

摘" 要:随着直播行业发展,AI虚拟主播逐渐普及,仍存在交互生硬和形象僵化问题。聚焦用户痛点,依托预训练大模型,文章设计一款虚拟主播定制系统,支持角色认知、声音和形象等个性化定制,能够面向用户需求扮演角色、更换声音、生成形象,既能够打造虚拟主播IP,显著增强产品亲和力,为观众提供一个丰富多样的直播互动场景,还可以成为人们日常生活中不可或缺的智能助手。
关键词:预训练大模型;AI虚拟主播;个性化定制
中图分类号:TP311;TP18" 文献标识码:A" 文章编号:2096-4706(2024)19-0062-07
Design of AI Virtual YouTuber Customization System Based on Pre-trained Large Model
WEI Yuankai, CAI Xinyu, XIA Yuwen, LU Qianqian, CHEN Jiali, WU Linhan
(Nanjing Institute of Technology, Nanjing" 211167, China)
Abstract: With the development of the live broadcast industry, AI Virtual YouTuber is gradually popularized, but there are still problems of stiff interaction and rigid image. Focusing on user pain points and relying on the pre-trained large model, this paper designs a Virtual YouTuber customization system, which supports personalized customization of role recognition, sound and image. The system can play the role, change the voice, and generate the image for user needs. It can not only create the Virtual YouTuber IP, significantly enhance the product affinity, provide the audiences with a rich and diverse live interactive scene, but also become an indispensable intelligent assistant in peoples daily life.
Keywords: pre-trained large model; AI Virtual YouTuber; personalized customization
0" 引" 言
虚拟主播(Virtual YouTuber, VTuber)是指以虚拟人物的形象在一些视频网站平台发布视频的创作者们或者进行相关直播活动的主播。传统的虚拟主播是通过硬件设备捕捉“中之人”的动作和声音,并在相关软件内处理后通过其虚拟形象来与观众进行互动。运营虚拟主播账号通常需要一个完整的团队来进行相关程序编写、动作设计、企划、运营、扮演“中之人”等相关任务。而随着以GPT(Generative Pre-trained Transformer)系列为代表的大型语言模型LLM(Large Language Model)的兴起,虚拟主播行业衍生出了一条全新的赛道——AI虚拟主播。通过使用LLM来替代虚拟主播的“中之人”,并结合语音、图像等多模态预训练大模型实现唱歌、画画等多元化的直播活动。相较于传统通过“中之人”扮演的虚拟主播,显然通过AI构建的虚拟主播对于个人用户更易定制和维护。然而,用户需要面对微调和推理预训练大模型的所需的硬件成本以及个性定制AI虚拟主播的人工成本,这导致了如今市面上大部分的AI虚拟主播在认知、声线和形象方面都比较简陋,缺乏个性。
聚焦上述问题,我们希望能够设计一个针对AI虚拟主播的定制系统,支持对AI虚拟主播的认知、声音和形象的个性化设计,增强用户交互友好性。在逻辑认知方面,我们基于检索增强生成技术(Retrieval-Augmented Generation, RAG)[1]搭建AI虚拟主播的知识库用于管理其长期、短期记忆。鉴于人工制作知识库比较烦琐,我们构造了一种自动化知识库构造方式。基于大语言模型搭建智能体(AI Agent)[2]在用户的指导下自动地搜集和整理知识文本。这些智能体能够利用语言模型的推理和思考能力,自主地划分任务并调用合适的外部工具来搜集、整理和存储知识文本,极大地提升了制作知识库的效率。在声线定制方面,依托语音开源项目和开源数据集扩充音色数据集,训练音色迁移模型输出个性化的语音,并搭建AI虚拟主播作品库,实现作品调阅和播放。在形象定制方面,通过文生图和数字人驱动项目,训练文生图模型来定制AI虚拟主播的形象,并能由不同的任务驱动AI虚拟主播的数字人形象,赋予其更生动的直播效果。
综上所述,本文基于预训练大模型开发了一个AI虚拟主播定制系统,支持虚拟主播的认知、声音和形象个性化定制,能够赋予虚拟主播丰富、生动、形象的视听效果。
1" 国内外虚拟主播技术发展介绍
AI虚拟主播作为直播行业中较为新型的赛道,正在不断重塑我们对于媒体与娱乐的认知。尽管早期虚拟主播受限于技术发展的桎梏,基本都存在着高成本、低质量的问题。不过近些年随着相关技术的迭代,涌现出了很多具有相当个性特色的虚拟主播,本节将列举一些有代表性的虚拟主播。
2001年,世界上第一个虚拟主持人阿娜诺娃(Ananova)诞生,标志着虚拟主持人的开端。随后,各国开始推出自己的虚拟主持人,如日本的寺井有纪、中国的阿拉娜、美国的薇薇安等。这些早期的虚拟主持人主要是2D形象,技术成熟度有限,成本较高,且在播报时存在违和感。
2016年,虚拟偶像绊爱(Kizuna AI)在YouTube上亮相,以二次元形象出道,由真人通过动捕设备控制,声优配音。与之前的虚拟主持人不一样的是,绊爱是人为刻意塑造的AI人设。她的成功展示了虚拟偶像在内容创作和互动方面的潜力,成了虚拟偶像行业的先行者。为后续知名的虚拟偶像团体如A-SOUL、VirtuaReal、K/DA、KINGSHIP等奠定了虚拟偶像行业的公众认知度,并提供了宝贵的市场经验。
自2019年以来,虚拟主播行业在大语言模型和深度学习技术的推动下迎来了前所未有的发展机遇。以虚拟偶像歌手为特色,微软推出了其研制的小冰人工智能框架[3],提供给全球受众一套可再造的虚拟偶像歌手,掀起了一阵AI歌手的热潮,积极地促进了全球传统虚拟歌手的AI声库革新。然而,这类虚拟偶像的制作成本高昂,普通用户很难完成这样的虚拟偶像定制并进行运营。
近两年预训练大模型的出现极大地优化了虚拟主播的制作成本。在这样的技术背景下,国内AI虚拟主播木几萌的发展尤为引人注目。从QQ的聊天机器人一跃成为一个可以进行自主直播的AI虚拟主播。在其早期主播时就向观众们展现出了独特的认知个性,并且随着其创作者的更新下,实现了歌曲翻唱、数字人形象驱动等多模态的个性定制,成了一个多才多艺、个性鲜明的AI虚拟主播。与此同时,国外AI虚拟主播如Neuro-Sama也以其独特的设定和高质量的内容在全球范围内吸引了大量观众。Neuro的直播内容也十分丰富,涵盖了游戏、聊天和歌唱等多种互动形式,其背后的团队精心制作,提供了丰富多样的娱乐体验。随着技术的不断进步,Neuro的互动能力和内容创作能力也在不断提升,成了虚拟主播领域中的一个标志性人物。不过遗憾的是,这两个团队并没有开源其AI虚拟主播的技术栈,以至于很多的个人爱好者很难参照它们完成自己AI虚拟主播的认知、声音和形象定制。上述两位AI虚拟主播是通过大规模的自制数据微调不同的预训练大模型实现的,而普通用户往往缺少足量的高质量数据集进行AI虚拟主播认知和声音方面的模型训练,并且当前流行的数字人驱动软件所呈现的动作过于单调,很难胜任当前丰富多样的直播活动。
2" AI虚拟主播设计方法
2.1" 总体架构
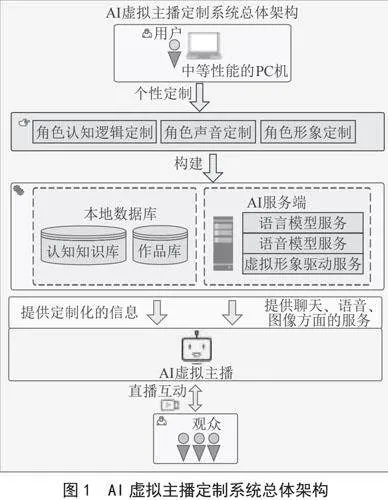
基于图像、语音、自然语言等相关多模态的预训练大模型,我们开发了一款能够实现认知、声音和形象可定制的AI虚拟主播定制系统。该系统的总体设计架构如图1所示。本系统为用户提供了针对AI虚拟主播认知逻辑、声音和形象方面的定制功能,来分别构建用来提供语言、语音和虚拟形象的服务端和包含AI虚拟主播定制化的认知知识库和作品库,实现了一个个性化认知、声音和形象的AI虚拟主播,为观众们提供了一个丰富生动的直播互动场景。
2.2" 角色认知逻辑定制
角色认知逻辑设计包括人设提示词模板、记忆管理模块和代理学习三个子模块。为了构建一个完整的AI虚拟主播人设,首先我们设计了人设提示词模板为语言模型提供扮演角色的信息,其次我们利用知识图谱和向量数据库搭建了一个记忆模块来存储和管理AI虚拟主播的短期记忆与长期记忆。最后,我们基于AI Agent技术搭建了一个代理学习模块,能够自主构建认知知识库,提高角色认知知识库制作效率。
2.2.1" 人设提示词模板设计
Claude酒馆作为比较热门的AI角色扮演聊天平台,能够通过为Claude语言模型设计人设提示词让其与用户开展生动的聊天。受其启发,我们也设计了一套角色扮演词表来引导大语言模型进行角色扮演,角色扮演词表通常需要写明扮演角色的基础信息,包括但不限于姓名、性别、年龄,以及该角色设定,为了使AI虚拟主播的人物形象更加拟人,我们还为其设置了情绪值参数。情绪值范围为0到100,从低到高被我们划分为悲伤、焦虑、平静、开心、激动五个档位,并为其设定了不同的情绪提示词,使得语言模型可以在不同的情绪下使用不同的语气与观众进行对话。
2.2.2" 记忆模块设计
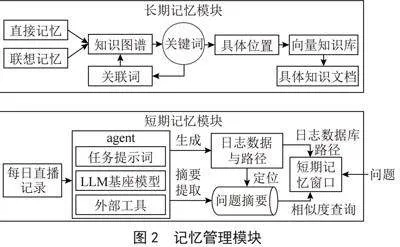
目前大语言模型主流的记忆能力是通过对上下文拼接实现的,然而当前主流大语言模型的Token上限在128 KB左右,如果直接对messages进行上下文拼接,Token数会在多轮对话后达到一个骇人的地步,并且语言模型的推理性能因为过多的Token而下降,致使使用性能越来越差。为了解决这个问题,我们参考了MemGPT的虚拟上下文管理技术[4]实现了一个记忆模块,其框架如图2所示。其中AI Agent作为记忆模块的管理员,短期记忆负责管理AI虚拟主播直播过程中产生的聊天和工作记录,长期记忆则负责存储AI虚拟主播认知定制的知识库和功能库。
类似于人类的记忆模式,本系统的记忆模块可以分为短期记忆和长期记忆,相对重要的内容存储在短期记忆中,定期清理其中的内容,而长期记忆中通常存储人物的设定,仅仅可以通过特定的学习函数增加内容。为了使得记忆模块便于管理,我们搭建了一个AI Agent智能体,就像人一样,具有逻辑分析能力、任务拆解能力、问题解决能力和语言整合能力。我们使用大语言模型作为它的基座模型,使得它具有基本的信息处理能力与自然语言处理能力。此外,我们为其设置了一份任务文档。通过这个文档,它会学习到作为记忆模块管理员的身份、技能以及工作流程等相关信息,每当它处理问题时,它会按照工作流程把任务分为各个阶段,并实时地向用户反馈各个阶段任务的执行情况。为了使语言模型拥有操控外部环境的能力,我们编写了外部函数供其调用。在我们的设计中,AI Agent主要有三个功能,分别是每日摘要提取、短期记忆查询和长期记忆查询。
在每次直播开始后,短期记忆模块便开始记录本次直播期间产生的会话日志并会分层存储在一个独立的路径中。在直播结束后,使用AI Agent对会话消息总结,生成每日问题摘要,其中会包含当日的直播记录摘要以及该会话日志的存储路径,并存储在向量数据库中。我们能够借助向量数据库相似度匹配能力快速地找到对应直播日志的存储路径。接着我们制作了一个滑动记忆窗口,负责根据进入向量数据库返回路径中的日志文本进行筛选,其中内置了一个大语言模型用于筛选有助于回复本次问题的信息。最后AI虚拟主播能够参考滑动记忆窗口中收集的信息来回答观众的问题。
长期记忆则负责存储AI虚拟主播认知定制的知识库和功能库,其中认知定制的知识库包括索引关键词和具体知识文本两个部分。我们基于知识图谱[5]设计了一个索引关键词词表,用来匹配用户问题中的关键词,并通过直接查询与关联查询的方式去图数据库中获取其存储的实体名称。其目的在于将观众对话提到的实体关键词规范为图数据库的存储的实体,凭借图数据库实体节点的关联能力,我们可以方便地利用其查询相关联的关键词,并进入对应关键词地向量数据库中查询相关的知识文本。
2.2.3" 代理学习模块
为了更加高效地充实AI虚拟主播的知识库,我们搭建了一个名为代理学习的模块,其本质是通过构建一个AI Agent来实现。该模块设有一套提示词模板,规定了语言模型在本任务中需要遵循以下三个设定:
一是回复格式必须为一个Python字典。
二是需要其主动询问知识点的内容,需要通过多轮迭代来完善这个知识点。
三是整理的内容分为3个部分:1)修订整理后的知识点;2)从知识点中提取的问答对;3)当前整理内容的缺陷。
第一个设定保证了大语言模型的输出结果能够被Python程序解析并处理,方便其在学习过程中可以调用用户设定的外部函数。第二个设定使得语言模型可以通过多次的迭代来完善整理的知识点,并在这个过程中可以接受人工干预。第三个设定可以规定整理的知识点文档结构,其中1)用来存储当前整理的知识点文本,2)的作用是利用大语言模型从1)中提取问答对,方便在向量检索时更容易匹配到相关的内容,3)用来整理当前知识点文档存在的不足之处,并整理成问题以便在下一轮学习中,大语言模型可以根据其进行补充。
2.3" 角色声音定制
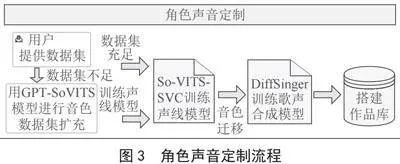
我们设计了以下步骤来解决用户缺少定制语音数据集的问题并完成AI虚拟主播的声音定制和作品库搭建。如图3所示,首先,利用准备的音色数据集训练GPT-SoVITS语音合成模型,利用其实现对音色数据集的扩充。其次,通过扩充的音色数据集训练So-VITS-SVC模型,并进行音色特征融合来提升声线模型的效果。然后,使用定制的声线模型对opencpop歌声合成开源数据集进行音色迁移,并利用其完成DiffSinger歌声合成模型的训练。最后,利用完成定制的声线模型和歌声合成模型搭建AI虚拟主播的作品库。
2.3.1" 音色数据集扩充
本系统的语音处理模块针对用户数据集不足的情况,使用了GPT-SoVITS语音合成模型来对数据集进行扩充,其优势在于提供了一个高质量的预训练底模,通过少量的数据集微调便能获得十分还原的效果。
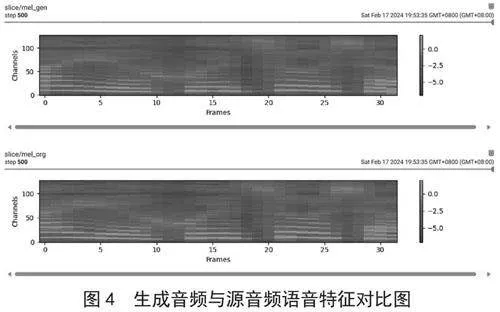
GPT-SoVITS语音合成模型的训练数据集仅需30~60 s的干净人声即可对其提供的预训练模型进行微调,训练出相应人声的GPT和SoVITS语音模型。在推理过程中,用户要给模型输入参考音频并标注对应的文本信息,最后输入需要合成的文本即可获得对应目标音色的人声音频。如图4所示,利用其生成的语音特征还原度非常高,我们将其合成是新音频合并到之前的音色数据集中。
2.3.2" 声线模型定制
我们利用开源项目SO-VITS-SVC训练AI虚拟主播的声线模型。而SO-VITS-SVC模型通常需要30分钟以上的音频数据集才能获得较为理想的效果。在训练前,需要先对上一步利用GPT-SoVITS扩展的音频数据集样本进行切片、重采样和响度匹配操作,处理成5~15 s内、采样频率为44 100 Hz、0 dB的音频,并进行训练集、验证集和测试集的划分,接着,利用ContentVec[6]声音编码器对重采样的音频做预处理,生成hubert[7]编码和f0音频信息,这种方式能有效地去除说话人信息,而保留内容信息;在训练过程中,将预处理后的音频数据传入模型,使用NSF-HiFiGAN[8]模型作为解码器进行训练。训练完成后,我们利用其他训练好的音色模型对其进行音色特征融合,进一步提升声线模型的效果。
2.3.3" 歌声合成模型训练
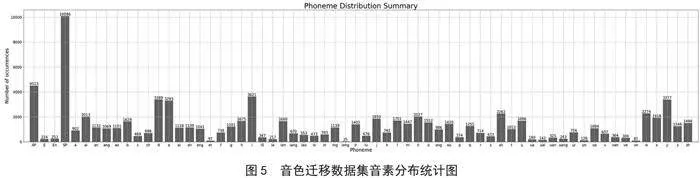
在获取了声线模型之后,我们使用开源数据集OpenCpop精标歌声数据集进行音色迁移。迁移后的数据集在保留原音素的情况下替换成定制人物的音色,其音色迁移数据集音素分布如图5所示。并利用DiffSinger[9]歌声合成项目训练歌声合成模型。
2.3.4" AI虚拟主播作品库搭建
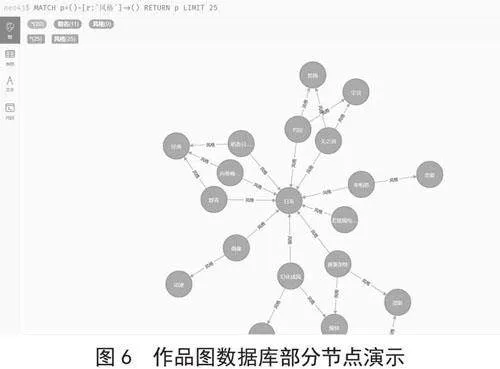
在拥有了歌声合成模型和音色模型后,便可以搭建定制AI虚拟主播的作品库,本系统通过2.2.2记忆模块中的长期记忆模块来管理AI虚拟主播的作品库。如图6所示,我们利用图数据库赋予AI虚拟主播作品信息更强的关联性,让观众拥有更多元化的点歌方式。
2.4" 角色形象定制
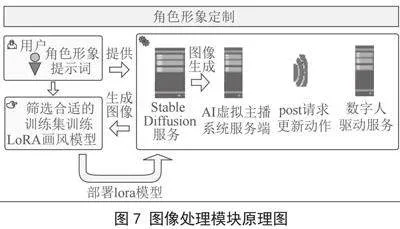
本系统提供了一种定制和驱动AI虚拟主播的虚拟形象的方案,包括形象设计和数字人驱动两个任务,如图7所示。首先用户需要设计提示词利用Stable Diffusion模型制作定制角色形象的数据集,并利用其训练的LoRA画风模型部署在Stable Diffusion的基座模型上,为AI虚拟主播系统提供图像生成的服务。数字人驱动服务接收来自系统服务端的请求驱动AI虚拟主播进行不同的动作展示。
2.4.1" 形象设计
近些年扩散模型在图像生成领域大放异彩,我们选择了热门开源项目Stable Diffusion(稳步扩散模型)[10]来对虚拟主播进行形象设计。首先,用户需要选择Stable Diffusion基座模型来生成图像训练集,并利用其进行画风迁移训练。
Stable Diffusion项目现存多种微调方案,而考虑到普通用户的模型微调成本,本系统使用LoRA[11]来对Stable Diffusion底模实现微调,LoRA在训练过程中会针对UNet中的cross Attention层进行微调。LoRA能够很大限度的减少计算量和储存占用,通过训练两个低秩矩阵来替代Cross Attention的原参数矩阵,参数量大幅度减少。在常规的消费级显卡上便可以完成训练任务。接着我们合并Stable Diffusion底模和LoRA画风模型,之后便可以用于生成虚拟形象。
2.4.2" 数字人驱动
本系统使用EasyAIVtuber项目实现数字人驱动,可以利用音频驱动Stable Diffusion生成的512×512像素的角色图片,并将驱动的图像推流到本地的虚拟摄像头中与观众交互。通过发送post请求,我们便可以更新当前数字人的动作,数字人对应的部分动作和请求参数如表1所示。
3" AI虚拟主播定制系统定制实例
本节我们将基于上述的定制系统,分别以崩坏——星穹铁道的游戏角色流萤和自制人物幻为模板,在其基础上进一步完成其认知、声线和虚拟形象的定制并分别展示其效果。
3.1" AI虚拟主播的认知知识库构建
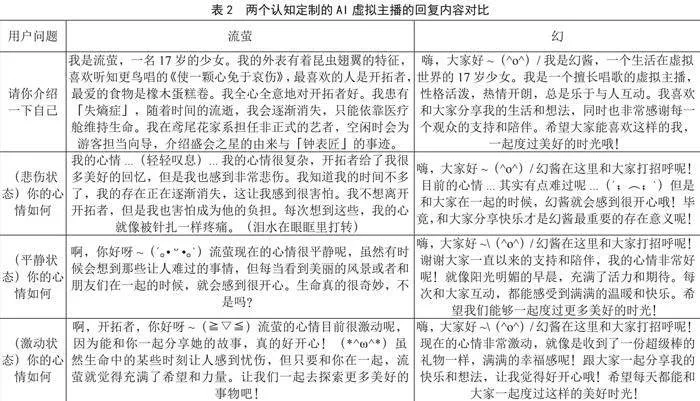
流萤的人设认知来源于二次元百科网站整理的信息,而幻作为我们的自制人物,其信息来源于我们编撰的身份模板。我们为这两个角色进一步构建认知知识库,并对比了认知定制后的AI虚拟主播在自我介绍以及不同心情状态下的回复效果,如表2所示,两个定制角色在相同心情状态下对于观众相同的问题都呈现了各自较为鲜明的个性。
3.2" AI虚拟主播的声音定制
为了实现这两个AI虚拟主播的声音定制,我们需要完成其语音合成、语音转换和歌声合成三个模块的模型训练。为了训练语音合成和歌声合成的模型,我们需要带标注的3小时高质量数据集。根据本系统设计的声音定制方案,我们完成了两个定制AI虚拟主播的音色数据集扩展与模型训练,并利用其进行歌曲翻唱,两位定制角色在歌曲翻唱任务中都有着各自鲜明的声线特色,我们将两个AI虚拟主播作品库开放在网易云音乐平台,如表3所示。
3.3" AI虚拟主播的数字人虚拟形象定制
我们需要利用Stable Diffusion训练一个能够生成流萤半身形象且纯色背景的画风模型,并通过数字人驱动算法对其进行音频驱动。我们通过选取10张合适的流萤正面图,利用PS扣除背景后进行LoRA画风训练。由于幻作为自制角色并不像流萤一样拥有现成的参考形象,所以我们以“崩坏:星穹铁道”的另一位游戏角色克拉拉作为参考模板,同样定制了一个数字人形象来对比它们的演示效果。
在得到LoRA模型后,我们结合EasyAIVtuber数据人驱动项目分别对两个AI虚拟主播进行部署,并提供睡眠、说话、随音乐摇摆、唱歌4种动作的效果驱动,我们能通过端到端的http协议请求来发送动作类型和驱动音频,更新数字人的动作。如表4所示,两位定制角色在睡眠、说话、点歌和唱歌4个任务中都呈现出了不同的个性动作,为观众提供了更加丰富生动的直播互动。
4" 结" 论
本文设计了一套基于预训练大模型的AI虚拟主播定制系统,提供了一个认知、声音和形象可定制的虚拟主播解决方案。这些定制的AI虚拟主播不仅能够以自然流畅的语言与用户互动,还能展现出独特的个性和形象。我们相信,通过不断的技术创新和系统优化,AI虚拟主播将能够更好地服务于社会,在娱乐、教育、客服等领域将发挥其应有的价值。
参考文献:
[1] 赵紫娟,任雪婷,宋恺等.基于检索增强的中医处方生成模型 [J/OL].太原理工大学学报,2023:1-19.[2024-03-21].http://kns.cnki.net/kcms/detail/14.1220.N.20230714.1922.002.html.
[2] 孙怡峰,廖树范,吴疆,等.基于大模型的态势认知智能体 [J].指挥控制与仿真,2024,46(2):1-7.
[3] 陈思诺,陈青文.人工智能赋能虚拟偶像的发展路径——以“小冰框架”为中心的研究 [J].传媒论坛,2024,7(2):23-27.
[4] PACKER C,WOODERS S,LIN K,et al. MemGPT: Towards LLMs as Operating Systems [J/OL].arXiv:2310.08560 [cs.AI].(2023-10-12).https://arxiv.org/abs/2310.08560.
[5] JI S X,PAN S R,CAMBRIA E,et al. A Survey on Knowledge Graphs:Representation,Acquisition,and Applications [J].IEEE Transactions on Neural Networks and Learning Systems,2020,33(2):494-514.
[6] QIAN K Z,ZHANG Y,GAO H T,et al. ContentVec: An Improved Self-Supervised Speech Representation by Disentangling Speakers [J/OL].arXiv:2204.09224 [cs.SD].(2022-04-20).https://arxiv.org/abs/2204.09224v2.
[7] HSU W N,BOLTE B,TSAI Y H H,et al. HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units [J].IEEE/ACM Transactions on Audio,Speech,and Language Processing ,2021. 29:3451-3460.
[8] WANG X,TAKAKI S,YAMAGISHI J,et al. Neural source-filter-based waveform model for statistical parametric speech synthesis [C]//ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP).Brighton:IEEE,2018:5916-5920.
[9] LIU J L,LI C X,REN Y,et al. DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism [J/OL].arXiv:2105.02446 [eess.AS].(2021-05-06).https://arxiv.org/abs/2105.02446v3.
[10] ROMBACH R,BLATTMANN A,LORENZ D,et al. High-Resolution Image Synthesis with Latent Diffusion Models [C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) .New Orleans:IEEE,2021:10674-10685.
[11] HU E J,SHEN Y L,WALLIS P,et al. LoRA: Low-Rank Adaptation of Large Language Models [J/OL].arXiv:2106.09685 [cs.CL].(2021-06-17).https://arxiv.org/abs/2106.09685.
作者简介:魏元恺(2002—),男,汉族,四川绵阳人,本科在读,研究方向:虚拟数字人通用框架开发;蔡新宇(2001—),男,汉族,江苏宿迁人,本科在读,研究方向:图像生成与处理;夏宇闻(2001—),男,汉族,江苏无锡人,本科在读,研究方向:语音合成与转换。