






摘 要:随着互联网技术的发展,传统的只根据榜单数据进行电影筛选的方式已经不能满足消费者的需求。基于Python实现了豆瓣网站TOP250电影数据爬虫,调用Requests下载网页并使用Beautifulsoup进行网页解析,利用PyeCharts等技术进行数据可视化分析,将数据以图表的形式展现,以让消费者更清晰地看到热门电影数据特征,为消费者选择电影提供参考依据。通过可视化分析发现,电影的评分与评论人数无正相关性。
关键词:Python;爬虫;豆瓣;数据可视化
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2024)16-0093-05
Research on Douban TOP250 Movie Data Analysis and Visualization Based on Python Crawler
Abstract: With the development of internet technology, the traditional method of screening movies based solely on ranking data can no longer meet the needs of consumers. The Douban website TOP250 movie data crawler is implemented based on Python, calling Requests to download Web pages, realizing Web page parsing through Beautifulsoup, and using technologies such as PyeCharts for data visualization analysis. It presents the data in the form of charts to enable consumers to see the characteristics of popular movie data more clearly, providing reference for consumers to choose movies. The visualization analysis has found that there is no positive correlation between movie ratings and number of reviews.
Keywords: Python; Web crawler; Douban; data visualization
0 引 言
Python被广泛应用于网络爬虫、人工智能、数据分析和可视化领域。当前有3种主流的Python爬虫技术:Requests、Scrapy和Selenium,5大Python可视化库:Matplotlib、Seaborn、Bokeh、Plotly、PyeCharts。近年来,基于Python的爬虫技术得到广泛研究和应用,如白金川等对Python网络爬虫在医学影像领域的发展qKroK7ejLWjbsexbTLWVVSJJSr228/jRoXnv4LXeDEQ=现状与趋势进行了研究[1],蔡文乐等基于Python爬虫对招聘数据进行了可视化分析[2],鲍培东进行了基于Python的新能源汽车数据爬取与数据可视化分析研究等[3]。
随着互联网的普及,多元电影榜单文化生态正在形成,豆瓣网站TOP250电影榜单比较有代表性。关于豆瓣TOP250电影榜单的相关研究已有不少,包括TOP250电影的国家、评分、时长的分析[4-5],豆瓣电影评论文本的情感分析及主题提取研究[6]以及爬虫技术对比[7]等。上述研究均使用Python实现,但均没有对电影数据特征进行深入挖掘和可视化分析。
针对以上问题,本文拟使用Requests进行豆瓣TOP250电影榜单数据爬取,使用Beautifulsoup进行网页解析,利用Pandas进行数据清洗,借助PyeCharts等工具进行可视化分析,挖掘豆瓣热门电影数据特征,包括这些电影的上映时间、制片国家、导演、编剧、演员、评分、以及电影评分与电影评论人数的关系等,以期展示热门电影数据全貌特征,为消费者选电影、看电影、评电影提供更阔的视角和参考依据。
1 相关技术
1.1 网络爬虫
网络爬虫是一种按照一定规则自动浏览或抓取万维网数据的程序[8],也称为自动索引程序。网络爬虫工作的原理是发现新页面后,为它们建立索引,并进行存储。爬虫到的数据要经过解析、清洗,才可以进行数据可视化分析。
1.2 数据可视化
数据可视化是使用图表、图形、地图等可视化元素来呈现数据,以达到更清晰、有效地将自己的见解传达给他人的目的[9-10]。该过程涉及大量复杂的数据转化,数据可视化也可以使用可视化表示从原始数据中提取可行的见解,以便于决策者确定数据之间的关系并发现隐藏的模式或趋势,促进智能决策。
1.3 几种Python库
下面对本次实验过程中主要用到的Python库Requests、Beautifulsoup、PyEcharts、Matplotlib、Seaborn进行一个简单的介绍:
1)Requests库。Requests是Python实现的一个简单易用的http访问库,用于访问网络资源并获取响应结果。Requests使用简单方便,导入模块后就可以向目标URL发送HTTP请求。
2)Beautifulsoup库。Beautiful Soup是一个可以从html或xml文件中提取数据的Python库,Beautiful Soup可以将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,调用相关方法即可完成数据解析。
3)PyEcharts库。PyEcharts是可以生成Echarts图表的Python库,它提供了简单易用的接口用于生成各类Echarts图表,包括折线图、柱状图、散点图等,生成的图像可以保存到本地,也可以生成html文件。
4)Matplotlib库。Matplotlib是Python的绘图库,用于将数据进行图形化展示,包括散点图、直方图等。
5)Seaborn库。Seaborn是基于Matplotlib的可视化库,属于Matplotlib的一个高级接口,它更便于用户进行可视化分析。
2 技术实现
2.1 数据来源
本次实验主要爬取豆瓣TOP250电影榜单的数据,豆瓣对应的网址是:https://movie.douban.com/TOP250。最终共爬虫到250条数据,利用Pandas进行数据清洗,最后保留并进行分析的字段有:电影名称、电影上映时间、上映地区、导演、编剧、主演、评分、评论人数、评分人数。
2.2 爬虫过程
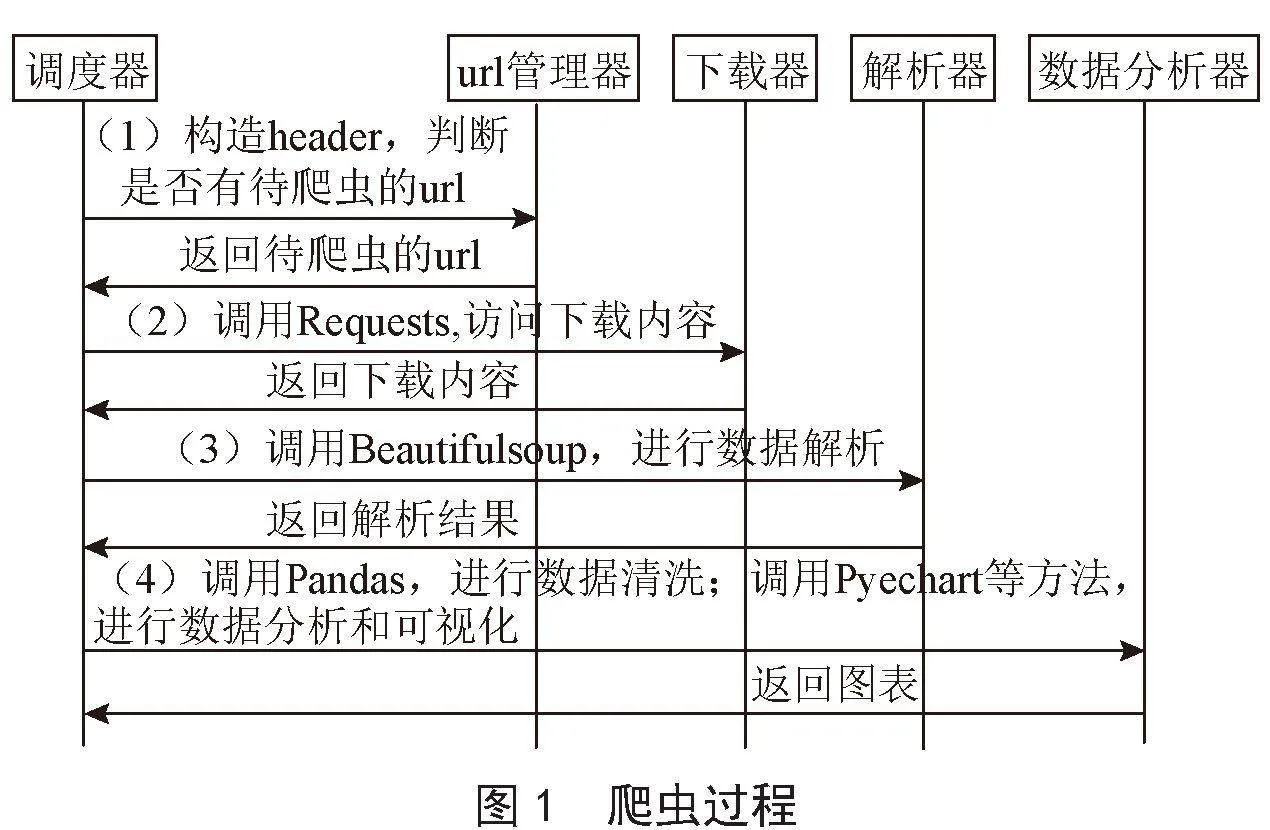
本次实验爬虫和数据分析均使用Python语言完成。爬虫共分为5步进行,如图1所示,主要通过调度器、URL管理器、下载器、解析器、数据分析器5个模块之间的配合完成,爬虫结果如图2所示。
下面对爬虫各个步骤进行详细介绍。
2.2.1 调度工作
调度器主要负责各个模块的协调工作,调度工作主要是由调度器完成。调度器会去访问url管理器,判断url管理器中是否有待访问的url,如果有就向下载器发起下载请求。
2.2.2 爬虫操作
如果下载器接收到了下载请求,就会调用Requests访问目标url下载网页并将结果保存,否则处于等待状态。
2.2.3 网页解析
调度器拿到爬虫结果后就会向解析器发起请求。解析器接收到请求后通过调用Beautifulsoup对下载的网页进行解析,获取目标字段的值将其进行存储并将结果进行返回。
2.2.4 数据清洗
调度器拿到网页解析器返回的数据后就会调用数据分析器进行数据分析。数据分析器分两步进行处理,先进行数据清洗后进行数据分析。数据清洗是使用Pandas方法对空值、异常数据进行清洗。
2.2.5 数据分析
数据分析器清洗完数据后,就会做数据分析的工作,这里主要是使用PyEcharts、Seaborn的方法进行数据分析和可视化,选择最合适的图表以最优的效果进行数据展示。部分可视化代码如下:
2.3 可视化分析结果
对爬取到250条电影数据进行可视化分析,结果如下:
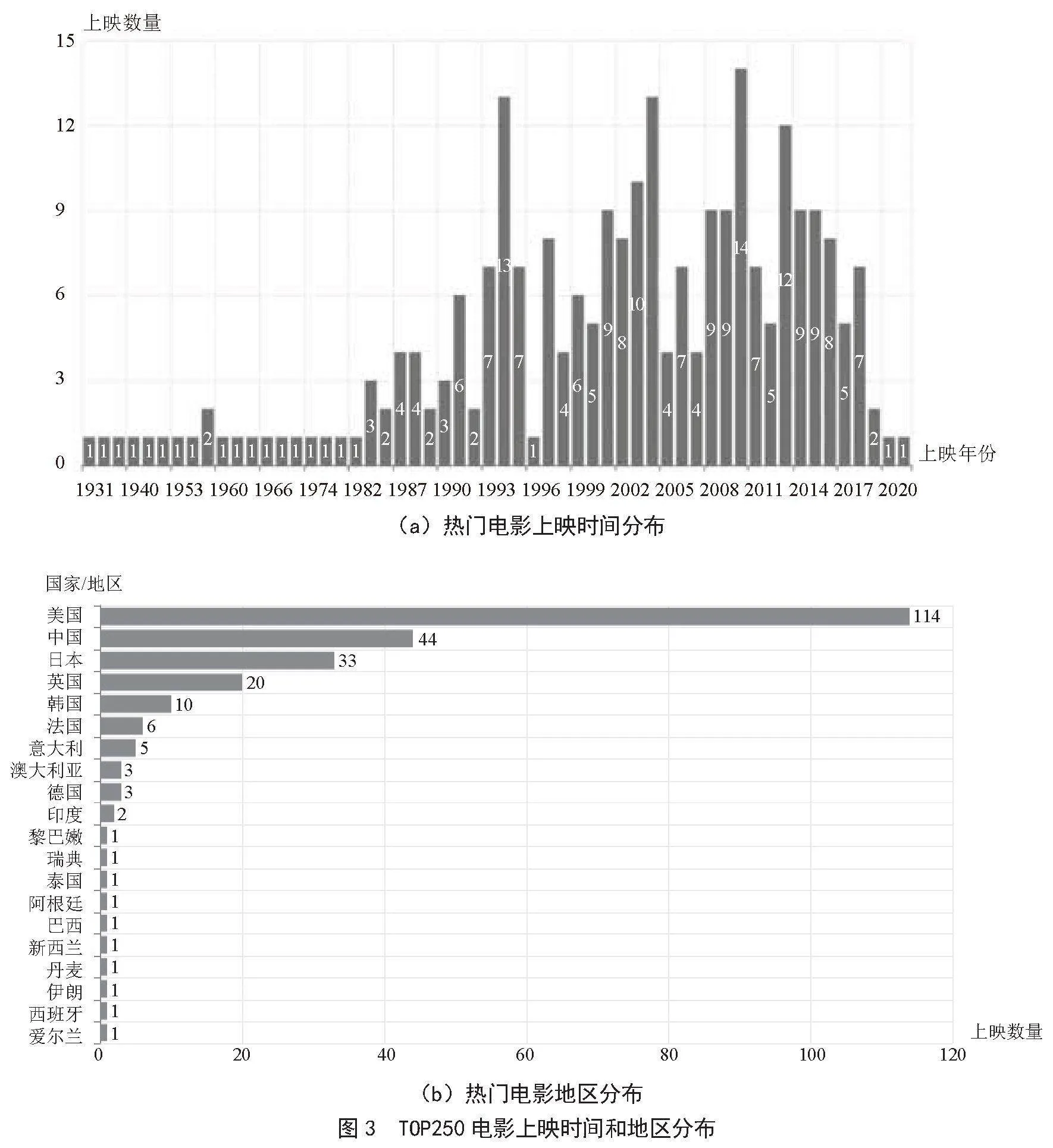
1)TOP250电影上映时间和地区分布如图3所示。由图可知,热门电影数量分布存在大小年情况,2010、2004、1994年上映的热门电影数较多,这些电影主要分布在美国、中国、日本。最高产的3位导演分别是宫崎骏、克里斯托弗·诺兰、史蒂文·斯皮尔伯格,导演词云图如图4所示,最高产的3位编剧是宫崎骏、J.K.罗琳、史蒂芬·斯皮尔伯格,最高产的3位演员是梁朝伟、张国荣、艾伦·瑞克曼。
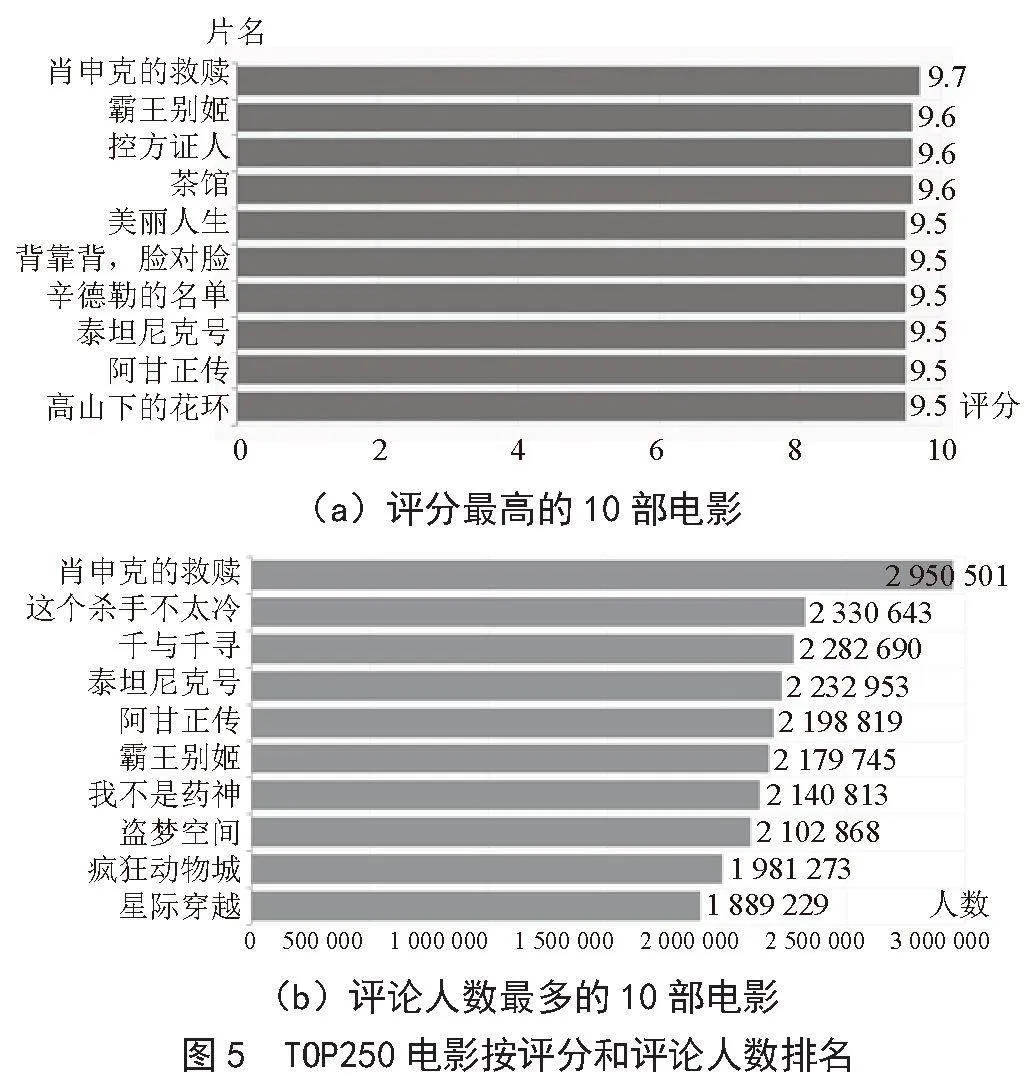
2)TOP250电影的评分分布和评论人数分布结果如图5所示。TOP250电影最低评分为8.4,最高评分为9.7,平均值为8.94。评分最高的电影为《肖申克的救赎》,该电影也是评论人数最多的电影,评论人数为2 950 501。分析发现,评分与评论人数不成正比。
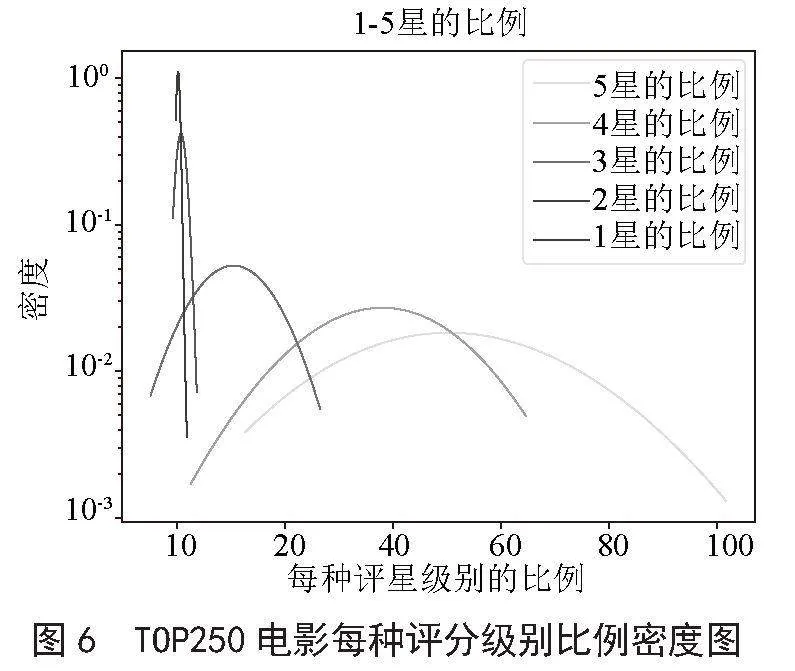
3)豆瓣将电影评分分为1星到5星5个级别,TOP250电影的评分等级比例分布结果如图6所示。由图可知,5星评分比例最高,4星评分比例次之,1星、2星评分比例占比较少。分析发现,评分人数和评论人数呈正比。
3 结 论
本文通过爬虫技术获取了豆瓣TOP250电影数据,使用Requests和Beautifulsoup进行网络爬虫和数据解析,利用Pandas进行数据清洗,调用TOP对数据进行可视化分析。可视化分析结果包括热门电影年份分布、制片国分布、导演、编剧、演员分布,以及评分情况和评论人数情况等内容。该结果清晰地展示了热门电影数据特征,帮助消费者更好、更有效的选电影。该数据后续也可以进一步进行文本挖掘、机器学习分析。
参考文献:
[1] 白金川,王豪,焦宝园.Python网络爬虫在医学影像领域的发展现状与趋势研究 [J].生物医学工程学进展,2023(3):260-266.
[2] 蔡文乐,秦立静.基于Python爬虫的招聘数据可视化分析 [J].物联网技术,2024,14(1):102-105.
[3] 鲍培东,宛楠,王婷婷,等.基于Python的新能源汽车数据爬取与数据可视化分析研究 [J].轻工科技,2023,39(5):105-107.
[4] 郝燕如.面向用户评论的细粒度情感分析与可视化系统研究与实现 [D].北京:北京邮电大学,2023.
[5] 王国华.基于Python的豆瓣电影网络爬虫设计与分析 [C]//第三十六届中国(天津)2022IT、网络、信息技术、电子、仪器仪表创新学术会议论文集.天津:[出版者不详],2022:212-215.
[6] 余洋.豆瓣电影评论文本的情感分析及主题提取研究 [D].昆明:云南财经大学,2018.
[7] 张璐璐,吴丽杰,孙俊杰,等.基于网络数据自动提取的爬虫设计与实现 [J].广州航海学院学报,2022,30(4):74-78.
[8] 黄永祥.实战Python网络爬虫 [M].北京:清华大学出版社,2019.
[9] 任永功,于戈.数据可视化技术的研究与进展 [J].计算机科学,2004(12):92-96.
[10] 刘勘,周晓峥,周洞汝.数据可视化的研究与发展 [J].计算机工程,2002(8):1-2+63.