


摘 要:简答题自动评分(ASAG)是智慧教育中的一个重要研究方向,解决该问题主要着眼于如何从参考答案、评分标准和学生作答信息中提取用来对比、评分的特征,通过构建模型和优化评估指标得到合理的学生作答评分。其中数据预处理和构建模型阶段多采用自然语言处理技术(NLP),近年来出现了以机器学习为主导的特点。文章综合梳理了ASAG的研究和发展,首先梳理、归纳出ASAG的五种解决方案,重点对基于机器学习的ASAG解决方法进行了总结,分析了中文、英文实现ASAG的区别,以及各方案关注点和相关主流算法;其次对比了ASAG主要算法特征以及它们在典型数据集上的效果;最后阐述了简答题自动评分研究面临的问题和挑战,以及未来的发展趋势。
关键词:简答题自动评分;自然语言处理;机器学习;智慧教育
中图分类号:TP391;TP18 文献标识码:A 文章编号:2096-4706(2024)14-0013-08
A Review of the Development of Machine Learning in Solving Automatic Scoring Problems for Short Answer Questions
XU Jining, HUANG Nan, GONG Bo
(School of Electrical and Control Engineering, North China University of Technology, Beijing 100144, China)
Abstract: Automatic Short Answer Grading (ASAG) is an important research direction in smart education, which focuses on how to extract features for comparison and grading from reference answers, grading criteria and student response information, and to obtain reasonable grading for student response by building models and optimizing assessment metrics. Natural Language Processing (NLP) is mostly used in the stages of data pre-processing and model building, and Machine Learning has emerged as a mainstream in recent years. It comprehensively summarizes the research and development for ASAG. Firstly, five solutions of ASAG are sorted out and summarized, a focused summary of Machine Learning based on ASAG solutions is presented, the differences between Chinese and English implementations of ASAG is analyzed, and the concerns of each solution and relevant mainstream algorithms are compared and summarized. Then, it compares the main algorithm features of ASAG and their effectiveness on typical datasets. Finally, the current problems and challenges faced by the research on ASAG and the future trends are described.
Keywords: ASAG; Natural Language Processing; Machine Learning; smart education
DOI:10.19850/j.cnki.2096-4706.2024.14.004
收稿日期:2024-01-04
基金项目:北京市教委北京市数字教育研究重点课题(BDEC2022619001)
0 引 言
国务院于2017年、2019年分别印发的《国家教育事业发展“十三五”规划》《中国教育现代化2035》提出要借助信息技术,大力开展实施智能教育[1]。自动评分是智慧教育领域的一项重要研究任务,简答题是主观题评价中的常见环节。近年来,国内外学者围绕简答题自动评分(Automatic Short Answer Grading, ASAG)问题进行了多种方法的研究,探索如何更客观准确地对学生作答进行评分,研究涉及语义分析、深度神经网络、知识图谱等技术。本文收集整理了59篇解决ASAG问题的国内外相关文献,对ASAG的研究方法、发展情况、相关算法做了梳理分析,重点关注了基于机器学习的解决方法,并归纳出现阶段ASGA中存在的问题和未来发展趋势。
1 简答题自动评分研究现状
1.1 技术发展历史和特征
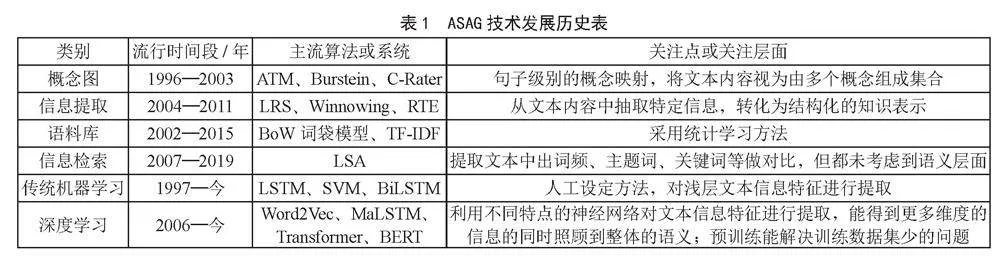
迄今为止,ASAG的5类解决方案及其各自主要关注点总结如表1所示。
ASAG系统最早可追溯到1966年Delta发表的论文,开启了自然语言文本自动评分的研究领域[2]。
ASAG数据预处理和自然语言处理(Natural Language Processing, NLP)技术的发展紧密相关,从早期利用字符串检索,到人工构建近义词词林,逐步发展到最新的基于语音相似度统计计算的阶段[3]。最早出现的是One-Hot独热编码形式,即用一个向量表示单个词,作为词汇的特征,该方法为词向量的出现埋下了伏笔[4]。随后Google中的研究团队提出了一些基于空间向量的编码方式,如2013年,Mikolov等的Word2Vec词向量模型[5];2017年由Vaswani等人提出的Transformer模型[6],以及2019由Devlin提出的当下NLP领域最为流行的BERT(Bidirectional Encoder Representations from Transformers)模型[7]。BERT模型将Transformer模型进行堆叠并引入双向编码技术,在NLP语句编码中取得优秀成果。
简答题自动评分的基本思路可归纳为图1所示流程,首先从学生作答和参考答案中分别提取特征,再进行相似度对比,其核心是提取用于对比内容的特征。提取两文本特征的方法主要有:概念图、词袋法、抽离出三元组结构对比、抽离文本向量等(神经网络可视为文本的encoder抽取文本特征);相似度对比方面,常用cos相似度、sim相似度、Frobenius范数等[8-15]进行对比。
鉴于中文和拼音文字的不同特点,下面就ASAG的国内外发展予以综述分析。由于国内对ASAG的研究晚于国外,所以采用先国外后国内的顺序,最后列举出中英文在实现ASAG时的区别。
1.2 国外研究现状
国外学者主要使用概念图(Concept Mappings)、信息抽取(Information Extraction, IE)、语料库(Corpus-based Methods)、信息检索(Information Retrieval, IR)以及机器学习(Machine Learning)方法[16]。
概念图技术最早,在1996年Burstein提出将简答题作答内容映射成为概念,通过概念或概念关系与标准答案进行匹配[7]。在此基础上,Caller与Leacock分别于2001和2003年开发了Automatic Text Marker(ATM)与C-Rater算法[17-18]。
信息抽取技术通过模板搜索和建模对文本信息进行抽取和匹配,从文本等非结构化数据中抽取结构化数据表示为元组以供在众多领域中使用[19]。Mitchell、Thomas在2002到2003年使用了IE中的语法树作为评分方法[20-21]。2007年Sima提出利用人工标注与分模式匹配的eMax算法进行评分[22]。2011年Cutrone利用词袋进行计算匹配率对作答内容进行评分[23]。2012年Hahn用LRS模型将参考答案和作答内容构成图(Graph)的形式作为对比评分依据[24]。2015年Sahu利用语义、单词重叠等多种特征的综合相似度作为评分依据[25]。2018年Ratna提取文本的对比依据是利用Winnowing算法生成一组最小哈希或指纹作为输出的文本[26]。2019年Basak利用识别文本蕴含RTE(Recognizing Textual Entailment)从内容中抽取三元组进行结构对比[27]。
基于语料库实现ASAG大多通过统计学手段抽离词袋模型,计算参考答案和作答内容的相似程度,如在2004年Diab与Alfonseca基于语言模型N-Gram标准化长度样本和词义重叠率计算相似率值,并在评价指标上使用不同变体[28-29]。2020年Süzen使用BW单词袋模型,从文档集合提取独特单词转化为单词频率向量来表示文本特征[30]。
信息检索(IR)技术应用于ASAG问题,早期通过英文单词或者中文字符串匹配的方式进行评分。如今信息检索领域常用算法是潜在语义分析LSA(Latent Semantic Analysis),利用矩阵分解基于话题挖掘文本语义关系,表示单词-文本矩阵并奇异值分解,以得到的主题词向量空间代表整个文本。在2011年Klein用LSA分析参考答案和作答内容的潜在语义[31]。2017年Pribadi使用单词重叠法来衡量参考答案与作答间的相似度[9]。2018年Hasanah采用了与Pribadi相同度量相似度的方法,但数据预处理环节使用了多种方法[32]。2019年Ratna用聚类算法K-means判断作答是否符合题意,再用LSA将文本提取用于对比的特征[10]。
基于机器学习的ASAG,早期受算力和NLP技术等限制,主要通过SVM和决策树等分类与回归算法对简答题进行评分[16]。近年来随着深度神经网络技术的成熟,机器学习可以弥补早期技术提取文本特征维数不够的问题,擅长处理序列信息的RNN(Recurrent Neural Network)网络,及LSTM(Long Short-Term Memory)循环神经网络模型、GRU(Gate Recurrent Unit)等均有应用。从2017年开始,BERT和Transformer等预训练模型开始用于解决ASAG问题。
机器学习方法的常见思路是用神经网络作为对比内容的特征编码器,从而输出对比向量。2018年Prabhudesai用BiLSTM(Bi-directional Long Short-Term Memory)神经网络对简答题进行评分[33]。同年,Ye用堆叠多层LSTM形成编码器,将文本编码成向量作为相似度比较依据[34]。基于LSTM的孪生神经网络MaLSTM(ManhaĴanLSTM)被用于多输入和单输出的场景,如文本相似度检验、人脸识别等[35]。2021年Tulu提出基于同义词集的词嵌入方法SemSpace,将上下文嵌入,利用MaLSTM将作答和参考答案在隐藏层中转化为向量,用曼哈顿距离计算相似度[36]。2022年,Sawatzki基于北得克萨斯大学的短答案评分数据集进行实验,将BERT模型与基于Ans2vec方法建立特征提取架构,再对比特征转换进行特征融合后,输入线性模型的解决方案进行了对比,发现BERT模型对英语和德语表现最好[37]。同年,Garg提出改进的带余弦相似性的问答BERT模型[11]。2020年Gomaa使用Ans2vec模型提取Skip-thought向量[38]。同年,Zhang引入DBN(Deep Belief Network)神经网络解决问题,由分层预训练优化参数[12]。
上述研究中,BERT模型在ASAG预处理中的表现尤为值得关注。因为它结构上分为预训练与下游任务微调两部分,预训练部分主要对语句进行双向编码,不同语言均可使用不同的预训练模型编码成相对统一的句向量形式。这使得ASAG在数据预处理阶段之后能获得相对统一的数据形式,使得不同语言的ASAG在建模、评分以及模型评估这几个阶段存在相互借鉴的可能性。
此外,一些学者引入关系网络或者图谱解决问题,2021年Li提出SFRN算法(Semantic Feature-wise transformation Relation Network),用基于语义特征的转换关系网络来学习,将问题Q、参考答案R、作答A构成向量三元组。编码器对QRA三元组各分量编码,作为相似度计算依据[39]。2022年Agarwal提出多关系图转换器MitiGaTe(Multi-Relational Graph Transformer)融入评分依据的结构性因素,将文本解析为图的形式作为分数依据。在英文Mohler数据集上MitiGaTe模型以0.762的均方根误差优于其他对比模型[40]。算法优化方面,2021年Sahani使用并行LSTM,使用不同特征向量考察不同指标[41]。
1.3 中文ASAG研究现状
由于中文不像英文有单词的天然分隔,在分词方面,中文简答题评分难度高于英文。早期中文ASAG在数据预处理阶段通常要将句子拆分成多个词,再利用概念图、信息检索、信息抽取等方法计算相似度。
基于信息抽取方法,2012年程传鹏抽取参考答案和作答的关键词形成二部图,并使用同义词词林计算二者之间词语的相似度[42]。2019年王逸凡使用基于命名实体识别的关键词提取方法以及基于同义词词林的词语相似度分析[43]。
基于信息检索方法,2007年田绪安等采用基于字符串的关键词模糊匹配的方法,不同于英文文本的词检索,使用的是对正文单字或字段进行检索[44]。2017年楚尚武使用LDA(Latent Dirichlet Allocation)模型计算参考答案和学生作答的主题分布相似度[45]。2018年姚洪发采用jieba分词工具做文本预处理,用TF-IDF及LSA提取文本特征作为相似度度量基础[46]。
近五年国内学者的研究主要集中在用机器学习的深度学习技术构建模型,从而提取作答和参考答案的特征。2019年李冰提出深度神经网络使机器获得抽象概念能力,可以使主观题自动阅卷提升准确率[47]。2019年李永丹用简答题评分模型提取两种语义特征;利用BERT、BiLSTM及注意力机制提取深层语义特征,浅层特征包括词汇和句子的特征[48]。罗枭提取关键词,用由BiLSTM、CNN和Attention机制组成网络架构BiLSTM-CA,SST-1和SST-2数据集实验中分别取得52.8%和89.7%的正确率[14]。
2020年杨松利用多头自注意力机制模拟多人主观判分进行关系抽取,降低了阅卷偏差,将其与BiLSTM网络结合进行评分,精确率、召回率、F1值均达到了较好的效果[49]。午泽鹏提出了基于注意力机制的Att-Grader模型,通过LSTM网络将对比特征编码捕获语义信息,用CNN网络获取局部特征。同时还利用K-means聚类,选择簇内与其他样例相似度最高的样例作为参考答案的补充[50]。王冲提出字符级的RCNN模型,先将作答进行字符级向量嵌入,通过LSTM层和降维处理,输出类别标签[51]。2021年郭振鹏使用CNN-BiGRU-CRF模型提升中文分词的准确性,用非线性加权TF-IDF算法及Word2Vec-CNN算法,计算参考答案和作答的相似度[52]。
在多特征融合计算相似度方面,乔亚男将题型和科目作为相似度的权值[53]。肖灵云综合文本、语义、关键词3种相似度,利用段落向量训练方法Doc2vec模型计算文本相似度[54-55]。2022年王金水分别计算专业术语和通用词语两种相似度,并综合考虑句子的词序、词形和搭配词对相似度,三个特征的加权得到结果分数[56]。同年,张展鑫提出利用BERT和互注意力机制提取对比特征,对比相似度时考虑到了关键词和语义,对于关键词组的匹配则使用同义词词林[57]。同年钱升华引入孪生网络,提出孪生BERT模型评分,在编码层后增加池化层来降低噪声影响,对比特征使用余弦相似度[15]。
2 ASAG方法归纳和对比
2.1 五种实现方法的特点和局限
基于概念图的方法在不同学科领域之间迁移时,需要专家对该领域概念进行词典扩展和持续更新,对人工成本较高,难以大规模使用。
基于语料库方法是利用通用性的统计学习方法,但需要大型文档语料库的支持,且一般词袋模型都没有考虑语义或句意,影响后期评分质量。
基于信息抽取的方法是从文本中抽取和提取特定的信息或实体,并将其转化为结构化的形式化的知识表示,以便后续分析处理。
基于信息检索的方法是从内容中检索和寻找,与特定问题或查询相匹配的文本。该方法对于建模算法有很强的依赖性。
基于机器学习的方法早期利用RNN、LSTM提取对比内容特征。近些年,深度神经网络弥补了特征维度不足的问题,利用更宽更深的网络结构挖掘出更多的潜在特征,有效地解决了高维信息难以表示、数据稀疏性、模糊属性难以提取等问题。该方法在不同学科领域之间迁移能力最强。
2.2 中文、英文实现ASAG的区别
中文和英文ASAG的不同主要体现在预处理阶段,其原因在于他们的处理存在如下区别:
1)分词。中文的单元词汇边界较为模糊,缺少英文文本中空格这样明确的分隔符。
2)词素/词元。英文构词基于词根和丰富的形态变化,可通过词形还原(lemmatization)和词干提取(stemming)等预处理操作简化文本;而中文没有明显的词形变换特征,容易造成许多边界歧义。
3)语法、句法结构。英文句子间的连接关系清晰,语句连接多是从属结构。中文的句子结构比较松散,靠语义连接而不靠连接词[58]。在预训练模型中基于英文训练集而得到句子位置、句子成分的权重,不能在汉语中发挥相应的效果。
4)多义性。中文存在多义性、句式复杂表达灵活、省略多等特点。语境比英文更加复杂,同一词语在不同领域中表示意思不同,同种语义也可存在多种表达形式。
3 ASAG应用算法总结
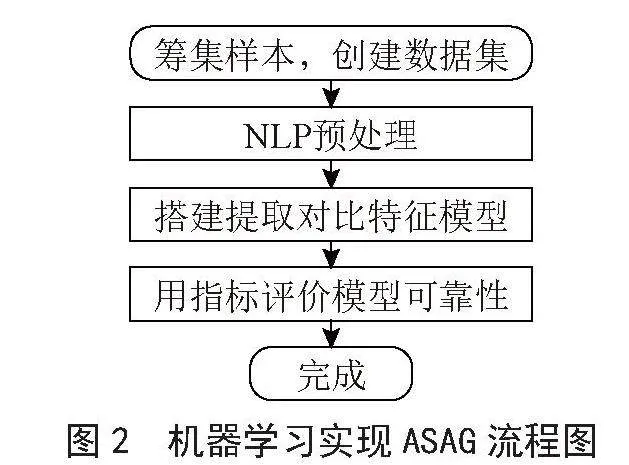
3.1 机器学习技术实现ASAG的流程
机器学习ASAG实现流程包括建立数据集、数据预处理、提取对比特征的模型、得到测试集预测结果以及模型评估[59] 5部分,如图2所示。目前主要采用的机器学习技术是深度学习。
3.2 深度学习解决ASAG部分算法对比
信息检索、深度学习是研究主流和热点。所以将这两种ASAG解决方案的算法思路特点进行对比整理,分别于表2和表3中呈现。
3.3 评价指标
评估模型预测与真实值之间的相关性和差异性的常见评价指标如下:
1)皮尔逊相关系数Pearson、平均绝对误差MAE和均方根误差RMSE。有些论文对比时只选两个。
2)准确率(A)、Kappa系数:准确率评估简答题自动评分模型的准确性,计算式如式(1)。其中,M1表示标注得分,M2表示模型得分,MTSQ表示题目总分(Total Score Of The Question)。
(1)
在文本分类中也常用Kappa系数作为评价指标,Kappa系数可以衡量预测结果与实际结果的一致性,它取值范围一般在-1到1之间。
3)精确率(Precision)、召回率(Recall)、F1值:精确率评估模型的查准率,即正确分类的样本在所有测试样本中所占的比例。召回率是评估模型的查全率,F1值是综合考虑准确率和召回率。
3.4 不同算法在典型数据集的效果对比
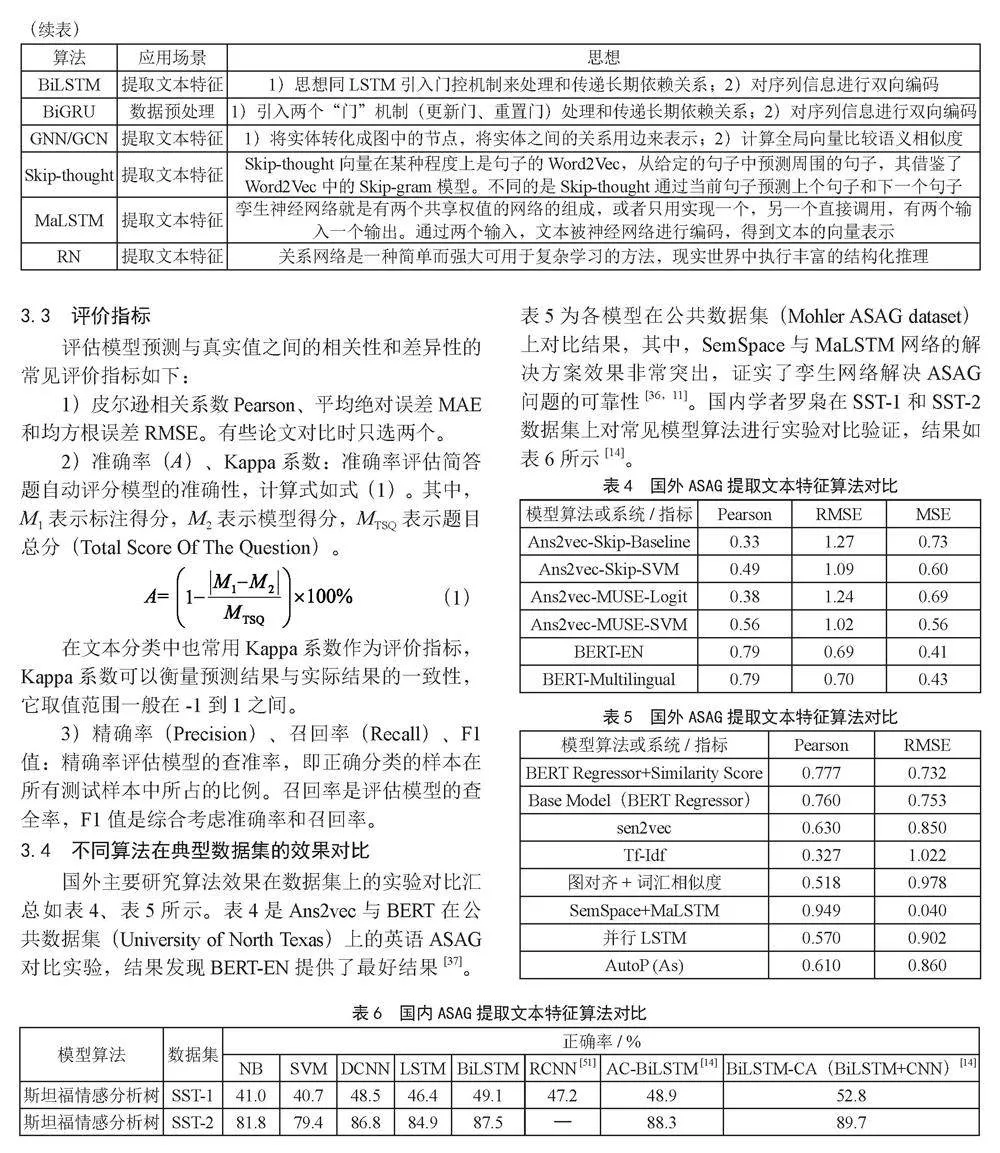
国外主要研究算法效果在数据集上的实验对比汇总如表4、表5所示。表4是Ans2vec与BERT在公共数据集(University of North Texas)上的英语ASAG对比实验,结果发现BERT-EN提供了最好结果[37]。表5为各模型在公共数据集(Mohler ASAG dataset)上对比结果,其中,SemSpace与MaLSTM网络的解决方案效果非常突出,证实了孪生网络解决ASAG问题的可靠性[36,11]。国内学者罗枭在SST-1和SST-2数据集上对常见模型算法进行实验对比验证,结果如表6所示[14]。
4 ASAG研究面临问题和挑战
现阶段简答题自动评分一些难点亟待解决,一是使用语义匹配的评分缺乏解释性,无法确定得分与被考查知识的关系。二是对开放式问题的评分方法目前研究较少。
针对上述问题,除了考虑多特征融合计算相似度,还可以增加、扩展简答题评分相关的考察点,比如引入题干表述、题目类型等;其次可以综合欧式与非欧式模型各自的分析优势,进行协同评价。在中文ASAG具体应用中,还存在专项训练的数据集不足,缺少学科垂直领域的预训练模型等问题。以后可以引入多模态数据的解决办法,或者利用ChatGPT等大模型进行评分。
5 结 论
主观题自动评分是教育领域一直想实现和突破的一个问题,因人工智能、自然语言处理等技术融合的研究仍有待深入,目前让模型理解复杂和深度语义仍然是一个挑战,尽管如今大语言模型的语言理解能力有目共睹,但理解复杂的语义、掌握话语中的含义、领会非文字语境等方面,还存在难以覆盖的问题。这对主观题评分造成了挑战,因为学生的答案语义可能复杂并含多重含义。所以想在教学任务中实现中文主观题自动评分仍是难题。同时对于例如表格等多种作答形式的简答题自动批改,仍然是领域内的一个棘手问题。本文对五种ASAG解决方案的思路要点和主流算法进行了总结对比,重点分析了最新的机器学习解决方案。特别关注了中文、英文实现ASAG的区别,阐述了常用的评价指标,对深度学习解决ASAG问题的主要算法优缺点以及在公开数据集上的效果对比进行了总结梳理。
随着技术成熟和发展,未来的教学辅助领域可以引入学习者画像和知识建模,实施动态的个性化练习题推荐,因材施教;还可以根据学生知识基础和能力倾向,有针对性的生成适合的试题。以ASAG为代表的主观题自动批改解决方案的发展和普及是教育教学数字化转型的重要组成部分,对全面、全流程提高学生自主学习能力和素质有显著的现实意义。
参考文献:
[1] 杨琴,蒋志辉,何向阳.智慧教育的缘起、挑战与发展路向追问 [J].当代教育论坛,2019(6):108-115.
[2] WRESCH W. The Imminence of Grading Essays by Computer—25 Years Later [J].Computers and Composition,1993,10(2):45-58.
[3] 南铉国.基于语句相似度计算的主观题自动评分技术研究 [D].延吉:延边大学,2007.
[4] BENGIO Y,SCHWENK H,SENÉCAL J S,et al. Neural Probabilistic Language Models [M]//Holmes D E,Jain L C. Innovations in Machine Learning,[S.I.]:Springer-Verlag,2006:137-186.
[5] MIKOLOV T,CHEN K,CORRADO G,et al. Efficient Estimation of Word Representations in Vector Space [J/OL].arXiv:1301.3781 [cs.CL].[2023-12-06].https://arxiv.org/abs/1301.3781v1.
[6] VASWANI A,SHAZEER N,PARMAR N,et al. Attention is All you Need [C]//Proceedings of the 31st International Conference on Neural Information Processing Systems.Long Beach:Curran Associates Inc.,2017:6000-6010.
[7] DEVLIN J,CHANG M W,LEE K,et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [J/OL].arXiv:1810.04805 [cs.CL].[2023-12-06].https://arxiv.org/abs/1810.04805.
[8] RATNA A A P,SANTIAR L,IBRAHIM I,et al. Latent Semantic Analysis and Winnowing Algorithm Based Automatic Japanese Short Essay Answer Grading System Comparative Performance [C]//2019 IEEE 10th International Conference on Awareness Science and Technology.Morioka:IEEE,2019:1-7.
[9] PRIBADI F S,ADJI T B,PERMANASARI A E,et al. Automatic Short Answer Scoring Using Words Overlapping Methods [C]//Proceedings of the 5th International Conference on Education, Concept, and Application of Green Technology.Semarang:AIP Publishing,2017,1818(1):020042.https://doi.org/10.1063/1.4976906.
[10] RATNA A A P,NOVIAINDRIANI R R,SANTIAR L,et al. K-Means Clustering for Answer Categorization on Latent Semantic Analysis Automatic Japanese Short Essay Grading System [C]//2019 16th International Conference on Quality in Research (QIR):International Symposium on Electrical and Computer Engineering.Padang:IEEE,2019:1-5.
[11] GARG J,PAPREJA J,APURVA K,et al. Domain-Specific Hybrid BERT based System for Automatic Short Answer Grading [C]//2022 2nd International Conference on Intelligent Technologies.Hubli:IEEE,2022:1-6.
[12] ZHANG Y,LIN C,CHI M. Going deeper: Automatic Short-Answer Grading by Combining Student and Question Models [J].User Modeling and User-Adapted Interaction,2020,30:51-80.
[13] 梁晓诚,岳晓光,麦范金,等.基于自然语言处理的主观题评分算法研究 [J].昆明理工大学学报:理工版,2010,35(2):81-84.
[14] 罗枭.基于深度学习的课程主观题自动判卷技术研究与实现 [D].杭州:浙江农林大学,2019.
[15] 钱升华.基于孪生网络和BERT模型的主观题自动评分系统 [J].计算机系统应用,2022,31(3):143-149.
[16] BURROWS S,GUREVYCH I,STEIN B. The Eras and Trends of Automatic Short Answer Grading [J].International Journal of Artificial Intelligence in Education,2015,25(1):60-117.
[17] CALLEAR D,JERRAMS-SMITH J,SOH V. CAA of Short Non-MCQ Answers [J/OL].Computer Science, Education,2001[2023-12-10].https://www.semanticscholar.org/paper/CAA-of-Short-Non-MCQ-Answers-Callear-Jerrams-Smith/515938ae02e12cbdc054175d42bb1e6d41aacb3c?p2df.
[18] LEACOCK C,CHODOROW M. C-Rater: Automated Scoring of Short-Answer Questions [J].Computers and the Humanities,2003,37:389-405.
[19] FARIA C,GIRARDI R. An Information Extraction Process for Semi-automatic Ontology Population [C]//Soft Computing Models in Industrial and Environmental Applications,6th International Conference SOCO 2011.[S.I.]:Springer,2011:319-328.
[20] MITCHELL T,RUSSELL T,BROOMHEAD P,et al. Towards Robust Computerised Marking of Free-Text Responses [J]. Computer Science,2002:233-249.
[21] THOMAS P. The Evaluation of Electronic Marking of Examinations [J]. ACM SIGCSE Bulletin,2003,35(3):50-54.
[22] SIMA D,SCHMUCK B,SZÖLLŐSI S,et al. Intelligent Short Text Assessment in eMax [C]//AFRICON 2007.Windhoek:IEEE,2007:1-7.
[23] CUTRONE L,CHANG M,KINSHUK. Auto-Assessor: Computerized Assessment System for Marking Students Short-Answers Automatically [C]//2011 IEEE International Conference on Technology for Education. Chennai:IEEE,2011:81-88.
[24] HAHN M,MEURERS D. Evaluating the Meaning of Answers to Reading Comprehension Questions: A Semantics-Based Approach [C]//Proceedings of the Seventh Workshop on Building Educational Applications Using NLP.Montreal:Association for Computational Linguistics,2012:326-336.
[25] SAHU A,BHOWMICK P K. Feature Engineering and Ensemble-Based Approach for Improving Automatic Short-Answer Grading Performance [J].IEEE Transactions on Learning Technologies,2019,13(1):77-90.
[26] RATNA A A P,LALITA LUHURKINANTI D L,IBRAHIM I,et al. Automatic Essay Grading System for Japanese Language Examination Using Winnowing Algorithm [C]//2018 International Seminar on Application for Technology of Information and Communication. Semarang:IEEE,2018:565-569.
[27] BASAK R,NASKAR S,GELBUKH A. Short-Answer Grading Using Textual Entailment [J].Journal of Intelligent & Fuzzy Systems,2019,36(5):4909-4919.
[28] DIAB M,RESNIK P. An Unsupervised Method for Word Sense Tagging Using Parallel Corpora [C]//Proceedings of the 40th Annual Meeting on Association for Computational Linguistics.Philadelphia:Association for Computational Linguistics,2022:255-262.
[29] ALFONSECA E,PÉREZ D. Automatic Assessment of Open Ended Questions with a Bleu-Inspired Algorithm and Shallow NLP [C]//4th International Conference,EsTAL 2004.Alicante:Springer,2004:25-35.
[30] SÜZEN N,GORBAN A N,LEVESLEY J,et al. Automatic Short Answer Grading and Feedback Using Text Mining Methods [J].Procedia Computer Science,2020,169:726-743.
[31] KLEIN R,KYRILOV A,TOKMAN M. Automated assessment of short free-text responses in computer science using latent semantic analysis [C]//Proceedings of the 16th annual joint conference on Innovation and technology in computer science education.Darmstadt:Association for Computing Machinery,2011:158-162.
[32] HASANAH U,ASTUTI T,WAHYUDI R,et al. An Experimental Study of Text Preprocessing Techniques for Automatic Short Answer Grading in Indonesian [C]//2018 3rd International Conference on Information Technology, Information System and Electrical Engineering.Yogyakarta:IEEE,2018:230-234.
[33] PRABHUDESAI A,DUONG T N B. Automatic Short Answer Grading using Siamese Bidirectional LSTM Based Regression [C]//2019 IEEE International Conference on Engineering,Technology and Education.Yogyakarta:IEEE,2019:1-6.
[34] YE X F,MANOHARAN S. Machine Learning Techniques to Automate Scoring of Constructed-Response Type Assessments [C]//2018 28th EAEEIE Annual Conference.Hafnarfjordur:IEEE,2018:1-6.
[35] MUELLER J,THYAGARAJAN A. Siamese Recurrent Architectures for Learning Sentence Similarity [C]//Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence.Phoenix:AAAI Press,2016:2786-2792.
[36] TULU C N,OZKAYA O,ORHAN U. Automatic Short Answer Grading With SemSpace Sense Vectors and MaLSTM [J].IEEE Access,2021,9:19270-19280.
[37] SAWATZKI J,SCHLIPPE T,BENNER-WICKNER M. Deep Learning Techniques for Automatic Short Answer Grading: Predicting Scores for English and German Answers [C]//Proceedings of 2021 2nd International Conference on Artificial Intelligence in Education Technology.Nanjing:Springer,2022:65-75.
[38] GOMAA W H,FAHMY A A. Ans2vec: A Scoring System for Short Answers [C]//The International Conference on Advanced Machine Learning Technologies and Applications.Cairo:Springer,Cham,2020:586-595.
[39] LI Z H,TOMAR Y,PASSONNEAU R J. A Semantic Feature-Wise Transformation Relation Network for Automatic Short Answer Grading [C]//The 2021 Conference on Empirical Methods in Natural Language Processing.Punta Cana:[s.n.],2021:6030-6040.
[40] AGARWAL R,KHURANA V,GROVER K,et al. Multi-Relational Graph Transformer for Automatic Short Answer Grading [C]//2022 Annual Conference of the North American Chapter of the Association for Computational Linguistics. Seattle:[s.n.],2022:2001-2012.
[41] SAHANI A,MEHTA S,RAMESH R,et al. An AES System to Assist Teachers in Grading Language Proficiency and Domain Accuracy Using LSTM Networks [C]//Proceedings of the 29th International Conference on Computers in Education.Asia-Pacific Society for Computers in Education.Taiwan:ICCE,2022:309-314.
[42] 程传鹏,齐晖.文本相似度计算在主观题评分中的应用 [J].计算机工程,2012,38(5):288-290.
[43] 王逸凡,李国平.基于语义相似度及命名实体识别的主观题自动评分方法 [J].电子测量技术,2019,42(2):84-87.
[44] 田绪安,郭华磊,刘瑞光,等.基于模糊匹配的主观题评分在线考试系统 [J].现代电子技术,2007(12):96-98.
[45] 楚尚武.基于LDA主题模型的主观题自动评分算法 [D].长沙:湘潭大学,2017.
[46] 姚洪发.基于TF-IDF及LSI的主观题自动评分系统的研究——以系统建模与仿真课程为例 [D].昆明:昆明理工大学,2017.
[47] 李冰.计算机技术在主观题自动阅卷中的应用述评 [J].江苏科技信息,2019,36(8):39-43+54.
[48] 李永丹.面向模糊语义和多相似度的简答题评分方法研究 [D].武汉:华中师范大学,2019.
[49] 杨松,卫文学. Multi Head-Self Attention BiLSTM网络应用于主观题评分的研究 [J]. 软件,2020,41(12):180-184.
[50] 午泽鹏.简答题自动评分方法研究 [D].太原:山西大学,2020.
[51] 王冲.短答案自动评分方法研究 [D].太原:山西大学,2020.
[52] 郭振鹏.基于中文分词与文本相似度的主观题评分系统研究与实现 [D].太原:太原理工大学,2021.
[53] 乔亚男,胡名凯,薄钧戈.基于特征融合的主观题智能阅卷算法研究 [J].电气电子教学学报,2021,43(6):104-111.
[54] 肖灵云,刘军库.基于相似度组合的主观题评分方法研究 [J].贵州大学学报:自然科学版,2021,38(5):64-68.
[55] 肖灵云,刘军库,李春红.基于doc2vec的主观题自动评分应用 [J].现代计算机,2022,28(1):79-82+95.
[56] 王金水,郭伟文,陈俊岩,等.多特征融合的电气领域主观题自动评分方法 [J].贵州大学学报:自然科学版,2022,39(2):77-82.
[57] 张展鑫.主观题自动评分方法的研究 [D].广州:广东工业大学,2022.
[58] 吴敏建.浅谈英语与汉语结构上的几点区别 [J].福建外语,1992(Z2):37-39+31.
[59] HASANAH U,PERMANASARI A E,KUSUMAWARDANI S S,et al. A Review of an Information Extraction Technique Approach for Automatic Short Answer Grading [C]//2016 1st International Conference on Information Technology,Information Systems and Electrical Engineering.Yogyakarta:IEEE,2016:192-196.
作者简介:徐继宁(1970—),女,汉族,陕西兴平人,副教授,博士,研究方向:控制理论与模式识别、智慧教育等;通讯作者:黄楠(1997—),男,汉族,北京人,硕士在读,研究方向:深度学习、自然语言处理、智慧教育;龚博(1996—),男,汉族,北京人,硕士在读,研究方向:深度学习、自然语言处理、智慧教育。