张伟娜
(中国民用航空飞行学院洛阳分院,河南 洛阳 471001)
0 引 言目前互联网应用已经深入到了人们生产生活的方方面面,计算机网络在人类生活的各个领域已起着越来越重要的作用。随之而来的网络安全威胁变得日益严重,越来越多的关键业务已成了黑客的攻击目标,各种网络攻击也层出不穷,一旦网络安全出现问题,将造成巨大的损失,因此网络安全成了一个困扰网络应用的首要问题。尤其是蠕虫、DDoS及DoS等攻击带来了巨大的危害,例如DDoS攻击可以利用分散在网络各处的其他主机协作共同完成对一台主机攻击的操作,从而使被攻击主机进入不安全状态。因此对网络主机的状态进行主动识别变得尤为重要,如何高效精确的检测主机是否存在不安全行为或处于不安全状态已成为一个十分必要的研究课题。
对于主机安全检测这一问题,国内外许多专家也已经做了很多的研究。传统的检测模型主要有数据统计及模式匹配等简单的数据分析方法。文献[1]提出了两种模式匹配的入侵检测方法,一个是基于BM的模式匹配算法进行入侵检测,另一个是根据字符出现概率进行优先匹配。文献[2]对四种模式匹配的入侵检测算法进行了测试和比较。文献[3]使用朴素贝叶斯分类器实现异常检测。随着大数据及神经网络等方法被广泛地应用于各个领域,常用的数据挖掘方法也逐渐被引入主机安全检测。文献[4]提出了一种支持向量机的入侵检测方法,并利用AdaBoost对其模型进行训练。文献[5]提出了一种改进的BP神经网络进行主机安全检测方法,主要是采用自动变速率学习法,同时引入遗忘因子等。文献[6]提出了一个基于机器学习的网络入侵检测系统。文中提出了将两种支持向量机结合起来的方法,此方法同时具有监督学习中的无监督学习的优点。文献[7]提出了一种网络入侵检测的非线性分析方法,文中使用了一种非线性技术递归量化分析,这种方法通常用于具有时间相关性的数据统计。文中深入探讨了递归量化分析和支持向量机技术在事件分类中的应用。结论表明非线性技术有助于获取网络数据的隐藏特性,当使用支持向量机机器学习时可以用于网络异常检测。
随机森林是由Breiman于2001年提出,其本质也是一种对数据进行挖掘的理论,利用重抽样方法抽取样本,然后生成对应的决策树,通过所有树的投票得到最终结果,是一种有效的非线性数据的建模工具,近几年来已经被广泛地应用于计算机、医学、经济学、等多个领域。文献[9]提出了一种利用随机森林来改进图像分割的方法,文中讨论了随机森林是如何学习判别特征的,并提供了这些特征重要性的量化,利用这种被量化的重要性特征设计一个策略进行有效的分类,作者在许多医学图像上测试了这种分割方法,结果表明这是一种有效的图像分割方法。一些传统方法例如决策树、支持向量机及贝叶斯等在面对数据较多时检测误差率较大,因此检测效率不够。但是随机森林在处理高纬度数据时具有较好的表现,随机森林对异常值和噪声具有很好的容忍度,并且具有较好的泛化能力,因此本文采用随机森林分类模型实现对主机的网络行为进行检测。
1 检测模型随机森林可以通过重采样的方法从原始数据集中提取多个子样本,通过构造多个针对不同的特征值的决策树对同一问题进行预测,然后通过所有决策树产生的结果进行投票,最终度量特征值重要程度,同时消除不太重要的特征值的影响,进而产生一个较为准确的结果。随机森林模型对于海量的数据集也能达到较快的训练速度,并且与单独决策树相比可以有效地避免过拟合现象,具有更好的稳定性。
本文分别对多个特征值构造多个决策树,在每棵树的每一次分割时对分割准则不断进行调整。随机森林中的决策树由训练集的二进制分割序列构造成终端节点,如图1所示。
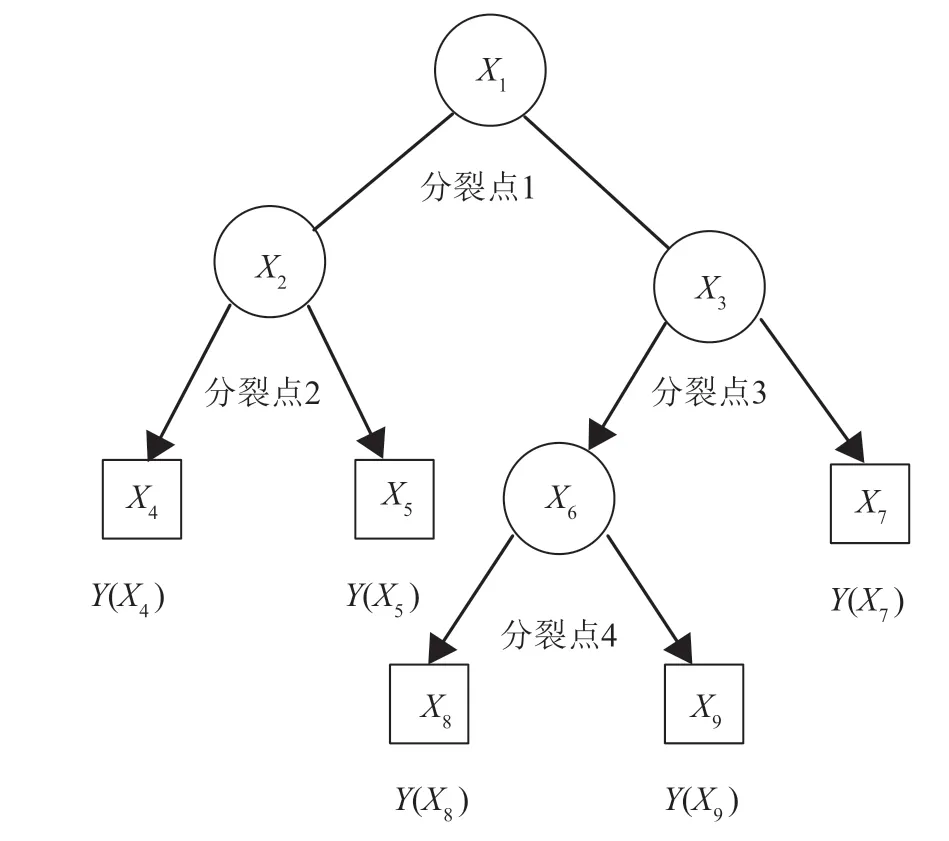
图1 决策树的结构
在主机安全检测中把度量主机是否存在不安全状态的相关参数作为输入的特征值,用这些特征值对相应主机的安全状态进行检测。首先需要用训练集对模型进行训练,随机森林的构建过程如下:
1.1 构建数据集本文对主机安全状态使用归一化的方法进行评估,越接近1说明主机的状态低,越接近0代表主机的安全状态越高,因此实际主机的安全状态为I=[I,I,…,I],其中∈[0,1]。定义第个与检测主机安全状态相关的个特征值数据集为X=[X,X,…,X],其中X∈R,X={X,X,…,X}。本文的I与X有对应关系,也就是说X为第个主机的特征值,I为第个主机的安全状态。
1.2 单棵决策树的构造过程
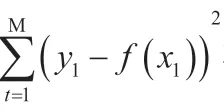
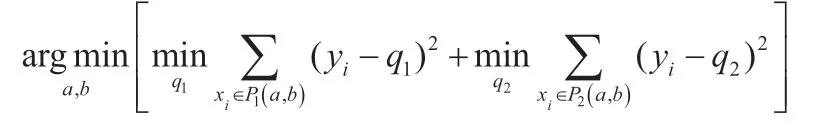
其中y代表第个主机的安全状态,x代表与检测主机安全状态相关的特征值,q代表分裂的第一部分主机安全状态的平均值,q代表第二部分主机安全状态的平均值。
决策树不能一直的分裂,这会导致最终生成树的复杂度过高,所以需要在合适的时候停止分裂。当数据属性增多时,单棵决策树的节点也会相应增加,同时也会增加决策树的复杂度,最终导致模型的过拟合,因此在许多其他实验中决策树通常通过修剪进一步提升性能,也就是移除不重要的分支,但是本文在实验中发现剪枝对检测精度提高并不明显,因此在本文中不对决策树进行剪枝操作。本文直接设置节点到决策树根节点的距离为决策树的深度,也就是说当子节点深度D≤时,代表此节点为终端节点,不再进行分裂,本文中设置决策树的=5。
1.3 随机森林的构造在单棵决策树构建完成后,需要构造其他决策树共同形成随机森林。本文采用有放回的堆积抽取个特征值,按照构造单棵决策树的贪婪算法生成其他决策树。每棵决策树根据设定的决策树深度停止分裂。最终生成的棵决策树共同构成随机森林检测模型。检测模型训练完成后需要对模型的拟合度进行检验,本文通过最小化误差来验证检验模型,即:
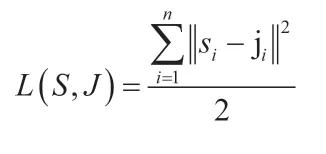
其中当检验结果和与实际数值的差值足够小时,说明整个模型的拟合程度较为充分,也就是说这个模型是有效的。随机森林的构造方法具有多个优点,首先通过随机选择特征值使得每棵决策树的关联性更小,这可以提高模型的检测精度,并避免出现过拟合现象;其次可以区别特征值在分类中的重要性,并且单个决策树增长速度更快;最后针对具有噪声的数据也具有良好的稳定性。
2 实验验证本文的数据通过实验仿真在局域网模拟DDOS攻击采集相应特征值数据并进行模型的参数训练与检测验证。得到数据集后,首先对数据进行预处理,由于各种实际原因,原始数据包含一些缺失或无效的数据,本文对缺失的数据使用平均值进行填充。然后把原始数据集分为两个子集,分别是训练集和测试集。选取方式为随机抽取多个样本作为训练集,其余的未被选中的数据集作为测试集。首先用训练集的数据来训练的检测模型,从原始数据集中随机抽取多个子集,每个子集组成每棵决策树的训练集,然后按照相应的方法构造对应的决策树,过程如图2所示。然后利用测试集的数据通过训练完成的决策树,每棵决策树共同投票得到最终分类结果,即使用测试集来验证整个检测模型的过程如图3所示。为了加快训练和检测的过程,本文采用归一化方法对预处理后的数据集进行处理。在训练模型之前,对原始数据进行归一化处理并不会对检测结果有影响,因为在得到预测结果后,通过对归一化过程进行逆向处理,就可以得到正常检测值。
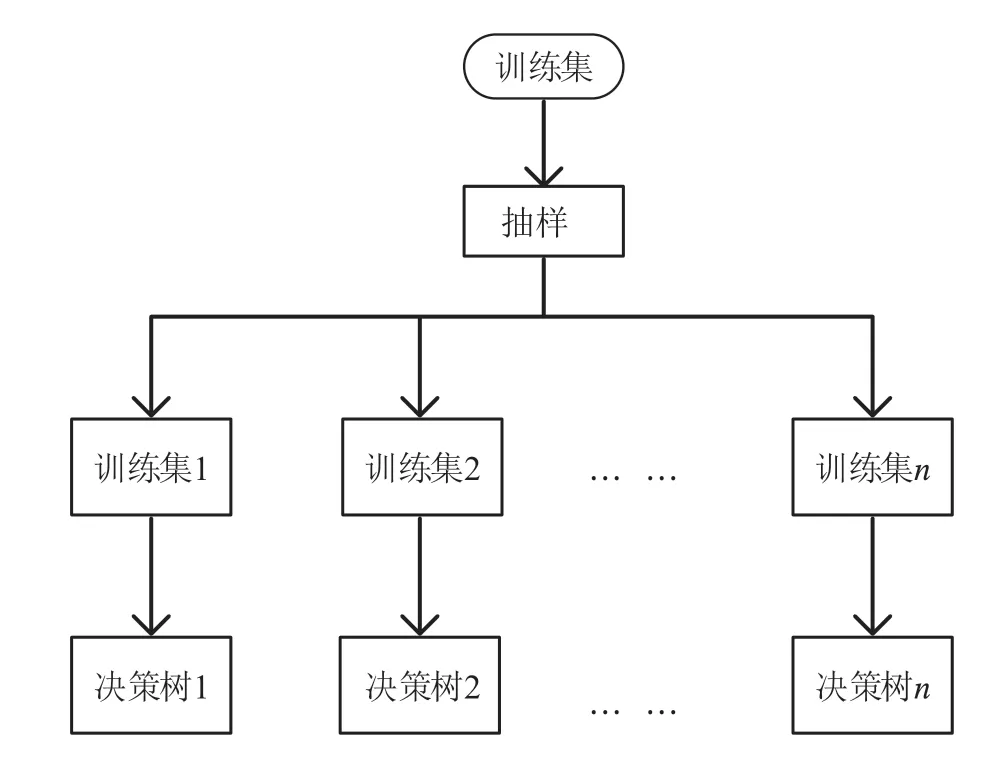
图2 模型训练过程
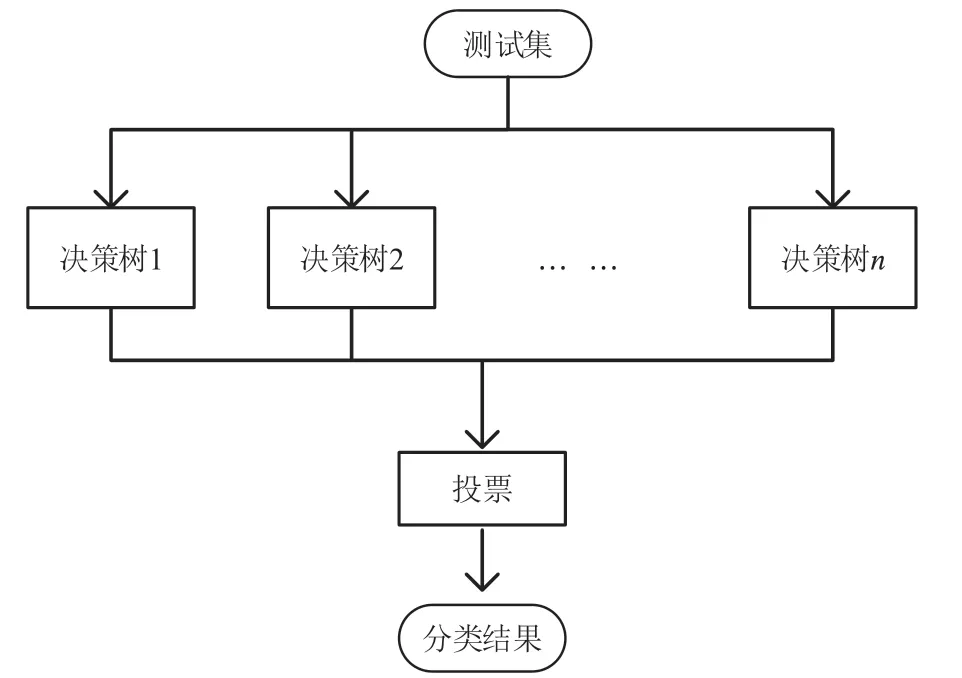
图3 模型测试过程
本检测模型使用的特征值包括五种,分别是特殊协议所占总流量的比例、网络传输速率、实时连接会话数、TCP确认报文数量和报文长度。在生成每个决策树时采用随机选取多个不同方面的多个特征值。检测方法的性能使用三种常用的有效性度量来评估,分别是误报率、检测率和漏报率。其中误报率为安全样本被判断为不安全样本数量与安全样本总数的比,检测率为成功检测出不安全样本数量与不安全样本总数的比。
从表1的试验结果可以看出本文使用的检测模型与传统检测模型支持向量机相比,检测精度高于传统的检测方法,检测率达到了0.81,同时误报率也比传统的检测方式更低,误报率为0.12,可见该检测模型对主机安全检测具有较高的检测精度。

表1 检测模型性能比较
3 结 论本文提出了一种用于网络中主机安全检测的随机森林的检测模型。此模型从原始数据中进行随机有放回的抽取子集,并利用子集构建决策树,这样可以避免每棵决策树之间的相关性,从而使得检测模型不容易陷入过拟合,并且具有很好的抗噪能力,提高检测精度。本文在实验的数据集上验证了此模型的性能,实验结果表明,对原始数据进行特征提取后再进行数据清洗可以提高检测的精度,并且与传统检测模型相比该模型在主机安全检测方面具有良好的性能,其提高了检测率,降低了误报率,具有更好的稳定性,为网络安全提供更好的安全保障。