


摘" 要:安全帽佩戴对于电厂施工人员的安全至关重要,但在复杂的电厂环境中施工人员难免会出现掉帽的情况。为了判断施工人员是否佩戴安全帽,文章提出了一种基于YOLOv8电厂场景的安全帽检测识别方法。针对开源安全帽数据集在电厂场景样本数量不足的问题,采集、清洗并标注电厂场景数据,重新构建安全帽数据集。基于ultralytics框架,采用YOLOv8 Nano神经网络模型对数据集进行训练,得到FPS为91.7,AP50为93.5%的网络模型。实验结果表明:该方法有效和快速检测施工人员是否佩戴安全帽,具备较好的应用效果。
关键词:安全帽检测;安全帽识别;电厂施工场景;深度学习;YOLOv8
中图分类号:TP391.4" " 文献标识码:A" " " 文章编号:2096-4706(2024)22-0051-05
Detection and Recognition Method of Safety Helmet Wearing in Power Plant Scene Based on YOLOv8 Algorithm
Abstract: Safety helmet wearing is crucial to the safety of power plant construction personnel, but the construction personnel inevitably fall off the helmet in the complex power plant environment. In order to judge whether the construction personnel wear safety helmets, this paper proposes a safety helmet detection and recognition method based on the YOLOv8 power plant scene. Aiming at the problem of insufficient number of samples in the power plant scene of the open source safety helmet data set, the power plant scene data is collected, cleaned and labeled, and the safety helmet data set is reconstructed. Based on the ultralytics framework, the YOLOv8 Nano neural network model is used to train the data set, and a network model with FPS of 91.7 and AP50 of 93.5% is obtained. The experimental results show that this method can effectively and quickly detect whether the construction personnel wear the safety helmet, and has a good application effect.
Keywords: safety helmet detection; safety helmet recognition; power plant construction scene; Deep Learning; YOLOv8
0" 引" 言
一直以来,安全是施工生产行业的重中之重,其中施工人员的个人安全防护措施尤为重要[1]。从建筑施工事故原因调查结果来看,大多数事故原因均是施工过程不够规范导致的[2],而安全帽则是保障施工人员安全的基础设备。尽管电厂管理明确规定,任何人进入电厂必须佩戴安全帽,但在复杂的电厂环境中难免会出现掉帽或者佩戴不当的情况,存在很大的安全隐患。为了确保电厂施工人员正确佩戴安全帽,通常是通过人工检查,但这种方式效率低下且易出错。
传统的安全帽识别方法主要通过图像的边缘特征、颜色特征、SIFT特征、HOG特征等对安全帽目标进行识别。冯国臣等[3]致力于运用机器视觉技术进行安全自动检测的研究工作。Vanbang等[4]则通过提取HOG特征来识别人体,再利用颜色直方图技术来区分安全帽。刘晓慧等[5]则通过分析安全帽与头发颜色的差异来判断工人是否正确佩戴安全帽。尽管这些传统目标检测方法通过手工设计特征来执行检测任务,但它们通常效率较低,并且伴随着模型复杂性和检测精度不足的问题。
针对传统方法对安全帽识别性能较低的问题,深度学习逐渐成为安全帽检测识别的主流算法。吴冬梅等[6]在Faster R-CNN[7]的基础上,改进安全帽目标特征融合的方式,大大降低了模型对安全帽的误检和漏检率。张明媛等[8]针对现有的安全帽佩戴检测技术,开发了一种利用TensorFlow平台的Faster R-CNN模型,该模型以高准确度和快速响应为特点,专门设计用于实时监控工人是否按要求佩戴安全帽。在2018年,Fang等[9]在Faster R-CNN模型的基础上,提出了一种名为Non-Hardhat-Use(NHU)的自动安全帽检测算法,从多个建筑工地的远程监控视频中随机选取了超过10万个建筑工人的图像帧,被分类后输入Faster R-CNN模型中进行训练。尽管这种方法达到了较高的准确度和速度,但它并没有在原始的目标检测算法上做出针对安全帽佩戴检测的进一步优化,因此在实际应用于建筑工地的安全帽佩戴实时监控时仍存在局限。Fu等[10]提出Faster R-CNN+ZFNet的组合应用在安全帽检测中,检测速度达到27FPS。随着YOLO[11]系列目标检测算法的不断发展,研究人员开始将YOLO算法应用到安全帽目标检测中。徐传运等[12]基于YOLOv4算法,采用数据增广进行改进,增强了检测模型对小目标物体的检测能力。侯公羽等[13]基于YOLOv5采用Ghost卷积修改骨干网络,降低模型的复杂度。赵睿[14]采用DenseBlock模块改进 YOLOv5s 模型,提升对小目标的检测性能。但是在实际电厂场景应用中,上述的方法在安全帽识别准确率和推理速度仍存在不足。
本文重点研究基于YOLOv8的目标识别算法,并将其应用于安全帽识别任务中。在实际应用背景下,采集了40天的电厂场景数据,并对其进行数据清洗和数据标注。在模型训练时,为提高模型的泛化能力,采用电厂实际场景数据和公开安全帽检测数据集进行训练,训练出安全帽识别率高、推理速度快的网络模型,满足电厂实际生产需求。
1" YOLOv8检测算法
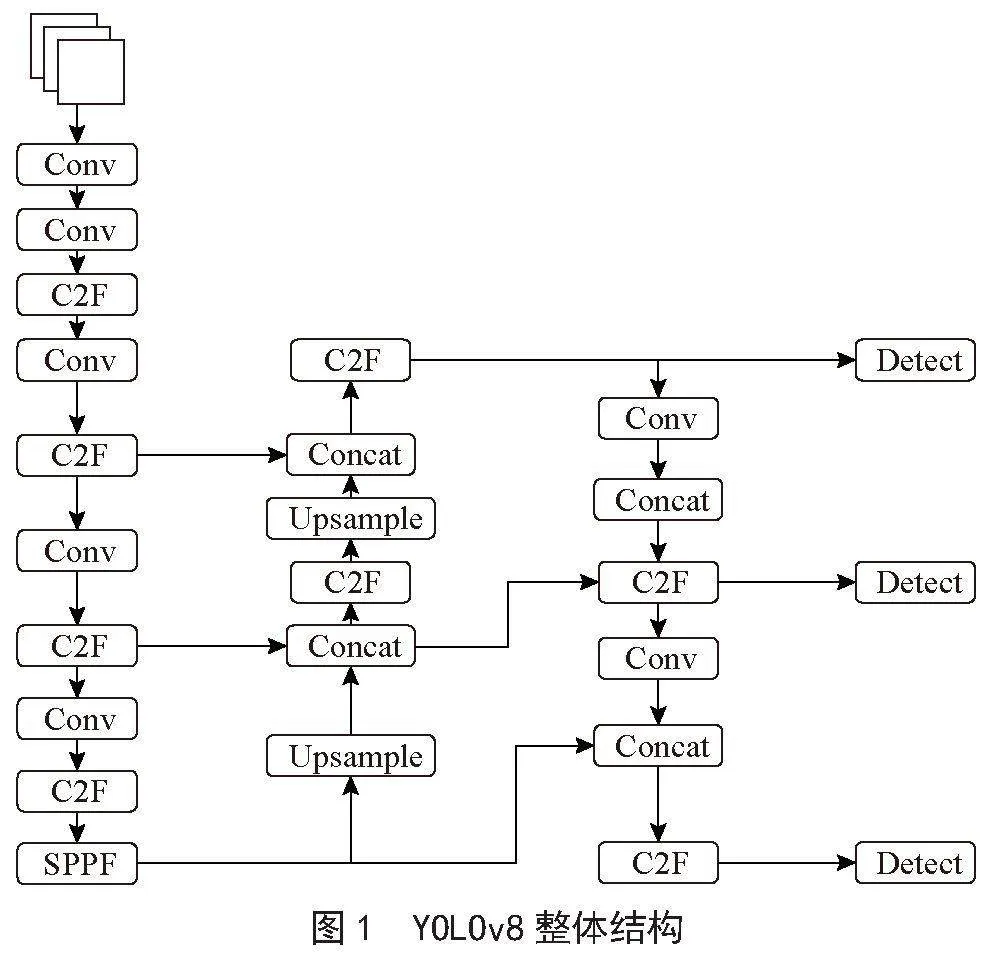
在深度学习领域,目标检测技术一直是计算机视觉任务中的热点和难点。YOLO(You Only Look Once)系列模型以其快速准确的检测性能而闻名,自2015年首次推出以来,已经发展了多个版本。YOLOv8作为该系列的最新升级版本,不仅继承了前代模型的优势,还引入了一系列创新技术,使其在目标检测识别、图像分类和分割等应用中表现出色。YOLOv8的整体结构如图1所示。YOLOv8架构由多个组件组成,按照网络架构可以分为输入端(Input)、 骨干网络(Backbone)、颈部层(Neck)和预测层(Prediction)4个部分。
输入端采用了mosaic数据增强技术,通过自动裁剪和拼接图像,显著增强了模型对不同图像布局和结构的适应能力。此外,输入端还引入了自适应锚框机制,该机制能够根据图像内容动态调整锚框的大小和比例,确保锚框与目标对象的形状和尺寸更加匹配。这不仅提高了目标检测的准确性,也为模型提供了更好的泛化能力。另外,图像色调变化技术的应用,通过调整亮度、对比度、饱和度等,为模型提供了更多样化的输入图像,增强了模型对不同光照和色彩条件下图像的鲁棒性。
主干网络基于CSPDarknet设计,由CBS(常规卷积层)、C2f单元和SPPF(空间金字塔池化)三个核心组件构成,目的是从输入图像中提取特征并增强这些特征的表达力。C2f单元是YOLOv5中C3单元的升级版,它致力于提升网络在特征整合方面的性能,同时加快推理过程,并对网络结构进行精简。SPPF单元作为空间金字塔池化的一部分,通过扩展感受野,实现局部与全局特征的整合,从而更有效地捕获空间信息。
颈部层的设计采用了PAN-FPN结构,使得网络能够更好地检测到不同大小的对象。颈部层通过自顶向下(Feature Attention Network, FAN)和自底向上(Pyramid Attention Network, PAN)的双重特征传递机制,有效地整合了不同层级特征图的特征信息。自顶向下的路径强调了高层语义信息的传递,而自底向上的路径则强化了低层空间细节的保留。这种双向信息流的融合,使得模型在特征提取时能够同时考虑到目标的全局上下文和局部细节。通过PAN-FPN结构,模型能够实现跨尺度的特征融合,增强了对目标的多尺度表征能力。
预测层是YOLOv8实现目标检测的关键部分。该层采用了一个解耦检测头,将输入的不同尺寸特征层分成两个分支进行检测。第一个分支负责预测对象的类别,使用BCE(Binary Cross Entropy)Loss作为分类损失;第二个分支则负责预测对象的位置和大小,采用DFL(Distribution Focal Loss)Loss和CIoU(Complete Intersection over Union)Loss作为回归损失。这种设计改变了以往基于锚框(Anchor-Based)的方法,采用了无锚框(Anchor-Free)的思想,使模型在预测目标的位置和尺寸时更具自适应性,减少了对先验信息的依赖,从而提高了目标检测的鲁棒性。
2" 实验设计
2.1" 数据集
在电力行业,安全帽的佩戴是确保工作人员安全的重要措施。然而,针对电厂场景下的安全帽检测,目前尚未有公开可用的数据集,这对相关研究构成了一定的挑战。因而论文中数据集的构成是两部分:一是现有开源的安全帽数据集SafetyHelmetWearing-Dataset[15-16],该数据集共有7 581张图片;二是通过实地拍摄,获得了大量反映电厂实际情况的图像,筛选有效电厂场景的图片,使用LabelImg工具进行标注,并标注成VOC(Pascal Visual Object Classes)格式,标注成两类,没戴安全帽(no hat)和戴了安全帽(hat)。两部分数据组合并转换成YOLOv8的数据集训练格式,训练集为9 113张图片,验证集为3 905张图片,部分数据如图2所示。
2.2" 网络参数设置
论文中安全帽检测模型训练与测试均在Ubuntu16.04环境下,所使用显卡为1张NVIDIA Tesla V100显卡,CUDA版本为10.0,CUDNN版本为7.3.1,采用Python3.8和Pytorch 1.12.1框架进行训练。YOLOv8模型在ultralytics为8.1.45的库中进行训练,为在电厂场景下快速检测施工人员是否佩戴安全帽,采用YOLOv8 Nano的模型结构。网络训练参数如下:图片输入尺寸为640×640,总训练epoch为215。训练时的batch size为64。采用Stochastic Gradient Descent (SGD)优化器进行优化,动量设置为0.937。初始学习率设置为0.01,学习率衰减权重为0.000 5,并采用余弦退火学习率衰减自动调整学习率。
2.3" 实验衡量指标
精确率(Precision)是分类正确的数量占总分类数量的比值;召回率(Recall)是分类正确的数量占总样本的比例;平均精确度(Average Precision, AP)是对精确率—召回率曲线(PR曲线)上的 Precision值求均值,平均精确率 mAP 是对所有类别计算出的 AP 值求平均值,AP50表示IoU=0.5时 mAP 的值。精确率(P)、召回率(R)以及AP50能有效反映模型的检测效果,因此在测试过程中,采用精确率(P)、召回率(R)以及AP50作为衡量模型精度的指标。
模型推理速度也是衡量模型性能的另一重要指标,在实际的电网生产环境中,模型推理时间越短,对安全帽的检测速度越快。因此在文中,采用500张1 920×1 080的图像,计算模型平均的推理时间,同时计算每秒模型推理图像数量FPS(Frames per second),将这两数据作为衡量模型速度的指标。
3" 实验结果与分析
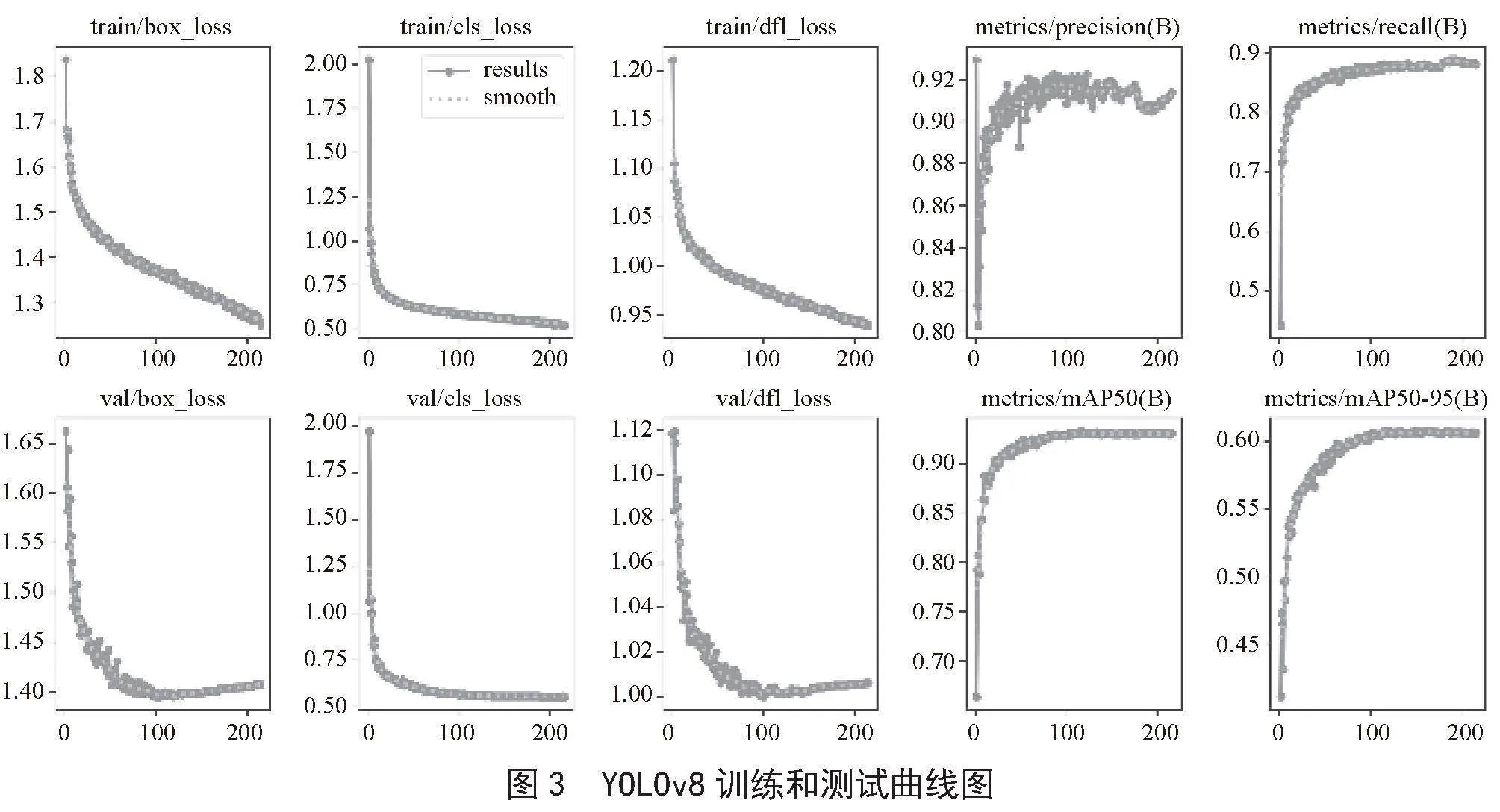
根据网络参数配置,本文对制作的安全帽场景数据集进行模型训练和测试。图3为在不同指标,包括验证集、训练集的置信度损失、边界框损失及类别损失曲线、准确率、召回率、AP50、AP50-95的收敛曲线,横坐标表示迭代次数。
由图3的YOLOv8 Nano训练和测试曲线可知,模型的各项损失值较低。由准确率、召回率、AP50和AP50-95四个性能度量指标曲线可知,YOLOv8 Nano模型各项指标均能较快地进行收敛,并且模型在训练过程中没有出现过拟合和欠拟合的现象,模型整体的训练效果良好。
3.1" 图像增强实验
为了优化安全帽检测的训练模型,本文设计了关于图像增强方法对比的实验,主要包括图像混合增强(MixUp)、图像剪切合并(CutMix)、马赛克数据增强(Mosaic)和类标签平滑(Class label smoothing)。相关的实验结果如表1所示。
由表1结果可知,仅使用MixUp和CutMix的图像增强时,模型的AP50仅为89.9%;仅使用CutMix和Label smoothing的图像增强时,模型的AP50仅为89.7%;使用了Mosaic图像增强的模型2、模型4,对安全帽的检测指标精准率均大于90%,AP50达到92.5%以上。Mosaic图像增强方式对于安全帽检测模型的效果均有明显的提升。综合模型1到模型4的检测精度,该四种图像增强方式对于电网场景的安全帽检测效果有一定的提升,提高了模型的精度。因此对于本文模型,采用了四种的图像增强方式,在精准率、召回率和AP50上均得到最好的结果,相较于模型3,精准率提升2.8%,召回率提升5.7%,AP50提升3.8%,有效提高了电网安全帽检测的性能。
3.2" 消融实验
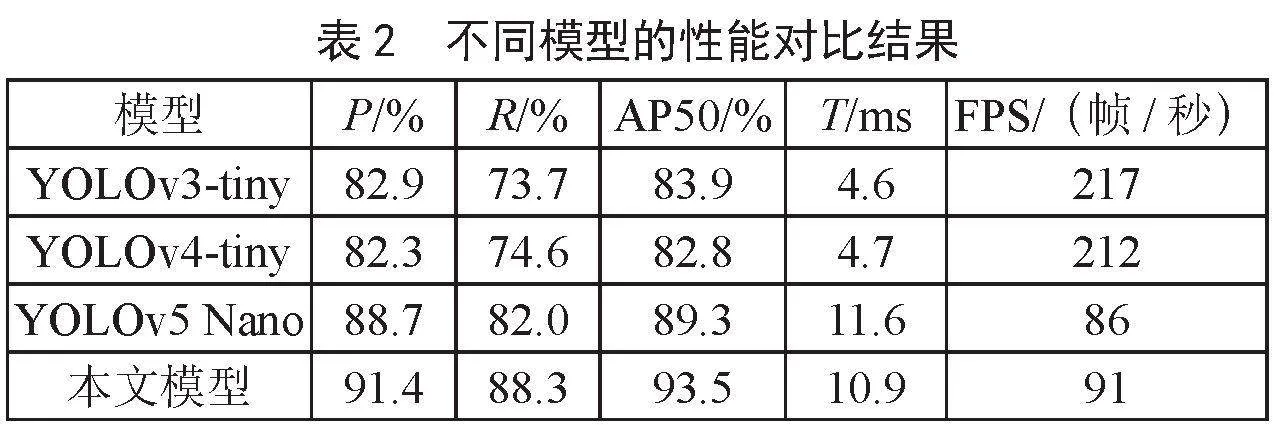
为了进一步验证本文模型的有效性,采用相同的安全帽训练集和测试集进行训练验证,对比了YOLOv3-tiny、YOLOv4-tiny、YOLOv5 Nano和本文模型,YOLOv3-tiny、YOLOv4-tiny、YOLOv5 Nano模型在训练时均采用默认训练参数,实验结果如表2所示。
由表2可知,本文模型的AP50达到93.5%,相比于YOLOv3-tiny、YOLOv4-tiny以及YOLOv5 Nano模型,分别提高了9.6%、10.7%和4.2%,模型精准率分别提高了8.5%、9.1%和2.7%,模型召回率分别提升了14.6%、13.7%和6.3%。YOLOv3-tiny和YOLOv4-tiny模型的推理时间(t)分别为4.6 ms 和4.7 ms ,FPS达到217帧/秒和212帧/秒,但由于模型的精准率和召回率较低,在实际应用中会产生较多的误报和漏报佩戴安全帽情况;而本文模型的FPS为91帧/秒,能满足实时应用的需求,同时精准率、召回率和AP50均处于最好的结果,综合模型精度和模型推理速度的平衡,进一步验证本文模型的有效性。
3.3" 安全帽视觉检测结果
为更直观地展示本文模型的检测识别效果,针对实际电厂场景的安全帽的检测进行了实验,图4为检测结果。安全帽的类别标签为“hat”,“hat”后面的数值表示的是识别成安全帽的置信度。可以看到本文方法可有效识别电厂场景内施工人员佩戴安全帽情况,当施工人员之间存在遮挡或者图像拍摄不够全面时,也可识别该施工人员佩戴安全帽情况,本文方法的检测准确率较高。
4" 结" 论
安全帽佩戴对于电厂施工人员的安全十分重要,为满足实际应用对安全帽识别检测的精度与速度的要求,本文采用YOLOv8 Nano算法进行安全帽识别检测。本文采集、清洗并标注现实电厂场景下的数据,并加入安全帽公开数据集进行模型训练。在自建的安全帽数据集上的评估,AP50达到93.5%,准确率稳定于91.4%;召回率稳定于88.3%,相较于YOLOv3-tiny,YOLOv4-tiny和YOLOv5 Nano模型,模型的精度有明显的提升。在模型的推理速度上,本文模型的FPS达到91帧/秒,能有效进行实时安全帽检测。综合模型精度和模型推理速度,验证了本文方法的准确性与高效性。
参考文献:
[1] LI H,LI X Y,LUO X C,et al. Investigation of the Causality Patterns of Non-helmet Use Behavior of Construction Workers [J].Automation in Construction,2017,80:95-103.
[2] 张勇,吴孔平,高凯,等.基于改进型YOLOV3安全帽检测方法的研究 [J].计算机仿真,2021,38(5):413-417.
[3] 冯国臣,陈艳艳,陈宁,等.基于机器视觉的安全帽自动识别技术研究 [J].机械设计与制造工程,2015,44(10):39-42.
[4] VANBANG L,朱煜,ANHTU N.深度图像手势分割及HOG-SVM手势识别方法研究 [J].计算机应用与软件,2016,33(12):122-126.
[5] 刘晓慧,叶西宁.肤色检测和Hu矩在安全帽识别中的应用 [J].华东理工大学学报:自然科学版,2014,40(3):365-370.
[6] 吴冬梅,王慧,李佳.基于改进Faster RCNN的安全帽检测及身份识别 [J].信息技术与信息化,2020(1):17-20.
[7] GIRSHICK R. Fast R-CNN [C]//Proceedings of the IEEE international conference on computer vision.Santiago:IEEE,2015:1440-1448.
[8] 张明媛,曹志颖,赵雪峰,等.基于深度学习的建筑工人安全帽佩戴识别研究 [J].安全与环境学报,2019,19(2):535-541.
[9] FANG Q,LI H,LUO X,et al. Detecting Non-hardhat-use by a Deep Learning Method From Far-field Surveillance Videos [J].Automation in Construction,2018,85:1-9.
[10] FU J T,CHEN Y Z,CHEN S W. Design and Implementation of Vision Based Safety Detection Algorithm for Personnel in Construction Site [EB/OL].Engineering,Computer Science,2018:[2023-02-18].https://www.semanticscholar.org/paper/Design-and-Implementation-of-Vision-Based-Safety-in-Fu-Chen/9e22ef48b825eac3f417437ff2cc43c3d85128a7.
[11] REDMON J,DIVVALA S,GIRSHICK R,et al. You Only Look Once: Unified, Real-time Object Detection [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas:IEEE,2016:779-788.
[12] 徐传运,袁含香,李刚,等.使用场景增强的安全帽佩戴检测方法研究 [J].计算机工程与应用,2022,58(19):326-332.
[13] 侯公羽,陈钦煌,杨振华,等.基于改进YOLOv5的安全帽检测算法 [J].工程科学学报,2024,46(2):329-342.
[14] 赵睿,刘辉,刘沛霖,等.基于改进YOLOv5s的安全帽检测算法 [J].北京航空航天大学学报,2023,49(8):2050-2061.
[15] 辜诚炜,谌志东,罗仁强,等.基于PP-YOLOv2电厂场景的安全帽佩戴检测 [J].现代信息科技,2023,7(18):114-118.
[16] 李达,刘辉.针对小目标的YOLOv5安全帽检测算法 [J].现代信息科技,2023,7(9):9-13.