摘 要:随着人工智能时代的加速到来,高性能计算、人工智能计算等多元化算力成为当前数字信息社会发展的生产力核心,通过搭建算力网络能够充分调动分布式算力中心资源。华中科技大学通过整合校内多个算力中心,实现算力资源的统一调度管理。文章阐述跨域算力集群的软硬件环境,并基于PyTorch框架对比各个算力中心的AI性能。实验结果证明,平台支持AI算力的跨域调用,采用一定优化方案后,可以完全解决跨域数据传输带来的性能瓶颈。
关键词:人工智能;高性能计算;跨域算力;PyTorch
中图分类号:TP18;TP38 文献标识码:A 文章编号:2096-4706(2024)14-0043-06
AI Performance Testing and Optimization Based on University-level
Cross-domain Computing Power Cluster
ZHANG Ce, ZHANG Kaizhen, LONG Tao
(Network and Computing Center, Huazhong University of Science and Technology, Wuhan 430074, China)
Abstract: With the accelerated arrival of the era of Artificial Intelligence, high-performance computing, Artificial Intelligence computing and other diversified computing power has become the productivity core of the current development of digital information society, and the construction of computing power network can fully mobilize the resources of distributed computing power center. Huazhong University of Science and Technology realizes the unified scheduling and management of computing power resources by integrating multiple computing power centers in the university. This paper describes the hardware and software environment of cross-domain computing power cluster, and compares the AI performance of each computing power center based on PyTorch framework. The experimental results show that the platform supports the cross-domain call of AI computing power, and the performance bottleneck caused by cross-domain data transmission can be completely solved by adopting certain optimization schemes.
Keywords: Artificial Intelligence; high performance computing; cross-domain computing power; PyTorch
DOI:10.19850/j.cnki.2096-4706.2024.14.009
0 引 言
近年来,高性能计算(HPC)技术发展迅速,已经进入E级时代[1],HPC应用也从过去的高端科学计算领域转向新兴的互联网大数据和人工智能领域,随着HPC与云计算、大数据、AI不断融合创新,多元化算力作为生产力核心,成为当前整个数字信息社会发展的关键[2]。目前,人工智能算力需求[3]是算力发展的主要动力,由超级计算、云计算等组成的强大算力和通过物联网、互联网技术收集的大数据,以及机器学习、深度学习等算法,被公认为是人工智能时代的三驾马车[4]。为推进全国算力和数据中心建设的一体化进程,国家于2021年启动了“东数西算”工程,规划了10个国家数据中心集群。为充分发挥算力资源的作用,必须提高算力资源利用率,需要在各个算力中心之间构建一张高带宽、低延时的算力网络,让算力能够像电力一样形成一张网,随时可以跨域调配。在这一大背景下,华中科技大学根据校内各单位算力集群“散而小”的实际情况,创新性地采取“众筹式”建设模式,整合校内各个算力中心资源,并构建跨域算力网络,实现了算力的跨域调用。同时,在校级算力平台上,利用PyTorch框架下的图像分类模型训练,对比在各个算力中心上的AI算力性能,验证跨域算力平台对于深度学习应用的支持效果。
1 校级跨域算力集群
相对其他高校,华中科技大学校级算力平台的建设起步较晚,很多有科研计算需求的院系和团队早已独立建设了一定规模的超算集群。但是,院系或课题组级超算集群相对校级平台而言存在一些问题,比如机房配套环境难以满足、缺少专职运维管理人员、资源分散不均等。在此背景下,校级算力平台采用“众筹式”建设模式,推动各个学院、课题组计算资源的统一管理,有效整合校内多个算力中心资源,实现算力共建共享共用。
1.1 硬件架构
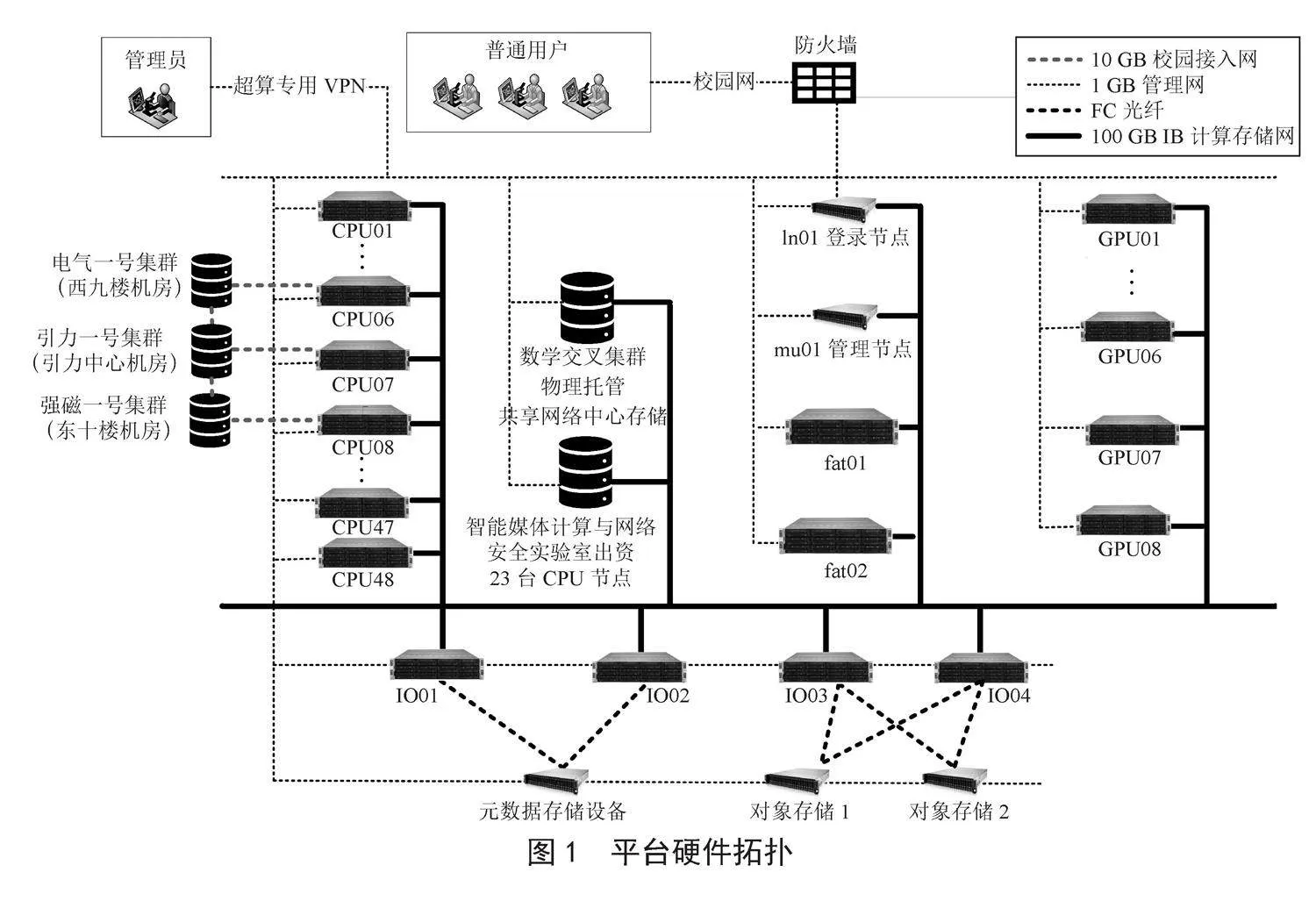
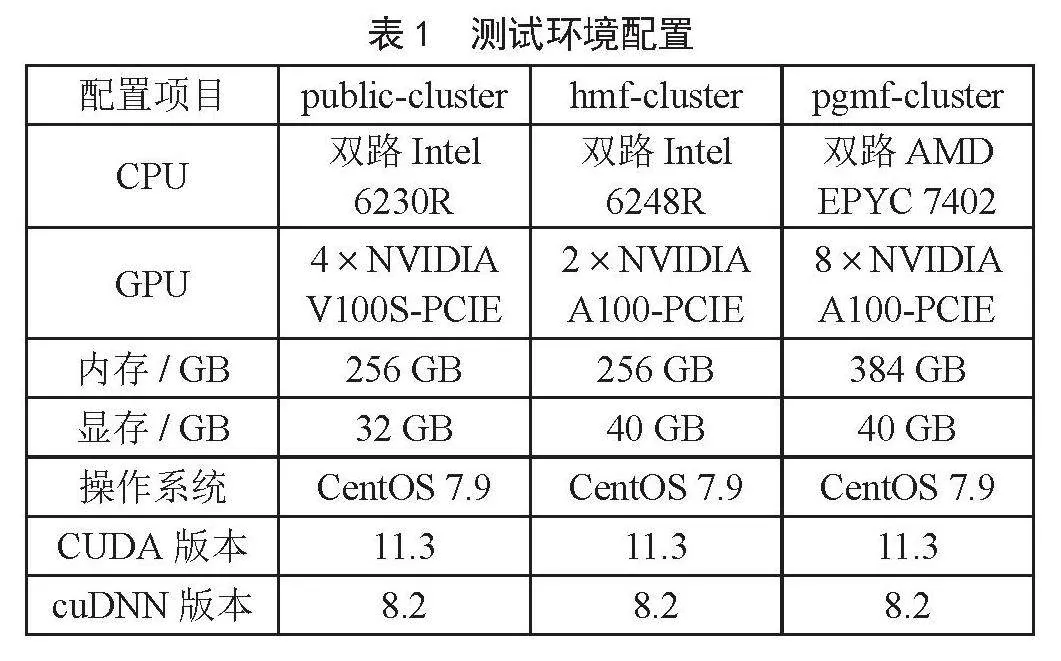
学校公共集群(public-cluster,学校超算一期)投入569.6万元,配有1个登录节点、1个管理节点、58个计算节点、4个IO节点和3台存储设备,其中计算节点包含48个CPU节点、8个GPU节点、2个胖节点,IO节点包含2个元数据节点和2个对象存储节点,存储设备包含1台元数据存储和2台对象数据存储。
平台整体硬件拓扑架构如图1所示,通过本地物理托管和远程接入方式先后完成了数学交叉研究院(数学交叉集群)、国家脉冲强磁场科学中心(hmf-cluster,强磁一号集群)、精密重力测量国家重大科技基础设施(pgmf-cluster,引力一号集群)、电气学院高性能数据采集分析系统(电气一号集群)、智能媒体计算实验室等多家单位的算力中心和资源的接入纳管,整合各集群资源后的理论峰值算力达2.5 PFLOPS,可用存储容量4 PB。其中,电气一号、强磁一号和引力一号为远程接入,这三个集群的机房与公共集群机房物理隔离,公共集群机房通过与三个集群直连万兆光纤的方式进行远程管理。在数据存储方面,强磁一号集群通过远程挂载方式使用公共集群机房的存储,引力一号因自身具备存储设备,所以直接使用本地存储,并挂载学校存储以便集群间的数据拷贝。
1.2 软件环境
校级算力平台面向全校师生提供计算服务,为满足高性能计算、人工智能计算、大数据、实验教学等不同场景下的多样化需求,平台采用容器技术,将分布在校内不同位置的本地硬件资源虚拟化,通过对底层资源抽象、封装、整合以及调度管理,提供给用户一个可伸缩、可定制、可隔离的计算环境,这个环境可以是传统的超算集群,也可以是一台高性能工作站,也可以是一个即插即用的SaaS计算软件。对普通用户而言,根据自身需求申请使用不同的资源类型,比如选择某个公共集群登录并提交Slurm计算任务,或通过平台的Web页面申请独占一台或多台裸金属机器,或通过平台创建一个预装好某计算软件的容器实例。在公共集群中,利用Lustre并行文件系统保证所有计算节点存储共享数据,常用的计算软件、编译环境被安装在集群的共享目录下供所有用户使用,并利用Module工具管理用户的环境变量。单机或容器实例为用户独占资源,用户具备管理员权限,可以使用本地磁盘存储数据,也可以使用并行文件系统。
Python是数据分析、机器学习和深度学习等方向的主流编程语言,Python的版本比较多,并且它的库也非常广泛,同时库和库之间存在很多依赖关系,所以在库的安装和版本的管理上很麻烦。Conda是一个管理版本和Python环境的工具,它使用起来非常容易。公共集群中会预先创建好常用的Conda环境,并安装对应的依赖库,比如PyTorch、TensorFlow、Deepmd、AlphaFold等,用户在公共集群上可以使用Conda命令切换到需要的环境后直接运行程序。虽然公共集群可以通过Conda切换软件环境,但是有些深度学习代码对GPU显卡驱动版本有特殊要求,用户此时可以申请独占的单机资源,使用管理员权限重新安装驱动。
2 深度学习应用
深度学习是通过建立一种类似人脑分析学习的神经网络,模仿人脑的机制来解释数据,如声音、图形和文本的识别等。从数学模型的角度上看,深度学习是一种复杂的特征提取方法,通过一些非线性模型将原始数据变成更高层次的抽象表达,再组合多层变换,学习提取出函数特征方法[5]。卷积神经网络是深度学习中的一种基本模型,这种网络可以看成是卷积运算和矩阵运算的组合,2012年卷积神经网络[6]首次用于ImageNet大规模视觉识别挑战赛(ImageNet Large Scale Visual Recognition Challenge, ILSVRC)并获得冠军,之后卷积神经网络在图像领域受到越来越多的关注。ImageNet数据集[7]是图像识别项目中最大、最常用的数据库,共有1 400多万张图像,包含气球轮胎等2万多个类别,ImageNet主要用于计算机视觉识别的研究。由于深度学习神经网络的每个卷积运算和矩阵运算都是独立的,可以采用高度并行的方式进行计算,而GPU相比于CPU拥有更多独立的大吞吐量计算通道,所以深度学习和神经网络模型非常适合采用GPU进行加速计算。
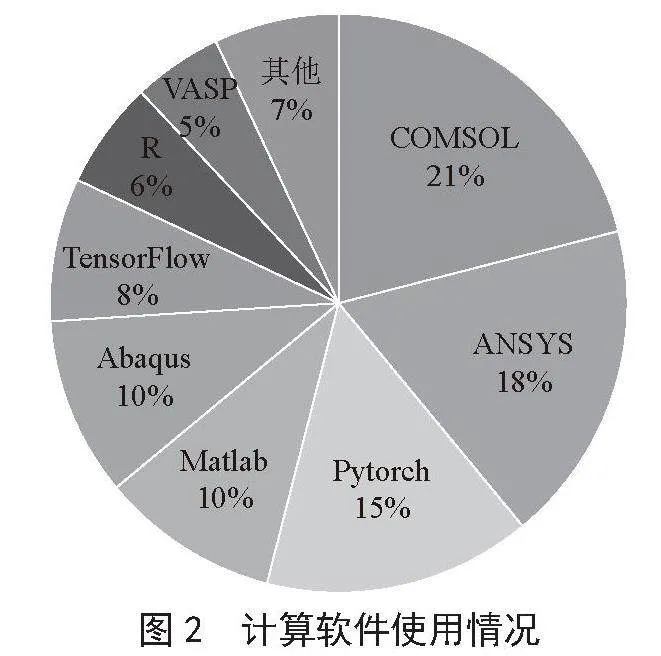
目前,我校算力平台上的深度学习计算需求绝大部分是计算机视觉领域,如三维重建、视频跟踪等,主要用户来自计算机学院、电子信息与通信学院和网络安全学院的团队。平台上使用的深度学习框架主要是PyTorch和TensorFlow,其使用率在所有计算软件中占比23%,其中PyTorch占比15%,仅次于传统科学计算领域的COMSOL和ANSYS软件,如图2所示。PyTorch是由Facebook公司基于Torch框架开发的深度学习框架,同时也是一个原生的Python包,它具有动态计算图表、精简的后端与高度可扩展等优势[8],是深度学习领域的主流框架。
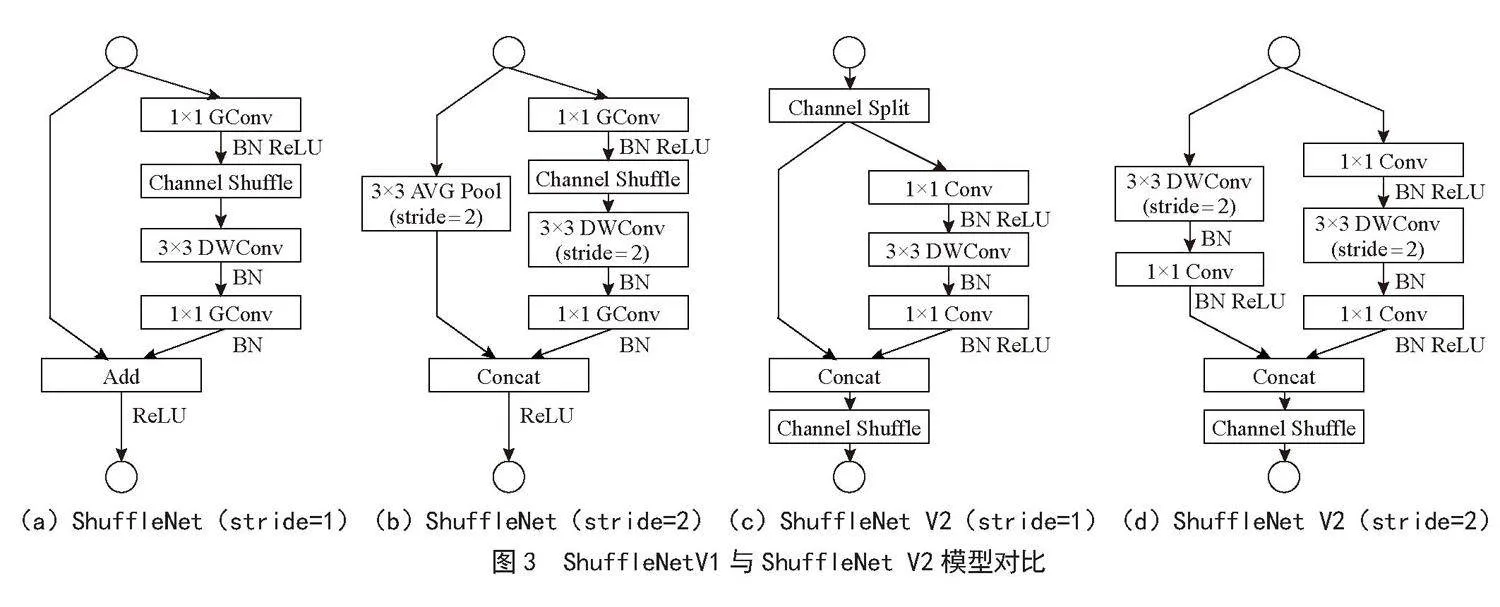
近年来,深度卷积神经网络如ResNet [9]和GoogLeNet [10]已经极大提高了图像分类的准确度,但是计算复杂度同样也是网络模型需要考虑的重要指标,网络如果太过复杂会影响计算速度,一些特定场景如无人车领域则需要低延迟。ShuffleNet是旷视[11]提出的一种轻量级的卷积神经网络,其主要思想是采用通道混洗、点态卷积以及深度可分离卷积来修改ResNet单元,ShuffleNet V2 [12]是ShuffleNet的升级版本,被ECCV2018收录。ShuffleNet V2针对V1使用逐点组卷积和类似瓶颈结构增加了MAC的问题,引入了通道分割操作。在同等复杂度下,ShuffleNet V2比ShuffleNet更准确,两者网络模型对比如图3所示。
3 性能分析
为快速分析深度学习应用在我校各个算力中心集群上的实际性能,本文针对基于PyTorch架构的ShuffleNet V2模型进行训练性能的测试。
由于ImageNet数据集太大,在验证性能方面耗时太久,本文选取Mini-ImageNet [13]数据集进行实验对比,该数据集是Google DeepMind团队从ImagNet数据集中抽取的一小部分组成,其在元学习和小样本学习领域应用广泛。Mini-ImageNet共有100个类别,每个类别都有600张JPG格式的图片,共60 000张,而且图像的大小并不是固定的。
3.1 测试环境
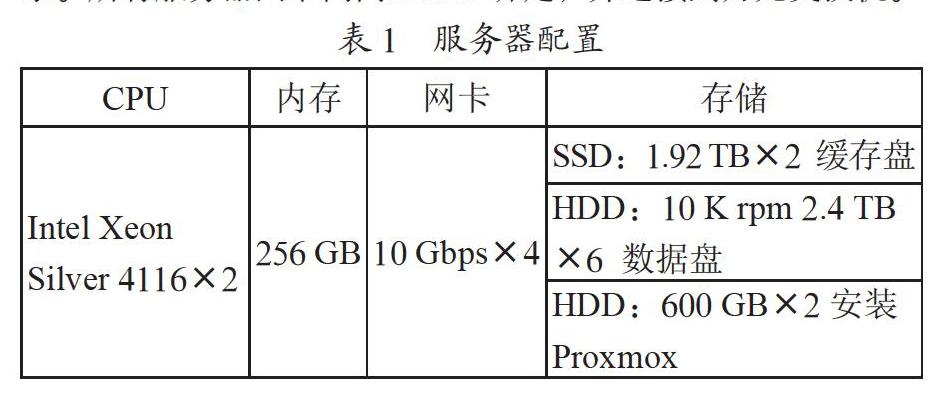
本次实验在学校公共集群(public-cluster)、强磁一号集群(hmf-cluster)和引力一号集群(pgmf-cluster)的GPU服务器上进行。其中,公共集群提供的是一台独占的裸金属机器,数据集放在机器本地磁盘,强磁一号和引力一号集群则是通过Slurm作业调度系统分配一台交互式计算节点,强磁一号因为本地机房没有独立的存储设备,通过万兆校园专网直连到公共集群机房的磁盘阵列,因此在强磁一号上加载数据集时涉及远程跨域数据访问,引力一号本地具备独立且相当性能的存储设备,数据集存放在本地集群的Lustre并行文件系统上。各算力中心集群的具体软硬件环境配置如表1所示。
3.2 测试方案
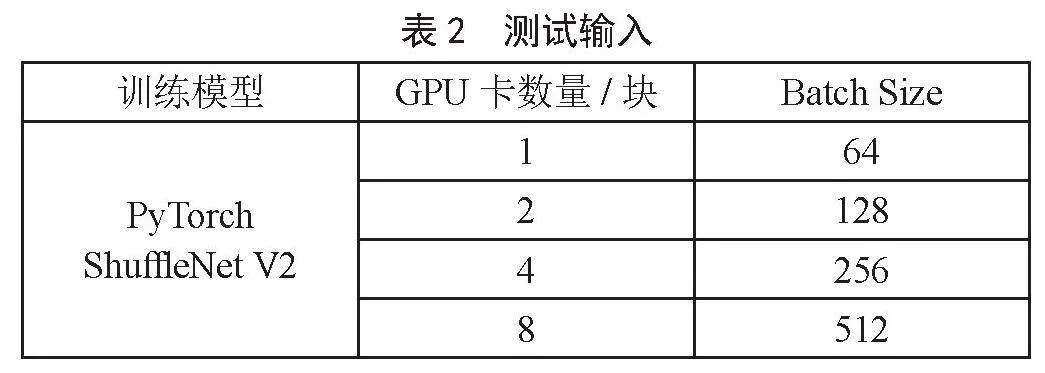
实验使用Mini-ImageNet数据集训练ShuffleNet V2模型,在公共集群上进行1、2、4块GPU卡的训练测试,在强磁一号上进行1、2块GPU卡的测试,在引力一号上进行1、2、4、8块GPU卡的测试,为保证负载均衡,Batch Size值也做了相应的调整,实验输入如表2所示。
3.3 测试结果
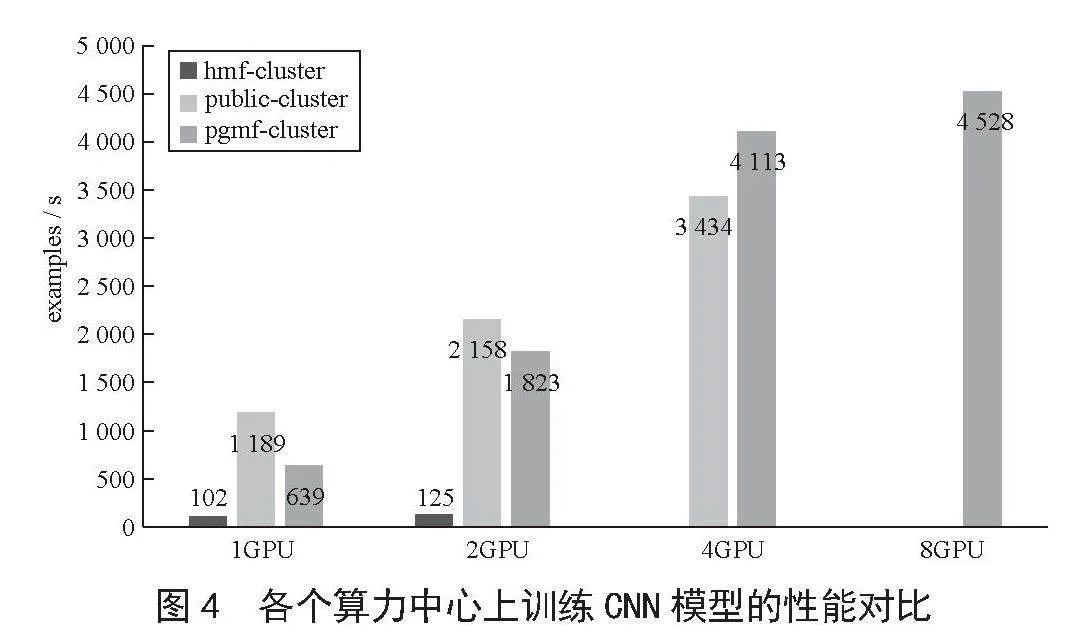
实验结果如图4所示,在强磁一号集群hmf-cluster上不管是1卡还是2卡,其训练速度远远低于另外两个集群,因为PyTorch不是计算密集型应用,在每个Batch训练之前需要加载大量样本数据,对IOPS性能要求高,而强磁一号上的训练数据是通过频繁的远程访问其他算力中心的存储获取。实验结果还证实了Lustre文件系统在海量小文件上的性能表现非常差,引力一号集群pgmf-cluster在Batch Size较小时,由于涉及大量频繁的小文件读写,因此即使其GPU卡配置高于公共集群public-cluster,最终训练速度仍然低于使用本地文件系统的公共集群,当Batch Size变大时,其高配置的显卡优势才得以体现。
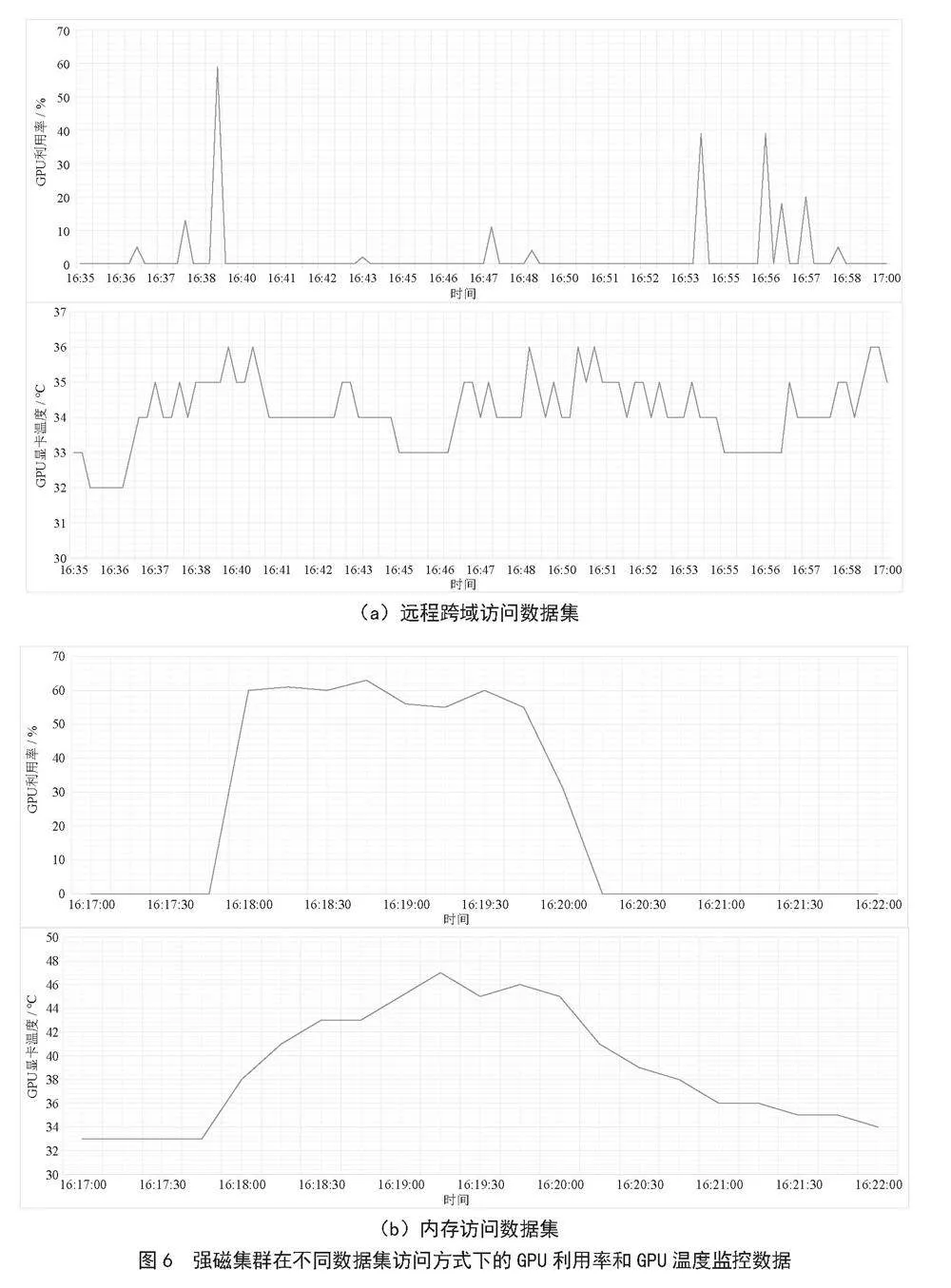
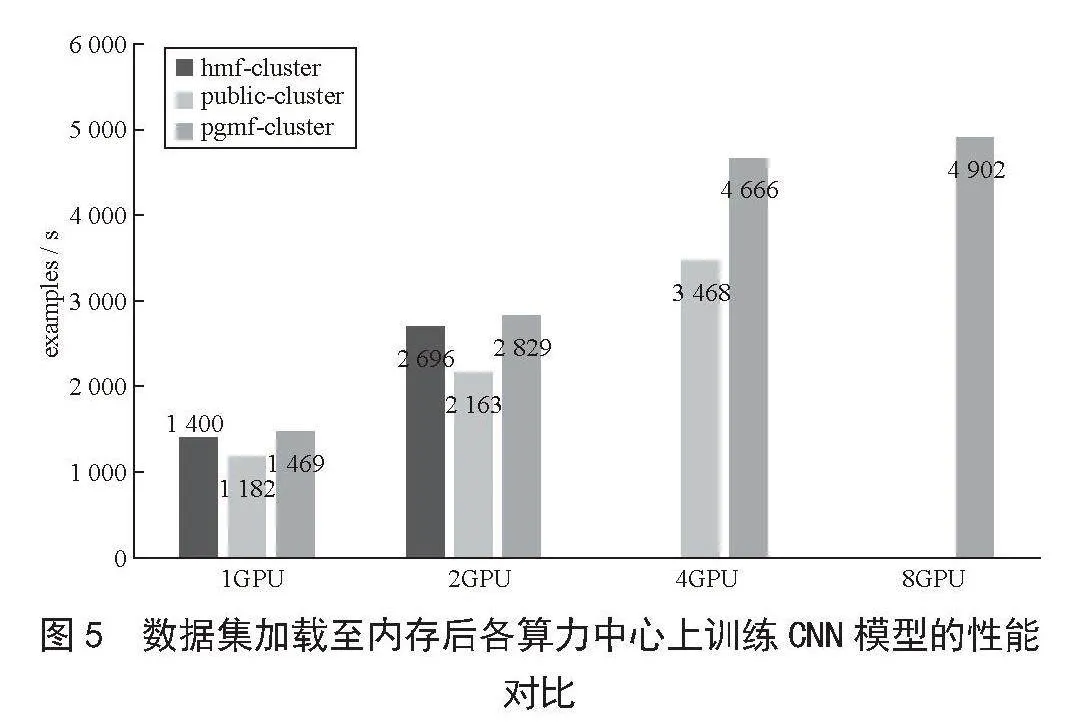
由于本次实验数据集比较小,为降低IO性能对PyTorch训练的影响,又进行第二次实验,这次不使用文件系统存放数据集,而是将Mini-ImageNet数据全部拷贝到GPU节点的/dev/shm目录,即提前将所有数据集加载到本地内存中,然后按照之前的测试方案再进行一轮测试,最终结果如图5所示。可以看出,强磁一号集群hmf-cluster和引力一号集群pgmf-cluster的训练速度几乎相同,且高于公共集群public-cluster,说明在解决IO性能瓶颈后,PyTorch训练速度最终受到GPU显卡本身的配置影响。
为了更直观地体现IO性能对PyTorch应用的影响,两次实验都通过Grafana对GPU利用率和GPU显卡温度进行监控,图6(a)为强磁一号集群hmf-cluster上采用一张GPU卡通过远程跨域访问数据集时训练一个Epoch的监控数据,图6(b)为强磁一号集群hmf-cluster上采用一张GPU卡且将数据集提前加载到节点内存后训练一个Epoch的监控数据,对比后可以发现,将数据加载到内存后,GPU显卡的平均利用率获得显著提高。
根据实验结果可以得出以下结论,在跨域算力集群中,非计算密集型任务不适合在运行时进行跨域数据访问,针对PyTorch这类对IO要求高的应用,小文件随机读的性能瓶颈明显,数据集应尽量放在算力中心本地存储,而非远程其他算力中心存储,如果内存容量允许,可以直接将数据集全部放在计算节点本地内存中,这样可以最大限度地降低IO影响,提高GPU使用率,最大化利用GPU显卡的性能。
4 结 论
AI大模型的火爆进一步激发了各行各业对智能算力的需求,同时国家也不断加大投入构建算力基础设施。但是只有算力是不够的,当前算力资源并未得到充分利用,必须通过构建跨域算力网络将不同算力资源进行混合调度输送,实现算力的远程调用。在高校级别的算力平台上,同样存在算力资源分布不均且小而散的情况,并且同样出现了大量人工智能研究的计算需求,因此需要整合全校算力资源,并保证整合后的资源能够有效支撑对人工智能领域的研究。本文分享了华中科技大学跨域算力集群的软硬件环境,并基于PyTorch框架实践对比了各个算力中心的AI性能,证实了平台可以支持AI算力的跨域调用,但由于深度学习训练算法并非经典的计算密集型任务,不适合跨域数据访问,针对此场景提供了将数据集放在集群本地存储或节点内存的解决方案,实验结果表明此方案能够有效降低IO影响,提高GPU利用率。
参考文献:
[1] ZHENG W M. Research Trend of Large-scale Supercomputers and Applications from the TOP500 and Gordon Bell Prize [J].Science China Information Sciences,2020,63(7):124-137.
[2] 张云泉,袁良,袁国兴,等.2022年中国高性能计算机发展现状分析与展望 [J].数据与计算发展前沿,2022,4(6):3-12.
[3] 国务院.新一代人工智能发展规划 [EB/OL].(2017-07-08).https://www.gov.cn/gongbao/content/2017/content_5216427.htm.
[4] 张云泉,方娟,贾海鹏,等.人工智能三驾马车——大数据、算力和算法 [M].北京:科学献出版社,2021.
[5] 毛勇华,桂小林,李前,等.深度学习应用技术研究 [J].计算机应用研究,2016,33(11):3201-3205.
[6] KRIZHEVSKY A,SUTSKEVER I,HINTON G E. ImageNet Classification with Deep Convolutional Neural Networks [J].Communications of the ACM,2017,60(6):84-90.
[7] DENG J,DONG W,SOCHER R,et al. ImageNet: A Large-scale Hierarchical Image Database [C]//2009 IEEE Conference on Computer Vision and Pattern Recognition.Miami:IEEE,2009:248-255.
[8] 张康林,叶春明,李钊慧,等.基于PyTorch的LSTM模型对股价的分析与预测 [J].计算机技术与发展,2021,31(1):161-167.
[9] HE K M,ZHANG X Y,REN S Q,et al. Deep Residual Learning for Image Recognition [J/OL].arXiv:1512.03385 [cs.CV].(2015-12-10).https://arxiv.org/abs/1512.03385.
[10] SZEGEDY C,LIU W,JIA Y Q,et al. Going Deeper with Convolutions [J/OL].arXiv:1409.4842 [cs.CV].(2014-09-17).https://arxiv.org/abs/1409.4842.
[11] ZHANG X Y,ZHOU X Y,LIN M X,et al. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices [J/OL].arXiv:1707.01083 [cs.CV].(2017-07-04).https://arxiv.org/abs/1707.01083v2.
[12] MA N N,ZHANG X Y,ZHENG H-T,et al. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design [J/OL].arXiv:1807.11164 [cs.CV].(2018-07-30).https://arxiv.org/abs/1807.11164.
[13] RUSSAKOVSKY O,DENG J,SU H,et al. ImageNet Large Scale Visual Recognition Challenge [J/OL].arXiv:1409.0575 [cs.CV].(2014-09-01).https://arxiv.org/abs/1409.0575v3.
作者简介:张策(1992.10—),男,汉族,湖北黄冈人,工程师,硕士,研究方向:高性能计算;通讯作者:龙涛(1974.03—),男,汉族,湖北武汉人,高级工程师,博士,研究方向:数据中心信息化。
收稿日期:2023-12-04