
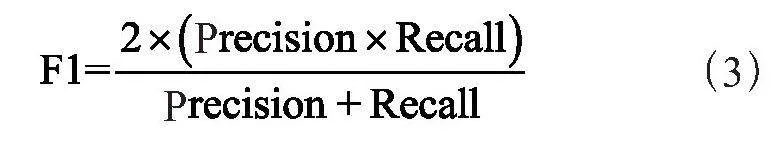

摘" 要:中医药领域积累了丰富的知识与经验,但如何从这些海量、深奥的中医资料中准确提取中医药知识,一直是医学领域的挑战。为了提供高效准确的中医药知识抽取方法,提出了一种基于PERT模型的中医药知识抽取式问答模型。该方法依托中医药领域的专业知识与增强数据集,结合PERT模型,使用乱序语言预训练任务,实现了一个具有较强中医药知识阅读理解能力的问答模型。实验结果表明,该模型在中医药知识数据集上的问答性能优于其他相关模型,当给出中医药知识文本和问题时,能较为精确地理解并给出对应答案。
关键词:PERT;抽取式问答模型;预训练模型;中医药知识;机器阅读理解
中图分类号:TP391;TP18 文献标识码:A" 文章编号:2096-4706(2024)11-0125-05
Research on Extractive Qamp;A Model for Traditional Chinese Medicine Knowledge Based on PERT
CHEN Haoyang, YU Tongzhou, HE Qiangqiang
(Department of Computer Science and Technology, Nanjing University, NanJing" 210023, China)
Abstract: The field of Traditional Chinese Medicine (TCM) has accumulated a wealth of knowledge and experience, but how to accurately extract TCM knowledge from these massive and profound TCM materials has always been a challenge in the medical field. In order to provide an efficient and accurate method for extracting traditional Chinese medicine knowledge, a traditional Chinese medicine knowledge extractive Qamp;A Model based on the PERT model is proposed. The method relies on professional knowledge and enhanced datasets in the field of TCM, and uses the PERT model and disordered language to pre-training task, and a Qamp;A model with strong reading comprehension of TCM knowledge is realized. Experiment results show that the Qamp;A performance of this model on the TCM knowledge dataset outperforms that of other related models, and it can understand and give the corresponding answers more accurately when the TCM knowledge text and questions are given.
Keywords: PERT; extractive Qamp;A model; pre-trained model; TCM knowledge; machine reading comprehension
0" 引" 言
传统中医药是中国丰富文化遗产的一个组成部分,是中国医学实践中蕴含的深邃智慧的见证。然而,积累的中医药文献经验往往具有复杂性、难理解、海量性、多样性等特点。面对这些晦涩难懂的大量中医药文本,如何高准确率且高效地自动抽取信息,是中医信息化中的一大难题。
问答系统是解决抽取中医药知识信息问题的一种智能化方法。在传统问答系统相关的研究和技术中,比如基于检索或者文法规则的方法,它们往往问答理解能力较弱,面对海量信息时的处理效率也较低。目前流行的问答系统是基于知识库问答系统和机器阅读理解(Machine Reading Comprehension, MRC)的问答系统。知识库问答系统是利用存储有结构化或半结构化知识的数据库来回答用户自然语言问题的系统,但是它们往往十分依赖于高质量、结构化的知识库,限制于静态知识,在面对复杂多样的中医药文本时,其推理和理解能力有一定局限性。
基于MRC的问答系统则依靠自然语言处理和机器学习技术,利用各类具有强大学习表征能力的神经网络结构,根据上下文和对应的问题,自动抽取信息和理解语义,从而提供回答。然而大量中医文献内容具有复杂的上下文结构和深奥晦涩的领域知识,这为深度学习模型学习中医药知识表征和理解分析中医知识问答带来了挑战。同时,在中医领域中,MRC问答系统的应用十分有限,相关研究也较为稀缺。
为应对问答系统在中医药知识抽取中的挑战,本研究实现了一个专门针对中医药领域的抽取式问答(Qamp;A)系统,利用PERT预训练模型[1],采用乱序语言模型作为预训练任务;并且借鉴《黄帝内经》和《中成药卷》等中医基础典籍,建立一个强大的知识库,作为训练模型的数据集;最终模型可以根据中医药背景知识以及对应的问题,提供比较精确的答案。
该中医药知识抽取式问答模型可以作为创建智能中医药知识问答系统的重要组成部分,当遇到中医药知识文本和相关查询时,该模型表现出了较高的辨别能力,能提供准确度较高的答案。模型的功能可以推广应用于从大量中医药文献和专家知识库中自动提取关键见解,为促进中医药专业知识的智能处理提供一定的参考。
1" 相关工作
抽取式问答系统的研究最早可以追溯到20世纪60年代,这个时期主要流行限定领域、处理结构化数据的基于规则的问答系统,例如BASEBALL等。到20世纪90年代,问答系统进入开放领域、基于检索的时期。但是,这些系统难以应对复杂问题,鲁棒性较弱,并且无法满足更细粒度需求。
随着深度学习领域的蓬勃发展,目前基于知识库的问答系统(KBQA)以及基于机器阅读理解的问答系统较为流行。基于知识库的问答系统是一种把结构化的知识库作为信息源,利用知识库中的事实和关联知识来回答用户提问的系统,它在抽取式问答中也有较多应用。Xiong等人提出了一种新的端到端问题解答模型,可以利用结构化和非结构化信息源来回答不完整知识库(KB)上的问题[2]。Das等人提出了一种神经符号(Case-Based Reasoning, CBR)方法,用于回答大型知识库中的问题[3]。虽然KBQA系统具有很多优点,但由于KBQA十分依赖于知识库的构建水平,在目前中医药领域缺乏大规模结构化知识库的情况下,KBQA很难发挥它的优势,同时,在面对纷繁复杂的中医药文本时,其推理和理解能力也具有局限性。
基于机器阅读理解(MRC)的问答系统目前已成为文本问答的主流形式,抽取式问答系统则是其中的重要分支。在大规模的阅读理解数据集基础上,深度学习网络模型成为机器阅读理解的研究热点,神经网络模型能自动学习文本和问题之间的语义表示和交互,有利于提高问答的准确性和泛化能力。Lee等人将检索和重新排序机制作为内部段落注意力机制,依次应用于阶段性的transformer架构,使得特征表示在各个阶段逐步优化,构建了一个开放域问答系统[4]。Seo等人提出的模型BiDAF,基于双向注意力流,能够有效提高机器阅读理解能力,避免过早地对上下文进行摘要而损失信息[5]。Qu等人提出了一种基于注意力机制的循环神经网络和基于相似度矩阵的卷积神经网络的模型,利用多任务学习的方式来同时优化实体链接和关系检测,在SimpleQuestions数据集上取得了最佳结果[6]。Fedus等人提出了Switch Transformer,它利用了一种简单而灵活的稀疏注意力机制,将输入分配给多个专家模块,专家模块间相互协作,有较强的阅读理解能力[7]。虽然这些基于机器阅读理解的问答系统进一步提高了问答能力,但是对于语义深奥、古文句式多、上下文关系复杂的中医药知识文本没有提出很好的应对方法,且当前聚焦于中医药领域问答系统研究也十分稀少。
综上,为了推动中医药知识体系信息挖掘,并应对中医药文本问答的挑战,我们基于PERT预训练模型,利用乱序语言预训练任务,结合“万创杯”中医药天池大数据竞赛开源数据集与DRCD数据集,构建了一个中医药知识抽取式问答模型。经实验表明,该模型在中医药知识问答任务上的性能比较优异。
2" 模型结构
2.1" 整体研究框架
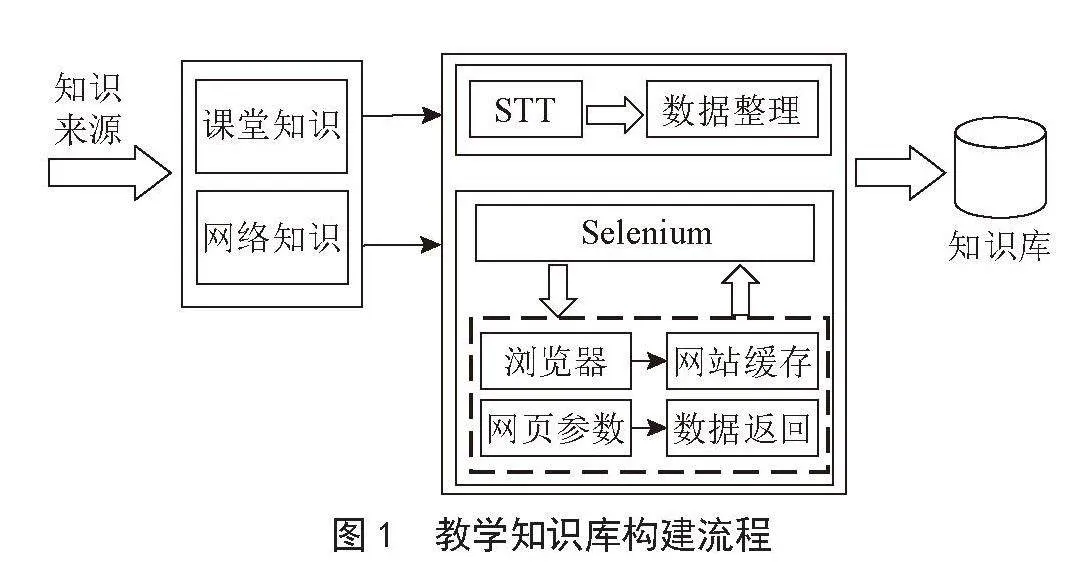
构建基于PERT模型的中医药知识抽取式问答模型主要包括以下流程:1)选取和调整数据集,对数据集进行多轮的清洗与分析;2)划分训练集、验证集、测试集;3)对数据进行分词;4)构建PERT乱序语言模型;5)模型训练与微调;6)模型评估与反馈。
2.2" PERT模型
PERT模型采用了一种新的乱序语言预训练任务,其机器阅读理解能力较为优秀,其核心思想主要包括以下部分:1)使用乱序语言模型(Permuted Language Model, PerLM)作为预训练任务,预测目标为原始输入序列中的字词位置;2)传统掩码任务中预测空间为词表,但是PERT模型预测空间的大小取决于输入序列长度;3)PERT模型舍弃了NSP任务,能够在没有添加掩码标记的情况下自监督学习文本语义信息;4)通过全词屏蔽和N-gram屏蔽策略来选择乱序的候选标记;5)对输入序列中的15%词语进行掩码,其中的90%进行位置乱序,剩余10%作为负样本保持原顺序。
模型其他结构与BERT相同,使用WordPiece方法作为分词器,打乱部分句子顺序后再进入词嵌入层,之后进入堆叠的Transformer-Encoder神经网络,进行PerLM预训练任务,最后接线性层并应用于下游任务。
2.3" 模型描述
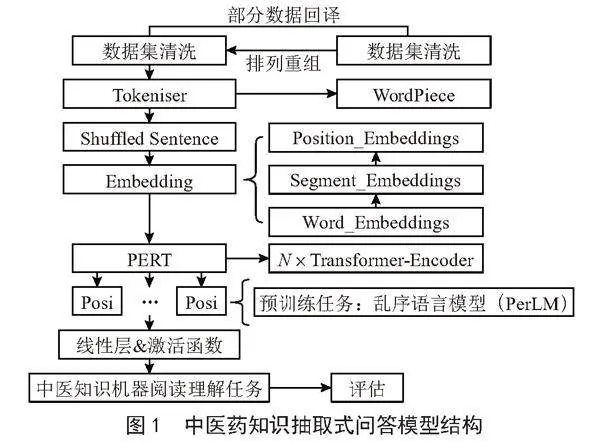
基于PERT模型的中医药知识抽取式问答模型整体结构如图1所示。结构主要分为数据输入层、分词层、打乱词序层、嵌入层、Transformer-Encoder神经网络层、乱序语言模型层、线性层与激活函数。在数据输入层和分词层中,我们将问题与背景知识相拼接,而由于有较多文本长度超过了PERT模型512字的输入限制,所以我们需要对超长输入中的背景知识进行切片,以免文本被直接截断影响问答训练效果。切片的主要思想如下:1)切片的地方也可能包括答案,所以我们需要对相邻切片之间的交集进行控制;2)我们利用答案的起始位置作为训练标签,同时维护原始文本和切片的对应关系;3)若背景知识中没有答案,则将答案起始位置设为CLS标签的位置;4)利用序列ID来区分一个输入中的问题和背景知识;5)验证集处理时,需要存储偏移映射,并利用ID属性与原始文本进行匹配,最终将预测的结果解释为原始文本的跨度。
在打乱词序层和嵌入层中,我们将对15%的输入中的90%进行随机打乱,剩余10%不变,然后,输入将经过3个Embedding:1)Word_Embedding中输入的字词将被映射为高维向量表示;2)Segment_Embeddings将区分输入中不同句段的关系;3)Position_Embeddings把字词的位置信息嵌入向量表示中。
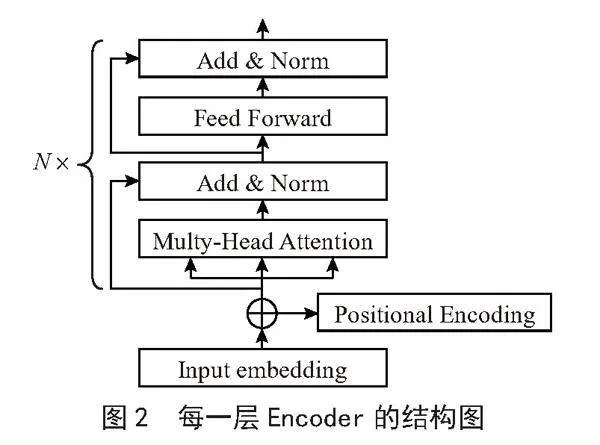
在Transformer-Encoder神经网络层中,每一层Encoder的结构如图2所示。其中多头注意力机制(Multi-Head Attention)能提高模型注意力集中于不同位置的能力,以更好地利用上下信息;前向神经网络(Feedforward Neural Network)能促进特征提取,学习融合数据的非线性映射关系。向量最终进入乱序语言模型层。
在乱序语言模型层中,将按PERT模型介绍中的思想完成乱序语言预训练任务(PerLM)。其中,PERT只需要去预测PerLM中所选定的位置,所以收集关于这些位置的子集,形成向量为H,然后依次用前馈全连接层(FFN)、Dropout层和Layer Normalization层对H进行处理,如式(1)所示。接着,使用Softmax函数得到归一化概率,并使用交叉熵损失函数进行优化,如式(2)所示:
最后进行中医药知识机器阅读理解任务,其中会过线性层、激活函数等,并在此基础上进行模型评估。
3" 实验部分
3.1" 数据集
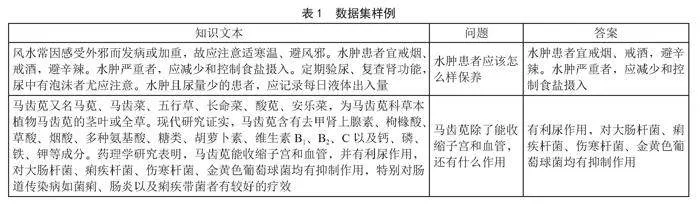
选取“万创杯”中医药天池大数据竞赛中医文献问题生成数据集作为核心数据集并进行格式调整,其包含18 000余条问答数据,涉及《黄帝内经翻译版》《名医百科中医篇》《中成药用药卷》等中医药知识,如表1所示。
而为了增强数据集,实验中根据中医药知识数据集的长度特点,提取并翻译了8 000余条DRCD繁体中文数据作为我们的辅助问答数据。同时,还利用回译技术对2 000余条中医药数据进行了回译,以期提高模型泛化能力。最终经过多轮清洗和分析后,将数据集划分为训练集、验证集、测试集,如表2所示。
3.2" 评价指标
实验选取在评判机器阅读理解能力中常用的Exact-Match与F1值作为评估标准。Exact-Match指预测字符串与其正确答案完全匹配的比例。F1值是模型准确率和召回率的调和平均,如式(3)所示,在阅读理解任务中,准确率是将预测答案与标准答案的重叠长度与预测答案的比率;召回率的计算方法是预测答案与标准答案的重叠长度除以标准答案的长度。最终总的F1值是对每一个问答的F1值取宏平均。
(3)
不过,从人类实际理解的角度出发,当预测答案包括正确答案,并且成完整句子时,也是一种合理的正确答案。因此,增加了Contain-Answer-Rate指标,用于表示预测答案包含正确答案的比例。
测试评估的核心思想是利用模型的原始预测值logits。因为每个特征中的各个字都会对应一个预测值logit,所以,可以从起始位置的预测值里选择最大的下标作为答案起始位置,从结束位置的预测值里选择最大下标作为答案的结束位置,从而得到预测答案。但是对于起始位置比结束位置的下标更大、答案过长等特殊情况有额外处理。
3.3" 实验环境和模型参数
实验的环境参数如下所示:1)CPU:Xeon Gold 6248R 10核;2)GPU:NVIDIA A100-PCIE-40GB;
3)操作系统:Linux(Ubuntu 20.04);4)PyTorch 1.10.0;5)CUDA 11.3;6)Python 3.8。
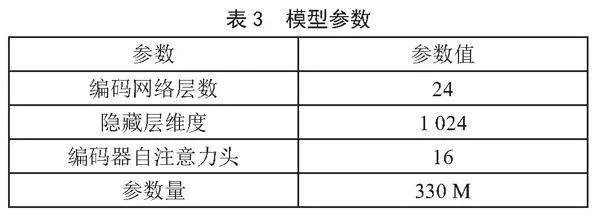
模型参数是预训练模型中神经网络中的权重和偏置,对模型的行为和性能具有重要影响,如表3所示。
3.4" 实验对比与结果分析
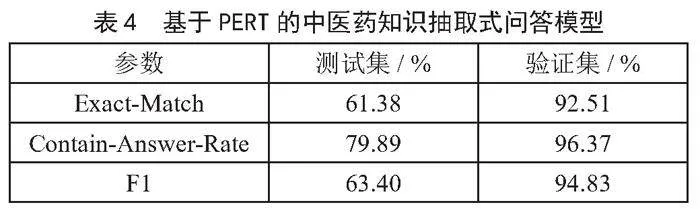
为了验证模型在中医药知识问答任务中的性能与表现,首先对基于PERT的中医药知识抽取式问答模型进行了评估测试,如表4所示。考虑到数据集随机划分的影响,表中的数据是三次测试结果的平均值,每次实验的参数相同,但是数据集的随机划分不同。
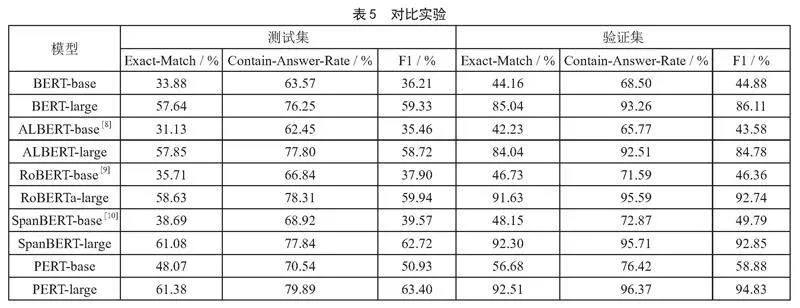
同时,为了更充分地体现该模型的中医药知识问答性能的优越性,实验选取了BERT、ALBERT、RoBERTa、SpanBERT在中医药知识问答任务中进行了多组对比实验,并在同一中医药问答测试集和验证集上测试,测试的结果如表5所示,表中的数据依旧是三次测试的平均值,每次实验数据集划分不同。
从表4可以看出,本模型的验证集评估结果中,三个数值均超过92%,这充分说明了对于已经学习过的中医药知识问答,本模型能提供极高的问答准确性,这具有较强的实际应用意义;而测试集中,模型Contain-Answer-Rate高达79.89%、Exact-Match数值超过61%、F1值为63.40%,这也证明了本模型对于未接触过的中医药知识问答,也有不错的泛化能力。
从表5中可以看出,对比同样善于机器阅读理解的BERT、ALBERT、RoBERTa、SpanBERT模型,本模型在中医药知识问答任务中的表现更为优秀,在测试集和验证集上的Exact-Match、Contain-Answer-Rate、F1均为最高。以测试集为例,本模型比第二优秀的SpanBERT-large模型分别高约0.3%、2.05%、0.68%,比第三优秀的RoBERTa-large模型分别高约2.7%、1.5%、3.4%。这些对比实验证明了,基于PERT模型的中医药知识抽取式问答模型,相比于其他模型而言,在中医药问答任务上具有更优异的表现和性能,对于给定的中医药背景知识以及对应的问题,能够给出更精确的回答。
4" 结" 论
针对从海量中医药资料中准确提取和应用知识的难题,本文构建了一个基于PERT模型的中医药知识抽取式问答系统,结合乱序语言预训练任务,在阅读理解任务中,有效提高了模型提取文本语义特征和信息的能力,增强了模型问答性能。同时,通过多组对比实验,充分证实了,该模型在中医药知识问答任务上具有优异的表现和性能,善于对中医药知识的机器阅读理解。本研究是对中医药知识和智能处理的一次结合,能为挖掘庞大中医药知识体系、提取应用中医药知识提供一些借鉴。在未来也会结合相关技术,做进一步思考与改进。
参考文献:
[1] CUI Y M,YANG Z Q,LIU T. PERT: Pre-training BERT with Permuted Language Model. [J/OL].arXiv:2203.06906 [cs.CL].[2023-10-26].https://arxiv.org/abs/2203.06906.
[2] XIONG W H,YU M,CHANG S Y,et al. Improving Question Answering over Incomplete KBs with Knowledge-Aware Reader [J/OL].arXiv:1905.07098 [cs.CL].[2023-10-26].https://arxiv.org/abs/1905.07098v1.
[3] DAS R,ZAHEER M,THAI D,et al. Case-based Reasoning for Natural Language Queries over Knowledge Bases [J/OL] arXiv:2104.08762 [cs.CL].[2023-10-26].https://arxiv.org/abs/2104.08762v2.
[4] LEE H,KEDIA A,LEE J,et al. You Only Need One Model for Open-Domain Question Answering [BE/OL].[2023-10-26].https://arxiv.org/pdf/2112.07381v1.
[5] SEO M,KEMBHAVI A,FARHADI A,et al. Bidirectional Attention Flow for Machine Comprehension [J/OL].arXiv:1611.01603 [cs.CL].[2023-10-27].https://arxiv.org/abs/1611.01603.
[6] QU Y Q,LIU J,KANG L Y,et al. Question answering over Freebase via attentive RNN with similarity matrix based CNN [J/OL].arXiv:1804.03317 [cs.CL].[2023-10-27].https://arxiv.org/abs/1804.03317v3.
[7] FEDUS W,ZOPH B,SHAZEER N. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity [J/OL].arXiv:2101.03961 [cs.LG].[2023-10-26].https://arxiv.org/abs/2101.03961v3.
[8] LAN Z Z,CHEN M D,GOODMAN S,et al. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations [J/OL].arXiv:1909.11942 [cs.CL].[2023-10-26].https://arxiv.org/abs/1909.11942.
[9] LIU Y H,OTT M,GOYAL N,et al. RoBERTa: A Robustly Optimized BERT Pretraining Approach [J/OL].arXiv:1907.11692 [cs.CL].[2023-10-26].https://arxiv.org/abs/1907.11692.
[10] JOSHI M,CHEN D Q,LIU Y H,et al. SpanBERT: Improving Pre-training by Representing and Predicting Spans [J/OL].arXiv:1907.10529 [cs.CL].[2023-10-26].https://arxiv.org/abs/1907.10529.
作者简介:陈昊飏(2003—),男,汉族,浙江嘉兴人,本科在读,主要研究方向:文本分类、问答系统;于同舟(2002—),男,汉族,内蒙古人,本科在读,主要研究方向:数据处理与分析;何强强(1996—),男,汉族,江苏南通人,博士研究生在读,主要研究方向:自然语言处理、人机交互。
收稿日期:2023-11-17