
摘" 要:针对短文本存在的语义稀疏及语义模糊等问题,提出一种有监督的双词主题模型(Su-BTM),将其应用于短文本分类。在BTM主题模型的基础上引入主题-类别分布参数,识别主题-类别语义信息,建立主题与类别的准确映射,并提出Su-BTM-Gibbs主题采样方法,对每个词的隐含主题进行采样。在两个中英文短文本数据集上进行对比实验,实验结果表明,该方法相比经典模型具有更优的分类效果。
关键词:语义稀疏;BTM主题模型;隐含主题;短文本分类
中图分类号:TP181" " 文献标识码:A" " " 文章编号:2096-4706(2024)10-0056-04
A Short Text Classification Method Based on Supervised Biterm Topic Model
WEI Hongmin
(Shandong Huayu University of Technology, Dezhou" 253034, China)
Abstract: In response to the problems of semantic sparsity and ambiguity in short texts, this paper proposes a Supervised Biterm Topic Model (Su-BTM) and applies it to short text classification. Based on the BTM topic model, distribution parameter between topic and category is introduced to identify semantic information between topic and category, accurate mapping between topic and category is established, and a Su-BTM-Gibbs topic sampling method is proposed to sample the implied topics of each word. Comparative experiments are conducted on two datasets of Chinese and English short texts, and the results show that this method has better classification performance compared to classical models.
Keywords: semantic sparsity; BTM topic model; implied topic; short text classification
0" 引" 言
短文本分类是自然语言处理领域的一项重要任务,广泛应用于社交媒体监控、情感分析[1]、产品评论分类[2]等场景。近年来,随着现代信息科技及互联网技术的迅速发展,微信、微博等社交网络平台飞速发展,短文本的数量逐渐增多[3,4]。由于短文本存在数据量少[5]、语义特征稀疏[6]、类别不平衡[7]等问题,导致了短文本分类的精度不高。
黄佳佳等人提出潜在狄利克雷分布模型(Latent Dirichlet Allocation, LDA)[8],得到文档-主题和主题-词分布,从而提高文本分类的精度。之后,双词主题模型(Biterm Topic Model, BTM)被提出[9],通过词对的结合扩大语料库,对短文本语义稀疏的问题进行改进。BTM和BERT模型[10]通过综合考虑文本主题特征信息和全局语义信息,增强了文本语义,从而解决了语义特征稀疏的问题。
鉴于此,本文提出了一种Su-BTM主题模型用于短文本分类。Su-BTM主题模型利用语料库中的类别标记信息,在BTM主题模型的基础进行改进。1)引入主题-类别分布参数,由此来识别主题与类别之间的语义关系,将主题与类别进行精确的映射,以完成文档的主题分类。2)采用Su-BTM-Gibbs采样方法,对语料库中所有共现词对的隐含主题进行采样,在同类别的文档中进行采样。3)主题-类别分布参数可以将主题进行分类,更准确地计算出单词-主题的概率,提高短文本分类的准确度。
1" Su-BTM的概率图
Su-BTM的概率图模型如图1所示,在短文本语料库中, B 为语料库中由两个单词组成词对的总数,其中B = {b1, b2, …, bn},b = {wi, wj}为一个词对,Z为的是所有的词对的主题分布。θ为全局主题分布参数,φ为主题-词分布参数,δ为主题-类别分布参数。
在Su-BTM模型中,θ、φ和δ服从Dirichlet分布,为多项式参数分别生成主题、词和类别,α、β和γ为相应的Dirichlet分布的先验参数。Su-BTM模型语料库中所包含的词对生成过程如下:
步骤1:每一个主题z生成一个服从φz~Dir(β)的主题-词分布。
步骤2:整个语料库生成一个服从θ~Dir(α)的全局主题分布。
步骤3:每个主题z生成一个服从α~Dir(γ)的主题-类别分布。
步骤4:每一个词对b ∈ B 。
从全局主题分布θ中抽取出服从z~Multi(θ)的主题z。
从主题z中抽取出服从(wi, wj)~Multi(φz)的词对(wi, wj)。
按照上述生成过程,词对b的联合概率如式(1)所示:
其中,p(z) = θz为主题z的概率;p(wi z) = φi z为主题z下词wi出现的概率;p(wj z) = φj z为主题z下词wj出现的概率。
因此,生成词对语料库的概率如式(2)所示:
文档主题推断的公式如式(3)所示:
其中,p(z d)为文档d的主题概率,基于Su-BTM中估计的参数 p(z b)可以通过贝叶斯公式计算,如式(4)所示:
其中,p(z (wi, wj)) = θz φiz φjz,文档中单词对的条件概率p(b d),计算如式(5)所示:
其中,n(b)为词对b在文档d中出现的次数,且p(b d)为均匀分布。
2" Su-BTM模型参数估计
Su-BTM主题模型中,求得以下参数:主题概率θ、主题-词分布φ和主题-类别分布δ。基于BTM-Gibbs采样算法,Su-BTM的Gibbs采样算法得到了极大的改进。其中所求参数不需要直接计算,而是对每个词对b的隐含主题进行采样,再通过Dirichlet的先验参数α、β和γ进行计算。对词对b的概率分布进行抽样,从而得到隐含主题参数z。
依据Su-BTM-Gibbs,每个词对b的条件概率的计算公式如式(6)所示:
其中,除了词对b以外的其他词对的主题分布为z¬b,nz为词对b属于主题z的次数,nwz为单词w属于主题z的次数,nbz为词对b在主题z中出现的次数,词对b与其所包含的wi, wj属于同一个主题。
主题-词概率分布φ,全局主题概率分布θ,主题-类别概率分布δ的概率估计如式(7)~(9)所示:
Su-BTM模型的Gibbs采样算法描述如Algorithm1所示:
Algorithm1:Gibbs sampling algorithm for Su-BTM
Input:topic number K,hyper parameters α、β、γ、B
1.rondomly initialize topic assignments for all the biterms
2.for 1 to ni do
3." " " "for i ∈ B do
4." " " " " get zb from Eq(6)
5. update nz、、
6." end
7.end
8. computer φ in Eq(7)and θ in Eq(8)and δ in Eq(9)
Output:θ、φ、δ
如Algorithm1所示,对语料库中所有词对b进行初始化。然后在每次迭代时,对于语料库中的每一个词对b,通过式(6)计算得到词对b的主题zb,并更新以下参数:nz、、。最后通过式(7)至式(9)得到主题-词概率分布φ,全局主题概率分布θ,主题-类别概率分布δ。
3" 实验分析
3.1" 数据集描述
实验选取中文搜狗新闻标题短文本数据集(sogou)和英文亚马逊评论短文本数据集(AMAZON),随机抽取部分文档并构建训练集。具体描述如下:选取sogou数据集中的5类文档:体育、教育、科学、科技和汽车;选取AMAZON数据集中的5类文档:Digital_Product、Baby_Product、AMAZON_FASHION、Professional_Books和Clothing。其中测试样本与训练样本的比例为2:8,实验数据集如表1所示。
为验证了基于Su-BTM主题模型的短文本分类方法的有效性,与SVM、BTM和LDA模型进行实验比较。
3.2" 实验结果及分析
3.2.1" Su-BTM主题推断与类别映射
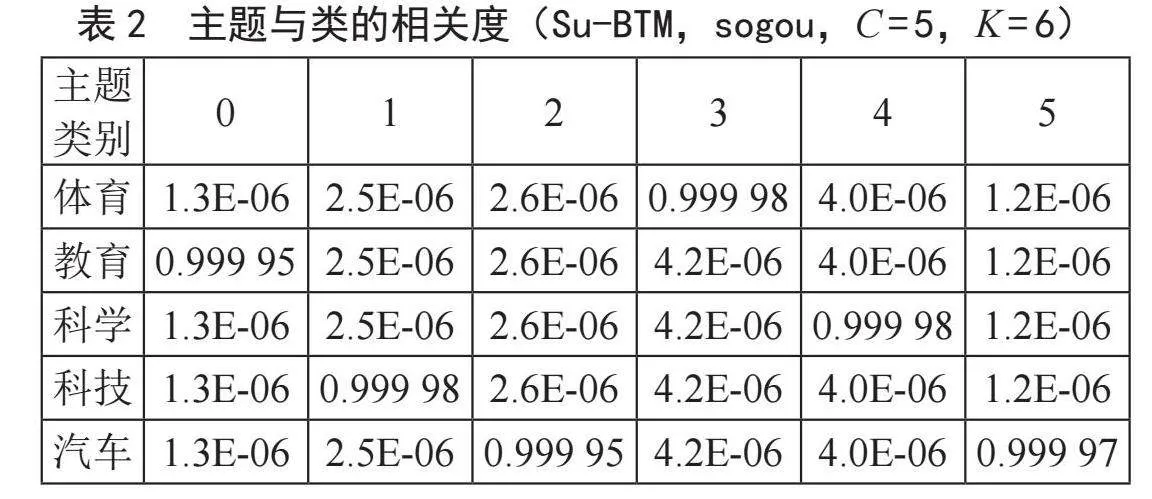
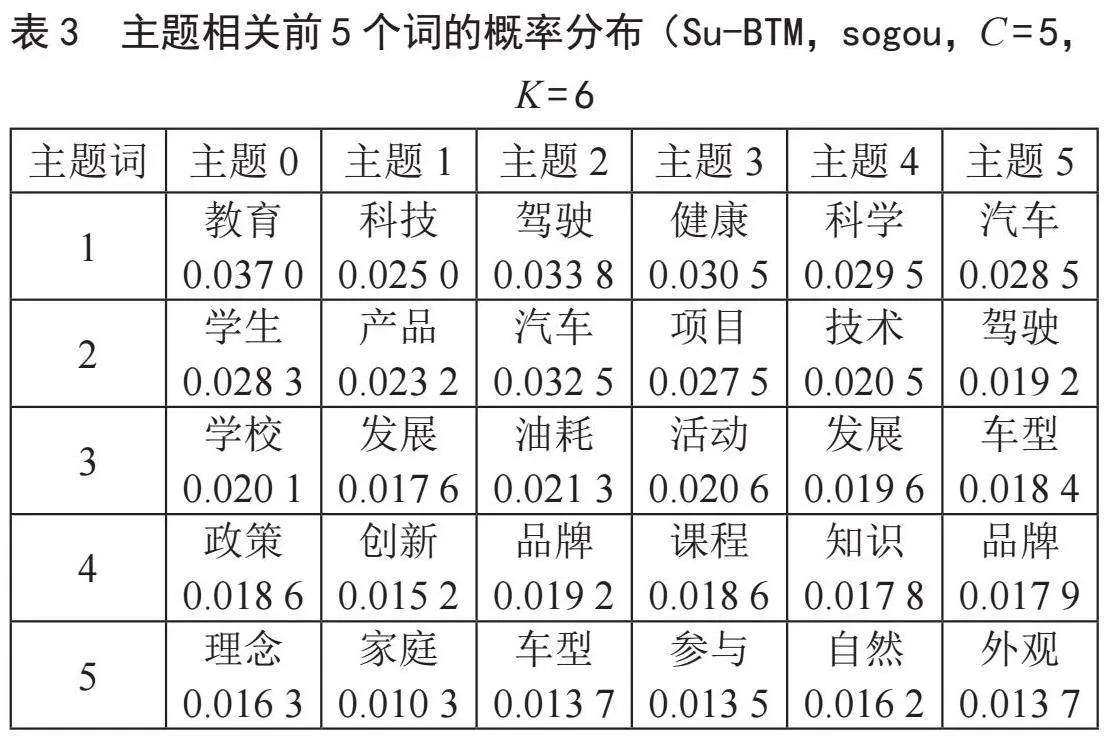
对Su-BTM模型进行主题推断,在搜狗数据集上,类别和主题之间的相似度以及与主题最相关的前5个词的概率分布如表2、表3所示。其中类别C = 5、主题数K = 6,其中,α、β和γ的值设为0.01。
如表2、表3所示,在sogou数据集上,主题0的映射类别为“教育”,主题1的映射类别为“科技”,主题2的映射类别为“房产”,其他主题与类别之间准确映射,映射的相似度大于99%。如表3所示,主题0的前5个特征词,都与主题“教育”有关,概率最大的词“教育”的概率为0.037 0。同样的,在其他主题下,特征词都与对应的主题相关。
3.2.2" 短文本分类结果
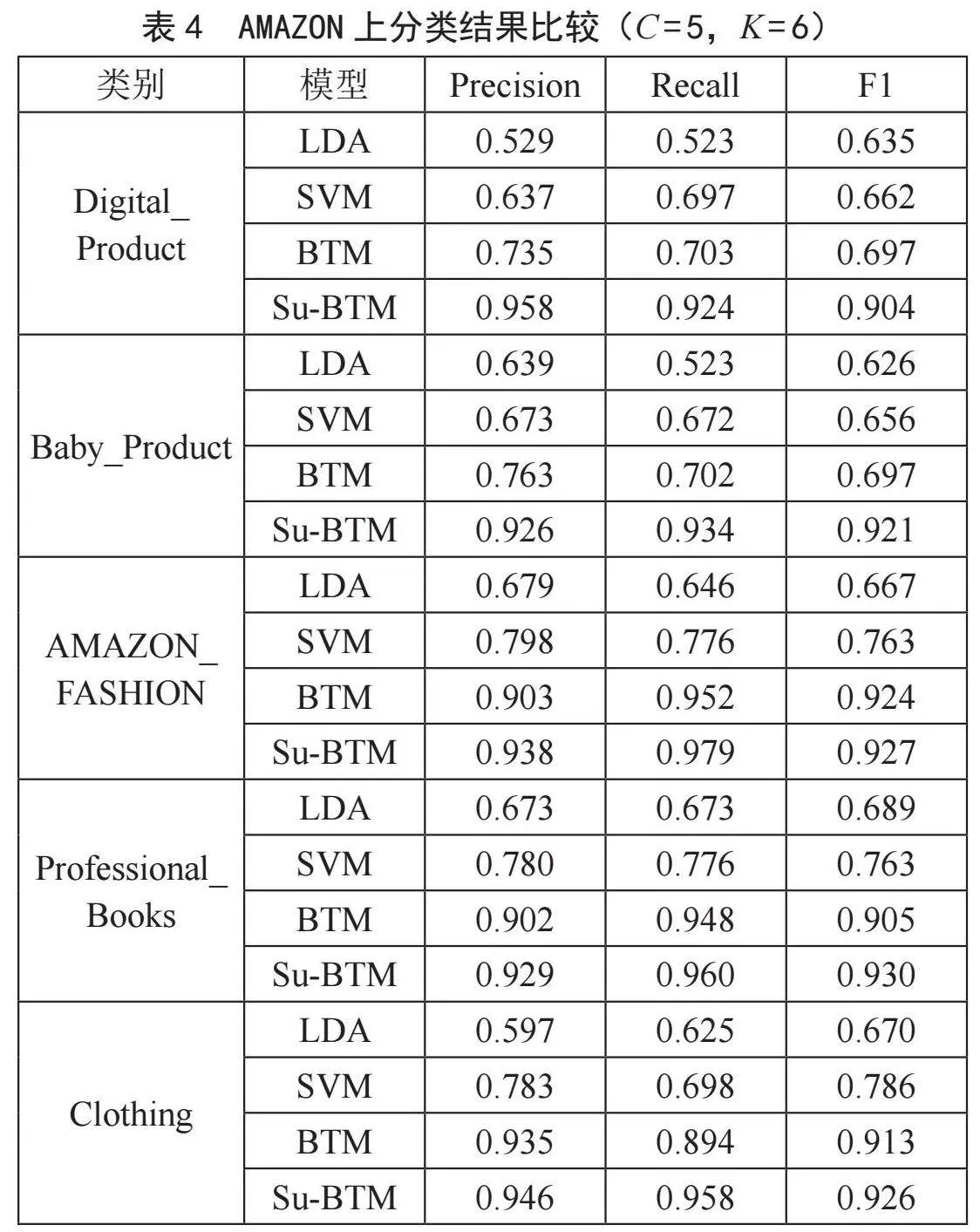
通过短文本分类,来验证Su-BTM主题模型的有效性。BTM、LDA是利用BTM、LDA主题模型直接进行分类,SVM指采用LDA主题模型的K个主题为特征的SVM分类算法。在AMAZON数据集上的实验结果如表4所示。
如表4所示,在AMAZON数据集上,当类别为“Digital_Product”时,LDA的Precision、Recall和F1分别为52.9%、52.3%和63.5%,SVM的分别为63.7%、69.7%和66.2%,BTM的分别为73.5%、70.3%和69.7%,Su-BTM的分别为95.8%、92.4%和90.4%,Su-BTM比BTM的三种分类结果分别高了22.3%,22.1%,20.7%,Su-BTM比SVM的三种分类结果分别高了32.1%,22.7%,24.2%,Su-BTM比LDA的三种分类结果分别高了42.9%,40.1%,26.9%。在其他类别上也是如此,基于Su-BTM的短文本分类算法的分类结果均优于其他经典模型。
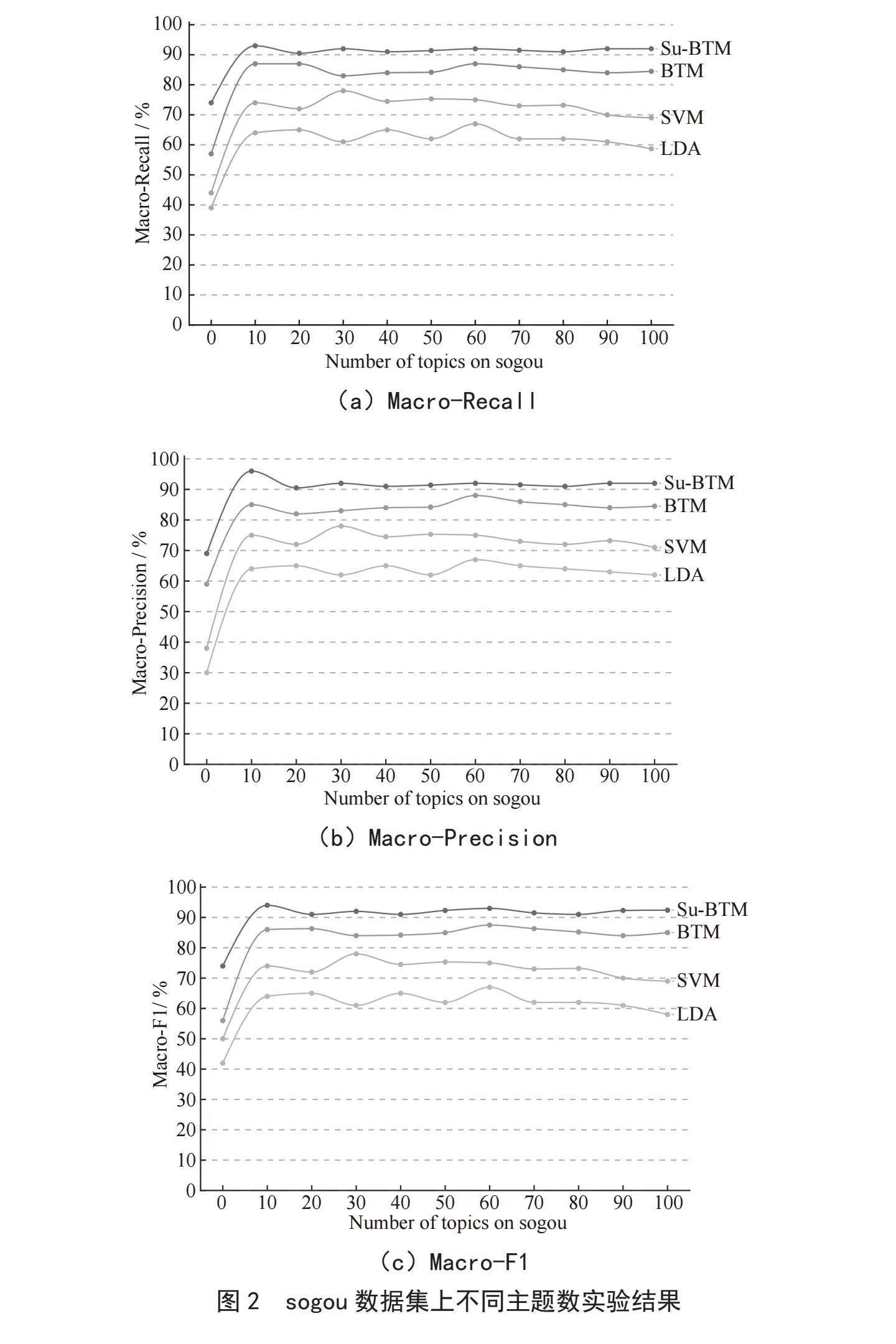
在sogou数据集上,对比分析Su-BTM、BTM、LDA和SVM模型在不同的主题数下,分类的Macro-F1、Macro-Recall和Macro-Precision,实验结果如图2所示。
如图2所示,纵坐标表示分类的Macro-F1、Macro-Recall和Macro-Precision,横坐标表示主题的数目。从图中可以看出,随着主题数的增加,分类的各种指标逐渐升高并趋于稳定。当K = 10时,Macro-Precision的值达到最高,LDA为64.8%,SVM为76.8%,BTM为83.6%,明显的低于Su-BTM。在Macro-Recall和Macro-F1分类指标上,基于Su-BTM模型的分类精度更高。
4" 结" 论
本文在BTM模型的基础上引入主题-类别分布参数,结合Su-BTM-Gibbs主题采样方法,从而识别出主题-类别语义信息,将主题与类别进行映射,来完成文档的主题分类任务。综合实验表明,基于Su-BTM的短文本分类方法能明显提高分类精度。
参考文献:
[1] 邓入菡,张清华,黄帅帅,等.基于多粒度特征融合的新型图卷积网络用于方面级情感分析 [J].计算机科学,2023,50(10):80-87.
[2] 喻涛,罗可.结合产品特征的评论情感分类模型 [J].计算机工程与应用,2019,55(16):108-114.
[3] 关慧,宗福焱,曲盼.基于BTM和长文本语义增强的用户评论分类 [J].计算机技术与发展,2023,33(7):181-187.
[4] 张志昌,曾扬扬,庞雅丽.融合语义角色和自注意力机制的中文文本蕴含识别 [J].电子学报,2020,48(11):2162-2169.
[5] 段丹丹,唐加山,温勇,等.基于BERT模型的中文短文本分类算法 [J].计算机工程,2021,47(1):79-86.
[6] 王李冬,魏宝刚,袁杰.基于概率主题模型的文档聚类 [J].电子学报,2012,40(11):2346-2350.
[7] 马慧芳,邢玉莹,王双,等.融合词语共现距离和类别信息的短文本特征提取方法 [J].计算机工程与科学,2018,40(9):1689-1695.
[8] 黄佳佳,李鹏伟,彭敏,等.基于深度学习的主题模型研究 [J].计算机学报,2020,43(5):827-855.
[9] 刘良选,黄梦醒.融合词向量特征的双词主题模型 [J].计算机应用研究,2017,34(7):2055-2058.
[10] 付文杰,杨迪,马红明,等.融合BTM和BERT的短文本分类方法 [J].计算机工程与设计,2022,43(12):3421-3427.
作者简介:卫红敏(1997—),女,汉族,山东德州人,助教,硕士,研究方向:数据挖掘、机器学习。