
摘 要:当前深度学习技术对数据库自然语言查询的实现起到了很大的推动作用,但是仍存在难以实现复杂查询、准确率不高等问题。因此,提出了新型数据库自然语言查询实现方案,设计了一种基于谓词的、类Prolog语言的中间语言,以自然语言—中间语言—SQL的方式实现了很高的准确率,解决了自然语言与SQL语句之间语义差距大的问题,可以投入到实际应用中。还提出了一种学习样本自动生成的方法,降低了数据库自然语言查询技术的使用难度。
关键词:数据库自然语言查询;NL2SQL;谓词推理;学习样本自动生成
中图分类号:TP391.1;TP311 文献标识码:A 文章编号:2096-4706(2024)15-0051-05
A New Implementation Scheme for“Database Natural Language Query”
FU Tingxuan, CHEN Qiming, YANG Huaiyu
(Faculty of Information Engineering and Automation, Kunming University of Science and Technology, Kunming 650504, Unc+nQZzFYvhlqL+Hb+APA==China)
Abstract: The current Deep Learning technology has played a significant role in promoting the implementation of natural language query in databases, but there are still problems such as difficulty in implementing complex queries and low accuracy. Therefore, a new implementation scheme for natural language query in databases has been proposed, and an intermediate language based on predicate and language similar to Prolog has been designed to achieve high accuracy in a natural language—intermediate language—SQL manner, solving the problem of large semantic differences between natural language and SQL statements. It can be put into practical applications. A method for automatically generating learning samples has also been proposed, which reduces the difficulty of using natural language query techniques in databases.
Keywords: database natural language query; NL2SQL; predicate inference; automatic generation of learning sample
0 引 言
非专业人员在对数据库中的信息进行统计分析时,结构化查询语言(SQL)是一个必须要克服的障碍。随着深度学习技术在自然语言处理领域中广泛的应用,利用自然语言查询生成SQL语句(NL2SQL)的研究也获得了很大的进展,比较引人注目的是出现一系列基于BERT解决NL2SQL问题的模型结构,如SQLNet [1]、Type SQL [2]、SQLova [3]、X-SQL [4]、M-SQL [5]等。
但是仍存在如下一些问题:
1)对于单表的查询准确率较高,文献[6-7]对追一科技的NL2SQL数据集准确率达到90%以上。但是仍低于期望值,而且在实际应用中,仅仅是单表查询远远不能满足实际需求。
2)对于多表查询准确率一般,文献[6]对于多表查询的DuSQL数据集准确率达到80%左右的,但是这个准确率达不到实用标准。
3)基于深度学习技术来实现NL2SQL,必然面对一个问题,就是学习样本的建立面临较大困难。深度学习需要大量的学习样本数据,当前理论研究所使用的数据集都是手工创建或半自动创建的[8],若将NL2SQL技术投入实际应用,如何简单快捷的创建样本数据是一个必须解决的问题。
4)在一些场景下,由于业务逻辑的复杂性,一些查询要求很难用一个SQL查询语句去描述,也很难用自然语言来表达查询要求。
1 一种新的解决思路
在一些应用场景中,具有复杂的数据表关系和复杂的业务逻辑,这时候自然语言与查询语句具有很大的语义差距,直接实现NL2SQL的难度很大[9]。为了在复杂应用场景中提供一种实用的数据库自然语言查询技术,本文采用了一种新的解决思路。
鉴于自然语言(NL)和SQL语句之间语义差距很大,引入一种过渡性的中间语言,实现一个NL—中间语言—SQL的流程。
本文受到GEO数据集[10]的启发,设计一个类Prolog语言的中间语言。此种基于谓词的中间语言的作用,一是准确提取NL中的查询语义(实现NL—中间语言);二是准确的实现数据库查询(实现中间语言—SQL)。
GEO数据集是一个美国地理的小型英文数据库,其训练语料包括一些自然语言及其相对应的查询语句。其数据集中主要包括各州信息、人口密度、地区主要城市、山川河流等信息。
与GEO数据集类似,我们的中间语言也包括一系列谓词,这些谓词表达了各种数据库查询的要求和操作,每个谓词可以转化为一个或一些SQL来实现查询,各个谓词之间的逻辑推理则由一个推理引擎来实现。
下面建立一个简单的应用场景,以此为背景讨论我们的技术。
2 应用场景
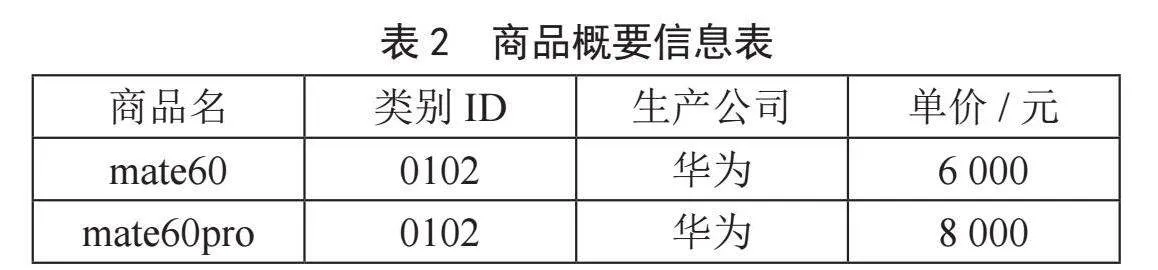
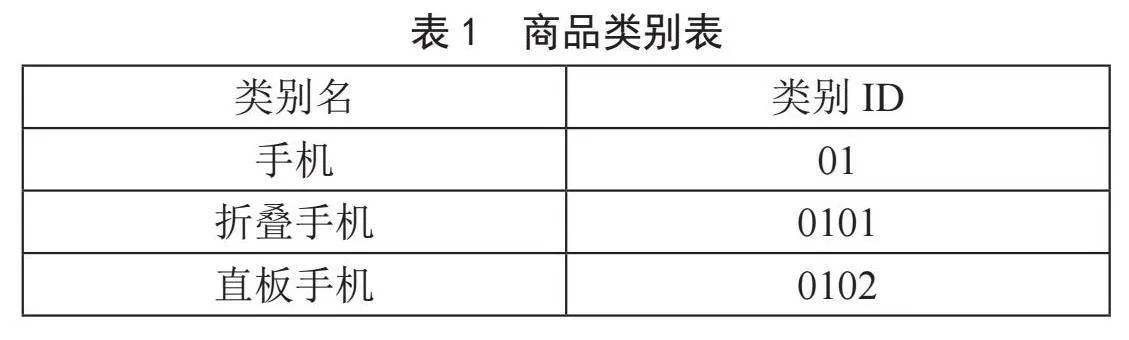
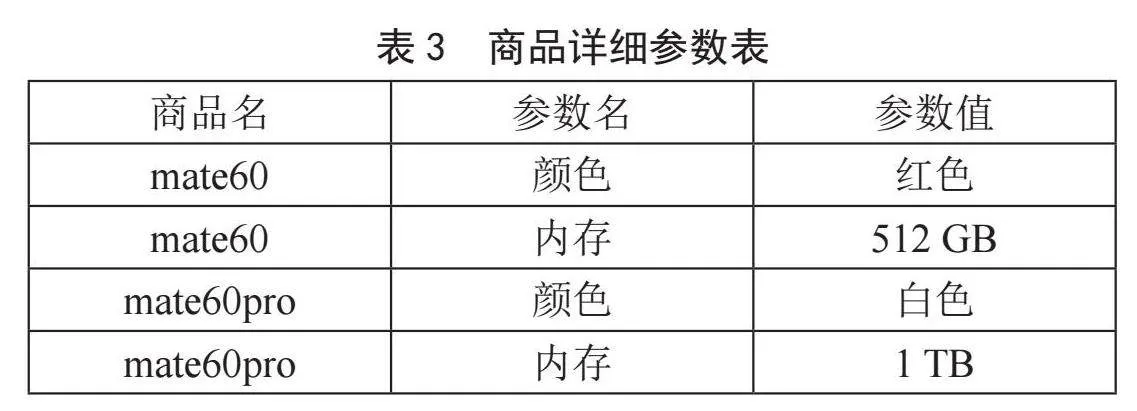
假设有一个简单的电商平台,所需的信息保存在数据库中,如图表1、表2、表3所示。以下为结构和相关样例数据介绍。
商品类别表中的“类别ID”字段的赋值规则可以表示父类和子类关系。例如“手机”的类别ID值“01”是“折叠手机”的ID值“0101”的前缀,说明“手机”是“折叠手机”的父类。利用这种方法可以灵活地将不同类商品分出不同层级,具有很好的通用性。
商品详细参数表的设计方法,使得不同类的商品可以定义不同的参数,极大地增加了系统的灵活性。
下面以此应用场景为例来详细说明我们的方案。
3 自然语言查询接口实现方案
3.1 中间语言的谓词设计
针对此电商平台的查询需要,我们为中间语言设计了谓词。
3.1.1 变量类型定义谓词
_answer(A,()):表示语句的查询最终结果要保留在A变量中。
_goods(A):声明变量A用来保存商品概要信息。
_info(A): 声明变量A用来保存商品详细信息。
3.1.2 信息提取谓词
_getgoods(A,B):在商品概要信息表中,以A变量的值为“商品名”字段的查询条件,查询相关商品概要信息保存到变量B。
_getinfo(A,B):在商品详细信息表中,以A变量的值为“商品名”字段的查询条件,查询相关商品详细信息保存到变量B。
_belongto(A,B):在商品概要信息表中,以A变量的值为“公司”字段的查询条件,找到相关的商品名保存在B变量中。
_property(A,B,C):从商品详细信息表中,获取属性名为A、属性值为B对应的商品名,保存在C变量中。
3.1.3 常量类型定义谓词
_typename(A):在商品类别表和商品概要信息表中,以A常量的值为“类别名”字段的查询条件,查询相关的“商品名”。
_goodsname(A):声明常量A是一个商品名。
_companyname(A):在商品概要信息表中,以A常量的值为“公司名”字段的查询条件,查询相关的“商品名”。
_price(A):声明常量A是一个价格。
3.1.4 变量从常量赋值谓词
_const(A,XXX)谓词表示将常量XXX(或常量集合)赋值给变量A。
3.1.5 数值比较谓词
_BT(B,A):查询A变量中的数值大于B的对象,结果保存在A变量中。
_LT(B,A):查询A变量中的数值小于B的对象,结果保存在A变量中。
3.2 自然语言转中间语言的实现
我校的研究团队在文献[11]中给出了一种利用对偶学习完成数据库查询的方案。采用对偶学习不仅可有效解决NL2SQL领域中需要大量标注训练集问题,还能增强模型质量及数据利用效率,提高模型的准确度。这种方案对GEO数据集可以达到90%的正确率。我们设计的中间语言比GEO数据集还要简洁,可以达到98%以上的正确率,完全可以满足实际应用的需要。
3.3 从中间语言推理查询结果
基于上述谓词,可以表示常见的商品查询要求。例如,对于“查询折叠手机类商品的详细信息”这个要求,转换为下述的中间语言:
_answer(A,(_info(A),_getinfo(B,A),_const(B,_typename (折叠手机))))
对于此语句的推理过程如下:
1)执行_typename(折叠手机)谓词,查询出“折叠手机”类商品有哪些。
2)执行_const(B,_typename(折叠手机)),将上一部查询结果保存到变量B中。
3)执行_getinfo(B,A),以B变量保存的各个商品名作为查询条件,查询相关商品详细信息保存到变量A。
4)_answer(A,()),把A变量的结果作为最终结果返回。
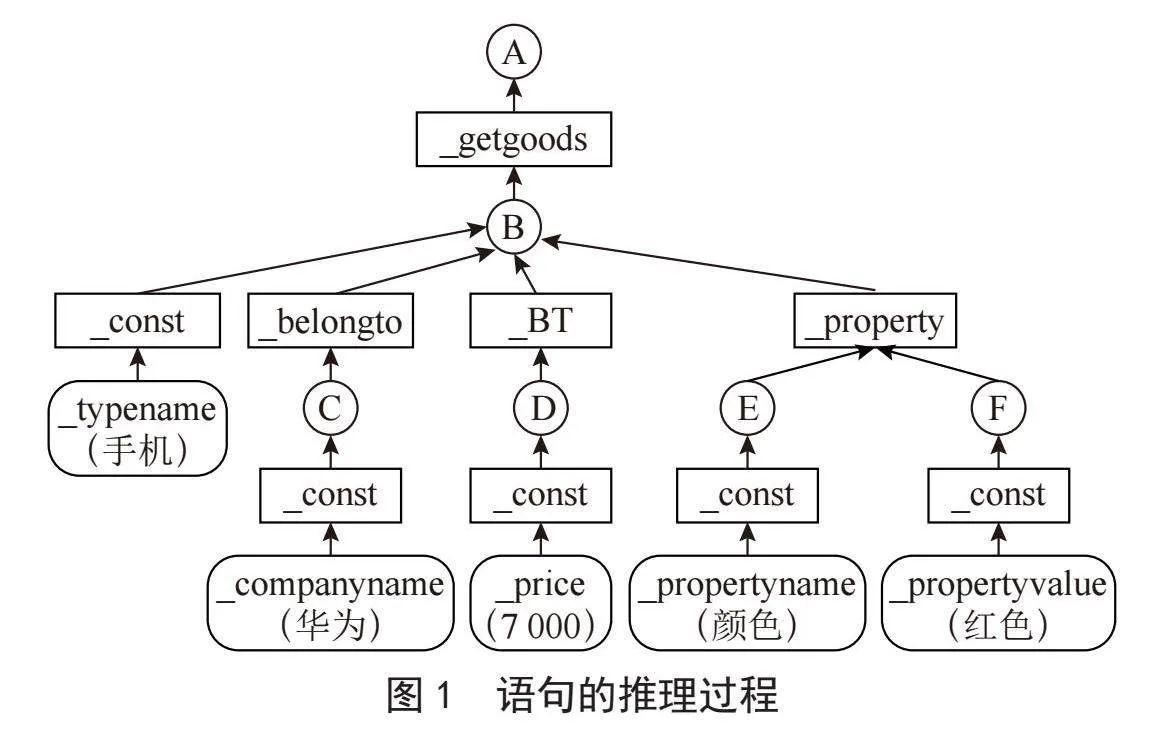
对于“查询华为公司的价格大于7 000的手机有哪些颜色是红色的”这个要求,转换为下述的中间语言:
_answer(A,(_goods(A),_getgoods(B,A),_const(B,_typename(手机),
_belongto(C,B),_const(C,_companyname(华为)),
_BT(D,B),_const(D,_price(7000)),_property(E,F,B),
_const(E,_propertyname(颜色)),
_const(F,_propertyvalue(红色)) ))
上述语句的推理过程比较复杂,可以用图1来表示。
此语句的推理过程被表示成树状结构,推理是从树的叶子开始,逐渐向上层运算。不同的谓词实现了不同的数据表查询和处理要求。
如果将这个查询要求直接转成一条SQL,那么会很复杂,因为这涉及三张数据表的多表连接。实际上这里有一个业务逻辑用一条SQL语句很难实现,就是我要查询的不是“手机”这个类别,而是这个类别下面所有的子类别。忽略这一点不计,其他的查询逻辑也是很复杂的,直接使用深度学习方法,不会有理想的识别效果。
但是,将这个查询要求转为中间语言去表达,则会简单很多。将“华为公司”转换为“_belongto(C,B),_const(C,_companyname(华为))”,将“价格大于7 000”
转换为“_BT(D,B),_const(D,_price(7000))”,将“颜色是红色的”转换为“_property(E,F,B),_const(E,_propertyname(颜色)),_const(F, _propertyvalue(红色))”,这样的转换对于当前的“机器翻译”技术来说是容易实现,可以达到理想的识别效果。而利用中间语言进行数据查询则能够保证100%的正确率。可以看出,“NL—中间语言—SQL”这个流程,可以在比较复杂的查询场景下,实现令人满意的正确率。
3.4 学习样本的自动生成
基于深度学习的数据库自然语言查询技术在实际应用中,有一个重要的障碍就是构建学习样本。深度学习需要大量的学习样本数据,如果手工创建或半自动创建,会耗费很多人力,极大地阻碍这种技术的推广和应用。我们必须要寻求自动生成学习样本的方法。
自动生成学习样本数据集最基本的方法就是基于模板和规则。例如设计如下模板:
查询{companyname}公司的价格大于{price}的{class}类商品有哪些。
_answer(A ,(_goods(A), _getgoods(B,A), _const (B,_typename({class}), _belongto(C,A),_const(C,_companyname({companyname})),_BT(D,A),_const(D,_price({price})) ))
只要从数据表中获取不同的{companyname}、{price}、{class}信息,分别填写到问题模板和中间语言模板中,即可自动生成一条学习样本。
这种方法虽然简单易行,但是缺点是生成的自然语言明显模板化,语句形式不够丰富,这样的样本在学习之后泛化能力较差。
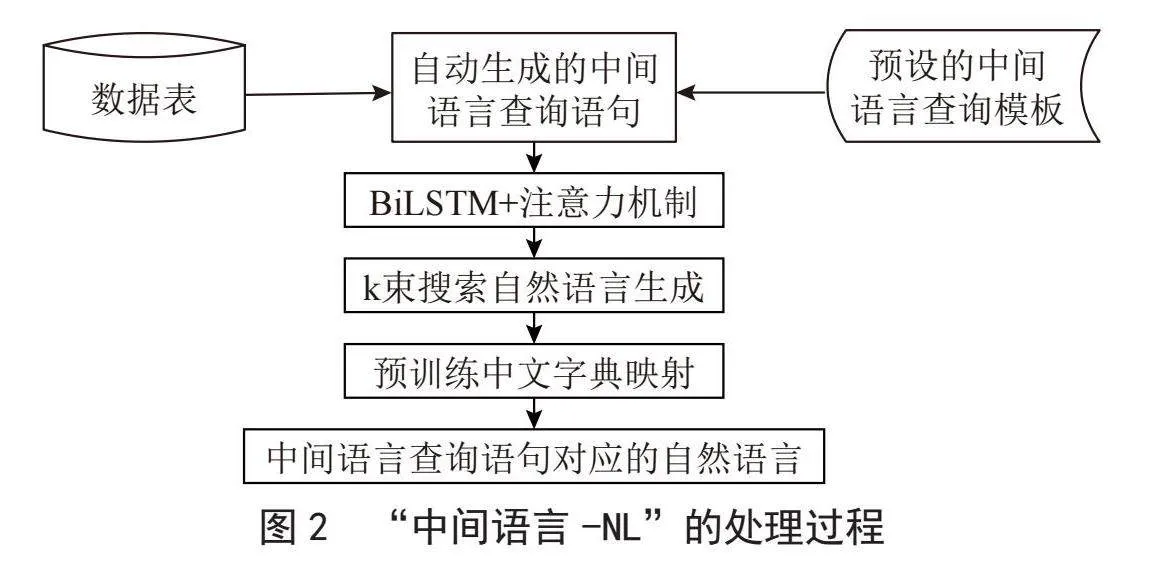
所以,本文在样本集的自动生成过程中,引入“中间语言—NL”的方法。“中间语言—NL”的处理与“NL—中间语言”的处理是一个反向的过程,其主要任务是输入中间语言语句,输出此中间语言语句对应的自然语言查询的问句。图2表示了“中间语言—NL”的处理过程。
在此过程中,先用预先设计好的模板结合数据表的信息,自动生成各种中间语言查询语句,然后经过中间语言—NL模型训练生成自然语言。输入一个中间语言查询语句,经过一个带有注意力机制的双向LSMT模型之后,可以获取k种可能的自然语言结果(k为束搜索的大小)。再通过预训练中文字典的转换,最后就形成自然语言查询问句。这样生成的自然语言查询问句,具有句式灵活多样的特点,避免了问句模板化的问题。有了“中间语言—NL”的帮助,很大程度上消除了部署到不同应用场景时面临的一个障碍,有利于提高模型的通用性。
4 实验结果
基于上述技术方案,我们完成了一个简单的电商平台,验证了相关技术的正确性。下面展示两个示例。
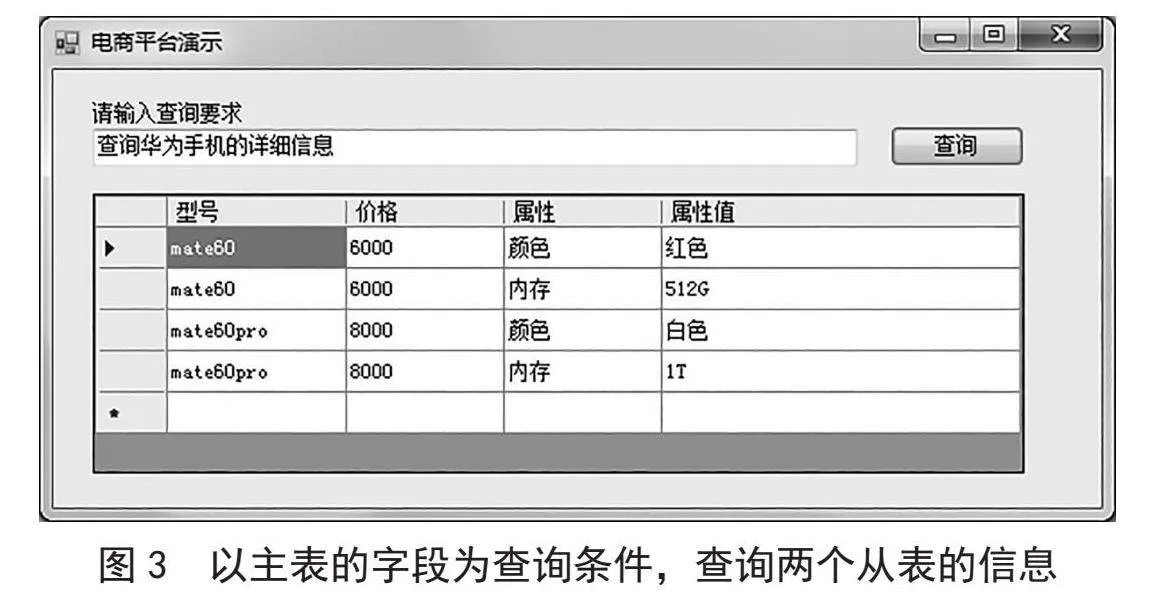
第一个示例是演示以主表的字段为查询条件,查询两个从表的信息,如图3所示。
第二个示例是演示三个表的字段都是查询条件这种复杂的查询场景,如图4所示。
我们的深度学习框架是用TensorFlow 2.0.0+Keras 2.3.1实现的,样本的批量大小为16,采用Adam作为优化器,训练过程中采用的学习率为1×10-5,采用Dropout正则化方法(比率为0.3)来预防过拟合。
我们为电商平台供设计了42个样本模板,在“中间语言—NL”模型的支持下,共生成了两批学习样本,第一批1 272个、第二批3 386个。我们对这两批样本分别进行了训练,测试集和验证集都按9:1进行分配。第一批的127个验证样本,有2个出错,准确率达到了98.4%;第二批的338个验证样本,有5个出错,准确率达到了98.5%,已经可以满足实际应用的需要。我们对出错的7个样本进行了分析,其中有6个是由于“中间语言—NL”模型生成的查询问句不合理造成的。从此实验可以看出,第一,通过进一步提高样本数的方法难以获得更高的准确率,第二,“中间语言—NL”模型的准确率成为系统进一步提高准确率的瓶颈。
5 结 论
本文提出的数据库自然语言查询实现方案具有如下优点:
1)中间语言与NL的语义差距小,进行机器翻译的难度小很多,正确率很高。
2)中间语言由多个谓词组成,每个谓词可以单独对应到一个查询,并通过简单的推理计算最终的结果,实现难度低。
但是此方法也有如下缺点:
1)只能针对特定场合设计专用的中间语言谓词,缺少通用性。
2)利用中间语言进行查询的处理过程,实际上是将一个查询要求分解成多个子查询,最后通过推理计算出最终的结果,所以处理速度比单一SQL语句实现查询要慢。
我们未来的研究方向:
1)将中间语言转换为单一SQL语句,这样可以极大地提高查询速度,实现“NL—中间语言—SQL”这个完美的流程。
2)研究“通用化”的、能够自动适应数据库表结构和多表连接关系的谓词,以便在更换应用场景时,可以减少谓词定义的工作量、提高通用性。
参考文献:
[1] XU X J,LIU C,SONG D. SQLNet: Generating Structured Queries From Natural Language Without Reinforcement Learning [J/OL].arXiv:1711.04436 [cs.CL].[2024-01-08].https://arxiv.org/abs/1711.04436.
[2] YU T,LI Z F,ZHANG Z L,et al. TypeSQL: Knowledge-Based Type-Aware Neural Text-to-SQL Generation [L/OL].arXiv:1804.09769 [cs.CL].[2024-01-09].https://arxiv.org/abs/1804.09769.
[3] HWANG W,YIM J,PARK S,et al. A Comprehensive Exploration on WikiSQL with Table-Aware Word Contextualization [J/OL].arXiv:1902.01069[cs.CL].[2024-01-09].https://arxiv.org/abs/1902.01069v2.
[4] HE P C,MAO Y,CHAKRABARTI K,et al. X-SQL: Reinforce Schema Representation with Context [J/OL].arXiv:1908.08113 [cs.CL].[2024-01-09].https://arxiv.org/abs/1908.08113.
[5] ZHANG X Y,YIN F J,MA G J,et al. M-SQL: Multi-task representation learning for single-table Text2SQL generation [J].IEEE Access,2020,8:43156-43167.
[6] 张啸宇.基于有监督深度学习的SQL解析关键技术研究 [D].长沙:国防科技大学,2020.
[7] 欧杨磊.基于BERT的中文NL2SQL任务的技术研究 [D].杭州:杭州电子科技大学,2021.
[8] WANG L J,ZHANG A,WU K,et al. DuSQL: A Large-Scale and Pragmatic Chinese Text-to-SQL Dataset [C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing.EMNLP:Association for Computational Linguistics ,2020,6923-6935.
[9] 潘璇,徐思涵,蔡祥睿,等.基于深度学习的数据库自然语言接口综述 [J].计算机研究与发展,2021,58(9):1925-1950.
[10] Welcome to Getquery!: A Learned Natural Language Interface to a US Geography Database [EB/OL].[2024-01-09].https://www.cs.utexas.edu/users/ml/geo.html.
[11] 赵志超,游进国,何培蕾,等.数据库中文查询对偶学习式生成SQL语句研究 [J].中文信息学报,2023,37(3):164-172.
作者简介:富庭轩(2003—),男,满族,辽宁辽阳人,本科在读,研究方向:自然语言处理和时间序列预测。