
摘" 要:为解决盲人由于视觉缺陷而产生的交流障碍,结合普通人交流理论的研究与传播学现有模型,构建了盲人交流模型和盲人辅助交流模型,通过软硬件结合的形式,设计了一个盲人辅助交流系统。硬件系统主要包括智能眼镜和便携计算装置两部分;软件系统主要采集图像和声音,识别交流目标及其外部特征、表情交流行为,其中表情识别技术是运用了ResNet18残差神经网络,实现了实时的表情识别功能,最后合成了声音并输出了结果。
关键词:盲人;交流模型;辅助交流;表情识别
中图分类号:TP18 文献标识码:A 文章编号:2096-4706(2024)22-0015-06
Research on the Blind Auxiliary Communication System Based on Deep Learning
Abstract: In order to solve the communication obstacles caused by the visual defects of the blind, combining the research on ordinary peoples communication theory with the existing model of communication, the blind communication model and the blind auxiliary communication model are constructed. Through the combination of hardware and software, the blind auxiliary communication system is designed. The hardware system mainly includes two parts of smart glasses and portable computing devices. The software system mainly collects images and sounds, identifies communication targets and their external features, and expression communication behaviors. Among them, expression recognition technology uses ResNet18 Residual Neural Network to achieve real-time expression recognition function, and finally the sound is synthesized and the result is output.
Keywords: the blind; AC model; auxiliary communication; expression recognition
0" 引" 言
盲人群体数量庞大。根据世界卫生组织统计,全世界约有3 600万人完全失明[1]。据2017年9月英国《柳叶刀全球卫生》刊登的一篇报告,Rupert Bourne预测:如果不加强眼疾的治疗,全球的盲人数量将在2050年增至1.15亿,是目前的3.2倍。研究表明,人的大脑通过感官接受的外部信息中,所占的比例分别为:味觉1%、触觉1.5%、嗅觉3.5%、听觉11%以及视觉83%,视觉占比最大,对感知外部环境最重要[2]。如果长时间在与其他人交流过程中存在障碍,那么盲人的心理健康也很容易受到影响。因此,盲人面对面辅助交流产品的研究十分重要。
本文目的在于为盲人辅助交流产品的设计与生产提供理论支撑与实现指引,在后续做出相应产品,从而解决盲人交流过程中存在的问题。马斯洛的需求层次理论指出人的需求从低层次到高层次分为生理需求、安全需求、社交需求、自尊需求和自我实现。本文主要解决盲人的精神层面需求,层次上对应社交需求和自尊需求。
近年来,将助盲产品设计作为研究课题的趋势逐渐突显。例如,2019年,赵晚尔为更具情感化的智能自行车的设计提供了新的思路[3]。西班牙的Abreu等人设计了视障人士便携式出游的辅助产品[4]。然而,国内助盲产品相较于国外依然存在系统性不足,产品涉及的方面偏少等问题。
表情识别算法的发展大致分为两个阶段:第一阶段集中在2000年附近,方法大多基于滑动窗口和人工特征提取。如Viola-Jones检测器[5]、HOG(Histogram of Oriented Gradients)算法[6]等。第二个阶段是从2014年的R-CNN算法为始。该方法基于深度学习技术,自动提取隐藏特征,以提高样本的分类与预测准确率。之后又出现了如Faster R-CNN[7]、SPPNet[8]、YOLO(You Only Look Once)[9]等算法。
本文针对盲人交流中由于视觉缺失导致信息收取困难的问题,收集、分析交流传播的相关理论,进行归纳总结,并在此基础上提出盲人交流模型;结合现有技术,提出盲人智能辅助交流模型;根据模型,设计盲人辅助交流系统,研究其技术可行性。
1" 盲人交流理论
1.1" 信息传播理论经典模型
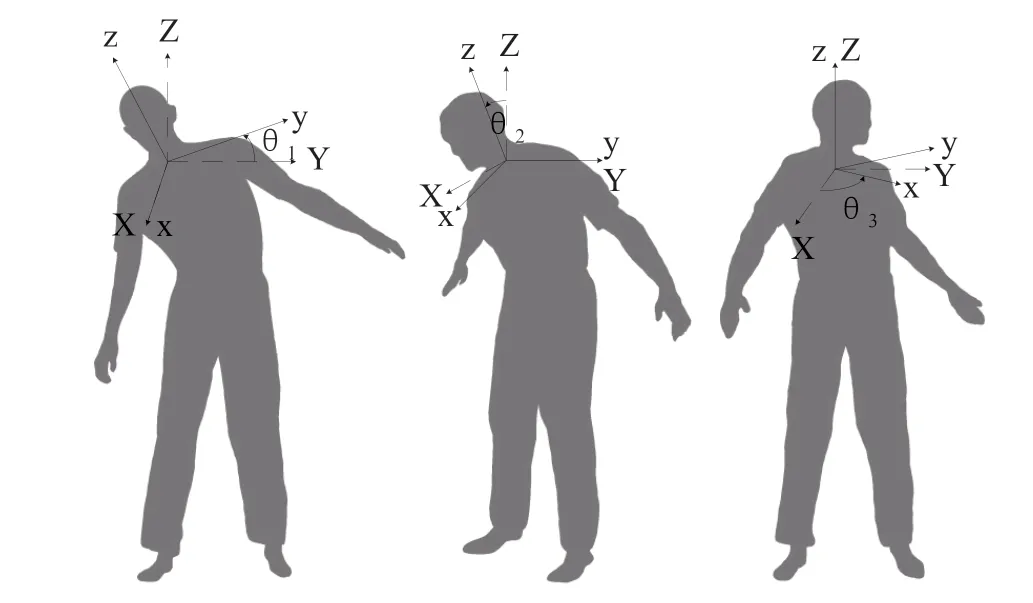
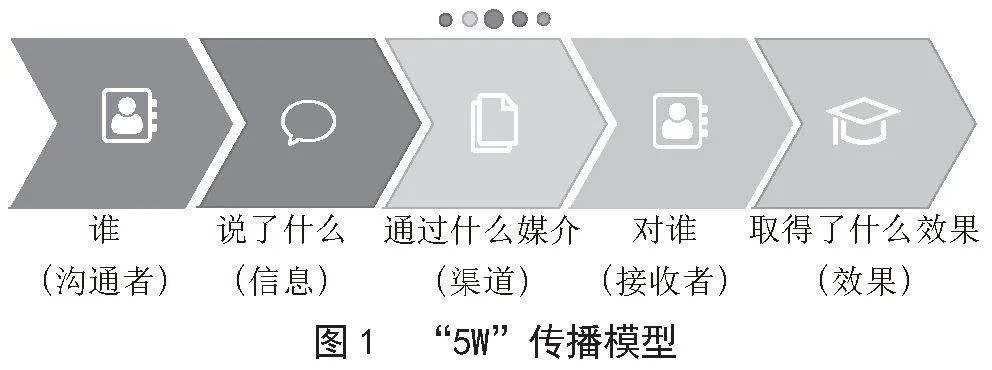
20世纪40年代至60年代,国外学者开始研究信息传播理论。哈罗德·拉斯韦尔提出了拉斯韦尔传播模型,也称为“5W”传播模型[10]。即:谁(Who)—说什么(Says What)—通过什么渠道(In Which Channel)—对谁(To Whom)—取得什么效果(With what effects),这个模型成为传播学重要的理论基础,如图1所示。
1.2" 盲人交流模型
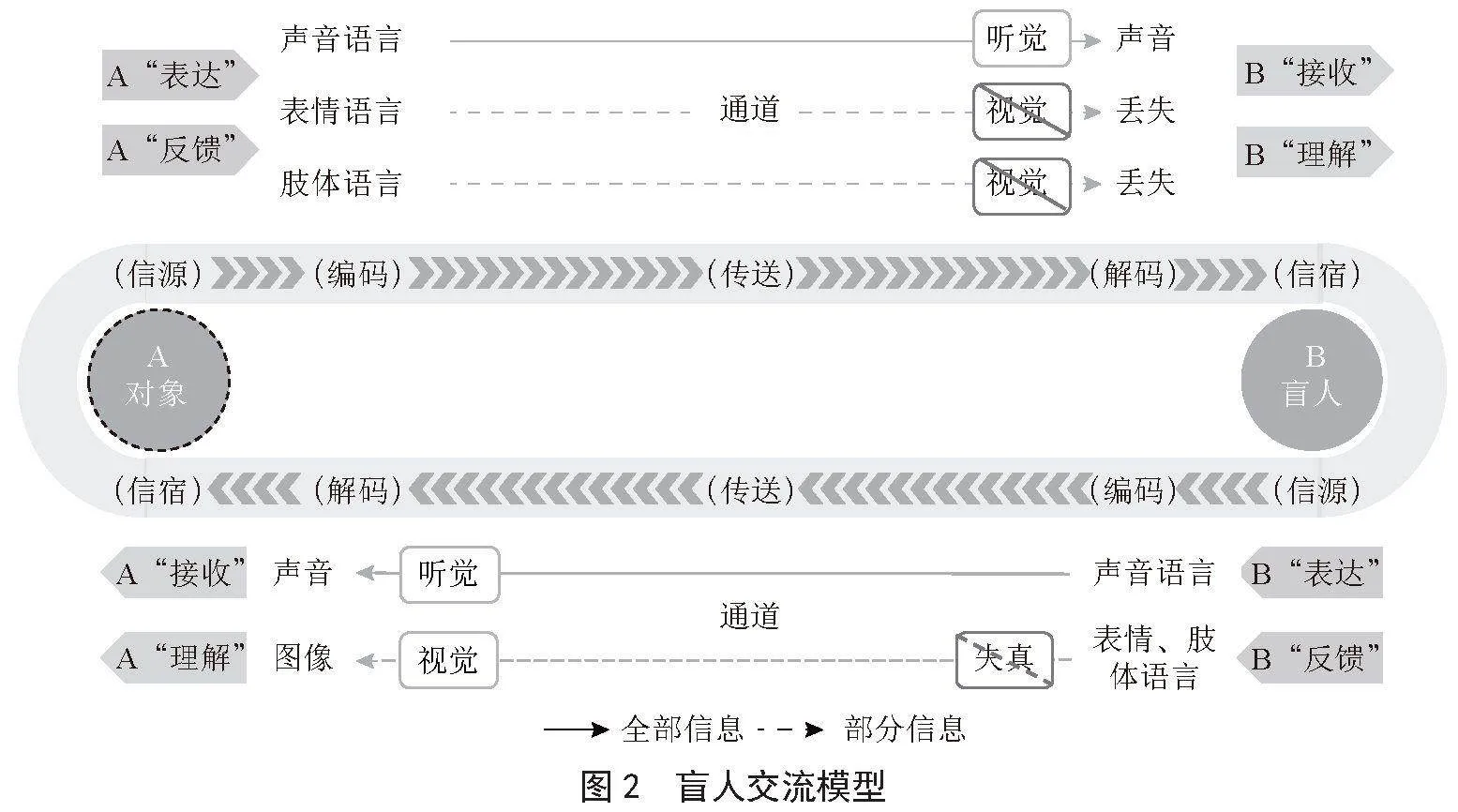
前人对人际沟通建立了一些经典模型,但对于人与人交互沟通的完整过程还存在模型不完整的问题,对于盲人的沟通问题更是很少研究。艾伯特·梅拉比安提出了一个著名的公式,指出信息的影响力中,言语内容(文字)占7%,声音(语音、音调)占38%,而非言语的面部表情和肢体语言占55%。盲人在交流过程中,需要依赖听觉、触觉等非视觉感官来获取视觉信息,他们通过语言、声音、触摸等方式与他人进行交流。由于视觉信息的缺失,盲人在理解复杂信息和情感表达时面临着一定困难。针对盲人的交流特点,基于以上传播理论,本文提出了盲人交流模型,如图2所示。
盲人交流过程与普通人交流过程在整体结构上相似,也存在表达与反馈、接收与理解的循环过程,但在一些关键部位上也有区别。
首先,普通人交流过程中确定交流对象有视觉和听觉两个主要途径。盲人由于视觉障碍,无法通过视觉获取有效信息,如果仅通过听觉判别对象的身份,难度较大,准确度也无法保障。
随后,对象在表达与反馈时对盲人传送的信息包括声音语言、表情语言、肢体语言等。盲人能够通过听觉完成对声音语言的接收与理解,但无法完成对表情语言、肢体语言及对象其他属性(位置、外部特征等信息)的接收,从而导致这些信息丢失。
最后,在盲人向对象表达与反馈时,部分盲人会因为长期无法接触到表情语言和肢体语言,无法用表情语言和肢体语言进行准确的表达与反馈,从而导致发出的信息失真。
1.3" 盲人辅助交流模型
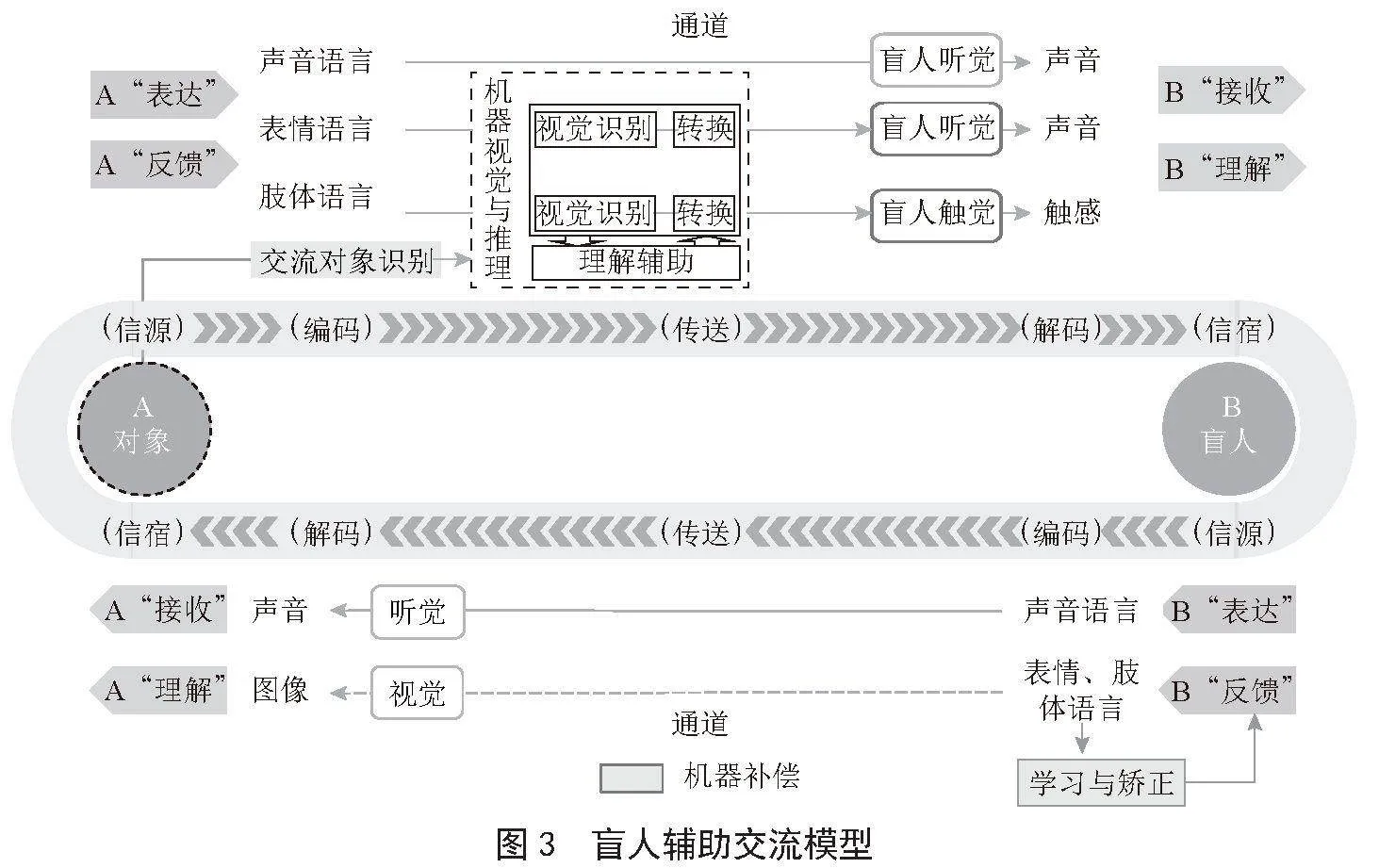
在盲人交流模型的基础上,本文结合信息与人工智能技术和盲人交流模型中存在的缺陷,构建了盲人辅助交流模型,如图3所示。盲人辅助交流模型是一个利用机器补偿,针对盲人辅助交流的实用性模型,为盲人辅助交流后续实现提供了方向和指导。
盲人辅助交流模型在盲人交流过程中存在障碍的部分使用机器补偿,从而补全盲人交流的全过程。盲人交流过程中的主要问题是无法接收对象表达与反馈中的视觉信息,使用机器补偿解决该问题需要确定对象、对象表达与反馈的视觉识别、交流信息理解辅助、视觉信息的形式转换4步:
1)确定对象。结合盲人交流模型可知,在盲人辅助交流中要首先确定对象是哪个人,这样一方面可以让盲人知道面对的是谁,另一方面才能匹配信息和对象。
2)对象表达与反馈的视觉识别。在确定对象之后,传送对象表达与反馈的视觉信息是盲人辅助交流模型的核心。结合盲人交流模型,对象传送的视觉信息有表情语言、肢体语言和对象其他属性等。这些信息都可以利用机器视觉进行捕获与识别。
3)交流信息理解辅助。在盲人交流模型中,盲人无法接收表情语言与肢体语言,因此也无法完成接收之后对于表情语言与肢体语言的理解环节。一些盲人会因为长期没有理解表情语言与肢体语言的机会,导致在理解这些语言时出现障碍。而单纯通过机器视觉传送接收到的视觉信息,并不能有效解决盲人对视觉信息理解的障碍,这就需要利用机器推理,将接收的视觉信息加以理解,转化为对盲人交流有意义的信号。
4)视觉信息的形式转换。通过机器视觉及机器推理将视觉信息识别并辅助理解后,还需要将信息的形式转换为盲人可接收的形式。在盲人没有受损的四种感官形式中,听觉和触觉转换较为方便,接收信息量也相对较大,其中听觉接受的信息量最大,对盲人最为重要。因此,机器需要根据实际情况,将视觉信息转为听觉信息或触觉信息传送给盲人。
2" 系统框架组成
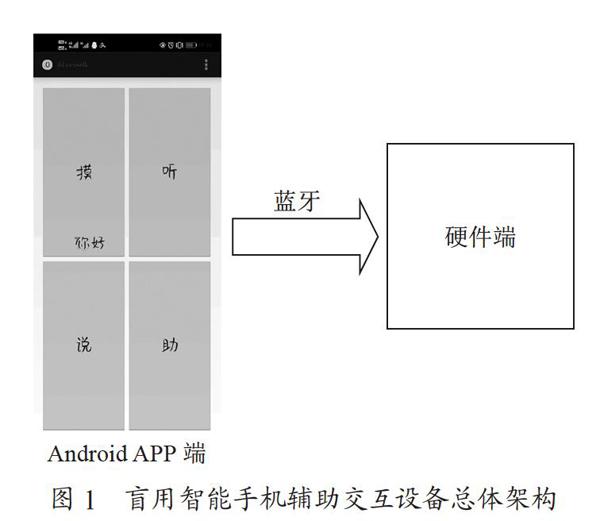
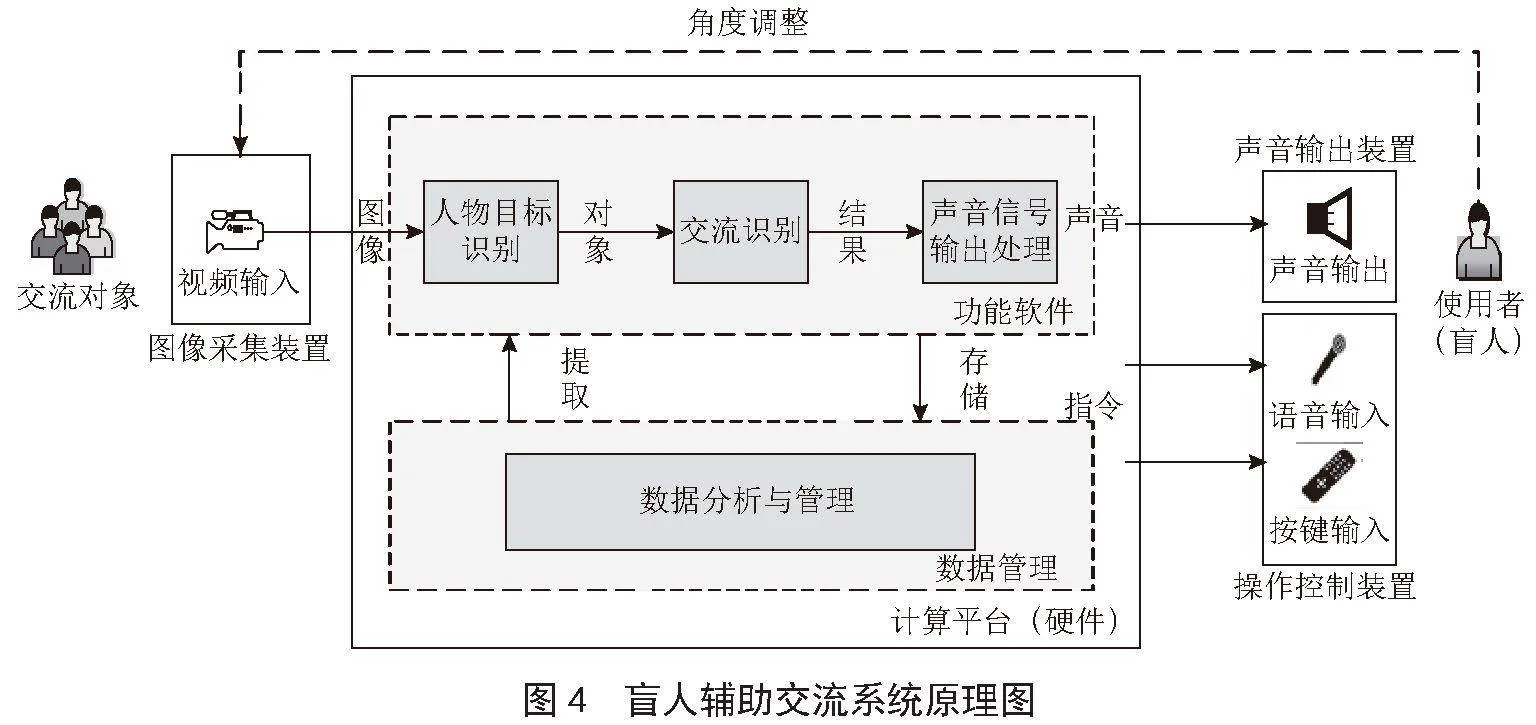
针对盲人无法识别交流对象表情及外部特征的问题,本文提出了由硬件系统和软件系统组成的盲人辅助交流系统,其中硬件系统包括四个部分:图像采集装置、系统硬件平台、输出装置、操控装置;软件系统包括两个部分:功能软件、支撑平台。其系统原理图如图4所示。
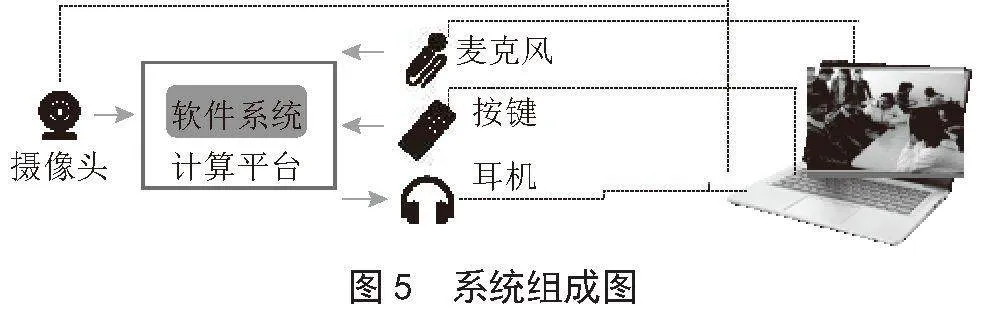
系统通过图像采集装置对交流对象的图像进行采集,通过加载在计算平台上的软件系统对视野中的图像进行识别,发现人物,并对对象进行识别。交流过程中,系统对讲话人和人群进行表情、肢体语言的识别,将识别的结果转换成声音,通过输出装置传递到盲人(使用者)耳中,让盲人对交流环境有全面的认知,对交流内容有更丰富、更深入的理解。盲人通过操作控制装置对系统进行控制,使系统按照需求进行运作。系统组成图如图5所示。
2.1" 硬件系统
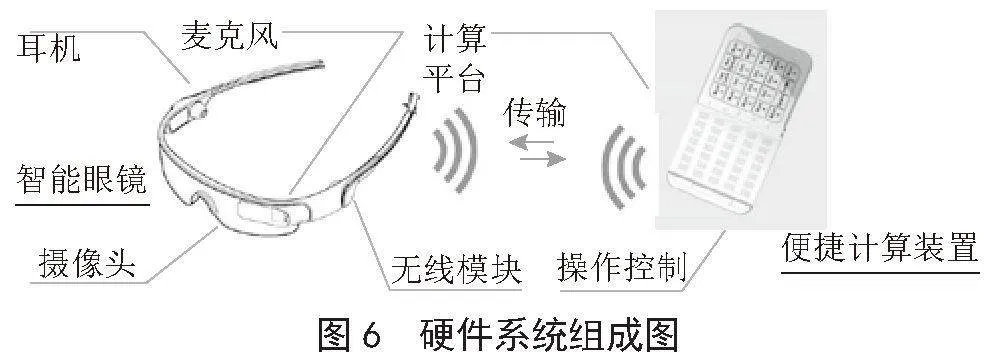
硬件系统的主要作用是信号的输入、输出,支撑软件运行和系统的操作控制。为了便于佩戴和使用,硬件系统需要小巧轻便,并尽可能对功能模块进行集成。硬件系统组成如图6所示。
硬件系统主要包括两部分:智能眼镜和便携计算装置,智能眼镜集成了摄像头、麦克风、耳机等音视频输入输出功能,便携计算装置用于搭载软件系统,同时集成了按键操作功能。智能眼镜与便携计算装置采用有线和无线两种方式进行通信。
2.2" 软件系统
2.2.1" 软件系统框架
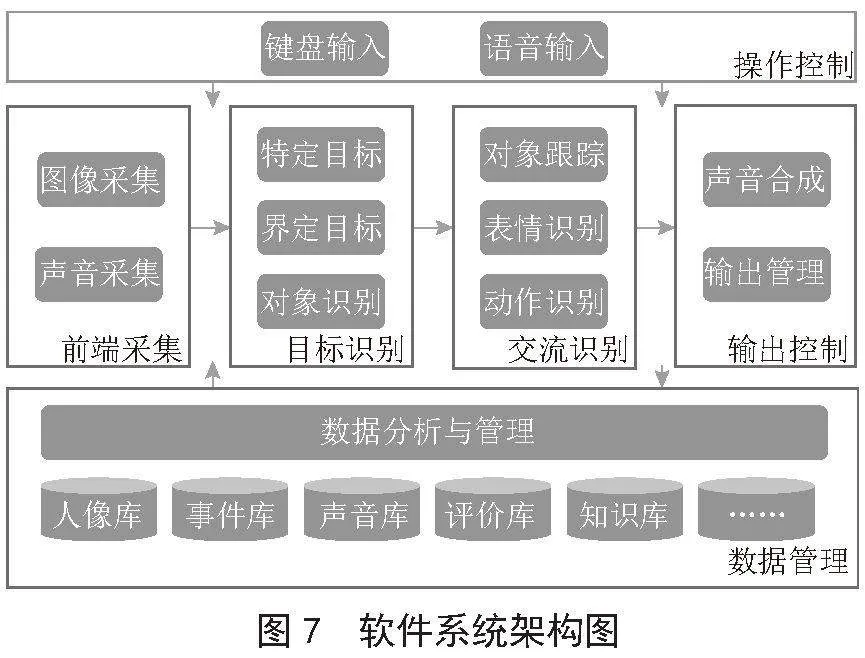
软件系统是整个系统的功能核心,是解决盲人交流障碍的关键,在硬件系统的支持下,软件系统完成从前端信号采集、目标人物识别、交流过程识别到声音输出处理的全过程,在此过程中,可以通过键盘操作或语音输入对系统进行控制,系统数据由数据分析与管理模块进行应用与管理,最终实现识别性别、年龄、表情等身份信息并完成语音播报,辅助盲人交流。软件系统架构如图7所示。
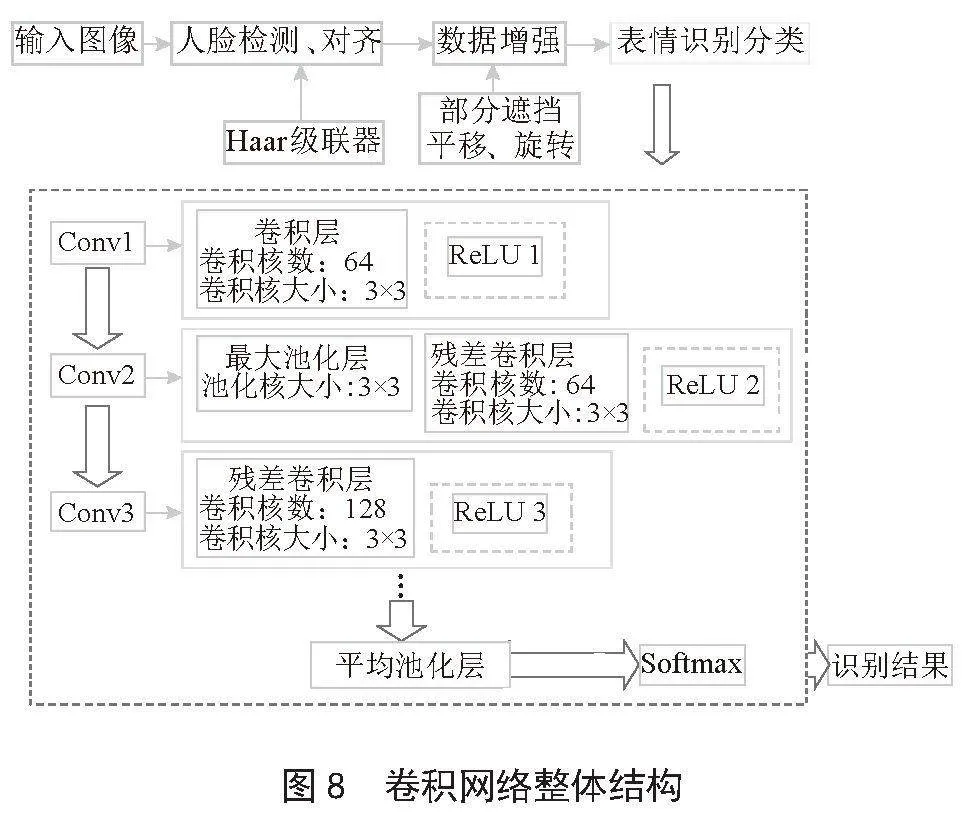
目标识别与交流识别过程主要包括人脸图像采集及检测、人脸图像预处理、人脸图像特征提取以及匹配与识别。系统在模型训练阶段,使用了数据增强技术(图像旋转放缩以及随机排序)来增加数据数量,泛化模型,并通过回调函数和Adam优化器(优化指标为测试Loss值)对模型进行调优。通过结合Haar级联分类器检测人脸,并对检测到的人脸进行处理和识别,实现了实时的表情识别功能[11]。卷积神经网络图如图8所示。
目标识别完成后,软件系统通过进一步推断、解读肢体动作背后的深层次含义从而对盲人交流进行实时辅助:系统将识别的结果传递给肢体语言推理机,推理机将输入的信息与知识库中各个规则的条件进行匹配,对推理结论信息进行声音转换,最终输出给用户。系统的识别结果和相关信息需要通过声音的形式传递给盲人。最后,系统对于每次交流活动进行记录,形成基础数据,通过统计、分析和计算形成交流对象、事件、综合统计等方面分析结果。基于交流记录数据,统计数据和评价算法,形成交流质量的评价结果。通过这些数据形成量化指标,使系统能够利用大数据量化评估手段,更好的辅助盲人进行交流。
2.2.2" 软件系统关键技术实验验证
针对辅助盲人面对面交流时获取对方表情的问题,为了获得更快的响应速度和实时获取到对方的表情变化,在旷视API调用的基础上,我们对于识别算法的本地化开展了进一步研究。本系统使用了ResNet18作为表情识别特征提取的神经网络模型,选取了CK+数据集和Fer2013数据集[12]。针对Fer2013数据集噪声较大这一特性,使用高斯滤波器进行去噪处理,CK+数据集由于数据集标注准确率较高,数据噪声较少,未做过多处理。
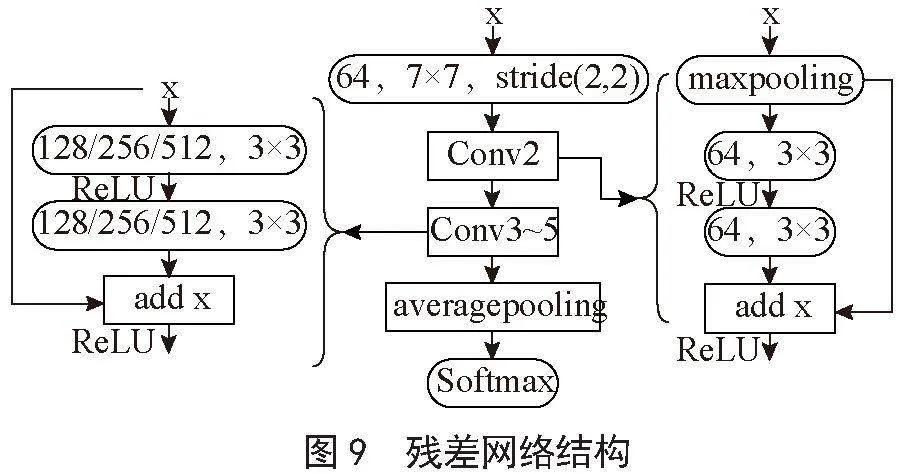
本模型使用的ResNet18共有5层卷积层,其中Conv2到Conv5为残差神经网络,整个神经网络结构如图9所示。为了增强模型的泛化能力,本系统在此神经网络中加入随机舍弃率为0.2的dropout层,训练时增加了数据增强的操作(如放缩、旋转)以及Early Stopping策略(patience值为50),数据集训练测试的划分比率为7∶3,使用交叉熵作为损失函数对模型的学习误差进行计算,以及使用Adam优化器对模型现状进行评估和最小化损失值。训练测试之后保存比上次性能更好的模型,直到模型在50个Epoch内Loss值不再减少。
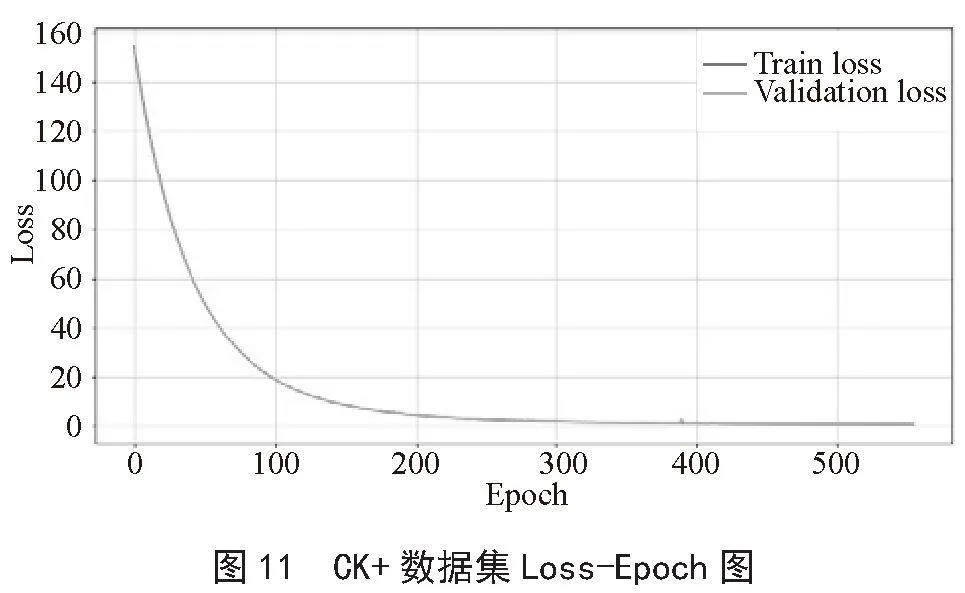
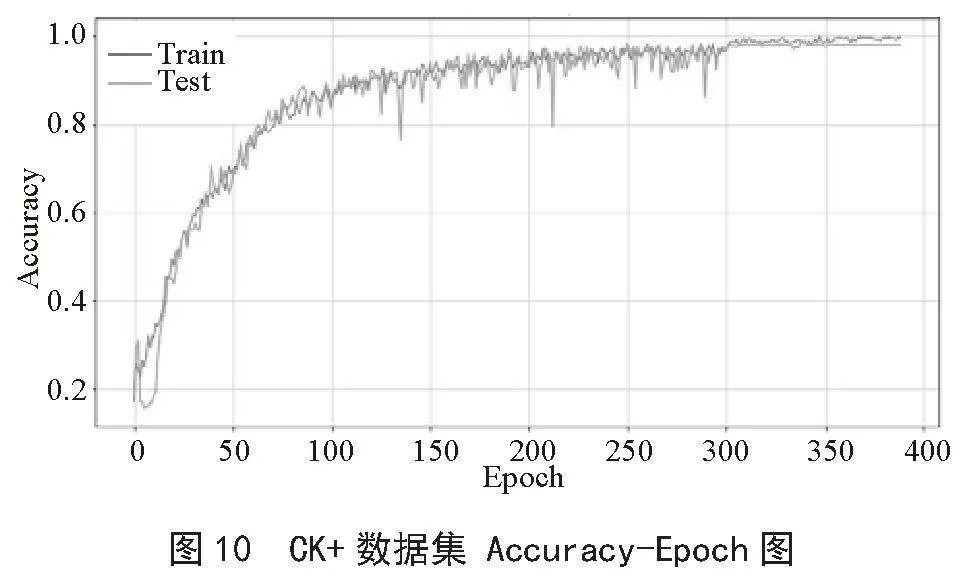
通过参数的调整和训练得到的结果:CK+数据集上的训练集准确率为0.987 0,测试集准确率为0.982 6,Loss值0.486 72;在Fer2013数据集上的训练集准确率为0.679 7,测试集准确率为0.682 4,Loss值1.106 04;由训练结果得出,此模型在CK+数据集上表现良好,Fer2013数据集由于数据本身噪声较多,标识准确率较差等原因,模型的准确度在68%左右,本系统最终采用由CK+数据集训练保存的参数模型。CK+数据集上的表现如图10、图11所示。
应用该模型进行表情识别时,调用OpenCV读取摄像头的图像信息,将每帧读取到的图像做灰度化处理,调用OpenCV的Haar级联分类器对处理后的图像进行人脸识别,若检测到人脸则将此图像大小调整至识别模型输入大小48×48,将调整后的图像转成像素矩阵并对像素值进行归一化处理,处理后的像素矩阵传入识别模型,得到的识别结果使用数组存储,将其和对应情绪标签压缩配对,使用Canvas将识别结果使用滑动进度条的形式呈现在屏幕上,此过程在一个循环中一直执行,直到用户按下结束按钮即跳出此循环。识别效果如图12所示。
3" 结" 论
本文针对基于计算机视觉技术辅助盲人面对面交流的问题进行研究,提出了盲人交流模型、盲人辅助交流模型两个基础理论模型;通过软硬件结合的形式,设计了盲人辅助交流系统;硬件系统主要包括智能眼镜和便携计算装置两部分;软件系统采集了图像和声音,识别了交流目标及其表情等交流行为,其中最关键的表情识别技术采用了Resnet18残差神经网络,解决了助盲系统中表情识别技术的关键技术问题,其在CK+数据集上的表现,测试准确率达到98%以上,Loss值为0.486 72,实现了实时的表情识别功能,合成了声音并输出了结果。本文尚未针对盲人在表达与反馈时存在的问题等其他盲人交流中的缺陷给出具体解决方案,可以进一步进行研究.
参考文献:
[1] 胡伟健.面向视障出行辅助的避障和定位技术研究 [D].杭州:浙江大学,2021.
[2] 任伟苗.基于感知觉的视障用户产品设计研究 [D].青岛:青岛理工大学,2021.
[3] 赵晚尔.盲校视障儿童智能自行车设计与研究 [D].杭州:中国美术学院,2019.
[4] ABREU D,TOLEDO J,CODINA B,et al. Visually Impaired Interaction with the Mobile Enhanced Travel Aid eBAT [C]//International Conference on Human Systems Engineering and Design.Croatia:[s.n.],2020:1-6.
[5] 王广宇.基于残差网络的人脸表情识别研究 [D].青岛:青岛科技大学,2022.
[6] 姜煜杰.基于LBP和HOG特征融合的人脸表情识别研究与实现 [D].黄石:湖北师范大学,2024.
[7] 王潇.基于Faster R-CNN的人脸面部情感识别方法 [J].信息与电脑:理论版,2023,35(21):148-150.
[8] 杨海舟,李丹.基于改进SPPnet的YOLOv4目标检测 [J].电子制作,2021(22):52-54.
[9] 宋明芮,唐海,徐洪胜.基于改进YOLOv5s的微表情识别研究 [J].重庆科技学院学报:自然科学版,2023,25(6):65-71.
[10] 哈罗德·拉斯韦尔.社会传播的结构与功能 [M].北京:北京广播学院出版社,2013.
[11] 焦阳阳,黄润才,万文桐,等.基于图像融合与深度学习的人脸表情识别 [J].传感器与微系统,2024,43(3):148-151.
[12] 赵晓,杨晨,王若男,等.基于注意力机制ResNet轻量网络的面部表情识别 [J].液晶与显示,2023,38(11):1503-1510.