
摘" 要:为支持智慧校园和数据服务能力的提升,高职院校开始进行大数据平台建设,随着大数据平台业务流程数量的增加,越来越需要高容量计算处理能力,而云计算成为满足此类需求的关键技术,其中云资源调度优化又成了新的亟待解决的问题。根据某高职院校学生综合预警大数据处理流程,提出一种基于BPMN的云资源分配模型并进行优化,开发了相应的仿真模块进行验证,测试了模型的有效性和可行性,最终表明该模型对进一步提升高职院校大数据平台的运行效率具有参考价值。
关键词:大数据平台;BPMN;资源优化;业务流程;云计算
中图分类号:TP301 文献标识码:A 文章编号:2096-4706(2024)21-0114-06
Research on Resource Optimization of Big Data Business Process in Higher Vocational Colleges
PENG Fei
(Yangzhou Polytechnic College, Yangzhou" 225009, China)
Abstract: To support the improvement of smart campus and data service capability, higher vocational colleges begin to carry out the construction of Big Data platform. With the increase in the number of business processes on the Big Data platform, there is an increasing need for high-capacity computing and processing capabilities, and cloud computing has become a key technology to meet such needs. Among them, cloud resource scheduling optimization has become a new and urgent problem to be solved. According to the Big Data processing process of students comprehensive early warning in a higher vocational college, a cloud resource allocation model based on BPMN is proposed and optimized. The corresponding simulation module is developed for verification, and the validity and feasibility of the model are tested. Finally, it shows that the model has reference value for further improving the operation efficiency of Big Data platform in higher vocational colleges.
Keywords: Big Data platform; BPMN; resource optimization; business process; cloud computing
0" 引" 言
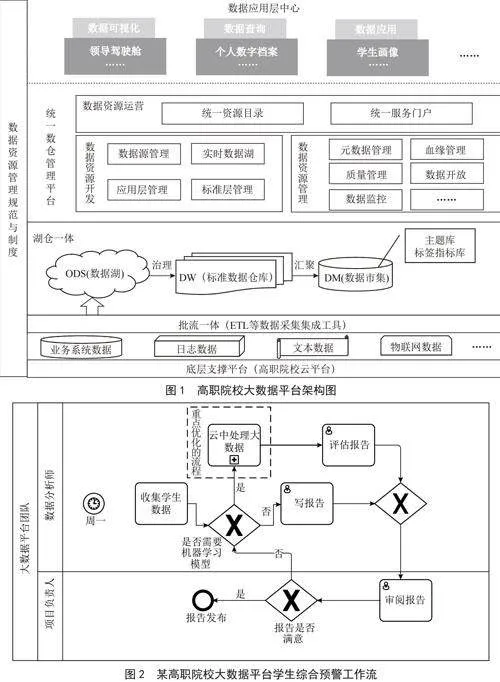
随着信息化水平的不断提升,高职院校积累了大量数据,并逐步建设了大数据平台。大数据平台的建设使得学校能够完成全量数据采集、管理与共享,从而提升了智慧校园的数据服务能力,为学校提供全面、高效、精准的数据支撑,如图1所示。
在技术层面上,大数据平台通常依赖Hadoop、Spark、Flume等工具来处理和驱动(半)自动化流程,即工作流[1]。大数据平台的数据收集和转换过程会需要很多工作流,亟待开发业务流程模型进行系统化管理,此外针对底层支撑平台的大量计算和存储资源的需求是大数据处理过程中的又一个难点。本文以某高职院校大数据平台中学生综合预警为例进行研究,旨在提出一种框架,统一大数据平台的业务流程和资源分配工作,以业务流程建模符号(BPMN)[2]作为业务流程建模标准,对大数据平台业务流程的资源分配进行优化,同时使得学校管理层能够直观掌握业务流程运行时间和成本。
1" 学生综合预警大数据处理流程
某高职院校建设完成学生综合预警大数据平台[3],如图2所示。该平台巧妙地结合了大数据挖掘、人工智能和规则引擎技术,与高校日常业务运作无缝对接,整合了学生在不同系统内的分散数据,并进行了深度分析和统计,以便全方位地展现学生在校的学习、生活状态以及多方面的行为特征。该平台基于复杂的算法模型,提前识别出学生可能存在的风险行为,发出预警,为学院管理者提供精准、及时的决策支持,助力实现对学生群体的精细化、个性化管理。
学生综合预警工作流程与典型的数据科学流程类似,分为数据收集、处理和清理,根据可用数据进行
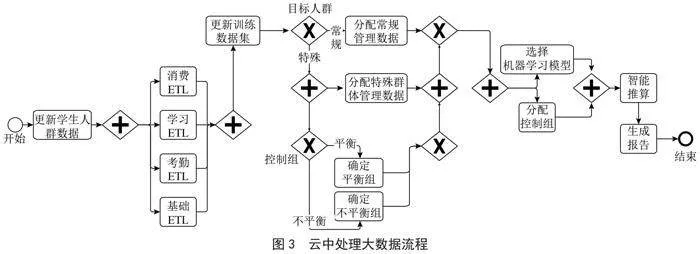
预测,并生成报告以指导相关学生管理方面的业务决策。该流程由学校的大数据平台团队在每周一启动。团队分为数据分析师和项目负责人。数据分析师从各种数据仓库中获取学生消费等相关数据,利用新获得的数据,数据分析师会在云中启动大数据处理,然后对生成的报告进行评估。当新设计的活动最终完成时,项目负责人会批准报告,批准率为80%,随后报告发布。如果报告未获批准时,数据分析师必须重复利用给定数据寻找最优解决方案。本文重点优化云中处理大数据流程(图2虚框内标注的重点优化的流程),由于包含该子流程的路径在大约90%的实例中出现,因此找到执行该子流程的最佳解决方案至关重要。
图3所示的云中处理大数据的工作流程(以下简称工作流程)可分为以下四大类:1)更新大型数据集(训练和人群池);2)寻找合适的目标人群;3)选择并运行机器学习模型[4];4)根据结果生成报告。
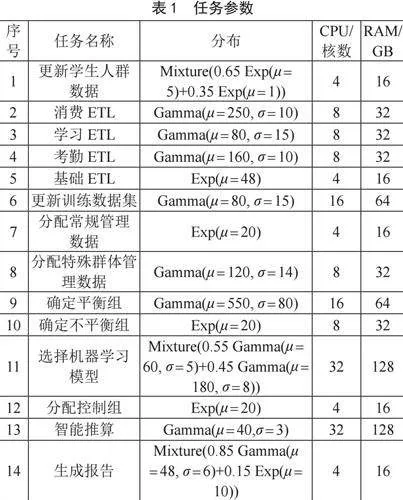
工作流程模型设计为BPMN模型,为每个任务指定了执行时间和计算资源要求,如表1列举了所使用模型中每个任务参数。第一组更新大型数据集为表1中的前六项任务,第二组寻找合适的目标人群为表1中的第7到第10项任务,第三大组为表1中的第11到第13项任务,第四组根据结果创建报告为表1中第14项任务。
第一组任务包括基本的提取、转换和加载(ETL)[5]步骤,准备数据并增加训练数据集的规模。第二组任务是根据预定义的业务规则映射数据集,以进行相关操作,特殊的数据程序会确定不同的测试组和控制组,这些测试组和控制组在十几个关键指标上是没有统计学差异,属于计算密集型任务。还有一些任务具有多模态分布[6],必须为每个基础分布定义额外权重,从而观察多模态任务中每种分布(混合系数)的概率。
此外,工作流程有独占网关(Exclusive gateways)[7],需要为每个分支建立概率模型。表2列出了每个BPMN元素的权重。例如,控制组网关在平衡路径上的权重为30%,在不平衡路径上的权重为70%。
2" 基于BPMN的资源调度框架模型
本文框架模型支持使用与Flowable Modeler[8]兼容的相关软件创建,通过RESTful API进行操作。模型从创建BPMN对象实例开始,通过在RESTful API调用指定BPMN模型文件,为每个任务指定属性(如运行时分布参数)作为key-value属性。在模型对象的初始化过程中,整个BPMN文件都会被解析,其中的所有信息都会被保存以备后用。模型对象初始化成功后,就可以执行有向无环图(DAG)仿真工作流的验证和初始化。
BPMN模型验证和DAG对象初始化,如算法1所示。
Algorithm 1 Validation of BPMN model and initialization of a DAG object
# Input: BPMN model
# Output: Initialized DAG object
# Define variables
1 flows = model.get_flows()" # Get sequence flows in the model
2 pending_tasks = model.get_pending_tasks()" # Get pending tasks
3 processed_tasks = []" # List to track processed tasks
4 # Main loop to process pending tasks
5 while pending_tasks is not empty
6" " new_pending_tasks = []" # Initialize new list for pending tasks
7" " for current_task in pending_tasks
8" " " " if current_task.type == \"Task\"
9" " " " " " process_task_information(current_task)
10" " " " " "processed_tasks.append(current_task)
11" " " "for next_task in flows[current_task]
12" " " " " "if next_task.type == \"Gateway\"
13" " " " " " " "handle_gateway(next_task)
14" " " " " "else
15" " " " " " " "handle_activity(next_task)
16" " " " " "new_pending_tasks.append(next_task)
17" "pending_tasks = 0" # Update pending tasks list
18" "# Refill pending_tasks elements from new_pending_tasks
19" "for new_task in new_pending_tasks
20" " " "if new_task not in processed_tasks" # Validate model to ensure its a DAG
21" " " " " "pending_tasks = new_task
22" " " "else
23" " " " " "raise Exception(\"Model is not a DAG\")
2.1" 初始化变量和迭代处理任务
算法首先定义主要变量(第1~3行)。Flows为模型中序列流程的所有执行逻辑,pending_tasks存储待执行任务,processed_tasks跟踪已经处理过的任务,在算法1里没有加入一些不重要的附加变量。从第5行开始循环迭代处理任务,为了存储当前任务之后的所有项目,第6行每次迭代中都会创建new_pending_tasks。第8行通过process_task_information处理每一个任务,该函数主要获取任务信息,创建所需的分配模式,并存储与任务相关的优化指令,该任务会在第9行被添加到processed_tasks中。
2.2" 处理网关
无论网关的类型是什么,都必须进行特殊逻辑处理。在第13行handle_gateway函数首先检查待处理元素中是否包含网关,以及网关之前的元素是否都已处理过,与该网关相关的顺序流(Sequence Flow)数量进行比较,计算每个next网关出现的次数,从而确保元素顺序与BPMN文件中指定的保持一致。当第一项检查通过时,接下来需要决定网关是否进一步拆分或合并,这一步通过检查网关出口顺序流(Outgoing Sequence Flow)的数量来完成,如果有一个以上的出口顺序流,网关就会被归类为拆分,否则就会被归类为合并。网关作为参数传递给相应处理程序,这些处理程序会找到相关路径,映射分割和合并网关,并管理深嵌套网关。handle_gateway函数结束时会在new_pending_tasks里将网关标记为including。第15行,当next为任务或事件时,handle_activity函数将处理next,根据处理结果,handle_activity函数会检查current_task,并将next分配到正确的网关和路径,最后next会被添加new_pending_tasks中。
2.3" 迭代结束
每次迭代结束时,第17行就会把pending_tasks重新初始化,并从new_pending_tasks中重新填充元素。第20行包含关键的验证,以确保模型是DAG,验证的方法是从new_pending_tasks中检索new_task,并检查new_task是否存在于processed_tasks中,如果验证失败,系统会发出错误信息,指出导致问题的元素,并建议BPMN设计人员更改图表。在成功验证整个模型并收集其元素的所有基本信息后,DAG对象将被初始化,并可进一步优化。
3" 模型优化
为了使学校管理层清楚地掌握工作流程的运行时间和成本[9],模型需要能够创建总周期时间和成本分布,并将其可视化,为了实现这一功能,需要对整体执行时间分布进行分析,为每个任务的执行时间建模,也要处理模型内部深度嵌套网关(即三层或更深),如算法2所示。
算法1在process_task_information收集的任务数据,这些数据存储在tasks_distributions变量中。在算法1第13行的handle_gateway函数中,为每个分割网关在tasks_distributions中添加了占位符。此外,在handle_gateway函数中,还添加了一个path_probability变量,用于存储拆分网关时每条路径的概率,对于独占网关来说,可以在每次执行时根据拆分条件选择不同的可用路径,对于并行网关(Parallel Gateway),也称为AND网关[10]则必须合并所有路径的执行结果。
创建总分布时,如果模型中包含规则的、嵌套的,甚至是深度嵌套的网关,就会出现复杂性。该过程首先创建一个网关列表,按照它们在模型中出现的顺序排列。该列表将传递给算法2中的resolve_complexity函数。
Algorithm 2 Resolve Complexity
# Input: gateway_list
# Output: Complex distributions samples
# Define variables
1" all_paths = []" # List to store all possible paths
2" probabilities = []" # List to store probabilities for each path
3" complex_samples_list = []" #List to store complex distributions samples
4" # Main loop to process each gateway
5" for gateway in gateway_list
6" " " if gateway not in tasks_distributions
7" " " " " return
8" " " # Traverse each path in the gateway
9" " " for key, path in gateway_list[gateway]
10" " " " "single_path = []" # Initialize list for a single path
11" " " " "# Process each element in the path
12" " " " "for element in path
13" " " " " " "if element is Gateway
14" " " " " " " " "distributions = resolve_complexity(gateway_list, element)
15" " " " " " "else if element is Task
16" " " " " " " " "distributions = tasks_distributions [element]
17" " " " " " "del tasks_distributions [element]
18" " " " " " "single_path.append(distributions)
19" " " " "all_paths.append(sum(single_path))
20" " " " "if gateway is XOR_Gateway
21" " " " " " "probabilities.append(path_probability(key))
22" " "# Determine the distribution type based on the type of gateway
23" " "if gateway is XOR_Gateway
24" " " " complex_samples = mix_distributions(all_paths, probabilities)
25" " "else if gateway is AND_Gateway
26" " " " "complex_samples = max_distributions(all_paths)
27" " "complex_samples_list.append(complex_samples)
28 return complex_samples_list
3.1" 初始化变量
算法首先定义主要变量(第1~3行),主要包含了所有可能的分割路径的分布值,以及在独占网关情况下每条路径的概率,在第5行开始遍历流程网关。
3.2" 处理网关路径
算法第9行开始遍历分割网关后的所有路径。必须跟踪每条路径,因此初始化了single_path变量,然后遍历路径上的每个元素,从tasks_distributions变量中获取其分布值,并将其添加到single_path中。第14行是确保每个嵌套网关(无论深度如何)处理的关键步骤。resolve_complexity函数被递归调用于路径上的每个网关元素,并传递当前元素作为网关参数。此外,在第17行中删除tasks_distributions中的每个已处理元素,这个对算法的正常运行至关重要,因为这样可以消除对同一元素进行多次处理的可能性。由于所有元素都在一条路径上进行管理,可以将它们的分布求和,并将其添加到all_paths变量中。在第21行,独占网关每条路径的概率在path_probability函数中收集,并在变量probabilities中存储。
3.3" 处理分布结果
算法第23~26行,在处理完分割网关每条路径后将all_paths填入所需的分布值。在独占网关中,混合分布是根据all_paths和probabilities变量创建的,而并行网关以不同的方式处理时间和成本分布,在管理时间分布时,需要关心执行每条路径所需的最长时间,从all_paths中取最大值。
3.4" 返回模型的总体分布
算法在第28行结束,该行返回第27行经过迭代的complex_samples_list。网关的占位符分布将更新为task_distributions变量中的分布值,由于每个网关都被简化为一个任务,最终得到一个任务序列,将其相加就能得到模型的总体分布。
4" 框架测试
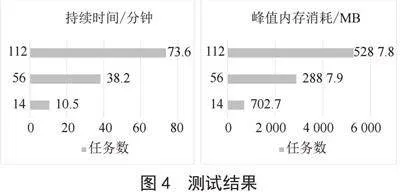
学生综合预警业务流程由14个任务组成,但实际任务数量会更多。因此,框架测试分别创建了包含56个和112个任务的附加模型,测试框架在更多任务模型上的性能,这两个附加型具有表1和表2中指定的相同属性,区别在于分别具有原来4倍和8倍的任务数量。
本次测试初始化DAG对象、优化流程的资源分配,使用标准Python库time和tracemalloc来获取峰值内存消耗。由于tracemalloc会影响执行时间,故分别进行了时间和内存测量,框架测试结果如图4所示。优化小型工作流程需要10.5分钟,中型工作流程需要38.2分钟,大型工作流程需要73.6分钟,其中资源分配是优化过程中的主要瓶颈。在14个任务的工作流中,优化步骤占总持续时间的99.66%,而在56个任务中为99.75%,在112个任务中为99.76%。对于具有112个任务的工作流程,本文框架的执行时间和峰值内存消耗属于可接受范畴。
5" 结" 论
本文提出了一种高职院校大数据工作流系统云计算资源优化框架,通过建立BPMN模型和DAG对象,结合优化算法,实现对工作流的资源分配和可视化。通过测试验证了算法的有效性和性能,结果表明,即使在任务数量较多的情况下,本文框架仍然具有可接受的执行时间和内存消耗。
未来将进一步探索基于大数据技术的资源优化方法,优化算法的效率和性能,提高系统的整体执行效率,还将研究如何应对更加复杂和多样化的工作流场景,提供更加灵活和智能的资源分配方案。随着技术的不断进步和研究的深入,本文将为高职院校大数据业务流程系统的优化和发展提供重要参考。
参考文献:
[1] 刘智慧,张泉灵.大数据技术研究综述 [J].浙江大学学报:工学版,2014,48(6):957-972.
[2] 陈广智,潘嵘,李磊.工作流建模技术综述及其研究趋势 [J].计算机科学,2014,41(S1):11-17+23.
[3] 安洋,李军怀,王怀军,等.基于大数据的学生行为综合分析与服务平台设计与实现 [J].四川职业技术学院学报,2021,31(4):153-157.
[4] 黄立威,江碧涛,吕守业,等.基于深度学习的推荐系统研究综述 [J].计算机学报,2018,41(7):1619-1647.
[5] 于起超,韩旭,马丹璇,等.流式大数据数据清洗系统设计与实现 [J].计算机时代,2021(9):1-5.
[6] 刘建伟,丁熙浩,罗雄麟.多模态深度学习综述 [J].计算机应用研究,2020,37(6):1601-1614.
[7] 赵莹,赵川,黄苾,等.BPMN2.0过程模型的语义和分析 [J].计算机科学,2018,45(S2):558-563.
[8] 徐进东.大数据工作流系统的关键技术研究与实现 [D].北京:北方工业大学,2023.
[9] 杜清华,张凯.一种高效的跨平台工作流优化方法 [J].计算机工程,2022,48(7):13-21+28.
[10] 代飞,赵文卓,杨云,等.BPMN 2.0编排的形式语义和分析 [J].软件学报,2018,29(4):1094-1114.
作者简介:彭飞(1982—),男,汉族,江苏徐州人,高级工程师,硕士,研究方向:教育信息化。
基金项目:江苏省现代教育技术研究2021年度智慧校园专项课题(2021-R-96762)