

摘 要:为有效地收集、整理和利用高校数字文化资源,文章设计并实现了一个基于Python 3.9和Django 4.2架构的高校微信公众号资源管理平台。平台以高校相关的微信公众号为主要内容来源,利用网络爬虫、MySQL数据库,实现相关的数字文化资源的收集、存储,并利用深度学习框架的自然语言处理工具库对资源进行实体抽取形成多维度标签,实现对资源内容的深度揭示与关联化检索。
关键词:数字文化;Python;Django;ERNIE-UIE
中图分类号:TP311.1;G258.6 文献标识码:A 文章编号:2096-4706(2024)20-0072-07
Design and Implementation of a University Resource Management Platform for WeChat Official Accounts Platform
LIN Li
(Minjiang University Library, Fuzhou 350108, China)
Abstract: This paper designs and implements a university resource management platform for WeChat official accounts platform based on Python 3.9 and Django 4.2, aiming at effectively collecting, sorting out and utilizing university digital cultural resources. The platform takes WeChat official accounts platforms related to colleges and universities as the main content sources, uses Web crawler and MySQL database to collect and store related digital cultural resources, and uses the natural language processing tool library of Deep Learning framework to extract entities from resources to form multi-dimensional tags, thus realizing in-depth disclosure and related retrieval of resource contents.
Keywords: digital culture; Python; Django; ERNIE-UIE
0 引 言
2022年5月中央办公厅、国务院办公厅印发《关于推进实施国家文化数字化战略的意见》,部署建设中华文化数据库和文化数据服务平台等重点任务,将数字文化建设提升为国家战略[1]。随着数字化浪潮的深入发展,高校已成为数字文化资源的重要汇聚地。这些资源包括校史档案、学术讲座、校园活动等丰富内容,它们主要通过微信公众号、视频号等新媒体平台进行传播[2]。然而,由于运营主体分散,缺乏统一的管理机制,这些资源的关联性检索与高效利用受到了一定的限制[3]。为此,本文设计并实现了一个基于Python 3.9和Django 4.2架构的高校微信公众号资源管理平台,旨在解决这一问题。
1 平台设计
1.1 系统需求分析
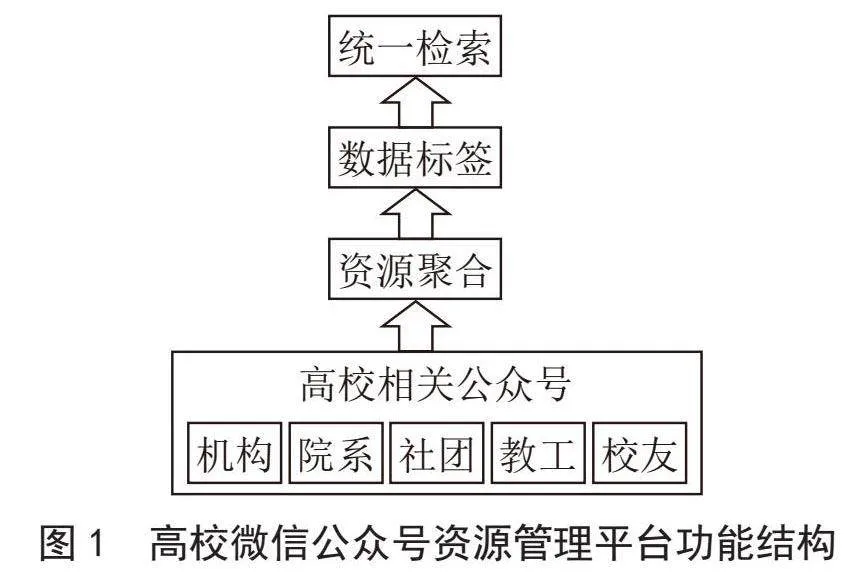
高校微信公众号资源管理平台用于整合与高校相关的微信公众号所发布的数字资源。一方面,与高校相关的微信公众号运营主体分散,有的属于学校相关职能机构如教务处、科研处等,有的属于学校各院系,有的属于学生社团,有的属于教工个人,还有的属于校友,导致资源的共享性较差[4];另一方面,由于微信公众号平台在资源管理上主要以内容展示为主,对于内容主题检索,特别是跨公众号的内容主题检索支持有限,无法实现高校微信公众号资源的统一检索利用。因此平台需实现以下功能:
1)将与高校相关的微信公众号上的数字文化资源进行统一聚合,对相关公众号所发布资源进行自动化收集。
2)对收集的数字资源进行统一存储和元数据抽取,实现文本资源的数据化处理,生成资源的多维度标签。
3)支持基于分析数据的多维度检索和图谱化展示。
平台功能结构如图1所示。
1.2 技术选型
平台选择Python作为开发语言,Django作为后台框架。Python拥有强大而广泛的第三方库和框架支持,能够满足各种Web开发需求。开发者可以利用现成的工具和库,提高开发效率,减少重复劳动,使得Web应用的构建更加迅速和灵活[5]。选择Django 4.2作为Web框架,Django是一个高度集成的Web框架,提供了大量的内置组件和工具,包括ORM(对象关系映射)、模板引擎、表单处理等。此外,选择MySQL 8.0作为关系型数据库,它具有良好的存储和查询性能[6]。选择百度开源的ERNIE-UIE大模型,该模型实现了实体抽取、关系抽取、事件抽取、情感分析等任务的统一建模,并使得不同任务间具备良好的迁移和泛化能力,可以支持对不限定行业领域和抽取目标的关键信息抽取[7]。选择NetworkX作为图谱库,它可以将知识点可视化为知识图谱。
1.3 平台架构
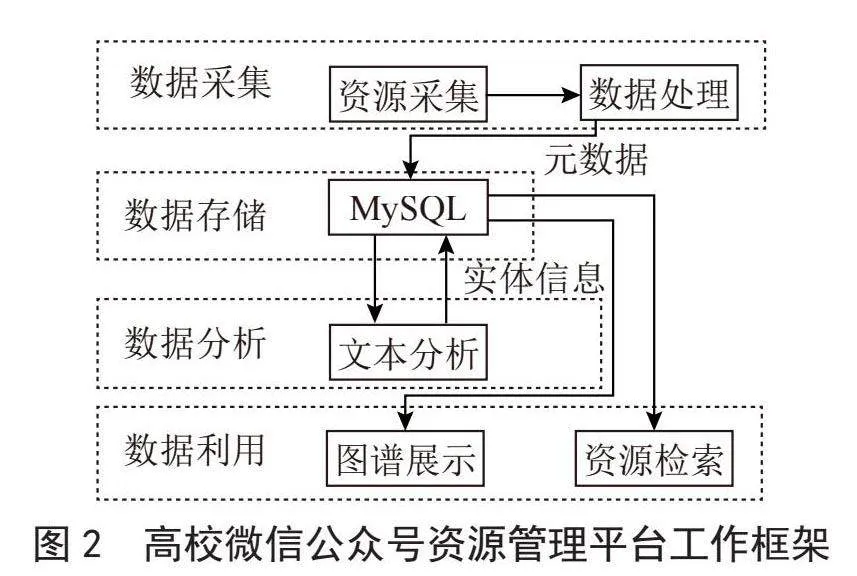
平台采用B/S架构、模块化设计,如图2所示,主要包括以下模块:
1)数字资源的采集和处理模块。负责自动从微信公众号、视频号上爬取数字文化资源,并抽取出资源的元数据。
2)数据存储模块。负责将爬取到的资源元数据存储到MySQL数据库中。
3)数据分析模块。负责通过爬取的URL数据来提取资源中的文本信息,经过清洗、分析,生成资源多维度实体信息,并存入MySQL数据库中。
4)数据利用模块。负责将以提取到的资源多维度实体信息作为资源的标签,方便资源的回溯检索。同时,以实体信息为参数生成资源的知识图谱。
1.4 数据库设计
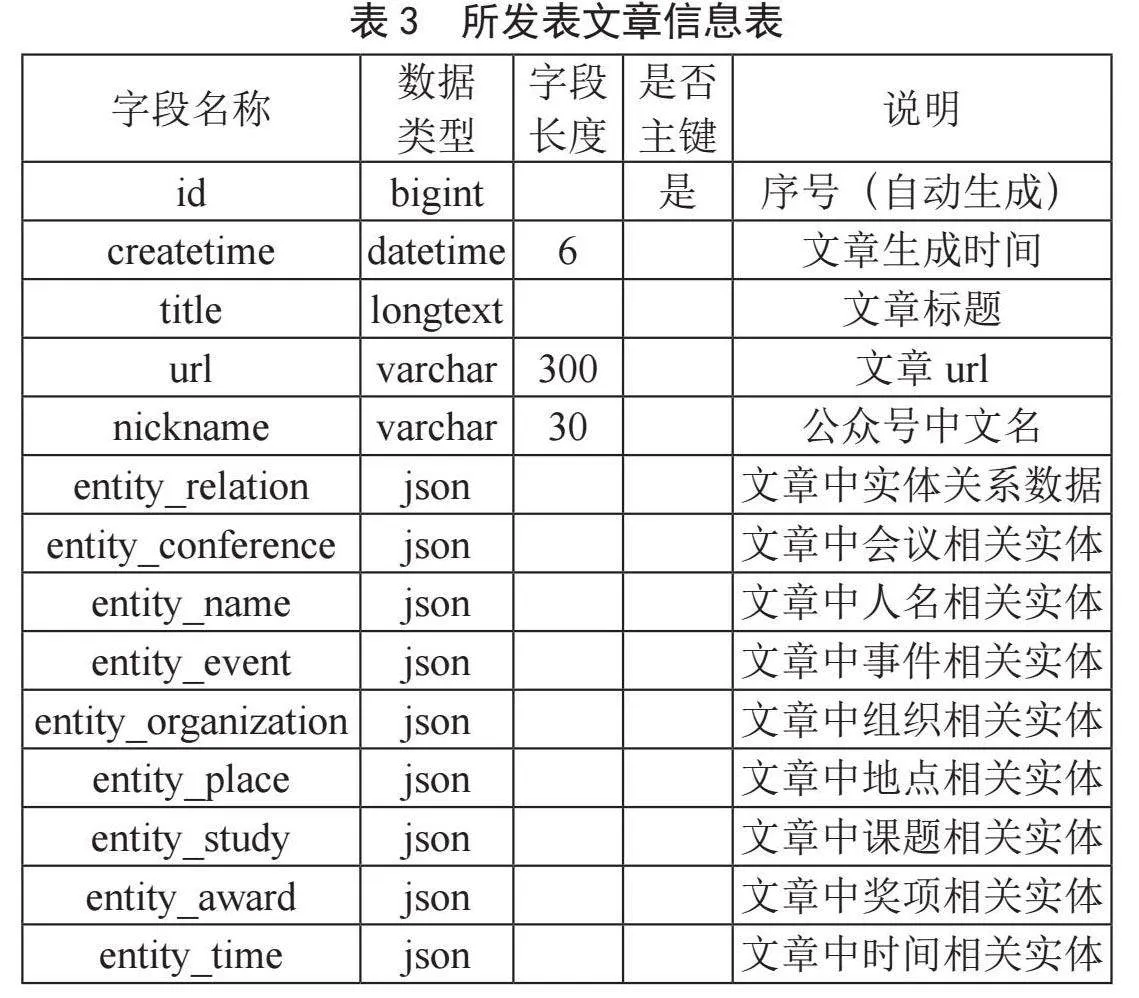
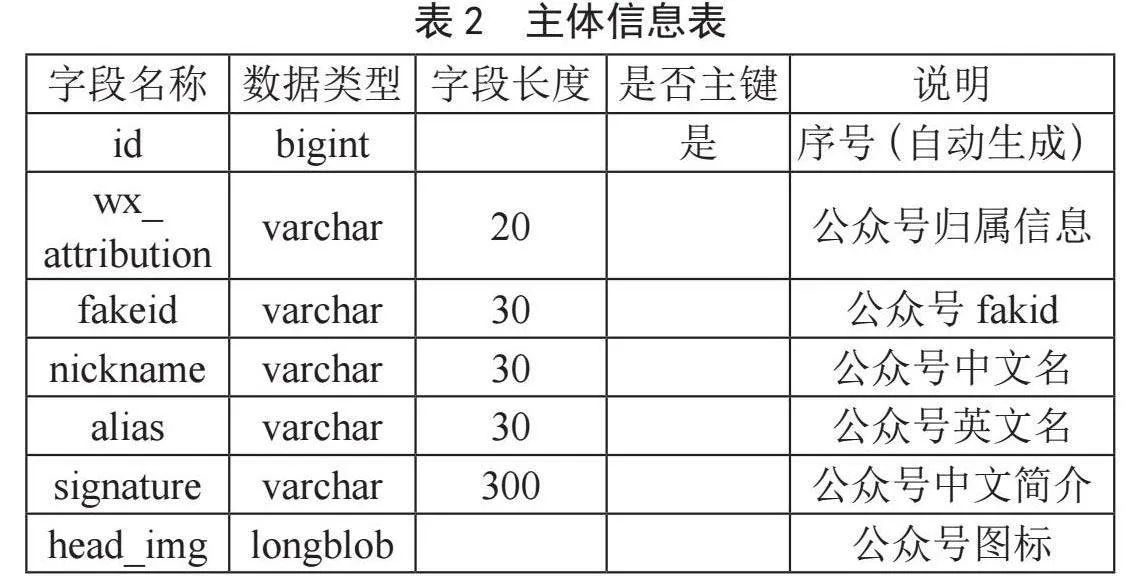
按平台功能需求数据库共设计了三张表,如表1至表3所示,分别用于存储公众号运营主体类别信息、公众号主体信息、公众号所发表文章信息。
2 平台功能实现
2.1 数字资源的采集和处理
首先将收集的微信公众号按运营主体进行分类登记,分两步实现:一是通过表单预先设置运营主体信息并存入数据表中;二是在进行公众号主体信息登记时,通过下拉表单强制要求公众号进行分类登记,如图3所示,以丰富后期爬取资源的标签信息。以上功能通过django的forms(表单类)实现。
核心代码如下:
from django import forms
from .models import *
class wxidform(forms.Form):
nickname=forms.CharFieNb6GeduUBmMRMDMEHnrQrQ==ld(max_length=30,label=请完整填写公众号中文名称)
wx_attribution_choices=forms.ModelChoiceField(queryset=wx_attribution.objects.all().values_list(wx_attribution, flat=True),
label=请选择微信公众号类型, empty_label="请选择" ,)
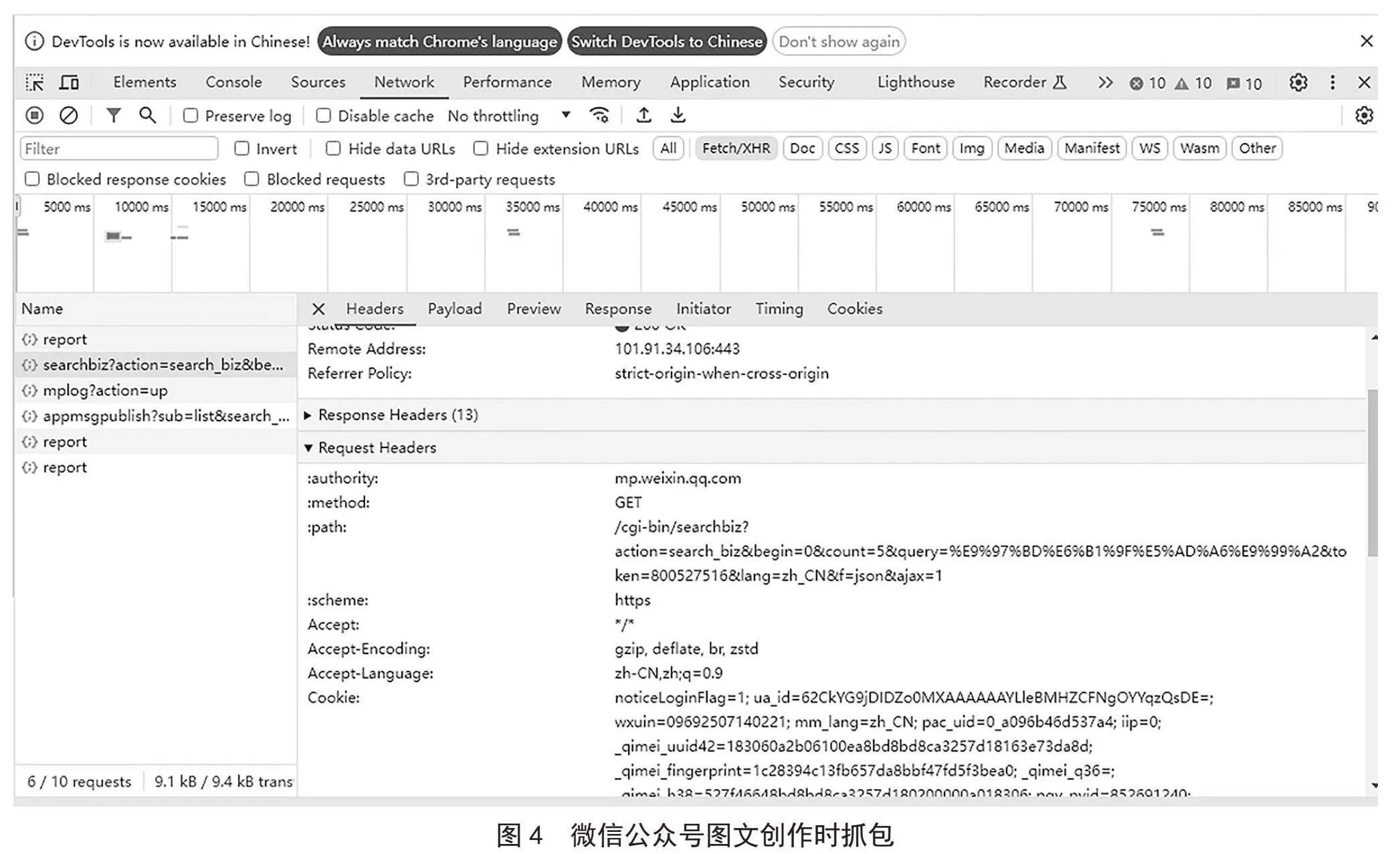
微信公众号没有提供API接口,且如果通过第三方检索的方式爬取资源时,资源的URL不是永久可访问。平台选择通过注册的公众号在创作图文消息时获取各公众号文章长链接的途径来实现,主要利用Chrome中开发者工具抓包获取相关接口信息,最终实现对相关公众号资源的爬取,如图4所示。
爬取分三步实现:
1)利用selenium.webdriver模拟登录微信公众号,获取登录之后的cookies信息[8]。
2)利用cookies爬取微信公众号token、fakeid、nickname等数据。
3)利用已有的token、fakeid、nickname进一步爬取该公众号下的文章元数据。
该模块功能主要通过Django的views实现,核心代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time,json,random,requests,re
from wxarticle.models import *
from django.db.models import Max
from datetime import datetime
from django.utils import timezone
#获取cookies
def wechat_login(account_name,password):
driver=webdriver.Chrome()
driver.get("https://mp.weixin.qq.com/")
time.sleep(2) driver.find_element(By.XPATH,//*[@id="header"]/div[2]/div/div/div[2]/a).click()
driver.find_element(By.NAME,"account").send_keys(account_name)
driver.find_element(By.NAME,"password").send_keys(password)
driver.find_element(By.CLASS_NAME,"frm_checkbox_label").click()
time.sleep(1)
driver.find_element(By.CLASS_NAME,"btn_login").click()
time.sleep(20)
cookie_items=driver.get_cookies()
post={}
for cookie_item in cookie_items:
post[cookie_item[name]]=cookie_item[value]
cookie_str=json.dumps(post)
with open(wxcookie.txt, w+, encoding=utf-8) as f:
f.write(cookie_str)
driver.quit()
#爬取微信公众号token,fakeid,nickname等数据
def wxh_get_fakeid(query):
url=https://mp.weixin.qq.com
header={"HOST": "mp.weixin.qq.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/\
537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/ 537.36",
"Accept - Encoding": "gzip, deflate, br ,utf-8",}
with open(wxcookie.txt, r, encoding=utf-8) as f:
cookie=f.read()
f.close()
cookies=json.loads(cookie)
session=requests.Session()
session.keep_alive=False
time.sleep(1)
response=session.get(url=url, cookies=cookies, verify=False)
token=re.findall(rtoken=(\d+), str(response.url))[0]
time.sleep(1)
search_url=https://mp.weixin.qq.com/cgi-bin/searchbiz
query_params={action: search_biz, token: token, lang: zh_CN, f: json, ajax: 1, query: query, begin: 0, count: 5 }
search_response=session.get(search_url,cookies=cookies,headers=header,params=query_params)
lists=search_response.json()[list][0]
fakeid=lists[fakeid]
nickname=lists[nickname]
alias=lists[alias]
signature=lists[signature]
round_head_img=lists[round_head_img]
return token,fakeid,nickname,alias,signature,round_head_img
#爬取该微信公众号文章信息提取元数据并写入数据表
def wxh_get_content(nickname,fakeid,header,cookies):
appmsg_url=https://mp.weixin.qq.com/cgi-bin/appmsg
session=requests.Session()
session.keep_alive=False
time.sleep(1)
response=session.get(https://mp.weixin.qq.com, cookies=cookies, verify=False)
token=re.findall(rtoken=(\d+), str(response.url))[0]
query_id_data={token: token, lang: zh_CN, f: json, ajax: 1, action: list_ex, begin: 0, count: 5, query: , fakeid: fakeid, type: 9}
appmsg_response=session.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
max_num=appmsg_response.json()[app_msg_cnt]
num=int(int(max_num) / 5)
begin=0
while num + 1 > 0:
query_id_data={token: token, lang: zh_CN, f: json, ajax: 1, action: list_ex, begin: {}.format(str(begin)), count: 5, query: , fakeid: fakeid, type: 9}
query_fakeid_response=session.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
fakeid_list=query_fakeid_response.json()[app_msg_list]
print(fakeid_list)
max_createtime=wx_article_url.objects.filter(nickname=nickname).aggregate(Max(createtime))
for item in fakeid_list:
createtime=item[create_time]
content_createtime=time.strftime(%Y-%m-%d %X, time.localtime(createtime))
datetime_content_createtime=datetime.strptime(content_createtime, "%Y-%m-%d %H:%M:%S")
datetime_content_createtime=timezone.make_aware(datetime_content_createtime, timezone.utc)
if datetime_content_createtime > max_createtime[createtime__max]:
content_title=item[title].encode(utf-8)
content_link=item[link]
content_coverlink=item[cover]
wx_article_url.objects.create(nickname=nickname,createtime=content_createtime,title=content_title,url=content_link)
num -= 1
begin=int(begin)
begin += 5
2.2 数据存储
在数据存储部分,平台使用Django框架里ORM系统来管理数据库操作,确保获取的数据被安全、有效地存储在MySQL 8.0数据库中。Django提供了强大的数据库抽象层,使得开发者可以在不关心底层数据库实现细节的情况下进行高效的数据操作。数据存储功能属于Django的MVT(模型-视图-模板)的M(模型)部分,在Models.py中完成模型定义。接着通过django的管理工具manage.py完成在MySQL 8.0数据库中创建表。另外,在数据抓取部分(即上面的代码),每次获取到新的文章数据时,都会检查这篇文章的创建时间是否晚于数据库中已有数据的最晚创建时间。如果是,就将这篇新文章的数据存储到数据库中。
2.3 数据分析
微信公众号缺乏资源的细粒度标签,无法满足用户多维度的检索需求。随着AI技术的不断发展和成熟,深度学习框架中的自然语言处理技术为我们提供了一种有效的解决方案——文本自动化实体抽取任务。平台选择了百度开源的ERNIE-UIE大模型。它是一个基于知识增强的统一信息抽取框架,不仅结合了百度在深度学习和自然语言处理领域多年的积累,而且具备处理多种类型信息抽取任务的能力。通过引入ERNIE-UIE大模型,平台能够自动化地从微信公众号的海量文本中抽取出各类实体,如人名、地名、机构名等,并为其打上细粒度的标签。这些标签不仅丰富了资源的元数据,还为用户提供了更加精准、多维度的检索条件。核心代码如下:
from bs4 import BeautifulSoup
from paddlenlp import Taskflow
import networkx as nx
import matplotlib.pyplot as plt
def wx_article_analyse(url):
schema_entity=[时间, 人名, 地名, 事件, 组织, 课题, 奖项, 会议]
response=requests.get(url)
html_content=response.text
soup=BeautifulSoup(html_content, html.parser)
text_content=soup.get_text()
# 实体抽取
ie_entity=Taskflow(information_extraction, schema=schema_entity, model=uie-base)
entity=ie_entity(text_content)[0]
# 关系抽取
schema_relation={事件: [时间, 人名, 组织], 课题:[时间, 人名, 组织], 奖项:[时间, 人名, 组织], 会议:[时间, 人名, 组织]}
ie_relation=Taskflow(information_extraction, schema=schema_relation, model=uie-base)
relation=ie_relation(text_content)[0]
return entity,relation
2.4 数据利用
数据利用主要体现如下:
1)通过将与高校相关的微信公众号上的数字文化资源进行统一聚合,并对其进行抽取和分析得到的实体信息数据,构建资源的标签以实现八个维度的资源回溯检索功能,核心代码如下:
from django.http import JsonResponse
from .models import wx_article_url, wx_id
def search_articles_by_dimension(request, dimension, value):
# 根据传入的维度和值进行过滤
articles=wx_article_url.objects.filter(**{fentity_{dimension}__contains: value}).distinct()
# 获取微信公众号归属等信息,需要关联wx_id模型
article_list=[]
for article in articles:
try:
wx_info=wx_id.objects.get(fakeid=article.fakeid)
article_list.append({nickname: wx_info.nickname,
wx_attribution: wx_info.wx_attribution,
title: article.title,
url: article.url,})
except wx_id.DoesNotExist:
continue
return JsonResponse(article_list, safe=False)
数据抽取和分析结果样本见表4。
2)通过分析得到的实体关系信息数据构建知识图谱[9]。核心代码如下:
import networkx as nx
import matplotlib.pyplot as plt
def wx_article_plt(ID,data):
G=nx.DiGraph()
for category, items in data.items():
for item in items:
text=item[text]
start=item[start]
end=item[end]
probability=item[probability]
relations=item.get(relations, {})
G.add_node(text, label=text, start=start, end=end, probability=probability)
for relation_type, relation_items in relations.items():
for relation_item in relation_items:
relation_text=relation_item[text]
G.add_edge(text, relation_text, relation=relation_type)
pos=nx.spring_layout(G)
nx.draw_networkx_nodes(G, pos, node_size=1000, node_color=lightblue)
nx.draw_networkx_edges(G, pos, alpha=0.5)
nx.draw_networkx_labels(G, pos, font_size=16, font_family=sans-serif)
plt.rcParams[font.sans-serif]=[SimHei]
plt.rcParams[axes.unicode_minus]=False
plt.axis(off)
plt.savefig(./pltfig/+str(ID)+ .png)
3)实现对所聚合资源的跨公众号统一检索和图谱展示[10],如图5所示。
3 结 论
平台不但实现了基于微信公众号的高校相关数字文化资源的统一保存,而且突破了微信公众平台上传统的只能根据关键词进行搜索的检索方式,实现从时间、人名、地名、事件、组织、课题、奖项和会议这八个维度回溯检索。用户可以根据自己的需求,选择相应的维度和条件,快速定位到自己感兴趣的资源。除了回溯检索外,平台还利用抽取的实体关系数据,构建了一个知识图谱。通过这个图谱,用户可以发现不同资源之间的关联和联系,促进资源的有效传播和利用。同时,这也为微信公众号带来了更多的互动和活跃度,提升了其整体的用户体验和价值。
参考文献:
[1] 新华网.中共中央办公厅 国务院办公厅印发《关于推进实施国家文化数字化战略的意见》 [EB/OL].(2022-05-22).http://www.news.cn/2022-05/22/c_1128674022.htm.
[2] 马丽丁娜,朱丽丽.数字文化10年研究:技术、日常生活与在地实践 [J].传媒观察,2023(3):80-90.
[3] 任立.数字人文时代文化遗产融入高校德育教育体系探究 [J].黑河学院学报,2024,15(1):173-176+184.
[4] 张玉清,赵江南,赵威.平台、内容与运维:高校共青团微信公众号影响力提升策略的实证探析 [J].东南大学学报:哲学社会科学版,2023,25(S2):72-77.
[5] 田文涛.Python技术在计算机软件中的应用 [J].集成电路应用,2024,41(2):344-346.
[6] 李朝阳,周维贵,张小锋,等.一种麒麟系统下基于Django的网络性能管理系统设计与实现 [J].计算机应用与软件,2024,41(3):130-133.
[7] 飞桨.UIE模型简介 [EB/OL].(2022-11-28)[2024-03-02].https://aistudio.baidu.com/modelsdetail/22?modelId=22.
[8] 朱烨行,赵宝莹,张明杰,等.基于Scrapy框架的微博用户信息采集系统设计与实现 [J].现代信息科技,2023,7(24):41-44+48.
[9] 蔡文乐,秦立静.基于Python爬虫的招聘数据可视化分析 [J].物联网技术,2024,14(1):102-105.
[10] 许梦雅.基于Echarts技术的企业数据可视化的设计与开发 [J].现代信息科技,2022,6(6):90-92+96.
作者简介:林立(1978—),男,汉族,福建福州人,副研究馆员,本科,研究方向:图书馆自动化与数字化。