



摘" 要:针对现有双流卷积神经网络由于运动中人体移动速度快,无法快速、准确地识别人体信息的问题,提出了一种基于FlowNet2.0网络改进的人体识别检测方法,通过给FlowNet2.0网络的各视频帧输入通道引入自注意力,能够有效增强网络对外观信息和姿态特征的提取能力,从而更好地描述运动目标。最终该模型在HDBM51数据集上进行训练,实验结果表明,改进后的FlowNet2.0网络取得了显著的改进效果。此研究为解决动作时的人体识别问题提供了一种有效的解决方案。
关键词:双流卷积神经网络;视频理解;运动目标;多注意力网络
中图分类号:TP181" " 文献标识码:A" " 文章编号:2096-4706(2024)21-0078-05
Research on Improved Moving Human Body Recognition Based on FlowNet2.0
SHEN Yingjie, FU Jianglong, WANG Jianxiong, WEI Shilei, Ren Yishuai
(Hebei University of Architecture, Zhangjiakou" 075000, China)
Abstract: Aiming at the problem that the existing Two-Stream Convolutional Neural Networks cannot quickly and accurately identify human body information because the human body moves fast in motion, an improved human recognition detection method based on FlowNet2.0 network is proposed, which can effectively enhance the networks ability to extract appearance information and posture features by introducing Self-Attention into the input channels of each video frame of FlowNet2.0 network, so as to better describe moving targets. Finally, the model is trained on the HDBM51 dataset, and the experimental results show that the improved FlowNet2.0 network has achieved significant improvement results. This study provides an effective solution to solve the problems of human recognition during action.
Keywords: Two-Stream Convolutional Neural Networks; video understanding; moving target; Multi-Attention Networks
0" 引" 言
在人体运动条件下,快速准确地检测和识别运动人体信息是计算机视觉领域中的一个重要研究方向[1]。运动人体识别在许多领域得到了广泛应用[2]。然而,由于动态背景、遮挡、姿势变化和光照等多种复杂因素的存在,对运动人体的准确检测和跟踪仍然具有挑战性。近年来,基于深度神经网络的目标检测算法在运动人体识别中崭露头角,其中FlowNet2.0网络在准确检测运动人体方面取得了卓越的成果。该技术主要应用在运动员辅助训练方面,在训练过程中通过捕捉运动员运动过程中动作的变化,来对运动员的动作进行标准判定,但是目前在动态背景多变的情况下,检测速度和识别精度还可以提高[3]。以上背景说明了运动人体检测和识别在体育行业中的重要地位和广阔的发展前景[4]。
1" FlowNet2.0相关研究
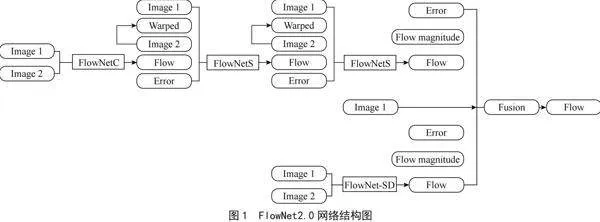
FlowNet2.0是一种端到端的光流估计学习的神经网络结构,该网络结构总体上是一种Encoder/Decoder的编/解码器结构。首先输入视频序列帧的第t帧及第t+1帧的两张图像;接着通过由卷积层组成的收缩部分网络结构,用以提取各自的特征图;再通过扩大层网络结构,深度提取相邻帧的特征;最终实现光流预测[5]。本文采用的是FlowNet2.0网络,其可分为FlowNet2.0-C网络、FlowNet2.0-S网络,如图1所示。
1.1" FlowNet2.0-S网络
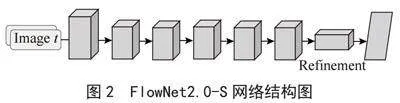
FlowNet2.0-S网络采用直接且高效的方法处理输入图像:将连续的第t帧和第t+n帧在通道维度上进行堆叠(拼接);随后,网络通过一系列卷积层下采样以提取特征,自主学习如何从成对的图像中识别运动信息。此网络结构以其简洁而强大的特性,为光流预测提供了一种直观的解决方案,如图2所示。
1.2" "FlowNet2.0-C网络
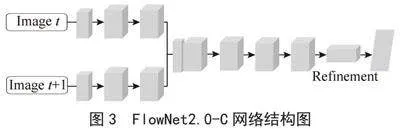
与FlowNet2.0-S相比,FlowNet2.0-C网络采用了更精细的处理机制,如图3所示。它使用两个独立的处理流水线,分别处理每一帧输入图像,通过卷积层独立提取重要特征,并在网络深层融合这些特征,进行下采样和光流预测。通过这种方法,FlowNet2.0-C在光流估计的准确性和可靠性方面实现了显著提升。
在FlowNet2.0-C网络通过引入关联层(correlation layer),提升了光流预测的准确性和处理效率。关联层通过分析并匹配图像序列中的特征,能够精确识别图像间的相对移动。这种先进的特征融合方法不仅增强了网络的运动信息捕捉能力,还使网络能快速处理复杂的视觉场景,显著提高了大规模数据处理的性能。FlowNet2.0-C的这一创新设计在光流估计领域展示了深度学习在视频理解和处理中的应用潜力。
2" FlowNet2.0网络改进
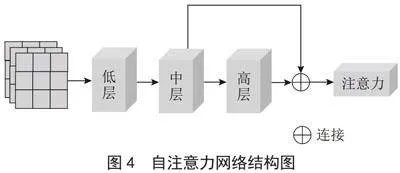
在运动过程中,对于迅速变化的人体姿态和形状,及时捕捉存在一定难度,为了应对这一挑战,我们在FlowNet2.0网络中引入了自注意力机制,如图4所示。
为了进一步提取人体运动的变化趋势,并理解时序与动作之间的细微联系,本研究引入了一种高级的自注意力机制[6]。这种机制特别设计用于整合视频序列中的中层和高层特征,使得模型能够对不同时间点上的信息赋予适当的权重。通过这种方法,模型在分析输入序列时能够更加灵活地调整其注意力,确保在每一个时间步骤上都能同时关注到多个重要位置,从而捕获序列中的局部细节与全局上下文信息。
传统的视频处理模型,如固定窗口技术和递归神经网络(RNN),在处理视频中长期依赖的问题上常常遇到困难。这些模型通常受限于其结构,只能捕获有限的时间范围内的信息,难以捕捉视频序列中的长距离动作关系。相比之下,自注意力机制通过在每个时间点计算不同位置间的动态注意力得分,极大地提高了模型处理长期依赖问题的能力。它允许模型不受任何预设距离的限制,自由地在整个序列中移动关注点,这样模型就能够在更广阔的范围内探索信息,有效捕捉长距离间的动作相关性[7]。
更进一步,自注意力机制为视频分析带来了前所未有的灵活性和深度。它不仅使得模型能够理解各个时间点上动作的细节,还能够洞察整个动作序列的结构和流程,从而深入解析动作的发展脉络。这一点在处理复杂的人体运动时尤为重要,因为这些动作往往涉及快速变化的姿态和相互作用,需要模型具备高度的敏感性和分析能力。通过对自注意力机制的引入和应用[8],本研究不仅显著提高了人体运动识别的准确性,还为深度学习模型在视频理解方面开辟了新的道路。
下面是自注意力机制的公式:我们对输入序列的每个元素进行线性变化,得到相应的Query(Q)、Key(K)、Value(V)表示。这些线性变换通过权重矩阵Wq、Wk、Wv完成。
Qi=Wq·Xi
Ki=Wk·Xi (1)
Vi=Wv·Xi
这一步计算了Query和Key之间的注意力分数,其中是Query和Key的维度。注意力分数表示了元素与序列中其他元素的关联程度。
(2)
最终的输出表示是通过对Value(V)进行加权求和得到的,权重由注意力分数确定。这样,模型在处理每个元素时,会关注整个序列中其他元素的信息,从而更好地捕捉序列中的重要特征。
(3)
3" 实验与数据分析
3.1" 数据集概述
本研究采用开源数据集HMDB51进行人体行为检测。该数据集涵盖51种动作类别,总计6 849个视频,每类动作至少包括101个视频实例。这些视频主要来源于YouTube和Google视频,其中数据集中的训练集和验证集比例为8∶2。
3.2" 数据集预处理
调整视频分辨率:所有视频调整到统一的分辨率,例如320×240像素,以减少模型处理的计算量。
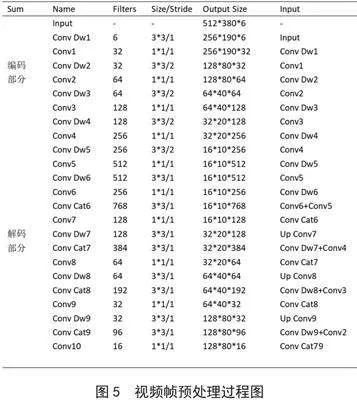
帧提取和采样:从每个视频中以固定的时间间隔进行采样,提取固定数量的帧以获得时间上的连续性和减少训练时间,视频帧预处理过程如图5所示。
3.3" 网络结构
在本研究中,所采用的注意力机制基于自注意力(Self-Attention)模型,它可以自适应地学习特征图中每个位置的重要性。自注意力模块计算特征图上所有位置之间的响应,通过这种方式使网络能够捕捉长距离的依赖关系[9]。
自注意力模块的实现可以表述为一个变换函数F,它将输入特征图X映射为加权特征图Y:
Y=F(X ) (4)
其中,F通常由一系列卷积层和非线性激活函数构成。
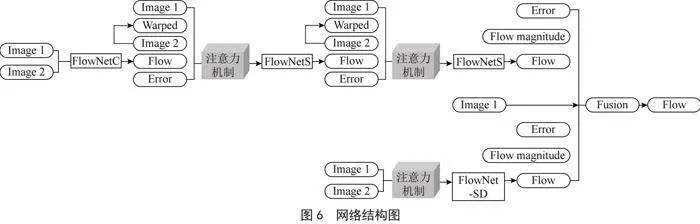
注意力模块被集成到FlowNet2.0的编码器部分,如图6所示,具体地,它被置于每个编码层之后,从而允许在不同尺度上提取特征时,自注意力模块可以独立地调整每个位置的特征响应。这一设计使得网络在进行光流估计时,能更加聚焦于与人体运动相关的特征。
集成了自注意力机制的FlowNet2.0在训练过程中采用端到端的方式[10]。注意力模块的参数是通过反向传播算法和整个网络一同优化的,损失函数同样为光流预测的误差量度。我们使用一个新的超参数R来平衡光流损失和注意力模块的正则化损失:
L = Lflow+R×Lattention (5)
其中,Lattention表示注意力模块的损失项,设计为度量注意力加权特征图与真实人体运动区域之间的一致性。
3.4" 特征提取与增强
在FlowNet2.0网络中引入自注意力机制,允许模型自动关注于视频帧中重要的动作特征,提高对动作细节的识别能力。
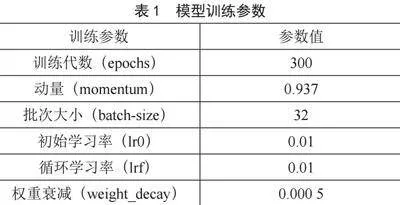
3.5" 训练参数设置
模型训练参数如表1所示。
3.6" 实验结果与分析
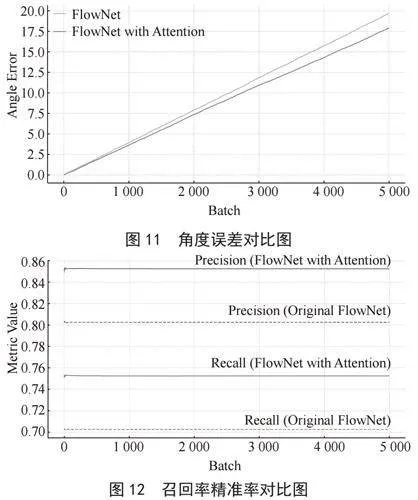
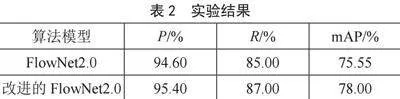
本研究采用准确率(Precision)、召回率(Recall)和平均精度均值(mean Average Precision, mAP)作为评估指标。准确率(P)定义为模型预测正确的对象占预测总数的比例;召回率(R)是指模型正确预测的对象占实际对象总数的比例;mAP则表示所有类别准确率的平均值。为验证改进方法的有效性,本研究在公开数据集上进行了对比实验[11]。如表2所示,通过改变损失函数,模型的网络精度得到提高,在mAP上增加了2.45%。
此外,本文将改进后的FlowNet2.0方法与算法模型(SSD、Faster R-CNN、YOLOv3)进行对比,结果如表3所示,相较于SSD、Faster R-CNN、YOLOv3,本文改进方法的mAP均有明显提升,提升值均为3.71%、2.72%、4.1%。综上所述,本文改进的YOLOv5算法对运动足球识别的综合性能良好。
图7、图8分别是改进前后的实验识别检测图,从图中可以看出在高速运动情况下可以准确地去检测出人体部位的轮廓信息。图8改进后的检测结果比图7改进前的检测结果,检测手掌的效果更准确,检测参数有所提高。图7改进前的检测结果中手掌边缘检测不准确,而图8改进后的检测结果可以检测到,有效地减少了轮廓不准确的问题。实验表明,改进FlowNet2.0网络对人体信息有更好的识别效果,在保证精确率的同时,还降低了漏检率,提高了模型的性能。
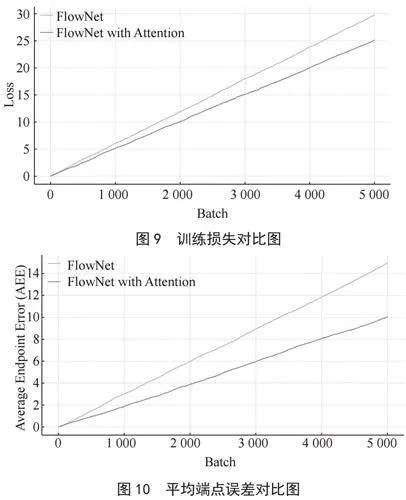
图9至图12是实验前后的评估标准对比图。
4" 结" 论
本研究成功地在FlowNet2.0网络模型中引入了自注意力机制,旨在解决传统双流卷积神经网络在动态环境下识别运动人体时面临的挑战。通过精心设计的实验,我们不仅验证了改进模型在处理快速移动的人体目标时准确率和速度的显著提升,而且还探索了其在工业生产自动化中的潜在应用价值。尤其在质量控制和生产监控的应用场景中,改进的FlowNet2.0模型展现出对高速运动零件和工件的高效识别与追踪能力,这对于提高生产效率和保障产品质量具有重要意义。
进一步地,本研究的成果不仅为动态人体识别技术的发展提供了新的思路,同时也为深度学习在视频理解和处理领域的应用拓展了视野。特别是在自动化技术不断进步的今天,我们相信,通过进一步优化和定制,改进后的FlowNet2.0模型能够在更广泛的应用场景中,如智能监控、交互式媒体、虚拟现实等领域,发挥其独特的价值。
参考文献:
[1] 姬江涛,刘启航,高荣华,等.基于改进FlowNet2.0光流算法的奶牛反刍行为分析方法 [J].农业机械学报,2023,54(1):235-242.
[2] 周泳,陶兆胜,阮孟丽,等.基于FlowNet2.0网络的目标光流检测方法 [J].龙岩学院学报,2020,38(2):37-42.
[3] GREYVENSTEIN G P,ROUSSEAU P G. Design of a Physical Model of the PBMR with the Aid of FlowNet [J].Nuclear Engineering and Design,2003,222(2):203-213.
[4] 徐涛,李夏华,刘才华.基于生成对抗网络动态建模的人群密度预测方法 [J].计算机工程与设计,2023,44(10):3070-3075.
[5] 袁启营,费树岷.基于FlowNet2.0和LIBLINEAR的IDT行为识别研究 [J].工业控制计算机,2020,33(4):46-48.
[6] XIE X M,ZHANG S,WU J J,et al. A Real-Time Rock-Paper-Scissor Hand Gesture Recognition System Based on FlowNet and Event Camera [C]//2019 Pattern Recognition and Computer Vision(PRCV).Xian:Springer,2019:98-109.
[7] WANG Z R,LI S D,HOWARD-JENKINS H,et al. FlowNet3D++: Geometric Losses for Deep Scene Flow Estimation [C]//2020 IEEE Winter Conference on Applications of Computer Vision(WACV).Snowmass:IEEE,2020:91-98.
[8] CHEN M-Y,WANG C-L,LIU H-J. Salient FlowNet and Decoupled LSTM Network for Robust Visual Odometry [C]//2019 IEEE International Conference on Robotics and Biomimetics(ROBIO).Dali:IEEE,2019:2699-2706.
[9] YU G L,TAN S-K. Estimation of Boundary Shear Stress Distribution in Open Channels Using FlowNet [J].Journal of Hydraulic Research,2007,45(4):486-496.
[10] QIAN H J,HUANG Z Y,WANG J,et al. Friction Measurement of Aircraft Wing Based on Optimized FlowNet2.0 [J].Chinese Journal of Aeronautics,2023,36(11):91-101.
[11] LIU X Y,QI C R,GUIBAS L J. FlowNet3D: Learning Scene Flow in 3D Point Clouds [C]//2019 IEEE/CVP Conference on Computer Vision and Pattern Recognition(CVPR).Long Beach:IEEE,2019:529-537.
作者简介:沈英杰(1999—),男,汉族,河北衡水人,硕士在读,研究方向:人工智能;通信作者:付江龙(1988—),男,汉族,河北张家口人,讲师,硕士,研究方向:人工智能和大数据分析。
基金项目:河北省体育科技研究课题资助项目(2024QT01);河北省研究生创新资助项目(XY2024038,XY2023080)