王耀葛,文瑞森,庞贵杰
(广东工业大学 信息工程学院,广东 广州510006)
0 引 言大数据时代,图像描述所用到的技术包括计算机视觉与自然语言处理,这是人工智能的两个主要研究领域。图像描述任务就是给计算机一张图像,让计算机自动生成一句符合图像内容的描述语句。图像描述任务在盲人视障、儿童早教、人机交互、游客导航等多方面有着不可估量的应用前景。
图像描述任务的生成算法主要有三类:基于模板的图像描述生成方法、基于检索的图像描述生成方法和基于深度学习的图像描述生成方法。目前用得最多的方法是基于深度学习的图像描述生成方法,该方法采用卷积神经网络(Convolution Neural Network, CNN)获取图像特征信息,采用循环神经网络(Recurrent Neural Networks, RNN)生成描述语句。2015年,Vinyals等提出了神经图像字幕(Neural Image Captioning, NIC)模型,Decoder使用带有记忆功能的长短期记忆网络(Long Short-Term Memory, LSTM)来生成描述语句。Xu等对NIC模型进行了改进,第一次在图像描述任务中引入机器翻译中常用的注意力机制。2018年,Anderson等提出了一个自底向上与自顶向下相结合的注意力模型,使用Faster R-CNN获取图像的特征信息。2020年,Wu等提出了用于图像描述的层次注意融合模型,将多级视觉特征与层次注意力整合在一起生成描述。Wei等通过结合语句级注意和单词级注意生成图像描述。
以上模型的解码器大多数是通过单层或双层LSTM网络实现的,对于复杂的图像描述任务来说解码能力有限。同时模型使用交叉熵损失进行训练,这会存在曝光偏差和损失评估失配等问题。为了解决上述问题,本文提出一种基于注意力机制和强化学习的三层LSTM网络图像描述模型。本文进行了以下研究工作:
(1)提出一种改进的结合注意力机制的三层LSTM网络解码器,其中每两层LSTM网络间使用空间注意力模型进行连接,以增强注意力机制的效果。
(2)采用强化学习的训练策略来解决曝光偏差和损失评估失配等问题,提升模型在评价指标中的得分,进一步提高模型的性能。
1 基于编码器-解码器的图像描述模型在编码器-解码器框架中,编码器将图像作为输入。该图像的真实描述语句为= {,, . . . ,} ,S为One-hot向量,表示每个单词。模型训练的目标是使生成下一个预测单词的概率值最大,即:
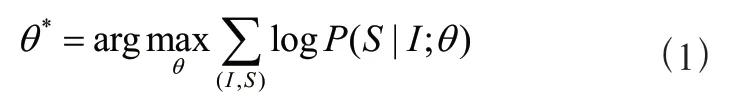
其中,为模型参数。因为描述语句由不同单词组成,故上式可以分解为:
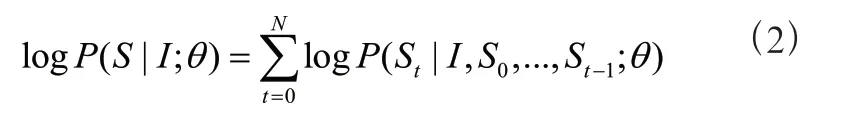
上式中(,, . . . ,;) 的计算是一个序列问题,故可以使用LSTM网络作为解码器,可以表示为:
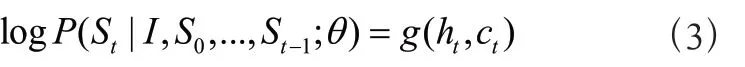
其中,(·)为S概率的非线性输出,h为LSTM的隐藏层状态,c为上下文向量。使用LSTM网络求得+1时刻生成单词的概率分布,即:
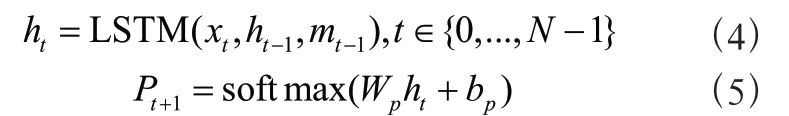
其中,x,h分别为LSTM网络当前时刻的输入和前一时刻的隐藏层状态,m为前一时刻的记忆细胞状态,W为要训练的参数,b为偏置参数。
2 改进的图像描述解码器模型本文提出的解码器模型为三层LSTM网络结构,其模型结构图如图1所示。图1中用上标表示每一层,用表示图像特征。
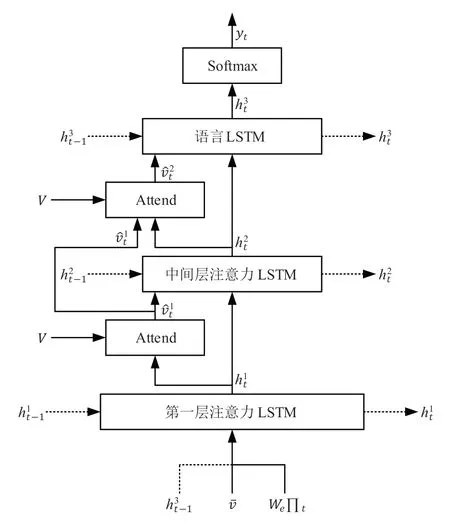
图1 改进的三层LSTM网络模型结构图
2.1 第一层注意力LSTM模型
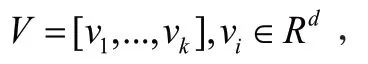
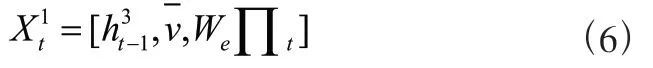
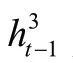
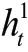
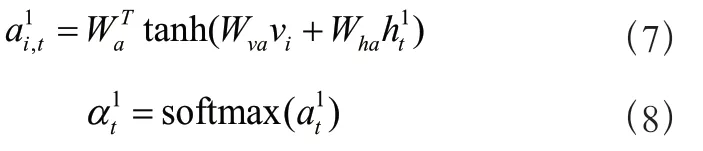
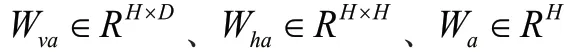

第二个LSTM层为中间层注意力模型。在这一层中,当前时刻中间层注意力LSTM的输入向量由下式给出:


第三个LSTM层为语言模型。在这一层中,第步的语言注意力LSTM的输入向量由下式给出:


本文使用的训练数据集为MS-COCO数据集,MSCOCO图像集含有113 287张训练图片,5 000张验证图片,5 000张测试图片,图像集中每张图像对应于5个人工生成的描述信息。对于人工标注描述,计算每个单词出现的次数,保留出现次数大于5次的单词,<START>标记生成语句的开头,<END>标记生成语句的结尾,最终得到的单词表包含9 489个单词。
实验平台为Ubuntu16.04.7,使用Pytorch深度学习框架,GPU为显存为11 G的GeForce RTX 2080 Ti,CUDA版本为11.0,CPU为英特尔E5-2609,内存为32 GB。
3.2 图像描述模型训练模型训练阶段使用ResNet-101网络作为编码器,使用改进的三层LSTM网络作为解码器。选用Adam优化器,学习率设置为5,每隔3epoch就会渐进式地减小学习率为原来的0.8倍。实验Resnet101(XE)采用交叉熵损失函数,设置batch_size为192,并进行多达100 epoch的训练。实验Resnet101 (RL)在训练集上总共训练了100个epoch,前50个epoch使用交叉熵损失函数进行训练,设置batch_size为192;后50个epoch使用强化学习损失函数进行训练,设置batch_size为64。为了避免出现过拟合,采用Dropout方法来优化训练,beam_size设置为3。
3.3 实验结果与分析本文采用BLEU-1、BLEU-4、METEOR、ROUGE和CIDEr共5种评价指标,评价得分越高表示生成描述语句的质量越好。与其他学者提出的模型相比,将本文模型Ours(XE)、强化学习优化后的本文模型Ours(RL)分别与Up-Down、HAF和DAIC模型在MS-COCO数据集上进行对比,结果如表1所示。表中加粗的为最高评分,“—”表示未在文献中找到其数据。

表1 本文图像描述模型与其他模型在MS-COCO数据集上的得分对比
从上表中的实验数据可以看出,本文提出的基于三层LSTM网络的图像描述生成模型的评价指标得分大都优于目前流行的图像描述生成模型。通过对比Ours(XE)和近期提出的HAF图像描述生成模型获得的评价指标得分,除了BLEU-1,本文提出模型的其他评价指标均持平或有所提升。通过强化学习策略优化模型Ours(RL)后的各项评价指标的得分均优于目前流行的模型,能生成更有效的图像描述语句。
图2为本文模型与Up-Down模型生成描述语句的对比示例。本文Ours(RL)模型生成的描述语句比Up-Down模型和未进行强化学习的Ours(XE)模型更准确。例如图2的第一幅图像,Up-Down模型给出的描述为A man riding on the back of a horse,而本文提出的Ours(XE)模型给出的描述为A man riding on the back of a brown horse,把马匹的颜色都描述出来了。再看一下本文提出的用强化学习策略优化的Ours(RL)模型,其给出的描述为A man riding a horse with a group of dogs,不仅准确描述了主体事件——男人骑马,还把后面跟着的一群小狗也表达出来了,所描述的语句更加具体生动,更加符合图像所展示的内容,展现了本文模型的良好性能。

图2 Updown模型、Ours(XE)模型和Ours(RL)生成图像描述对比
4 结 论本文提出了一种基于视觉注意力机制和强化学习的三层LSTM网络图像描述模型,在编码器阶段采用ResNet-101网络提取图像的特征信息,在解码器阶段使用三层LSTM网络模型对提取到的图像特征进行解码,生成图像描述。MSCOCO数据集上的评价指标对比结果表明,本文模型可以生成更具体、更全面的描述语句,同时利用强化学习优化后的模型生成的描述语句更加准确。