
摘 要:现有的三维点云MAE的算法存在位置信息泄露问题和模态单一问题。为了解决这些问题,文章提出了一种用于点云-图像-点云MAE算法,称为PIP-MAE,该算法通过丰富二维图像知识来指导三维点云预训练模型,对输入的三维点云及其投影的二维图像进行随机掩模,然后重建两种模态的遮掩信息。对下游任务进行了实验,验证了PIP-MAE算法的有效性,提高了下游任务精度,能广泛用于各类下游任务。
关键词:深度学习;点云重建;点云分类;点云分割
中图分类号:TP18 文献标识码:A 文章编号:2096-4706(2024)08-0097-05
0 引 言
学习未标记数据中的潜在特征的表示称为自监督学习[1]。自监督学习通过对大规模数据进行预训练,该网络对各种下游任务具有强大的表示能力和高泛化能力。MAE(Masked Autoencoders)是自主监督学习的主要方案之一。它随机遮掩一部分输入数据,并采用Transformers [2]编码器来提取未遮掩的特征。然后,利用轻量级Transformers解码器对掩码位置信息进行重构,在自然语言处理、计算机视觉和多模态学习方面取得了巨大成功。
最近,人工智能技术和三维传感器的迅猛发展,三维点云由于其丰富的形状信息,正受到机器人、逆向工程、自动驾驶等领域的广泛关注。MAE在三维点云上将三维点云划分为多个点块,并随机遮掩部分点块,自编码器从未遮掩的点块中学习用来重建坐标空间中遮掩点块。一旦自编码器在自重建任务上训练得到足够好的表示,这些表示可以用于其他下游任务,如分类、聚类或生成新的样本上。然而,传统的MAE方法只能独立处理单个模态,而不能利用它们的隐含相关性。其次,在编码过程中,重复连接多个三维点云,导致三维点云位置信息多次泄露。为此,本文提出了PIP-MAE算法,通过实验验证了该方法的有效性和高泛化能力。
1 相关工作
1.1 三维点云预训练
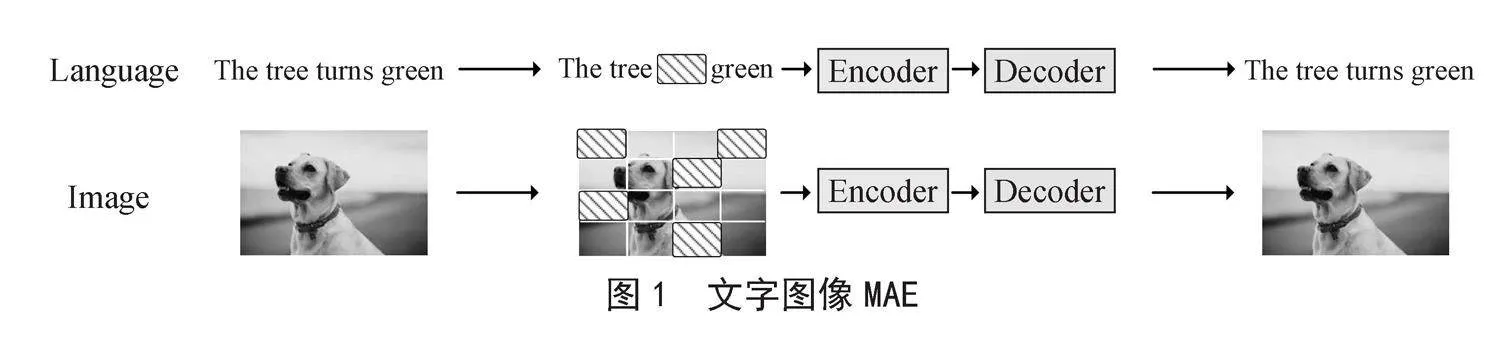
近些年,随着在MEA在文字和图像(如图1所示)上的处理成功。促使人们开始研究三维点云自监督学习的框架。在这些方法中,对比法已被广泛研究,PointContrast [3]利用来自不同视图的相同点的特征之间的对比学习,来学习有区别的三维表示,以获取丰富的自监督信号。另一种思路则是集成跨模态信息,利用语言或图像模型转移的知识用于三维点云学习。PCT [4]采用交叉模态自动编码器作为训练模型,以从其他模态获取知识。
因此自监督学习显著增强了三维迁移学习。受图像中的MAE [5]的启发,Point-BERT [6]提出从随机重新排列的部分重建点云。具体来说,给定一个高比率掩蔽的输入点云,学习编码器-解码器模型,以从未掩蔽的点重建掩码点。通过这种方式,编码器可以学习语义特征表示,这可以很容易地应用于下游任务。其中,Point-MAE [7]直接对三维点云进行掩码编码。我们的PIP-MAE的不同之处在于采用了传统的Transformer框架,我们的解码器只输入可见的点并输出重建了遮掩点,以减少解码过程中的位置泄漏。然后,我们将掩蔽点投影到二维图像中,并利用二维和三维模式之间的隐式相关性,来构建更强大的三维自监督学习模型。
1.2 Transformer
Transformers通过自注意机制对输入的全局依赖性进行建模,并且在自然语言处理时中占主导地位。自ViT [8]以来,Transformers在计算机视觉中一直很流行。然而,作为掩码自编码器的主干,用于点云表示学习的Transformers架构较少。最近的工作Point-BERT引入了一个标准的Transformer架构,但需要DGCNN [9]来辅助预训练。本文的提出的MAE架构,完全基于标准的Transformer。
1.3 Point-Image-Point(点云-图像-点云)学习
从不同模态上学习,往往会得到多个模态的学习信息,从中可以很容易地处理给定上下文的语义信息。在三维点云MAE风格中,大部分文章都展示了多模态预训练的强大能力。CrossPoint [10]提出了一种图像点对比学习网络,CLIP [11]通过最大化图像和文本模态之间的余弦相似性来学习多模态嵌入空间,I2P-MAE [12]通过图像到点学习方案,以二维预训练模型为指导。与这些方法不同,我们的PIP-MAE在遮掩阶段引入了PIP引导的和二维图像的局部几何信息。在重建阶段,我们的PIP-MAE直接重建了三维点云的遮掩点,而且还将重建的点沿X、Y、Z投影到二维几何局部图像中,用于二维图像重建。
2 PIP-MAE
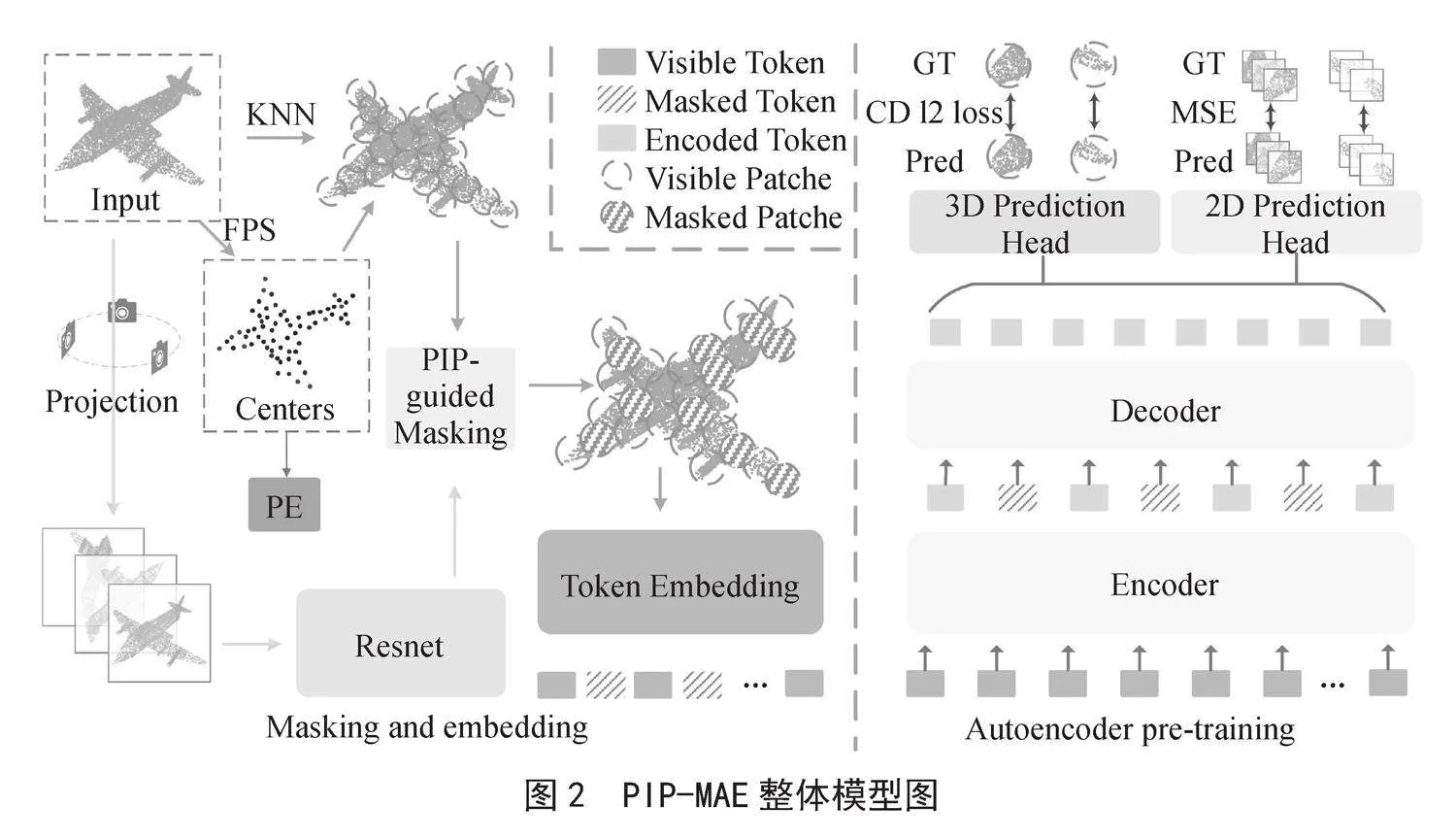
本文的目标是为三维点云设计一个整洁高效的掩码自编码器方案。图2为本文的总体方案。本章节首先介绍了三维点云遮掩和嵌入自编码器预训练,其中包括重要的PIP引导过程和嵌入。接下来,我们介绍一下我们的编码器和解码器设计,值得注意的是,在解码器中我们只输出遮挡重构的点。最后,介绍了交叉重建损失。
2.1 三维点云遮掩和嵌入
与计算机视觉中可以划分为规则块的图像不同,三维点云由三维空间中的无序点组成。根据点云的性质,可以对输入点云进行了两个阶段的处理:点云块生成、二维深度投影和嵌入。
2.1.1 点云块生成
通过最远的点采样(FPS)和K近邻(KNN)算法将输入点云划分为不规则的点块。形式上,给定具有p个点X ∈ ℝM×3的输入点云,FPS被应用于采样点片中的CT中心的N个点。基于中心点,KNN从输入中选择k个最近点用于对应的点块P。
(1)
(2)
2.1.2 二维深度投影和嵌入
为了多个模态对齐,需要在三维点云中建立RGB图像像素建立连接,通从三个正交视图中沿着X、Y、Z轴投影输入点云X ∈ ℝM×3。对于具有M个点的输入点云,只需省略每个点的第三个坐标,并将其他两个坐标取整,可获得相应地图上的二维位置。然后,在三次重复之后,模拟三通道RGB来反映点的相对深度关系。公式化为:
(3)
2.2 PIP(点云-图像-点云)遮掩
在现有的MAE算法中,一般使用了两种策略:随机遮掩或快遮掩,它们具有很高的不稳定性,且会忽略局部几何信息。PIP-MAE算法将局部几何形状显式地反向投影到三维空间中,以指导P面片的遮罩。具体来说,取上一个沿X、Y、Z投影的二维图像I ∈ ℝH×W×3,并使用经过训练的ResNet [13]网络提取RGB多通道视图特征,表示为F。最后,在反投影到三维空间后,使用Softmax函数进行归一化,得到S ∈ ℝN×1,并将每个元素的大小视为对应点斑块的可见概率。通过归一化,我们能够更好地关注局部信息,并且更关键的三维点块更有可能被保留:
(4)
2.3 自编码器预训练
我们用标准的Transformer块构建了自动编码器,并采用非对称的编码器-解码器设计。并通过三维-二维预测头重建三维点-二维目标。
2.3.1 编码器
只有可见标记Tvis ∈ ℝ(1-m) N×C被编码,而被屏蔽的补丁不暴露于编码器。这不仅在计算上高效,而且避免了掩码补丁位置信息的早期泄漏。编码标记表示为Te ∈ ℝ(1-m) N×C。标准的Transformer块编码器公式化为:
(5)
2.3.2 解码器
与编码器类似,也使用标准Transformer构建解码器。解码器将编码的可见标记Te ∈ ℝ(1-m) N×C可学习掩码标记Tm ∈ ℝmN×C及其PE作为输入,经过处理后,解码器仅输出解码的掩码标记Td ∈ ℝmN×C,解码器公式为:
(6)
2.4 三维——二维重建
使用简单线性层(FC)作三维点云的重建头,预测头旨在重建坐标空间中的遮掩点云点块Ppre ∈ ℝmN×k×3,遮掩点的地面实况三维坐标Pgt ∈ ℝmN×k×3。预测头的公式为:
(7)
然后,我们通过倒角距离(CD [14])计算损失,其公式化为:
(8)
2.4.1 二维语义重构
我们以预测点斑块Ppre ∈ ℝmN×k×3坐标为索引,沿X、Y、Z轴重建二维局部语义特征,通过通道聚合Td ∈ ℝmN×C对应的二维特征,公式为:
(9)
然后,沿遮挡中心CTmask的X、Y、Z轴重构二维局部语义特征,其中CTmask表示遮蔽面片的中心,CT = CTmask + CTvis,并使用均方误差(MSE)计算L2D损失为:
2.4.2 总损失
三维-二维交叉重建损失可以更好地对重建点云的空间结构进行自我监督,可以更好地关注三维点云的局部信息。PIP-MAE预训练的总损失公式化为:
(11)
3 相关实验
实验首先介绍PIP-MAE预训练,然后在一系列下游任务中评估了预训练模型的有效性。整体效果图如图3所示。
3.1 PIP-MAE 预训练
在数据集ShapeNet [15]上预训练PIP-MAE,ShapeNet由51 300个干净的三维点云组成,涵盖55个常见对象类别。对于每个实例,通过FPS采样1 024个点作为输入点云,深度图大小H×W设置为224×224特征信道(C),32个邻接点(k),512个下采样数(M),以及60%的遮掩比例。将数据集拆分为一个训练集和验证集,仅对训练集进行预训练。使用AdamW [16]优化器和余弦速率衰减[17]。学习率设置为10-3,权重衰减为5×10-2。预训练为300个批次,批量大小为128。对于现成的二维模型,使用CLIP预先训练的ResNet作为默认值,冻结在三维点云预训练期间的权重。
3.2 下游任务
在预训练后,本文在多个三维下游任务上微调PIP-MAE的三维点云分支,既形状分类、少样本分类和部件分割。在每个任务中,使用解码器(去掉二维分支),并由编码器使用特定的分类头进行下游任务。
3.2.1 形状分类
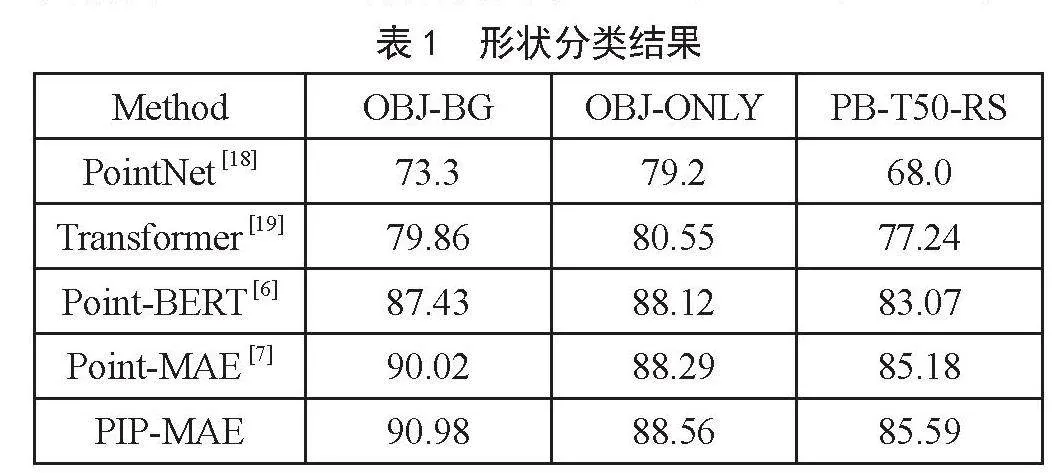
本文在ScanObjectNN [15]数据集上进行三维形状分类实验,ScanObjectNN是从背景杂乱的真实室内场景数据中扫描的,因此包括带有噪声的背景,含11 416个训练样本和2 882测试样本。实验在三种不同的设置下进行,OBJ-BG、OBJ-ONLY和PB-T50-RS。结果如表1所示,与传统的方法Point-MAE相比,我们的PIP-MAE分别提高了1.0%、0.3%和0.4%。
3.2.2 少样本学习
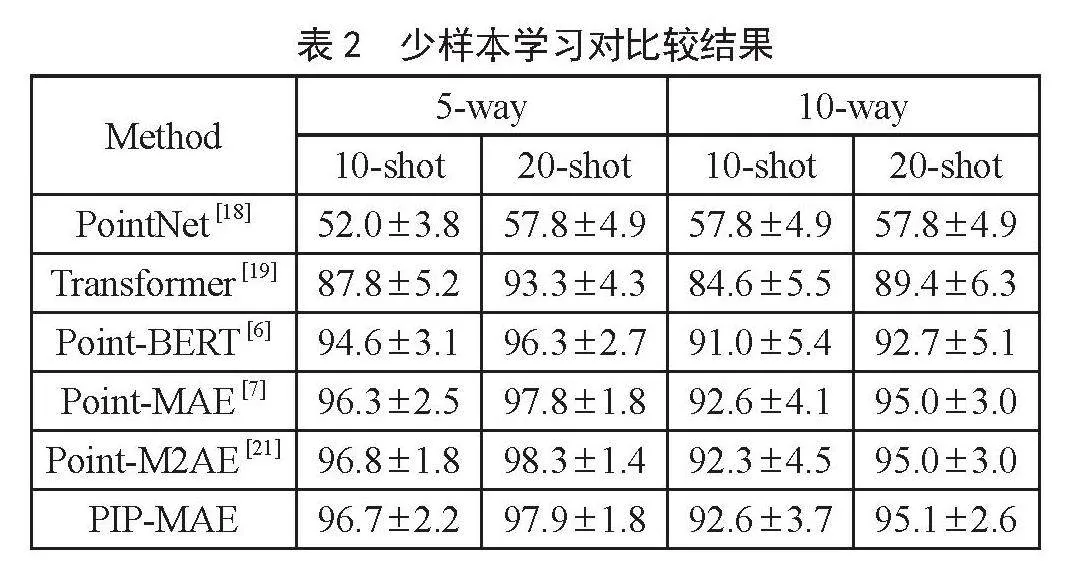
为了评估PIP-MAE在有限的约束下的表现,本文还在ModelNet40 [20]上进一步进行了少样本分类任务。少样本分类实验由四个不同的测试组成,即使用方法和射击设置。具体地说,w ∈ {5,10}表示随机选择的类的数量,s ∈ {10,20}表示每个选择的类随机采样的对象的数量。每个测试包含10个独立属性。结果如表2所示,PIP-MAE显著提高了四种设置的水平0.3%~0.8%。证明了的PIP-MAE可以在有限的约束下表现良好。
3.3 对比实验
在本节中,将探讨PIP-MAE中不同遮掩实验得出的精度结果。同时将探讨令牌在解码器和编码器中的对精度的影响。
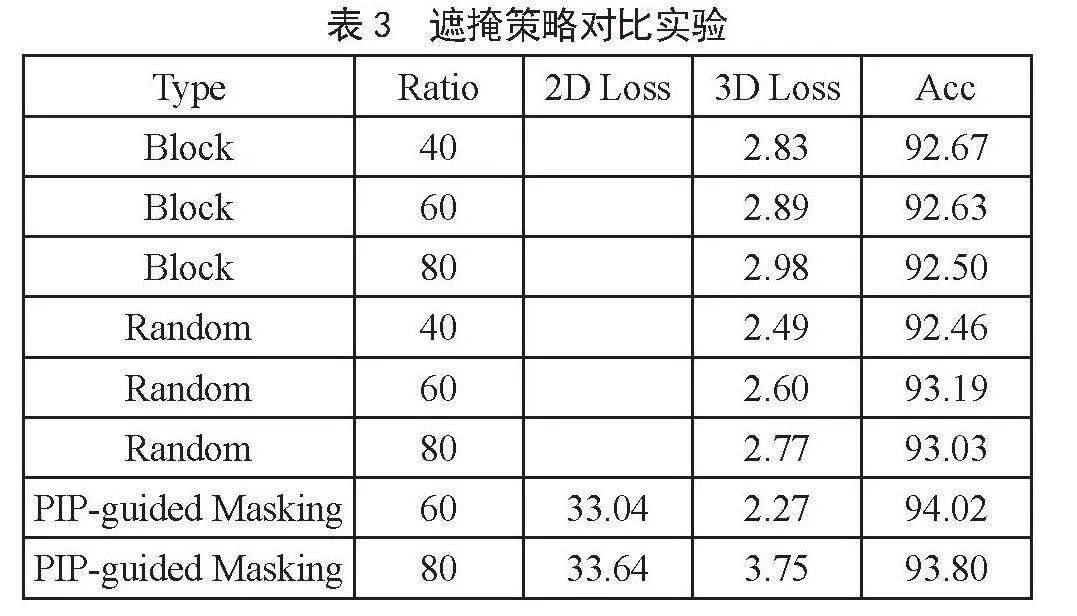
3.3.1 遮掩策略
遵循之前的Point-MAE,在ModelNet40数据集上进行了实验,我们比较了3种类型的遮掩:PIP引导遮掩型、块遮掩型、随机遮掩类型以及不同的遮掩比例。遮掩策略决定了下游任务的难度,影响重建质量和下游任务精度。如表3所示,当遮掩比较高时,块遮掩型和随机遮掩型的性能较差,这意味着使用中等遮掩比(即60%~80%)可以获得良好的性能。而我们的PIP引导遮掩实现了94.2%的精度,这能使编码器能够“看到”重要的空间特征和信号结构。
3.3.2 令牌在解码器和编码器中的影响
我们的PIP-MAE将掩码令牌从编码器的输入转移到轻量级解码器。为了证明这种设计的有效性,我们进行了一个实验,其中掩码令牌是从编码器的输入中处理的。为了公平比较,自编码器的主干网采用与Point-MAE相同的编码器和预测头,但没有解码器,从而在预训练任务上产生完全相同的模型。我们在这个实验中使用PIP引导的遮掩。预训练后,与PIP-MAE(2.60)相比,观察到较小的重建损失(2.51)。在ModelNet40上微调性能,准确率达到92.14%,远低于PIP-MAE(93.19%)。这个结果并不意外。在编码器的输入端,所有标记(包括掩码标记)都必须通过位置嵌入提供位置信息。这会导致位置信息的早期泄漏,因为掩码令牌被处理用于重建坐标空间中的点补丁。位置信息的泄露使得重建任务的挑战性降低,模型无法很好地学习潜在特征,导致微调性能较差。
4 结 论
本文提出了一种低位置泄漏点云-图像-点云MAE多模态自监督学习方案PIP-MAE。PIP-MAE解决了预训练编码过程中位置信息泄漏问题和单一模态问题。该方法在目标分类、小样本学习、零件分割等多种任务中验证了该方法的有效性和高泛化能力。希望PIP-MAE能够启发更多作品在探索三维点云MAE自监督学习解决方案时关注位置泄漏问题。对于后面的工作,保持着低位置泄漏同时,将研究是否可以将其他模态信息(例如文本标签)合并到的PIP-MAE中。
参考文献:
[1] VASWANI A,SHAZEER N,PARMAR N,et al. Attention Is All You Need [C]//NIPS17:Proceedings of the 31st International Conference on Neural Information Processing Systems.Red Hook:Curran Associates Inc,2017:6000-6010.
[2] UY M A,PHAM Q H,HUA B S,et al. Revisiting Point Cloud Classification: A New Benchmark Dataset and Classification Model on Real-World Data [C]//Proceedings of the IEEE/CVF international conference on computer vision.Seoul: IEEE,2019:1588-1597.
[3] XIE S,GU J,GUO D,et al. PointContrast: Unsupervised Pre-training for 3D Point Cloud Understanding [C]//Computer Vision-ECCV 2020, 16th European Conference.Glasgow:Springer International Publishing,2020:574-591.
[4] GUO M H,CAI J X,LIU Z N,et al. PCT: Point Cloud Transformer [J].Computational Visual Media,2021,7:187-199.
[5] HE K M,CHEN X L,XIE S N,et al. Masked Autoencoders Are Scalable Vision Learners [C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition.New Orleans: IEEE,2022:16000-16009.
[6] YU X,TANG L,RAO Y,et al. Point-BERT: Pre-training 3D Point Cloud Transformers with Masked Point Modeling [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE,2022:19313-19322.
[7] PANG Y,WANG W,TAY F E H,et al. Masked Autoencoders for 3D Point Cloud Self-supervised Learning [C]//European conference on computer vision. Cham:Springer Nature Switzerland,2022:604-621.
[8] DOSOVITSKIY A,BEYER L,KOLESNIKOV A,et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale [J/OL].arXiv:2010.11929 [cs.CV].(2020-10-22).https://arxiv.org/abs/2010.11929v1.
[9] WANG Y,SUN Y,LIU Z,et al. Dynamic Graph CNN for Learning on Point Clouds [J].ACM Transactions on Graphics (tog),2019,38(5):1-12.
[10] AFHAM M,DISSANAYAKE I,DISSANAYAKE D,et al. CrossPoint: Self-Supervised Cross-Modal Contrastive Learning for 3D Point Cloud Understanding [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.IEEE,2022:9902-9912.
[11] RADFORD A,KIM J W,HALLACY C,et al. Learning Transferable Visual Models From Natural Language Supervision [C]//International conference on machine learning. PMLR,2021:8748-8763.
[12] ZHANG R,WANG L,QIAO Y,et al. Learning 3D Representations from 2D Pre-trained Models via Image-to-Point Masked Autoencoders [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.IEEE,2023:21769-21780.
[13] HE K,ZHANG X,REN S,et al. Deep Residual Learning for Image Recognition [C]//Proceedings of the IEEE conference on computer vision and pattern recognition.IEEE,2016:770-778.
[14] UY M A,PHAM Q H,HUA B S,et al. Revisiting Point Cloud Classification: A New Benchmark Dataset and Classification Model on Real-World Data [C]//Proceedings of the IEEE/CVF international conference on computer vision.IEEE,2019:1588-1597.
[15] CHANG A X,FUNKHOUSER T,GUIBAS L,et al. ShapeNet: An Information-Rich 3D Model Repository [J/OL].arXiv:1512.03012 [cs.GR].(2015-12-09).https://arxiv.org/abs/1512.03012.
[16] LOSHCHILOV I,HUTTER F. Decoupled Weight Decay Regularization [J/OL].arXiv:1711.05101 [cs.LG].(2019-01-04).https://arxiv.org/abs/1711.05101.
[17] LOSHCHILOV I,HUTTER F. SGDR: Stochastic Gradient Descent with Warm Restarts [J/OL].arXiv:1608.03983 [cs.LG].(2016-08-13).https://arxiv.org/abs/1608.03983.
[18] QI C R,SU H,MO K,et al. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation [C]//Proceedings of the IEEE conference on computer vision and pattern recognition.IEEE,2017:652-660.
[19] HAN K,XIAO A,WU E,et al. Transformer in Transformer [J]. Advances in Neural Information Processing Systems,2021,34:15908-15919.
[20] WU Z,SONG S,KHOSLA A,et al. 3D ShapeNets: A Deep Representation for Volumetric Shapes [C]//Proceedings of the IEEE conference on computer vision and pattern recognition.IEEE,2015:1912-1920.
[21] ZHANG R,GUO Z,GAO P,et al. Point-M2AE: Multi-scale Masked Autoencoders for Hierarchical Point Cloud Pre-training [J].Advances in neural information processing systems,2022,35:27061-27074.
作者简介:陈博(1995—),男,汉族,湖南湘乡人,硕士研究生,研究方向:深度学习、3D点云重建、3D点云分类、模式识别;袁鑫攀(1982—),男,汉族,湖南株洲人,副教授,博士,研究方向:信息检索、自然语言处理、局部敏感哈希。
收稿日期:2024-02-26
基金项目:湖南省自然科学基金项目(2022JJ30231)
DOI:10.19850/j.cnki.2096-4706.2024.08.022
PIP Masked Autoencoders Based on 3D Point Cloud
CHEN Bo, YUAN Xinpan
(Hunan University of Technology, Zhuzhou 412007, China)
Abstract: Existing algorithms for 3D point cloud MAE suffer from issues such as position information leakage and lack of diversity in modes. To address these problems, this paper proposes a PIP-MAE algorithm for point cloud-image-point cloud MAE. The algorithm guides the 3D point cloud pre-training model by enriching 2D image knowledge, randomly masks the input 3D point cloud and its projected 2D image, and then reconstructs the masked information for both modes. The experiments on downstream tasks validate the effectiveness of the PIP-MAE algorithm, and it improves accuracy of these downstream tasks, which can be widely used in various types of downstream tasks.
Keywords: Deep Learning; point cloud reconstruction; point cloud classification; point cloud segmentation