胡定兴 杜建强 石强 罗计根 刘勇


摘 要:文章针对中医临床症状实体及属性抽取存在医疗短文本语义信息欠缺,常用的流水线方法易导致多任务之间产生错误累积的问题,提出一种基于深度学习的症状实体及属性抽取方法。首先通过基于BLSTM-CRF的序列标注模型完成“实体/修饰属性”识别;其次根据扩展步长的就近匹配原则生成高覆盖率、低冗余度的“实体—属性值”候选对;最后基于ERNIE-BGRU-MP完成关系分类,利用ERNIE丰富文本上下文信息,联合BGRU提取文本全局特征信息,采用最大池化法过滤冗余和噪声信息,提高模型的泛化性和鲁棒性。
关键词:实体及属性抽取;ERNIE;BGRU;最大池化;中医药信息学
中图分类号:TP391 文献标识码:A文章编号:2096-4706(2022)03-0070-06
Symptom Entity and Attribute Extraction for TCM Electronic Medical Record
HU Dingxing1, DU Jianqiang1, SHI Qiang2, LUO Jigen1, LIU Yong1
(1.School of Computer, Jiangxi University of Chinese Medicine, Nanchang 330004, China; 2.Qihung Medical College, Jiangxi University of Chinese Medicine, Nanchang 330004, China)
Abstract: Aiming at the problem of the lack of semantic information of medical short texts in entity and attribute extracting of TCM clinical symptoms and the accumulation of errors among multiple tasks coursed by common pipeline methods. A symptom entity and attribute extracting method based on deep learning is proposed. Firstly, the recognition of “entity/modification attribute” is completed by the sequence annotation model based on BLSTM-CRF; Secondly, “entity-attribute value” candidate pairs with high coverage and low redundancy are generated according to the nearest matching principle of extended step size; finally, the relationship classification is completed based on ERNIE-BGRU-MP, Ernie is used to enrich the text context information, and the max-pooling method is used to filter the redundant and noise information, so as to improve the generalization and robustness of the model.
Keywords: entity and attribute extracting; ERNIE; BGRU; max-pooling; Chinese medicine informatics
0 引 言
中医电子病历作为记录中医临床诊疗过程和诊疗结果的重要载体,主要包含疾病的临床表现、检查记录、病证结论、治疗计划、疗效反馈等基本内容,蕴含中医师丰富的临床诊疗知识与经验以及患者的健康医疗数据信息[1],但是很难做到显性表达与传播。面向中医电子病历的症状实体及属性抽取是中医临床诊疗文本结构化表示的重要手段,旨在识别中医临床文本中患者疾病的临床症状实体及其修饰信息,以及确定实体与修饰信息之间的关系。其中,症状的修饰信息是患者疾病临床表现的个性化表达,对正确理解患者疾病当前的发展态势和辅助中医临床个性化治疗具有重要意义。
为了简化问题的复杂度,本文将症状的修饰信息视为实体,将“识别中医临床症状实体和修饰信息”转化为命名实体识别(Named Entity Recognition, NER)任务;将“确定实体与修饰信息之间的关系”转化为中医临床短文本分类任务。本文从中医临床症状的时间性、空间性和程度性三个维度定义八类修饰信息:否认的、当前的、既往的、有条件的、身体部位、频次、严重程度、关联时间。
1 相关工作
实体及属性抽取任务主要包括实体识别和实体间关系分类,依据子任务组织方式的不同,该研究可以从联合学习法[2-5]和流水线法[6-8]两个角度展开。在临床医疗领域,部分学者采用参数共享和序列标注的联合学习方法,克服各阶段模型相互独立、多任务之间存在错误累积传播的问题。MIWA等[2]使用端到端的LSTM-RNNs框架进行实体识别和关系抽取的联合学习,通过共享联合编码层实现命名实体识别与关系分类两个子任务之间的交互,但仍存在无法剔除冗余实体信息的问题。ZHENG等[3]首次提出基于统一标注的策略,将实体关系抽取任务等价转化为一个序列标注任务,但却无法解决实体关系重叠的问题;石雪[4]在BIOHD1234标签表示法的基础上,采用Multi-Label多层标签表示法提升实体属性关系的覆盖率,并构建基于BLSTM-CRF的文本序列标注模型,首先利用BLSTM网络完成文本的特征编码,再利用CRF解码输出标注结果。增加标签复杂度虽然能提高实体关系覆盖率,但是存在标签扩展性弱,人工标注语料难度大的弊端,同时,标签数量增大又会带来数据稀疏的问题。
也有部分学者采用流水线思想,将实体及属性抽取任务拆分为命名实体识别和关系分类两个互相独立的子任务,具有模型灵活、简单易行的特点。张昱[8]提出通过基于CNN-GRU的医疗实体修饰识别,将卷积神经网络(Convolutional Neural Network, CNN)预先提取的文本字符级特征用以表示输入门控循环单元(Gate Recurrent Unit, GRU),对文本信息进行编码,并使用Softmax分类器进行解码,该方法只实现了医疗实体修饰信息的识别,并没有进一步确定实体与修饰信息的关系类别。石雪[4]首先基于BLSTM网络完成命名实体识别,采用实体与属性两两配对生成一系列的<实体,属性>候选对,然后使用树结构长短期记忆(Tree-Structure Long-Short Term Memory, Tree-LSTM)网络学习句子的结构特征并进行关系分类,该方法的两两配对原则容易产生大量的冗余实体对。
本文针对医疗短文本语义信息欠缺以及常用的流水线法存在错误累积传播的问题,提出一种基于深度学习的中医临床症状实体及属性抽取的流水线方法,分别训练一个命名实体识别模型和一个中医临床短文本分类模型。通过优化Word2vec预训练方式,加强对中医临床领域知识的表示学习,提升症状实体和修饰信息识别效果;提出基于扩展步长的就近匹配原则生成候选实体对;利用ERNIE模型提高实体属性抽取语义信息的丰富性,联合BGRU网络抽取全局特征,采用最大池化法过滤冗余和噪声信息,同时增强模型的泛化性和鲁棒性。
2 模型介绍
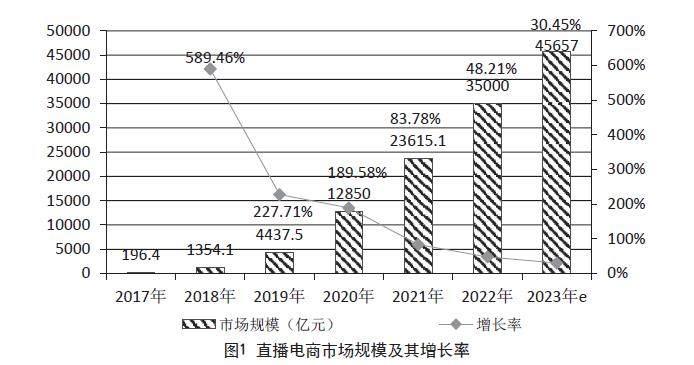
本文提出的中医临床症状实体及属性抽取方法的整体流程分为三个阶段:(1)利用中医临床文本命名实体识别模型对输入的医疗文本进行症状实体和修饰信息识别;(2)基于扩展步长的就近匹配原则将所识别的实体与修饰信息进行配对,形成<实体,属性>候选对集;(3)利用中医临床短文本分类模型确定每个<实体,属性>候选对的修饰关系类别。最后得到医疗文本中包含的所有<症状实体,修饰关系,修饰信息>三元组。以输入医疗文本“反复胸闷,气促,哮喘7年余”为例,其症状实体及属性抽取过程三个阶段主要的输入与输出如图1所示。
2.1 基于EMR2vec-BLSTM-CRF的中医临床文本命名实体识别
在第一阶段,本文提出可完成中医临床文本命名实体识别任务的EMR2vec-BLSTM-CRF模型,主要包括Embedding层、BLSTM层和CRF层,模型整体框架如图1(第一阶段)所示。为避免因分词错误而造成误差累积以及加强对中医医疗领域知识的表示学习,通过采集大量中医临床诊疗文本构建Word2vec[9]模型预训练语料,生成中医临床领域知识的字向量编码(Character Vector of TCM Electronic Medical Record, EMR2vec)作为初始特征表示。算法流程如算法1所示。
算法1:基于EMR2vec-BLSTM-CRF的中医临床文本命名实体识别。
输入:中医临床医疗文本或句子{S1,S2,…,Sp}。
下面是具体的过程:
(1)利用EMR2vec对训练集样本进行Embedding操作,得到输入文本的字向量特征矩阵{x1,x2,…,xp};
(2)将{x1,x2,…,xp}输入到BLSTM模型中,计算t时刻的前向输出ht和后向输出ht,将前向输出与后向输出拼接得到综合特征ht=[ht,ht];BLSTM层输出综合特征矩阵{h1,h2,…,hp};
(3)将{h1,h2,…,hp}输入到CRF层解码序列标签,输出文本的标注结果{y1,y2,…,yp};
(4)将{y1,y2,…,yp}输入到“标签-实体/修饰信息”解码器,输出文本中包含的症状实体和修饰信息列表。
输出:医疗文本中包含的症状实体和修饰信息列表。
以输入医疗文本“反复胸闷,气促,哮喘7年余”为例,第一阶段输出症状实体和修饰信息:反复、胸闷、气促、哮喘、7年余,修饰信息:反复、7年余。
2.2 基于NMP-ESS生成候选实体对
在第二阶段,传统的两两随机匹配原则容易生成大量冗余实体对,而单一的就近匹配原则容易遗漏部分实体对。本文通过分析文本的结构特征和中医电子病历信息抽取的实际需求,提出基于扩展步长的就近匹配原则(Nearest Matching Principle of Extended Step Size, NMP-ESS),使生成的实体对集实现高覆盖率、低冗余度,具体的算法流程如算法2所示。
算法2: 基于扩展步长的就近匹配原则生成候选实体对。
输入:医疗文本S、医疗文本中包含的症状实体和修饰信息列表L。
下面是具体的过程:
(1)循环遍历列表中各个修饰信息(A),依次进行以下操作:匹配修饰信息(A)左向或右向第一个相邻的实体词(E),匹配方向先右后左,若右边存在关联实体词,则停止左向匹配;生成(E,A)候选实体对列表L1;##就近匹配实体;
If列表L1为空:##扩展匹配步长
修饰信息(A)左边或右边均无直接相邻实体词(E),则逐步向外匹配紧邻的实体词(E),直至为空;生成(E,A)候选实体对列表L2;
将列表L1、L2中候选实体对(E,A)加入候选对集合set_A。
(2)输出医疗文本中包含的<症状实体,修饰信息>候选对集合set_A。
(3)将候选对集合set_A中的(E,A)候选对与医疗文本S拼接,生成待分类中医临床短文本。
输出:医疗文本中包含的<症状实体,修饰信息>候选对集合set_A。
将第一阶段输出的(反复、胸闷、气促、哮喘、7年余)列表和医疗文本作为算法2的输入,在第二阶段输出两个待分类的医疗文本——“反复胸闷,气促,哮喘7年余。#胸闷#反复”和“反复胸闷,气促,哮喘7年余。#哮喘#7年余”。
2.3 基于ERNIE-BGRU-MP的中医临床短文本分类
在第三阶段,本文将“确定症状实体与修饰信息之间的修饰关系”视为中医临床短文本分类任务,提出用于中医临床短文本分类的ERNIE-BGRU-MP模型,主要包括ERNIE层、BGRU层、最大池化层和Softmax分类器,模型整体框架如图1(第三阶段)所示,具体的算法流程如算法3所示。
算法3 :基于ERNIE-BGRU-MP的中医临床短文本分类。
输入:包含<症状实体,修饰信息>候选对的中医临床短文本{S1,S2,…,Sp,…,Sn}。
下面是具体的过程:
(1)将文本序列输入到ERNIE模型中,得到文本的字向量特征矩阵{w1,…,wn};
(2)将{w1,…,wn}矩阵输入到BGRU模型中,计算t时刻的前向输出ht和后向输出ht,将前向输出与后向输出拼接得到综合特征ht=[ht,ht];BGRU层输出的特征表示向量S=[h1,hp]。
(3)将S=[h1,hp]输入到最大池化层,输出特征向量。
(4)将输入到Softmax分类器,输出修饰关系类别r。
(5)将<实体,修饰信息>与对应的修饰关系拼接后,输出<症状实体,修饰关系,修饰信息>三元组。
输出:<症状实体,修饰关系,修饰信息>三元组。
本文利用ERNIE模型[10,11]引入实体外部知识特征来丰富临床文本的上下文语义信息,将知识编码器最后一层的综合特征向量输入到BGRU层抽取全局特征;将t时刻前向和后向捕获到的隐藏状态ht和ht进行拼接得到综合特征ht=[ht,ht],将BGRU输出的第一个隐藏状态h1和最后一个隐藏状态hp进行信息融合,得到Token序列的综合特征表示向量S=[h1,hp];利用Max-Pooling层对全局特征S=[h1,hp]进行冗余信息和噪声信息过滤,缓解命名实体识别和<实体,属性>候选对生成器任务间错误累积对文本分类的影响,增强模型的泛化能力;将过滤后的特征向量S=max(S)输入到Softmax分类器,计算实体属性类别的概率分布,将概率值最大的类别标签作为预测结果,具体计算为:
(1)
(2)
其中,We表示权值矩阵,be 表示偏置向量,M表示所有实体属性类别的数量。
将第二阶段算法2输出的两个待分类医疗文本作为第三阶段模型的输入,最后输出对应的<症状实体,修饰关系,修饰信息>三元组(胸闷,发病频次为,反复)和(哮喘,关联时间为,7年余)。
3 实验
3.1 实验语料
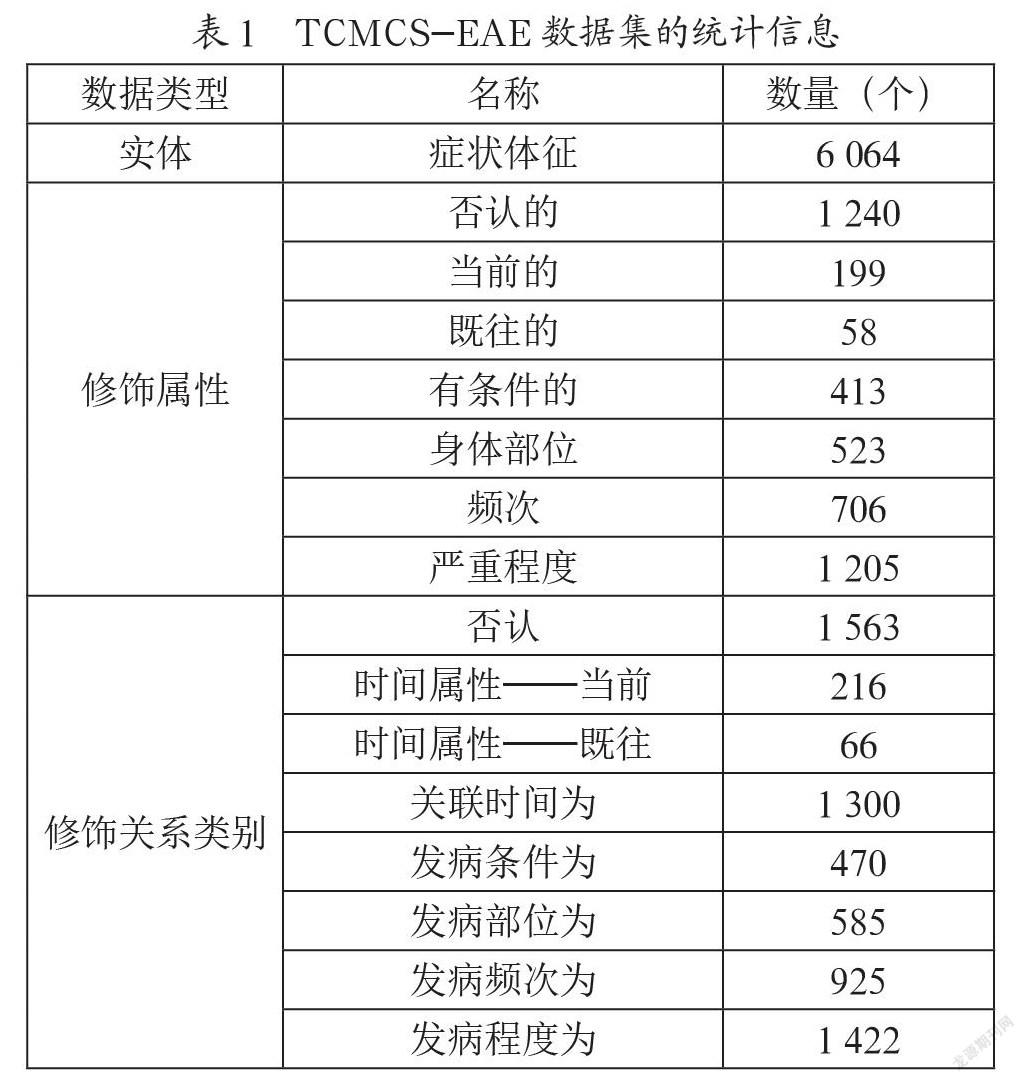
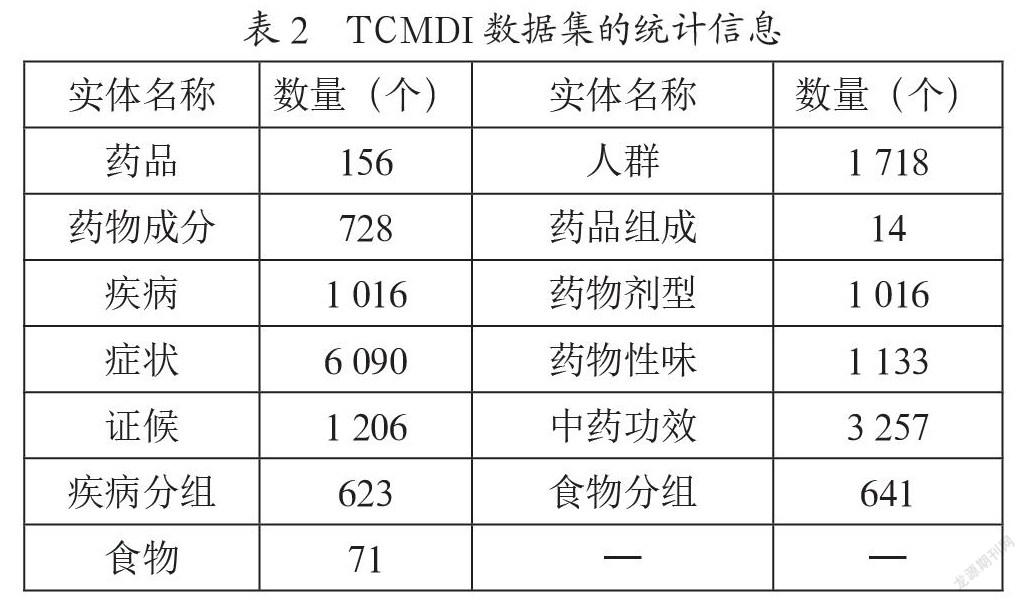
本文以江西中医药大学岐黄国医书院300份哮喘病中医(门诊)电子病历为数据源,人工标注构建中医临床症状实体及属性抽取(Entities and Attributes Extraction of TCM Clinical Symptoms, TCMCS-EAE)数据集验证模型性能,共有2 767个句子样本,数据集的详细信息如表1所示。此外,针对命名实体识别任务,使用CHIP-2020中药说明书命名实体识别数据集TCMDI进行对比评价,数据集的详细信息如表2所示。
3.2 评价指标
为避免样本类别不均衡对评测结果的影响,本文采用加权求和的准确率(P)、召回率(R)和F值来评估模型性能,权重值为实体类别总数占全部样本总数的比例。
(3)
(4)
(5)
其中,n为分类结果的类别总数;Pi、Ri、Fi分别为类别i的P、R、F值;N为数据集样本总数,Ni为实体类别i的样本总数。
3.3 实验环境与参数设置
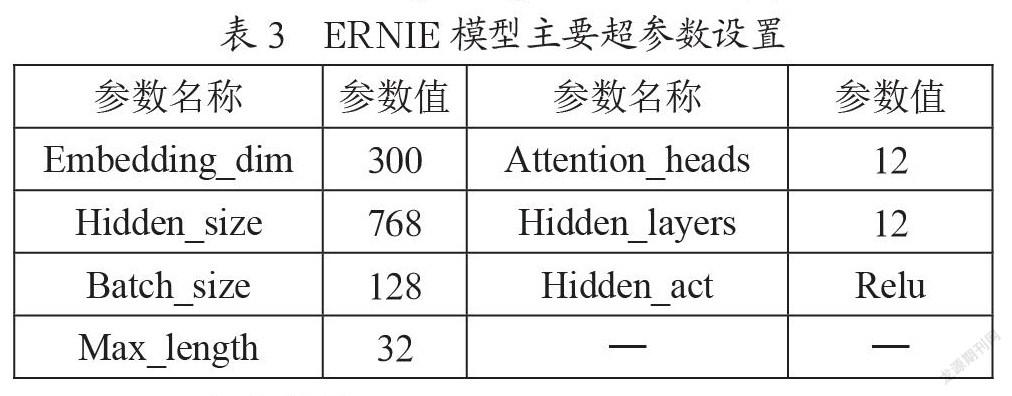
本文使用深度学习框架PyTorch1.5和预训练语言模型ERNIE1.0搭建网络模型。第一阶段BLSTM网络主要参数Embedding_dim、Dropout、学习率和优化器分别为200、0.6、0.01和RMSProp;第三阶段ERNIE模型主要超参数如表3所示,BGRU网络主要超参数Hidden_size和Dropout分别设置为768和0.1;Max-pooling超参数kernel_size为32。
3.4 实验结果
在真实的中医电子病历数据集上验证本文提出的由EMR2vec-BLSTM-CRF和ERNIE-BGRU-MP组成的流水线方法完成中医临床症状实体及属性抽取任务的整体性能。
3.4.1 中医临床文本命名实体识别
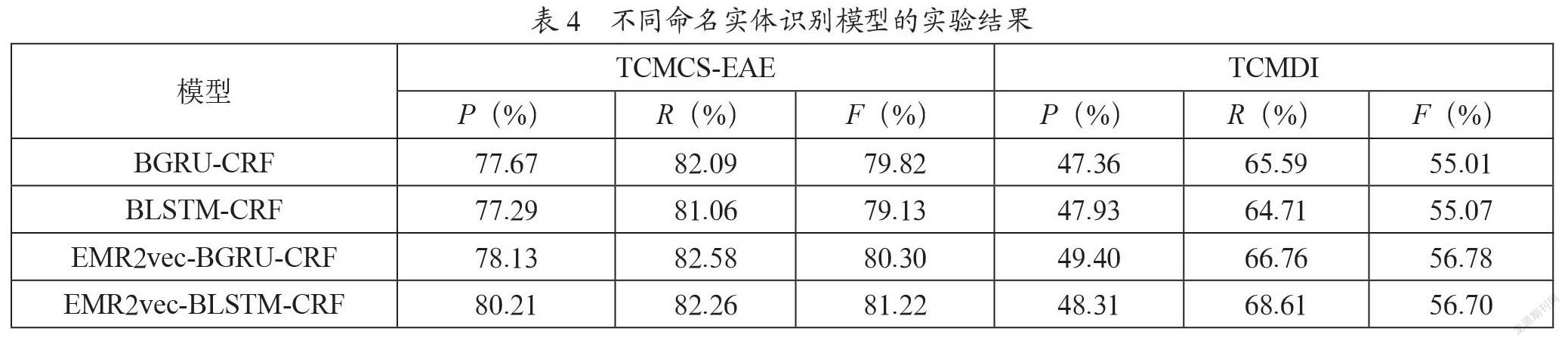
验证EMR2vec-BLSTM-CRF模型在第一阶段中医临床文本命名实体识别任务上的性能,本文选择BLSTM-CRF、BGRU-CRF和EMR2vec-BGRU-CRF作为命名实体识别对比模型,并在TCMCS-EAE和TCMDI数据集上进行对比实验。在模型训练阶段,不同命名实体识别模型的实验结果如表4所示。
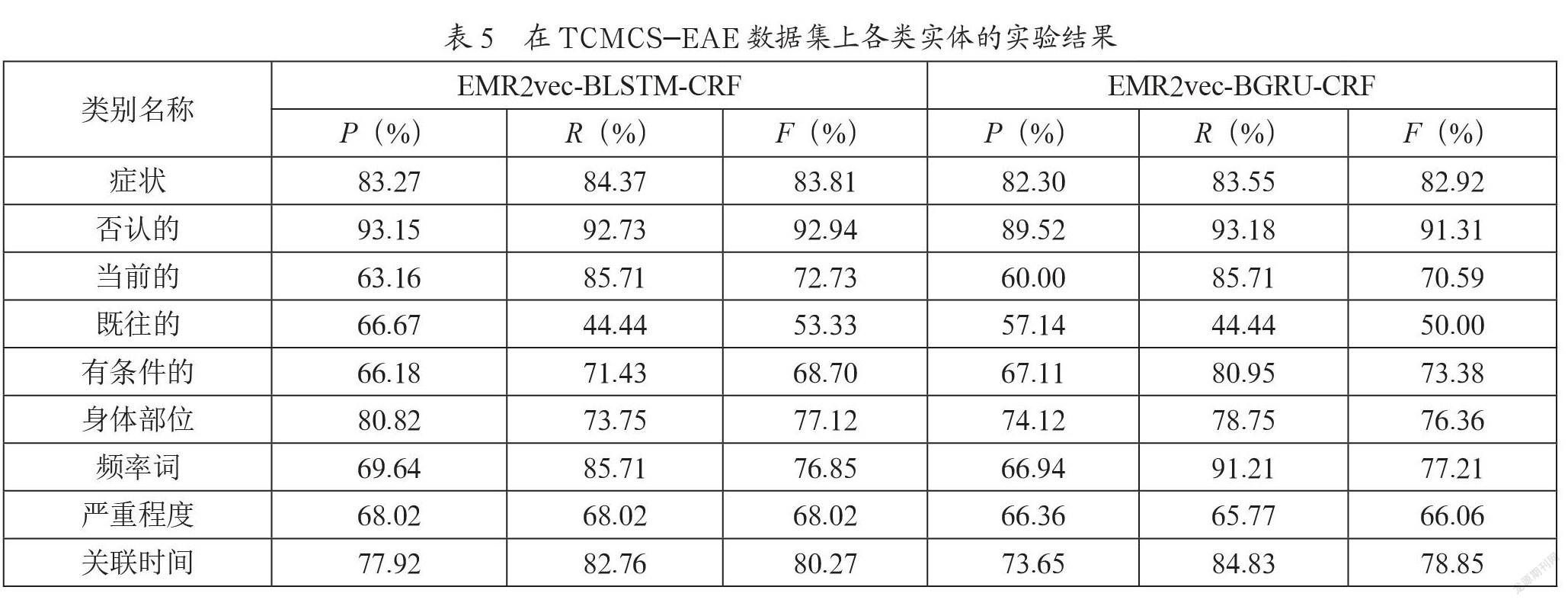
由表4可知,在TCMCS-EAE数据集中,本文提出的EMR2vec-BLSTM-CRF模型效果最优,F值为81.22%;与BLSTM-CRF相比F值提升了2.1%;在TCMDI数据集中,以EMR2vec作为模型输入效果更优,F值提升约1.5%。实验结果表明,通过引入中医临床诊疗领域数据加强对特定领域知识的表示学习,对中医临床诊疗领域命名实体识别任务有较大提升。由表5可知,除“有条件的”和“频率词”两类修饰信息外,EMR2vec-BLSTM-CRF模型的实体识别结果均优于EMR2vec-BGRU-CRF模型,其中,症状实体的P、R和F值均超过83%;8种修饰属性中,“否认的”识别效果最好,P、R和F值均超过90%;“身体部位、频率词和关联时间”的识别效果较优,F值均超过75%。这主要是因为“否认的”实体词在表达形式上相对简单、用词较固定,所以识别效果明显优于其他类别实体。
3.4.2 中医临床症状实体及属性抽取
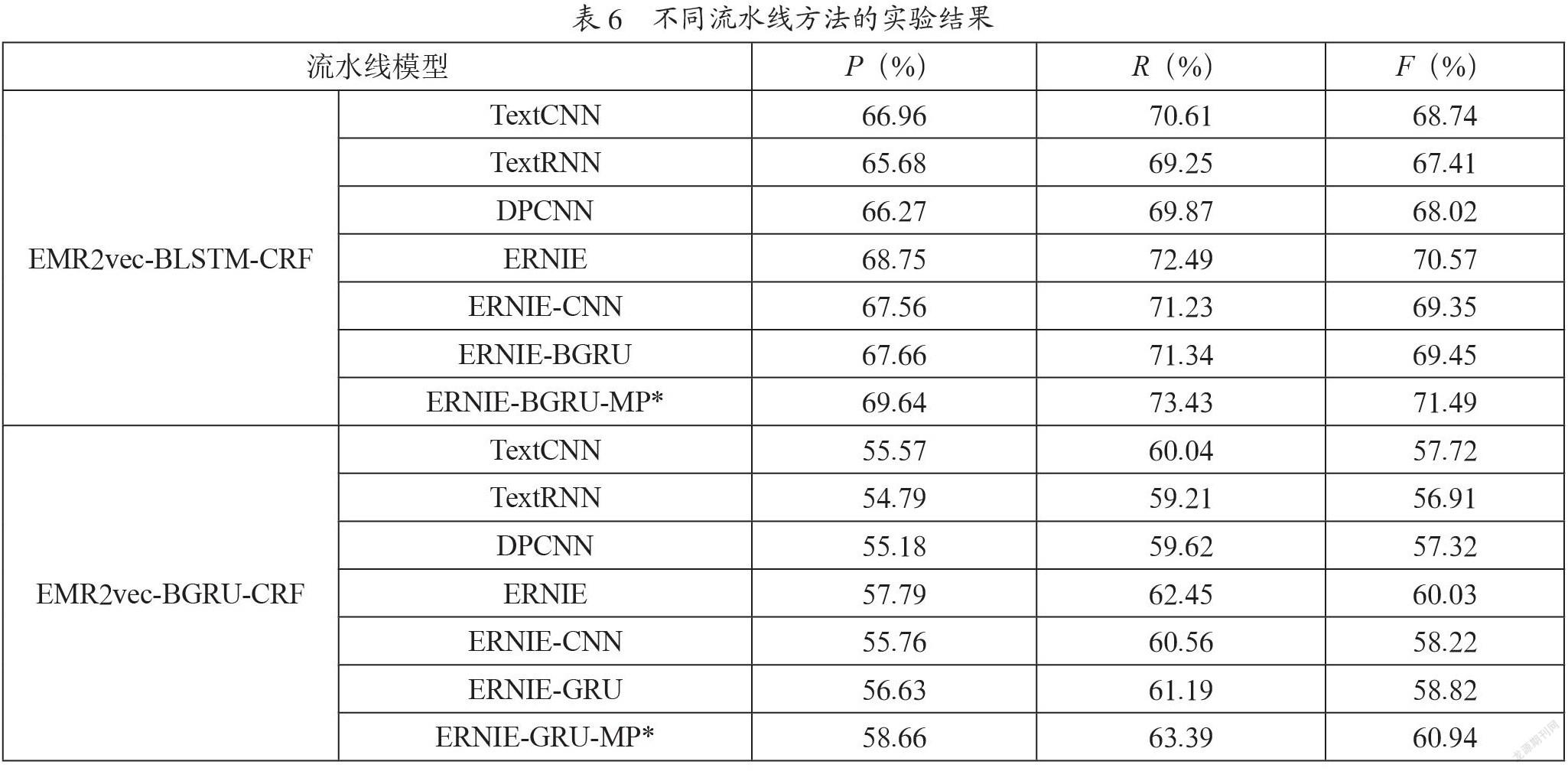
验证本文提出的由EMR2vec-BLSTM-CRF和ERNIE-BGRU-MP组成的流水线方法的整体性能。选取EMR2vec-BGRU-CRF作为第一阶段命名实体识别的对比模型,选取TextCNN、TextRNN、DPCNN、ERNIE、ERNIE-BGRU和ERNIE-CNN作为第三阶段短文本分类对比模型。因此,共有2组14个不同的基于流水线的中医临床症状实体及属性抽取方法,在TCMCS-EAE数据集上的实验结果如表6所示。
由表6可知,本文提出的由EMR2vec-BLSTM-CRF和ERNIE-BGRU-MP组成的流水线方法效果最优,F值为71.49%。第一阶段命名实体识别方法确定后,基于ERNIE及其改进的短文本分类模型ERNIE-CNN、ERNIE-BGRU和ERNIE-BGRU-MP的效果均优于传统的TextCNN、TextRNN分类模型,F值提升2%~3%。实验结果表明,ERNIE模型通过引入实体外部知识丰富文本上下文语义特征,能够有效提升中医临床症状及属性抽取任务的整体性能。此外,第三阶段短文本分类方法确定后,基于EMR2vec-BLSTM-CRF的组合模型的效果明显优于EMR2vec-BGRU-CRF组合模型,二者的F值相差约10%。其主要原因是错误累积传播,第一阶段“症状实体/修饰信息”识别的准确性严重影响第三阶段<症状实体,修饰关系,修饰信息>三元组的准确率。由ERNIE-BGRU-MP与ERNIE-BGRU模型对比结果可知,添加Max-pooling后模型的整体性能提升2.04%,与ERNIE模型相比,提升约1%。这表明最大池化通过抽取局部接受域中值最大的点,可对特征向量中的冗余信息和噪声信息起到较好的过滤效果,能够缓解多任务之间错误累积传播的问题,增强模型的泛化能力和鲁棒性。
4 结 论
本文针对医疗短文本语义信息欠缺和多任务之间错误累积传播的问题,通过ERNIE模型引入实体的外部知识特征来丰富句子的上下文信息,能够有效缓解文本语义信息欠缺的问题,使模型的整体性能提升约2%,F值达到71.49%;利用Max-Pooling过滤冗余信息和噪声信息,缓解错误累积,增强模型的泛化性和鲁棒性。在中医临床文本命名实体识别阶段,通过加强对中医临床领域知识的表示学习,使中医临床症状及属性识别的性能提升约2%,F值达到81.22%;症状实体的识别率高达83.8%,能较好地识别中医电子病历文本中患者的关键症状信息。在真实的中医电子病历数据集上的实验结果表明,本文提出的中医临床症状及属性抽取方法切实可行。在当前的研究工作中,仍面临着中医临床术语规范化弱、实验语料规模小等问题。在后续工作中,将会继续扩大实验语料规模,进一步探索新的实体及属性抽取方法,着力于中医临床诊疗知识图谱的构建。
参考文献:
[1] 杨锦锋,关毅,何彬,等.中文电子病历命名实体和实体关系语料库构建 [J].软件学报,2016,27(11):2725-2746.
[2] MIWA M,BANSAL M. End-to-end Relation Extraction Using LSTMs on Sequences and Tree Structures [EB/OL].[2021-12-16].https://arxiv.org/pdf/1601.00770.pdf.
[3] ZHENG S,WANG F,BAO H,et al. Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme [J/OL].arXiv:1706.05075 [cs.CL].[2021-12-16].https://arxiv.org/abs/1706.05075v1.
[4] 石雪.临床医疗实体及其属性的联合抽取方法 [D].哈尔滨:哈尔滨工业大学,2019.
[5] 吴赛赛,梁晓贺,谢能付,等.面向领域实体关系联合抽取的标注方法 [J].计算机应用,2021,41(10):2858-2863.
[6] 马进,杨一帆,陈文亮.基于远程监督的人物属性抽取研究 [J].中文信息学报,2020,34(6):64-72.
[7] 罗计根,杜建强,聂斌,等.基于双向LSTM和GBDT的中医文本关系抽取模型 [J].计算机应用研究,2019,36(12):3744-3747.
[8] 张昱.基于深度学习的中文电子病历实体及其修饰识别技术研究 [D].兰州:西北师范大学,2019.
[9] CHO K,MERRIENBOER B V,GULCEHRE C.et al. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation [EB/OL].[2021-12-16].https://arxiv.org/pdf/1406.1078.pdf.
[10] 毕云杉,钱亚冠,张超华,等.基于ERNIE模型的中文文本分类研究 [J].浙江科技学院学报,2021,33(6):461-468+476.
[11] ZHENG Y Z,XU H,ZHI Y L,et al. ERNIE:Enhanced Language Representation with Informative Entities [C]//the 57th Annual Meeting of the Association for Computational Linguistics.2019:1441-1451.
作者简介:胡定兴(1996—),男,汉族,湖北黄冈人,硕士研究生在读,研究方向:自然语言处理、知识图谱构建;杜建强(1968—),男,汉族,江西南昌人,教授,博士,研究方向:中医药信息学、数据挖掘;石强(1976—),男,汉族,江西南昌人,副教授,医学博士,研究方向:中医辨证规律;罗计根(1991—),男,汉族,江西萍乡人,讲师,硕士,研究方向:自然语言处理;刘勇(1997—),男,汉族,江西抚州人,硕士研究生在读,研究方向:自然语言处理。