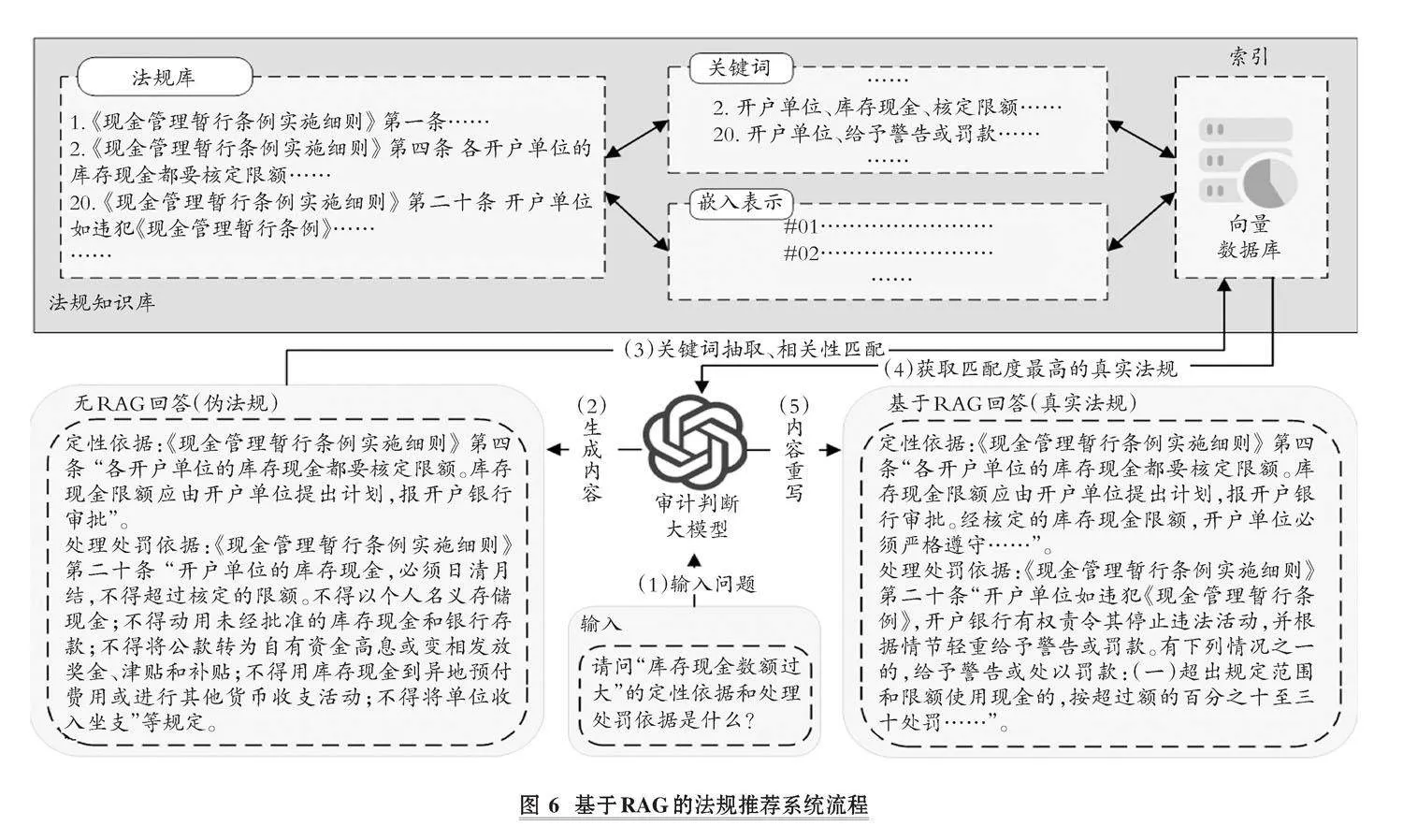
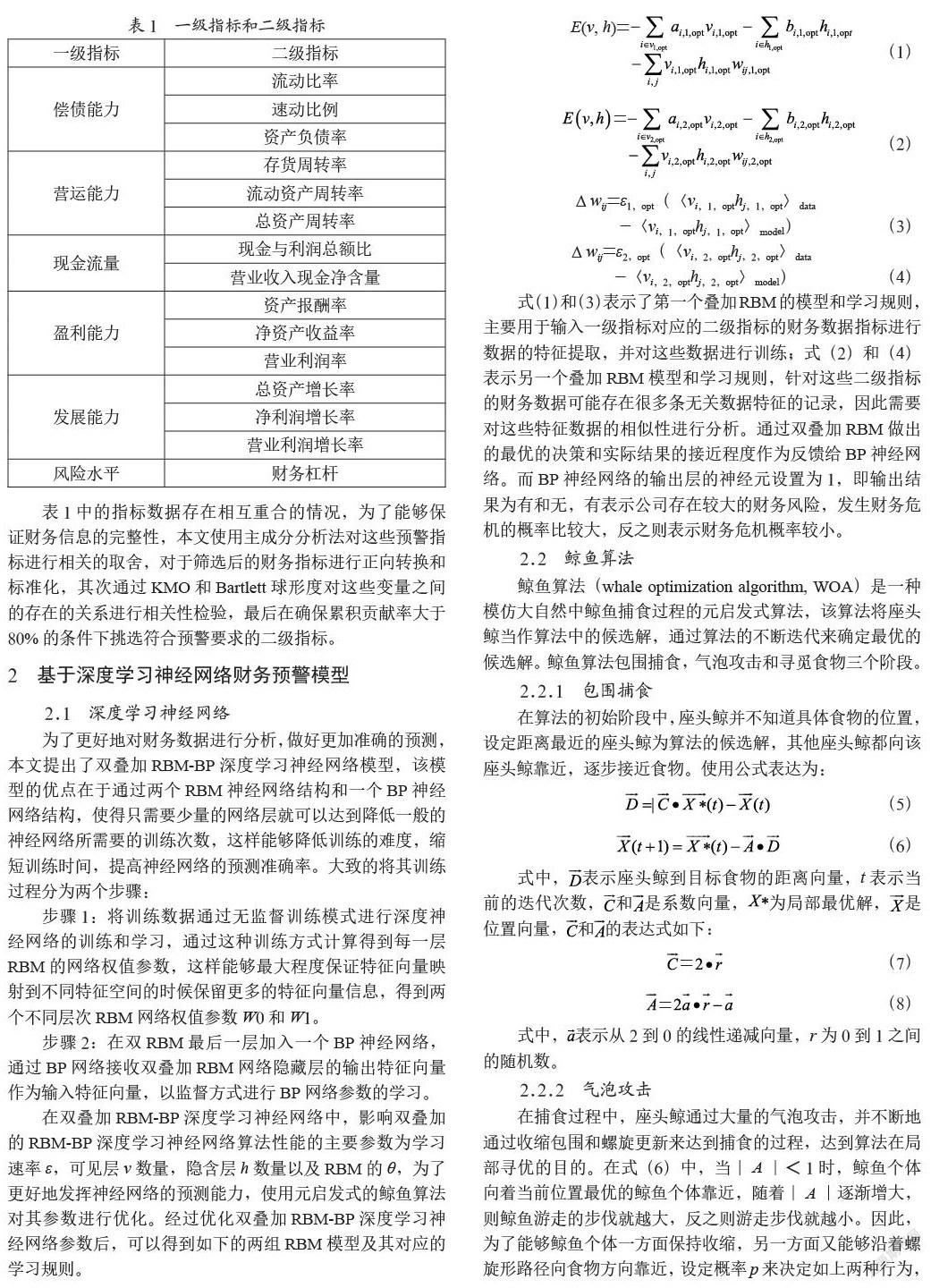
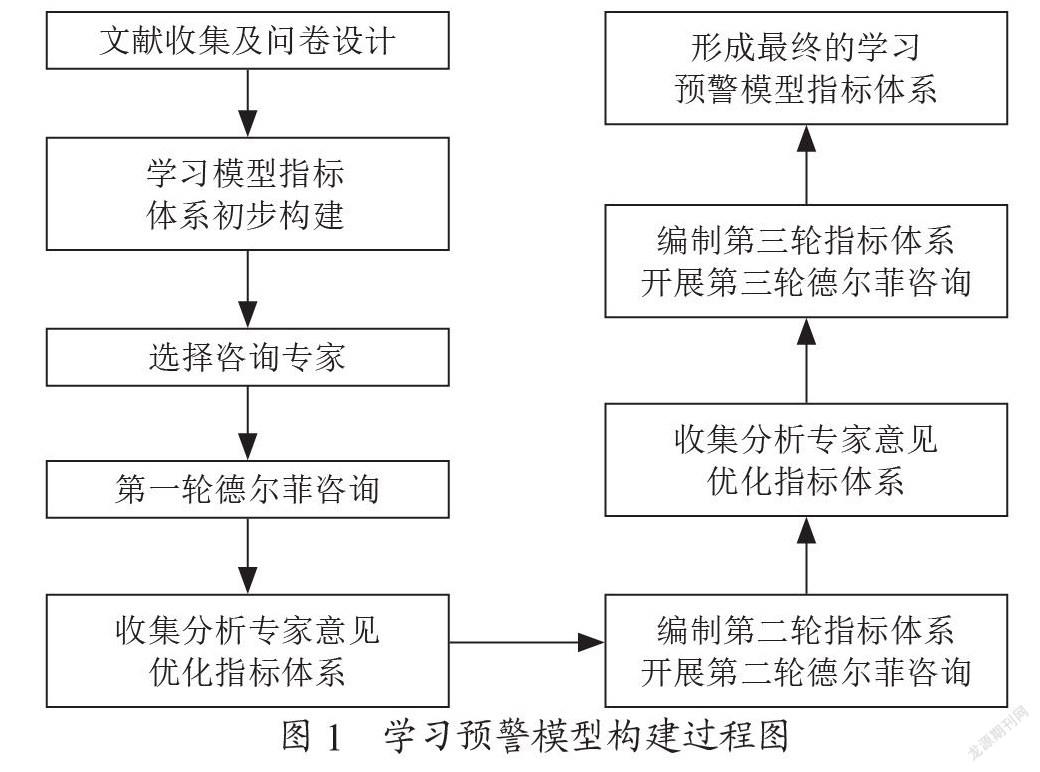
【中图分类号】F239;TP391 【文献标识码】A 【文章编号】1004-0994(2025)10-0034-6
一、引言
随着信息技术的迅猛进步和数字化转型的进一步深化,审计领域正经历深刻变革,面临着数据量激增和类型多样化的挑战。传统审计方法难以处理海量、多样化的文本数据,亟需新的工具以提升审计效率和准确性。知识图谱作为一种高效的知识表示和推理工具,能够整合审计过程中的相关信息,揭示数据内在联系,为审计决策提供智能化支持。然而,审计数据多以非结构化文本形式存在,如何将其转化为结构化数据以形成知识结构,是亟待解决的问题。实体关系抽取作为知识图谱构建的关键技术,能够自动化地从大规模非结构化文本中准确抽取知识结构。然而,审计文本具有独特的语言特点和专业术语,且包含大量背景信息和上下文依赖,增加了实体关系抽取的难度。如何在保证准确性和效率的前提下,设计适用于审计文本的实体关系抽取模型,成为当前审计知识图谱构建面临的重大挑战。
本文通过对比分析不同算法的特点和性能,揭示实体关系抽取在审计领域面临的挑战和机遇,并提出针对性的改进策略和优化方案。通过设计适用于审计文本的实体关系抽取模型,实现高效率、高质量地构建审计知识图谱,为审计行业提供智能化、精准化的决策支持,推动审计行业的转型升级和可持续发展,为企业在大数据时代背景下的风险管理提供有力保障。
二、文献综述
1.实体关系抽取。当前基于深度学习的实体关系抽取主要采用监督学习模型,可进一步分为管道模型和联合模型。管道模型将任务分为命名实体识别和关系提取两个子任务,虽已具备优秀性能,但存在级联误差传播、信息丢失和信息冗余等问题(Li和Ji,2014)。为解决这些问题,联合模型集成了两个子任务,有效利用了实体对和关系之间的交互信息,性能优于管道模型(任乐等,2023)。
在联合抽取模型中,Miwa和Bansal(2016)提出的基于端到端树形结构的联合学习模型采用参数共享方式,改善了管道模型的结构问题,但仍非完全同步提取,存在着子任务之间相对的先后顺序。随后的“多模块一单步骤\"模型,如Sui等(2020)的集合预测模型和Wang等(2021)的UniRE填表模型,进一步提高了抽取性能,但仍存在模块间错误传播的问题。Shang等(2022)提出的OneRel模型将关系提取转化为细粒度的三分类问题,一步提取三元组,解决了管道模型的问题,但该模型针对的是通用英文的实体关系抽取任务,若应用到中文审计文本上,仍需进行针对性改进。
在文本特征提取方面,Wang等(2022)从BERT中提取实体一关系类型,结合位置感知的语义角色注意机制构建新模型。Zhao等(2023a)结合卷积神经网络(CNN)
和图卷积神经网络捕获语义与结构。Li等(2024)引人关系感知增强模块提高关系分类性能。在中文特征处理领域,张军莲等(2021)的图卷积神经网络编码先验词间关系,葛君伟等(2021)的字词混合联合提取模型融合字级与词级特征,加入字符位置编码。Zhao等(2023b)利用实体描述和属性信息提升中文语境关系提取能力。然而,审计领域文本因包含大量专业术语、实体名称较长且边界不易界定以及关系类型相对不常见等特点,复杂性和多样性显著高于通用中文领域,上述处理方式在审计领域的应用仍需进一步优化和完善。
2.审计知识图谱。当前已有很多关于知识图谱在审计领域应用的研究,如:王瑞萍等(2020)从技术层面探索基于Neo4j图数据库进行审计知识数据的清洗、构建和存储,设计了面向审计领域的知识图谱构建流程;黄佳佳等(2022)通过深人探索审计文本特点,构建包含审计知识图谱在内的审计知识库,提升了审计文本分析的准确性和可解释性,但均未深人探讨非结构化数据自动化转换的问题。此外,现有研究大都侧重于应用,如崔婧和李真(2020)针对知识图谱在医保审计中的应用展开研究,肖嘉丽等(2024)则针对知识图谱在智能化审计中的应用进行探索。而对于如何高效率、高质量地从海量多样的审计文件中获取结构化信息,还缺乏更加深人的研究。
针对目前研究中存在的问题,本文首先提出了一种改进的中文审计领域特征融合方案,旨在从非结构化文本中直接抽取出实体关系三元组。该方案将优化编码与特征处理相结合,既考虑了文本的表面层次、句法、语义、词边界和上下文依赖性,又保证了模块的效率。然后将该模块应用于“多模块一多步骤\"的OneRel模型,形成审计实体关系抽取(Audit-OneRel)模型。
三、基于OneRel改进的审计实体关系抽取模型
本文提出的针对审计领域的文本特征处理方法主要分为基于注意力加权机制的融合编码、卷积神经网络的局部特征提取、Transformer层的全局上下文建模三个模块,其共同组成了最终的特征融合方案,如图1所示。
等,2017)与BERT(Jacob等,2019)的提出为文本编码带来了革新,其中BERT通过双向Transformer编码器堆栈输出强大文本嵌入式表示,成为实体关系抽取模型的首选。然而,现有模型在处理复杂文本时仍存在特征提取问题。Jawahar等(2019)的研究表明,BERT各层能学习到不同级别的特征,因此单纯使用最后一层输出可能并非最优。基于此,本文针对审计领域文本特点,设计了注意力加权的特征融合方法,集成BERT各层级输出信息,并学习相应权重,以提升特征提取的全面性和准确性。
首先,将所有BERT隐藏层的输出堆叠起来,形成一个四维张量H,其形状为 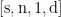 ,其中s是每批数据的大小、n是隐藏层的数量、1是文本序列的长度、d是BERT预训练模型的维度。
,其中s是每批数据的大小、n是隐藏层的数量、1是文本序列的长度、d是BERT预训练模型的维度。
其次,使用注意力网络对张量H中的每一层、每一位置的隐藏状态进行处理,得到一个三维张量S,其形状为 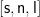 。每个元素
。每个元素 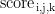 表示第i个样本、第j层、第k个位置的得分,公式如下:
表示第i个样本、第j层、第k个位置的得分,公式如下:
对张量S在层的维度应用Softmax函数,得到注意力权重w,其形状也为 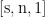 。每个元素
。每个元素 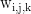 表示第i个样本、第j层、第
表示第i个样本、第j层、第 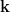 个位置的注意力权重,公式如下:
个位置的注意力权重,公式如下:
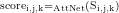
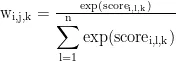
最后,将注意力权重与对应的隐藏状态相乘,并在层的维度上求和,得到加权融合后的表示R,作为文本的嵌入式表示,公式如下:
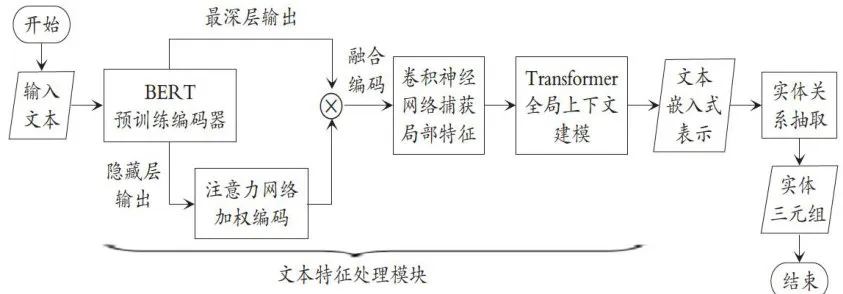 图1文本特征处理模块结构图
图1文本特征处理模块结构图1.基于注意力加权机制的融合编码。文本嵌入式表示方法(如Word2Vec、GloVe等)在处理文本数据时存在局限性,无法捕捉深层语义信息。Transformer(Vaswani
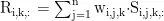
完成编码融合后,将BERT预训练模型与注意力网络共同纳入训练,反向传播会同时更新两者的参数,使模型学习最佳层输出组合,生成适配任务的文本编码。此方法能够增强模型的文本表示能力,解决信息丢失问题,提升模型的性能,且设计简洁、模型训练高效。
2.卷积神经网络的局部特征提取。命名实体识别在审计领域文本中面临专有名词与专业术语导致的词边界模糊问题,需关注文本字符间的局部依赖特征。为此,本文提出利用CNN捕获文本序列局部特征依赖信息。CNN在图像、视频领域表现突出,能捕获局部空间模式信息。虽然文本数据并不具备明确的二维空间结构,但经编码转为向量表示后,可形成类似的二维矩阵。通过调整卷积核宽度与词向量维度对齐,来捕获局部特征。本文在编码器后添加CNN作为后处理器,用不同宽度卷积核提取相邻字符间局部依赖特征,融人文本编码,并添加激活函数增强非线性,经多层处理获得充分融合局部特征的嵌入式表示。
假设BERT的输出是一个形状为[1,d]的二维矩阵E,其中1是序列长度(单词数量)、d是BERT预训练模型的维度,那么卷积核的形状就是[s,d],其中s为卷积核的宽度。设该卷积层有  个卷积核,那么对于第i个卷积核
个卷积核,那么对于第i个卷积核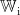 和对应的偏置项
和对应的偏置项 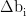 ,以及BERT输出矩阵E的一个窗□(局部区域)
,以及BERT输出矩阵E的一个窗□(局部区域) 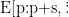 ](其中
](其中 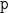 是窗口的起始位置),卷积操作可以表示为如下公式:
是窗口的起始位置),卷积操作可以表示为如下公式:
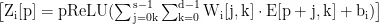
其中,PReLU(·)是激活函数, 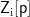 是第i个特征映射在位置p的输出值。这一操作会在整个序列上滑动进行,产生一个完整的特征映射
是第i个特征映射在位置p的输出值。这一操作会在整个序列上滑动进行,产生一个完整的特征映射 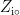 这些特征映射被堆叠在一起后形成的张量即可输人到后续的网络中做进一步处理。此外,CNN的共享权重机制也保证了整个模型的训练效率。
这些特征映射被堆叠在一起后形成的张量即可输人到后续的网络中做进一步处理。此外,CNN的共享权重机制也保证了整个模型的训练效率。
3.Transformer层的全局上下文建模。由于实体对在文本中位置多变,需全局上下文建模以全面理解实体间及上下文的依赖关系。传统循环神经网络(RNN)和CNN在处理长距离依赖时存在限制。为此,本文引入多头自注意力机制的Transformer层进行后续文本编码。自注意力机制允许模型同时考虑所有位置信息,通过计算序列中各位置间的点积评估相似性和依赖程度,经Soft-max转化为权重分布,描述依赖强度。这些权重组合所有位置表示生成融人全局上下文信息的编码,既包含局部信息,又捕捉任意位置依赖关系,使模型深入理解文本整体结构和含义。
假设BERT输出的文本编码序列是一个形状为[1,d]的二维矩阵E,其中1是序列长度(单词数量)、d是BERT嵌入的维度,Transformer的查询矩阵 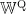 、键矩阵WK和值矩阵
、键矩阵WK和值矩阵 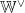 的形状为[d,
的形状为[d, 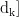 (
( 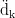 是查询/键向量的维度),那么对于BERT输出矩阵E中的每个位置i,可以计算其查询向量
是查询/键向量的维度),那么对于BERT输出矩阵E中的每个位置i,可以计算其查询向量 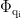 、键向量
、键向量 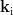 和值向量
和值向量 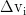 ,公式如下:
,公式如下:
其中, 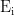 是BERT输出矩阵E的第i行,即第i个单词的嵌入。对于第i个位置,可以计算其注意力权重和上下文表示,公式如下:
是BERT输出矩阵E的第i行,即第i个单词的嵌入。对于第i个位置,可以计算其注意力权重和上下文表示,公式如下:
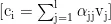
其中: 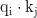 表示查询向量
表示查询向量 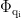 和键向量kj的点积;
和键向量kj的点积; 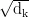 是一个缩放因子,用于防止点积结果过大导致Softmax函数进入饱和区;
是一个缩放因子,用于防止点积结果过大导致Softmax函数进入饱和区; 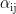 是第i个位置对第j个位置的注意力权重;
是第i个位置对第j个位置的注意力权重; 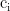 是考虑了全局上下文信息的第i个位置的表示。
是考虑了全局上下文信息的第i个位置的表示。
将ci用于后续的前馈神经网络层或其他Transformer层中。整个序列的输出将形成一个形状为[1, 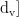 的二维矩阵(其中
的二维矩阵(其中 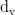 是值向量的维度,通常与
是值向量的维度,通常与 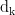 相同),该矩阵包含了每个位置的全局上下文信息。通过引入Trans-former进行后处理,模型可以更准确地识别出文本中的实体对,并判断它们之间的语义关系,从而提升关系抽取的性能和准确性。
相同),该矩阵包含了每个位置的全局上下文信息。通过引入Trans-former进行后处理,模型可以更准确地识别出文本中的实体对,并判断它们之间的语义关系,从而提升关系抽取的性能和准确性。
经过以上三个模块的处理,最终得到的文本编码已融合了中文文本的表层信息、句法信息、深层语义信息、局部依赖信息以及全局上下文依赖信息五种重要特征,分别针对审计文本表达方式多样、句法结构灵活、专业术语繁多、词边界模糊、上下文联系紧密的特点进行点对点的解决。相较于原始编码,融合了多种特征信息的文本编码能够帮助模型更好地完成实体识别、关系分类等子任务,最终提高整个实体关系抽取任务的性能。
四、实验研究与结果分析
1.数据集。
(1)DuIE通用数据集。DuIE为中国科学院计算技术研究所发布的大型关系抽取数据集,包含超过21万个现实世界的中文句子,涉及超过45万个SPO(主语—谓语—宾语)三元组。这些三元组由预先指定的架构与49种谓语关系组成。此外,其还包含海量新闻语句,多样的实体与关系类别适合用于评测模型的综合抽取能力。
(2)面向审计领域的指令评测数据集。该数据集由南京审计大学计算机学院和清华大学计算机科学与技术系联合研究构建,包含来自887个不同领域的11598个审计领域命名实体、123746个三元组和1217个谓语关系,并根据源数据构建了120万条审计知识三元组。本文选取其中的审计公告与审计文本描述三元组数据作为实验数据集,其包含审计主体、问题表现、法律法规等多种命名实体与审计事项、审计依据、审计问题等8种关系,适用于评测模型对审计领域文本的抽取性能。
2.评价指标。评价实体关系抽取模型性能的指标一般选择准确率(precision)、召回率(recall)和 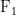 值(准确率和召回率的调和平均数),公式如下:
值(准确率和召回率的调和平均数),公式如下:

3.实验设置。本文实验设置CNN的层数为4,每层的卷积核大小分别为3、3、5、5;Transformer层中多头注意力的头数设置为8,层数设置为4;前馈神经网络的维度设置为2048;激活函数使用PReLU。上述设置的参数在多次实验中得到了较好的结果。在训练过程中,学习率设置为1e-6,dropout率设置为0.2,每批数据量设置为8,其余参数设置均与基线模型保持一致。
4.实验结果分析。
(1)对比实验。为验证审计文本特征处理模块的有效性,本文设计了对比实验,选取以下模型作为对照:一是FCM模型(Gormley等,2015),其整合了非词汇化手工特征与深度学习词嵌人表征,以提升模型性能和泛化能力。该模型利用传统特征与深度学习技术的优势,通过互补性信息整合,在处理复杂文本关系时更准确、鲁棒性更高。二是Attention-BLSTM模型(Zhou Peng等,2016),其在双向LSTM中深入捕捉句子核心语义信息,同时考虑单词前向和后向上下文,生成含丰富语义且突出关键信息的句子级别特征向量。三是Bi-LSTM-BIO方法(Lample等,2016),其采用先关系分类后实体标注的方法,使用BIO标注方案标记实体边界,简化实体识别过程,可提高任务效率和准确性。四是MultiR模型(Hoffmann等,2011),其针对重叠关系,结合句子级别抽取模型和语料库级别组件,实现对单一事实的聚合处理,准确识别复杂关系结构。五是CoType模型(RenXiang等,2017),其采用联合学习策略,将实体、关系、文本特征和类型标签共同嵌入低维空间,捕捉潜在联系,增强模型泛化能力和鲁棒性。六是指针标注模型(王勇超等,2021),其用指针指示关系类别来应对重叠实体标注问题,能够同时抽取多个实体关系三元组,提高关系抽取效率和准确性。七是OneRel模型(Shang等,2022),其创新性地提出“单模块一单步骤\"的抽取模式,将联合抽取视为三重分类问题,通过评分分类器与角标策略联合识别实体对和关系,避免信息丢失和冗余计算,在处理实体重叠和复杂文本时表现出色。
本文在同样的参数、相同的数据集条件下对以上对照模型与本文的改进模型(Audit-OneRel)进行了对比实验测试,测试结果如表1所示(采用DuIE通用数据集)。
由表1可知,FCM模型准确率高达 7 4 . 7 % ,但召回率较低,在处理关系重叠场景时存在局限。Attention一BLSTM模型亦面临此难题,反映了传统管道模型的不足。MultiR、CoType及指针标注模型采用联合学习方法,能有效避免错误累积。Bi-LSTM-BIO模型创新了处理流程,优先考虑关系分类,在处理重叠关系方面取得了巨大的进步。而OneRel模型则实现了真正的联合抽取,性能大幅优于前述模型。本文提出的改进模型在通用领域上的性能相较以上模型都有显著的提升,与性能最好的OneRel模型相比,准确率提高了 6 . 6 % , 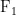 值提高了 4 . 2 % 。这表明使用特征融合方法丰富文本编码内容,能够综合提升模型的三元组抽取精度。
值提高了 4 . 2 % 。这表明使用特征融合方法丰富文本编码内容,能够综合提升模型的三元组抽取精度。
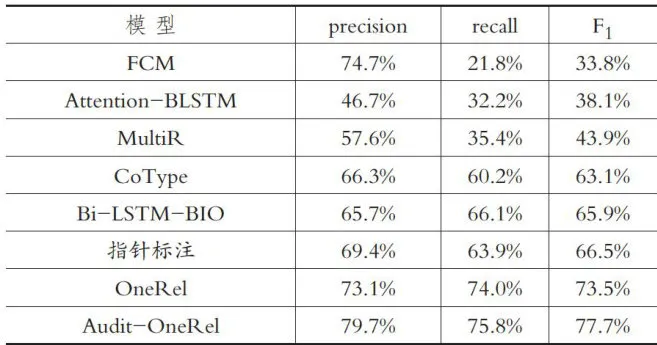 表1 通用领域不同实体关系抽取模型的实验结果对比
表1 通用领域不同实体关系抽取模型的实验结果对比
审计领域的对比实验结果如表2所示(采用面向审计领域的指令评测数据集)。由于该审计三元组数据集更复杂,模型抽取三元组的准确性相较DuIE通用数据集均偏低。但由实验结果可知,特征后处理模块针对高难度的审计公告与审计文本描述特点,能够获得更加丰富的特征信息,提升模型的抽取精度。与OneRel模型相比,本文改进模型的准确率提升了 8 . 3 % , 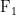 值提升了 4 . 5 % ,证明了本文所设计模型在审计场景中的优越性。
值提升了 4 . 5 % ,证明了本文所设计模型在审计场景中的优越性。
 表2 审计领域不同实体关系抽取模型的实验结果对比
表2 审计领域不同实体关系抽取模型的实验结果对比(2)消融实验。为了验证本文提出的三个子步骤分别对OneRel模型的中文实体关系抽取性能的影响,本文进行了消融实验。在保持其他参数不变的条件下,训练相同的轮次,实验结果如表3所示。
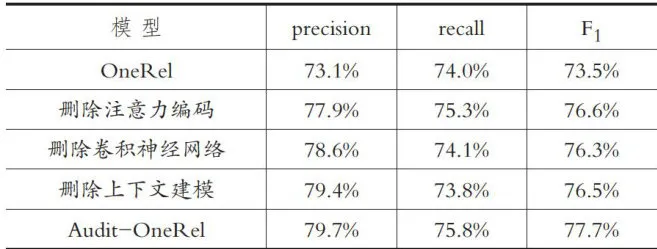 表3 消融实验结果
表3 消融实验结果
由表3可知,三种方法均可提升基准模型的性能。具体而言:对文本编码的注意力加权融合显著提升了模型的准确率,可见在文本编码中加入表层和句法信息特征,能帮助模型更好地应对表达方式多样的审计领域文本,从而更精准地预测三元组;卷积神经网络的运用使得准确率和召回率均有所提升,说明局部特征信息能够很好地应对审计领域文本中词边界模糊的问题,且对模型性能的提升较为均衡,能在保证提升精度的同时使模型不过于保守或激进;使用Transformer层进行后处理的影响则主要体现在召回率上,表明全局上下文特征信息能帮助模型更好地识别出实体对,进而提升检测能力。而综合三种方法进行特征融合改进的Audit-OneRel模型相比原始OneRel模型在三项指标上都有提升,其中准确率和 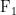 值的提升尤为显著,证明了本文所构建方法的有效性。
值的提升尤为显著,证明了本文所构建方法的有效性。
五、案例分析
为阐释实体关系抽取技术在审计知识图谱构建及线索发现中的实践价值,本文选取某复杂股权结构与关联方交易审计案例进行深人剖析。案例文本节选自 × × 会计师事务所出具的专项审计调查报告,具体内容如下:“ × 号审计调查报告揭示,A公司存在关联方交易披露不充分及资金流向不明晰的重大风险。经穿透式核查发现,公司实际控制人王明辉通过多重亲属关系构建关联网络:其父王建国曾任关联企业B公司法定代表人,现由王明辉实际掌控;胞弟王立阳身兼A公司董事长及关联企业C公司创始人双重身份,C公司法定代表人由其配偶杨娜担任;王明辉配偶赵敏与关联企业D公司法定代表人赵刚存在直系亲属关系。审计证据显示,A公司与上述关联方存在异常资金往来,涉及金额达 × × 万元,其中 × × 笔交易未按规定进行关联方披露。审计机构通过访谈法、财务分析法及数据追溯法,未能完全查明资金流动的具体情况,仍存在 × × 万元资金流向无法合理解释的情况,暴露出重大内部控制缺陷。根据《公司法》及相关财务会计准则要求,本所建议A公司完善关联方识别机制,规范交易披露程序,并建立穿透式资金监控体系。”
上述案例所提及的所有人名及所属单位均为虚构内容,旨在提供分析和讨论的情境背景。这些名称与现实中可能存在的任何个人或单位均无任何关联,也不代表对任何具体实体或个人的评价。所有信息仅用于学术探讨目的,特此声明,以避免任何潜在的混淆或误解。
1.实体关系抽取。本案例呈现出亲属关系与股权结构交织形成的隐蔽关联网络,具有审计领域特有的专业术语密集、实体指代复杂、语义关联隐蔽等特征。传统文本分析难以有效识别多层嵌套的关联关系。本文运用Audit-OneRel智能分析模型,通过语义分割、上下文编码及深度特征学习技术,系统提取审计报告中的实体关系三元组,结果如表4所示。
经过模型的实体关系抽取,成功识别出18组核心关联关系,可以在短时间内获得文本中所含信息的结构化形式,该形式经过筛选后可以直接输入图数据库等软件中做进一步处理,构建出可视化关联网络图谱,为发现异常资金流向提供关键线索。
 表4 审计报告示例中的实体关系抽取结果
表4 审计报告示例中的实体关系抽取结果2.知识图谱构建。基于实体关联数据,本文运用可视化分析工具构建动态审计知识图谱(见图2)。该图谱通过文本信息结构化处理,将隐蔽的关联网络转化为可追溯的节点关系模型。在实务应用中,审计人员可借助图谱的层级展开功能,掌握股权穿透路径与亲属关系交叠形成的复杂网络,显著提升对异常交易模式的识别效率。特别是在穿透式监管框架下,图谱构建技术能有效解决该审计任务在执行过程中面临的关联方识别难题,为核查资金闭环流动提供可视化分析工具。
3.审计线索发现。知识图谱技术在本案例中展现出三重应用价值:其一,通过亲属任职路径的可视化呈现,揭示王明辉家族通过B、C、D公司构筑的潜在利益输送通道,特别是赵敏与D公司的亲缘关系形成的资金暗流;其二,整合访谈记录、财务数据与法律条文构建多维分析框架,有效追溯A公司与关联方间 × × 笔未充分披露交易的资金闭环;其三,依托图谱的层级穿透功能,精准定位审计程序中的关键证据节点,如会计师事务所实施的访谈法、财务分析法及数据追濒法的应用轨迹。
此外,通过知识图谱,审计团队能够迅速获取当前审计过程的相关信息。例如,审计机构的具体名称、所采用的审计方法、审计依据的法律法规以及当前获得的审计成果等。这些信息对于推动审计任务的下一步进行至关重要。图谱的呈现方式使得审计团队能够一目了然地掌
·38·财会月刊2025.10
 图2知识图谱构建结果
图2知识图谱构建结果握审计进展,从而做出更为精准的判断和决策。
这一精准且高效的信息抽取方法,突破了传统文本分析的局限性,将碎片化信息转化为具有逻辑关联的证据链,不仅有助于审计团队全面理解资金流动的背景与潜在风险点,还可通过实体间的多维度关系分析,揭示可能存在的非正常交易或利益输送模式。这对于深入调查与取证工作具有极大的指导意义,使得审计团队能够精准导向关键问题,避免盲目摸索,从而显著提升审计效率与质量。在面对具有复杂关系的审计案件时,这种依托知识图谱的审计方式,能够确保审计结果的客观性与准确性,为审计工作的专业性和权威性提供有力保障。
六、总结与展望
本文针对审计文本分析中存在的专业术语密集、语义结构复杂、上下文关联隐蔽等技术难点,创新性地构建了面向审计实务的特征融合分析框架。通过建立多维度特征融合机制,有机整合文本表层语义、句法结构与上下文依存关系,有效破解了传统方法在关联方识别中的局限。实证研究表明,该框架支撑下的Audit-OneRel模型在关联关系抽取准确率等核心指标上显著优于基准模型,特别是在处理实体关系交叉重叠等复杂场景时,展现出独特的实践价值。本文取得了三方面的突破性进展:其一,构建了“局部一全局\"双重视角的信息抽取范式,通过特征加权融合技术精准捕捉审计文本中隐含的关联路径;其二,创新设计审计领域适配算法,成功解决了关联交易中常见的角色冲突与利益嵌套问题;其三,在审计知识图谱构建实践中验证了技术方案的可行性,为穿透式监管提供了智能分析工具。
未来研究将着重于三方面的深化:一是拓展智能算法在持续审计中的应用场景,强化对隐蔽利益输送模式的预警能力;二是完善审计知识图谱的动态更新机制,提升其对新型关联交易模式的适应性;三是构建业技融合的智能审计生态系统,推动审计模式从风险应对向风险预见转型。这些探索将为资本市场信息披露质量的提高及审计行业的数字化转型持续提供技术支撑。
【主要参考文献】
葛君伟,李帅领,方义秋.基于字词混合的中文实体关系联合抽取方法[J].计算机应用研究,2021(9):2619~2623.
黄佳佳,李鹏伟,徐超.大数据驱动的审计知识库建设与应用[J].财会月刊,2022(3):101~107.
任乐,张仰森,刘帅康.基于深度学习的实体关系抽取研究综述[J].北京信息科技大学学报(自然科学版),2023(6):70~79+87.
王瑞萍,刘峰,杨媛琦等.审计知识图谱的构建与研究一一基于Neo4j的图谱技术[J].中国注册会计师,2020(9):109~113.
肖嘉丽,蔡玲嘉,黄玉昆等.基于知识图谱的企业智能化审计构建与应用[J].数字技术与应用,2024(3):19~21.
张军莲,张一帆,汪鸣泉等.基于图卷积神经网络的中文实体关系联合抽取[J].计算机工程,2021(12):103~111.
(责任编辑·校对:喻晨陈晶)