半监督学习的方法提高了对新信道数据的识别准确率。其中训练集为在云南采集到的信道数据,包含城区、山区、空地三种场景,测试集为在青岛采集到的信道数据,包含城区、山区两种场景。
1 信道测量和数据预处理
1.1 信道数据采集
在多个场景下采用信道探测系统按照所计划好的路线进行实验。探测系统平台由发射端、接收端及其配套天线系统构成,发射机固定在高楼上,接收机每间隔5 s记录一条时长1 s的接收样本,采用ZC序列进行测量。在青岛的城区和山区分别进行测量,得到不同信道环境下的数据,同时在云南采用信道探测仪按照所规划好的路线进行实验,得到的数据包括城区、山区和空地。
1.2 数据去噪
如图1所示,通过滑动相关方法获得的原始测量信道脉冲响应(CIR)快照不仅包含明显的多径分量,还包含大量的噪声分量。因此,有必要在收集测量数据后对数据进行去噪和参数提取。为了去除噪声引起的伪峰值,根据恒虚警率检测器(CFAR)方法确定噪声阈值。通过阈值的动态估计来区分信号抽头和噪声抽头。这种去噪方法可以通过计算动态阈值将信号抽头与噪声区分开。
1.3 信道特征提取
提取每个信道快照的多个参数作为模型的输入,不同的信道场景下的信道特征存在着明显的不同。
1.3.1 莱斯K因子
莱斯K因子定义为直射路径的信号功率与非直射路径的信号功率比值,文献[10]提出信道莱斯K因子计算式为:
(1)
式中μ2和μ4分别表示样本数据二阶矩和四阶矩。由于上式方程求解时可能不存在实数解,在没有视距链路的场景下也能计算莱斯K因子,所以广义上的莱斯K因子的计算式如下:
(2)
在本文中,空地的莱斯K因子最大,城区的莱斯K因子最小,山区的莱斯K因子介于二者之间。
1.3.2 均方根时延扩展
多径扩展是指无线通信中,电磁波在多径衰落信道中传播,空间传输距离与路径干扰的差异性造成信号到达接收端的时间不一致的现象。通常使用均方根时延扩展(Root Mean Squared-Delay Spread, RMS-DS)参数对多径扩展进行描述,其计算式为:
(3)
其中τ表示该径的时延,Pτ表示该径的功率。在本文中,城区的RMS-DS最大,空地的RMS-DS最小,山区的RMS-DS介于二者之间。
1.3.3 最大接收功率
不同信道场景下中的多径分量(Multipath Component, MPC)包含的功率不同,因此,每个快照的最大接收功率" 可以用于识别LOS情况。在本文中,空地的最大接收功率最大,城区的最大接收功率最小,山区的最大接收功率介于二者之间。
1.3.4 上升时间
上升时间表示为最强MPC和第一个MPC之间的时间间隔:
(4)
其中l表示MPC的序号。在视距链路少的信道场景中的第一组分可能会因阻挡物体或强衍射而衰减,因此,视距链路少的场景下的上升时间通常大于视距链路多的场景中的上升时间。在本文中,城区的上升时间最长,空地的上升时间最短,山区的上升时间介于二者之间。
1.4 信道数据归一化
采用离差标准化的方法将提取到的信道的多个特征的数据进行归一化处理,具体方法如下:
将全部抽头的其中一个特征作为序列x1, x2, …, xn中的元素,其中n为抽头数量,采用算式" 进行处理,得到的新序列y1, y2, …, yn ∈ [0,1]且无量纲,即是该特征归一化之后得到的特征值。对选取的4个信道特征均进行归一化处理,使得其数值处于[0,1]之间,便于其后将多个数值差距大的特征共同用于进行信道类型的聚类。
2 信道场景识别
在处理完信道数据后,将信道数据用于信道场景的识别。
2.1 有监督学习
有监督学习方法的信道场景识别过程如图2所示。
首先用有监督学习的方法进行信道场景的识别,作为训练集的样本数据由多个信道快照组成。每个信道快照都是由4个特征值组成的行向量,将第i个样本被表示为xi = {xi,1, xi,2, xi,3, xi,4},1≤i≤N,第i个样本所对应的信道场景用yi表示。因此在输入部分的信道数据表示为:
(5)
用该数据训练好信道识别模型之后,将测试集输入模型,测试集被表示为:
(6)
模型将根据特征数据预测其属于哪一类信道场景,预测的结果为 ,1≤i≤NT,将其与测试集数据真实的标签进行对比,得到信道场景识别的准确率。
采用支持向量机(Support Vector Machine, SVM)作为有监督学习中的神经网络,首先训练集和测试集都使用在云南采集到的信道数据,每类场景都有各2 400个样本。训练集包含城区、山区、空地三种场景,取总样本中的70%为训练集,其学习曲线如图3所示。
图3中的学习曲线是根据不同训练集大小,显示模型在训练集和验证集上的得分变化的曲线,其反映了信道场景识别模型的训练过程,不代表最终的识别准确率,最终的识别准确率还与待识别的样本数据有关。测试集为方便后续的比较,仅采用在云南采集到的城区和山区场景,得到的识别结果如图4所示。
图4为用云南的城区、山区和空地数据进行训练,并用云南的城区、山区进行测试的结果,取总数中的30%作为测试集,即每个场景各720个信道快照。该结果由混淆矩阵表示,一行为该信道数据实际所属的类别,一列为该信道数据被预测为的类别。因为没有用空地数据进行测试,所以空地数据那一行都为0。黑色方块表示被准确预测的信道数据,白色表示被错误预测的信道数据。从图中可以看出,在城区场景中有626个信道样本被准确预测为城区,有58个信道样本被错误预测为了山区,有36个样本被错误预测为空地,准确率为87%;在山区场景中有634个信道样本被准确预测为山区,有58个信道样本被错误预测为了城区,有28个样本被错误预测为空地,准确率为88%。
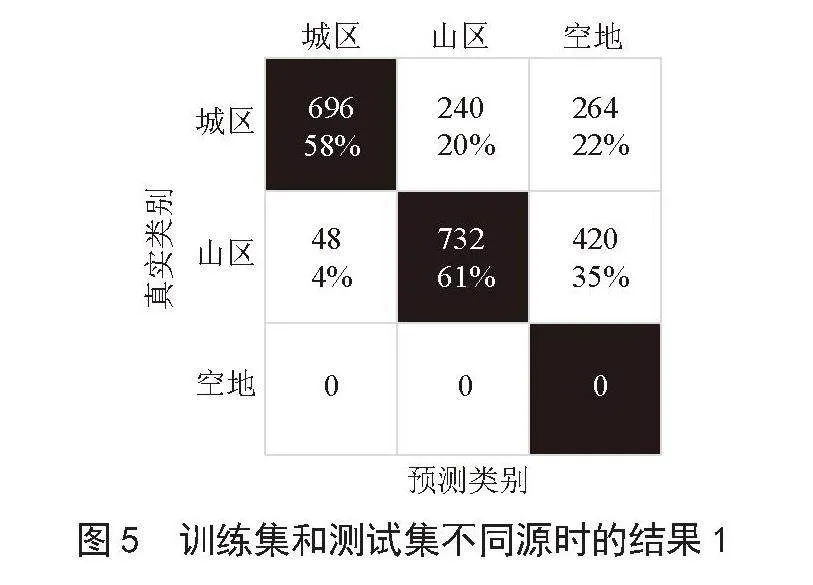
然后使用和图4所示结果同样的训练集和神经网络,但将测试集换成在青岛测量得到的城区和山区场景的信道数据,得到的结果如图5所示。
图5为用云南的城区、山区和空地数据进行训练,用青岛的城区和山区数据测试的结果,测试集中每个场景各有1 200个信道样本。从图中可以看出,在城区场景中有696个信道样本被准确预测为城区,有240个信道样本被错误预测为了山区,有264个样本被错误预测为空地,准确率为58%;在山区场景中有732个信道样本被准确预测为山区,有48个信道样本被错误预测为了城区,有420个样本被错误预测为空地,准确率为61%。
两次实验的结果不同说明了在有监督学习中,如果识别的信道样本和用于训练的信道样本数据同源,信道识别网络的性能较好,识别准确率能达到88%。但如果将该信道识别模型用于识别新的信道样本数据(其对应的信道场景属于模型中的信道场景)的话,准确率只有60%。可以得出结论,将有监督学习所得到的信道识别网络用于新的信道样本数据时,识别的效果较差,体现了有监督学习的泛化性较差的缺点。
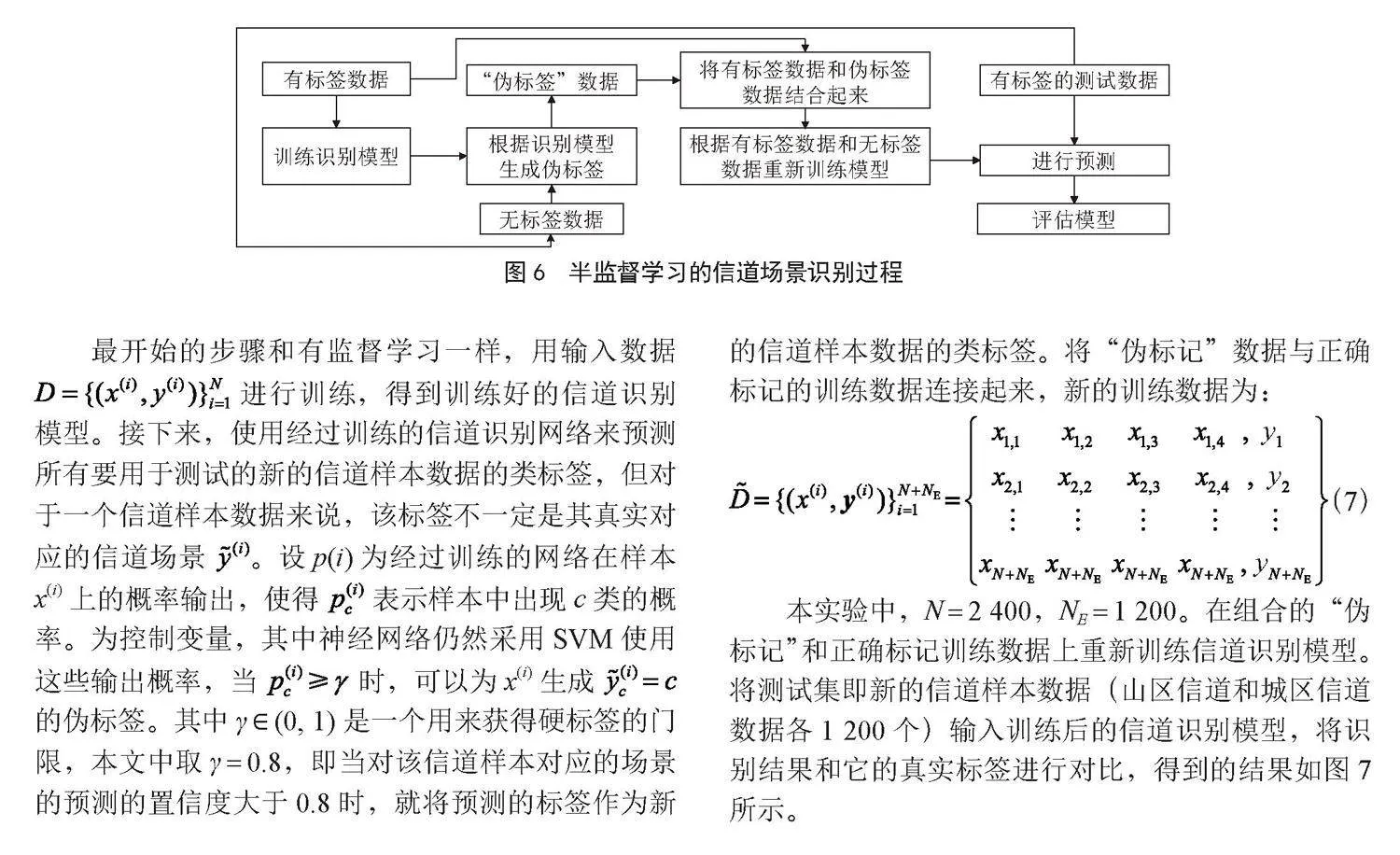
2.2 伪标签的半监督学习方法
因此本文提出了用伪标签的半监督学习的方法改善有监督学习中识别模型泛化性较差的缺点,使得信道识别模型在识别新的信道样本数据(其对应的信道场景属于模型中的信道场景)时也能达到较好的效果。使用半监督学习的方法识别信道场景的具体步骤如图6所示。
最开始的步骤和有监督学习一样,用输入数据 进行训练,得到训练好的信道识别模型。接下来,使用经过训练的信道识别网络来预测所有要用于测试的新的信道样本数据的类标签,但对于一个信道样本数据来说,该标签不一定是其真实对应的信道场景 。设p(i)为经过训练的网络在样本x(i)上的概率输出,使得" 表示样本中出现c类的概率。为控制变量,其中神经网络仍然采用SVM使用这些输出概率,当" 时,可以为x(i)生成" 的伪标签。其中γ ∈ (0, 1)是一个用来获得硬标签的门限,本文中取γ = 0.8,即当对该信道样本对应的场景的预测的置信度大于0.8时,就将预测的标签作为新的信道样本数据的类标签。将“伪标记”数据与正确标记的训练数据连接起来,新的训练数据为:
(7)
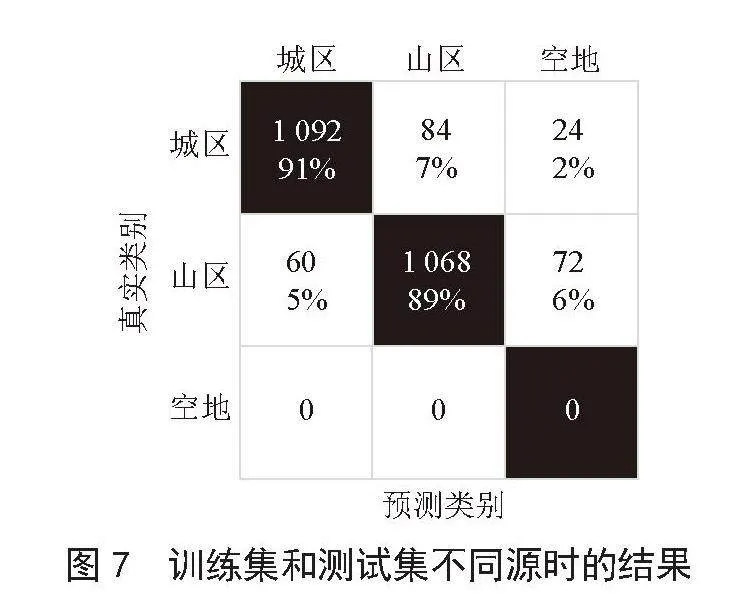
本实验中,N = 2 400,NE = 1 200。在组合的“伪标记”和正确标记训练数据上重新训练信道识别模型。将测试集即新的信道样本数据(山区信道和城区信道数据各1 200个)输入训练后的信道识别模型,将识别结果和它的真实标签进行对比,得到的结果如图7所示。
图7与图5的训练集和测试集都相同。图7为使用半监督学习中的伪标签方法,用云南的山区、城区和空地信道数据进行训练后,再加入青岛的山区和城区数据,并用青岛的山区数据和城区数据进行测试所得到的结果(各有1 200个信道样本)。从图中的混淆矩阵可以看到,在城区场景中有1 092个信道样本被准确预测为城区,有84个信道样本被错误预测为了山区,有24个样本被错误预测为空地,准确率为91%;在山区场景中有1 068个信道样本被准确预测为山区,有60个信道样本被错误预测为了城区,有72个样本被错误预测为空地,准确率为89%。
2.3 结果对比
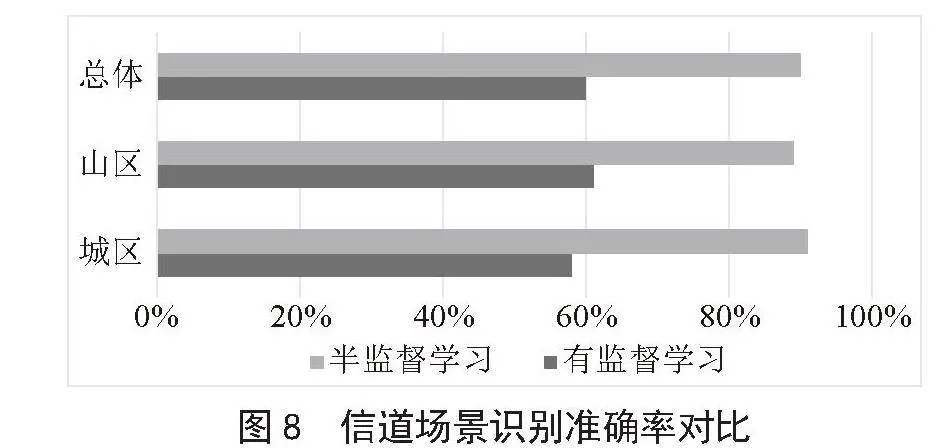
将有监督学习的识别结果和半监督学习的识别结果进行更直观的对比,如图8所示,即同样的用云南测量得到的城区、山区、空地信道数据训练得到的信道场景识别模型,对在青岛测量得到的城区、山区的信道数据的识别效果的对比。
对比识别结果可以看出,无论是山区场景、城区场景还是总体的信道场景识别准确率,半监督学习的识别准确率都远高于有监督场景的识别准确率。所以可以得出结论,运用半监督学习的方法,可以提高分类网络对于新的信道场景样本数据的识别准确率。
3 结 论
针对有监督学习的泛化性较差,只能较好地识别已经见过的用于训练的信道数据属于哪种信道场景的缺点,本文提出了一种基于伪标签半监督学习方法的无线信道场景识别方法,实现能较准确地识别新的信道数据(来源不同但属于模型中的某一类信道场景)所对应的信道场景的效果,提高了无线信道场景识别模型的泛化能力。
参考文献:
[1] 黄家炜.车联网中基于信道状态信息的轻量化场景识别算法研究 [D].南京:南京邮电大学,2023.
[2] HUANG C,HE R S,AI B,et al. Artificial Intelligence Enabled Radio Propagation for Communications—Part II: Scenario Identification and Channel Modeling [J].IEEE Transactions on Antennas and Propagation,2022,70(6):3955-3969.
[3] ZHANG J C,LIU L,FAN Y Y,et al. Wireless Channel Propagation Scenarios Identification: A Perspective of Machine Learning [J].IEEE Access,2020,8:47797-47806.
[4] 刘祥.基于深度学习的无线通信场景识别研究 [D].西安:西安电子科技大学,2018.
[5] YANG M,AI B,HE R S,et al. Machine-Learning-Based Scenario Identification Using Channel Characteristics in Intelligent Vehicular Communications [J].IEEE Transactions on Intelligent Transportation Systems,2021,22(7):3961-3974.
[6] HUANG C,MOLISCH A F,HE R S,et al. Machine Learning-Enabled LOS/NLOS Identification for MIMO Systems in Dynamic Environments [J].IEEE Transactions on Wireless Communications,2020,19(6):3643-3657.
[7] 王英捷,周涛,陶成.基于LSTM与多特征融合的高铁无线信道场景识别 [J].电波科学学报,2021,36(3):453-459+476.
[8] ALHAJRI M I,ALI N T,SHUBAIR R M. Classification of Indoor Environments for IoT Applications: A Machine Learning Approach [J].IEEE Antennas and Wireless Propagation Letters,2018,17(12):2164-2168.
[9] DENG B W,XU T W,YAN M D. UWB NLOS Identification and Mitigation Based on Gramian Angular Field and Parallel Deep Learning Model [J].IEEE Sensors Journal,2023,23(22):28513-28525.
[10] 冯松.无线信道测量参数提取算法研究 [D].西安:西安电子科技大学,2013.
作者简介:谭思源(1998.11—),女,土家族,重庆人,硕士研究生在读,研究方向:信道测量和信道场景识别。
收稿日期:2024-01-12
Wireless Channel Scenario Classification Based on Semi-supervised Learning
TAN Siyuan
(Xian Electronic Engineering Research Institute, Xian 710000, China)
Abstract: To address the issue of poor generalization of supervised learning, which can only effectively classify which channel scenario the channel data used for training belongs to, this paper proposes a wireless channel scenario classification method based on pseudo-label semi-supervised learning. Simulation results indicate that, when classifying the channel scenario corresponding to new data (originating from different sources but belonging to a known category of channel scenario in the model), the semi-supervised learning approach significantly outperforms supervised learning in terms of classification accuracy. Thus it can be seen, it is concluded that semi-supervised learning can enhance the generalization ability of wireless channel scenario classification models.
Keywords: channel scenario classification; semi-supervised learning; pseudo label