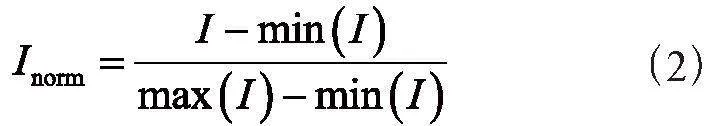


摘 要:针对人脸表情识别中存在的受到光照和姿势的影响导致识别精度不高和深度学习模型参数量巨大的问题,文章提出一种基于注意力机制的卷积神经网络改进模型。通过引入注意力机制模块,使模型选择性地关注目标对象的局部重要信息,降低无关信息的干扰;同时,利用较少神经元数量与大卷积核的神经网络,大幅减少了网络参数,该方法构建了一种层次更浅、参数量更少的轻量卷积神经网络模型。在CK+人脸表情数据集上进行实验,结果表明,文章提出的方法在保证人脸识别精度的情况下,还大大减少了模型参数,其准确率可达到96.37%。
关键词:人脸表情识别;注意力机制;卷积神经网络;深度学习
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2024)08-0102-05
DOI:10.19850/j.cnki.2096-4706.2024.08.023
0 引 言
表情是人类传递情感和表达情绪最明显的特征,能够很容易被机器所捕获,当机器能够理解人类的表情时,就能使人机交互更加智能和拟人。从20世纪起,心理学家们在情绪分类方面就展开了讨论。目前,较为广泛认同的是人们共存在六种基本表情:喜悦、生气、害怕、忧郁、厌恶和震惊。随着AI和传感器技术不断成熟和发展,人脸表情识别已经成为情感计算的重要研究方向[1]。人脸表情识别是利用计算机提取图像特征并对其进行分类的技术。主要分为基于传统地表情识别算法和基于深度学习的表情识别算法。深度学习方法比传统学习方法更容易获取数据特征[2]。面部表情识别系统可分为两大类:静态图像识别、动态视频识别。静态图像的表情识别就是对一张人脸表情图片识别,而动态视频要对序列图像进行识别,需要考虑时间和空间的联系。随着深度学习和计算机性能的发展和提升,许多网络模型被用于表情识别,其识别效率有了显著的提高。
文献[3]在深度卷积神经网络中引入了混合注意力机制,使模型能够提取出更具辨识度的特征表示,随着网络深度的增加注意力模块性能将持续提升。文献[4]提出了一种轻量型的人脸表情识别模型,在保证性能的同时参数量更少,实验结果证明只要设计合理的感受野,人脸表情特征就可以通过轻量型网络进行学习。
目前识别准确率较高的人脸表情识别模型参数量巨大,不便于移植到硬件设备上,并且训练代价较大。在真实环境中受到光照和人脸角度等的影响,为识别带来了挑战。本文提出了一种基于注意力机制和浅层卷积神经网络的改进方法。改进主要包括以下两个方面:1)在网络中引入注意力机制模块使模型关注目标对象的局部细节信息,降低无关信息干扰。2)使用大卷积核的神经网络增大感受野,减少全连接层神经元数量,在保障识别准确率的基础上大幅减少网络参数量。
本文首先介绍基于注意力机制的人脸表情识别改进方法中的注意力机制,接着介绍基本的算法结构与详细的方法步骤,最后详述本文方法的实验过程及其分析。本文方法使用公开数据集CK+数据集进行模型训练以及实验测试,最后对本文方法做简要评估总结。
1 注意力机制概述
注意力机制可以理解为:计算机视觉系统模型人类视觉中选择性关注重点区域的特性。在计算能力有限的情况下,为了合理利用视觉信息处理资源,需要集中关注视觉区域的特定部分,将计算资源分配给更重要的任务。在计算机视觉任务中,如图像分类、目标检测和图像生成等,注意力机制被广泛应用。图像中的注意力机制可以分为四个部分:1)第一个部分是序列决策下的注意力RAM [5],特点是使用循环神经网络产生注意力。2)第二部分是空间变换网络[6](Spatial Transformer Networks, STN),其特点是明确预测和计算所有数据中的重要区域,相关的工作有DCNs [7,8]。3)第三部分是以压缩和激励网络[9](Squeeze-and-Excitation Networks, SENet),该部分以通道注意力为核心,通过权重调整聚焦某些高信息量通道,相关的工作有CBAM [10]等。4)第四个部分既为基于自注意力机制相关的注意力通道与注意力模块,相关的工作有Non-Local [11]、ViT [12]等。注意力机制可以与卷积神经网络结合使用,以增强模型的性能。在卷积神经网络中,注意力机制可以应用于不同的层级,从低级特征到高级特征,以提取更具有区分性的特征。例如,在卷积层后添加注意力机制,以帮助模型聚焦于图像中的重要区域。注意力机制的引入可以提高模型的感知能力和泛化能力,使模型更加灵活和准确。它可以帮助模型更好地理解图像中的上下文信息,并提取与任务相关的关键特征。
2 本文识别方法介绍
基于注意力机制的卷积神经网络人脸表情识别方法首先识别视频流中的人脸,将抽帧、提取为数据集,获取基础图像后,将人脸图像归一化为48×48像素。获取收据后,将图像直方图归一化,以减少光照和其他变量的影响。然后使用卷积方法配合注意力通道对图像的各个层的边缘进行卷积计算。为了保持纹理图像的边缘结构数据,将提取的边缘信息添加到每个特征图像中。通过利用训练和测试数据来减小得到的隐式特征的大小,可以加快模型训练和测试速度。
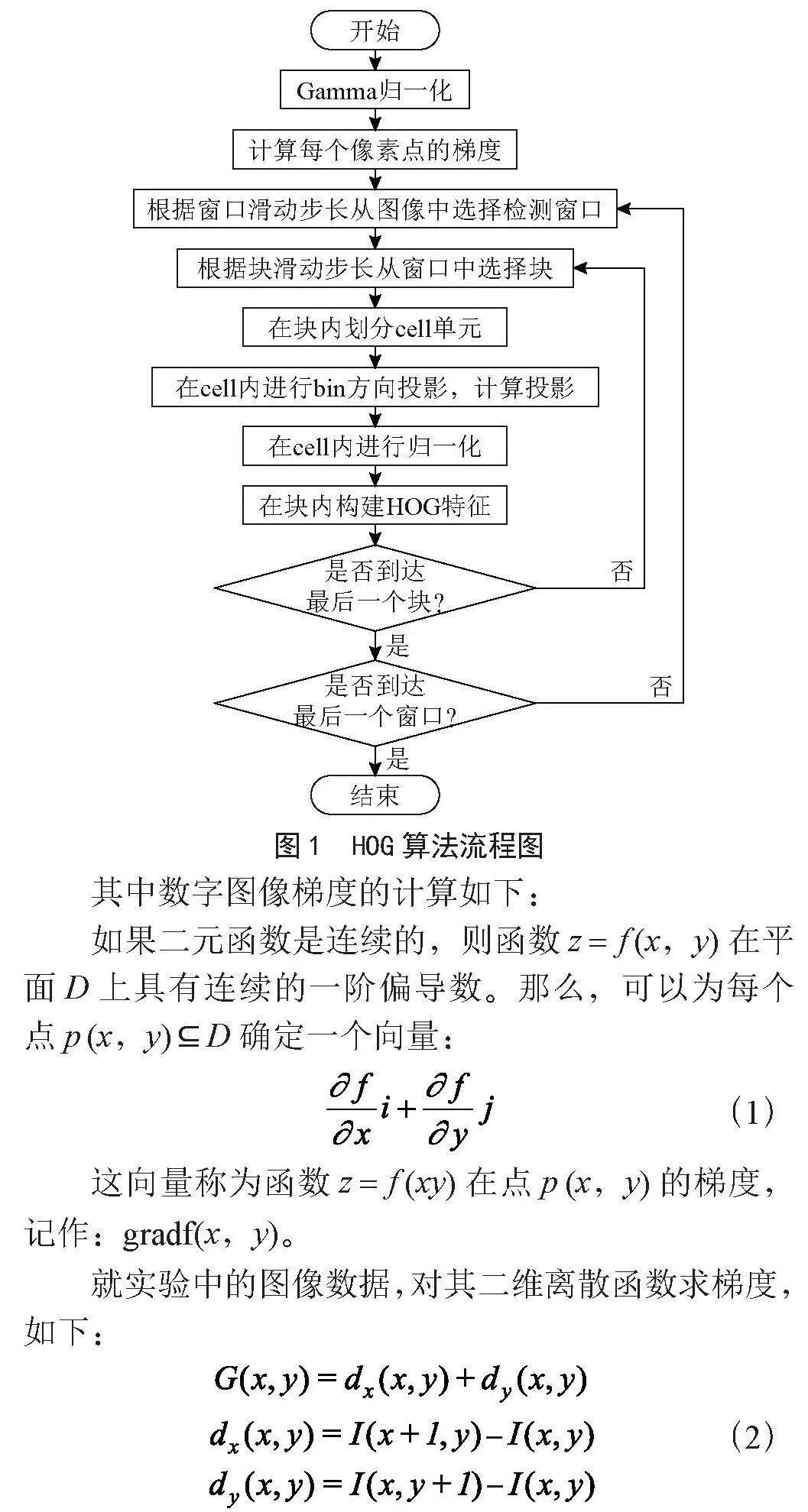
在基于数字图像的计算分析与处理中,研究者们提出了众多算法来解决空间特征提取的问题,并配合图像自身的数学特征,例如梯度信息来识别图像。方向梯度直方图(Histogram of Oriented Gradient, HOG),HOG属于一种常见的数据分布二维表现形式,类似于柱状图,其列的高度各不相同,每一列代表一组数据在一定范围内的数值。数字图像的边缘的梯度或方向密度分布可以描述局部目标区域的特征,HOG就是在此基础上对梯度信息进行统计,生成最终的特征描述。具体流程图如图1所示。
其中数字图像梯度的计算如下:
如果二元函数是连续的,则函数z = f (x,y)在平面D上具有连续的一阶偏导数。那么,可以为每个点p (x,y) ⊆ D确定一个向量:
(1)
这向量称为函数z = f (xy)在点p (x,y)的梯度,记作:gradf(x,y)。
就实验中的图像数据,对其二维离散函数求梯度,如下:
(2)
其中,I (x,y)是图像在点(x,y)处的像素值。
HOG算法的过程主要如下:
1)首先读取彩色图像并将其转化为灰度图像,对灰度图像矩阵归一化,目的是为了减少光照和背景等因素的影响。
2)选择合适的梯度算子来计算梯度图,主要分为x和y方向上的梯度,计算出合梯度的幅值和方向。
3)划分检测窗口成大小相同的单位图像单元,组合相邻的单位图像单元成更大的相互重叠的块,便于充分利用重叠的边缘信息。
4)统计整个块的直方图;再对每个块内的梯度直方图进行归一化处理,综合所有块的信息,对HOG特征描述符可视化。
计算机显示的彩色图像其实是由三原色红、绿、蓝按照不同的比例叠加构成的。一张彩色图像每个通道中的每个像素值都是在0~255范围内的数字,计算机对图像进行计算时,就需要对三个通道都进行操作,颜色信息对于人脸关键点的检测并无太大贡献,因此利用Gamma归一化处理将彩色图像变成灰度图像可以有效提升计算效率。
卷积神经网络中,感受野的大小往往取决于卷积核的大小。大卷积核能使神经元拥有更大的感受野,感受更大范围的特征信息。目前应用范围较广的表情识别神经网络都是使用小感受野的卷积核,再堆叠多个神经层实现,导致神经网络较为复杂,参数量较大,若要进行嵌入式设备的移植较为不便。但减小神经网络模型的深度会导致模型的感知能力降低,从而导致准确率降低。
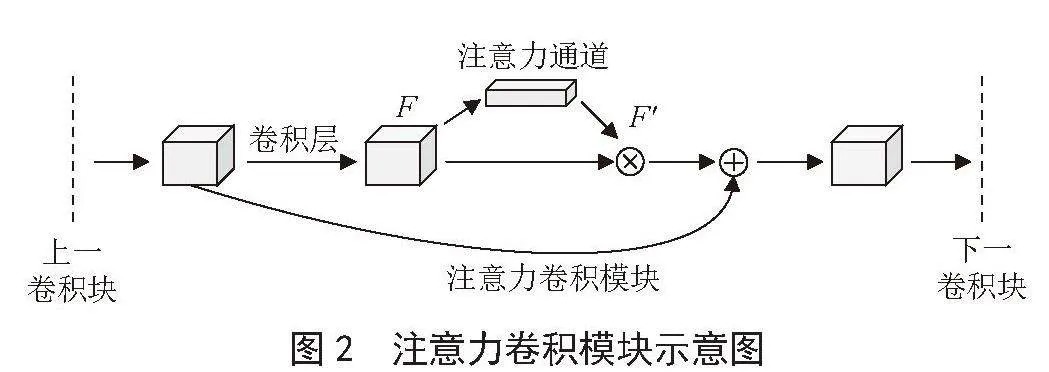
针对以上问题,在目前的卷积网络模型基础上引入注意力机制模块和增大卷积核感受野并缩小网络规模不仅可以增强模型的感知能力和泛化能力,还能有效减少模型参数量。将一个卷积层和一个注意力块合并表示成一个注意力卷积块,如图2所示。将注意力机制层设置在每个卷积层后,再将通道注意力提取到的特征与卷积提取到的特征进行融合,帮助模型更好地理解图像中的上下文信息,因此只需堆叠2到3层注意力卷积块就可以实现人脸表情的识别。
方法核心结构在于Dropout层接收来自全连接层的输出,然后是注意力卷积层和下面的全连接层。这种自动学习大型数据集的潜在规则的方法,通过给每个收集到的特征提供更详细的数据特征,极大地改善了分类结果。在将二维输入图像从计算机的初始检测像素逐层转换为人类大脑已知的事物和物体的边缘、部分和轮廓后,神经网络模型对输入图像进行计算识别从而提供分类判定。卷积、池化和连接层构成了本文方法的三个关键部分。初始化层中有许多神经元,由特征映射模块或二维平面化模块组成。
卷积C和最大池化S必须在CNN的整个特征提取过程中进行切换。CNN有三个基本部分组成:局部视点、权重共享和下采样。由于这些特性,该模型能够产生特定的平移、旋转和畸变不变性
其中的激活函数使用PReLU函数,PReLU就是带参数的ReLU,其定义为:
(3)
实验表明,使用注意力卷积模块堆叠成神经网络模型对于特征学习的能力更强,在参数量较小的情况下也能达到较高的识别准确度。
3 实验与分析
3.1 参数设置
本文实验输出的图片尺寸为48×48,初始学习率为0.01,Batch Size为64,采用余弦退火策略更新学习率,总共训练100个epoch,就可以达到较高的准确率。
3.2 数据集处理
本文采用人脸表情识别公开数据集CK+进行实验。CK+数据集包含8种基本面部表情(愤怒、厌恶、恐惧、快乐、悲伤、惊讶、蔑视、自然笑)以及16种复合表情,在此文章中将人脸表情分成生气(angry)、厌恶(disgust)、恐惧(fear)、高兴(happy)、悲伤(sad)、惊讶(surprise)、蔑视(contempt)7类。本文测试8种基本面部表情。其中一共包含800个样本。实验过程中,以7:1:2的比例划分训练集、验证集和测试集。
在训练前首先进行数据预处理,使用Opencv的人脸检测器检测出人脸位置并进行裁剪,得到只包含人面部的表情图像,降低其余背景信息的干扰,再使用Keras的ImageDataGenerator实现批量数据增强,从而得到更丰富的训练数据。
3.3 对比实验
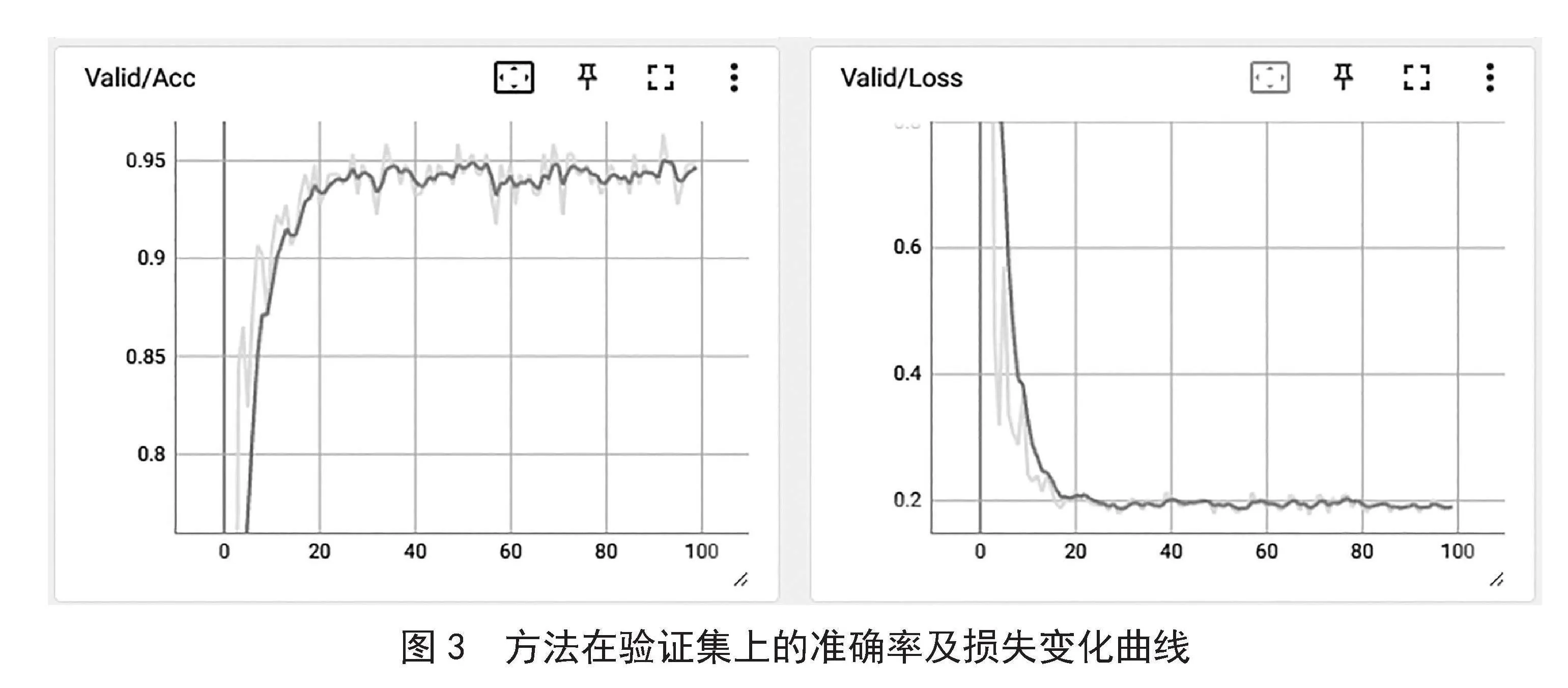
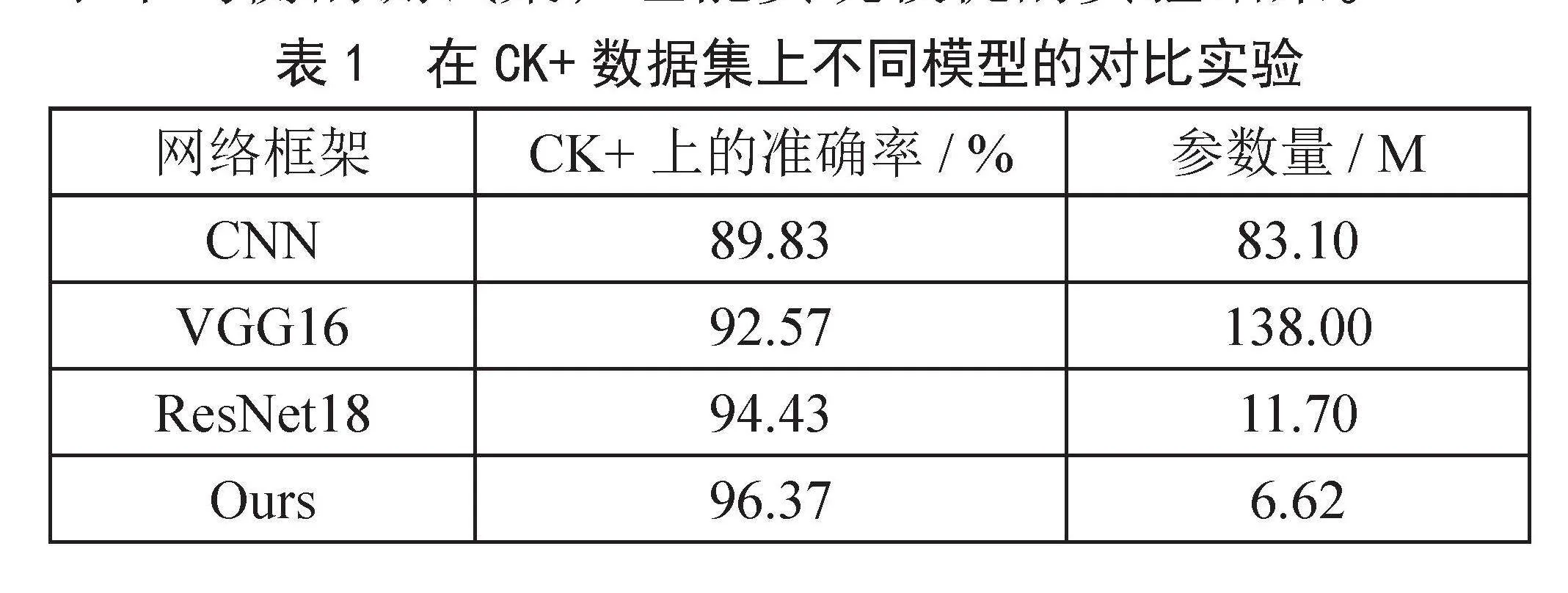
为了综合评价模型的效果,本文选取了模型参数量Params(M)、测试集准确率Accuracy(%)作为评价指标。同时将本文算法与其他经典的表情识别算法进行对比,本文方法加入注意力机制,并采用大卷积核的神经网络使得参数量大大降低。实验结果表明本文提出的模型在准确率和参数量上均表现较好,如表1所示,从准确率角度,本文为96.37%,较前三者中最优良的94.43%高出1.94%;从参数量的角度,本文提出的方法为6.62M,较之前三者中最小的11.7M降低了5.08M。综上所述,本文提出的方法在准确率与模型参数上都保持了优良的性能。本文方法在验证集上准确率及损失变化曲线如图3所示。
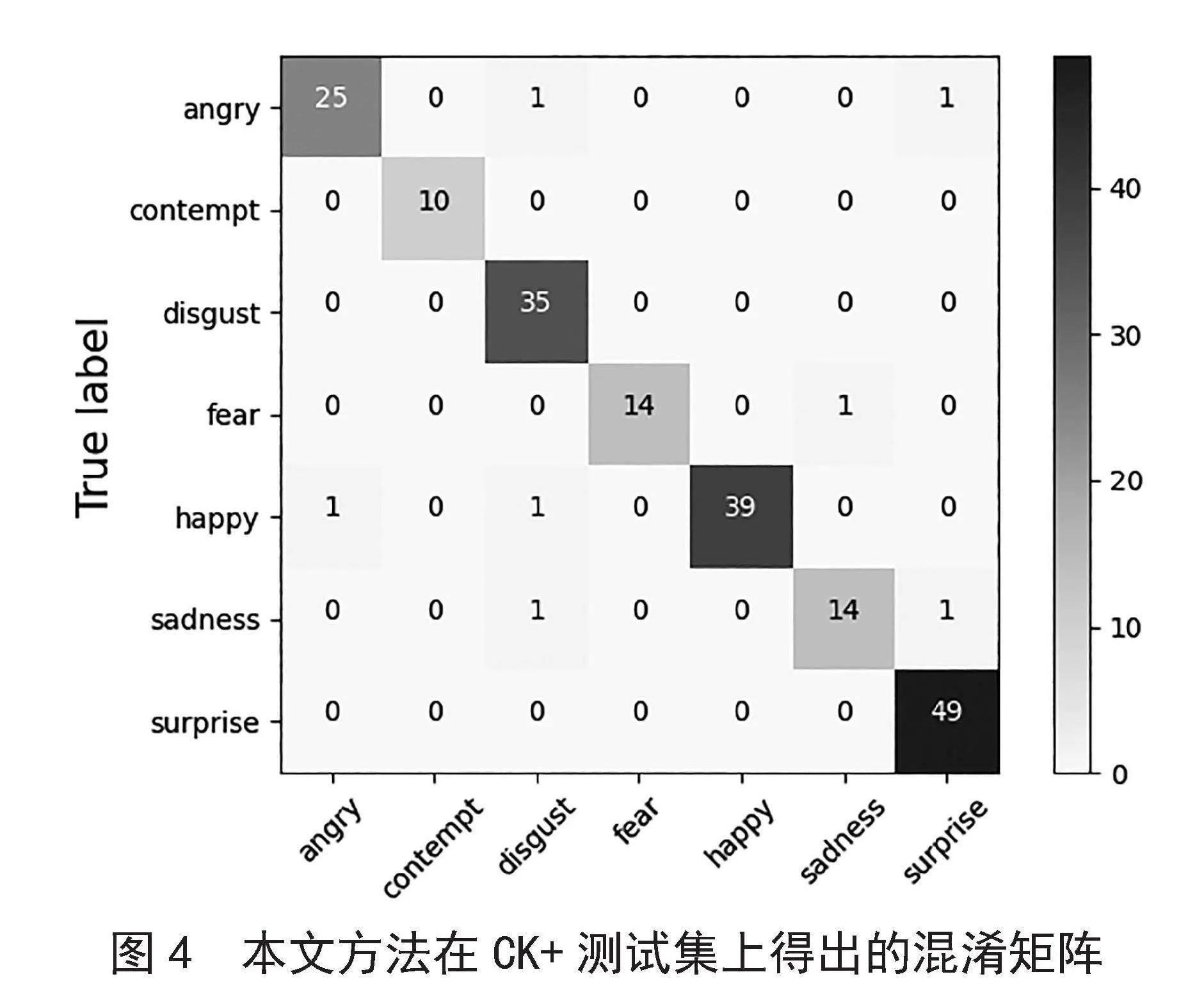
图4为本文方法在CK+数据集上的混淆矩阵。模型测试中,测试集的不均衡往往会导致识别准确率的不稳定,导致模型的识别效果下降,本文模型通过注意力机制,实现了轻量化的表情识别框架,同时对于不均衡的测试集,也能实现较优的实验结果。
图5为本文方法在测试集上的表情识别结果。随机抽取8个表情图片进行测试,图片上方显示表情的真实类别,括号内为模型预测的表情类别。可以看出该轮测试较为准确地对表情进行了识别,预测结果与真实表情标签一致。
4 结 论
针对多角度复杂背景下的面部表情识别度低、深度学习运算损耗大等问题,本文提出了一种基于注意力机制的改进算法。通过引入注意力机制模块来应对多角度复杂背景下的其他干扰,提高对于人脸表情识别中的局部特征关注度,提出一种更加轻量化的深度学习框架,利用更少的神经元,结合更简化的网络层次在提高检测效果的同时降低了计算冗余。本文所提改进算法在降低参数量的同时准确率可达到94.81%,同时对比于其他网络结构,本文模型在同等体量下检测精度更高,在同等精度下体量更小、检测速度更快,对各种场景变化具有更好的鲁棒性。
参考文献:
[1] 潘家辉,何志鹏,李自娜,等.多模态情绪识别研究综述 [J].智能系统学报,2020,15(4):633-645.
[2] FURKAN A,EKIN E,ZEYNEP G. Traditional Machine Learning Algorithms for Breast Cancer Image Classification with Optimized Deep Features [J].Biomedical Signal Processing and Control,2023,81:104534.
[3] WANG F,JIANG M Q,QIAN C,et al. Residual Attention Network for Image Classification [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Honolulu:IEEE,2017:6450-6458.
[4] KUO C M,LAI S H,SARKIS M. A Compact Deep Learning Model for Robust Facial Expression Recognition [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops(CVPRW).Salt Lake City:IEEE,2018:2202-22028.
[5] MNIH V,HEESS N,GRAVES A. Recurrent Models of Visual Attention [J/OL].[2023-08-09].http://www.arxiv.org/pdf/1406.6247.pdf.
[6] JADERBERG M,SIMONYAN K,ZISSERMAN A,et al. Spatial transformer networks [J/OL].arXiv:1506.02025 [cs.CV].[2023-08-06].https://arxiv.org/abs/1506.02025v1.
[7] DAI J F,QI H Z,XIONG Y W,et al. Deformable convolutional networks [C]//2017 IEEE International Conference on Computer Vision (ICCV).Venice:IEEE,2017,764-773.
[8] ZHU X Z,HU H,LIN S,et al. Deformable Convnets V2: More Deformable, Better Results [C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Long Beach:IEEE,2019:9300-9308.
[9] HU J,SHEN L,ALBANIE S,et al. Squeeze-and-Excitation Networks [J].EEE Transactions on Pattern Analysis and Machine Intelligence,2020,42(8):2011-2023.
[10] WOO S,PARK J,LEE J Y,et al. CBAM: convolutional block attention module [J/OL].arXiv:1807.06521 [cs.CV].[2023-08-06].https://arxiv.org/abs/1807.06521.
[11] WANG X L,GIRSHICK R,GUPTA A,et al. Non-local Neural Networks [J/OL].arXiv:1711.07971 [cs.CV].[2023-08-06].https://arxiv.org/abs/1711.07971v3.
[12] DOSOVITSKIY A,BEYER L,KOLESNIKOV A,et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale [J/OL].arXiv:2010.11929 [cs.CV].[2023-08-06].https://arxiv.org/abs/2010.11929v1.
作者简介:徐梦阳(2002—),女,汉族,陕西西安人,本科在读,研究方向:人脸表情识别。
收稿日期:2023-08-29
An Improved Method for Facial Expression Recognition Based on Attention Mechanism
XU Mengyang
(Xian Technological University, Xian 710021, China)
Abstract: Targeting the problems of poor recognition accuracy and a large number of Deep Learning model parameters due to light and posture influence in facial expression recognition, this paper proposes an improved Convolutional Neural Network model based on Attention Mechanism. Through the introduction of the Attention Mechanism module, the model selectively focuses on the locally important information of the target object and reduces the interference of irrelevant information, while using a neural network with fewer neurons and a large convolutional kernel, the parameters of the network are significantly decreased, and the method builds a lightweight Convolutional Neural Network model with a shallower hierarchy and fewer parameters. Experiments are conducted on the CK+facial expression dataset, and results show that the proposed method significantly reduces model parameters while ensuring facial recognition accuracy, with an accuracy rate of 96.37%.
Keywords: facial expression recognition; Attention Mechanism; Convolutional Neural Network; Deep Learning