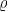
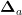
中图分类号:TP181;TP301.6;TP242 文献标识码:A 文章编号:2096-4706(2025)07-0103-06
Abstract: Aiming atthe problem that unconstrained exploration maycause damage to the mobile car,thisstudy proposes a ReinforcementLearning methodthatcombinesadaptive noiseexplorationandLagrangemultiplierconstraints,aiming tooptimize thetrajectoryplaningofthecarreachingthe targetpoint.Thismethodimprovestheexplorationefciencybydynamically adjusting the noise,uses the TD3algorithmtodeal with thecontinuousaction space,and uses the Lagrange multiplier method to deal withtheconstraints,whichis diferentfromthe wayofaddingthepenaltyofunexpectedbehaviordirectlyintheMarkov Decision Process(MDP).Simulation experiments show that this methodcan effectively guidethecar to avoid obstacles,educe theviolationofconstraints,andensurethesafetyandreliabilityofthetask,showinggoodtrainingconvergencecharacteristics.
Keywords: SafetyReinforcementLearning; ConstrainedMarkovDecision Proces;trajectoryplanning;TD3algorithm
0 引言
随着自动化技术的飞速发展,机器人技术已在工业制造、服务业等众多领域得以广泛应用[1],成为提升作业效率与操作精确度的关键要素。尤其在动态且不确定的环境中,机器人的轨迹规划至关重要,其直接关乎机器人的性能表现以及安全操作。然而,传统的轨迹规划方法常常难以适应快速变化的环境,在保障安全性方面也存在局限性。近年来,强化学习作为一种行之有效的机器学习方法,在机器人轨迹规划领域得到了广泛应用。通过与环境进行交互,机器人能够自主学习到最优的行为策略。不过,大多数强化学习方法主要侧重于性能的优化,对安全性的考量不够充分,这在实际应用中可能引发严重的安全风险。
在安全强化学习(SafeReinforcementLearning,SRL)领域,目前还没有算法能够在所有情形下杜绝违反安全约束的情况发生。安全问题已然成为强化学习中一个活跃的研究领域[2],大量研究聚焦于探索怎样在训练或者决策过程中融入安全保障措施。然而,鉴于强化学习依靠与环境的交互来学习策略,这种探索特性致使在未知环境中达成绝对安全异常艰难。一些理论方法,比如模型预测控制(ModelPredictiveControl,MPC),或者在约束马尔可夫决策过程(Constrained MarkovDecisionProcess,CMDP)中保障安全的方法,通常假定对环境有全面的了解。那些依赖环境模型的方法,像基于模型的强化学习[]其安全保障程度受限于模型的准确性。
在模型与实际环境存在差异的情况下,要实现零约束违反颇具难度。有鉴于此,本研究提出一种基于安全强化学习的机器人轨迹规划方法。该方法旨在构建一个能在环境中高效规划轨迹的机器人系统,以满足实际应用中的软约束需求。软约束的引入,为系统设计和运行赋予了更大的灵活性,通过巧妙设计和执行约束,可显著提升系统的安全性。此外,本方法引入先进的安全策略,以降低机器人在探索新环境时出现潜在危害的可能性。在现有的强化学习算法中,无论是基于模型的方法还是基于策略的方法,在实际应用中都存在一定局限性,比如智能体训练时间过长、性能难以稳定收敛,以及容易进入危险区域致使智能体受损等问题。在相关研究中,研究者通过给智能体添加相关约束,提出了基于信任区间的CPO[4](ConstrainedPolicyOptimization)算法,该算法能有效应用于高维度任务。高斯过程 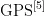 (GaussianProcess)也常被用于为非确定性因素建模,以确保规划过程的安全性。本研究未采用CPO算法,而是选用结合off-policy特性的TD3算法,利用其在连续动作空间中的高效性,以及借助拉格朗日[乘子处理约束的能力,同时引入动态噪声调整机制以增强探索效率和适应性。这种方法能够在控制探索程度的同时,确保算法遵循安全或其他类型的约束。基于现有的强化学习算法,本文构建了一个兼顾安全性[考量的强化学习框架,该框架能够有效地平衡探索与安全性,实现轨迹规划过程中的软约束。通过一系列仿真实验验证了本方法的有效性,实验结果表明,与传统方法相比,本文方法在保障安全性的同时,还提高了轨迹规划的效率和准确性。
(GaussianProcess)也常被用于为非确定性因素建模,以确保规划过程的安全性。本研究未采用CPO算法,而是选用结合off-policy特性的TD3算法,利用其在连续动作空间中的高效性,以及借助拉格朗日[乘子处理约束的能力,同时引入动态噪声调整机制以增强探索效率和适应性。这种方法能够在控制探索程度的同时,确保算法遵循安全或其他类型的约束。基于现有的强化学习算法,本文构建了一个兼顾安全性[考量的强化学习框架,该框架能够有效地平衡探索与安全性,实现轨迹规划过程中的软约束。通过一系列仿真实验验证了本方法的有效性,实验结果表明,与传统方法相比,本文方法在保障安全性的同时,还提高了轨迹规划的效率和准确性。
1强化学习
1.1强化学习基本原理
机器学习[大致可分为监督学习、无监督学习和强化学习(ReinforcementLearning)。强化学习考量智能体与环境相互作用的范式,其目标是学习使奖励最大化的行为。在每个离散时间步t,给定状态s ,智能体依据策略 π 选择动作 a ,获取奖励 r ,环境随之进入新状态  。收益被定义为奖励的折现总和
。收益被定义为奖励的折现总和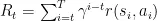 ,其中γ为决定短期奖励优先级的折现因子,强化学习框架如图1所示。
,其中γ为决定短期奖励优先级的折现因子,强化学习框架如图1所示。
环境Environment 奖励Reward 状态State 动作Action 智能体Agent
1. 2 深度强化学习
深度强化学习(DRL)是一种新兴的人工智能技术,它融合深度学习和强化学习的优势,以解决高维系统的决策问题。因此,DRL已被应用于复杂场景下的机器人路径规划,并获得了更高效、准确的解决方案。强化学习算法适用于马尔科夫决策过程MDP[(MarkovDecisionProcess),由于生活中除离散动作外,更多问题的状态是连续且维度极高的,故而引入神经网络来解决这类问题。深度强化学习(DeepReinforcementLearning)能够很好地处理此类问题,它借助深度函数的近似能力(高维度输入的特征缩放)以及强化学习的泛化能力,使智能体可以应对具有高维离散或连续状态/动作的复杂环境,比如控制机器人转向、读取传感器数值等。DRL方法需要动作值函数的近似值,通常采用深度神经网络 (DNN)来描述庞大的离散空间。然而,用DNN或其他函数近似表示的策略系统,其性能颇具挑战性,这对于有安全要求的系统而言尤为关键。基于DNN的强化学习算法在稳定性分析方面存在局限性。DQN是常用的深度强化学习算法,它是Q-Learming与神经网络(NeuralNetworks)相结合的产物。DQN中有两个结构相同但参数不同的网络,一个用于预测 Q 估计,另一个用于预测 Q 现实。 Q 估计网络采用最新参数,Q 目标网络则使用较早之前的参数, Q 现实的目标  算如式(1)所示:
算如式(1)所示:
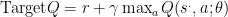
式中, r 为基于当前观测状态所做出动作所获得的奖励值, γ 为衰减函数一般默认为0.99, θ 为 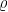 网络的参数。根据Target
网络的参数。根据Target 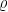 与 Q 估计得到损失,损失函数一般采用均方差损失表示,损失函数如式(2)所示,更新公式如式(3)所示:
与 Q 估计得到损失,损失函数一般采用均方差损失表示,损失函数如式(2)所示,更新公式如式(3)所示:
初始化现实网络和目标网络后,依据损失函数对现实网络的参数进行更新,在此期间目标网络参数保持固定。经过若干次迭代后,把现实网络的参数复制给目标网络,接着再次循环迭代,直至Targe  的值收敛,最终实现算法更新的稳定状态。
的值收敛,最终实现算法更新的稳定状态。
1.3 安全强化学习
安全强化学习,也就是约束强化学习,指的是在强化学习的学习训练阶段,着重关注安全性的方法。尽管强化学习[](RL)在模拟环境中取得了显著成功,但将RL应用于现实世界仍面临诸多挑战,其中最主要的便是安全问题。目标约束是现实应用中最常见的约束之一,也是安全强化学习里极具挑战性的问题之一。对于诸如一些机器人运动、操作[等众多具有挑战性的任务而言,满足约束条件是必要的。鉴于大多数神经网络是在模拟环境中训练的,当动作部署到现实的机器人[12]上时,安全约束就显得极为重要。
在安全强化学习(Safe ReinforcementLearningSRL)领域,目前尚无一种算法能够在所有情形下确保完全避免违反安全约束。安全问题在强化学习中是一个十分活跃的研究领域,众多研究工作都在探寻如何在训练过程或决策过程中融入安全保障措施。然而,由于强化学习依赖与环境交互来学习策略,这种探索特性致使在未知环境中保证绝对安全极为困难。目前,已有不少科研人员开发出各种方法,以避免在真实世界实验时出现不安全行为。例如对非期望行为的惩罚[13],该方法是通过代价值来间接惩罚奖励值,也就是将对非期望行为的惩罚添加到马尔科夫决策过程(MDP)的奖励函数中。
本文研究了约束马尔可夫决策过程(CMDP)框架中的约束RL[14问题,该框架由一个元组 ( S , A , P , r c )构成,其中 S 为状态空间, A 为动作空间, P:S × AS 为确定性状态转移函数, r⋅Sr 为奖励函数, 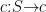 为代价函数。在此设定下,假设动态转移方程 P 和成本函数
为代价函数。在此设定下,假设动态转移方程 P 和成本函数 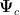 均未知,需从获取的数据中进行学习。策略
均未知,需从获取的数据中进行学习。策略 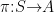 是从状态空间到动作空间的映射。
是从状态空间到动作空间的映射。 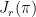 为策略 π 的预期收益,即对应奖励函数 r ,而
为策略 π 的预期收益,即对应奖励函数 r ,而 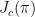 为策略 π 的预期损失,即对应成本函数
为策略 π 的预期损失,即对应成本函数 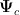 。具体定义为:
。具体定义为: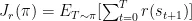 ,
, 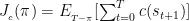 其中 T 为时间范围,
其中 T 为时间范围, 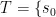
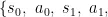 ⋅ s 3 为由 π 收集的轨迹[15]。
⋅ s 3 为由 π 收集的轨迹[15]。
2 本文改进的算法
2.1 约束价值网络
与Reward_Critic网络类似,本研究引入一个CostCritic网络,该网络用于生成在每个观测环境下做出动作所导致的违反约束的值,以此评估在特定观测环境中执行动作引发的约束违反程度。同时,智能体与环境交互后获得的损失值存储于经验缓冲池中,以便TD3算法在训练智能体时能够同步训练神经网络。为计算训练过程中产生的约束值,需要在智能体与环境交互的每一步都计算cost值。以状态state和动作action作为输入,其中state包含机器人的位置、朝向以及与各个危险区域的距离等信息。该网络第一层隐藏层大小为256,第二层大小也为256,最终输出一个值,此值会被存入经验池中,供神经网络离线学习。约束价值网络如图2所示。
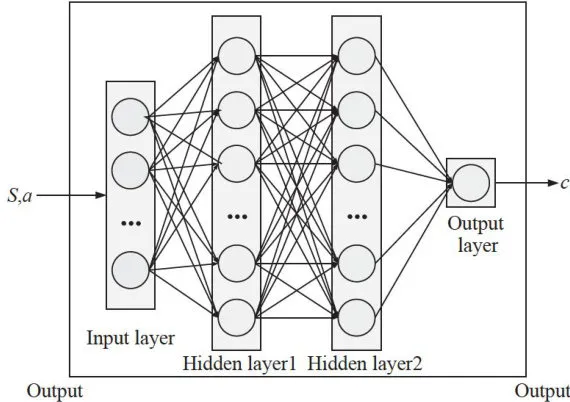 图2约束价值网络
图2约束价值网络2. 2 自适应探索噪声
修改策略网络的输出,使动作选择包含基于动态调整的噪声,这一过程涉及总迭代次数的变化。在探索策略中引入基于动态变化标准差的噪声,随着学习进程推进逐渐降低噪声水平,有助于算法在初期进行广泛探索,后期则更聚焦于运用已学到的知识。递减噪声的计算如式(4)所示,动作的选择由式(5)所示:
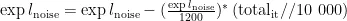
其中 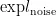 为探索噪声,
为探索噪声, 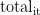 为与环境交互的总次数。
为与环境交互的总次数。
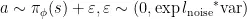
其中var为与 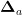 具有相同形状的张量,大小全部初始化为1,最终返回一个与
具有相同形状的张量,大小全部初始化为1,最终返回一个与 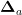 大小相同的张量,其中的每个元素都是根据均值为0,标准差为
大小相同的张量,其中的每个元素都是根据均值为0,标准差为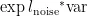 的正态分布所生成的随机数。
的正态分布所生成的随机数。
2.3拉格朗日乘子约束
无模型的约束强化学习方法,如基于拉格朗日的方法,旨在最大化累计奖励,由式(6)所示,同时将违反约束的成本限制在目标约束违反值 d ∈ ( 0 + ∞ )。
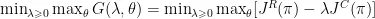
拉格朗日乘子更新如式(7)所示。其中 η λ 为拉格朗日乘子λ的学习率。
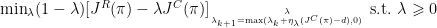
基于有约束型TD3的动态探索噪声改进算法的整体框架如图3所示。
3 实验结果与分析
在本节研究中,通过仿真环境对结合自适应噪声探索的约束型TD3方法的可行性进行了评估,并将其与几种off-policy强化学习算法开展了对比实验,实验结果证实了该方法的优越性。通过这种对比分析,本研究旨在展现所提出方法在处理约束型强化学习问题时的有效性与效率,尤其是在自适应噪声探索机制的助力下,如何提升算法的性能与适应性。
3.1实验仿真环境配置
本系统所使用的硬件设备为DESKTOP-T3PCVKP,其内置的GPU芯片型号为GeForceRTX1 0 5 0 T i ,处理器为IntelCorei5-8300HCPU @ 2.30GHz,内存为 1 6 G B 。
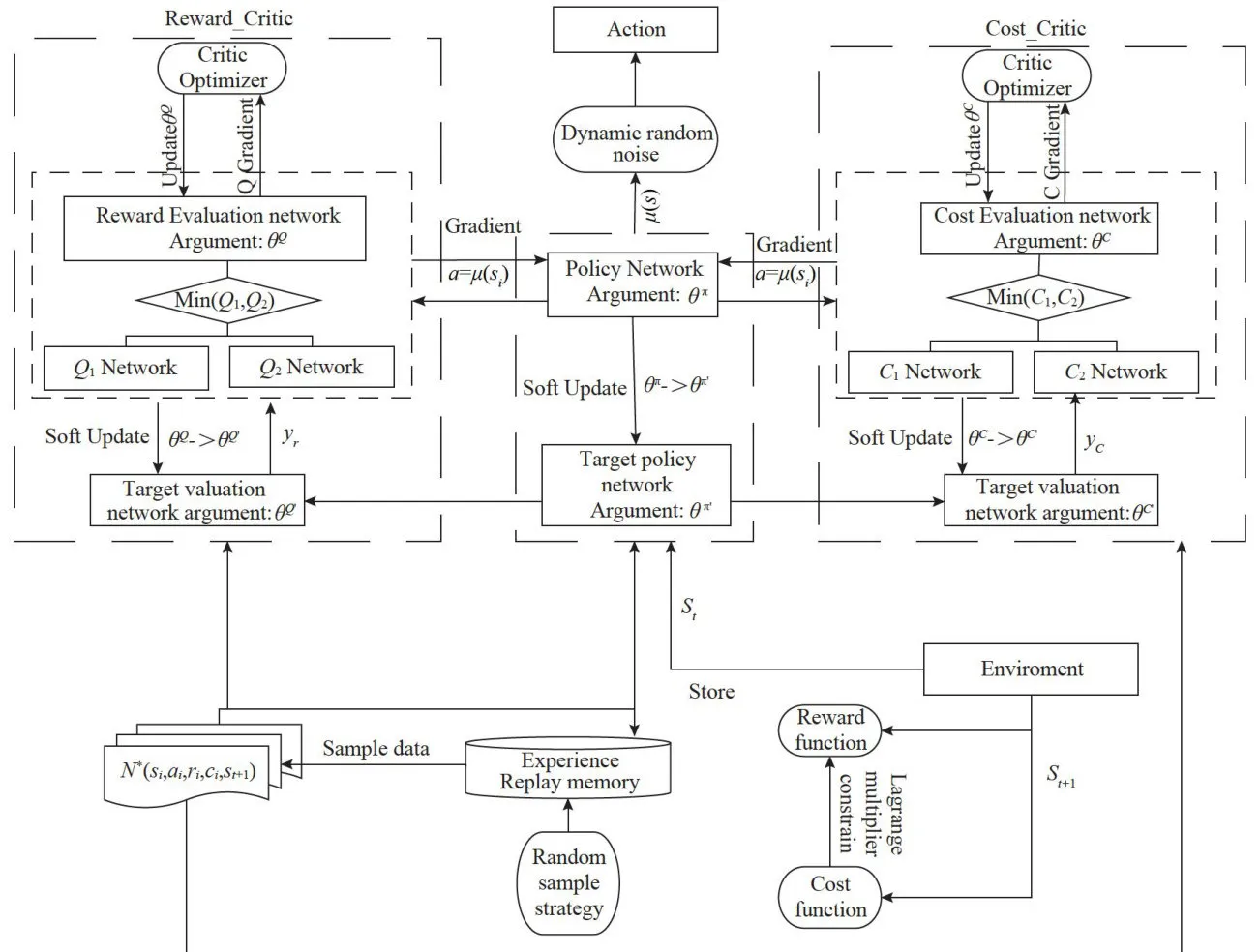 图3算法整体框架
图3算法整体框架本方法的实验在Ubuntu系统的SafetyGym环境中开展,OpenAI团队最早推出一套用于加速安全探索研究的工具SafetyGym。该工具包基于MuJoCo 物理引擎,采用OpenAI的Gym接口,并且与许多当前的强化学习库能够无缝集成。SafetyGym由以下两部分组成:
1)一个环境创建器,允许用户通过混合搭配各种物理元素、目标以及安全要求,创建新的环境。
2)一套预先配置的基准环境,仿真环境如图4所示,用于助力标准化定量评估安全强化学习方法的优劣。在所有SafetyGym环境中,机器人都必须在复杂环境里进行导航,以完成任务。仿真环境中有三个预先设定的机器人(Point、Car、Doggo),三项主要任务(Goal、Button、Push),且每个任务都设有两个难度级别。
基于Mujoco引擎构建了移动小车模型仿真系统,并将其应用于导航到目标点的场景[1中,如图4所示。移动小车模型仿真系统包含四轮小车、危险区域、目标点以及三轮小车的仿激光雷达。Agent是一种较为复杂的机器人,可在三个维度上移动,具备两个独立驱动的平行轮和一个自由滚动的后轮。对于该机器人而言,转向以及向前/向后运动均需两个驱动器协同工作。
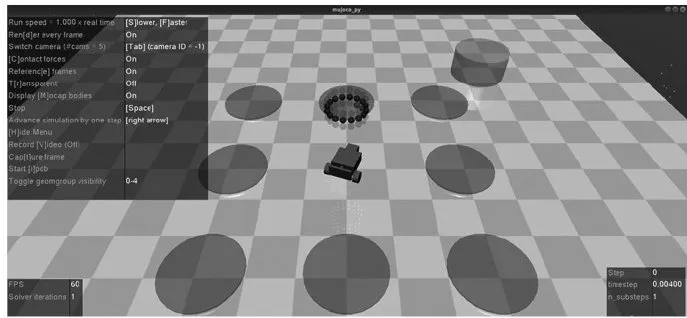 图4仿真环境示意图
图4仿真环境示意图在训练过程中,各个算法需统一神经网络的参数配置[1,参数配置情况如表1所示。算法中有关拉格朗日约束和噪声的参数设置如表2所示。
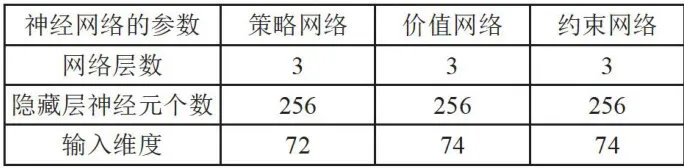 表1算法中神经网络的参数设置
表1算法中神经网络的参数设置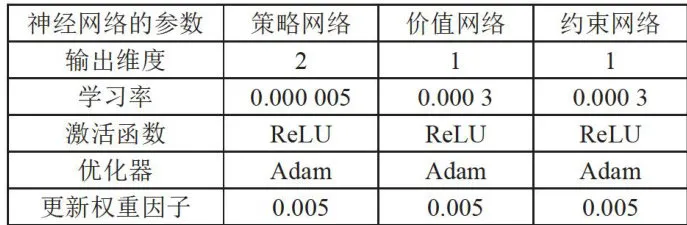 (续表)
(续表)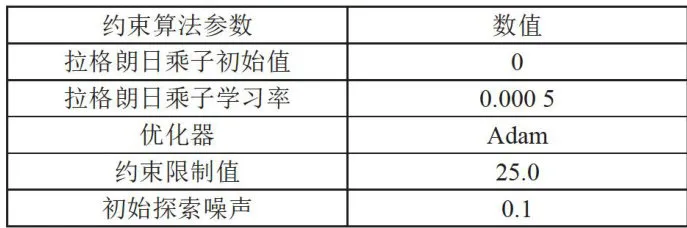 表2拉格朗日约束和噪声的参数设置
表2拉格朗日约束和噪声的参数设置3.2小车导航避障结果
搭载本文算法的智能体小车开展训练。当训练趋于稳定后,仿真结果显示,移动小车能够在导航至目的地的同时,减少违反约束的情况[17]。仿真效果如图5所示。
 图5导航仿真效果图
图5导航仿真效果图3.3 对比实验
根据数据缓存器中的数据,分别计算500次回合训练下DDPG、TD3、TD3Lag的损失函数值以及奖励优化性能。强化学习智能体以不断试错的方式学习,在训练过程中缺乏对环境的先验知识,所以可能会出现陷入危险区域的情形。例如,现实生活中的机器人在前往目标点时,需要尽可能避开危险区域,以防自身受损。为最大程度减少训练过程中对不安全动作的尝试,保证在尽量抵达目标的同时尽可能避免违反约束条件,该方法致力于实现长期奖励的最大化,同时最小化违规行为的出现。对比结果如图6、图7所示。
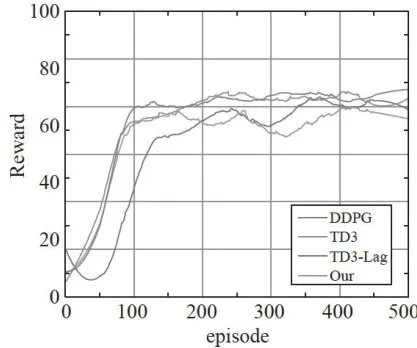 图6训练奖励曲线图
图6训练奖励曲线图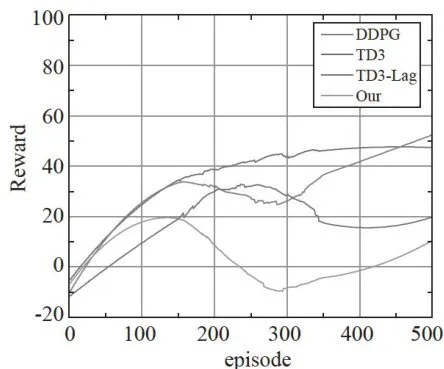 图7训练损失曲线图
图7训练损失曲线图图6展示了四种算法的学习曲线,其中“Our”代表本文提出的方法。图6为奖励曲线图,图7为损失曲线图。分析此图可发现,与其他三种算法相比,本研究所提方法在训练过程中呈现出更优的稳定性与可靠性,且实现了良好的收敛性能。需注意,在训练的前100个回合中,因算法尚未引入拉格朗日乘子惩罚损失函数,算法在探索阶段的试错可能致使成本值短暂上升。随着拉格朗日乘子的引入,算法开始有效管控成本,进而在后续训练中展现出更为稳定可靠的性能。这一现象表明,拉格朗日乘子的引入对优化算法的长期性能有着显著的积极影响。训练结果对比情况如表3所示。
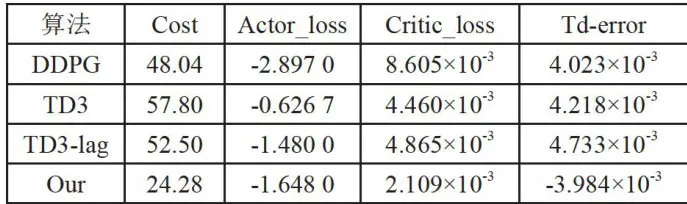 表3训练结果对比
表3训练结果对比4结论
本文提出一种旨在减少碰撞并优化到达目标点轨迹的规划方法。该方法确保了规划性能,显著提升了目标点附近的收敛速度与稳定性。此外,此方法已成功应用于设计场景中的规划任务。与现有的强化学习基准相比,本方法展现出卓越性能。未来研究方向将涵盖把该方法应用于实际机器人,并在动态复杂环境而非单一静态环境中加以测试,以进一步验证其适用性和鲁棒性。
参考文献:
[1]计时鸣,黄希欢.工业机器人技术的发展与应用综述
[J].机电工程,2015,32(1):1-13.[2]王雪松,王荣荣,程玉虎.安全强化学习综述[J].自
动化学报,2023,49(9):1813-1835.[3]MORALESEF,ZARAGOZAJH.AnIntroductionto
ReinforcementLearning[M]//SUCARLE,MORALESEF,
HOEYJ.DecisionTheoryModelsforApplicationsinArtificial
Intelligence:Conceptsand Solutions[S.I.]:IGI Global,2012:
63-80.
[4]ACHIAMJ,HELDD,TAMARA,etal.Constrained Policy Optimization [C]//Proceedings of the 34th International Conference onMachine Learning.Sydney:PMLR,2017,70: 22-31.
[5]SUIY,GOTOVOSA,BURDICKJ,etal.Safe Exploration for Optimization with Gaussian Processes [C]// International ConferenceonMachineLearning.Lille:PMLR, 2015:997-1005.
[6]LILLICRAPTP,HUNTJJ,PRITZELA,etal. Continuous Control with Deep Reinforcement Learning [J/OL]. [2024-10-03].arXiv:1509.02971[cs.LG].https://doi.org/10.48550/ arXiv.1509.02971.
[7] STOOKE A,ACHIAMJ,ABBEEL P.Responsive SafetyinReinforcementLearningbyPIDLagrangianMethods [J/OL].arXiv:2007.03964[math.OC].[2024-10-06].https://doi. org/10.48550/arXiv.2007.03964.
[8]IBARZJ,TANJ,FINNC,etal.Howto Trainyour Robot with Deep Reinforcement Learning:Lessons we have Learned[J].The International Journal ofRoboticsResearch, 2021,40(4-5):698-721.
[9]MARCHESINIE,CORSID,FARINELLIA.Benchmarking SafeDeep ReinforcementLearninginAquaticNavigation[C]//2o21 IEEE/RSJ International ConferenceonIntelligentRobotsandSystems(IROS).Prague:IEEE,2021:5590-5595.
[10]李潇宇,张君华,郭晓光,等.基于强化学习的机器人底盘能量管理与路径规划优化算法[J].农业工程学报,2024,40(21):175-183.
[11]聂振邦,于海斌.基于参考轨迹的移动机器人避碰决策及轨迹跟踪方法[J].计算机集成制造系统,2023,29(9):2879-2889.
[12]ISCENA,YUG,ESCONTRELAA,etal. LearningAgileLocomotion Skillswitha Mentor[C]//2021 IEEE International Conference on Robotics and Automation (ICRA). Xian:IEEE,2021:2019-2025.
[13]DALALG,DVIJOTHAMK,VECERIKM, et al. Safe Exploration in Continuous Action Spaces [J/OL]. arXiv:1801.08757 [cs.A1].[2024-10-10].https://doi.0rg/10.48550/ arXiv.1801.08757.
[14]RAMEZANIM,HABIBIH,SANCHEZ-LOPEZ JL,etal.UAVPath PlanningEmployingMPC-Reinforcement LearningMethod ConsideringCollision Avoidance[C]//2023 International ConferenceonUnmanned AircraftSystems (ICUAS). WarsaW:IEEE,2023:507-514.
[15]JIJ,ZHOUJ,ZHANGB,etal.Omnisafe:An Infrastructure for Accelerating Safe Reinforcement Learning Research[J].JournalofMachineLearningResearch,2O24,25 (285):1-6.
[16]ZHAOWY,HETN,CHENR,etal.Statewise Safe Reinforcement Learning:A Survey[J/OL]. arXiv:2302.03122 [cs.LG].[2024-0-16].https://doi.0rg/10.48550/ arXiv.2302.03122.
[17] FUJIMOTO S,HOOF H,MEGER D.Addressing Function Approximation Error in Actor-Critic Methods[J/OL]. arXiv:1802.09477[cs.A1].[2024-10-11].https://doi.org/10.48550/ arXiv.1802.09477.
作者简介:陈春甫(1999一),男,汉族,山西晋中人,硕士研究生在读,研究方向:强化学习、机器人系统;通信作者:穆煜(1978一),男,汉族,山西太原人,讲师,博士,研究方向:机器人运动控制与规划;韩凯涛(1999一),男,汉族,山西吕梁人,硕士研究生在读,研究方向:光电信息处理与通信技术。