胡文杰,雷兵强
(咸阳职业技术学院 陕西 咸阳 712000)
0 引 言目前,基于深度神经网络的计算机视觉技术通过模拟生物视觉,使用经过训练的神经网络模型来执行多项任务,例如图像分类、图像分割和目标检测等。计算机视觉的主要应用领域是无人驾驶,几乎所有的路径规划和无人化控制都需要借助计算机视觉技术来实现,通过将基于神经网络的计算机视觉任务的结果输入到路径规划、导航算法中,求得最优和避障路径。如果在无人机上加载一个有效的计算机视觉系统和决策系统,那么无人机将拥有与人类相仿的眼睛和大脑,在多维复杂的环境中,可以实时有效地检测到周围的物体并进行目标检测、物体分类、障碍物划分、危险等级划分等处理,从而在路径规划问题上及时做出最佳决策。
计算机视觉包含许多复杂的任务,这些任务可以切分为语义分割、实例分割、图像分类和目标检测等基本任务。它们的简单定义如图1所示。

图1 计算机视觉任务
(1)语义分割需要预测所输入图像的每个像素属于哪种类型的标签。
(2)实例分割还需要在语义分割的基础上确定同一类型不同个体的具体个数。
(3)图像分类需要预测图像中物体的类别。
(4)目标检测需要在图像分类的基础上进一步识别物体的位置。
1 目标检测目标检测是一项比较实用且极具挑战性的计算机视觉任务,可以看作是图像分类和目标定位的结合。给定一张图片,目标检测系统需要识别图片中指定对象的类别并给出其位置。由于图片中物体的数量是不确定的,而且还要给出物体的精确位置,所以目标检测比分类任务更加复杂。随着计算机视觉技术的不断发展,目标检测已渗透到航天航空、智能交通、农业、高空安防、物流、森林防火等各个领域。由于在复杂的场景中,存在检测对象种类繁多、维度复杂等情况,常用的目标检测算法会出现精确度和完整度低等问题。近年来,随着深度学习的不断发展,各式各样基于卷积神经网络的目标检测算法被陆续提出。卷积神经网络可以实现数据的自主训练学习,更新参数得到一个比较准确的模型。基于卷积神经网络的目标检测算法可以分为两大类:一类是基于Region Proposal 的R-CNN(Region-Conventional Neural Network)双步目标检测算法,包括R-CNN、Fast R-CNN、FasterR-CNN 等;另一类是单步目标检测算法,包括YOLO(You Look Only Once)、SSD 等,其发展如图2所示。
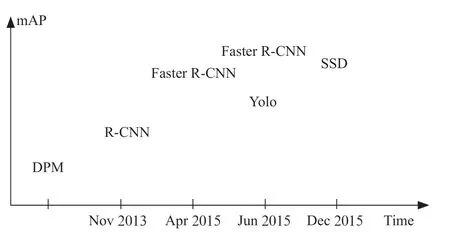
图2 目标检测主流算法发展史
自2012年Alex net 赢得ImageNet 比赛以来,卷积神经网络(CNN)已成为图像分类的基准。CNN 方法在ImageNet 挑战中的表现优于人类。最近,CNN 在对图像中物体的检测、分割和识别方面取得了巨大成功。例如,基于CNN 的方法应用于车辆检测、医学图像检测等计算机视觉任务中。双步目标检测算法分两步执行,首先是利用选择算法或卷积神经网络生成候选区(Region Proposal),然后将候选区送入网络结构中提取特征,最终生成检测目标的位置和类别。Faster Region-based CNN(Faster R-CNN)是一种基于CNN 的双步目标检测算法,其结构图如图3所示。
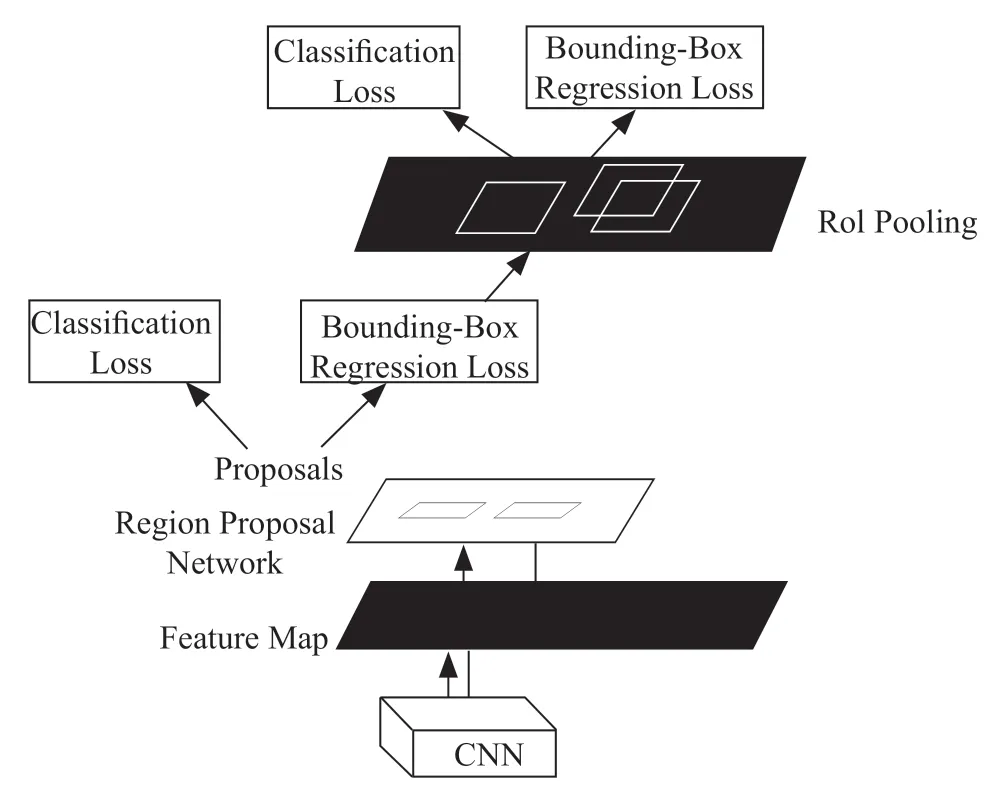
图3 Faster R-CNN 算法结构
单步目标检测算法不用生成候选区,把图像分为M×M个网格单元后,使用卷积神经网络直接预测不同对象的类别和位置。在双步目标检测算法中,由于生成一些候选区花费了不少的时间,故其检测速度比单步目标检测算法要慢,但准确率却相对较高。单目标检测算法是在图片直接划分的网格上进行的,因此其检测速度较快。早期的双步目标检测算法在检测精确度上不够理想,经过不断的改进和完善,这一问题慢慢得以解决,尤其是YOLOv5 算法在很大程度上提高了目标检测的精确度。
2 YOLOv5 网络结构按照网络深度和网络宽度的不同,YOLOv5 可以分为YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x。本文使用YOLOv5s,其网络结构最为小巧,图像推理速度最快(高达0.007 s)。采用COCO 数据集进行测试,YOLOv5s 的推理速度可以达到140 FPS,其他版本的推理速度优于谷歌于2018年推出的Efficient Net。YOLOv5 的网络结构包括Input、Backbone、Neck、Output,它们之间的关系如图4所示。
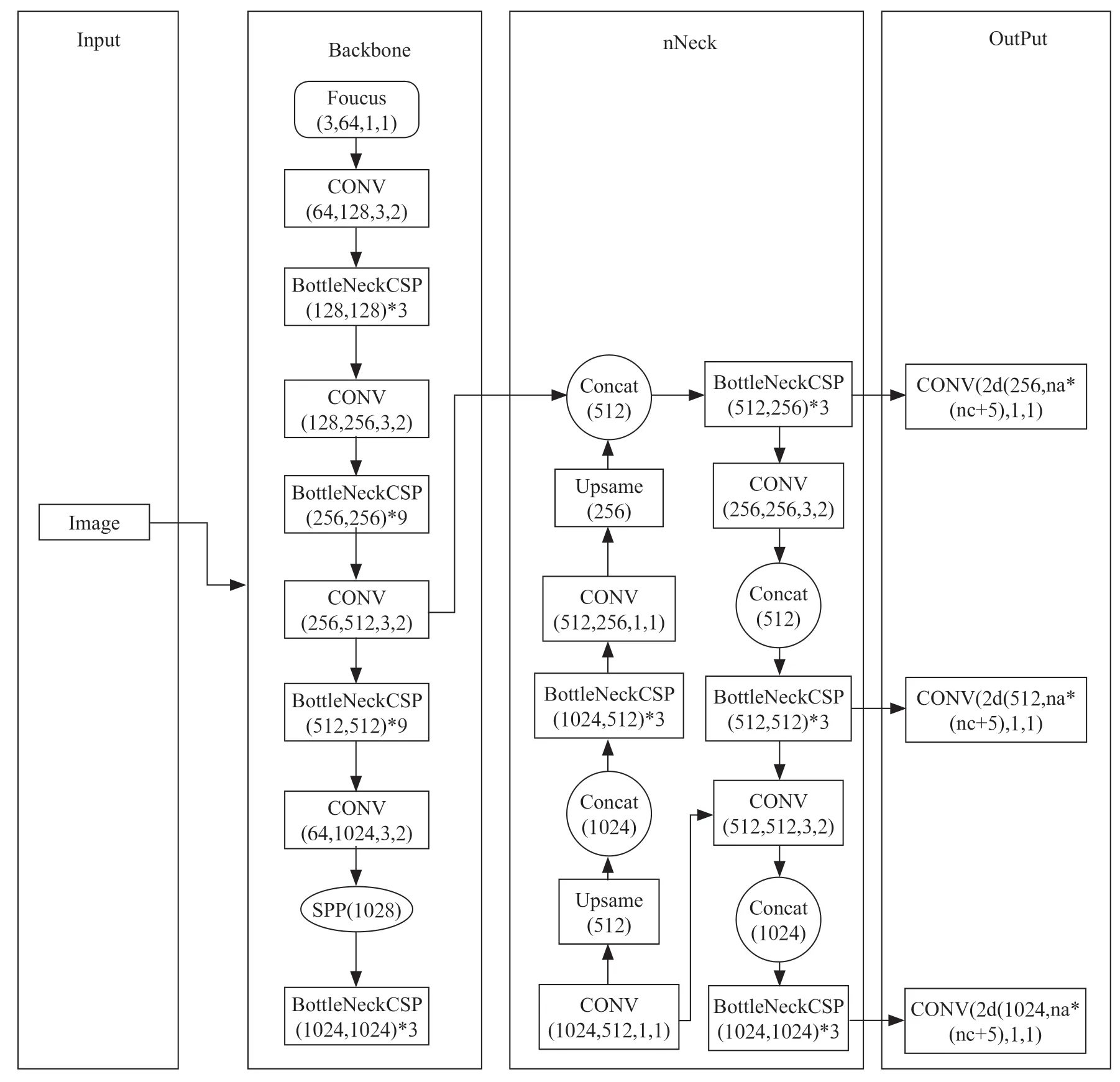
图4 YOLOv5s 网络结构
下面介绍YOLOv5s 的主要组成部分:
(1)输入端。输入端完成对输入数据的预处理,主要涉及对图片进行统一大小、增强、翻转,色域变化等操作。YOLOv5 的输入端采用Mosaic 数据增强的方法并且以随机缩放、随机裁剪、随机排布的方式对原数据和增强数据进行拼接,再将拼接结果传入卷积神经网络模型进行学习,因此其对小目标的检测具有很好的检测效果。
(2)Backbone(网络主干)。Backbone 在不同图像细粒度上聚合并形成基于图像特征的卷积神经网络,其主要包含Focus、CSP 和SPP。Backbone 的第一层是Focus,从高分辨率图像中周期性抽出像素点并将其重构到低分辨率的图像中,提高每个点感受野,并减少原始信息的丢失,该模块的目的主要是减少计算量从而加快检测速度。YOLOv5 默认640×640×3 的输入,先将其复制四份,通过切片操作将这四个图片切分成四个320×320×3 的切片,然后连接这四个切边,再通过64 核的卷积层进行卷积操作,生成320×320×64 的输出,最后再通过激活函数将结果输入到下一个卷积层。YOLOv5s 的CSP 结构用于将原输入分成两个分支,分别对两个分支进行卷积操作使得通道数减半,再对其中一个分支进行Bottleneck*M操作,然后拼接两个分支,使得BottlenneckCSP 的输入与输出大小相同,从而使网络模型学习到更多的特征,提高目标检测的精确度。YOLOv5 中的CSP 有两种结构CSP1_X 和CSP2_X。SPP(Spatial Pyramid Pooling)模块(即空间金字塔池化模块)先采用4 种不同大小的卷积核进行最大池化操作,再进行张量拼接,从而使最终的输入特征保持一致。
(3)YOLOv5s 的Neck 部分仍然采用FPN+PAN 进行采样,但是它在YOLOv4 的基础上做了优化改进,采用CSPnet 设计的CSP2 结构,以此加强网络特征融合能力。Neck 主要用于增强模型对不同缩放尺度对象的检测,使其能够识别出不同大小的同一个物体。YOLOv5 采用CSP2结构替代YOLOv4 中的部分CBL 模块,其具体结构如图5所示。
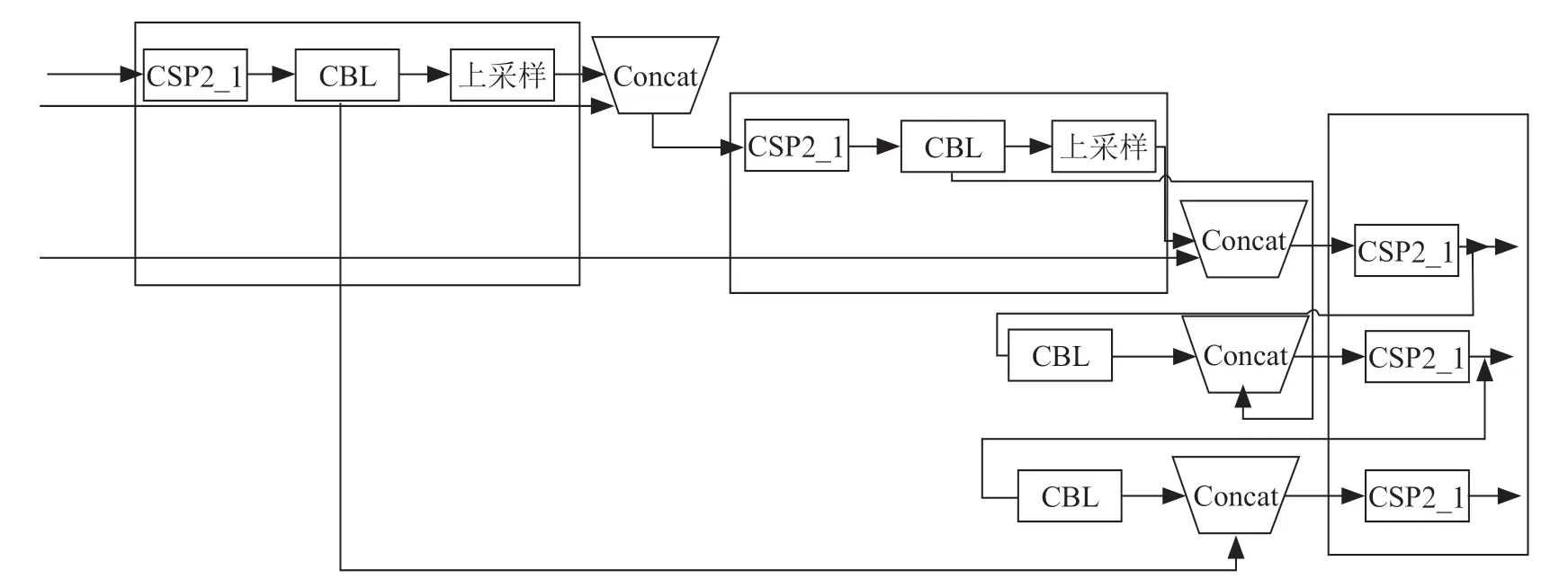
图5 YOLOv5s 的Neck 结构
(4)Output YOLOv5 采用GIoU_Loss 作为损失函数,GIoU_Loss 解决了无法区分Prediction Box 与Ground Truth Box 相交的问题,增加了相交尺度的衡量手段,缓解了单纯IOU_Loss 时存在的一些问题。CIOU_Loss 在DIOU_Loss的基础上增加了一个影响因子,将Prediction Box 和Ground Truth Box 的长宽比也考虑在内。即CIOU_Loss 将GT 框的重叠面积、中心点距离和长宽比全部纳入考虑范围。
3 强化学习强化学习(Reinforcement Learning,RL)是指agent 在与环境的交互中,通过状态值的改变不断调整的action,从而获取最大价值的无监督学习。RL 已经广泛应用于无人机和自主系统的决策确定(尤其是路径规划和导航任务),Agent 与环境的交互如图6所示。
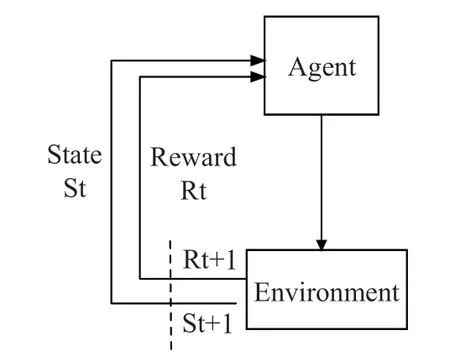
图6 RL 中Agent 与环境交互结构
深度强化学习是指将深度学习和强化学习相结合处理复杂多维度环境中遇到的问题。深度强化学习有机结合了深度学习的感知能力和强化学习的决策能力,并可根据输入的图像直接控制决策过程。它是一种更接近于人类思维的人工智能方法。此外,深度强化学习的最新技术已经扩展到解决自主系统路径规划的难题中。
4 实验步骤与结果分析实验流程及优化效果如下:
(1)搭建Anaconda 集成开发环境。Anaconda 是一个开源的包、环境管理器,可以用于在同一个机器上安装不同版本的软件包及其依赖,并能够在不同的环境之间切换:
1)下载并安装Anaconda 开源软件;
2)为提高Anaconda 中所创建环境安装指定软件的速度,配置Anaconda 下载通道为清华镜像路径,命令如图7所示。

图7 配置Anaconda 下载通道命令
3)配置YOLOv5s 的工程环境进行目标检测任务时,务必要注意各软件包版本的兼容性。在本项目中,在requirement.txt 文件中指定了对于各个软件版本的要求,具体要求为:
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.2
Pillow
PyYAML>=5.3.1
scipy>=1.4.1
torch>=1.7.0
torchvision>=0.8.1
tqdm>=4.41.0
tensorboard>=2.4.1
seaborn>=0.11.0
pandas
thop
pycocotools>=2.0
(2)使用YOLOv5s网络模型训练数据并对训练结果(例如精确度、阈值等)进行相关分析,最后优化YOLOv5s 网络模型:
1)将无人机拍摄的照片或视频中截取的照片作为训练数据,在数据被训练之前,首先进行resize 的操作,将训练数据调整为720×720 大小的图片;
2)配置YOLOv5s 配置文件conf.yaml 中的参数,指定训练数据的文件路径;
3)运行应用程序train.py 训练数据;
4)对运行结果进行分析并优化YOLOv5s 模型相关参数的设置。
(3)运用优化后的YOLOv5s 模型和参数值对测试图像进行目标检测:
1)将无人机拍摄的照片或视频中截取的照片作为训练数据,在数据被训练之前,首先进行resize 的操作,将训练数据调整为720×720 大小的图片;
2)配置YOLOv5s 配置文件conf.yaml 中的参数,指定训练数据的文件路径;
3)运行应用程序test.py 训练数据。
(4)将计算机视觉任务的处理结果输入到深度强化学习决策算法中,选择合适的策略算法,获取预期价值。
5 结 论鉴于传统位置固定的摄像头、照相机所拍摄的图像和视频采集设备采集的视频角度单一、画面不全的弊端,本项目将图像、视频采集设备安装在无人机上,在无人机飞行的过程中实时动态采集数据,这些设备的位置会随环境和需要发生动态改变,能更为准确地模拟和创建真实的环境模型。其次,将基于神经网络模型的计算机视觉任务的有效输出结果作为强化学习中路径规划问题的状态输入,而不是直接使用采集到的原始图片和视频,从而提高了强化学习策略算法的执行效率和精确度。