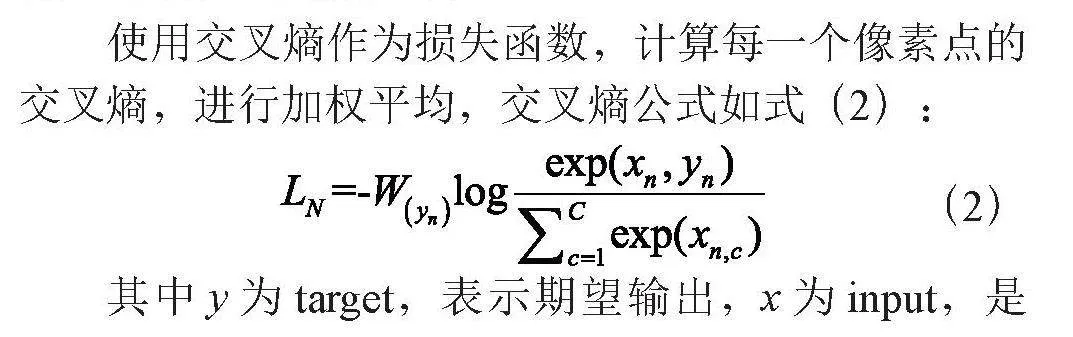



摘 要:针对传统交通灯通行时间不灵活,通过对采集交通灯下的车流量信息进行了研究,设计了一种基于深度学习的智能交通灯。首先通过FCN提取车道线,使用聚类算法拟合车道线函数;其次使用以VGG网络作为模型的主干特征提取SSD网络模型,检测车辆的位置信息,将车辆的位置信息与车道线位置信息综合起来,统计当前交通灯下的每个车道上的车流量信息,实验结果表明,基于深度学习的智能交通灯系统实际的应用过程中,车流量统计的精确度为90.69%,基本实现在现实环境的应用。
关键词:车辆检测;SSD;FCN;智能交通
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2024)17-0179-06
0 引 言
随着社会和国民经济持续快速发展,人们的生活质量不断提高,全国汽车总量大幅度提高,至2022年11月底,全国汽车保有量已经达到3.18亿辆,汽车驾驶人增加至4.63亿人,全国汽车总量年均增量大约为2 000万辆,但长期以来,我国城市人均道路面积一直处于低水平状态,道路用地占城市用地的比重小,路网密度低,路网容量供给严重不足,随即产生的交通问题也越来越多,给交通管理人员带来了很大的负担。因此设计一款智能交通灯,精确检测各个车道上的车辆数据,更精细的使用交通资源,成为一项迫切的需求。
传统的交通灯是采取固定的通行时间,无法根据车流量的实时情况调整红绿灯的通行时间,在车流量大的时间段,没有足够的通行时间,车流量小的时间段,通行时间过剩,对交通资源的利用率不高,容易导致交通问题的发生。对交通灯下的车辆进行精确的检测,预测车辆的行驶方向,并根据这些实时信息动态调节红绿灯的通行时间,是智能交通系统中主要的功能之一。
智能交通灯通常是基于单片机传感器[1]或基于图像处理[2-3]的方式实现。基于单片机传感器的方式通常使用一个车流量计数器获取车流量,构造一个延时时间计算函数,通过车流量、车速、车流密度等参数进行计算延时时间。这种方法构造简单,成本低,可以在单片机上运行,但是缺陷也非常明显,首先无法精确统计车流量信息,不能准确获取车辆的位置信息,实际部署难度大、误差大、精度小。
基于图像处理的车流量检测最早使用的检测方法是从视频中提取有意义的代表性的图像特征,例如通过轮廓、图像直方图、差分等方法获取车辆特征[4]。窦菲等通过OpenCV实现的道路分析系统[5],通过帧差法取出视频中的背景,使用背景与后续的视频作差分,可以得到视频中运动的物体,再通过Mean Shift算法[6]跟踪视频中的车辆。传统的图像处理算法虽然在一定程度上解决了车辆检测问题,但是传统的车辆检测方法受限于人工设计的特征优劣,人工设计的特征往往依赖设计时的具体环境,当外界环境变化大时,无法提供一个准确的结果。并且小目标检测效果不佳,受环境影响较大,低泛化,很难在日常的复杂环境下应用。
随着近年来深度学习的发展,越来越多研究者将深度学习应用在目标检测任务中来,不再需要设计者对具体环境设计人工特征,机器学习到的特征可以在更多场合下使用,在国内外,使用深度学习进行目标检测任务[7-8]已经成为一种趋势,也有很多研究者将深度学习引入到车辆检测和车道线识别任务中来,获得了许多优秀的成果。
邓天民等人实现了一个基于FCN的车道线检测方法[9],首先通过FCN进行语义分割,得到车道线的二值图,其次通过DBSCAN算法聚类对每一条车道线进行区分,使用逆透视变换将弯曲的车道线转换俯视图下的直线,再拟合出车道线转换回原有平面,上述两种算法的叠加形成一个端对端系统提高了车道线的检测能力,这个算法虽然可以有效拟合弯曲的车道线,但是由于其结构较为复杂,需要计算和拟合的参数较多,检测的速度较慢,且对于机器拟合的错误结果,比较难以矫正和更改,这个方法更适合在自动驾驶中使用。
秦晓晖实现了一个基于计算机视觉的智能交通灯系统[10],通过SSD网络进行目标检测网络实现的车辆检测,通过一个延时计算模块计算交通灯的通行时间,通过网络通信模块传输交通灯的时间数据,实现动态调节通行时间,但是缺少车道线信息,不能对车辆进行更详细的分类,延时计算不够准确。
目前交通灯下的车流量统计还没有一个较为完善的方案,本文设计了一种基于深度学习的智能交通灯,通过摄像机拍摄到的图像,首先通过FCN提取车道线,对车道线进行聚类,拟合获取车道线信息,通过对ROI(Region Of Interest)区域进行车辆检测,获取车辆信息,综合车道线和车辆信息统计当前图片中的每一个车道上的车流量。
1 总体设计方案
1.1 智能交通灯的设计框架
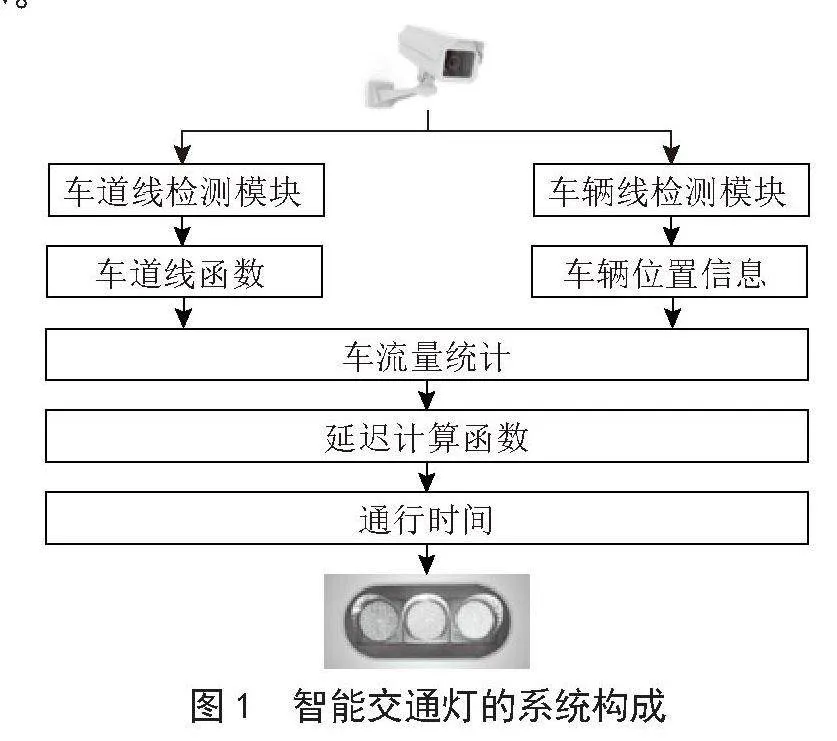
智能交通灯主要由5个模块组成,包括数据采集模块、车道线检测模块、车辆检测模块、信息传输模块和延时计算模块,首先数据采集模块会取得交通灯下的图像信息,通过车道线检测模块获取车道线信息,同时选择ROI区域进行车辆检测获取车辆信息,综合车道线和车辆信息统计实时的当前车道的车辆数量,通过延时计算模块计算交通灯的通行时间参数,通过信息传输模块与交通灯进行交互,按照计算的参数设置通行时间,智能交通灯的系统构成如图1所示。
1.2 数据采集模块
数据采集模块主要功能是获取当前交通灯下的图像信息,并对图像进行预处理,更好地进行后续检测工作,本文使用IP摄像头作为数据采集模块,对采集到的图片进行自适应图像填充和裁剪等操作,输入到下一个模块。自适应图像填充是一个图像缩放和裁剪,会根据采集到图片的大小计算缩放比例参数,最后将采集到的图片缩放至合适的模型输入大小。
1.3 车道线检测模块
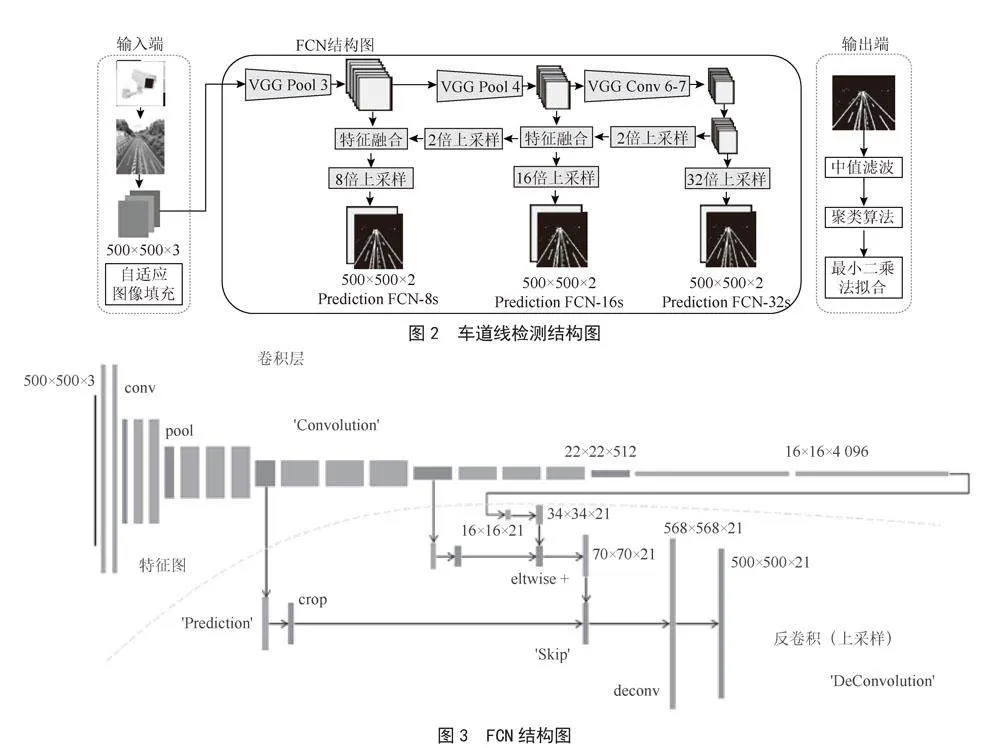
车道线检测的方法是通过语义分割网络[11]与聚类算法结合,进行实例分割,将车道线从图片中分离出来,对每一条车道线进行拟合得到车道线函数。本文使用FCN网络做语义分割任务,FCN网络结构简单,速度快,通过VGG16网络进行特征提取,对提取的特征进行反卷积放大,得到车道线的二值图结果,车道线检测结构如图2所示。
1.4 FCN基本原理
FCN的结构由3部分组成:如卷积、反卷积和跳跃结构,FCN网络结构[12]如图3所示。
FCN网络使用VGG16的主干网络,使用卷积层代替VGG16的全连接层,取出VGG16 conv6-7的特征图,由于经过5次池化,特征图与原图相差32倍,所以需要做一次32倍上采样,即可得到与原图大小一致的语义分割图FCN-32s,将VGG16 conv6-7特征图与第四次池化的特征图融合,进行16倍上采样,由于同时包含多个层次的特征信息,我们可以获得比FCN-32s更精细的FCN-16s语义分割图,融合后的特征图与第三次池化的特征图再次融合进行8倍上采样取得更精细的语义分割图FCN-8s,FCN通过将一步到位的上采样拆分成多步上采样的方式,取得比直接上采样更好的效果。
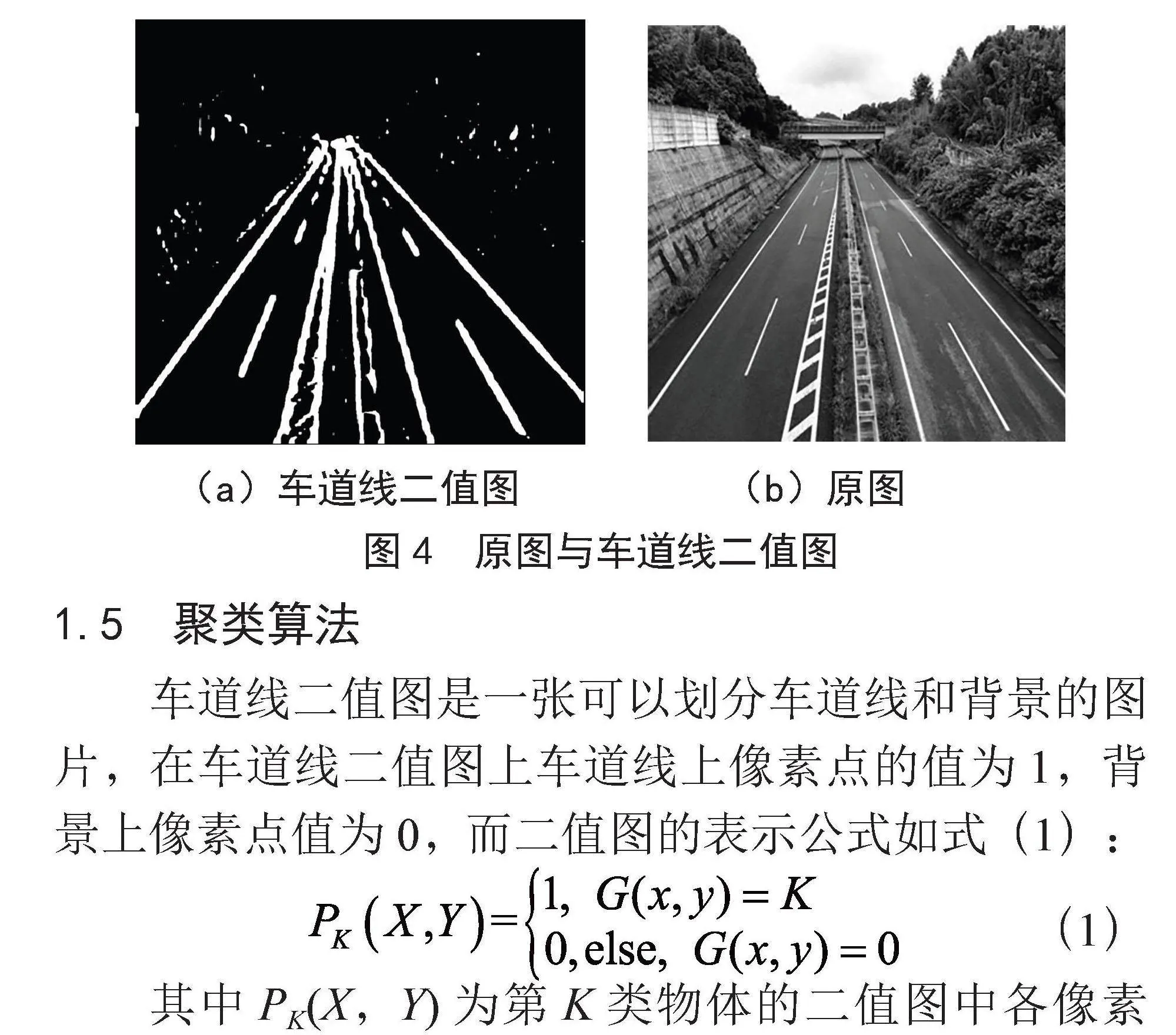
本文首先通过FCN进行语义分割,得到车道线的二值图,对二值图进行聚类,将每一个车道线实例化,使用最小二乘法进行拟合出车道线函数,通常情况下,交通灯下的车道线可以视为直线,可以直接使用多项式拟合,如果对弯曲车道拟合结果有需求,可以加入一个逆透视变换矩阵的过程,对弯曲车道的拟合,一般不使用没有限制条件的多项式,因为如果没有限制函数的定义域,在没有数据定义的部分,拟合的函数可能会出现偏差,本文建议可以使用三阶贝塞尔函数拟合。在训练过程中,由于车道线相对于背景的像素比例较小,需要给予车道线较大的权重才能得到更好的训练结果,从图片中提取车道线,原图和车道线二值图对比如图4所示。
(a)车道线二值图 (b)原图
1.5 聚类算法
车道线二值图是一张可以划分车道线和背景的图片,在车道线二值图上车道线上像素点的值为1,背景上像素点值为0,而二值图的表示公式如式(1):
(1)
其中PK(X,Y)为第K类物体的二值图中各像素点像素值,G(x,y)为原图中各个像素点的物体类别,对于第K类二值图,只有原图中像素点属于K类物体才有值,否则值为0。
使用交叉熵作为损失函数,计算每一个像素点的交叉熵,进行加权平均,交叉熵公式如式(2):
(2)
其中y为target,表示期望输出,x为input,是实际输出,C为类别数量,N为维度数,W为每一个类的权重,通过公式可以判断实际输出与期望输出的相似度,对每一个像素点求取交叉熵后,可以得到预测二值图与期望输出的损失。由于车道线相对背景的像素点较少,在计算损失函数过程中,一般设置车道线比背景的权重更大,本文车道线和背景的权重比为50:1。
取得车道线二值图后,首先需要对图片进行预处理,对车道线二值图进行一次中值滤波,滤除二值图中的噪点后,只保留图片的下半部分,开始使用聚类算法进行聚类,具体步骤如下:
1)从图片中的某高度选取所有数值的坐标,放入集合A1中,从图片中去除这些点。
2)在A1中选取任意一个点,把这个点加入集合A3中,并在A1中删除这个点,选取与该点距离小于10的所有点,将这些点放入A3,并从图片中去除这些点。
3)寻找所有在A3内的点距离小与10的点,将这些点加入集合A3,并在图片中删除这些点
重复2),直至没有与A1点集相邻,A3则表示某一条车道线的全部点集。
不断重复,直至图片上所有点都聚类完成,删除点数量较少的点集,保留下来的即是图片中的车道线的点集,通过最小二乘法进行拟合,得到车道线函数。本文为了删除和修改拟合和检测错误的车道线,使用参数最少的一次函数进行拟合,只需确定两个参数即可,唯一确定一条车道线函数,当检测的车道线错误时,最多修改两个参数,即可对检测结果进行修改。
1.6 车辆检测模块
对于车辆检测,首先要确定ROI区域,使用方框确定一个ROI区域,使用鼠标确定方框的两个对角的坐标参数,精细的划分车道上的检测区域,对这些区域进行目标检测,计算车辆的位置属于哪个类型的车道。
1.7 目标检测
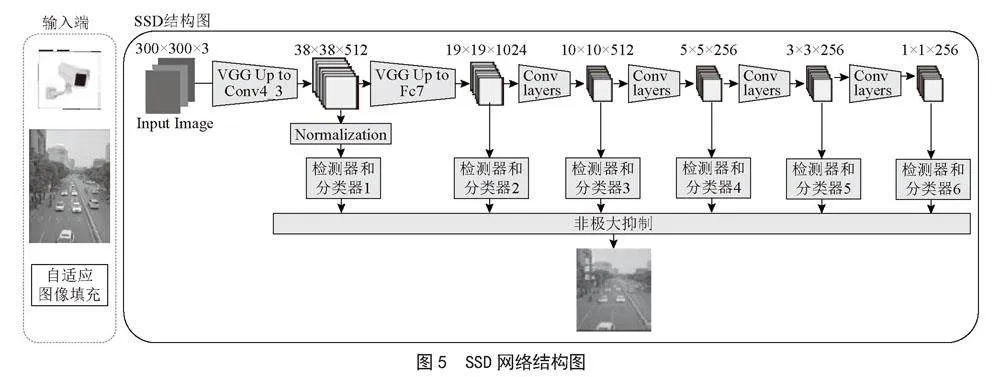
本文使用SSD(Single Shot MultiBox Detector)网络[13]作为目标检测网络,SSD网络是一种多尺度的检测方式,通过使用大尺度的先验框和检测器检测大尺度的目标,小尺度的先验框和检测器检测大尺度的目标,SSD网络有6个不同的尺度分类器,这样可以防止小目标在深层特征消失的问题,可以检测不同尺度大小的物体,在远处像素比较小的车辆也有较高的准确率,也使整个模型拥有较高的可靠性,SSD网络结构如图5所示。
SSD网络的特征提取网络使用VGG16的前4层卷积,后续补充4层额外卷积层,提取出的第一个特征图由于特征太浅,需要经过一个归一化模块,按不同的特征图尺度分配不同大小的先验框,先验框是一个不同尺寸的方框集合,当确定方框的尺寸和坐标后,还需要对计算方框的微调参数,对先验框进行微调,得到目标的包围框,使用非极大抑制,设置IoU的参数将所有尺度的包围框综合分析,得到最合适的包围框结果,IoU是表示两个框之间的重合程度的参数,通过重合面积除以总面积求得。
1.8 非极大抑制
非极大抑制(Non-Maximum Suppression, NMS)是判断临近框是否属于同一个目标的算法,SSD网络会总共产生8 732个先验框,可想而知很多先验框是无用的,需要对检测的结果进行筛选:
1)对于某个类别,将分类预测的置信度小于置信度阈值的框删除。
2)将筛选后的框按照置信度降序排序。
3)对处理后的框进行NMS: 首先计算置信度最高的框与其他所有框的IoU,IoU 大于IoU 阈值则删除;其次找到经过第一步处理后另一个置信度最高的框, 重复第一步,直到所有框遍历完成;最后对除背景以外的所有类别执行筛选操作。
IoU是指方框之间的重叠面积,当两个方框之间的重叠面积超过一个阈值时,可以认为这两个包围框所包围的是同一个目标物体,只需保留置信度最高的一个包围框即可。
1.9 SSD的损失函数分为置信损失和定位损失
在目标检测前,首先确定ROI区域,将车道线进行细致的划分,减少误差的出现,通过鼠标确定ROI区域的检测范围后,将ROI区域裁剪下来,将ROI裁剪的图像通过自适应图像填充调整为300×300,输入到车辆检测模块。
SSD网络的损失函数包括置信损失和定位损失,首先需要将筛选后的框与真实框对应起来,通过计算每个预选框之间的IoU,可以得到预测框与真实框的匹配关系,通过匹配关系计算置信损失,可以由交叉熵计算,计算真实框与预测框的Jaccard系数,可以得到预测框与真实框的相似度,计算定位损失,Jaccard系数和损失函数的计算公式如式(3)和式(4)所示:
L=Lconf+aLloc (3)
(4)
其中式(3)表示整体损失由置信损失和定位损失构成,式中α为定位损失的权重,默认为1,式中Lconf为置信度损失,表示物体包围框内的类别预测准确程度,通过匹配后框类型与真实类型的交叉熵计算,Lloc为定位损失,表示物体包围框与真实框的相似程度,通过计算Jaccard系数得到,其中,A∩B为重合面积,A为第一个框的面积,B为第二个框的面积,Jaccard系数就是IoU,是两个框的重合面积与总面积之比。
车辆检测的输出是车辆包围框的左上角坐标与右下角坐标和置信度,通过包围框的坐标点计算车辆的中心坐标,结合车道线函数计算车辆中心属于第几车道,统计各个车道上的车流量,车辆检测的效果如图6所示,从左到右分别为左转车道、直行车道、右转车道。
2 实验结果与分析
2.1 实验环境
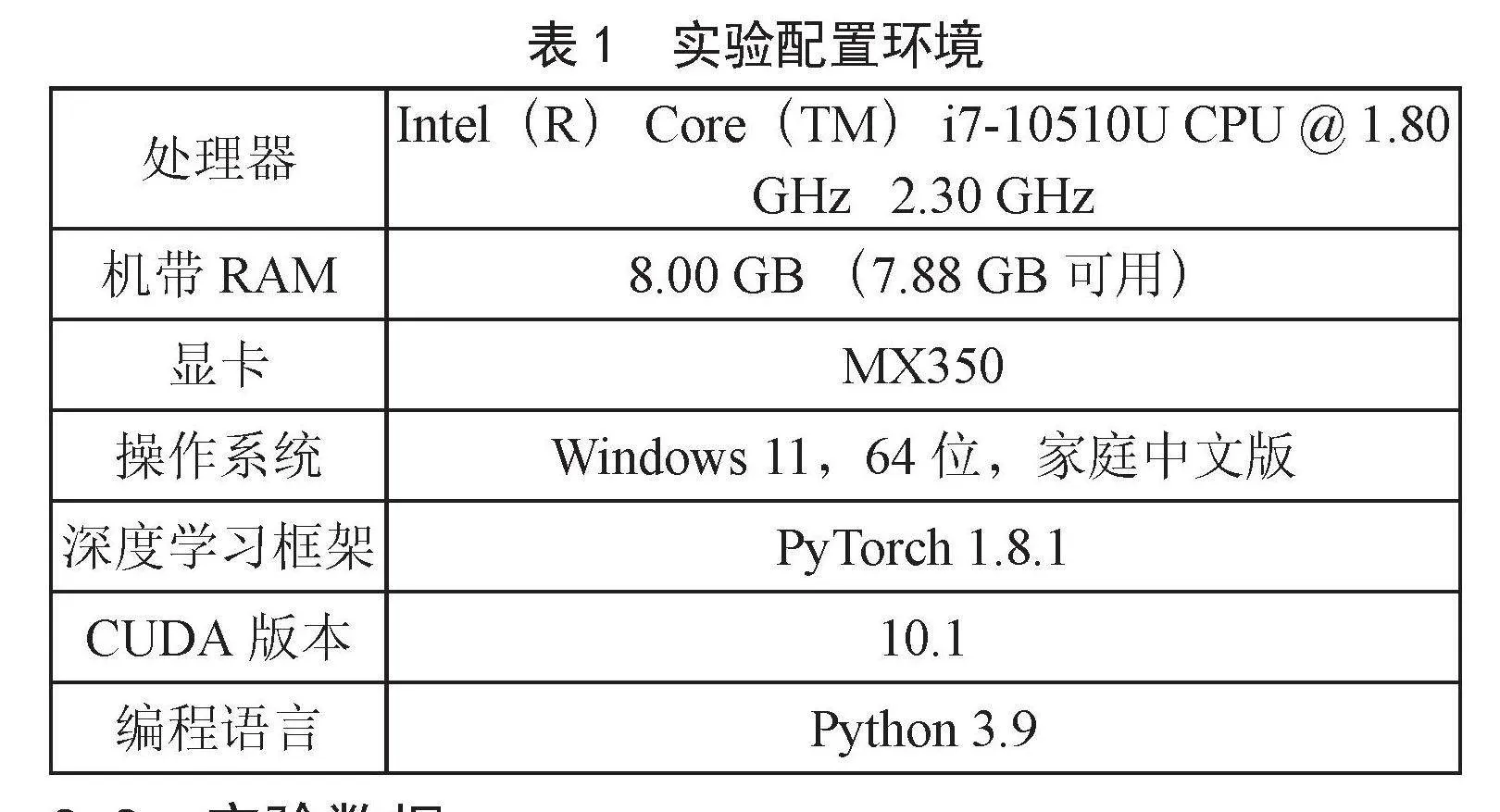
GPU是一种图形处理器技术,他的设计之初是为了满足视频和游戏等行业的高分辨率、高帧率的图像显示,是为了更快速地计算图像和图形相关的运算而设计的,由于GPU优秀的图像运算和并行计算的能力,GPU也成为深度学习发展的巨大推动力,非常适合深度学习中的CNN、RNN和等复杂模型,本文使用MX350训练本文的所有模型,具体实验配置如表1所示。
2.2 实验数据
为了验证真实环境下基于深度学习的智能交通灯设计的性能和可靠性,模拟交通灯的工作环境,对设计进行测试和评估验证,我们使用天桥下的车流视频对交通灯下的车流信息进行简单模拟,录制了10个不同车流视频,每个视频5分钟,在车流量较少的时段,录制2个空旷车道的视频,每个视频30 s。
主要评估项目为FPS(帧率)和精确度P(Precision),将视频中指定时间段固定区域内的各个车道的车辆信息人工记录下来,当系统检测这段时间的车流量时,与人工记录的数据对比得出系8704fadbff8cd389f1fd87d78f374dad022746c19614a7863f893434cb91f981统的准确度。
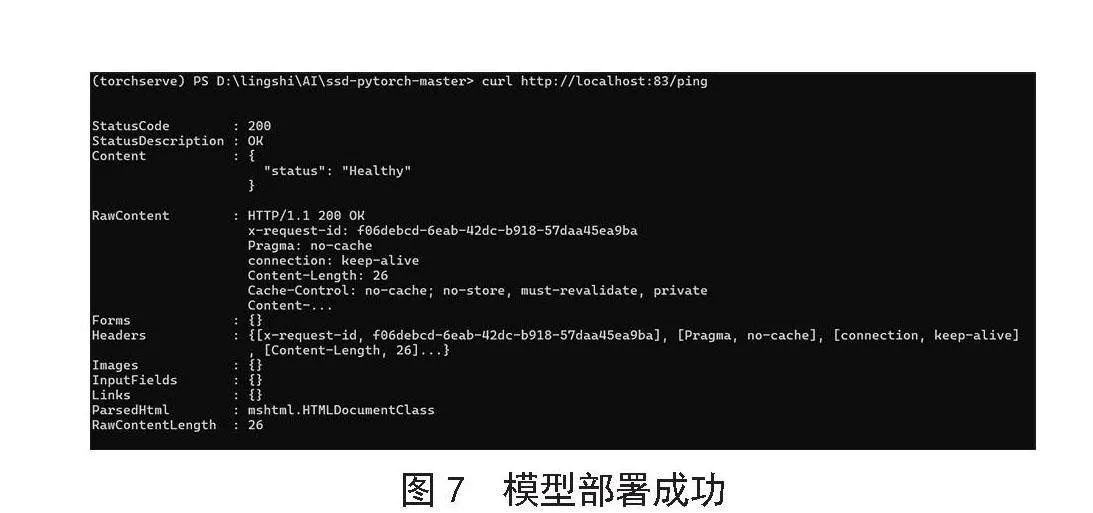
首先将模型部署好,这里使用Torchserve配置模型,简单修改配置文件后,检查是否部署成功,这里的localhost请根据真实的IP填写。模型部署成功图如图7所示。
部署成功后,将视频帧输入配置文件设置的端口,模型即可正常工作开始测试。
2.3 评估指标
本文使用2个指标作为车辆识别准确度的评估标准,精确度(P)和帧率FPS。计算公式如式(5)、式(6)所示:
(5)
(6)
其中准确率P为预测正确的数量与总数之比,TP为样本中预测正确的数量,FP为样本中预测错误的数量,FPS为每秒处理的帧数,处理图像数量和时间之比,FrameNum为处理的整体图像数量,ElapsedTime为处理的时间。
本文使用一个自制数据集测试,数据集由视频和标签组成,标签内标识对应的视频名字和对应帧数内的各个车道车流量,例如在200帧到400帧内左转车道3辆车、直行车道4辆车、右转车道5辆车,可以表示为200,3,4,5,400,测试实际结果与检测结果的误差,使用精确度P作为评估标准。
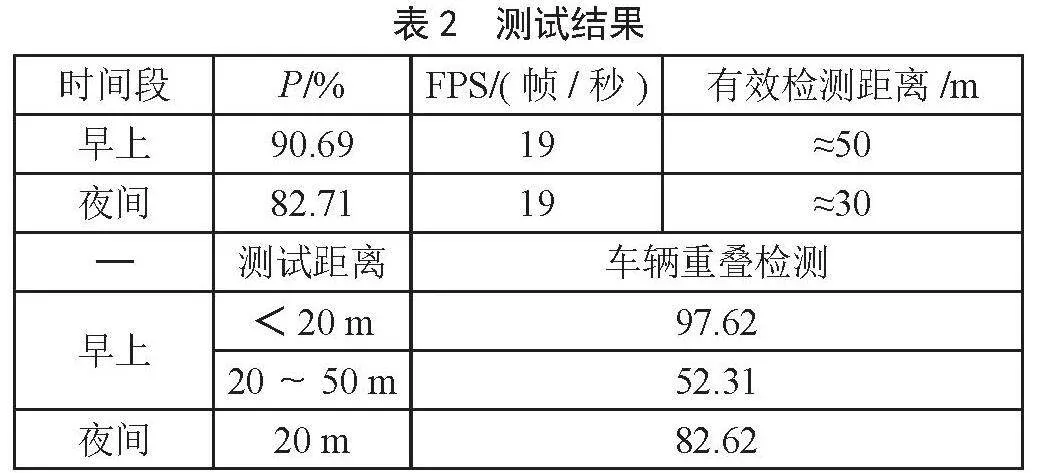
为了验证设计的泛化能力,本文使用在玉林市天桥上拍摄的道路视频制作的测试数据集,视频在三个时间段进行拍摄,分为早上和夜间2个不同种类的视频,分别测试在不同时间段中,系统的性能表现,测试结果如表2所示。
智能交通灯在光线充足的情况下准确率在90.69%,最远可以检测到50 m以内的车辆,可以检测到视频2/3的区域,在30 m到50 m对于部分重叠在一起的车辆检测正确检测不稳定,容易将重叠的两辆车辆检测成为一个车辆,在30 m以内重叠车辆的检测更加稳定,基本不犯错误,夜间检测由于车辆的轮廓和边界没有日间明显,导致车辆检测的错误率急剧上升。
3 结 论
本文对目前的传统交通灯存在的缺陷进行分析,对智能交通灯的主要功能进行设计。首先使用计算机视觉的方式统计各个车道的车流量信息,比原有的传感器检测检测范围更广、车流量信息更丰富、准确率更高,使用这些数据通过交通判决系统,可以实现对交通灯的动态调节,更好地利用交通路网,减少交通问题的发生,在日常出行有更好的体验。
参考文献:
[1] 林春雨,代春宇,田伟,等.基于车流量检测的智能交通灯控制系统设计与实现 [J].无线互联科技,2021,18(18):77-78.
[2] 李克文,杨建涛,黄宗超.基于边界极限点特征的改进YOLOv3目标检测 [J].计算机应用,2023,43(1):81-87.
[3] 赵奇慧,刘艳洋,项炎平.基于深度学习的单阶段车辆检测算法综述 [J].计算机应用,2020,40(S2):30-36.
[4] 李凌,李一平.一种基于轮廓和混合高斯模型的运动车辆视频检测方法 [J].吉林师范大学学报:自然科学版,2013,34(4):64-67.
[5] 窦菲,刘新平,王风华.基于OpenCV的道路视频分析系统 [J].计算机系统应用,2017,26(8):94-98.
[6] 韩俊,王保云.MeanShift算法在图像分割中的应用 [J].现代计算机,2021,27(33):71-76.
[7] 伍瀚,聂佳浩,张照娓,等.基于深度学习的视觉多目标跟踪研究综述 [J].计算机科学,2023,50(4):77-87.
[8] 杨锋,丁之桐,邢蒙蒙,等.深度学习的目标检测算法改进综述 [J].计算机工程与应用,2023,59(11):1-15.
[9] 邓天民,蒲龙忠,万桥.改进FCN的车道线实例分割检测方法 [J].计算机工程与设计,2022,43(10):2935-2943.
[10] 秦晓晖.基于计算机视觉的流量监控智能交通灯系统的设计与实现 [J].软件工程,2021,24(7):43-45.
[11] 王汉谱,瞿玉勇,刘志豪,等.基于FCN的图像语义分割算法研究 [J].成都工业学院学报,2022,25(1):36-41.
[12] 黄子兰.基于语义分割的复杂场景下的车道线识别 [D].石家庄:石家庄铁道大学,2023.
[13] 宋晓茹,刘康,高嵩,等.基于深度学习的军事目标识别算法综述 [J].科学技术与工程,2022,22(22):9466-9475.
作者简介:孔令龙(2000—),男,汉族,广西桂平人,电子工程师,本科在读,研究方向:机器学习、人工智能;任仕艳(2000—),女,汉族,贵州罗甸人,本科在读,研究方向:机器学习、人工智能。
DOI:10.19850/j.cnki.2096-4706.2024.17.035
收稿日期:2024-03-10
Design of Intelligent Transportation Light Based on Deep Learning
KONG Linglong, REN Shiyan
(Yulin Normal University, Yulin 537000, China)
Abstract: In view of the inflexibility of the passage time in traditional transportation light, an intelligent transportation light based on Deep Learning is designed through research on the traffic flow information collected under the transportation light. Firstly, the lane lines are extracted using FCN, and a clustering algorithm is used to fit the lane line function. Secondly, the SSD network model is extracted, with the VGG network as the backbone feature of model, to detect the positional information of vehicles, and the positional information of vehicles is combined with the positional information of lane lines to count the traffic flow information of each lane under the transportation light. The experimental results show that the intelligent transportation light system based on Deep Learning has an accuracy of 90.69% in the actual application process, which is basically applied in the real environment.
Keywords: vehicle detection; SSD; FCN; intelligent transportation
