

摘 要:研究旨在应对教育中的学生个体差异、教学资源限制及师生互动缺乏等问题,介绍了一种基于大型语言模型的创新型教育教学知识问答系统。该系统整合了课堂知识和网络资源,构建了全面丰富的教学知识库,并通过精细的数据清洗与分类处理提升了数据质量。为优化性能,研究团队设计实现了高效的多模型检索机制,确保系统在不同硬件环境下均能快速响应。系统不仅提高了响应速度,降低了基础设施成本,而且适用于学校教育和党课培训等多个领域,对教育数字化转型及创新产生深远影响。
关键词:大语言模型;人工智能教育;高效检索模型
中图分类号:TP311 文献标识码:A 文章编号:2096-4706(2025)02-0189-06
Design of Education and Teaching Knowledge Question and Answering System Based on Large Language Model
YI Yunheng, PAN Ji
(School of Rail Transportation, Southwest Jiaotong University Hope College, Chengdu 610400, China)
Abstract: This research aims to deal with the problems such as individual differences among students, limited teaching resources, and inadequate teacher-student interaction in education, and introduces an innovative education and teaching knowledge question and answering system based on Large Language Model. The system integrates classroom knowledge and network resources, builds a comprehensive and rich teaching knowledge base, and improves data quality through meticulous data cleaning and classification processing. To optimize performance, the research team designs and implements an efficient multi-model retrieval mechanism, which ensures the system could respond quickly in different hardware environments. This system not only improves response speed but also reduces infrastructure costs. It is suitable for multiple fields such as school education and party class training, and has a profound impact on the digital transformation and innovation of education.
Keywords: Large Language Model; Artificial Intelligence education; efficient retrieval model
DOI:10.19850/j.cnki.2096-4706.2025.02.036
0 引 言
传统教育模式通常以教师为中心,采用信息单向传授的教学方式,包括课堂提问和课后提问两部分;而课后问答环节则通过手机应用、邮件、课程网站等渠道向教师寻求问题的解决[1]。课堂教学质量的高低与教师的教育教学能力、课程内容丰富度直接相关。学生被动接受知识,难以培养自主学习能力。更为关键的是这种单向传授的教学方式使得教师难以掌握学生的学习进度、知识掌握情况,而部分学习能力较弱的学生由于跟不上教学进度对教学产生焦虑和抗拒情绪,丧失兴趣和主动学习和动力。此外,传统教育教学侧重考查学生的记忆力与理解力,忽视对于创新能力的培养[2]。
大语言模型技术在教育领域的应用具有广阔的发展前景和重要的意义[3]。该技术能够为学生和教师提供更为个性化、高效的学习与教学体验,有助于缓解教师的工作压力,丰富教学资源,并提升学校的学生管理效率。将大语言模型应用于教育领域能住与优化教育流程,增强学习效果与教学质量,为师生双方带来便捷。
因此,基于深度学习模型的教育教学知识问答系统,以学习者为中心提供线上知识问答,有助力推动教学教育的改革[4]。
1 数据获取与处理
基于大语言模型的教育教学知识问答系统的系统架构包括教学知识库构建、数据清洗与分类、多模型检索系统以及选择并加载大语言模型等关键环节。
1.1 数据获取
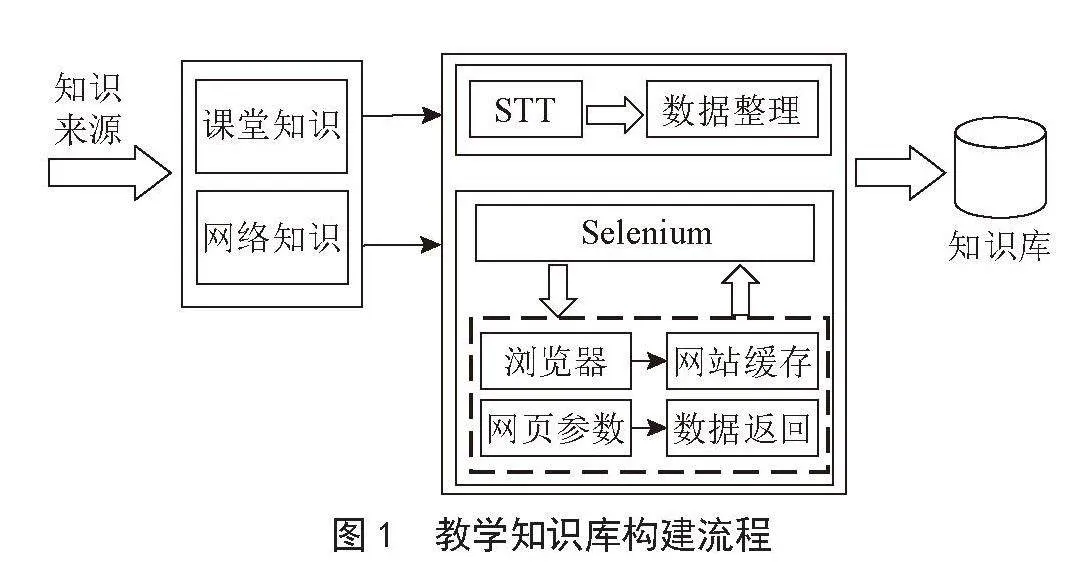
教学知识库构建过程包括知识数据提取流程和课堂知识构建过程,教学知识库构建流程如图1所示。其中,知识数据提取为教学知识库提供了丰富的数据来源,而课堂知识构建过程提取授课的语音,进一步扩充知识库的内容。所有的知识将会经过整理和清洗写入数据库。
1.1.1 知识数据提取流程
数据采集采用Python中的Selenium框架[5]。Selenium框架支持对动态网站的爬取和数据提取,能够在更广泛的网站范围内实时收集数据。数据主要来源于各大社区问答平台,同时辅以百度百科、知乎等第三方教育网站的问答库。为了高效地从这些不同网站中抓取数据,针对性地编写了多个Python脚本。在数据抓取环节,采用了Selenium框架,它能够模拟真实用户的行为,依次从预设的URL列表中提取网页链接并发起请求,从而精准地获取网站中的知识数据。在数据采集后,进一步利用正则表达式对数据进行细致的清洗和过滤,以剔除特殊字符和数据噪声,确保最终录入知识库的数据具备高度纯净性和准确性。
1.1.2 课堂知识构建过程
教师的课堂讲解内容更全面、更完整,而且这些内容往往并未被教材或文档所记录。因此,将教师的课堂讲解内容整合起来,可以极大地丰富教学知识库,为学生提供更多元、更深入的学习资源。
STT(Speech-to-Text)技术[6]是一种基于深度学习的自然语言处理技术,可以将语音转换为文本格式,将口头描述实时转化为书面形式,并提炼关键知识点,更好地分析和总结教师的授课内容,建立丰富且易于搜索的知识库。
1.2 数据处理
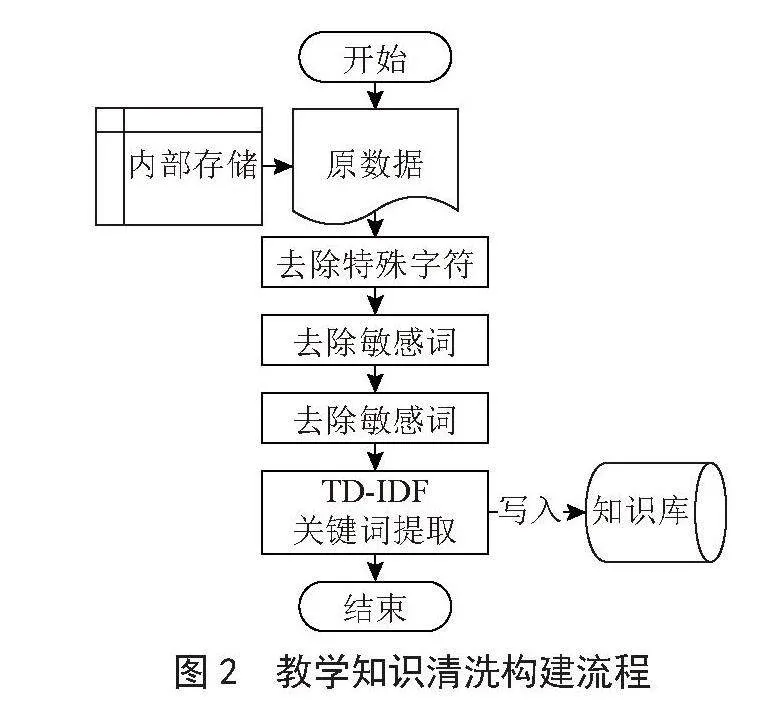
针对教育领域的数据处理,由于教学知识数据具有复杂且多样的特性,通常混杂着大量无效的信息和噪音,因此有必要对数据库中的数据进行一次清洗。整体的清洗过程如图2所示。
在对爬取的数据进行预处理操作时,需要采用一定的数据清洗规则和分类标准[7]。这一过程包括识别并剔除噪音、错误和不规则数据,去除HTML标签、特殊字符以及数据中的重复项等。
1.2.1 关键词提取
在构建教学知识库的过程中,为了提高数据的检索效率和精准度,采用了TF-IDF算法[8]对获取的文章进行关键词提取。TF-IDF(Term Frequency-Inverse Document Frequency)算法是一种统计方法,用于评估一个词语对于一个文档集或一个语料库中的其中一份文档的重要程度。通过TF-IDF算法,可以从文章中识别出那些能够代表文章主题和内容的核心词汇,这些词汇就是关键词。
具体来说,TF-IDF算法会计算每个词语的“词频”(TF),即词语在文档中出现的次数,以及“逆文档频率”(IDF),即词语在整个文档集中的稀疏程度。一个词语在文档中的出现次数越多,且在文档集中的出现频率越低,其IDF值就越高,表明这个词语在区分文档内容方面的重要性越大。
提取关键词后,将这些关键词与相应的文章一同存入数据库。这样,当用户在搜索特定知识点时,系统可以快速定位到包含相关关键词的文章,从而提高用户获取信息的效率。通过TF-IDF算法的有效应用,不仅优化了知识库的结构,还显著提升了系统的用户体验。
1.2.2 数据库设计
从课堂或网络中获取的数据,为了便于程序高效地查找和管理,应当被存储在数据库中。在本系统中,选择了MySQL数据库作为数据存储的解决方案。MySQL因其稳定性、可扩展性和易用性而被广泛应用于各种规模的系统中[9]。
为了组织和管理数据,将所有的表结构设计为包含三个基本字段:ID、Keyword、Text。每个字段的作用如下:
1)ID是一个唯一标识符,用于区分数据库中的每一条记录。它通常是一个自动递增的整数,确保了每条记录的唯一性,便于快速检索和引用。
2)Keyword这个字段用于存储从文章中提取的关键词,这些关键词是通过之前提到的TF-IDF算法计算得出的。关键词的存储为后续的搜索和检索提供了直接的索引,使得系统能够快速定位到与用户查询相关的数据。
3)Text这个字段用于存储实际的文本内容,无论是从课堂录音转换的文本,还是从网络爬取的文章,都会保存在这个字段中。文本内容是用户查询的最终目标,也是知识库中最有价值的部分。
通过这种简洁而高效的表结构设计,确保了数据库的灵活性,同时也为程序的快速查询和数据管理提供了便利。用户可以通过关键词搜索快速找到相关的教学资料,而程序也可以通过ID字段高效地进行数据维护和更新。这样的数据库设计不仅优化了数据存储,还提升了系统的整体性能和用户体验。
2 知识问答系统
2.1 基础结构
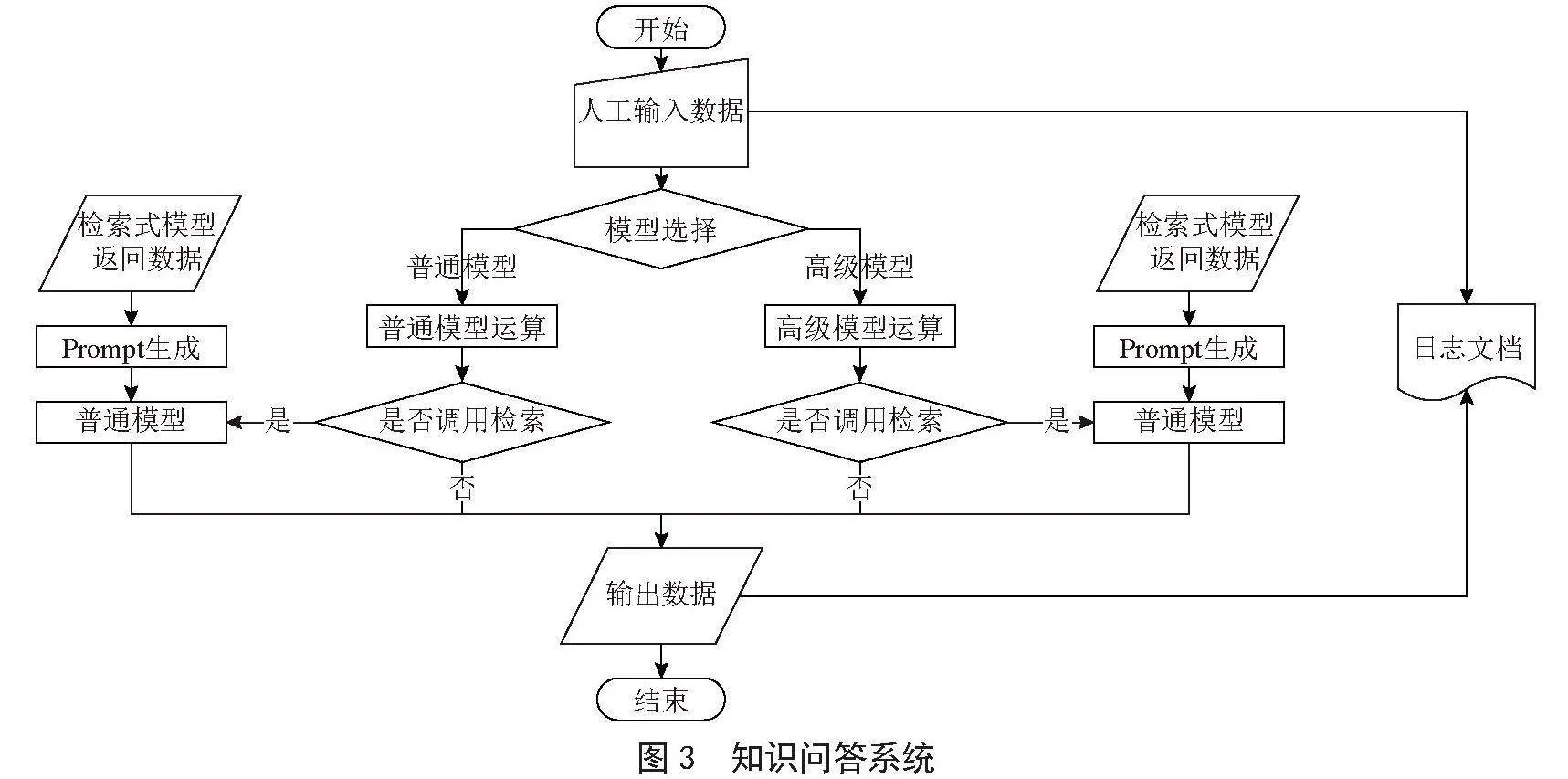
知识问答系统基于大语言模型,其包含两类主要模型,一个是大语言模型,一个是检索式模型,检索式模型通常以text2vec_base_chinese作为基座模型[10],并以LangChain框架[11]实现对文本的检索。多模型检索系统的示意图如图3所示。
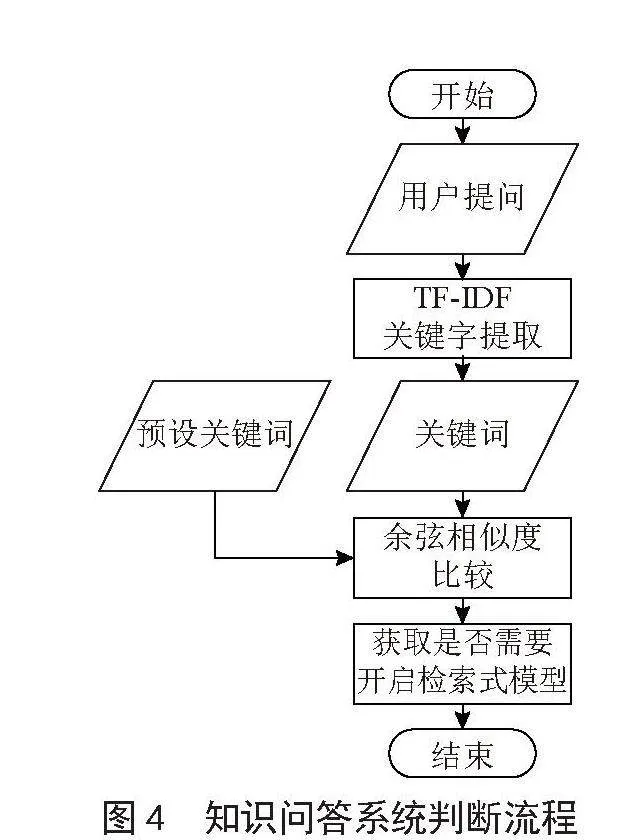
用户向系统提出问题后,系统会提示用户选择所需模型。用户仅需选择一次,之后系统将自动沿用该选择,无须用户再次操作。若用户选择普通模型,系统将调用本地的大型语言模型;若选择高级模型,则会接入如文心一言、通义千问等先进的大型语言模型。
选定模型后,该模型会分析用户的问题,判断是否需要借助检索式模型。若无须检索式模型,则直接给出答案;若需要,便将问题传递给检索式模型以获取相关提示词。后经过分析得到问题是否需要使用检索式模型的相关意见。
在实际实现中,仅需要对模型的意见进行TD-IDF关键字提取,随后将关键字与预设的关键字进行余弦相似度比对,即可精准地分类出是否需要调用检索式模型。关键字进行余弦相似度进行余弦相似度比较前可以使用Scikit-learn中的TfidfVectorizer或CountVectorizer来将文本转换为向量表示。
最后,大型语言模型会依据这些提示词来构建并给出回答。知识问答系统判断流程图如图4所示。
2.2 检索式模型
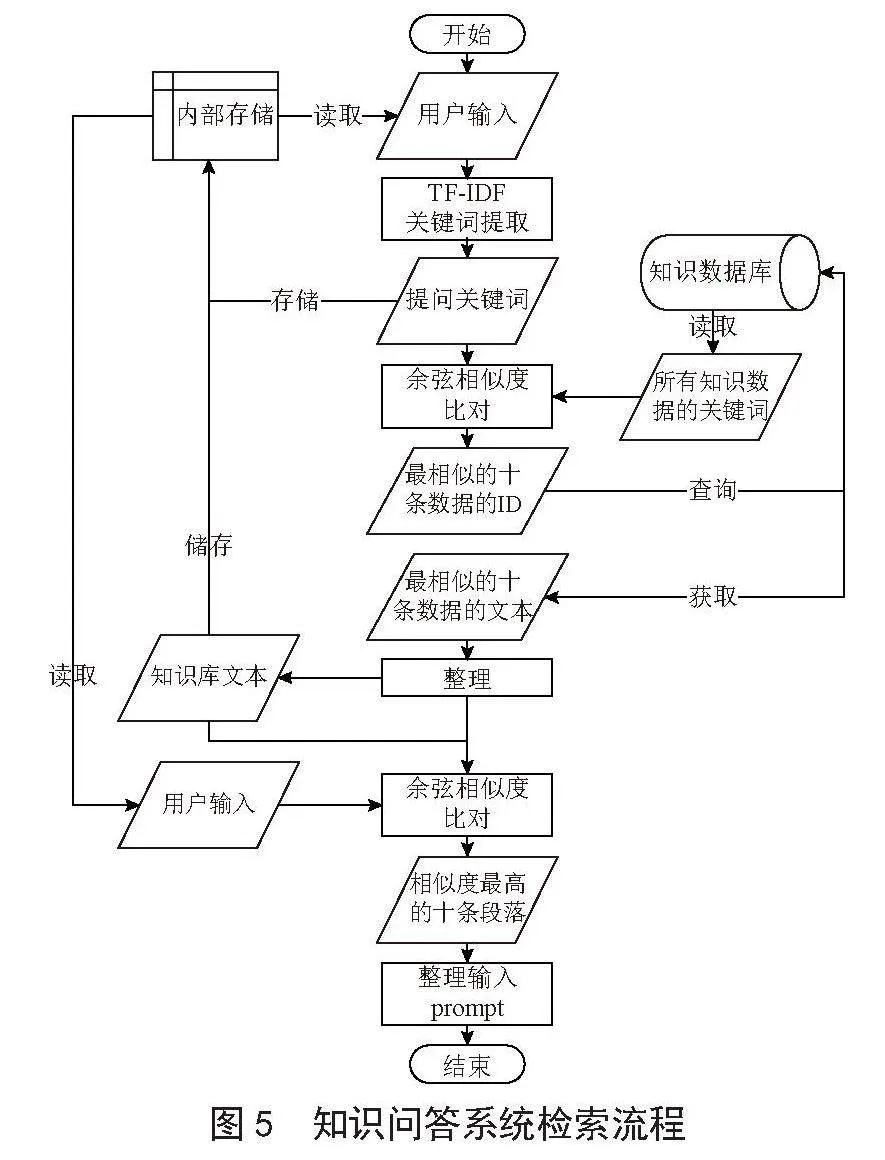
检索式模型是知识问答系统的核心组件,其性能的好坏直接关系到系统能否精确抓取到相关知识。这类模型通常以text2vec_base_chinese为基座,通过先进的算法将用户输入的查询语句转换成文本向量[12]。随后,这些向量会与知识库中的文本向量进行余弦相似度计算[13],从而找出与用户查询最相关的文本信息。这种机制确保了系统能够迅速、准确地提供用户所需的知识。为了优化这一模型,提出以下改进方案:首先,检索式模型接收用户的输入语句,并利用TF-IDF算法从中提取关键词。接着,将这些关键词与数据库中每条数据的关键词进行余弦相似度比较,选择相似度最高的十条数据,并将其对应的文本内容合并,形成一份综合知识文本。
随后,再次利用text2vec_base_chinese模型,将用户问题和这份综合知识文本分别转换为文本向量。通过计算这两组向量之间的余弦相似度,选取最相关的十个段落。最后,将这些段落转换为文字,整合后作为提示信息(prompt)反馈给大型模型,从而提供更精准、更全面的知识答案。这样的优化流程旨在提高检索式模型的精确度和效率,为用户提供更加优质的知识检索体验,示意图如图5所示。
2.3 基于Gradio的可视化界面
Gradio是一个功能强大的Python可视化库[14],其独特之处在于,它赋予使用者无须编写烦琐的HTML、CSS和js代码的能力,便可轻松构建出美观且实用的用户界面。通过Gradio,开发者可以迅速搭建起一个简约而不失现代感的交互界面,直观且易于操作,其中包括了用于显示聊天记录的清晰区域,便于用户追踪对话内容;用户输入区域设计得简洁明了,方便用户随时输入信息;此外,还提供了模型选择功能,用户可以根据自己的需求灵活选择不同的模型进行交互。整个界面布局合理,既符合现代审美,又充分考虑了用户操作的便捷性,使得用户能够便捷地进行交互操作,同时也大大提升了用户体验。
3 实现与实验结果
3.1 开发环境
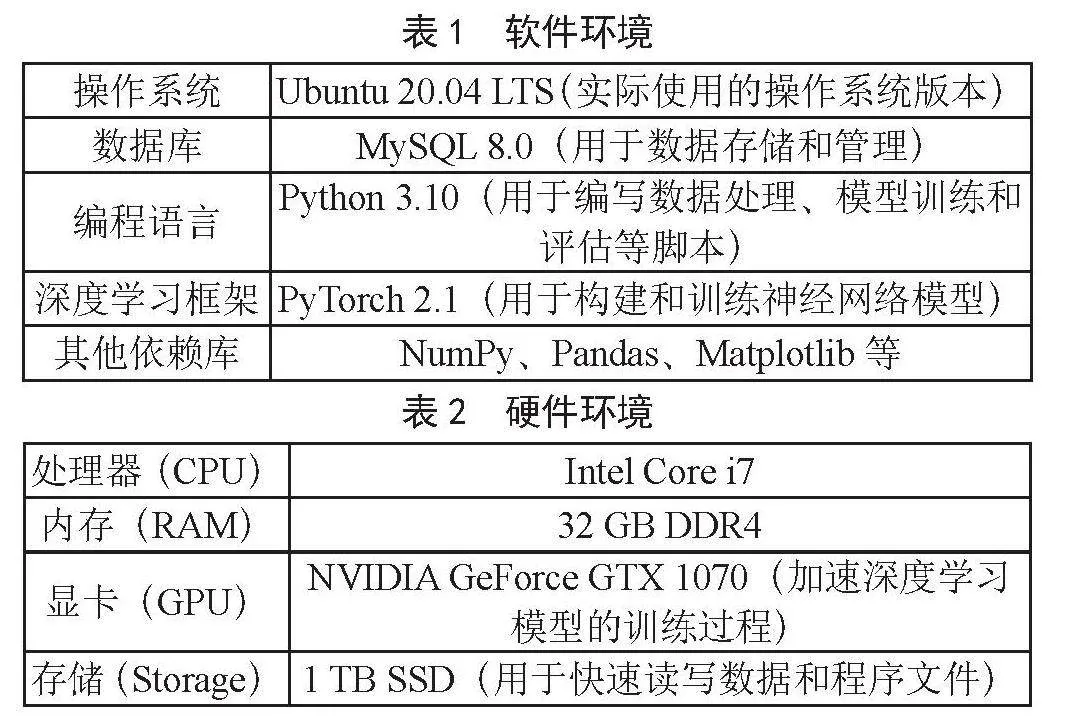
系统的软件环境与硬件环境如表1和表2所示。
3.2 数据集展示
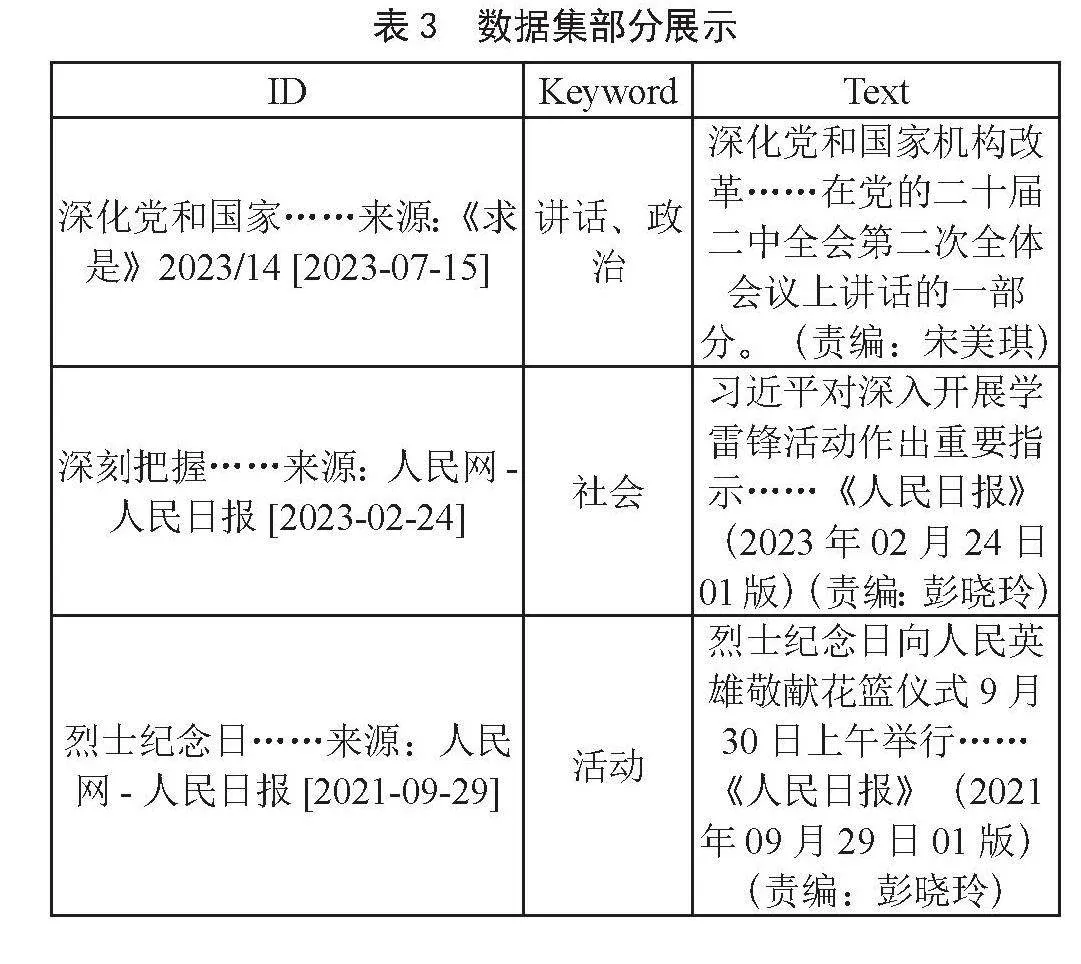
在具体实验中,采用了Gradio作为前端界面,后台则依托了强大的基础大语言模型ChatGLM 4和ChatGPT 3.5。本模型提供了两种模式:知识助手模式和原生模式。在原生模式下,模型会直接响应用户输入,不会进行任何额外的数据处理。
为了实现这一系统,以党课为具体案例,构建了一个专为党建教育设计的知识助手,称之为“党建助手”。为了确保数据的权威性和准确性,所有的数据集都来源于人民网党建数据库(http://jhsjk.people.cn/)。在遵守相关法律法规的前提下,从该数据库中合法爬取了少量数据,用于研究和分析。数据集部分展示如表3所示。
3.3 对比实验
本研究旨在评估基于大语言模型的教育教学知识问答系统的有效性。为实现这一目标,对比了党建模式和原生模式下大语言模型的表现。专注于党建知识数据库中的内容,并以此为基础设计提问,以全面观察和分析不同大语言模型在应对这些问题时的性能。
为确保实验的公正性和结果的可靠性,特别选择了不依赖联网搜索的ChatGLM-Pro作为基础模型。这一选择有助于更直观地比较不同模式下的模型表现,排除了网络搜索对实验结果可能产生的干扰。
通过实验,收集并整理了丰富的数据,详细记录了两种模式下大语言模型的回答质量和准确性。这些数据不仅揭示了模型在不同模式下的性能差异,也提供了关于如何优化教育教学知识问答系统的宝贵见解。
实验原始结果如图6所示,通过对比分析,可以更深入地了解大语言模型在教育教学领域的应用潜力,以及党建模式对模型性能的具体影响。这将有助于进一步探索和开发更高效、更智能的教育技术解决方案。
图6通过科学对比的方式,深入探讨了党建助手与原生模式在回答党建、政治及经济领域相关问题时的表现差异。研究结果显示,相较于原生模式,党建助手在针对各类问题的回答中,展现出了更高的具体性、专业性和针对性。举例而言,在回答有关党建新闻的问题时,党建助手能够精准地提供相关的具体内容和方向,反观原生模式,其回答则仅限于给出一般性的新闻获取建议。同样值得注意的是,在解读政治类文章以及提出经济领域学习要点的问题上,党建助手的回答均表现出了更深的洞察力和全面性,其不仅能够准确概括文章的核心主旨,还能为学习者提供切实可行的指导和建议。综上所述,本研究表明,党建助手在提供精确、专业的党建及相关领域信息方面具有显著优势,这一发现对于相关领域的研究和实践具有重要的指导意义。
4 结 论
本研究成功设计并开发了一款基于大语言模型技术的教育教学知识问答系统。通过巧妙运用Selenium技术,实现了广域数据的全面收集,进一步与STT技术相结合,构建了一个内容更为丰富、结构更为完善的教学知识库。此外,还采用了高级关键词搜索和语义匹配方法,对文本进行了细致的分类和异常值处理,从而显著提升了数据的可用性和可信度。
为了优化用户体验,特别是在硬件性能受限的环境下,特别设计了一个多模型检索系统。这一创新举措不仅大幅提高了检索速度,还确保了检索结果的准确性,为用户带来了更加流畅、高效的知识检索体验。
展望未来,计划进一步完善和优化该知识检索系统。首先,将继续扩充教学知识库,覆盖更多学科领域,以满足不同用户的需求。其次,将致力于提升系统的智能化水平,通过引入更先进的算法和技术,实现更加精准的语义理解和匹配,从而提高检索的精确度和效率。最后,将持续关注用户反馈,不断优化系统功能和用户界面,力求为广大教育者和学生提供更加全面、便捷、高效的知识检索服务,助力教育教学事业的发展。
参考文献:
[1] 朱卫平,林海,谢榕,等.智能问答系统在高校课程教学中的应用 [J].计算机教育,2019(10):23-26.
[2] 胡萍,蒲小琼.基于“互联网+”的互动式自主学习教学模式研究及应用 [J].高教学刊,2022,8(17):80-83.
[3] 张春红,杜龙飞,朱新宁,等.基于大语言模型的教育问答系统研究 [J].北京邮电大学学报:社会科学版,2023,25(6):79-88.
[4] 贺超波,林晓凡,程俊伟,等.学习型社区赋能教育强国建设——基于在线学习者关系网络分析视角 [J].中国电化教育,2024(6):38-45.
[5] 冯兴利,洪丹丹,罗军锋,等.基于Selenium+Python的高校统一身份认证自动化验收测试技术研究 [J].现代电子技术,2019,42(22):89-91+97.
[6] 付强,徐振平,盛文星,等.结合字节级别字节对编码的端到端中文语音识别方法 [J/OL].计算机应用,1-8(2024-05-17).http://kns.cnki.net/kcms/detail/51.1307.TP.20240515.0955.004.html.
[7] 白星振,隋舒婷,葛磊蛟,等.基于滑动四分位和可行搜索圆算法的风速-功率异常数据清洗方法 [J].山东科技大学学报:自然科学版,2023,42(6):106-116.
[8] 蒋昊达,赵春蕾,陈瀚,等.基于改进TF-IDF与BERT的领域情感词典构建方法 [J].计算机科学,2024,51(S1):162-170.
[9] 赵子晨,杨锋,郭玉辉,等.基于Hadoop技术的加速器大数据安全存储与高效分析系统设计 [J].现代电子技术,2024,47(8):9-17.
[10] 杨滨瑕,罗旭东,孙凯丽.基于预训练语言模型的机器翻译最新进展 [J].计算机科学,2024,51(S1):50-57.
[11] MORALES-CHAN M,AMADO-SALVATIERRA H R,MEDINA J A,et al. Personalized Feedback in Massive Open Online Courses: Harnessing the Power of LangChain and OpenAI API [J].Electronics,2024,13(10):1960.
[12] 郭顺.词和文本的表示与文本分类的研究 [D].大连:大连理工大学,2020.
[13] 武永亮,赵书良,李长镜,等.基于TF-IDF和余弦相似度的文本分类方法 [J].中文信息学报,2017,31(5):138-145.
[14] FERREIRA R,CANESCHE M,JAMIESON P,et al. Examples and Tutorials on Using Google Colab and Gradio to Create Online Interactive Student-learning Modules [J].Computer Applications in Engineering Education,2024,32(4):e22729.
作者简介:易云恒(1998—),男,汉族,四川达州人,专职教师,硕士,研究方向:自然语言处理;通信作者:潘济(1998—),女,汉族,辽宁葫芦岛人,专职教师,硕士,研究方向:计算机本科教学。
收稿日期:2024-06-15
基金项目:四川省教育信息技术研究课题(kt202309286459124);西南交通大学希望学院2023年党建研究项目(19)