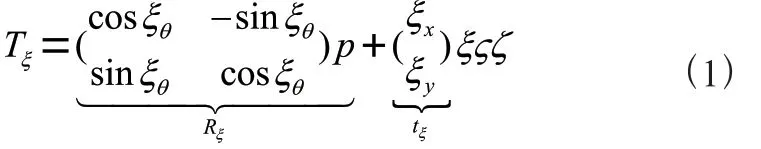




摘" 要:选择准确的图书推荐算法,不仅可以让读者快速而有效地获得所需图书信息,减少检索搜寻时间,同时也可以较好地发挥图书馆馆藏资源的潜在价值。在协同过滤推荐算法的理论与方法的基础上,针对目前比较常用的两种协同过滤图书推荐算法的不足,从作者与作者的相似性角度出发,提出了一种基于作者的协同过滤图书推荐算法。该方法包括计算作者的特征向量、计算相似度、逻辑打分、TOP-K推荐等步骤。算法示例给出了该算法的基本原理与实现过程,结果表明该算法简便、可行,为图书管理推荐工作提供了一种新的思路。
关键词:作者;协同过滤;图书;推荐算法
中图分类号:TP391" " 文献标识码:A" 文章编号:2096-4706(2024)18-0108-05
Collaborative Filtering Book Recommendation Algorithm Based on Author
HU Haiying, CHEN Xuewen
(Library of Hubei University of Arts and Science, Xiangyang" 441053, China)
Abstract: Choosing accurate book recommendation algorithm not only allows readers to obtain the required book information quickly and efficiently, reduces the retrieval and search time, but also gives better play to the latent value of library collection resources. Based on the theory and method of collaborative filtering recommendation algorithm, in view of the shortcomings of the two commonly used collaborative filtering book recommendation algorithms, from the perspective of the similarity between the authors, collaborative filtering book recommendation algorithm based on authors is proposed. The method includes calculating the authors feature vector, calculating similarity, logical scoring, TOP-K recommendation and other steps. The algorithm example shows the basic principle and implementation process of the algorithm, and the results show that the algorithm is simple, convenient and feasible, which provides a new idea for book management recommendation work.
Keywords: author; collaborative filtering; book; recommendation algorithm
0" 引" 言
随着互联网技术的飞速进步,推荐算法已渗透到各行各业的应用场景中。由于用户兴趣偏好各异,故个性化推荐算法的重要性日益凸显[1-2]。除了主动搜索获取信息外,个性化推荐算法作为一种被动信息获取方式,其优劣直接影响用户接收信息的价值性和相关性。
广泛应用的个性化推荐算法之一为协同过滤算法[3-4],该算法基于用户的历史行为数据挖掘其偏好模式,并通过预测用户可能感兴趣的产品进行推荐,如“猜你喜欢”和“购买此商品的用户还喜欢”等功能。协同过滤主要包括用户协同过滤[5-6]和物品协同过滤[7]两种主流实现策略,前者根据用户间的相似性推荐物品,后者则根据物品间的相似性进行推荐,并可通过综合考量两者进行优化推荐。
现有图书推荐系统中,仍广泛采用传统的用户协同过滤和物品协同过滤算法[8]。然而,用户协同过滤算法在用户基数庞大时,计算用户相似度矩阵的成本较高;相反,物品协同过滤算法在物品数量巨大时,计算物品相似度矩阵亦面临高昂代价。为克服这一局限,本文引入了一种新颖的基于作者协同过滤的图书推荐算法。设想一位读者阅读了A作者的作品,通过计算发现A作者与其他B、C、D作者相似度最高,即可推荐B、C、D作者的书籍给该读者,这是因为作者数据集相对较小,计算作者间相似度矩阵的成本较低。
1" 协同过滤算法分析
1.1" 协同过滤推荐算法理论
协同过滤推荐算法可分为基于记忆和基于模型两大类。基于记忆的协同过滤推荐算法直接对用户-物品评分矩阵进行计算,根据用户或物品的相似性进行推荐。其中,用户协同过滤算法通过寻找相似用户集合进行推荐,物品协同过滤算法则基于物品相似性推荐(即:相似物品推荐,根据物品之间的相似性,将目标用户已经喜欢的物品的相似物品推荐给目标用户;物品邻居选择,根据相似度度量方法,选择与目标物品最相似的一部分物品作为邻居,然后根据邻居物品的评分数据进行推荐)。而面对大规模用户和物品数据时,基于模型的协同过滤推荐算法利用统计学和机器学习技术训练模型,以解决基于记忆方法在高维数据下的扩展性和实时性问题,常用技术包括聚类分析、贝叶斯网络、降维技术、本体模型和云模型等。
1.2" 协同过滤推荐算法面临的问题
尽管协同过滤推荐算法在推荐系统中占据主导地位,但它依然遭遇了几个突出挑战,包括数据稀疏性、冷启动情境、推荐多样性及大数据处理问题。对于数据稀疏性,由于推荐系统中用户与物品交互的评分数据极其稀疏,严重影响了推荐质量。尽管可以通过填补缺失评分等方式予以缓解,但这可能导致引入误差,并且计算成本较高。针对数据稀疏性,虽不能彻底根治,但可借助适当策略如数据填充等手段,在一定程度上提高相似性度量的准确性,进而增强推荐算法的精确性。
冷启动问题涉及新用户和新物品的推荐困境。新用户初次接入推荐系统时,缺乏足够的行为记录,而新物品由于尚未积累用户评分和反馈信息,推荐系统对此类情况的处理十分棘手。通常,解决新用户问题可能需要借助用户统计属性或隐私保护前提下的相关统计信息,但隐私保护的现实约束可能限制了这种方法的效果。而对于新物品,可尝试结合基于内容的推荐算法来进行有效推荐。
推荐多样性的要求促使推荐系统不仅要提供精准匹配的结果,还要注重推荐项目的多元化,以满足用户多元化需求,增强用户对系统的满意度和忠诚度。同时,商业运营方期望推荐结果能展示更多种类的商品以刺激用户消费欲望,提高销售额。然而,推荐的多样性和精确性之间的权衡至今仍是推荐系统研究中的一大难题。
随着互联网的持续扩张,新用户、新物品不断涌现,用户与物品之间的交互活动频繁,由此产生的数据呈现出前所未有的规模和动态变化性,大数据处理成为严峻挑战。面对这一问题,关键在于发掘大数据潜力并优化推荐算法,以应对海量数据的存储和高效计算需求。
2" 基于作者的协同过滤图书推荐算法
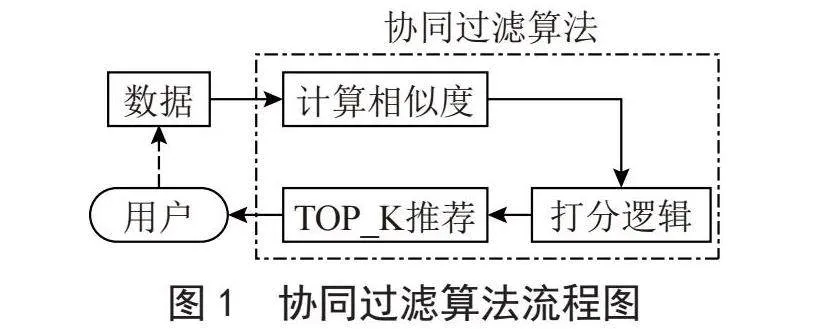
协同过滤算法是用户和数据的交互[9],只有在大数据情况的图书推荐算法才精准有效[10-12]。数据经过推荐算法推荐给用户(如图1中的实线箭头),而用户的行为日志(如图1中的虚线箭头)又会作为数据的一部分来优化对自己或别人的推荐。协同过滤算法核心包含了3个部分[13]:计算相似度、打分逻辑和TOP_K推荐,该算法的具体流程如图1所示。
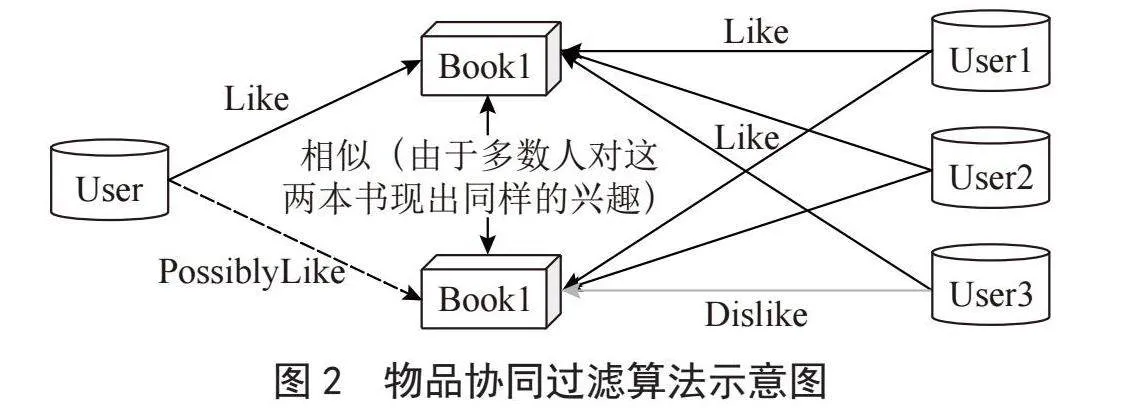
为了便于读者的理解,将抽象的问题简单化,图2给出了物品协同过滤算法核心思想。物品协同过滤算法示意图中,User1和User2都对Book1和Book2表现了兴趣,虽然User3喜欢Book1不喜欢Book2,Book1和Book2有较高的相似度,当一个新的用户User对Book1表现了兴趣时,Book2会被推荐给User。
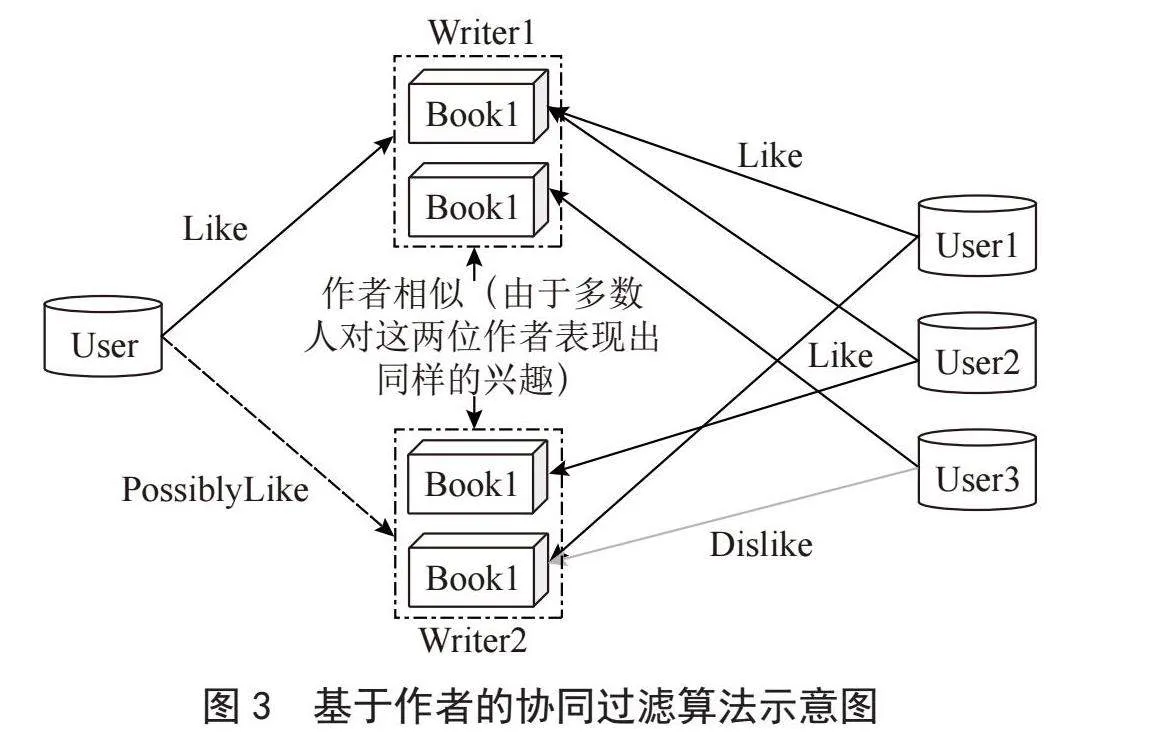
作为对物品协同过滤的补充和升级,本文提出了基于作者的协同过滤算法,其算法核心思想如图3所示。在作者协同过滤算法中,User1、User2和User3对Book的喜好会转换到对作者的喜好,多数用户对Writer1和Writer2的书籍表现了同样的兴趣,因此Writer1和Writer2有较高的相似度,当一个新的用户喜欢Writer1的书籍时,会将Writer2的书籍推荐给User。
主要过程包括以下步骤。
2.1" 计算作者的特征向量
协同过滤算法都会计算相似度,物品协同过滤计算的是物品与物品之间的相似度,用户协同过滤计算的是用户与用户之间的相似度,而作者协同过滤计算的是作者与作者之间的相似度。
计算相似度,首先需要计算特征向量。如若使用物品协同过滤,需计算书籍的特征向量;如若使用用户协同过滤,需计算读者的特征向量;本文提出的基于作者的协同过滤,作者的特征向量计算式为:
(1)
式中,i表示第i个作者,j表示特征向量的第j维,每个作者的特征向量的总维度为有效用户数量,Ni表示第i个作者的有效书籍数量,SBook[n,j]表示第用户j对作者i的第n本书籍的打分。
2.2" 计算相似度
接着就是要计算向量与向量之间的相似度。寻找相似读者使用相似性计算方法,计算出作者之间的相似性,寻找与目标作者相似度高的作者集合。相似性计算往往使用相关系数计算方法,相关系数绝对值越大说明相关性越强,相关系数越接近于0说明相关性越弱。计算作者向量与向量之间的相似度通常有多种计算方式,如皮尔逊相关系数[14]、余弦相似度、Jaccard相似系数等,皮尔逊相关系数计算式如下:
(2)
式中,b表示作者i和作者j对图书评分的交集,Rbi和Rbj分别表示作者i和作者j对第b个资源的评分,和分别表示作者i和作者j对所有资源评分的平均值。
余弦计算式为:
(3)
式中,p和q分别表示N维的特征向量。
本文采用余弦相似度来计算作者向量与向量之间的相似度。
2.3" 进行打分逻辑
打分逻辑指的是根据被推荐用户的阅读记录,对未阅读的候选书籍集合中的书籍进行预估打分的算法,后续会将打分较高的书籍推荐给用户。
首先依据用户的阅读记录和式(1)计算被推荐读者对作者的评分。然后,计算每本书籍的平均得分:
(4)
式中,k表示第k个用户,N表示总用户数,如果用户k对书籍i有阅读记录,I[i,k]=1,否则为0。
接着需要计算用户对未阅读的书籍的预估打分,该书籍的编号假设为u,书籍u对应的作者为m,与用户有交互记录的作者集合记为S0,作者的总集合记为S,则用户对书籍u的预估打分计算式为:
(5)
式中,j表示作者编号,wr[j]表示被推荐用户对作者j的评分,w[j,m]表示作者的相似度,b[u]表示书籍u的平均分。根据式(5)可计算用户对未读书籍的预估打分。
2.4" TOP-K推荐
根据每本书籍的预估打分,由高到低的顺利依次进行推荐。通常情况,为了保证推荐的多样性,会有多种推荐算法联合进行推荐,比如热门书籍推荐、最新书籍推荐、用户协同过滤算法推荐、物品(书籍)协同过滤算法推荐,以及本文提出的作者协同过滤算法推荐。综合考虑后,选取得分最高的K本书籍推荐给用户。当然,随着时间的推移,用户与书籍的交互发生改变,比如有的用户阅读了新的书籍、新的用户加入、新书籍的加入、被推荐算法阅读了新的书籍,这些数据会记录在数据表中,进而会影响下一次的推荐结果。
3" 算法示例
3.1" 数据示例
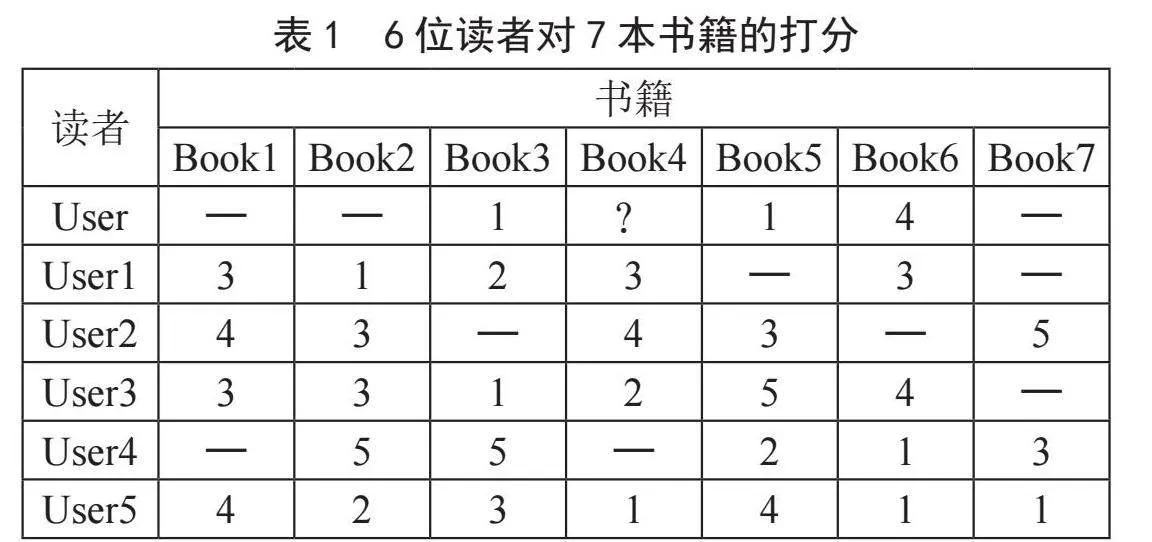
数据一般是以数据表的形式存储在数据库中,记录了读者与书籍的交互关系,表1为6位读者对7本书籍的打分。同时也会有额外的数据表来存储读者或书籍的信息,比如读者的性别和年龄,书籍的作者、语种和出版日期等。
表1中总共有6位读者、7本书籍,“—”是缺失值,表示相应读者没有读过该书籍。User读者读过Book1、Book3、Book5和Book6,本文将以示例的形式展示是否向User推荐Book2、Book4和Book7,并给出相应打分的计算方式。
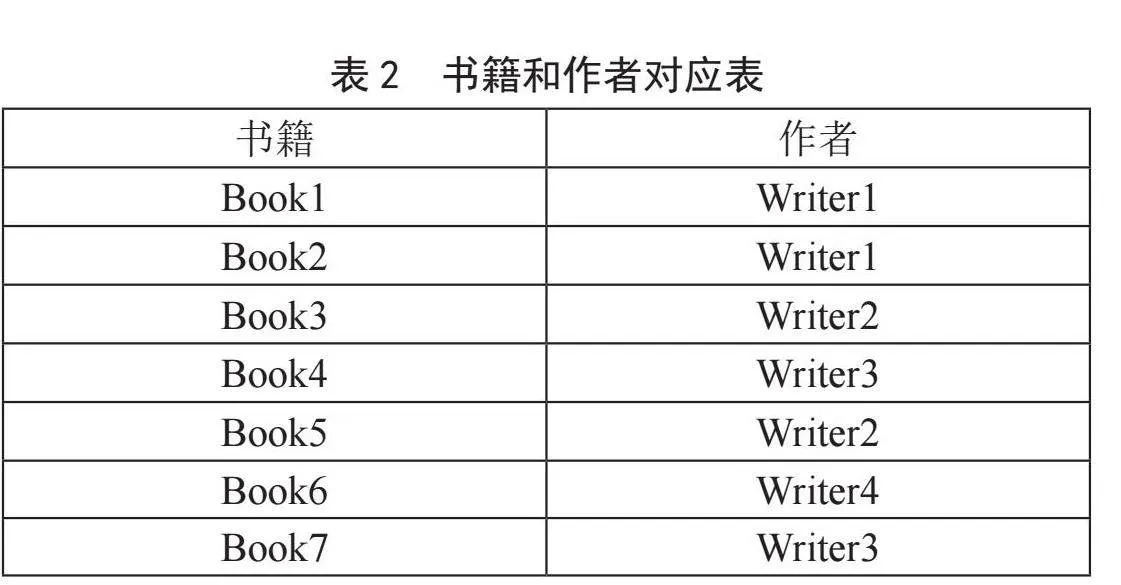
本文提出的基于作者的协同过滤算法会用到书籍和作者的对应关系如表2所示。
3.2" 相似度的计算
基于作者的协同过滤图书推荐算法,需要计算作者与作者之间的相似度。
首先计算作者的特征向量,为了便于计算需要对缺失值“—”进行补全,补全方式有多种,本文采取中值分的方式,最低分为1,最高分为5,缺失分为:
A=(1+2+3+4+5)/5=3
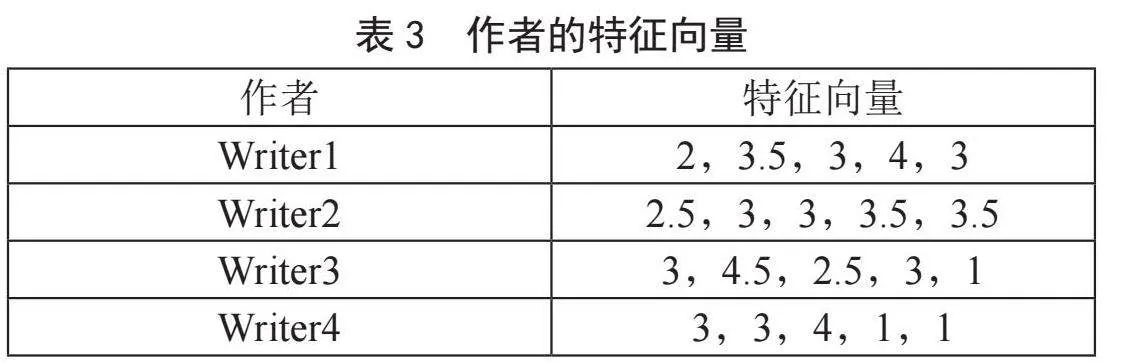
如若使用物品协同过滤,Book1的特征向量为(3,4,3,3,4),其他书籍以此类推;如若使用用户协同过滤,读者的特征向量User1的特征向量为(3,1,2,3,3,3,3)。本文提出的作者协同过滤中,本例中被推荐的用户为User,计算特征的有效用户为User1,User2,…,User5,因此特征向量总维度为5维。以Writer1为例,根据表2,Writer1有两本书籍Book1和Book2,User1对Book1和Book2的评分分别为3和1,因此SWriter[1,1]=(3+1)/2=2,User2对Book1和Book2的评分分别为4和3,因此SWriter[1,2]=(4+3)/2=3.5,同理可得SWriter[1,3]=(3+3)/2=3,SWriter[1,4]=(3+5)/2=4,SWriter[1,3]=(4+2)/2=3;因此Writer1的特征向量为(2,3.5,3,4,3)。依照上式,可得每个作者的特征向量如表3所示。
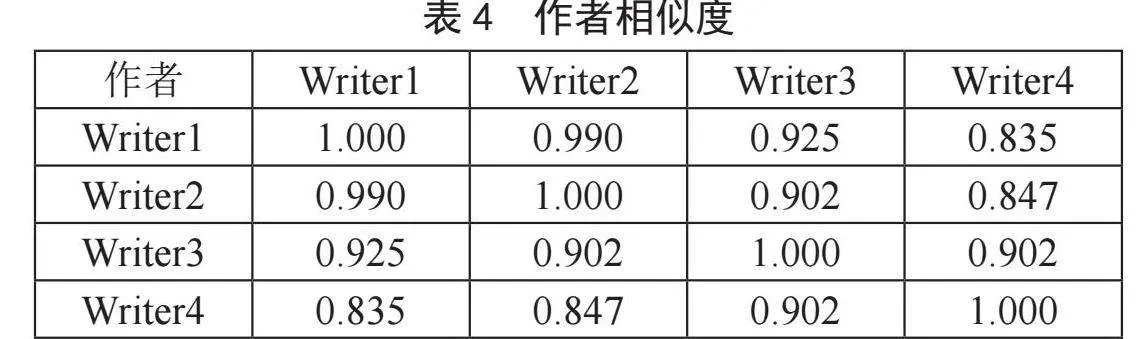
然后按照余弦度计算公式,就可以计算每两个作者之间的相似度如表4所示。
3.3" 打分逻辑
打分逻辑指的是根据被推荐用户的阅读记录,对未阅读的候选书籍集合中的书籍进行预估打分的算法,后续会将打分较高的书籍推荐给用户。首先依据用户的阅读记录和式(1)计算被推荐读者对作者的评分。本示例中,被推荐读者是User,User的阅读记录是Book3、Book5和Book6,根据表2可知,这些书籍对应的作者是Writer2和Writer4。User对Writer2的分值为(1+1)/2=1,对Writer4的分值为4。
接着计算每本书籍的平均得分,依据式(3),可得每本书籍的平均分如表5所示。
3.4" TOP_K推荐结果
根据每本书籍的预估打分,由高到低的顺利以次进行推荐。本例中,推荐顺序为Book1、Book7、Book2、Book4。
4" 结" 论
本文针对现行基于用户和物品协同过滤图书推荐算法存在的局限性,即在处理大规模用户或物品数据时,计算相似度矩阵所需的资源消耗较大的问题,从一个新的视角(作者间的相似性)出发,创新性地构建了一种基于作者协同过滤的图书推荐算法。此算法因其聚焦于作者层面的相似性挖掘,具有较强的可行性及广泛的适用性,能够在降低计算复杂度的同时提高推荐系统的响应速度和效率。此外,基于作者的协同过滤算法是对传统基于用户和物品协同过滤图书推荐方法的有效补充,通过引入作者维度的相似性考量,能够拓宽推荐的覆盖范围,提升推荐结果的多样性和新颖性,从而在提升用户满意度和保持推荐系统活力方面展现出独特优势。
参考文献:
[1] 张德青,程锦.高校图书馆个性化图书推荐算法研究 [J].西昌学院学报:自然科学版,2021,35(2):78-81.
[2] 赵楠.基于个性化图书推荐服务的智慧图书馆服务模式研究 [J].内蒙古科技与经济,2020(19):123-124+127.
[3] 关芳,高一弘,林强.基于协同过滤的高校图书馆纸本资源智能推荐方法实证研究 [J].情报探索,2020(4):109-115.
[4] 刘涛.基于协同过滤的高校图书推荐系统 [J].现代计算机:专业版,2019(2):87-90.
[5] 汪圳,李建苗.基于用户情境的高校图书馆书目协同过滤推荐研究 [J].图书馆研究与工作,2021(1):63-68.
[6] 黄树添,胡诗琳,卜祥智,等.融入用户风险偏好的三支协同过滤推荐模型 [J].南京大学学报:自然科学,2023,59(5):777-789.
[7] 李琳娜,李建春,张志平.启发式的物品相似度传播的协同过滤算法研究 [J].现代图书情报技术,2013(1):30-35.
[8] 傅汉霖,顾小宇.图书推荐算法综述 [J].计算机时代,2016(12):21-23.
[9] 郑祥云,陈志刚,黄瑞,等.基于主题模型的个性化图书推荐算法 [J].计算机应用,2015,35(9):2569-2573.
[10] 杨洁.大数据背景下公共图书馆图书精准推荐服务研究 [J].内蒙古科技与经济,2023(13):130-131+134.
[11] 刘芷茵.大数据环境下个性化图书推荐服务研究 [J].图书馆学刊,2017,39(6):101-106.
[12] 耿立艳,张占福,李达.基于ARIMA-SVM的城际高铁客流量短期预测 [J].交通与运输,2020,36(6):42-45.
[13] 刘军军.用户协同过滤个性化图书推荐算法的改进与实现 [J].图书情报导刊,2021,6(1):38-42.
[14] 汪妍,禹建湘.中国图书国际传播新动态与新思路——基于“丝路书香工程”皮尔逊系数的运用 [J].出版广角,2021(24):26-31.
作者简介:胡海莹(1983—),女,汉族,湖北襄阳人,馆员,本科,研究方向:数字图书馆;陈学文(1971—),男,汉族,湖北黄冈人,馆员,本科,研究方向:情报与档案管理。