李新焕,黄伟力
(江西开放大学 江西工程职业学院,江西 南昌 330046)
0 引 言随着网络的普及和科技的发展,人们的社交活动方式从传统的书信联络到便捷的电子邮件,再到即时通信工具(如微信、QQ、微博等),可谓发生了翻天覆地的变化。与此同时,新浪微博为众人所熟知,尤其是大多数知名人士和企业用户都会在新浪微博上注册认证。在微博平台上大家可以畅所欲言,随时随地接收信息和发表观点。正是由于微博使用的便利性,一些网络水军会带偏某些热点事件的走势。因此,若要更好地控制网络舆情,优化网络中的信息质量,引导风清气正的网络环境至关重要。
Fang等利用所提出的用户名特征提取算法,对网络中的僵尸粉进行识别研究。Chu等对用户发表的内容及其账号属性进行研究分析,从中发现有绝大多数水军使用第三方接口发送内容,同时还发现所发布的内容具有重复性和定点性,相反正常用户很少会选择在晚上发文。Irani等对众多的社交网络账户进行了研究,成功建立一个巨大的静态用户个人资料内容分析案例库。通过比较几种机器学习算法,最终获得用以甄别水军用户的决策树算法。王淑琪等研究微博中正常用户和水军用户的差异,基于提取出的特征属性去识别微博水军,利用SVM算法对其进行分类,最后得到水军识别的模型。程晓涛将传统用户的属性及其行为特征相结合,得出一种全新的关系图,这也充分证明了新特征的使用对于水军的识别有了很大的提升。韩忠明等把用户成为水军的概率当作其属性特征及行为特征的隐变量,从而构建了用于计算用户成为水军概率的模型。
目前对水军的识别大都是基于对微博用户语言特征和行为特征的分析,由于社交网络的数据量巨大,微博内容也比较繁杂,因此内容本身的不确定性给水军的识别带来极大的挑战。文章通过微博中的用户信息对用户进行识别,从而提高网络水军识别的准确率,同时还能对网络舆情起到很好的控制作用,进而提高网络上的信息质量。
1 微博数据的获取与处理1.1 获取微博中的用户数据据统计,新浪微博中的用户占微博用户的三分之二以上,因此本研究主要针对新浪微博中的用户展开,利用新浪微博对外开放的API(应用程序编程接口)提取新浪微博中的数据。但由于API的升级限制,这就为从新浪微博中获取数据带来一定的困难,故本研究还采用网络爬虫(Web Scraper)辅助获取数据。作者曾经发表的文献中详细介绍了新浪微博API接口获取数据的过程,故在此不再赘述,读者可自行去参阅。
网络爬虫(Web Scraper)是一个轻量级的谷歌浏览器爬虫插件,用于任意抓取Web页面并使用几行JavaScript代码从中提取结构化数据。它能够加载Web页面并实现动态抓取。按照谷歌浏览器中的提示,下载Web Scraper并将其保存到本地,打开谷歌浏览器的扩展程序,打开开发者选项,将下载好的Web Scraper直接拖拽到里面,再返回到要抓取的页面,打开开发者工具,即可找到并进入Web Scraper的界面,新建站点地图并添加节点,选中要抓取的内容,最后将抓取到的数据以.xlsx或.csv的格式导出即可。
本研究总共获取了12 680条微博数据,对所获取的数据进行了清理,如填写少量缺失值、使噪声数据光滑、删除离群点的数据。为了使数据能够适用于SVM,对部分字段进行了规范化处理,最终选择其中3 600条数据作为样本集。
1.2 对微博的用户进行分类1.2.1 微博用户种类分析
本研究将微博中的用户分为四类:(1)正常用户。微博中正常使用账号的用户。(2)炒作型水军。一般由营销团队(如第三方组织或权威人士)针对某一话题进行大力宣扬,以得到更多用户的关注,从而提高知名度或品牌影响力。(3)营销型水军。通过夸张的视频或图片广告极力宣传商品的优势,甚至是通过编造虚假故事来博取用户的信任或同情,以此来谋财。(4)谣言型水军。针对当下热点话题发布虚假言论,引导众人产生不满或恐慌的情绪。
1.2.2 特征属性定义
微博用户在社交网络中的行为主要表现为通过发布微博、转发评论等方式引起他人的关注。正常用户一般是引导积极向上的正能量,或者是处于中立的态度,而网络水军则要占据显要位置,以此来吸引大量用户的注意,进而带动整个话题的舆论方向,达到自己的目的或从中获利。
通过对微博中用户的特征属性进行详细的对比分析,可筛选得出有关网络水军的特征属性:(1)关注数。当前用户关注其他用户的数量,水军账号的关注数量远远大于正常用户的关注数量。(2)粉丝数。当前用户被其他用户关注的数量,水军账号的粉丝数少于正常用户。(3)标签数。为了让更多的人了解自己,用户一般会给自己贴标签(如运动、购物、开心等),用户贴的标签越多,代表其是正常用户的概率大,相反就是网络水军的概率大。(4)微博数。当前用户发布的微博总数,水军账号发布的微博数要远远高于正常用户。(5)粉丝关注比(粉丝数/关注数)。该比值越高,说明当前用户为认证或权威用户的概率更大;该比值越低,说明当前用户为水军账号的概率更大。(6)资料完善度。如基本信息、联系信息、职业信息、教育信息、标签信息等五项指标,每项指标又包含许多更为具体的小指标,在此规定每个小指标用户填写则计为1,不填写则计为0,资料完善度的各项值的和即为各项小指标相加。(7)有无简介。向用户介绍自己的基本情况、兴趣爱好、最近状态等,有计为1,无计为0。(8)阳光信用。共有5个等级,等级越高信用越好。
2 基于支持向量机的用户识别模型2.1 识别网络水军和正常用户的二分类模型

本研究基于多个二分类器设计了一个多分类器,利用台湾林智仁教授开发的一套实现支持向量机的库LibSVM中的函数svm.scale进行缩放,设置阈值为[-1,1]。处理过程如图1所示。将提取出的微博用户特征值输入到分类器后,第一个分类器判断该用户是正常用户还是炒作型水军,第二个分类器判断该用户是正常用户还是营销型水军,第三个分类器判断该用户是正常用户还是谣言型水军,第四个分类器判断该用户是营销型水军还是炒作型水军,第五个分类器判断该用户是谣言型水军还是炒作型水军,第六个分类器判断该用户是营销型水军还是谣言型水军。最后对这六个分类器的结果进行统计,得数最高的即为用户类型。
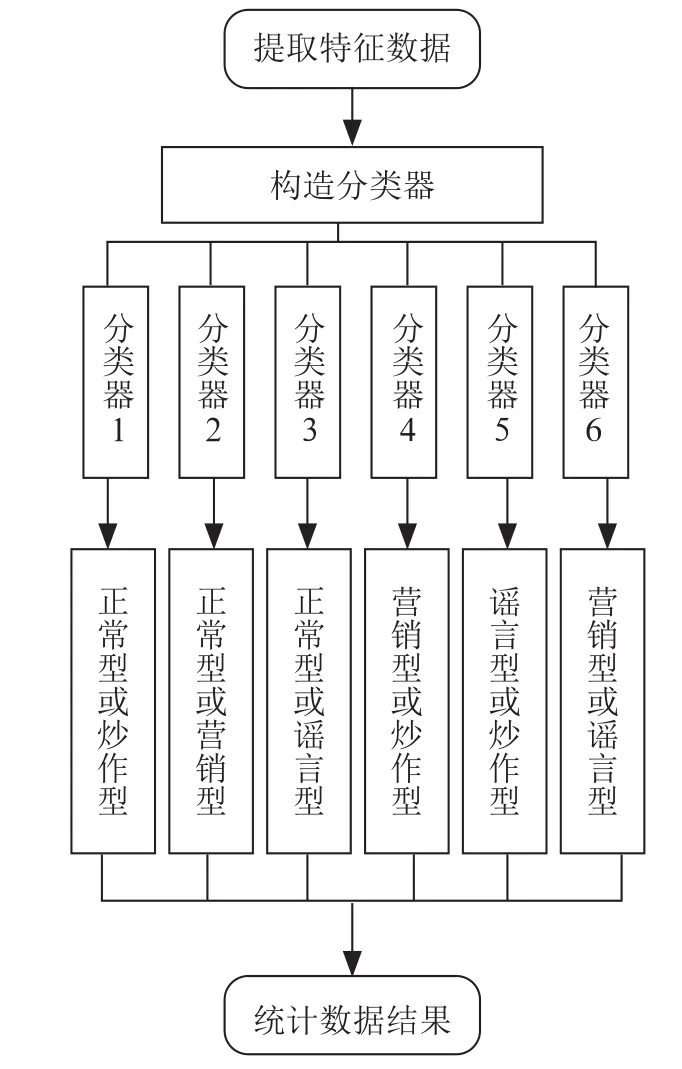
图1 多分类支持向量机模型
3 研究实现及结果分析3.1 微博数据的更新和获取本研究中的数据一部分来自新浪微博开放平台,一部分是通过网络爬虫获取的,快速识别出水军的类型对网络舆情的控制至关重要。本文设计了微博数据爬取程序和用户识别模型,用于获取微博中用户的关注数和粉丝数,识别出水军类型并进行统计分析。
3.2 实验数据结果的分析以前期获得的3 600条数据作为本研究的实验数据,人工分类如下:正常用户有2 854条,网络水军有746条,其中炒作型水军有369条,营销型水军有286条,谣言型水军有91条。通过人工分类和多分类识别器得到的数据如表1、表2和图2所示。

表1 人工分类得到的数据

表2 多分类器识别得到的数据
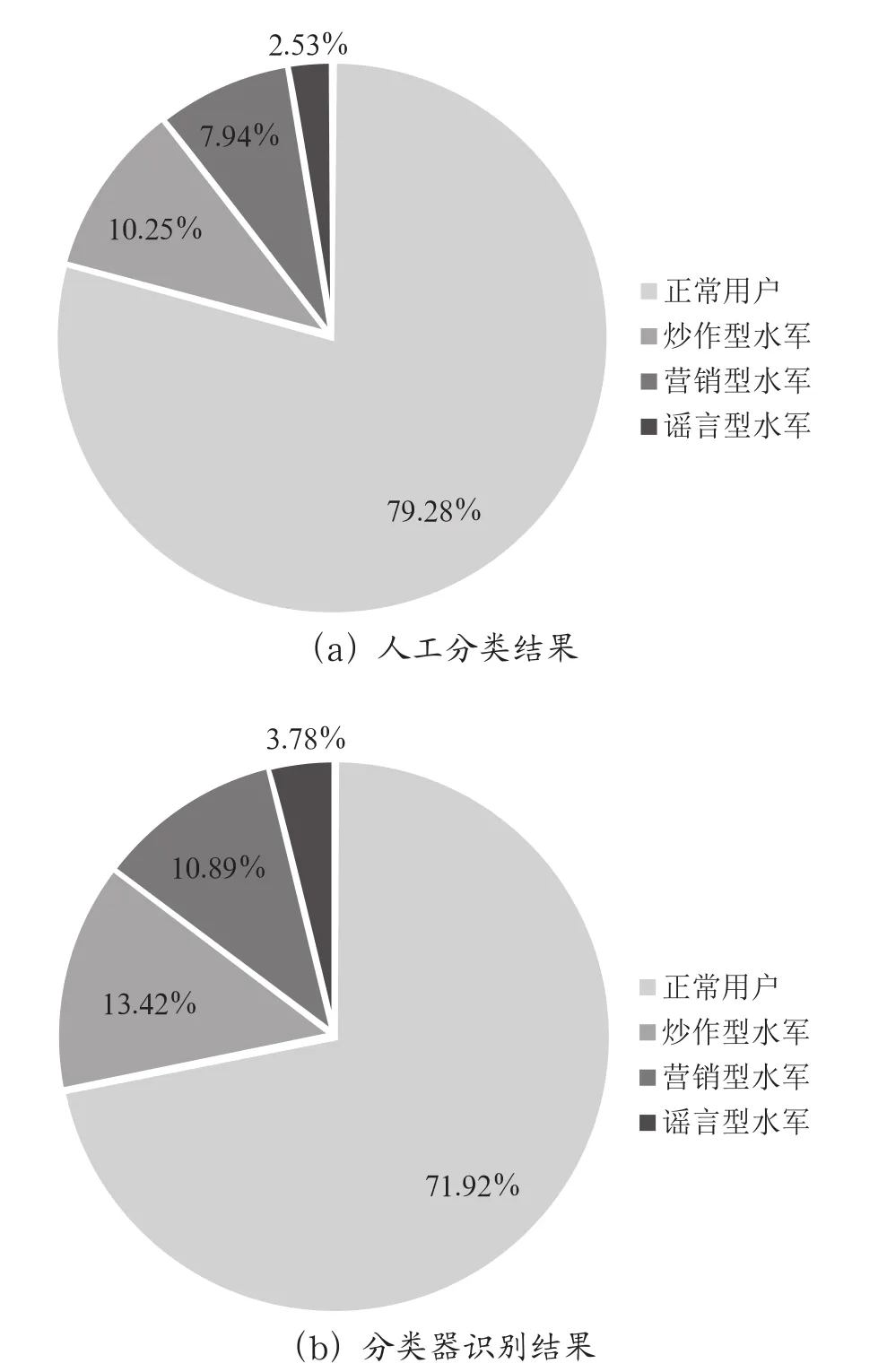
图2 实验数据识别结果
本研究定义了识别结果误差率,其为人工分类识别结果和分类器识别结果差的绝对值,公式为:

根据图2可以计算得出,正常用户的识别结果误差率为7.36%,炒作型水军的识别结果误差率为3.17%,营销型水军的识别结果误差率为2.95%,谣言型水军的识别结果误差率为1.25%。四个识别结果误差率的平均值约为3.68%,数值比较小,证明本研究提出的SVM多分类器识别方法对所提取数据的识别效果较好。
4 结 论网络给人们提供了极大的便利,但与此同时也带来一些负面影响,如本文研究的网络水军极大地干扰了网络舆论和信息安全,因此有必要将他们准确地识别出来并加以分类,以营造纯净健康的网络环境。本文采用一种基于SVM算法的多分类器模型,根据用户的特征信息进行检测识别,将他们分为正常用户、炒作型水军、营销型水军、谣言型水军四种类型。实验结果表明,所提出的多分类器模型可以有效识别网络水军。希望在以后的研究中,能开发出更优异的支持向量机算法模型,在识别网络水军上做到更加精准可靠。