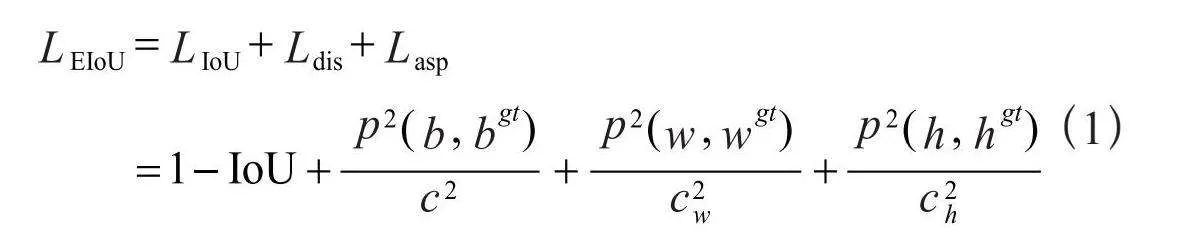


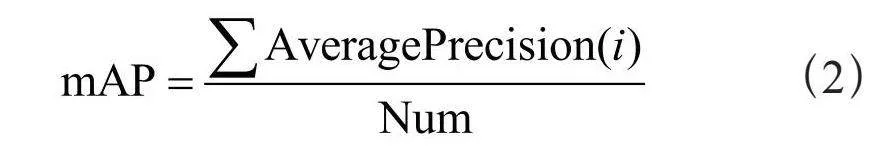
摘" 要:为解决无人机捕获场景中小目标检测存在的检测精度不高和漏检问题,提出基于YOLOv5改进的小目标检测算法DE_YOLOv5。DE_YOLOv5的数据集采用VisDrone2019。实验包括两个方面,一是引入解耦合头机制,通过独立的中心点预测减小感受野限制对小目标定位的影响,初始模型的mAP@0.5为0.334,加入解耦合头之后mAP@0.5值为0.344。二是将损失函数更换为Focal-EIoU,更换损失函数之后mAP@0.5值为0.351。实验结果表明,DE_YOLOv5可有效提升小目标的检测精度。
关键词:小目标;解耦合头;图像识别
中图分类号:TP391.4;TP183 文献标识码:A 文章编号:2096-4706(2024)10-0013-04
Research on Improved Small Target Detection Algorithm Based on YOLOv5
ZHU Menglin, YIN Quanhe, YUAN Suhui
(School of Information Engineering, North China University of Water Resources and Electric Power, Zhengzhou" 450046, China)
Abstract: To solve the problems of low accuracy and missed detection of small targets in scenarios by UAV, an improved small target detection algorithm DE_YOLOv5 based on YOLOv5 is proposed. The dataset of DE_YOLOv5 adopts VisDrone2019. The experiment includes two aspects. One is to introduce a decoupling joint mechanism, which reduces the impact of receptive field limitations on small target localization through independent center point prediction. mAP@0.5 of the initial model is 0.334, mAP@0.5 value is 0.344 after adding decoupling joint. The second is to replace the loss function with Focal-EIoU, and mAP@0.5 value is 0.351 after replacing the loss function. The experimental results show that DE_YOLOv5 can effectively improve the detection accuracy of small targets.
Keywords: small goal; decoupling joint; image recognition
0" 引" 言
随着无人机技术的飞速发展,越来越多的应用领域开始利用无人机进行各种任务和监测工作[1]。其中,无人机拍摄的图像和视频数据中往往包含大量的小目标,例如建筑物细节、农田作物、野生动植物等。准确地检测和定位这些小目标对于实现自动化分析、智能决策以及提供即时的反馈至关重要[2]。近年来,深度学习算法在目标检测领域取得了显著的突破[3]。特别是YOLO(You Only Look Once)系列算法以其快速且准确的特点,成为目标检测领域的热门方法。最新的YOLOv5算法进一步提升了小目标检测的性能和效率。然而,在无人机拍摄的小目标检测任务中,YOLOv5算法仍面临一些挑战和不足。首先,由于小目标的尺寸较小,其特征在图像中往往非常模糊和难以区分,导致检测精度有待提高[4]。其次,由于感受野限制,模型可能难以准确地定位小目标的位置,尤其是在复杂场景或目标遮挡的情况下[5]。此外,数据集中小目标数量较少,存在明显的数据不平衡问题[6]。为了解决上述问题并进一步提升小目标检测的性能,本论文提出了一种基于YOLOv5的改进算法DE_YOLOv5,进一步增加小目标检测的精度:
1)在原有的经典算法中添加解耦头,通过引入解耦头机制,将检测任务分解为两个子任务,一个负责预测目标的中心点坐标,另一个负责预测目标的宽度、高度和类别等信息,通过解耦宽度、高度和类别预测,可以更好地应对密集目标的情况,避免目标之间的干扰。
2)改进EIoU损失函数。EIoU Loss相对于传统的IoU损失函数在目标检测任务中具备以下优势:更专注于预测框与真实框重叠低的样本,从而实现提高回归精度的效果。
1" YOLOv5目标检测算法
YOLOv5算法[7]共有4种网络结构,分别是YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x,这4种网络结构在宽度和深度上不同,原理上基本一样,本实验使用YOLOv5s网络结构。其模型结构主要包括输入端、Backbone、Neck、Head四个部分。
1.1" 输入端
输入端采用了Mosaic数据增强和自适应锚框计算,Mosaic图像增强可以增加训练集的多样性和难度,提高目标检测模型的鲁棒性和泛化能力,同时,还可以降低过拟合风险。自适应锚框使用的是一种名为ATSS(Adaptive Training Sample Selection)的锚框,在训练过程中,根据样本与锚框的匹配度(即交并比IoU),自适应地选择正负样本。
1.2" Backbone层
Backbone层主要由Focus结构以及CSP结构组成。Focus结构是一种用于特征提取的卷积神经网络层,用于将输入特征图中的信息进行压缩和组合,从而提取出更高层次的特征表示。它被用作网络中的第一个卷积层,用于对输入特征图进行下采样,以减少计算量和参数量。具体来说,Focus结构可以将输入特征图划分成4个子图,并将这4个子图进行通道拼接,从而得到一个更小的特征图。CSP结构的核心思想是将输入特征图分成两部分,一部分经过一个小的卷积网络(称为子网络)进行处理,另一部分则直接进行下一层的处理。然后将两部分特征图拼接起来,作为下一层的输入。CSP结构在YOLOv5中被广泛应用,包括骨干网络中的多个阶段以及头部网络(head)中的一些模块。它可以显著地减少网络的参数和计算量,同时提高特征提取的效率,从而加快模型的训练和推理速度。
1.3" Neck网络
Neck网络是指在骨干网络的基础上加入的中间特征提取网络,主要用于增强模型的特征表达能力和感受野,进一步提升模型的检测性能。YOLOv5中采用了两种不同的Neck网络结构:SPP和PAN。SPP结构可以增强模型的感知能力和尺度不变性,而PAN结构可以增强多尺度特征的融合能力。
1.4" 输出端
输出层一般包括3个不同尺度的特征图,每个特征图对应不同尺度的预测框。具体来说,YOLOv5在输出层通过使用Anchor Box来预测目标的边界框位置和大小,同时对每个Anchor Box对应的预测结果使用Softmax函数来计算类别概率。
2" 改进的YOLOv5算法
2.1" 引入解耦合头机制
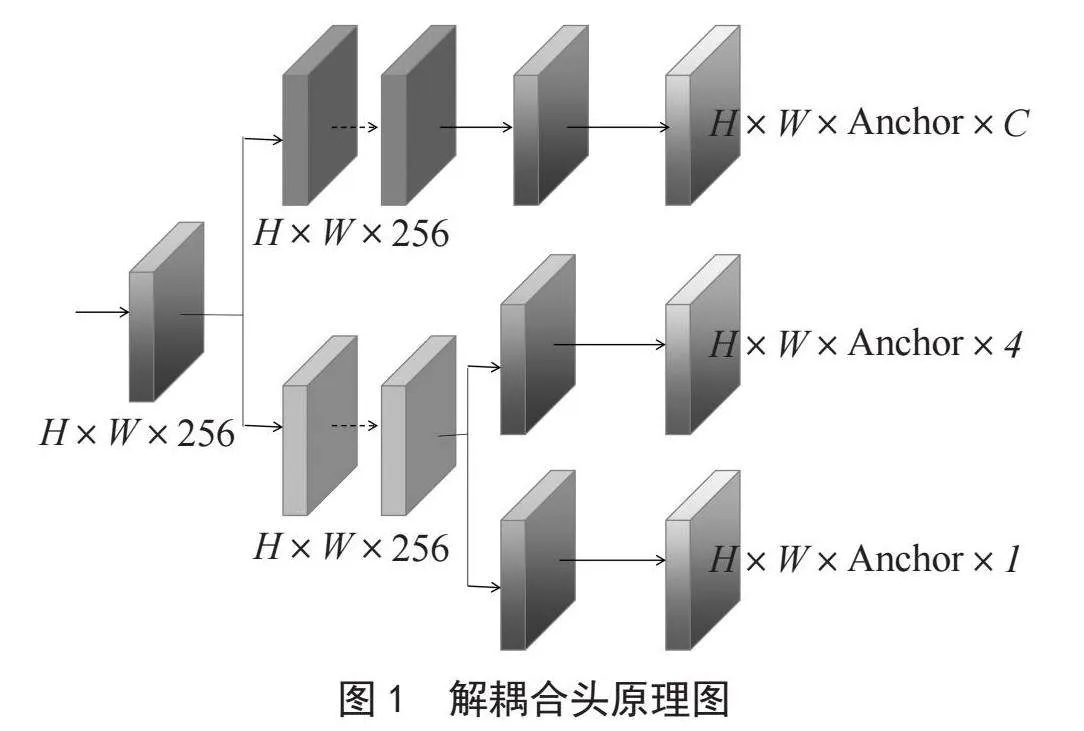
传统的Anchor-Based方法中,由于各个尺度上使用的Anchor数量和大小不同,导致模型参数非常大,训练难度高,速度缓慢。解决这类问题的一种方法就是使用解耦合头[8]。其原理是将区域建议网络(RPN)和分类器分开,并在两个任务之间共享特征,从而能够训练更快、参数更少的模型。具体来说,解耦合头将Anchor计算和分类器计算分开,让主干网络直接输出较粗略的BBOX的坐标,然后再用分类器进行分类,这样可以减轻Anchor数量带来的负担,同时也能将特征向量的维数降低,从而减少了模型的训练和运行时间。图1是解耦合头的原理图。
2.2" 改进的损失函数
原有模型的CIoU损失,在DIoU损失的基础上添加了衡量预测框和真实框纵横比V,在一定程度上可以加快预测框的回归速度,但是存在的问题是预测框回归过程中,一旦预测框和真实框的宽高纵横比呈现线性比例时,预测框W和H就不能同时增加或者减少,就不能继续进行回归优化了。EIoU是在CIoU的惩罚项基础上将预测框和真实框的纵横比的影响因子拆开[9],分别计算预测框和真实框的长和宽,来解决CIoU存在的问题。EIoU回归损失函数如式(1)所示:
3" 实验与分析
3.1" 数据集的选取
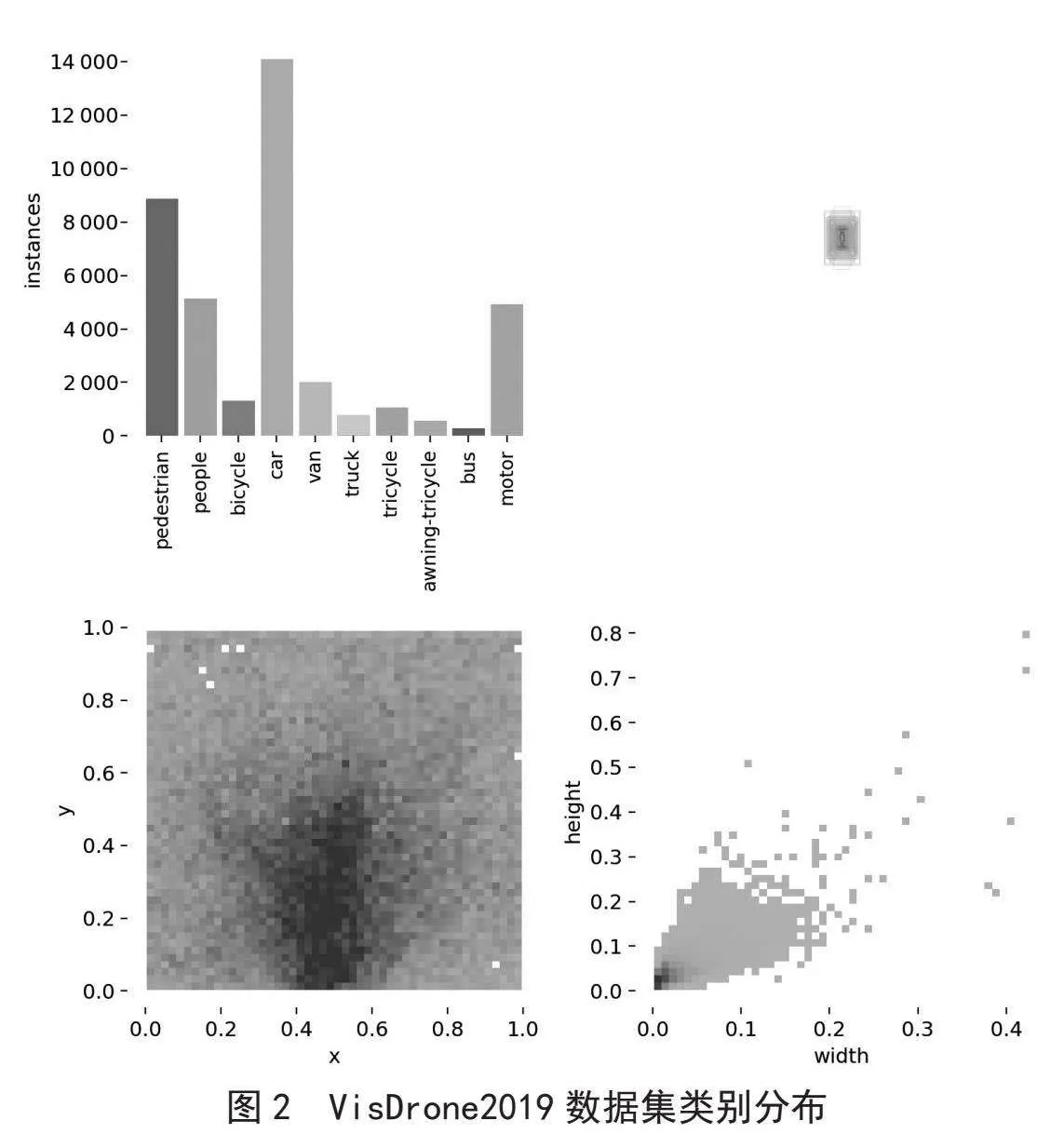
VisDrone2019数据集由天津大学机器学习和数据挖掘实验室AISKYEYE团队收集。图片由各种无人机摄像头捕获,覆盖范围广泛,包括位置(来自中国相隔数千千米的14个不同城市)、环境(城市和农村)、物体(行人、车辆、自行车、等)和密度(稀疏和拥挤的场景)。数据集包括不同的场景、不同的天气和光照条件下使用不同的无人机平台(即不同型号的无人机)收集,共包含8 629张静态图像(6 471张用于训练,548张用于验证,1 610张用于测试),包括行人、人群、自行车等10个类,类别分布如图2所示。
3.2" 算法在数据集上的性能对比实验
本实验采用平均精度均值mAP(Mean of Average Precision)作为评价指标,mAP即阈值大于0.5的均值平均精度。mAP指标综合了不同类别的精准率(Precision)和召回率(Recall),是一个更加全面的评价指标。
3.2.1" 评价性能指标
1)平均精度均值(mAP):mAP值越高,表明该目标检测模型在给定的数据集上的检测效果越好。mAP计算式如式(2)所示,其中i代表类别总数。
2)精准率(P):精确率[10]又称查准率。该指标表示在所有预测为正例的测试框(TP+FP)中,预测为正例且正确的测试框(TP)的占比。计算式为:
3)召回率(R):召回率[3]又称或查全率(有时也被称为灵敏度)。该指标表示在所有的正例(TP+FN)中,模型预测为正例且正确的目标(TP)的占比。计算式为:
3.2.2" 实验环境
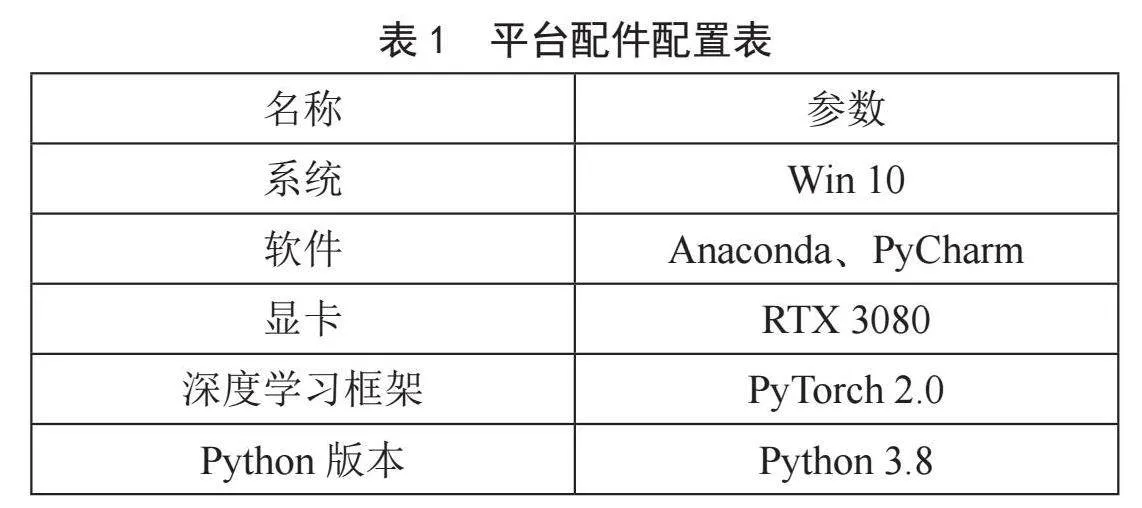
实验所使用的预训练权重是由COCO数据集上进行训练得到,训练轮数为100个Epoch。采用Win 10系统,显卡RTX 3080,软件配置Anaconda、PyCharm,深度学习框架PyTorch 2.0,Python 3.8。平台配件配置见表1。
3.2.3" 实验结果对比分析
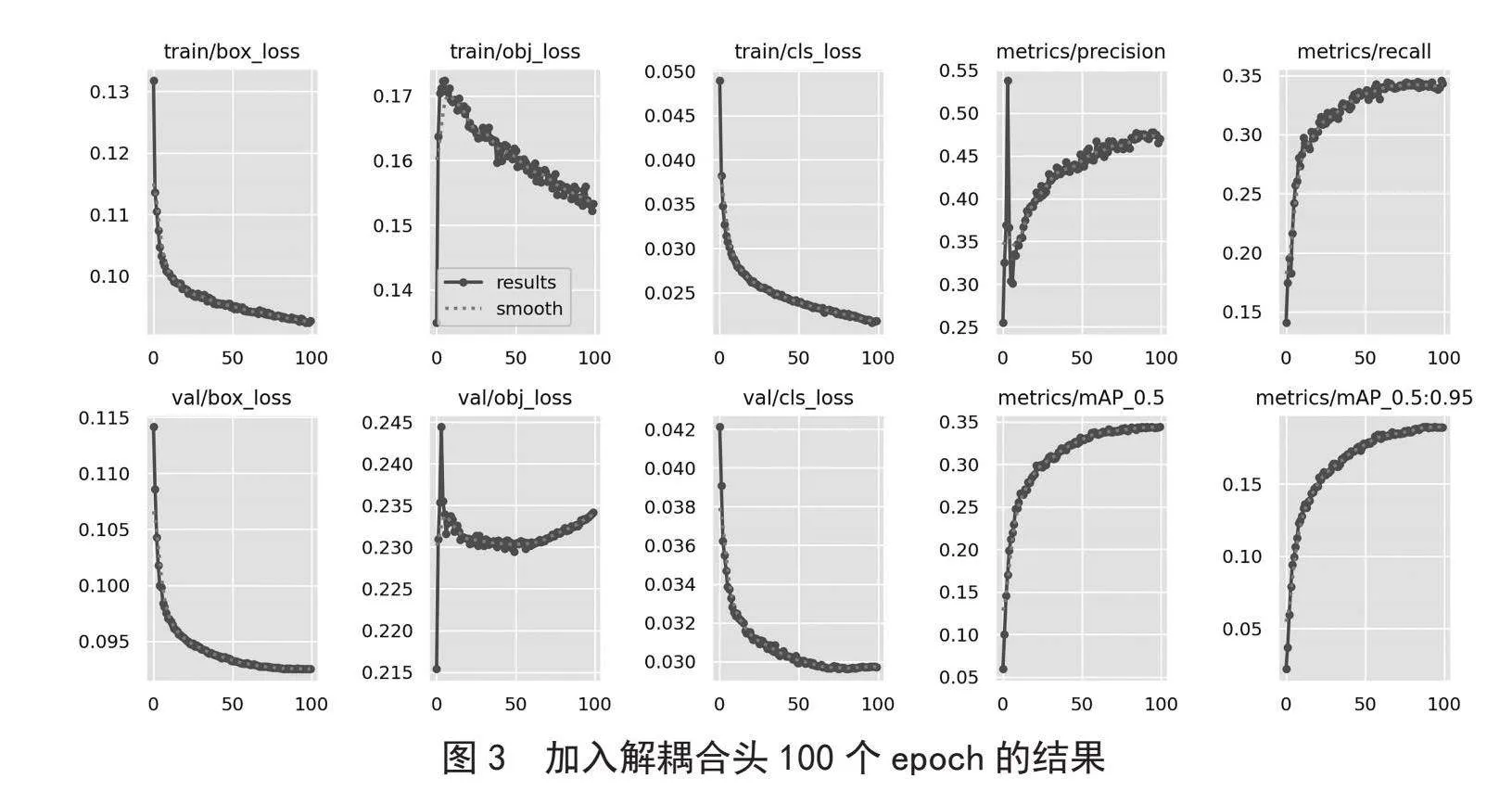
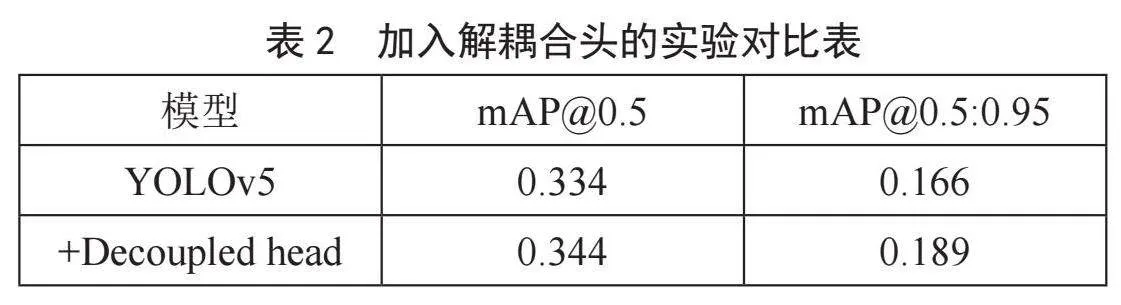
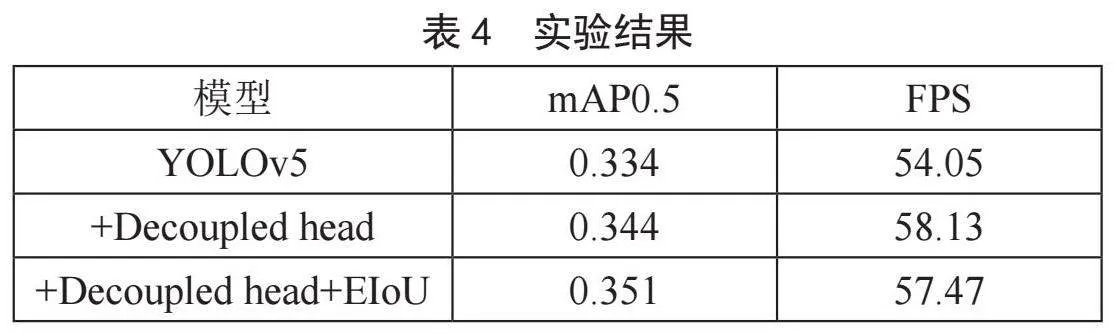
1)模型加入解耦合头将区域建议网络(RPN)和分类器分开,在两个任务之间共享特征,是训练更快、参数更少的模型。然后,主干网络对图像进行特征提取。这产生了一组特征映射,每个映射对应于不同的比例。这些特征图将作为解耦合头的输入,特征映射将进入解耦合头中,将特征映射从RPN网络中分离出来,然后用更少的Anchor进行定位。最后对模型的输出进行非极大值抑制(NMS)处理,以消除相邻边界框的重复。原有模型的mAP@0.5在100个Epoch上的精度为0.334,引入解耦合头之后的mAP@0.5上升到了0.344,由此可见,加入解耦合头机制可有效提高模型精度。加入解耦合头的对比结果如表2所示,实验结果如图3所示。
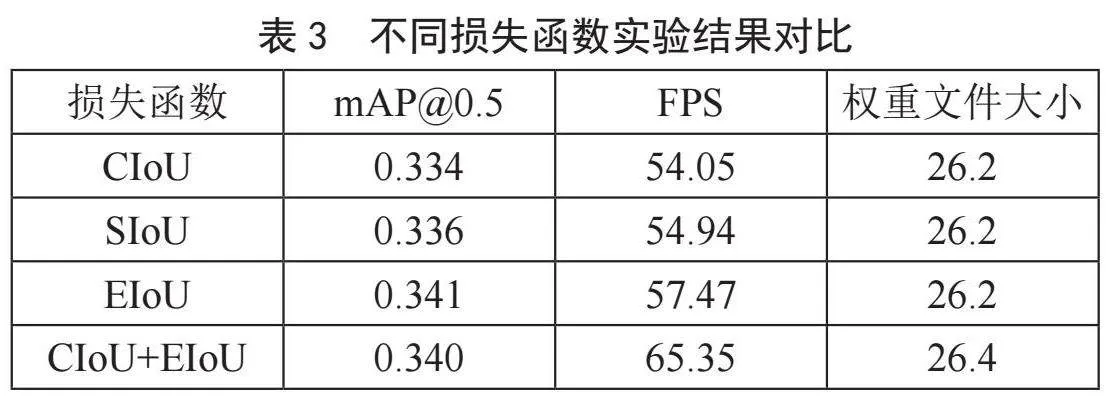
2)为了验证DE_YOLOv5上EIoU的有效性,本实验对不同的损失函数进行对比,最终在100个Epoch的实验结果中选择了EIoU为DE_YOLOv5的损失函数。不同损失函数的结果对比如表3。
3.3" 实验结果
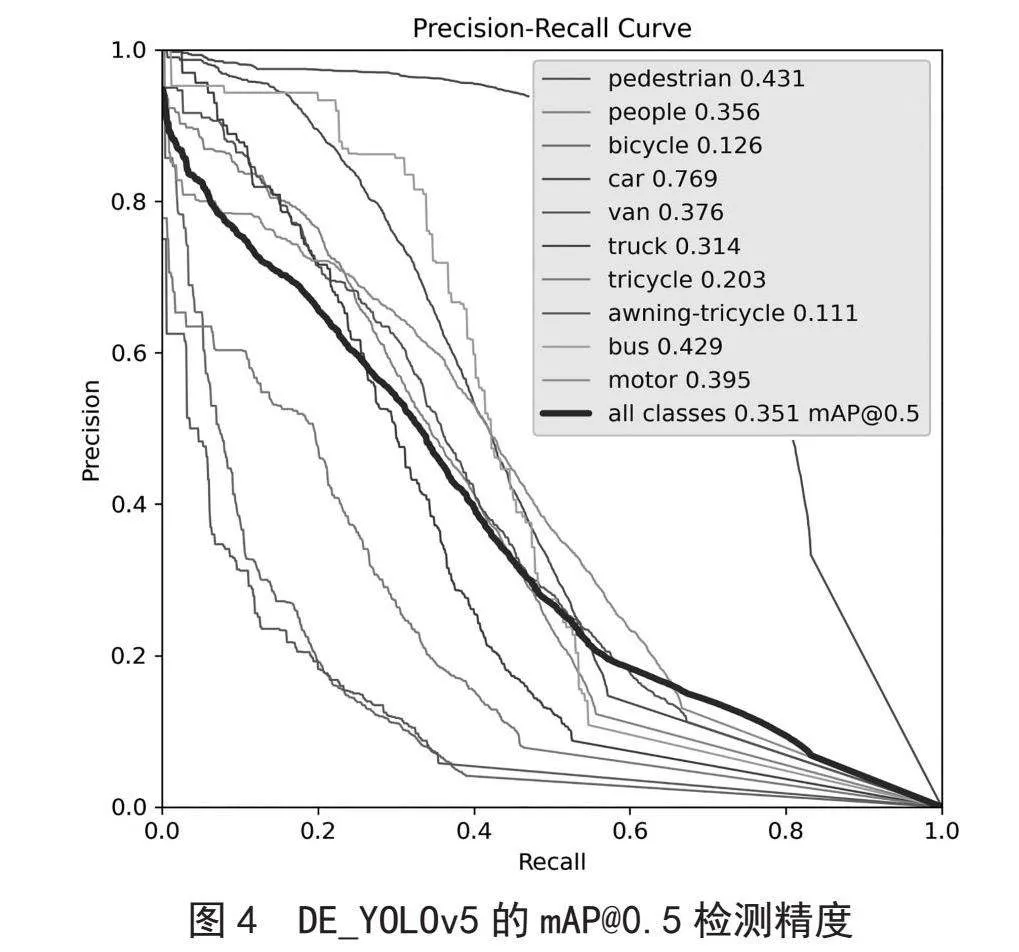
为了证明DE_YOLOv5对于模型检测能力的提升,将对不同模块对模型检测的效果进行评估。表4表明DE_YOLOv5有效提升了数据集的检测精度,DE_YOLOv5的mAP@0.5检测精度如图4所示。
4" 结" 论
传统的YOLO系列模型的检测头在处理小目标时受到很多因素的影响,导致对这些目标的检测效果较差。初始模型在Visdrone2019数据集跑100轮的mAP@0.5为0.334。DE_YOLOv5算法首先加入解耦合头机制,检测mAP@0.5值为0.344,其次原来基于IoU的损失函数模型收敛慢,忽略了正负样本不平衡的问题,将损失函数更换为Focal-EIoU,更换损失含税之后mAP@0.5为0.351。实验结果表明,DE_YOLOv5算法可以有效地提高小目标的检测精度。
参考文献:
[1] 韩镇洋,王先兰.一种改进YOLOv5的小目标检测算法 [J].电子设计工程,2023,31(19):64-67+72.
[2] 冷佳旭,莫梦竟成,周应华,等.无人机视角下的目标检测研究进展 [J].中国图象图形学报,2023,28(9):2563-2586.
[3] 张帅帅.基于YOLOv5的安全帽检测方法研究 [J/OL].重庆工商大学学报:自然科学版,2023:1-7(2023-09-04).http://kns.cnki.net/kcms/detail/50.1155.N.20230904.1223.002.html.
[4] 潘晓英,贾凝心,穆元震,等.小目标检测研究综述 [J].中国图象图形学报,2023,28(9):2587-2615.
[5] 邱昊,钟小勇,黄林辉,等.面向航拍小目标的改进YOLOv5n检测算法 [J].电光与控制,2023,30(10):95-101.
[6] 朱瑞鑫,杨福兴.运动场景下改进YOLOv5小目标检测算法 [J].计算机工程与应用,2023,59(10):196-203.
[7] 李建新,陈厚权,范文龙.基于改进YOLOv5的遥感图像目标检测研究 [J].计算机测量与控制,2023,31(9):102-108+115.
[8] 任克营,陈晓艳,茆震,等.基于注意力与自适应特征融合机制的小目标检测 [J].天津科技大学学报,2023,38(4):54-61.
[9] 吴明杰,云利军,陈载清,等.改进YOLOv5s的无人机视角下小目标检测算法 [J]. 计算机工程与应用,2024,60(2):191-199.
[10] 王勇,陶兆胜,石鑫宇,等.基于改进YOLOv5s的不同成熟度苹果目标检测方法 [J/OL].南京农业大学学报,2023:1-13[2023-10-16].http://kns.cnki.net/kcms/detail/32.1148.S.20230926.1201.002.html.
作者简介:朱梦琳(1998—),女,汉族,河南洛阳人,硕士研究生在读,研究方向:图像分类与识别;尹泉贺(2000—),男,汉族,河南周口人,硕士研究生在读,研究方向:图像分类与识别;原素慧(2001—),女,汉族,河南安阳人,硕士研究生在读,研究方向:图像分类与识别。