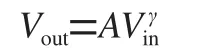中图分类号:TN911.22;TP391.4 文献标识码:A 文章编号:2096-4706(2025)07-0001-04
Abstract: JointSource-Channel Coding (JSCC),asa keyresearch direction in semantic communication,has achieved preliminary research results. However, with the increasing resolution of images,traditional JSCC algorithms based on Convolutional Neural Network(CNN)exhibitlimitations inextractingimagesemanticfeatures.Toadressthisissue,this paper proposes a JSCCalgorithm based on Swin Transformer.The algorithm firstlyutilizesa Multi-Scale Large Kemel Attention(MLKA)mechanismtoinitiallcapture thelocal informationand long-rangedependenciesofimages.Subsequently SwinTransformer is employed to further hierarchically extract image semantic features and perform adaptiverate coding. Experimentalresultsdemonstrate that,underthechannelmodelsofAditiveWhite GausianNoise (AWGN)andRayleighthe proposedalgorithmoutperformstraditionalalgorithmsin termsofPeak Signal-to-NoiseRatio (PSNR)andMulti-Scale Structural Similarity Index Measure (MS-SSIM).
Keywords: Joint Source-Channel Coding; Swin Transformer; Multi-Scale Large-Kernel Attention
0 引言
随着信息技术的飞速发展,通信系统的性能要求日益提高。传统通信系统采用信源信道分离编码的方法进行设计[]。信源编码通过减少源数据的信息冗余来降低数据量,信道编码通过使用错误检测或错误纠正编码技术来提高传输可靠性。然而,从系统最优性的角度来看,该方法是在不考虑信源信道相互影响的情况下独立设计和优化的,因此无法协同工作以达到最佳的系统通信容量[2]。
为了解决上述问题,研究者提出了联合信源信道编码(Joint Source-Channel Coding,JSCC),通过共同设计和优化信源编码和信道编码过程,以实现编码过程的系统级最优性[3]。对于图像传输任务,目前基于深度学习的JSCC及其变体使用卷积神经网络(ConvolutionalNeuralNetwork,CNN)作为骨干网络,可以实现优于经典分离方法的端到端图像传输性能[4]。如Bourtsoulatze[5]等人提出的首个基于CNN的 深 度JSCC(Deep-based Joint Source-ChannelCoding,DeepJsCC)方案,在低信噪比和信道带宽条件下,其性能优于基于分离的数字传输方案。Yoo等人提出了一种基于ViT的语义通信系统SemViT,把ViT的优势应用于图像语义通信系统中,并在图像处理任务中有较大的性能提升。 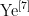 等人提出了一种基于注意力模块的DeepJSCC模型(ADJSCC),该模型利用一个挤压-激励模块来调整不同信噪比条件下学习到的图像特征,解决了不同信噪比条件下的适应性和鲁棒性问题,以最大化图像重建质量。
等人提出了一种基于注意力模块的DeepJSCC模型(ADJSCC),该模型利用一个挤压-激励模块来调整不同信噪比条件下学习到的图像特征,解决了不同信噪比条件下的适应性和鲁棒性问题,以最大化图像重建质量。
然而随着图像分辨率的提高,上述基于CNN的DeepJSCC模型通常难以学习层次特征和图像细节,导致明显的性能下降[8]。因此,本文提出了一种基于SwinTransformer的联合信源信道编码算法。为了解决传统的CNN对图像特征提取效率欠佳等问题,本文利用多尺度大核注意力机制(Multi-Scale LargeKernelAttention,MLKA)初步提取图像的局部信息和长距离依赖性,然后通过SwinTransformer进一步对图像语义特征进行提取。SwinTransformer的窗口注意力机制和移位窗口策略可以实现信源特征的分层提取和自适应码率编码。这一方法不仅显著提升了模型的性能和计算效率,节省了大量的信道资源,还能在恶劣的信道条件下表现出更强的鲁棒性。
1基础理论
1.1 多尺度大核注意力
多尺度大核注意力主要包含两个功能:用于建立相互依赖性的大核注意力(LargeKernelAttention,LKA)和用于获取不同尺度相关性的多尺度机制[。
输入特征图 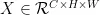 ,LKA通过将 K × K 卷积分解为三个部分来自适应地构建长距离关系: ( 2 d - 1 ) 1× ( 2 d - 1 ) 的深度卷积
,LKA通过将 K × K 卷积分解为三个部分来自适应地构建长距离关系: ( 2 d - 1 ) 1× ( 2 d - 1 ) 的深度卷积 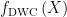 、深度扩张卷积
、深度扩张卷积 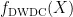 和逐点卷积
和逐点卷积 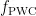 ( X) ,这三个部分可以表示为式(1):
( X) ,这三个部分可以表示为式(1):
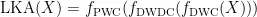
为了提取长距离、全尺度的语义信息,本文还使用了分组多尺度机制。首先将输入特征图分成 n 组,然后利用 n 组不同大小的LKA对每个图像块进行特征提取。至此多尺度大核注意力就完成了对图像信息的初步提取。
1.2 窗口多头注意力
传统Transformer架构在处理高分辨率图像任务时面临性能瓶颈,因为其多头注意力(Multi-HeadSelf-Attention,MSA)的计算复杂度与图像大小呈二次方关系。相比之下,SwinTransformer通过引入窗口多头注意力机制(WindowsMulti-HeadSelf-Attention,W-MSA)和移动窗口多头注意力机制(Shifted WindowsMulti-Head Self-Attention, SW-MSA),实现了与图像大小呈线性关系的计算复杂度,从而显著提升了性能[10]。
W-MSA机制将输入图像划分为不重叠的均匀区域,并在每个局部窗口内独立计算MSA。这种做法不仅降低了计算复杂度,还提高了特征提取的效率。然而,这种分区方式也带来了各区域间信息隔绝的问题。为解决此问题,SW-MSA机制通过在区域间进行窗口偏移,创建了新的分区,实现了跨窗口的信息连接,促进了信息的传递,并使得模型能够提取更丰富的语义信息。
在窗口偏移后,新的计算区域可能由特征图中原本不相邻的多个子区域组成。为了限制计算范围,SwinTransformer采用了掩码机制,确保MSA的计算仅在每个子区域内进行。虽然进行了窗口偏移,但新的计算区域数量与未偏移前相等,因此并不会降低计算效率。
SwinTransformer通过W-MSA与SW-MSA的交替组合,在保证语义特征提取效果的同时,极大地提高了系统的性能,特别适用于高分辨率图像任务。
2基于SwinTransformer的联合信源信道编码算法
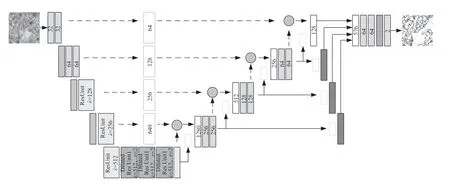
本文提出的基于SwinTransformer的联合信源信道编码算法(Swin Transformer-basedJoint Source-ChannelCodingAlgorithm,STJSCC)的主要功能模块如图1所示。
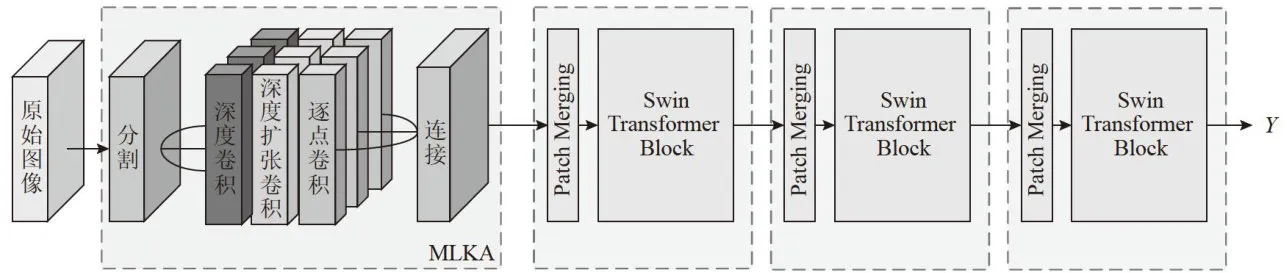 图1STJSCC原理图
图1STJSCC原理图MLKA和SwinTransformer是STJSCC编码器的主要组成部分。同时为了让大核注意力能够提取到更丰富的多尺度语义信息,本文引入了分组的多尺度机制。输入特征图被均匀地分割成 n 组,在本算法中 n 设置为3。每个组都使用了不同尺寸的大核分解,分别为: 7 × 7 、 2 1 × 2 1 和 3 5 × 3 5 ,并设置其膨胀率分别为{2,3,4}。最后三组特征提取的结果由连接模块进行特征融合。
图1中的PatchMerging采用的是一种类似于池化的操作,但它不会损失信息,而是将每个小窗口中相同位置的值取出来,拼成新的小块,再把所有小块拼接起来,在降低计算量的同时还能捕捉图像的多尺度特征。
Swin Transformer 由 PatchEmbedding 和 SwinTransformerBlock组成。PatchEmbedding将图像分割成小块并进行嵌入处理,它能够捕捉到图像的局部特征,并为后续的Transformer层提供有效的输入数据。SwinTransformerBlock是STJSCC最核心的部分,如图2所示。
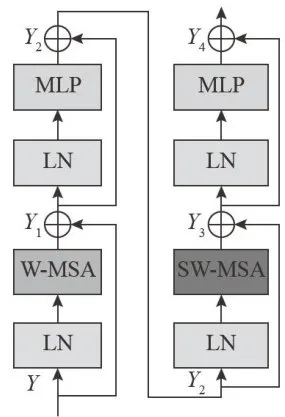 图2SwinTransformerBlock原理图
图2SwinTransformerBlock原理图一个Swin Transformer Block由层归一化 (LayerNormalization,LN)、多层感知器(Multi-LayerPerceptron,MLP)、W-MSA和SW-MSA组成。LN位于MLP和注意力机制模块之后,用于对输出特征进行归一化处理。MLP用于对注意力机制处理后的特征进行进一步的非线性变换,以提取更深层次的特征。W-MSA和SW-MSA是SwinTransformer的核心组件,通过交替使用W-MSA和SW-MSA,SwinTransformer能够在保持计算效率的同时,逐步扩大注意力机制的感受野,从而捕捉到更丰富的全局信息。同时这种设计使得SwinTransformer在处理高分辨率图像时能够显著减少计算量和内存占用。另外,由于SwinTransformer还具有较强的灵活性和易于扩展的特点,能够方便地集成到与其他模块中。
Swin TransformerBlock的计算如式(2)所示:
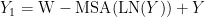
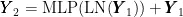
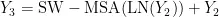
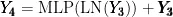
其中, Y 为输入特征矩阵, 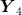 为SwinTransformerBlock的输出特征矩阵。
为SwinTransformerBlock的输出特征矩阵。
原始输入图像被分割后,由MLKA模块和多个SwinTransformer模块进行语义信息提取,最后发送到信道中。
3 实验与结果分析
3.1 实验设置
仿真环境:本算法基于PyTorch1.9框架,并使用Python3.8编程实现。实验所使用的CPU为IntelXeonPlatinum8336C,GPU为NVIDIARTX2080Ti。信道模型使用加性高斯白噪声(AWGN)和瑞利衰落(Rayleigh)信道模型。
数据集:本文使用DIV2K作为训练集,Kodak作为测试集。DIV2K由 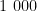 张高分辨率图像组成,其中包括800张训练图像、100张验证图像和100张测试图像。这些图像涵盖了丰富的场景和内容,具有较高的多样性和复杂性。Kodak包含24张高质量的彩色图像,涵盖了自然景观和人物肖像等多种场景,具有丰富的纹理、颜色和细节信息。
张高分辨率图像组成,其中包括800张训练图像、100张验证图像和100张测试图像。这些图像涵盖了丰富的场景和内容,具有较高的多样性和复杂性。Kodak包含24张高质量的彩色图像,涵盖了自然景观和人物肖像等多种场景,具有丰富的纹理、颜色和细节信息。
参数设置:本实验将Epochs设置为200,BatchSize设置为16,以权衡训练效率和性能。优化器采用Adam优化器,并将其学习率设置为 0 . 0 0 0 1 。信噪比的范围为 - 5 ~ 2 5 d B 。
3.2 结果分析
为验证本文提出的STJSCC的性能,本文将STJSCC与传统的DeepJSCC和SemViT方法进行对比,并使用峰值信噪比(PeakSignal-to-NoiseRatio,PSNR)和多尺度结构相似性指数(Multi-ScaleStructuralSimilarityIndexMeasure,MS-SSIM)来衡量STJSCC 的性能。
在仿真实验时,信噪比从 2 5 d B 开始降低,直至 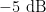 。经多次对比实验,得到三种模型的PSNR和MS-SSIM指标。PSNR指标的仿真结果如图3、图4所示。
。经多次对比实验,得到三种模型的PSNR和MS-SSIM指标。PSNR指标的仿真结果如图3、图4所示。
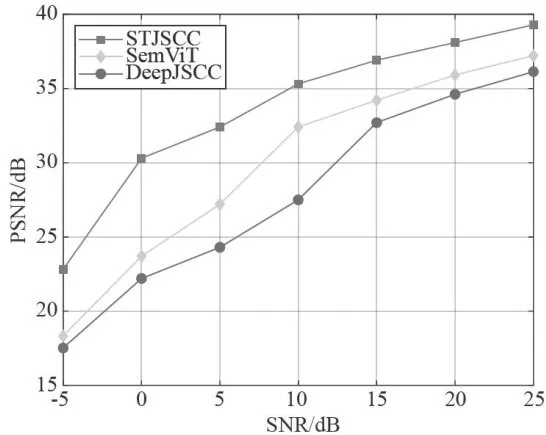 图3AWGN信道中PSNR指标的对比
图3AWGN信道中PSNR指标的对比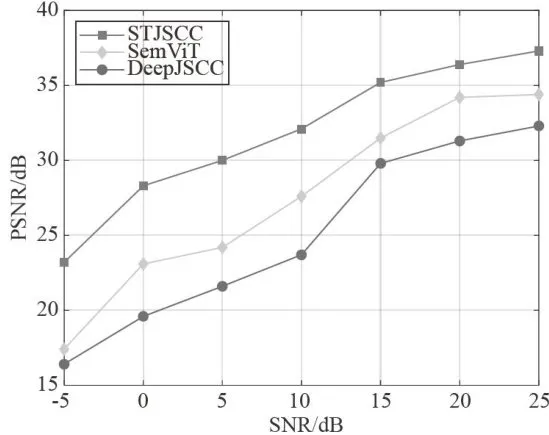 图4Rayleigh信道中PSNR指标的对比
图4Rayleigh信道中PSNR指标的对比从图3、图4可以看出,所提出的STJSCC的PSNR值在整个SNR范围内都比SemViT和DeepJSCC更高,特别是在SNR低于 1 0 d B 时,STJSCC提升的性能更明显。在SNR为 2 5 d B 时,STJSCC的PSNR值比SemViT提升了 3 . 1 5 d B ,比DeepJSCC提升了2.07dB。在SNR为-5dB时,三种方法的性能都偏低,这是由于噪声强度过高,但STJSCC的PSNR仍能保持在22.81dB,优于另外两种方法。MS-SSIM指标的仿真结果如图5、图6所示。
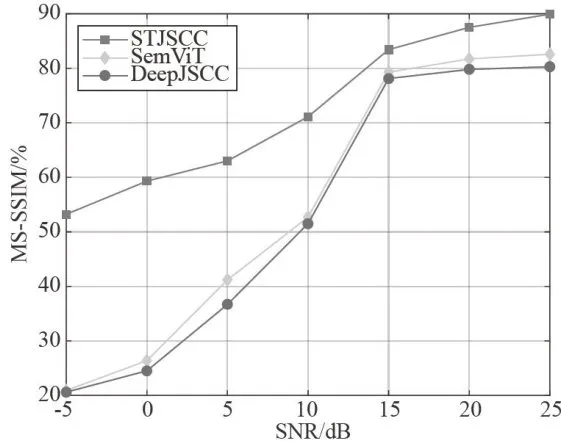 图5AWGN信道中MS-SSIM指标的对比
图5AWGN信道中MS-SSIM指标的对比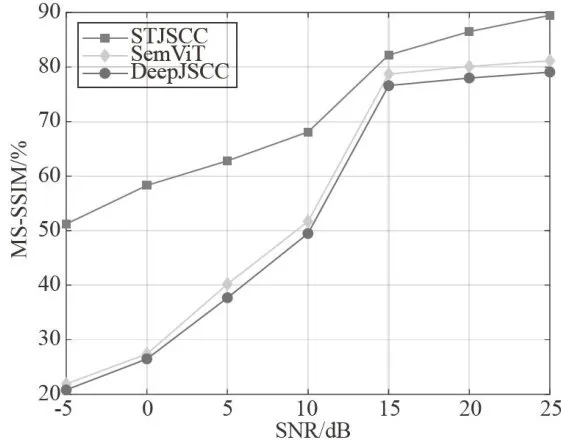 图6Rayleigh信道中MS-SSIM指标的对比
图6Rayleigh信道中MS-SSIM指标的对比从图5、图6可以看出,所提出的STJSCC的MS-SSIM指标比SemViT和DeepJSCC更好,在SNR为 2 5 d B 时,STJSCC的MS-SSIM指标比SemViT提升了 7 . 3 6 % ,比DeepJSCC 提升了 9 . 6 4 % 。随着信噪比的降低,STJSCC的MS-SSIM指标不会急剧下降,在SNR为 - 5 d B 时,MS-SSIM指标仍能保持在 5 3 . 2 2 % ,表明STJSCC在恶劣的信道条件下仍能展现出更强的鲁棒性。
4结论
本文提出了一种基于SwinTransformer的联合信源信道编码算法(STJSCC),主要针对传统的CNN对图像语义特征提取性能欠佳等问题。STJSCC将多尺度大核注意力机制(MLKA)与SwinTransformer相结合,通过MLKA初步提取图像的局部信息和长距离依赖性,然后通过SwinTransformer提取更丰富的长距离、全尺度的图像语义特征。最后AWGN信道模型的仿真实验表明,STJSCC的PSNR和MS-SSIM指标都优于传统的DeepJSCC和SemViT方法。
参考文献:
[1] XU J,AIB,CHEN W,et al.Wireless ImageTransmission Using Deep Source Channel Coding with AttentionModules[J].IEEE TransactionsonCircuitsand Systems for VideoTechnol0gy,2021,32(4):2315-2328.
[2]朱晓庆,杨红,陈洪刚,等.面向机器视觉任务的自适应语义通信[J].通信技术,2023,56(9):1043-1050.
[3]ZHANGW,ZHANGH,MAH,etal.PredictiveandAdaptive Deep Coding forWireless Image Transmission inSemantic Communication [J].IEEE Transactionson WirelessCommunications,2023,22(8):5486-5501.
[4] YANG K,WANG S,DAI J,et al. SwinJSCC: TamingSwin Transformer for Deep Joint Source-Channel Coding[J/OL].arXiv:2308.09361 [eess.SP].[2024-10-20].https://arxiv.org/abs/2308.09361.
[5]BOURTSOULATZEE,KURKADB,GUNDUZD.Deep Joint Source-Channel Coding for Wireless ImageTransmission [J].IEEE Transactions on Cognitive Communicationsand Networking,2019,5(3):567-579.
[6] YOO H,DAIL,KIMS,etal.On theRole of ViTand CNN in Semantic Communications: Analysis and PrototypeValidation[J].IEEEAccess,2023,11:71528-71541.
[7]YEH,LIGY,HUANGBHF,etal.ChannelAgnostic End-to-End Learning Based Communication Systemswith Conditional GAN [C]//2018 IEEE Globecom Workshops(GCWkshps).Abu Dhabi:IEEE,2018:1-5.
[8]郭畅,何占豪,杨君刚,等.图像语义通信技术综述与展望[J].电讯技术,2025,65(2):329-338.
[9]WANGY,LIYS,WANGG,et al.Multi-scaleAttentionNetwork for Single Image Super-Resolution[C]//2024IEEE/CVF Conference on Computer Vision and Pattern RecognitionWorkshops(CVPRW).Seattle:IEEE,2024:5950-5960.
[10]LIUZ,LINYT,CAOY,et al.Swin Transformer:Hierarchical Vision TransformerUsingShiftedWindows[C]//2021IEEE/CVF International Conference on Computer Vision (ICCV).Montreal:IEEE,2021:9992-10002.
作者简介:廖潇(2000.04—),男,汉族,四川仁寿人,硕士研究生在读,研究方向:语义通信。