中图分类号:TP391.1 文献标识码:A 文章编号:2096-4706(2025)08-0157-05
Abstract: In library service work, when facing local characteristic literature with a smalldata volume,library managers need to spend a great deal of time and efort manually organizing such local characteristic literature.In order to achieve automatedpre-clasificatinofcharacteristicliterature,thispaperproposestheCGBmodel,whichisanutomatedclasiiation modelforliteraturewithasmalldatavolume.TakingthecharacteristicliteraturedatasetofGuizhouProvinceas theexperimental object,the model conducts pre-training through GloVeand BERT,fuses the generated vectors,extracts andrepresents features throughTextC,andlasifsharactersticitratureofferentdatasales.Experimentalsultsidicatethatteaacy of the model with fused word vectors isat least 4 % higherthanthatof thebenchmark model.
Keywords: local characteristic literature; text classification; text vectorization
0 引言
在图书馆服务工作中,为展现地方特色建立地方文献库,图书馆管理人员需要将具有地方特色的文献从海量文献中挑选出来,与中图分类法不同,地方特色文献融合了多种类型文献,如:政治、科技、历史、小说等,却又与地方特色密切相关,将此类文献进行归纳整理需要耗费大量的时间与精力。通过特征提取对文献[1-3]进行分类,能够有效简化图书馆工作人员的工作内容。相较于大数据量动辄上万条的各种文献,地方特色文献具有小数据量的特点,以中图分类法为基础,每一个领域只有几百到几千条记录,这种数据量较小的情况使得传统的机器学习模型和分析方法在处理时可能不够有效,因此,在面对小数据量的文献分类时,仍然采用图书馆管理人员手工选择和提取特征。
在文献分类任务中,文献信息的相关性识别具有重要意义,语义信息的精确表达能够为文献的相关性识别提供可靠保障。目前,语义信息的精确表达主要采用大量文本数据进行词向量训练[4-5],但各个地区在建立地方特色文献库的过程中,相关文献的公开发表量并不大,在该领域中仅依靠语义信息实现文献相关度识别,会由于语义信息模糊造成文献相关性识别的准确率较低,现阶段,面向小数据量的文献分类任务仍然是通过人工完成,加大了员工工作量。为解决这一问题,本文提出了对小数据量的文献进行自动化预分类的方法,以实现文献的相关性识别及精准推荐。
为了满足小数据量的地方特色文献分类这一现实需求,本文采用贵州省部分特色文献作为实验数据,通过GloVe与BERT模型生成融合词向量后,结合TextCNN的深度学习方法,提出小数据量的文献分类模型融合词向量(ClassificationModelwithSmallDataVolumeBasedonBERT-GloVe),并且通过实验验证本文所提模型的有效性。
1 研究背景
为了实现文献自动分类,减轻人工负担,国内外大量研究人员对此进行研究,张雨卉[基于《中图法》分别从XMC和HTC对文献进行分类;吕琦等综合参考文献和文本内容信息,构建了引文词嵌入模型,对期刊文献进行学科分类;Sajid等[根据粒度主题分类的层次结构进行索引,通过可用元数据上进行多标签分类。
与大数据量的文献分类不同,小数据量文献具有数据特征少的特点,在有限的特征属性中挖掘潜在内容,可以有效增加模型的分类准确率,因此,文献数据中的文本信息需要加以利用,由于计算机无法对中文文本数据直接进行处理[9-10],衍生了大量的自然语言处理技术。易明等[1利用GloVe对在线研讨文本进行分类训练,结合BiLSTM层提取语义特征后实现最终分类;周燕[12]为了解决近义词、多义词的表征困难,采用GloVe模型表示词特征,充分利用全局信息和共现窗口的优势对文本进行向量化。针对一词多义问题,BERT模型由Devlin等[13]于2018年提出,该模型通过MASK(Masked-LM)任务以及NSP(NextSentencePrediction)任务,实现文本向量化。Li等[14]基于BERT提出了一种用句子序列代替词级序列的长文本相似度计算方法,解决了与长文本语义相关的应用的实际问题;陆佳丽[15]提出以Bert-TextCNN模型为基础且同时考虑标题、正文和正则判断的多标签分类方法,该方法在多标签分类任务中效果提升明显;Aziz等[利用BERT的上下文优势进行细微的语言理解,并采用双仿射注意力机制来精确描述单词关系,加强了其文本理解能力,并且能够迁移到其他语料中。综上所述,目前有大量学者对文本向量化进行研究,但面向中文文本向量化任务中仍然存在词向量表义不足的问题。
针对小语料库的文献分类问题,由于文献题目具有:专业性强;文本短,形成的上下文语境较小;文本数据小,训练数据小等特点。相较于其他文本向量化模型,GloVe模型在投入小量数据的短文本语料库的情况下,更能够充分利用语料库中的信息;BERT通过其深层的Transformer架构,能够动态地理解上下文,从而提高了对复杂语言结构的建模能力,使得词向量的表达更加完善。GloVe与BERT互相补充,相互完善,因此,本文提出融合GloVe模型与BERT模型地词向量表达模型,实现特征提取与表达后,对多类型特色文献进行有效分类。
2 模型设计
为了实现小数据量的文献精准分类,本文以知网爬取的贵州省特色文献作为实验数据,利用GloVe和BERT预训练生成的融合字向量矩阵[17],融合向量矩阵经过TextCNN进行特征提取后,通过全连接层得到最终的分类结果,本文使用准确率、召回率等指标对模型的有效性进行了充分评估。模型的整体结构如图1所示。
2.1 词向量转化模块
文本卷积神经网络无法识别字符,所以需要实现文本数据向量化。本文将原始数据经过清洗和分词任务后,通过基准模型生成字向量矩阵,经过融合层后得到该句子的融合向量矩阵。
在算法1中描述了基于GloVe与BERT的词向量融合方法:
算法1.融合词向量输入:初始数据集输出:短文本的向量矩阵初始化GloVe矩阵 X ,BERT矩阵 Y
1.FOR每条短文本DO
2.FOR每个字符DO
3. IF 字符不为空
4. 获取字符的GloVe词向量 x
5. 获取字符的BERT词向量 y
6. 扩展 x 维度到与 y 维度相同
7. 将 x 连接在 X 后
8. 将 y 连接在Y后
9. ELSE
10. X 与Y进行加权融合得到融合词向量矩阵
11. END IF
12. END FOR
13.返回融合词向量矩阵
14.ENDFOR
2.2特征提取分类模块
在文本向量化表示中,为优化数据结构,采用特征提取进行降维处理,本文使用文本卷积神经网络(TextCNN)对融合后的向量矩阵进行特征提取,以有效降低维度并提升模型性能。
在文本卷积神经网络中,卷积核通过滑动窗口对字符序列进行分析,以提取和组合文本特征,根据滑动窗口大小的不同,获取不同层次的语义信息。每个卷积核的宽度与字的维度相同,使得每次卷积操作都基于一个完整的字或词语。此外,每次卷积操作会加上一个偏置项,以增强模型的表达能力。为获取文本的特征值,采用最大池化方法,从特征向量中筛选出最大的特征值,从而使得模型提取出有效特征,提升分类任务的准确性。
在全连接层中,本文选取Sigmoid函数作为激活函数以实现二分类。若 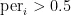 ,则类别为正,若
,则类别为正,若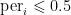 ,那么为负。
,那么为负。
3 实验分析
3.1 数据集
本实验以贵州特色文献库中的文献分类为例,采用贵州省特色文献为原始数据集共10632条,人工为其进行分类,其中以“贵州民族”为标签的文献共有2182条;以“贵州历史”为标签的文献共有2068条;标签为“贵州党政”的文献共有590条;标签为“贵州技术”的数据共有580条。将四组数据根据数据量组为“民族/历史”的数据集1与“党政/技术”的数据集2,分别由4250以及1170条数据组成,总数据共有5420条,数据集构成如表1所示,符合小数据量文献的标准,通过对该数据集的分类效果,可以证实该模型丰富小数据量文本语义的有效性。
进行文本清洗后,按照字粒度进行分词。选取每个数据集中的 20 % 为评估集,每个数据集中的剩余数据为训练集,数据集组成情况如表1所示。
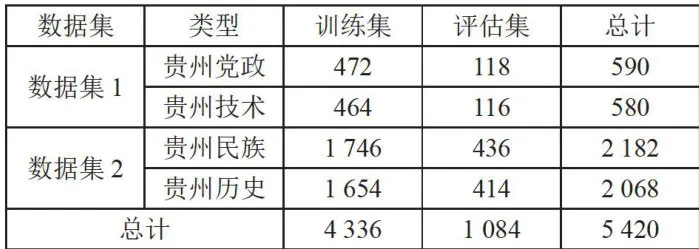 "表1数据集构成 单位:条
"表1数据集构成 单位:条3.2 评价指标
如表2所示,本文实验的评估指标包括:1)准确率(Accuracy):正确分类与数据总数之比。2)查全率(Recall):正确预测正类与实际正类样本数之比。3)查准率(Precision):正确预测正类与所有预测正类的样本数之比。4)F1值(F1),表示查全率和查准率的调和平均值。
 表2二分类混淆矩阵
表2二分类混淆矩阵可以将各类预测结果定义为:1)TP预测为历史且实际类别也为历史的结果。2)FN预测为民族但实际类别为历史的结果。3)FP预测为历史但实际类别为民族的结果。4)TN预测为民族且实际类别也为民族的结果。
根据这四个指标,可以进一步计算模型的评估指标:
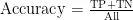
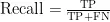
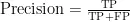
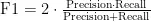
3.3 参数设置
本文使用300维度的GloVe词向量以满足词向量的准确描述。采用两层卷积结构减少计算复杂度。为了分析词语关系及主谓宾关系,卷积核大小设为2,以捕捉该长度的N-grams特征。具体参数如表3所示。
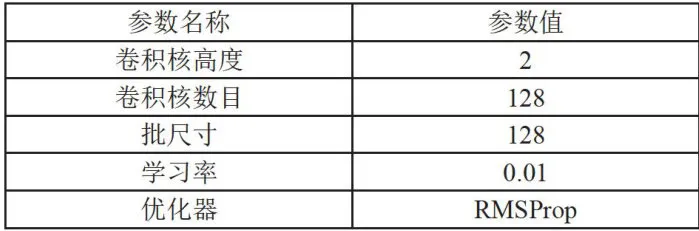 表3卷积层参数设置
表3卷积层参数设置3.4 结果分析
为了验证算法的有效性,本文使用不同大小的数据集进行实验。对比基线模型:GloVe-TextCNN及BERT-TextCNN,实验结果如表4所示。
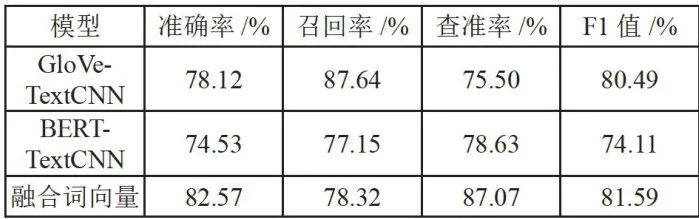 表4数据集1的实验结果数据集2在各个模型中,实验结果如图2所示。
表4数据集1的实验结果数据集2在各个模型中,实验结果如图2所示。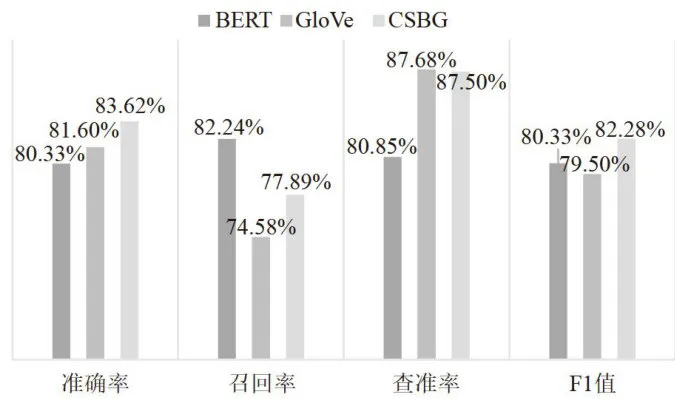 图2数据集2的实验结果
图2数据集2的实验结果由实验得出如下结论:
1)通过表4以及图2可发现,较小数据量时不同模型效果差异度要大于较大数据量时的模型效果。这是由于在小数据量的语料库中,依赖数据量的BERT模型的训练效果较差,而在GloVe与融合词向量模型的训练过程中,对数据量的依赖性较小。
2)融合词向量模型的表现优于单一模型。在1170条和4250条数据组成的语料库中,融合词向量模型的准确率均高于单一模型。在数据集1中,融合词向量模型比BERT提升了 8 . 0 4 % ,比GloVe高了4 . 4 5 % ;在数据集2中,本文提出的分类方法相比基准模型的精确率分别提升了 3 . 2 9 % 及 2 . 0 2 % 。
3)随着数据量的增加,融合词向量模型准确率的提升速率低于基准模型。这表明在增加数据量的情况下,BERT模型对性能的提升更为显著,同时GloVe也表现出了一定的提升。在数据量提升时,BERT词向量模型的准确率有了明显的大幅度提升,然而在特色文献数据库中,每个类别的数据量大多在1 0 0 ~ 1 0 0 0 这个小数据量范围,因此在小数据量时有更好分类效果的融合词向量能够更好地应用在特色文献分类这一应用场景。
4结论
本文提出一种针对小数据量的文本分类方法,通过结合GloVe和BERT的优点优化文本信息的表达,采用卷积神经网络可以有效提取文本中的局部特征,适合于处理短文本或句子,增强分类模型的性能。
本文详尽阐述了融合词向量模型,并通过实验,模型在不同数据集上的表现得到了充分评估,为其有效性提供了支持。这种融合方法显示了跨模型协同的潜力,尤其是在处理小规模数据集时,为后续研究提供了新的思路。在未来的研究中,可以引入注意力机制来加权融合不同来源的词向量,可能会进一步提升模型的表达能力和性能。
参考文献:
[1] ZHU B,PAN W. Chinese Text Classification MethodBased on Sentence Information Enhancement and Feature Fusion[J/OL].Heliyon,2024,10(17):e36861[2024-09-25].https://doi.org/10.1016/j.heliyon.2024.e36861.
[2] LI J,TANG C,LEI Z,et al. KRA: K-NearestNeighbor Retrieval Augmented Model for Text Classification [J/OL].Electronics,2024,13(16):3237[2024-09-25].https://doi.org/10.3390/electronics13163237.
[3] SARIN G, MUKUND P K M. Text Classification UsingDeep Learning Techniques: A Bibliometric Analysis and FutureResearch Directions [J].Benchmarking: An Intermational Journal,2024,31(8):2743-2766.
[4]王钦晨,段利国,王君山,等.基于BERT字句向量与差异注意力的短文本语义匹配策略[J].计算机工程与科学,2024,46(7):1321-1330.
[5]孙清华,邓程,顾振宇.结合词向量和自注意力机制的设计素材推荐系统[J].计算机辅助设计与图形学学报,2024,36(1):63-72.
[6]张雨卉.基于《中国图书馆分类法》的文献自动化深层分类的研究和实现[J].图书馆杂志,2024,43(3):61-74.
[7]吕琦,上官燕红,李锐.基于参考文献和文本内容学科分类的跨学科测度研究[J].情报学报,2024,43(8):976-991.
[8] SAJID N, AHMAD M,RAHMAN UA, et al. A NovelMetadata Based Multi-Label Document Classification Technique[J].Computer Systems Science and Engineering,2023,46(2):2195-2214.
[9]谭可人,兰韵诗,张杨,等.基于多层级语言特征融合的中文文本可读性分级模型[J].中文信息学报,2024,38(5):41-52.
[10]沈思,陈猛,冯暑阳,等.ChpoBERT:面向中文政策文本的预训练模型[J].情报学报,2023,42(12):1487-1497.
[11]易明,李藿然,刘继月.基于GloVe-BiLSTM的在线研讨信息分类模型研究[J].情报理论与实践,2022,45(9):173-179.
[12]周燕.基于GloVe模型和注意力机制Bi-LSTM的文本分类方法[J].电子测量技术,2022,45(7):42-47.
[13] DEVLIN J,CHANG M W,LEE K,et al. BERT:Pre-Training of Deep Bidirectional Transformers for LanguageUnderstanding [C]//Proceedings of the 2019 Conference of theNorth American Chapter of the Association for ComputationalLinguistics: Human Language Technologies, Volume 1(Longand Short Papers).Minneapolis:ACL,2019:4171-4186.
[14] LI X,HU L L. Chinese Long Text SimilarityCalculation of Semantic Progressive Fusion Based on Bert [J].Journal of Computational Methods in Sciences and Engineering,2024,24(4-5):2213-2225.
[15]陆佳丽.基于Bert-TextCNN的开源威胁情报文本的多标签分类方法[J].信息安全研究,2024,10(8):760-768.
[16] AZIZ K, JI D,CHAKRABARTI P,et al. Unifying Aspect-BasedSentimentAnalysisBERTandMulti-LayeredGraph Convolutional Networks for Comprehensive SentimentDissection [J].Scientific Rep0rts,2024,14(1):14646[2024-09-06]. https://www.nature.com/articles/s41598-024-61886-7.
[17]邵一博,秦玉华,崔永军,等.融合多粒度信息的用户画像生成方法[J].计算机应用研究,2024,41(2):401-407.
作者简介:陈蓝(1997—),女,汉族,重庆人,助理馆员,硕士,研究方向:信息管理与信息服务、文本挖掘;周杰(1992一),男,汉族,湖北安徽人,副研究馆员,硕士,研究方向:数据挖掘、智能检索;通信作者:杨帆(1969一),男,汉族,贵州贵阳人,教授,博士,研究方向:知识组织与知识工程、文本挖掘。