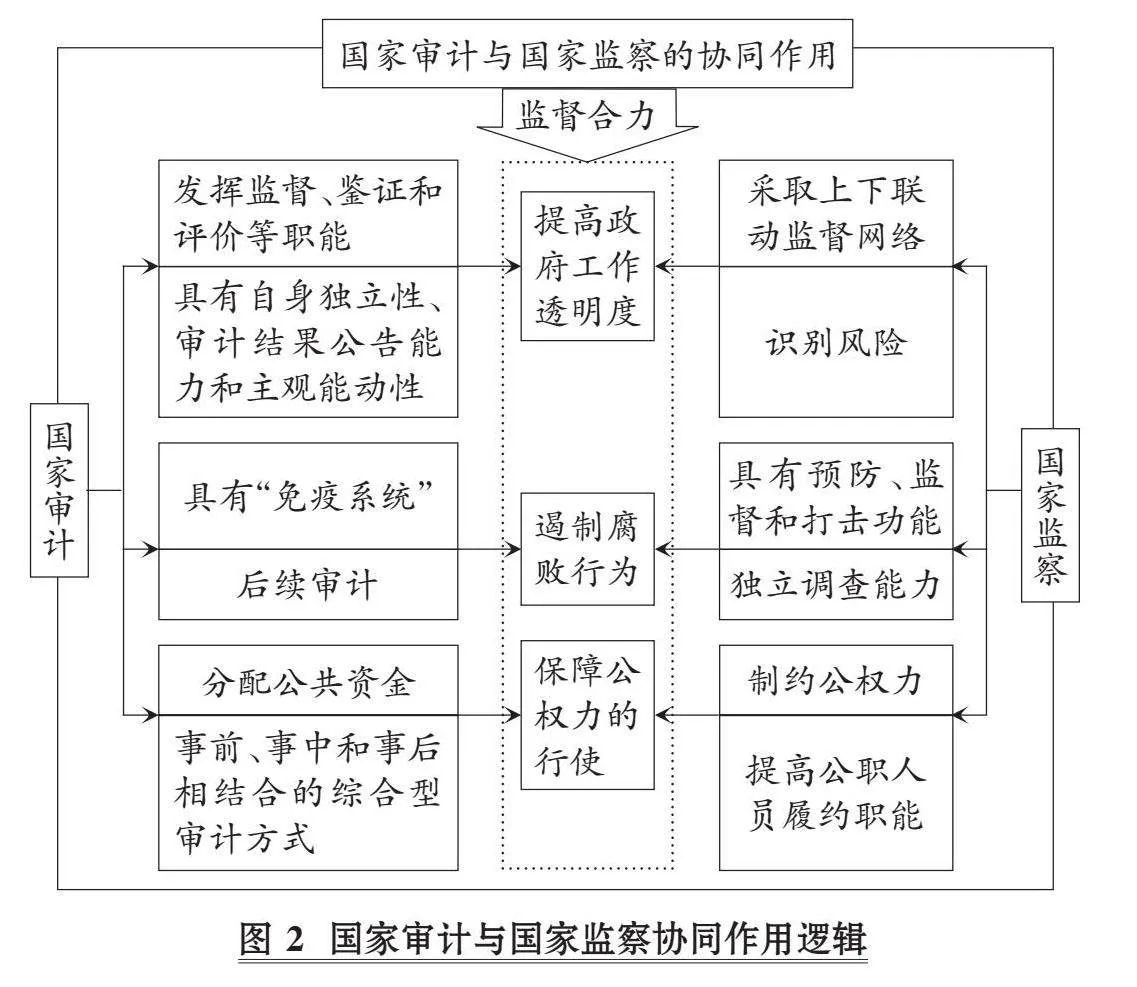
张忠进,王嘉伟,杨洁,徐鹏
(浙江农林大学暨阳学院 工程技术学院,浙江 诸暨 311800)
0 引 言国家精品课程是教育部通过一系列认定标准,推选出具有一流教师队伍、一流教学内容、一流教学方法、一流教材的课程,提供学生学习。国家精品课程的认定不仅有利于学生高效学习,也是对教师的教学工作极大程度上的肯定。目前,教育部为了贯彻落实以人为本的教学理念,深化教育体系的改革发展,大力推出了上千门国家精选课程。在2017年宣布首批国家精品课程中有468 门本科课程以及22门专科高等职业教育课程申报成功。第二批申报中,有690门本科课程以及111 门专科高等职业教育课程申报成功。随着多元化教学方式的发展以及慕课平台的发展,已有越来越多的课程评为国家精品课程。
中国慕课自2013年起步,从“建、用、学、管”等多个层面全面推进,目前上线慕课数量超过3.4 万门,学习人数达5.4 亿人次,慕课数量与学习规模已位居世界第一。伴随着慕课发展的契机,这种以互联网作为基础媒介,以学生为中心进行远程教学,满足学生的多样化需求的教学模式应运而生,它是信息技术与教育教学深度融合的结晶。在这个信息化的浪潮中,慕课的应用对教学是一种巨大的挑战。各所高校及时抓住这个机遇,将技术与教学进行结合,丰富教学模式,提高教学质量,旨在为学生提供优质的教学服务。
国家精品学科直播课作为高校在线教育产业的领军者和风向标,需要具备一定的学术地位以及社会影响力。构成一门国家精品网课往往需要具备以下几个特点:
(1)具备极强的专业性,该门课程为同科目、同领域内的经典课程,通用性强,普适性广,严谨性高,借鉴性好。
(2)具有较好的创新性,能够融合新时代互联网思维以及互联网授课形式,在合理运用先进技术的同时起到良好的教育效果。
(3)具有一定的社会影响力,国家精品课程作为学科建设的标杆,对广大高校相关科目的教学内容具有一定的指导作用和借鉴意义,教学形式和教学内容能够被广泛高校学生所接受。
虽然国家出台了相关的政策规定,说明评判了国家精品课程的要求,但实际上评判仍然没有十分准确的标准。基于此,需要一种评价模型来判定国家精品课程。王等人使用AHP 模型对精品课程评价指标进行研究,构建了AHP 指标层次模型,采用相对尺度定量的两两相互比较,构造判断矩阵,依据判断矩阵结果计算出指标的权重赋值。严军用基于NVivo 的方法对国家级精品课程评价进行研究,运用NVivo 质性分析工具,从视频内容、互动答疑、团队建设、课程资料四个维度对国家级精品课程进行分析。杨等人针对精品课程评估指标的模糊性,构造了模糊综合评价模型,开发了精品课程模糊综合评审系统。模糊评价子模块采用层次结构形式,实现了对评价信息的处理分析,以得到最优解。李火光针对我国精品课程网站及网络资源建设实际情况,分析了精品课程网站网络资源特点,对精品课程网站网络资源作了分类介绍,使用层次分析法理论与方法,提出了4 个一级指标、12 个二级指标、43 个三级指标的分层次的国家级精品课程评价指标,并对各级指标建立重要性成对对比矩阵,计算确定了各一二三级指标重要性权值,构建了国家级精品课程评价指标体系。
综上所述,机器学习技术还未被应用于国家精品课程分类中。随着计算机技术的发展,机器学习被广泛的运用于各个领域当中。本篇论文结合当今机器学习技术,提出了一种基于机器学习的分类方法,为国家精品课程评定提供参考。
1 方法1.1 数据来源实验数据主要来源于中国大学MOOC,中国大学MOOC 是由网易与高教社携手推出的在线教育平台,承接教育部国家精品开放课程任务,向大众提供中国知名高校的MOOC 课程。全面覆盖大学课程。
研究过程主要采用2021年采集的数据进行分析,数据共有八个字段(参与人数,评论人数,开课次数,是否含有团队,每周学时,老师数量,老师得分,团队得分)。样本数据总体数量为8 964 条,采用分层采样的方法按照4:1的比例划分为训练集和测试集,即训练集包含 7171 条样本数据,剩余的1 793 条样本数据划分为测试集。为了更充分地了解数据,对样本数据采用探索性分析方法,更好地将特征工程前期工作做好。
1.2 数据清洗获取数据后,要对数据中的问题数据进行处理。一般情况下,针对不同的问题数据有着不同的处理方法。对于数据中不正确的数据,可以将其删除和使用字段的平均数或中位数代替。对于冗余的数据,将其删除。对于缺失的数据,盲目的删去样本值可能会造成样本数的减少,为了使这部分信息有效,可以采用平均数或中位数替代。
1.3 特征提取机器学习中通过特征的选择来影响模型的准确率和时间复杂度。综合考虑每个特征对模型预测结果以及对训练时间的影响,所以在训练之前需要对现有的特征进行提取。
特征提取阶段,为给后续的机器学习算法提供最有利的特征,需要分析数据中属性(参与人数,评论人数,开课次数,是否含有团队,每周学时,老师数量,老师得分,团队得分)与国家精品分类之间的关系。
对于具有正态分布、线性关系的连续数据,用皮尔逊相关系数是较为恰当且效率较高的一种方法。本文章数据恰好符合此特点,因此,采取皮尔逊相关系数来分析数据中各特征与国家精品分类间的相关度,相关系数的绝对值越大,相关性越强。各特征与国家精品课相关系数如图1所示。

图1 各特征与国家精品课相关系数图
从图中可以得出参与人数、评论人数、开课次数这三个特征与国家精品课分类的相关度最高。
为验证所分析出来的特征是否与国家精品课呈高相关性,以参与人数,开课次数特征为例,抽取了参与人数和国家精品分类,将课程分类从多分类表示成是否二分类(是国家精品、非国家精品),以参与人数和课程分类当做度量绘制树状图,矩形大小表示参与学生人数,矩形面积越大表示学生参与人数越多,深颜色表示国家精品课程,生成结果如图2所示。从图中我们发现选课学生人数越多,则越有可能是国家精品课程。从选课人数中可以看出,选课人数越多,说明学生对该课程的兴趣更高,课程的教学效果越好,有助于课程被评选为国家精品课。对开课次数这一特征进行了分析,绘制的树状图如图3所示。开课数次数越多,越来越多出现国家精品课程,出现极强的相关性。开设时长越长,也就意味着该课程是经得起时间考验的,是有必要开设的,对于学生的教育是起着重要意义的。
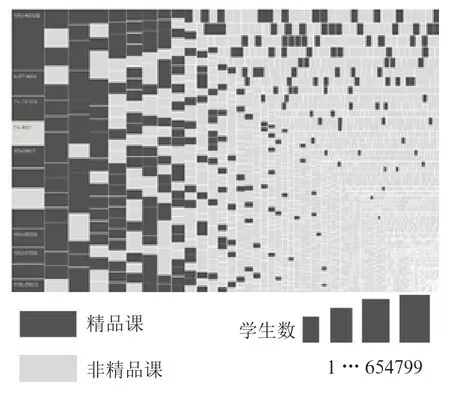
图2 参与人数与国家精品课关系图
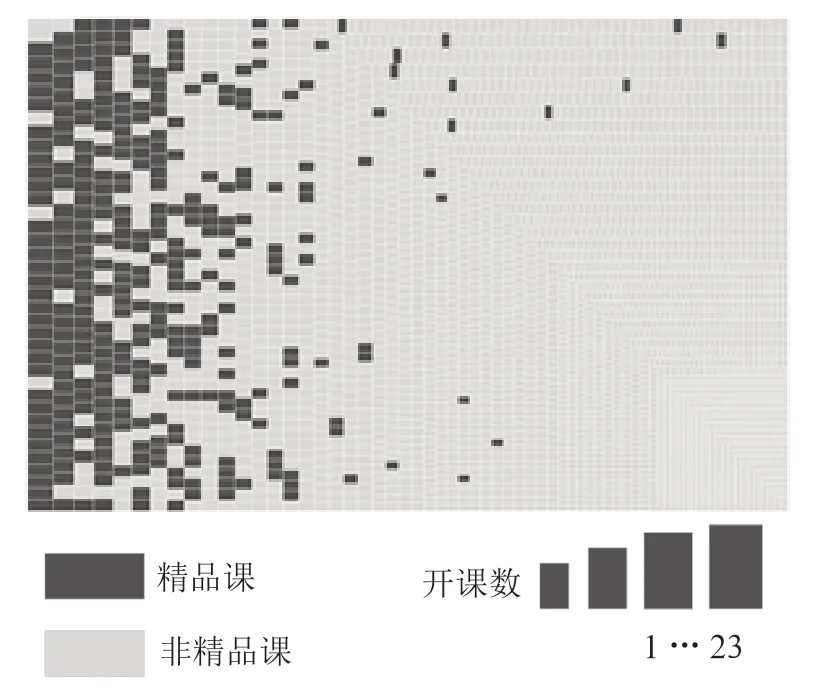
图3 开课次数与国家精品课关系图
同时为了验证使用皮尔逊相关系数分析出的低相关度特征是否与国家精品课呈低相关性,以老师数量特征为例。以老师数量和课程分类当做度量绘制树状图,矩形大小表示参与老师数量,矩形面积越大表示老师数量越多,深颜色表示国家精品课程,生成结果如图4所示。
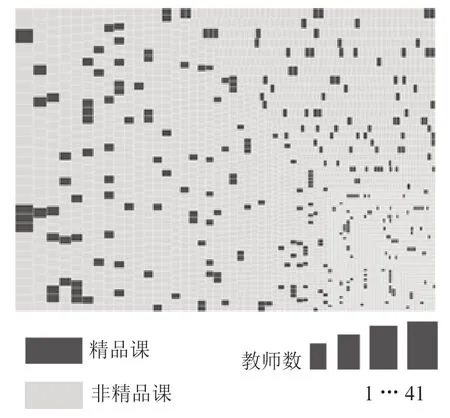
图4 老师数量与国家精品课关系图
从图4中可得出,教师数量度量大体上呈现均匀分布,无明显特征。因此教师数量与国家精品课程呈低相关性。
综上所述,使用皮尔逊相关系数分析各特征与国家精品分类间的相关度有着较好的效果。因此根据以上分析总结出了影响该学科成为国家精品课程具有高相关性的特征为:参与人数、评论人数、开课次数。
1.4 实验分析实验为达到对比效果,将使用多个机器学习算法:逻辑回归(LR),线性判别分析(LDA),K-近邻算法(KNN),分类回归树(CART),朴素贝叶斯(NB),支持向量机(SVM)。用以上算法对国家精品课程进行分类实验。
实验选取两组特征进行,一组为相关度最高的参与人数,评论人数,开课次数这三个特征,另一组为数据全部的八个特征,根据上述特征构建机器学习分类器,输入测试集得到分类模型,将测试集输入模型中,得到测试集的分类结果。各种机器学习算法在国家精品课程分类上的准确率如表1所示,其左侧准确率为使用三个特征的分类准确率,右侧准确率为使用八个特征的分类准确率。
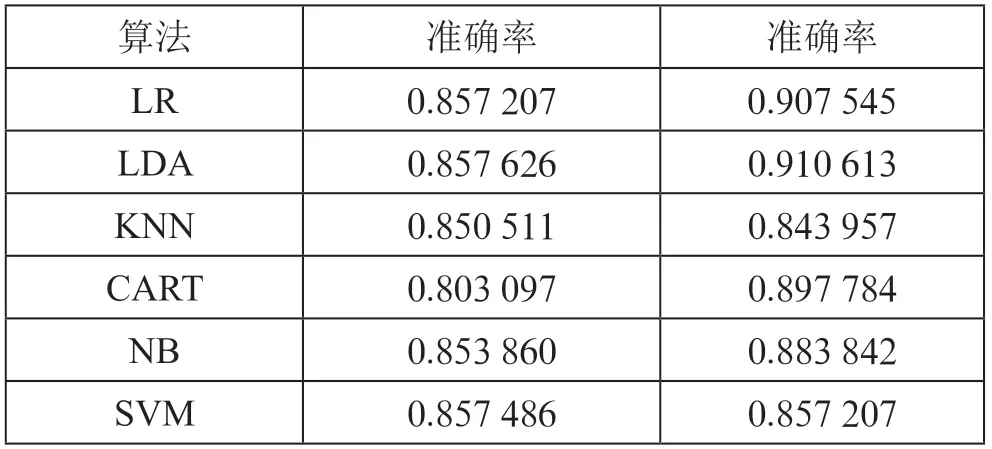
表1 各种机器学习算法在国家精品课程分类上的准确率
从实验结果中可得出KNN,NB,SVM 选用三个特征的机器学习分类器与选用了八个特征的机器学习分类器的准确率差距不大。在KNN 分类器中,选用八个特征的分类器反而比选用三个特征的分类器准确率要低。可见参与人数,评论人数,开课次数与国家精品课程的相关度较大。而在LR,LDA,CART 中,由于这类算法对特征数量的依赖较大,准确率的差距可高达5%以上。但是这类分类器选用的特征越多,训练以及分类的时间复杂度就越高。在考虑时间复杂度的情况下,选用参与人数,评论人数,开课次数这三个特征的机器学习分类器已经能够达到85.76%的准确率,展现出了较好的效果。
2 结 论在大数据时代下,越来越多的数据可以被获得,对于国家精品课程评定标准,本篇论文提出了基于机器学习的分类方法,并达到了不错的效果。可见通过机器学习技术来帮助分析评判国家精品课程是事半功倍的。
在今后的研究中,根据不同样本数据特点,灵活地选取多种算法和模型融合方式,结合更多的实际应用场景做出更多尝试性研究。做到对国家精品课程更精准的评价,为中国教育事业贡献更多的力量。