

摘" 要:针对实验教学课堂学生学习效果难以监测等问题,将SE注意力机制和改进的空间金字塔池化引入YOLOv5,设计了一款基于实验室低画质视频的学生表情检测系统,实现了对实验课堂中学生面部表情的高精度识别。实验结果表明,添加SE注意力机制模块后,模型识别精度达到89%;再添加改进的金字塔池化后,模型识别精度达到94%。系统将深度学习技术与实验室课堂教学质量评估实践相结合,创新了实验教学课堂质量评价模式,可以为教师调整实验课堂教学模式提供参考依据。
关键词:低画质视频;表情检测;YOLOv5;注意力机制;空间金字塔池化
中图分类号:TP311" 文献标识码:A 文章编号:2096-4706(2024)11-0106-05
Design and Implementation of a Student Expression Detection System in Experimental Teaching Classroom
WU Bin
(College of Mathematics and Computer Science, Zhejiang Aamp;F University, Hangzhou" 311300, China)
Abstract: In response to the difficulty in monitoring the learning effectiveness of students in experimental teaching classrooms, the SE Attention Mechanism and improved spatial pyramid pooling are introduced into YOLOv5. A student expression detection system based on low-quality laboratory videos is designed, achieving high-precision recognition of facial expressions of students in experimental classrooms. The experimental results show that after adding the SE Attention Mechanism module, the recognition accuracy of the model reaches 89%. After adding improved pyramid pooling, the model recognition accuracy reaches 94%. The system combines Deep Learning technology with laboratory classroom teaching quality evaluation practice, innovates the experimental teaching classroom quality evaluation mode, and can provide reference basis for teachers to adjust the experimental classroom teaching mode.
Keywords: low-quality video; expression detection; YOLOv5; Attention Mechanism; spatial pyramid pooling
0" 引" 言
面部表情识别技术[1]适用于心理研究、驾驶员疲劳监测、学生课堂状态检测、残疾人情绪检测等各种应用场景,已经融入现实生活,为人们提供了各种便利。学生课堂状态是教育教学质量评价一环中重要的一层,基于网络摄像头数据的学生面部表情识别方法可以用于学生课堂状态检测。但网络摄像头获取的数据画质不够清晰,利用传统算法很难对低画质视频进行学生面部表情检测。
YOLO是基于卷积神经网络的典型目标检测模型,该算法将目标检测当作回归问题来解决,直接从特征提取阶段获得检测框边界和类别概率[2,3]。在目标检测领域,YOLO检测展示出较高的精确度和识别速度,已成为应用最为广泛的检测模型和主流框架[3,4]。在该应用领域,Junos等先后开发了一种精度高、计算成本低、模型轻量级的自动检测系统[5,6]。YOLOv5是YOLO系列算法中的一个重要版本,唐强等采用YOLOv5检测识别技术对人脸、表情、身体姿态等数据进行了识别、分类与统计[7-10],其研究成果可为数字化课堂评价提供可靠依据[7]。
本文在相关学者研究成果基础上,设计了一种添加注意力机制并改进空间金字塔池化的YOLOv5算法,通过PyCharm把改进的YOLOv5模型打包到实验课堂学生表情监测系统中,实现低画质视频学生面部表情检测,旨在扩展实验课堂教学质量监测的维度,并推动相关教学工作开展。
1" 数据获取与处理
1.1" 表情选取
实验课堂学生面部特征有以下几种表情要素:眉毛、眼神、面部朝向、嘴巴、牙齿。对应眉头紧皱、眼神坚定、双目无神、面朝屏幕(或教师或黑板)、嘴巴上下大张、嘴巴微张。鉴于网络摄像头视频成像质量较差、机房设备遮挡面部等不利情况,以上这些表情特征无法全部应用于表情识别过程。因此,本次研究仅建立三类表情模型:1)严肃(Seriously),此类学生精神状态较好,上课听课效率高,紧跟老师的课堂内容。2)瞌睡(Sleepy),此类学生表现为较为明显的瞌睡、打哈欠状态,精神状态较差,昏昏欲睡。3)张嘴(Open mouth),正常教学过程中,一般不允许学生私下交流扰乱课堂纪律,此类说笑均为不认真听讲表现。
1.2" 数据处理
本次需自建数据集作为模型训练的样本,数据来源于浙江农林大学信息技术实验教学中心网络摄像头视频,并划分为训练集、验证集和测试集。数据处理过程如下:按视频帧序列进行1 000帧一提取并保存备用。在低成像质量条件下,为保证训练模型精度,本文采用图像清晰度增强、图像修复等方式完善样本。调用百度人工智能服务平台的图像恢复和图像清晰度增强算法API,对600张图像逐张增强,图像清晰度得到较为显著的提高,展示出更多学生面部的细节特征。
利用开源工具LabelImg对数据集进行标注。为提高识别精确度及模型识别稳定性,采用Python脚本进行图像增强,扩大样本量(标签对应变换)。增强方式为概率增强,内容包括对比度变换、翻转、镜像、锐化、像素丢失。增强倍数为5倍,共获得3 000张png格式的图像和对应的3 000个标签文件。
2" 算法改进与系统搭建
2.1" YOLOv5版本选择
YOLOv5增加了Focus和SPP结构[11],在图像输入时进行Mosaic数据增强操作,并在推理时采用自适应缩放操作。同时,还设计了位于网络最前端的Focus结构,该结构最主要的内容是对输入数据进行切片操作,可有效提升图片特征提取的质量[12]。在输出端,YOLOv5使用GIoU_Loss作为Bounding Box的损失函数,在进行非最大值抑制时使用加权非最大值抑制,在不增加计算资源的情况下,对检测图像中一些有重叠的目标检测效果较好[13]。YOLOv5有YOLOv5s、YOLOv5m、YOLOv5x、YOLOv5l四个版本,更换不同yaml文件即可切换版本。YOLOv5模型的深度和广度可仅用depth_multiple和width_multiple两个参数来控制,四种模型的yaml文件只有这两个参数不同[13],但最终的训练模型差异却非常大,其中YOLOv5s训练后的模型最小,仅十几兆大小,并能保持检测速度和精度,故本次使用版本为YOLOv5s。
2.2" SE注意力机制
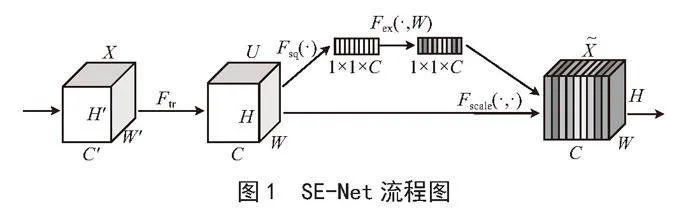
注意力机制[14]在人类世界可以理解为注意力集中或者视觉集中;但在计算机领域,深度学习中的注意力机制可以被广义地解释为表示特征重要性的权重向量[15]。为了预测或者推断某个元素,例如图片中的一个像素,或者句子中的一个单词,我们使用注意力向量估计它与其他元素的相关性有多强,并将它们的值与注意力向量加权之后的值之和作为目标的近似值[16]。深度学习中的注意力机制通常可分为三类:软注意(全局注意)、硬注意(局部注意)和自注意(内注意)[17,18]。许多软注意力模块不会改变输出尺寸,可以灵活插入到卷积网络的各个部分,但会增加训练参数导致计算成本提高。随着越来越多模块开始注重参数量和精度的平衡,很多轻量型注意模块也随之被提出,如SE.Net、CA、CBAM、ECA-Net等。SE-Net(Squeeze-and-Excitation Network)[19]考虑了特征通道之间的关系,通过学习的方式判断每个特征通道的影响强度,并利用得到的重要程度设置权重,来区分各特征对于识别精度的重要程度,本次研究引入SE注意力机制。SE-Net流程图[19]如图1所示。
2.3" 空间金字塔池化改进
2.3.1" SPP模块
由于CNN网络后面接的全连接层需要固定的输入大小,故往往通过将输入图像Resize到固定大小的方式输入卷积网络,这会造成几何失真影响精度[20]。SPP(Spatial Pyramid Pooling)模块运用三种不同尺度的池化技术,将各种大小的特征图转化为长度相等的特征向量,并将其传输至全连接层,从而成功解决了失真问题,继而可以避免由于特征提取不足导致网络性能下降等情况发生。
2.3.2" SPPF模块
SPPF(Spatial Pyramid Pooling-Fast)是基于SPP提出的,从形状来说SPP和SPPF的目的是相同的,只是结构上略有差异,从SPP改进为SPPF后模型的计算量变小了很多,模型速度提升[21-23]。
2.3.3" ASPP模块
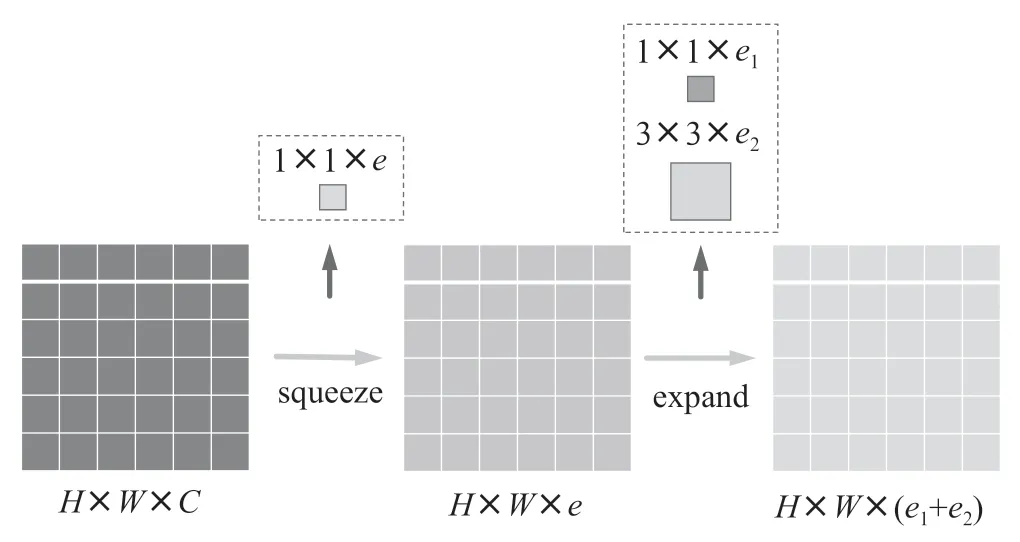
ASPP(Atrous/Dilated Convolution)[24]是由空洞卷积组成。该模块采用多个并行的空洞卷积层,卷积层采样率各异。为了获得高质量的图像细节,对这些采样进行优化和分割来形成一个或更多个分支。对于每个采样率所提取的特征,ASPP将在独立的分支中进行进一步的处理和融合,以生成最终的结果[25]。该模块运用不同的空腔rate来构建卷积核,以获取多尺度物体信息的不同感受野,从而实现多尺度物体信息的获取。
2.3.4" SPPFCSPC模型
在最新版的YOLOv7中使用的结构为SPPCSPC,其表现优于原本的PPF,但是参数量和计算量都提升了很多。在本文中借鉴SPPCSPC模型,结合SPP模型将其优化得到SPPFCSPC模型,在保持感受野不变的情况下获得速度提升[26],并且将其应用于YOLOv5版本。
2.3.5" RFB模块
RFB(Receptive Field Block)模块的出发点是模拟人类视觉的感受野从而加强网络的特征提取能力[27],在结构上RFB借鉴了Inception的思想,主要是在Inception的基础上加入了空洞卷积,从而有效增大了感受野[28]。
2.3.6" SIMSPPF模块
SIMSPPF(Simplified SPPF)为YOLOv6中提出的模块[29],与v5版本内的SPPF仅相差一个激活函数。本文将其借鉴到YOLOv5版本内。
2.4" 系统实现
改进的YOLOv5模型训练好后,对其进行封装,通过PyCharm把改进模型应用到学生表情检测系统中,实现实验教学课堂学生表情的智能检测。
3" 结果分析与评价
系统建成后,通过分类识别精度、总检测精度(P)、平均识别精度(mAP0.5)、模型实测精度等几个维度评价模型质量。
3.1" YOLOv5_SE模型评价
3.1.1" 精度变化曲线
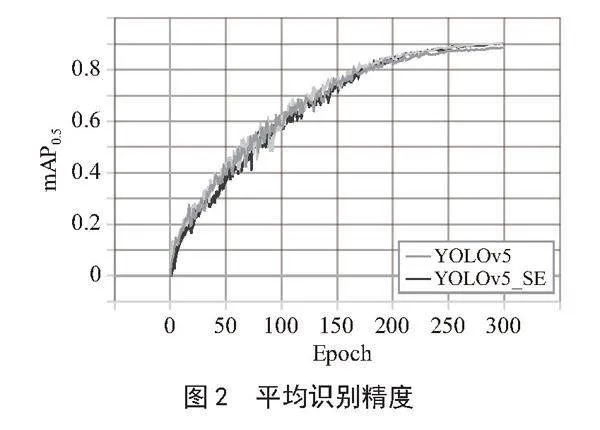
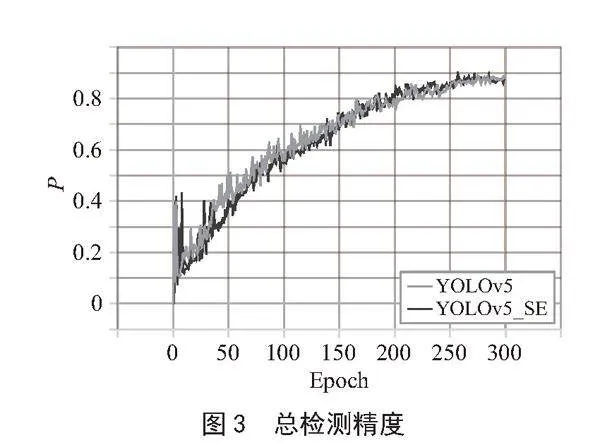
改进算法模型YOLOv5_SE和原始模型YOLOv5的平均识别精度(mAP0.5)和总检测精度(P)如图2、图3所示。
模型改进后mAP0.5提高了1.7%,P提高了0.5%。YOLOv5_SE在前期训练过程中精度上涨较为缓慢,但随着训练轮数Epoch的增长,YOLOv5_SE平均精度大于原模型平均精度。
3.1.2" 分类识别精度
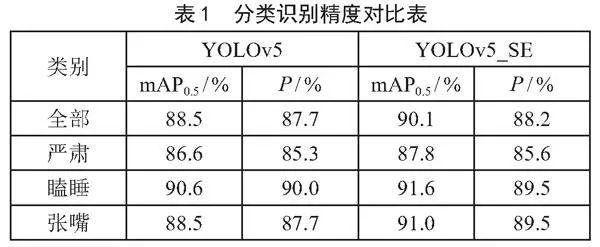
结合SE注意力机制后,总识别精度从87.7%上涨到88.2%,各类别识别精度均有上涨,其中,“严肃”上涨1.3%、“瞌睡”上涨1.1%、“张嘴”上涨2.8%,如表1所示。
3.1.3" 实测精度
通过实测,利用YOLOv5_SE模型,系统能较好识别出学生表情,精度达到89%,如表2所示。
3.2" 空间金字塔池化改进后评价
3.2.1" 精度变化曲线
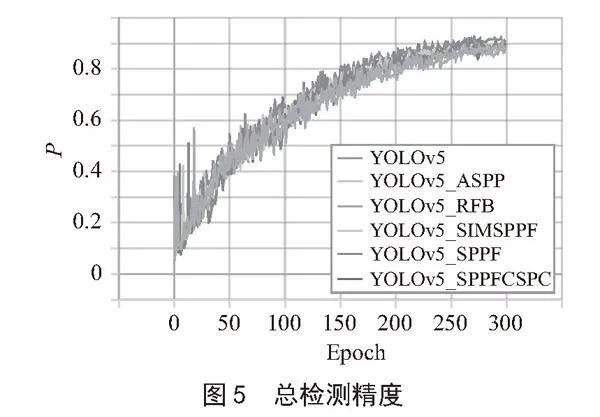
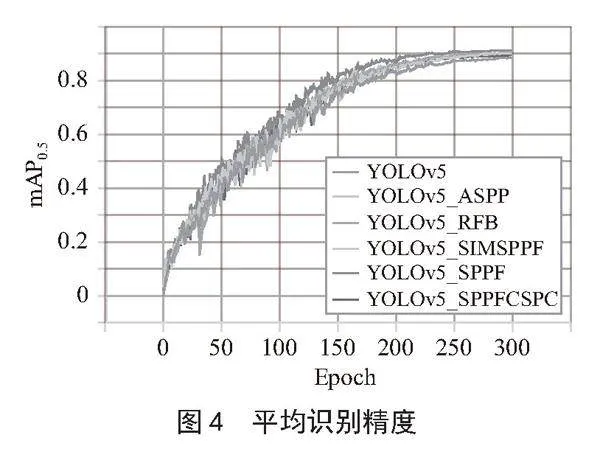
原模型曲线命名为YOLOv5,其他按照所添加模块命名,分别为YOLOv5_SPPF、YOLOv5_ASPP、YOLOv5_SPPFCSPC、YOLOv5_RFB,以及YOLOv5_SIMSPPF,各模型的mAP0.5和P分别如图4、图5所示。
识别精度由大到小排序为YOLOv5_SPPF、YOLOv5_RFB、YOLOv5_SIMSPPF、YOLOv5_ASPP、YOLOv5_SPPFCSPC、YOLOv5,六种空间金字塔池化改进方法均使模型精确度得到提高,其中效果最为明显的改进方法为SPPF,mAP0.5增长2.95%。
3.2.2" 分类识别精度
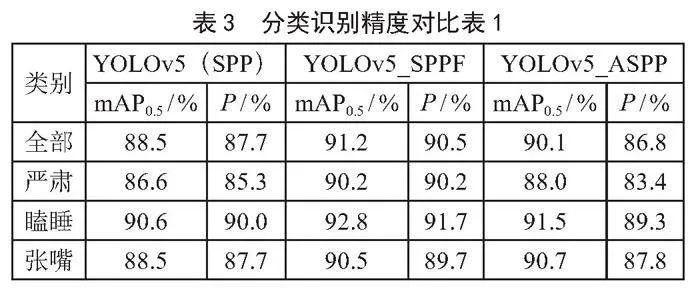
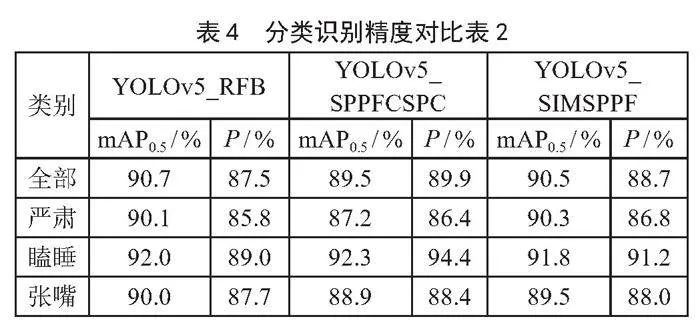
分类识别精度如表3、表4所示,对比可知SPPF算法模型在各类别中均有最高的精度,纵向对比可知在三种类别中“瞌睡”识别精度最高。
3.2.3" 实测精度
通过实测,添加SPPF模块后,系统精度得到进一步提升,达到94%,如表5所示,识别效果示意图如图6所示。
4" 结" 论
本文设计了一种基于改进YOLOv5算法的学生表情检测系统,利用实验课堂网络视频对学生面部表情进行识别。针对影像成像质量差、面部遮挡、摄像头角度单一等影响识别的问题,给出了基于YOLOv5的模型改进方案,并对各方案的识别精度进行了对比。引入改进模型的系统对学生面部表情的识别精度得到提高、性能更加稳定,可更好地辅助教师判断学生的上课状态,提高实验教学效率。此外,在识别过程中,由于教室后排位置分辨率较低,存在人脸识别率不够高、漏检的情况;另外,部分同学的表情未在识别范围内,划分的表情类别不够完善,因此,系统的识别效率还存在一定的提升空间,需要建立更加完备、实际应用价值更高的表情识别模型。
参考文献:
[1] RAJAN S,CHENNIAPPAN P,DEVARAJ S,et al. Facial Expression Recognition Techniques: a Comprehensive Survey [J].IET Image Processing,2019,13(7):1031-1040.
[2] NAZIR A,WANI M A. You Only Look Once - Object Detection Models: A Review [J].2023 10th International Conference on Computing for Sustainable Global Development(INDIACom).New Delhi:IEEE,2023:1088-1095.
[3] 刘芳,刘玉坤,林森,等.基于改进型YOLO的复杂环境下番茄果实快速识别方法 [J].农业机械学报,2020,51(6):229-237.
[4] 邵延华,张铎,楚红雨,等.基于深度学习的YOLO目标检测综述 [J].电子与信息学报,2022,44(10):3697-3708.
[5] JUNOS M H,KHAIRUDDIN A S M,THANNIRMALAI S,et al. An optimized YOLO - Based Object Detection Model for Crop Harvesting System [J].IET Image Processing,2021,15(2):2112-2125.
[6] LAROCA R,ZANLORENSI L A,GONALVES G R,et al. An Efficient and Layout - Independent Automatic License Plate Recognition System Based on the YOLO Detector [J].IET Intelligent Transport Systems,2021,15(4):483-503.
[7] 唐强,张璐平,夏志远,等.表情识别在课堂教学评价中的应用研究 [J].现代信息科技,2022,6(20):191-195.
[8] 万士宁.基于卷积神经网络的人脸识别研究与实现 [D].成都:电子科技大学,2016.
[9] 孙廨尧,李秀茹,王松林.基于改进YOLOv5的学生面部表情识别 [J].齐鲁工业大学学报,2023,37(1):28-35.
[10] 张波,兰艳亭,李大威,等.基于卷积网络通道注意力的人脸表情识别 [J].无线电工程,2022,52(1):148-153.
[11] 李洵,甘润东,钱俊凤,等.改进YOLOv5混合样本训练的绝缘子伞盘脱落缺陷检测方法 [J].计算机工程与应用,2024,60(4):289-297.
[12] 陈征,刘长龙,张乐,等.一种用于海上平台缆控注水井的多类型指针式仪表识别方法 [J].系统仿真技术,2022,18(2):103-108.
[13] 唐武.基于深度学习的户外盲道障碍目标检测与跟踪研究 [D].赣州:江西理工大学,2021.
[14] 袁超,王宏霞,何沛松.基于注意力机制的高容量通用图像隐写模型 [J].软件学报,2024,35(3):1502-1514.
[15] 朱丽,王新鹏,付海涛,等.基于注意力机制的细粒度图像分类 [J].吉林大学学报:理学版,2023,61(2):371-376.
[16] 张元昊.基于审议机制的视频描述方法研究 [D].北京:北京交通大学,2020.
[17] 任欢,王旭光.注意力机制综述 [J].计算机应用,2021,41(S1):1-6.
[18] 黄思佳.面向短文本的特征选择方法研究 [D].长春:长春工业大学,2022.
[19] HU J,SHEN L,ALBANIE S,et al. Squeeze-and-Excitation Networks [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2020,42(8):2011-2023.
[20] 梅礼晔,郭晓鹏,张俊华,等.基于空间金字塔池化的深度卷积神经网络多聚焦图像融合 [J].云南大学学报:自然科学版,2019,41(1):18-27.
[21] 于春和,鄂美玉.基于改进YOLOv3-tiny的工地行人检测 [J].电脑与信息技术,2022,30(4):5-7.
[22] 张秋雁,朱傥,肖书舟,等.基于改进YOLOv4算法的高压输电线路异物检测 [J].应用科技,2023,50(4):59-65.
[23] 徐红牛,余华云.基于改进YOLO模型的工业铝片缺陷检测 [J].组合机床与自动化加工技术,2023(9):106-111.
[24] 候少麒,梁杰,殷康宁,等.基于空洞卷积金字塔的目标检测算法 [J].电子科技大学学报,2021,50(6):843-851.
[25] 翟雨.单目机器人路标模型地图的研究与实现 [D].上海:上海交通大学,2019.
[26] 凡宁宁,刘爽,刘佳,等.基于改进YOLOv5s的饰品检测算法研究 [J].大连民族大学学报,2023,25(5):437-443.
[27] LIU S T,HUANG D,WANG Y H. Receptive Field Block Net for Accurate and Fast Object Detection [C]//Computer Vision – ECCV 2018.Munich:Springer,2018:404-419.
[28] 赵永强,饶元,董世鹏,等.深度学习目标检测方法综述 [J].中国图象图形学报,2020,25(4):629-654.
[29] HU H B,ZHU Z H. Sim-YOLOv5s: A Method for Detecting Defects on the End Face of Lithium Battery Steel Shells [J/OL].Advanced engineering informatics,2023,55101824[2024.03-26].https://doi.org/10.1016/j.aei.2022.101824.
作者简介:吴斌(1984—),男,汉族,江西九江人,工程师,信息技术实验教学中心主任助理,硕士研究生,研究方向:人工智能、图像识别与遥感技术应用。
收稿日期:2024-04-20
基金项目:浙江省教育厅科研资助项目(Y202250093);浙江农林大学科研发展基金项目(2023LFR147)