





摘" 要:增值税发票是各类经济交易中最常用的支付凭证,财务报账过程中人工处理发票效率低下。基于此,文章设计并实现了增值税发票解析和识别系统。该系统对不同类型的发票文档进行分类处理,文本类型的电子发票直接用XML文档处理工具进行解析,纸质发票的扫描件使用PaddleOCR进行识别。在识别纸质发票扫描件之前先解析二维码,得到二维码的位置信息和文本内容。基于位置信息对发票图像进行方向矫正,将矫正之后的图像送入OCR识别模块进行文字识别,并通过二维码解析得到的内容对OCR识别结果进行验证,从而提高识别结果的可靠性。
关键词:增值税发票;发票解析;发票识别
中图分类号:TP311" " 文献标识码:A" 文章编号:2096-4706(2024)10-0107-06
Research and Implementation of Value Added Tax Invoice Parsing and Recognition System
WANG Xiangjun, LIN Bingqing, CHEN Yuqiang, LIU Huifen
(College of Big Data and Internet, Shenzhen Technology University, Shenzhen" 518118, China)
Abstract: Value added tax invoices are the most commonly used payment vouchers in various economic transactions, and manual processing of invoices during financial reporting is inefficient. Based on this, the paper designs and implements a value added tax invoice parsing and recognition system. The system classifies different types of invoice documents. Electronic invoices in text type are directly parsed using XML document processing tools, while scanned copies of paper invoices are recognized using PaddleOCR. Before identifying scanned copies of paper invoices, first parse the QR code to obtain the location information and text content of the QR code. Based on location information, the invoice image is directional corrected, and the corrected image is sent to the OCR recognition module for text recognition. The content obtained through QR code parsing is used to verify the OCR recognition results, thereby improving the reliability of the recognition results.
Keywords: value added tax invoice; invoice parsing; invoice recognition
0" 引" 言
随着新一代信息技术浪潮袭来,新兴技术层出不穷,各项技术不断创新,相继融入经济社会发展的各个领域,展现出数字经济的蓬勃活力。增值税发票(以下简称“发票”)是记录商品交易行为的一种重要凭证,分为增值税普通发票和专用发票,主要有纸质和电子版两种形态。电子增值税发票因省却了纸张成本以及便于传递,逐渐成为信息化支付和入库的重要原始依据[1]。当前的电子增值税发票主要有.ofd和.pdf两种格式,这两种格式的电子发票都可以使用对应的解析工具进行信息提取。而纸质发票则需要扫描成电子文档后进行识别,百度和腾讯等大型IT公司都有提供对应的识别接口。由于发票信息的提取和识别直接关系到报账业务的正确性,对信息准确率的要求非常高。本系统会根据发票的不同而采用不同的处理方式,最大限度地提高准确率。
1" 系统设计
1.1" 系统架构设计
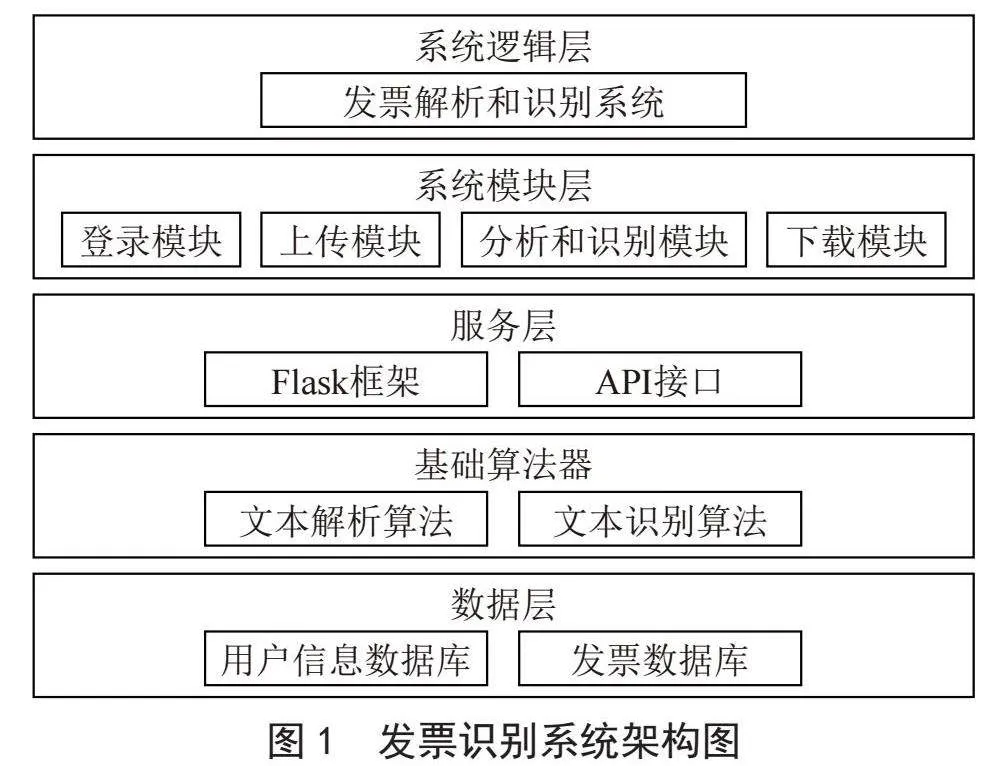
本系统采用的是B/S架构,前端部分通过HTML、CSS、JS等进行页面的开发和渲染,同时进行请求和响应。后端部分采用三层架构模型,由表现层、业务逻辑层、数据访问层组成。当表现层将客户请求下放时,业务逻辑层将调用业务逻辑进行业务处理,再对数据访问层发起对数据库增删改查的请求,系统最终将业务逻辑层与数据访问层交互的结果返回到表现层进行数据展示。系统架构图如图1所示。
1.2" 数据库设计
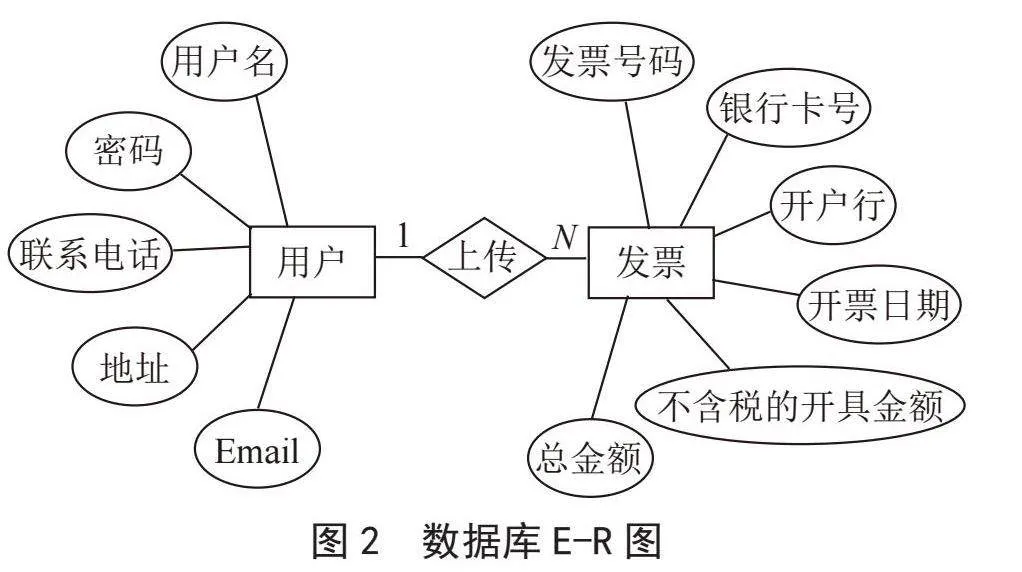
数据库是应用程序的关键要素之一,是系统设计的基石,好的数据库设计应当做到为系统提供翔实细致的数据分析和清晰简明的数据统计,做到具有较高的独立性和较小的冗余度。本系统主要是通过关系型数据库SQLite3实现的,数据库E-R图如图2所示,分为用户信息表和票据信息表。
用户信息表用于存储用户相关的信息,以系统使用者的ID作为主键,主要有用户名、密码、联系电话、地址等信息。创建用户信息表能够方便管理,提升效率。
用户在系统中上传发票后,系统会将识别后提取的内容存入票据信息表中供用户查询。其中以发票号码为主键,还包含有银行卡号、开户行、开票日期、不含税的开具金额、总金额五个字段。票据信息表会在内容展示页中将内容呈现给用户,用户还可以选中其中的某项数据进行大小排序。
1.3" 系统功能设计
增值税发票解析和识别系统主要是提供服务供财务报账的中间流程调用,结合信息处理等基础功能部署成Web系统,这样用户使用起来更加方便。针对该系统的目标用户及其使用需求,发票解析和识别系统需要具备如下基本功能:注册、登录、发票上传、发票识别、数据展示和数据下载等。
1.3.1" 注册登录
在用户登录模块中,前端在获取用户输入的登录信息后会将账号和密码与数据库中的账号密码进行比对。如果用户信息正确,回传系统主页;如果账号不存在,则提示用户注册账号。在用户注册账号时,前端会获取到用户填写的信息并将用户信息写入数据库。
当用户需要修改用户信息时,其提交修改信息,系统将用户提交的修改信息与原有信息进行对比。倘若信息无变化,返回“您的资料没有改动”,如果信息有变化,则存入数据库,同时反馈“您的资料已重新提交”的提示信息。
1.3.2" 发票上传
用户打开“上传文件”页面时呈现上传接口,在用户点击“上传”按钮后,系统对文件进行处理。
当用户选择文件时,前端会对文件类型进行判断。系统可对OFD、PDF、PNG和JPG等格式的文件进行解析或识别,如果是其他格式的文件则提示用户不支持该种类型文件的处理。在发票上传时为发票自动识别创建进程,前端以进度条显示当前处理进度,后端工作继续运转。
1.3.3" 发票识别
发票上传到系统后台后,后台会根据发票类型对发票进行解析或识别,获取发票上面的发票代码、发票号码、合计税额、合计金额、开票日期、销售方名称、销售方开户行及账号等信息返回给前端。
1.3.4" 发票下载
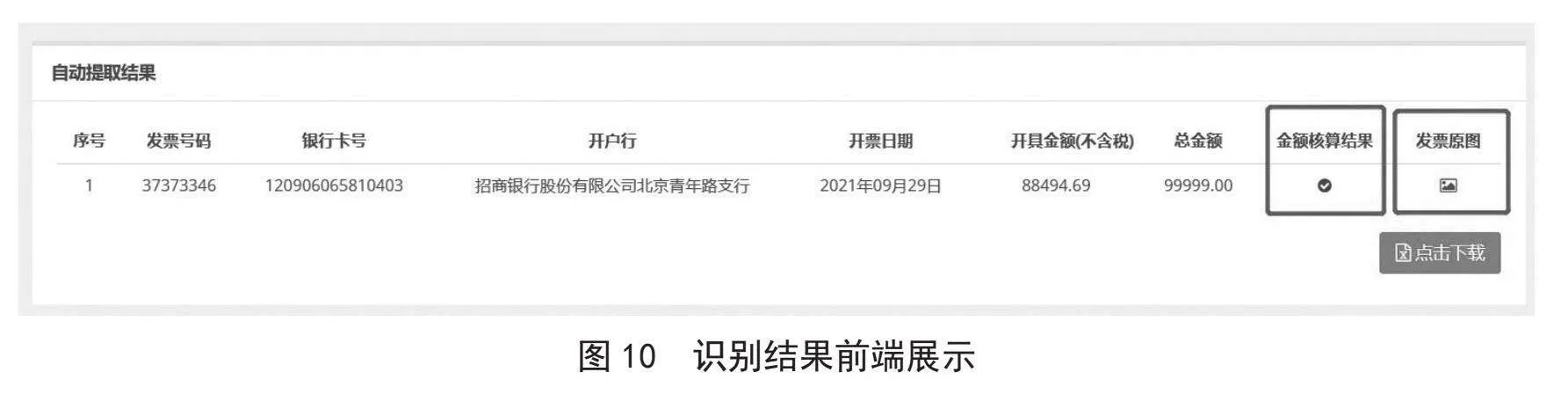
单次上传发票成功后,可以将该次识别的数据下载下来以供后续审查和使用。在发票审核页面中查询到该用户上传过的全部发票时,也可以根据需求下载曾经处理过的原始发票和处理过的发票信息。下载后的发票信息以CSV格式保存到本地,文件中包含发票号码、银行卡号、开户行等重要信息和金额核对等相关处理的结果。
2" 系统实现
本系统采用的是B/S架构,使用HTML、CSS、JavaScript以及开发框架Bootstrap进行前端开发。选用jQuery进行前后端数据交互和传递,采用jQuery作为微型JavaScript库,通过创建服务端函数并在服务端与客户端之间交换JSON数据,能够很好地体现Web应用的动态性特点[2]。在功能逻辑的实现上采用了以Python语言编写的Flask后台框架,Flask的特点在于其小巧灵活,可以很好地结合MVC模式,非常适用于中小型网站的开发[3]。
发票提取识别模块根据发票的类型进行相应的处理,电子发票一般有OFD和PDF两种格式,纸质发票扫描件有PDF、PNG和JPG等图片格式,不同格式发票需要采用不同的方法进行处理,OFD格式和文本格式的PDF文件可直接进行解析,而发票扫描件则需要进行文字识别。
2.1" 发票解析
OFD是开放版式文档(Open Fixed-layout Document)的英文缩写,是我国国家版式文档格式《GB/T 33190—2016电子文件存储与交换格式-版式文档》标准[4]。OFD文档不受设备影响,版式固定。在版式、版面、字体、字号等方面与纸质文件完全一致。版式文档格式的特点使它成为严肃类电子文档发布、数字化信息传播和电子存档的理想文档格式,特别适合用于保存电子发票。
OFD文件本身是压缩文件,在提取OFD格式的电子发票时,首先对文件进行解压缩,在解压的根目录下面有OFD.xml文件,如图3所示。
如图3所示,OFD.xml文件包含发票代码、发票号码、合计税额、合计金额和开票日期等信息,若要获得销售方名称和银行账号等信息,需要对./Doc_0/Attachs目录下的original_invoice.xml文件进行解析,该文件的部分内容如图4所示。
如图4所示,original_invoice.xml文件包含购买方名称、销售方名称、纳税号、地址、开户行等信息。OFD.xml和original_invoice.xml是xml格式的文件,利用xml解析库就可以得到所需的字段信息。而后缀为.pdf的发票文件可能是文本格式的电子发票,也可能是纸质版发票的扫描件,前者可直接运用PDF解析工具进行信息提取,后者则需要使用OCR方法进行字符识别[5]。但是发票文件中没有用以判断一份PDF文件到底是文本格式文件还是扫描件的字段,可以借助pdfplumber库来判断[6]。pdfplumber是一个用于处理PDF文件的Python库,可以提取文本、图像、表格等元素。它的extract_words函数可以获取文本类型PDF文件的文本内容,如果能够获取文本内容则为文本格式的PDF,否则就是扫描件。文本格式PDF文件利用pdfplumber的extract_text函数得到每一页的文本,然后运用正则表达式提取所需的字段信息。
2.2" 发票识别
纸质发票扫描件需要使用光学字符识别技术(Optical Character Recognition, OCR)进行识别,OCR是采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像,并通过识别算法将图像中的文字转换成文本格式的一种技术[7,8]。随着大数据以及人工智能掀起的狂潮,尤其是近年来深度学习的蓬勃发展,基于卷积神经网络的OCR技术可以快速识别到重要的信息,而且能达到很高的准确率。
目前,国内主流的ICT公司(例如腾讯、阿里巴巴、百度、华为和字节跳动)都有提供OCR服务[9]。其中,百度的PaddleOCR是一个开源的超轻量级OCR模型库[10],其通用OCR识别准确率已经超过95%,其端到端的识别模型将检测和识别放到一个网络结构中,使得训练的效率更高,预测阶段的资源开销更少,所以我们选用PaddleOCR识别纸质发票扫描件。
PaddleOCR对图片格式的发票进行识别,所以当发票扫描件为PDF格式时,需要先将其转换成图片。当前无论是增值税普通发票还是增值税专用发票都是横板的,即从正向看(文字从左向右,从上向下排列)发票图片的宽度比长度要大,但是发票扫描时可能会将纸质发票采集成竖版,所以还需要对发票的方向进行校正。当图片的长大于宽时,代表图片是竖直方向的,需要对图片进行由竖直向水平方向的旋转,但究竟是向左旋转90度还是向右旋转90度还需要做进一步的确定。
如图5(a)所示的发票需要向右旋转90度变为正向,而如图5(b)所示的发票需要向左旋转90度变成正向。我们可以借助发票上的二维码来判断发票当前的方向,图5(a)发票上的二维码在左下角,而图5(b)发票上的二维码在右上角。二维码的识别可以借助微信开发团队贡献给OpenCV社区的二维码扫描工具,先调用wechat_qrcode_WeChatQRCode()创建检测实例,再调用该实例的detectAndDecode()方法检测和识别二维码,它不仅能定位二维码所在的位置,还能解析二维码上的文本信息,对图5(b)发票调用二维码识别接口,得到的二维码识别结果如图6所示。
在如图6所示的二维码识别结果中,最上面一行数据是二维码的内容,其中的第三项044002000404是发票代码,第四项22477767是发票号码,第五项754.72是不含税的发票金额,第六项20221128是开票日期。第二行行首的array部分是二维码的坐标,每行有两个浮点数,分别表示二维码四个角的水平和竖直方向坐标。当二维码在左下角时,水平方向坐标较小,而竖直方向的坐标较大。反之,当二维码在右上角时,水平方向的坐标较大,竖直方向的坐标较小。我们可以根据二维码的坐标来确定向左还是向右旋转发票,将图5(b)发票向左旋转90度后得到矫正方向后的发票,如图7所示。
矫正图片方向后就可以调用PaddleOCR进行文字识别,调用PaddleOCR库的PaddleOCR()方法创建实例,然后调用该实例的ocr(self, img, det, rec, cls)方法进行识别。OCR方法有五个参数,第一个参数self表示类的实例本身,第二个参数img表示要识别的对象,可以是ndarray对象,图片的路径或者是列表对象,第三至第五个参数分别表示是否进行文本检测,是否进行文本识别,是否进行不同角度的识别,它们的默认值都是true。由于我们既要检测文本的位置,又要识别文本的内容,所以第三和第四个参数就使用默认值,但是我们在将图片对象送入OCR函数识别之前已经利用二维码信息对图片进行了方向矫正,所以将最后的参数cls设为1,这样就不用在各个方向上进行识别,提高处理速度。对如图7所示的发票进行OCR识别后得到如图8所示的识别结果(部分截图)。
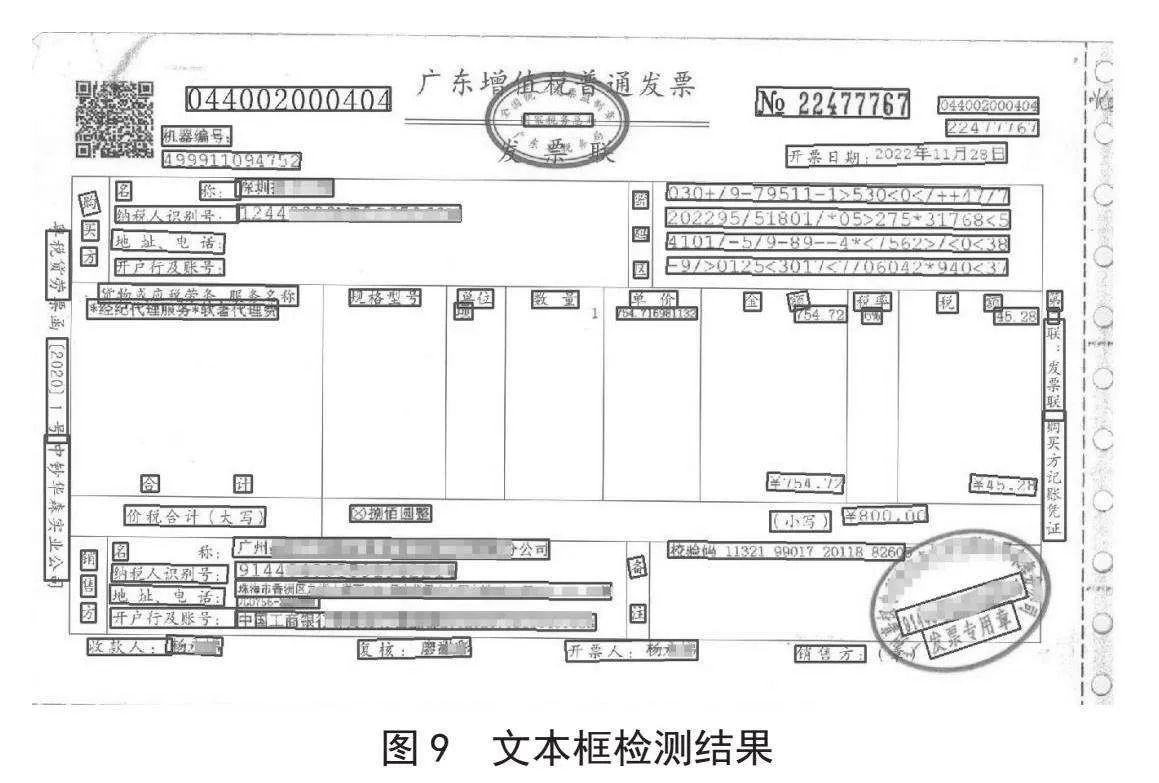
每行结果是一个列表,每个列表有两个元素,第一个元素是一个列表,该列表有四个元素,表示检测到文本框四个角的x轴和y轴坐标,第二个元素是一个元组,元组的第一个元素是文本框中包含的文字,第二个元素是置信度。我们提取所有的文本框信息画在原始发票图片上,可以看到如图9所示的文本框检测结果。
从图9可以看出,发票上绝大部分的文本框都检测出来了,但是OCR识别并不能达到100%的准确率,而发票信息直接关系到财务的安全,容不得半点差错。所以我们可以将如图6所示二维码识别结果和如图8所示识别结果的相同字段进行比对,如果有不一致的地方说明出现了识别错误,当出现识别错误时将该信息传递到前台界面,提示用户进行人工比对和手动矫正。
最后,将识别结果返回到前端进行页面展示,如图10所示。
3" 结" 论
本文设计并实现了增值税发票解析和识别系统,介绍了不同类型发票的解析和识别方法。利用二维码解析工具对发票图片的方向进行矫正,并对OCR的识别结果进行验证,以此保证发票识别结果的可靠性。后续考虑对接国税局的发票查询系统,对发票的真伪进行验证,进一步完善和提升系统的功能。
参考文献:
[1] 唐咏,王伟波.基于大数据平台的增值税发票识别与管理 [J].物联网技术,2022,12(6):125-126.
[2] 王梦梅,刘浩.基于jQuery Mobile的温室智能控制系统 [J].信息技术与信息化,2021(6):222-224.
[3] 唐满华,柳毅,段立军,等.基于MVC模式的科技管理信息系统设计与实现 [J].计算机技术与发展,2020,30(9):165-170.
[4] 陈亚军,张程,吕艳静.《信息技术OFD 档案应用指南》国家标准解读 [J].信息技术与标准化,2023(6):11-15.
[5] 张晔.电子文件归档格式研究 [D].沈阳:辽宁大学,2021.
[6] 周璐喆.面向PDF文件的研招数据辅助整合软件研发 [D].南昌:江西财经大学,2021.
[7] 刘艳菊,伊鑫海,李炎阁,等.深度学习在场景文字识别技术中的应用综述 [J].计算机工程与应用,2022,58(4):52-63.
[8] 刘崇宇,陈晓雪,罗灿杰,等.自然场景文本检测与识别的深度学习方法 [J].中国图象图形学报,2021,26(6):1330-1367.
[9] 仇建民.开源PaddleOCR技术在企业营业执照识别上的改进与实践 [J].现代信息科技,2021,5(9):65-69+74.
[10] 成日冉.基于嵌入式图像处理平台的集装箱编码识别系统研发 [D].成都:电子科技大学,2022.
作者简介:汪香君(1982.05—),女,汉族,湖北黄冈人,实验师,硕士,研究方向:人脸识别、深度学习;林冰清(2000.08—),女,汉族,广东深圳人,工程师,本科,研究方向:物联网工程;陈玉强(2002.10—),男,汉族,广东梅州人,本科在读,研究方向:数据科学与大数据技术;刘会芬(1983.11—),女,汉族,湖北黄冈人,实验师,硕士,研究方向:物联网应用、软件工程。
