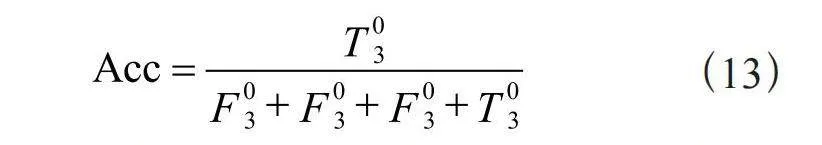
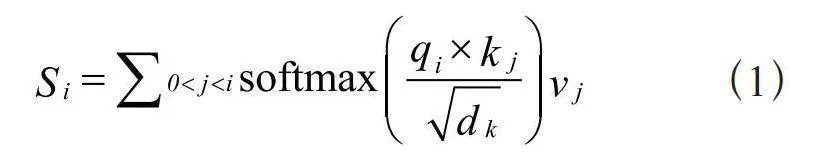
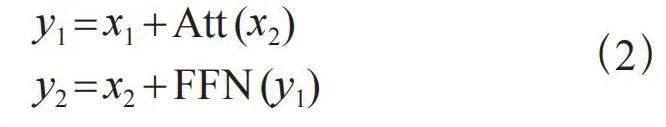
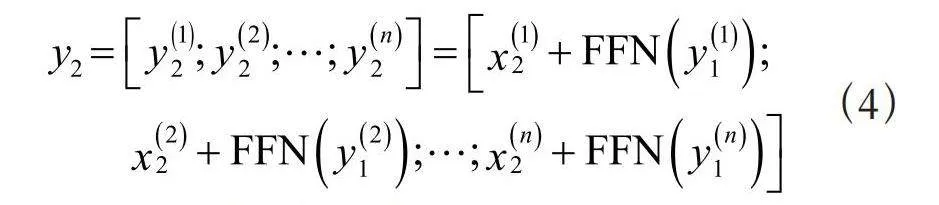


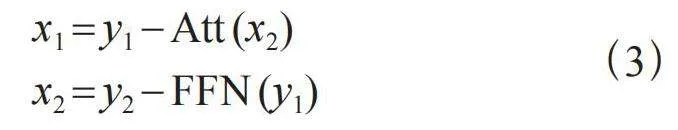
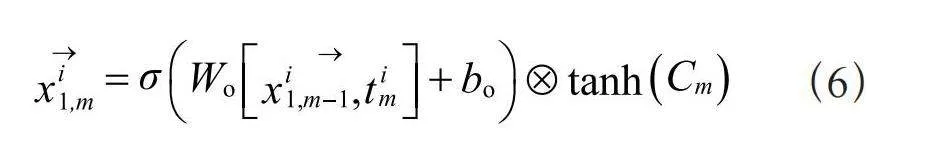
摘" 要:面向bilibili短视频评论数据的情感分析,旨在挖掘视频观看者对短视频的看法,使视频作者也可以快速得到自己想要的评价,进而对后续作品做出改进。针对短视频评论更新快、词汇新颖、评论过长、一词多义等因素造成的短视频评论情感分析准确率低的问题,文章构建了bilibili短视频评论数据集,并提出了ELMO(Embedding From Language Model)用以构建动态词向量解决一词多义及新词的问题,通过构建TextCNN和Reformer双通道神经网络结构来提取局部、全局特征。由于Reformer采用了局部敏感哈希的特殊注意力机制,更能联系全局特征,之后将两者得到的结果拼接送入分类器得出情感分析的结果,并将得出的结果与多个深度学习模型进行对比。
关键词:情感分析;ELMO;双通道;短视频;注意力机制
中图分类号:TP391" 文献标识码:A" 文章编号:2096-4706(2024)12-0146-06
Sentiment Analysis of bilibili Comment Based on ELMO-TextCNN-Reformer
ZENG Mengjia1,2,3, GUO Weiqiang1, HUANG Xu1,2,3
(1.School of Information Engineering, Huzhou University, Huzhou" 313000, China; 2.School of Electronic Information,
Huzhou College, Huzhou" 313000, China; 3.Huzhou Key Laboratory of Urban Multidimensional Perception and Intelligent Computing, Huzhou" 313000, China)
Abstract: Sentiment analysis of bilibili short video comment data aims to explore viewers opinions on short videos, enabling video creators to quickly obtain the feedback they desire and improve their subsequent works. In response to the low accuracy of sentiment analysis in short video comments caused by factors such as fast updates, novel vocabulary, long comments, and polysemy, this paper constructs the bilibili short video comment dataset and proposes ELMO (Embedding From Language Model) to construct dynamic word vectors to solve the problem of polysemy and new words. Local and global features are extracted by constructing a TextCNN and Transformer dual-channel neural network structure. Due to the use of a special attention mechanism with locally sensitive hashing in the Transformer, it can better connect global features. Then, the results obtained from both are concatenated and fed into the classifier to obtain the results of sentiment analysis, and the results obtained are compared with multiple Deep Learning models.
Keywords: Sentiment Analysis; ELMO; dual-channel; short video; Attention Mechanism
0" 引" 言
《2023中国网络视听发展研究报告》显示,截至2022年12月,我国网络视听用户规模达10.40亿[1],超过即时通信(10.38亿),成为第一大互联网应用。近年来,互联网与短视频的迅速发展使诸多短视频软件(如bilibili短视频、抖音短视频、快手短视频等)拥有庞大的用户量。随着众多短视频创作者陆续发布短视频作品,用户对短视频的评论也扑面而来,这使短视频平台产生大量的评论数据。在短视频评论的情感分析中发现,短视频的评论数据中很容易出现黑词、新词等新颖难懂的词汇,这与短视频的流行与超前不无关系,也会出现评论过短特征不足难以提供情感语义信息,或是评论过长难以提取上下文特征的问题。同时短视频的内容也是五花八门的,从书本阅读、街谈美食到国家政事、外星探索,包罗万象,相应地所产生的评论也是千汇万状,不少评论还会一词多义,同时对数据的标注也是一项烦琐耗时的工作。因此本文提出ELMO解决短视频评论中新词、一词多义等问题[2],即利用双向BiLSTM获取bilibili短视频评论数据集中句子的语法特征及词特征,进而得到动态的词向量以判别一个词语在不同语境中的确切意思。针对下游任务中因单个模型而导致的特征提取不足的问题,本文提出了TextCNN-Reformer的双通道神经网络,通过拼接TextCNN与Reformer获取文本全面的特征,最后输入到分类器中实现情感的分析。
1" 相关工作
Kim等[3]设计一种针对文本处理优化过的CNN模型——TextCNN [4]。此模型通过调整嵌入层来适配文本数据,但仍然面临无法有效捕获全局特征的挑战。随后,LSTM网络[5]被引入,它克服了传统RNN的长期依赖问题和梯度消失的困扰。Graves等[6]进一步发展了BiLSTM,它通过结合前向和后向LSTM层,提高了模型对上下文文本信息的推理能力。谷歌的研究者们引入了Transformer [7],这是一个基于自注意力机制的模型,尽管它仍然面临着结构复杂和训练缓慢的问题,但它解除了RNN的并行计算限制[8],尤其在情感分析任务中表现得更加优异。为了应对这些挑战,Kitaev等[9]对Transformer进行改进,提出了Reformer模型,这是一个可以更加高效地处理长文本的模型,虽然它在局部特征学习方面还存在一些不足,但它减少了内存使用,提升了训练速度。另外,尽管静态词向量技术(如Word2Vec [10]和GloVe [11])已经广泛应用,但它们在处理短视频评论中多义词和新词的适应性仍有不足。
综上所述,现阶段对短视频评论的情感分析还是存在准确率低下、对多义词和新词难以适应、局部特征提取速度受限等诸多问题,为此本文提出一种基于双通道模型及动态词向量的短视频评论情感分析,旨在有效提高预测准确率。
2" ELMO与双通道模型
2.1" ELMO模型
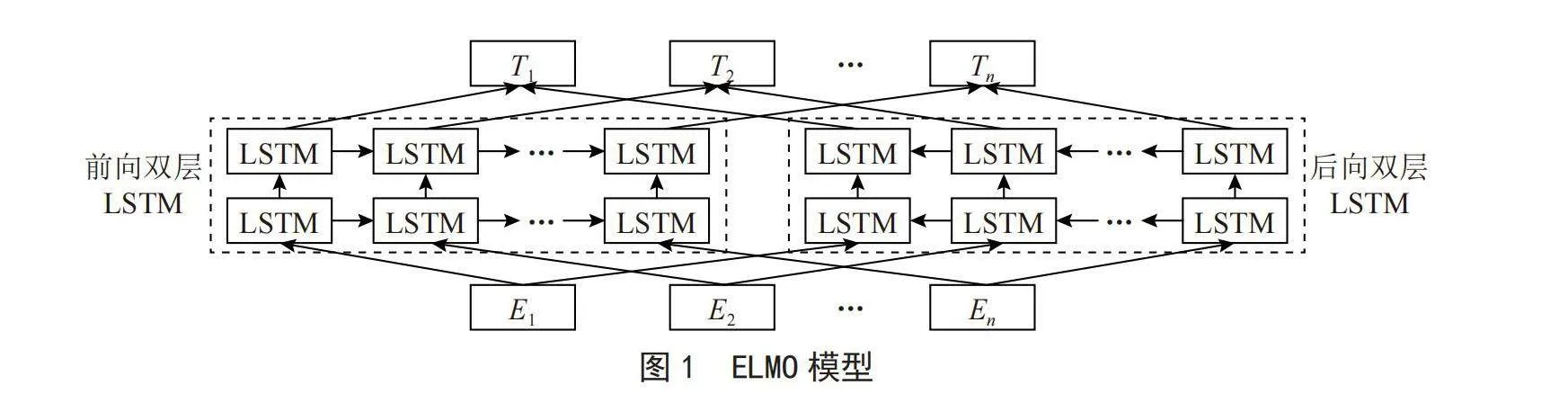
词嵌入技术是自然语言处理领域一种用来表征单词的流行方法。起初,人们使用独热编码,后来发展为通过神经网络语言模型获得分布式词向量。这些方法通常都是静态的,比如Word2Vec,它为每个单词分配一个固定的向量,而不考虑上下文。这意味着无论上下文如何变化,每个词的向量表示都保持不变,导致出现无法有效处理多义词的情况。ELMO是一种双层双向的LSTM结构,它包含一个向前和一个向后的LSTM,这两个LSTM分别通过计算给定前序上下文当前词的概率和给定后续上下文当前词的概率进行训练。前向LSTM预测序列中每个词的概率依赖于它之前的词,而后向LSTMLSTM预测序列中每个词的概率则依赖于它之后的词。ELMO结构如图1所示,ELMO模型的核心组成部分是将文本数据转换成词向量的“E”。通过在庞大的文本数据集上实施训练,可以得到一个经过预训练的ELMO模型。通过ELMO获得动态词向量就可以把这些词向量送入下游任务进行训练了。
2.2" TextCNN模型
TextCNN模型结构如图2所示,包括以下四大部分:
1)嵌入层(Embedding)。该层的主要功能是将文本转化为向量,以便计算机可以进行处理。通常是采用训练好的词向量模型(比如Word2Vec或GloVe)来完成,它能够把单词转换成对应的向量表示,也可以将ELMO的动态词向量当作嵌入层输入。
2)卷积层(Convolutional Layer)。TextCNN中的一个关键部分是卷积层,它利用各种尺寸的过滤器对输入的词向量序列执行滑动窗口的卷积。每个过滤器负责从其窗口范围内抽取特定的局部特征。通过结合多个这样的过滤器,系统能够识别和提取不同长度的局部文字特性。
3)池化层(Pooling Layer)。池化层在卷积层之后对特征集进行下采样,并且保留了最突出的特征。常用的技术包括最大池化和平均池化,最大池化是指从每个卷积核的输出中取最大值,平均池化是指计算输出的平均值,这样可以减少特征向量的大小。
4)全连接层(Fully Connected Layer)。全连接层作为神经网络的一部分,负责处理池化层传来的特征向量。它是由众多相互连接的神经元构成的,每个神经元都与前层所有的神经元相连接,并将这些信息映射到输出类别上。在网络的最终阶段,可以采用Softmax激活函数来实现多类别的分类。
2.3" Reformer模型
Reformer模型的提出解决了原始Transformer在处理长文本时内存占用过大和训练缓慢的问题,在改善其结构的同时令其拥有不逊于Transformer的性能。Reformer保留了Transformer的编码器-解码器结构,其中包括注意力机制(Attention)和前馈网络。但它在三个关键方面进行了创新:
1)采用局部敏感哈希注意力机制(LSH Attention)替代传统的点乘注意力。点乘注意力机制的表达式为:
(1)
而局部敏感哈希注意力机制与传统注意力机制相类似,采用了局部敏感哈希算法,去掉了查询向量q,并以键向量k的函数来替代原来的注意力权重,从而创建一种新型的局部敏感哈希注意力机制。
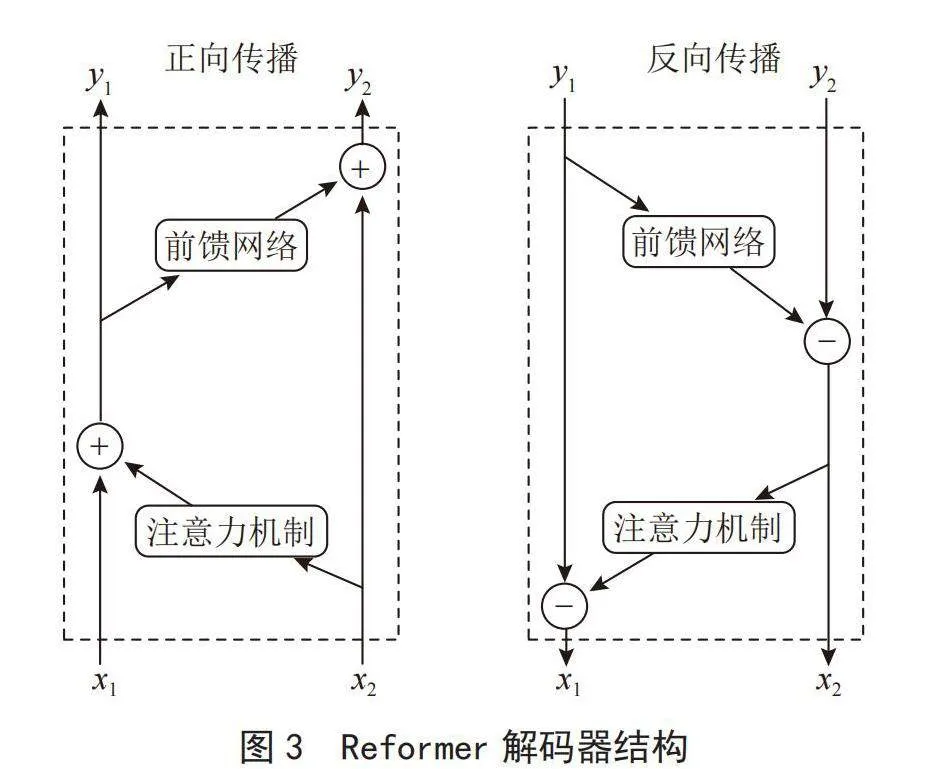
2)引入可逆残差网络替代标准残差网络,通过在编码器与解码器中使用可逆残差网络,可实现训练时只在编码器或解码器的首层保存一次激活即可,这样大幅减少了内存使用,其解码器结构如图3所示。
假设前馈网络和注意力机制分别为FFN和Att,通过图3可看出在正向传播时,
(2)
在反向传播时,
(3)
所以,在采用了可逆残差网络的情况下训练时只需保存一次激活即可,这极大地降低了内存消耗。
3)使用了分块的前馈网络,在Transformer中前馈网络的输入是独立的,采用分块的前馈网络之后可以对不同块的前馈网络进行单独计算,每次只需计算一个,其计算式为:
(4)
其中,n为前馈网络块的数量。
这三大改进有助于提高处理效率和降低内存需求,且保留了Transformer强大的全局特征获取能力。
3" ELMO-TextCNN-Reformer模型
3.1" 词嵌入层
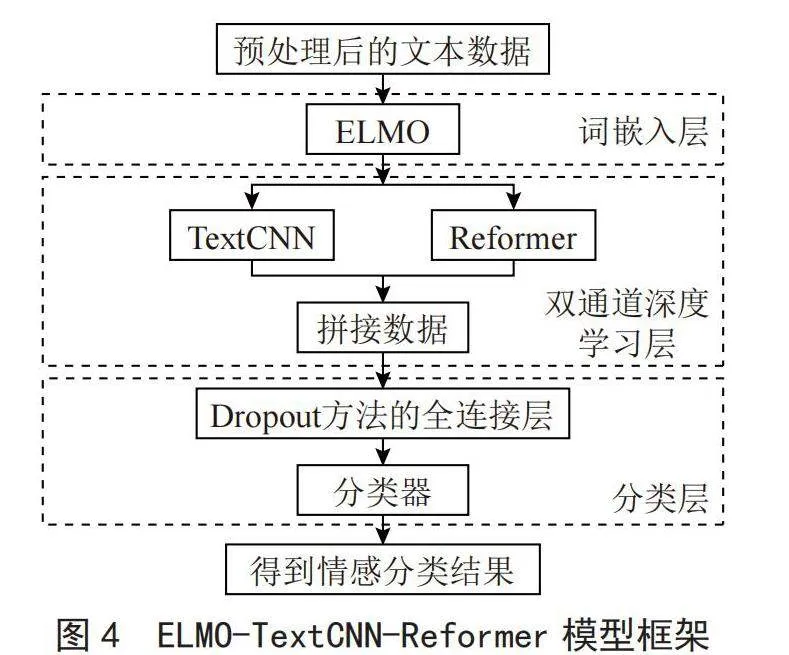
本文的模型结构图如图4所示,先对文本数据进行清理等预处理工作,再通过CharCNN构建初始化单词向量。
单词向量构建如式(5)所示:
(5)
其中,Ti中的i为文本数据中的第i条数据, 为第i条数据的第n个单词或字的词向量。接下来,这些词向量被送入一个双层双向的LSTM网络,每一层的LSTM单元被分成正向和反向两个部分,用以捕获每个单词的前文和后文信息。正向LSTM拥有双层LSTM结构,第一层的LSTM结构如式(6)所示:
(6)
其中,m为当前时刻,σ为sigmoid函数,WO为输出门的权重,bo为其偏置值, 为输入的词向量, 为LSTM第一层m时刻隐藏层的状态,Cm为m时刻的记忆信息,Cm的记忆信息可以由Cm-1通过遗忘门与输入门的权重及偏置值推出。
第二层的LSTM结构与第一层的LSTM结构相同,如式(7)所示:
(7)
其中的输入为第一层的 ,通过残差连接得到正向LSTM的词向量,如式(8)所示:
(8)
逆向LSTM与正向原理相同,其得到的逆向词向量同样如式(8)所示,最终,通过将词向量相结合可以获得ELMO的词表示,如式(9)所示。在这种情况下,即使是相同的单词,在不同的上下文中也可能承载有区分度甚至是完全相反的含义,以服务于后续的任务。
(9)
3.2" 双通道深度学习层
在大语料库中训练过的ELMO形成的动态词向量,分别当作TextCNN与Reformer的嵌入层输入。在TextCNN中,该卷积层使用四个不同尺寸的滤波器来提炼多层次的特征。同时,该层还应用ReLU函数作为其激活函数,以增强非线性特性。卷积层的构造如式(10)所示:
(10)
其中,f为ReLU的激活函数,Ch×w为高h和宽w的卷积核,高的取值为2、3、4、5,宽的取值对应于ELMO的词向量维度,b为偏置值, 为第i条数据第m到第m + h - 1个单词的ELMO词向量组成的矩阵,Ci为第i条数据从语序" 中提炼的特征图。
通过最大池化法对卷积后的特征进行降维,如式(11)所示:
(11)
其中,mi为第i条文本的特征最大池化层提取的特征向量。
经过双通道深度学习层之后,将训练后的特征进行拼接并输入到分类层中。
3.3" 分类层
将两个独立通道的特征数据合并,随后将这些合并后的数据传递给全连接层。为了解决过度拟合的问题,在全连接层之前加入Dropout方法。最后,运用Softmax函数对文本的情绪类别进行判定,计算式如式(12)所示:
(12)
其中,a和b分别为全连接层的权重和偏差,x为双通道合并后的向量,X为经过Dropout技术处理过的向量结果,Y为Softmax判别情感类型后的结果。
4" 实验测试
4.1" 数据集和实验环境
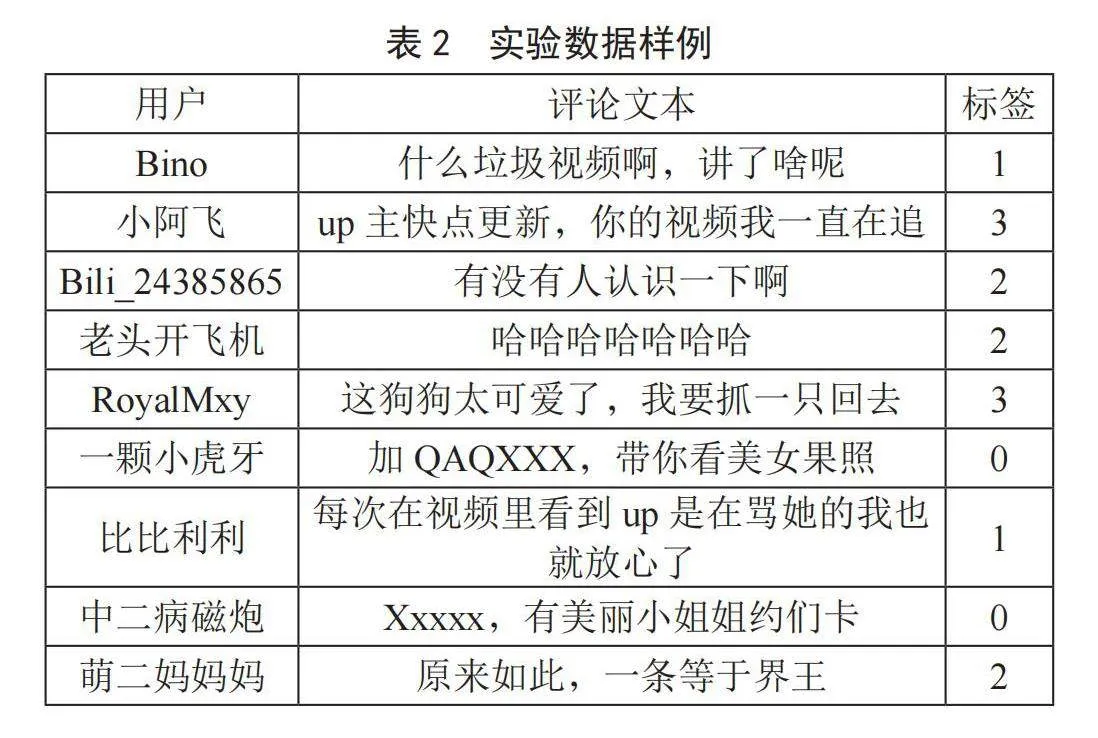
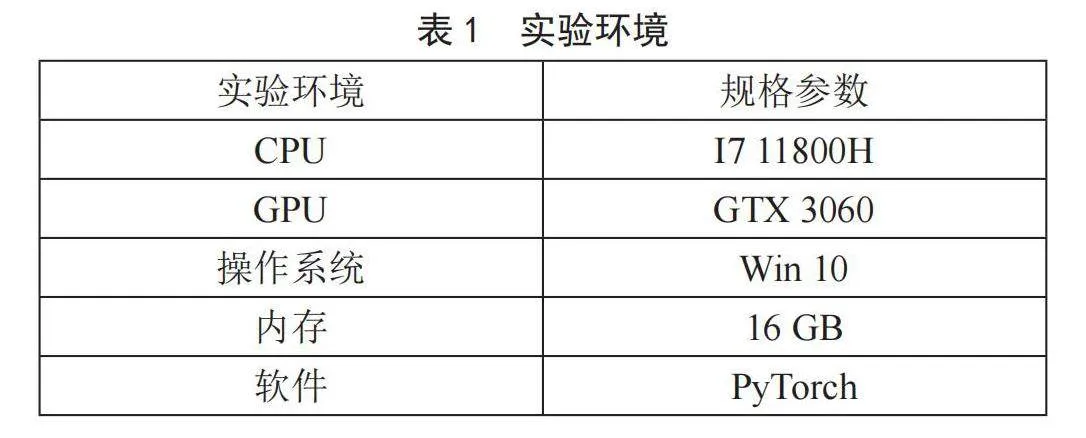
通过Python爬虫爬取bilibili近期各个板块热度高的短视频评论数据30 000条,其中训练集与测试集的比例为8:2,具体为24 000条训练数据和6 000条测试数据,实验环境如表1所示,实验文本数据如表2所示。
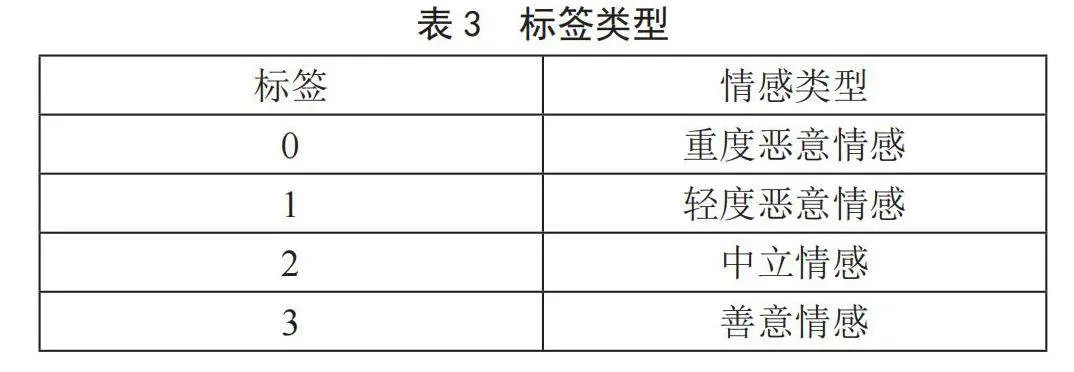
实验文本数据的标签类型如表3所示,本文将bilibili评论数据情感分为4大类,分别为重度恶意情感、轻度恶意情感、中立情感及善意情感,对数据进行清理以及进行jieba分词,利用ELMO将分词之后的文本转化为动态词向量分别输入到Reformer模型和TextCNN模型经过训练后,将结果合并并最终传入分类器进行情绪判定。
4.2" 实验参数设置
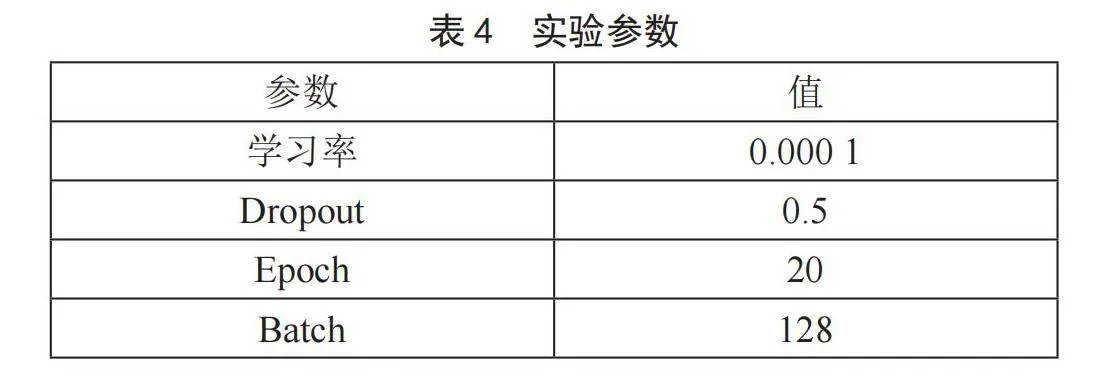
实验的参数设置如表4所示,本文将学习率设置为0.000 1,防止过拟合的Dropout值设置为0.5,词向量维度为300,迭代的次数为20,最大文本长度为128,对超过此长度的文本进行截断操作,在TextCNN中将卷积层卷积核尺寸设置为2、3、4,将Reformer中的哈希桶设置为10。
4.3" 评价参数
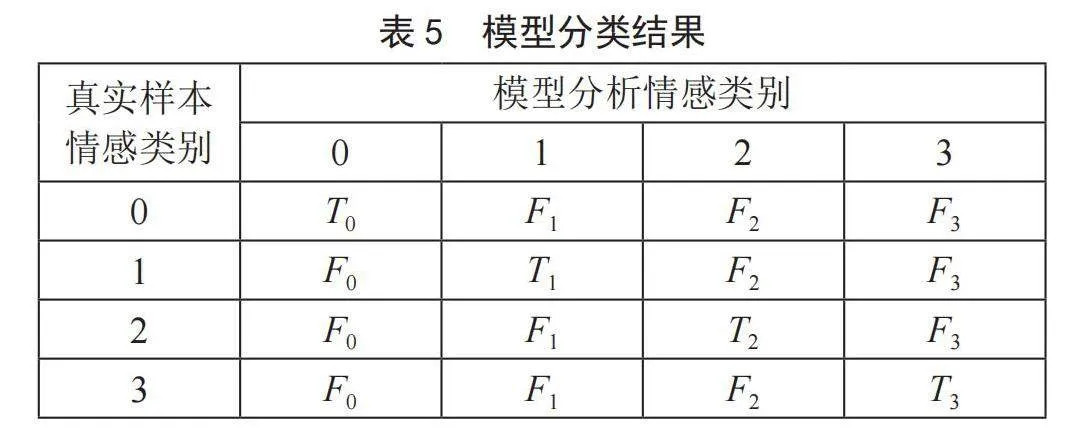
本文采用准确率Acc作为bilibili评论数据集情感分析的评论标准,对比多个模型的Acc值,Acc值更高的模型拥有更高的准确率,模型的分类结果如表5所示,Acc的计算式如式(13)所示:
(13)
其中, 为模型判别情感类型正确的4个相加, 为模型判别情感类型错误的相加。
4.4" 结果分析
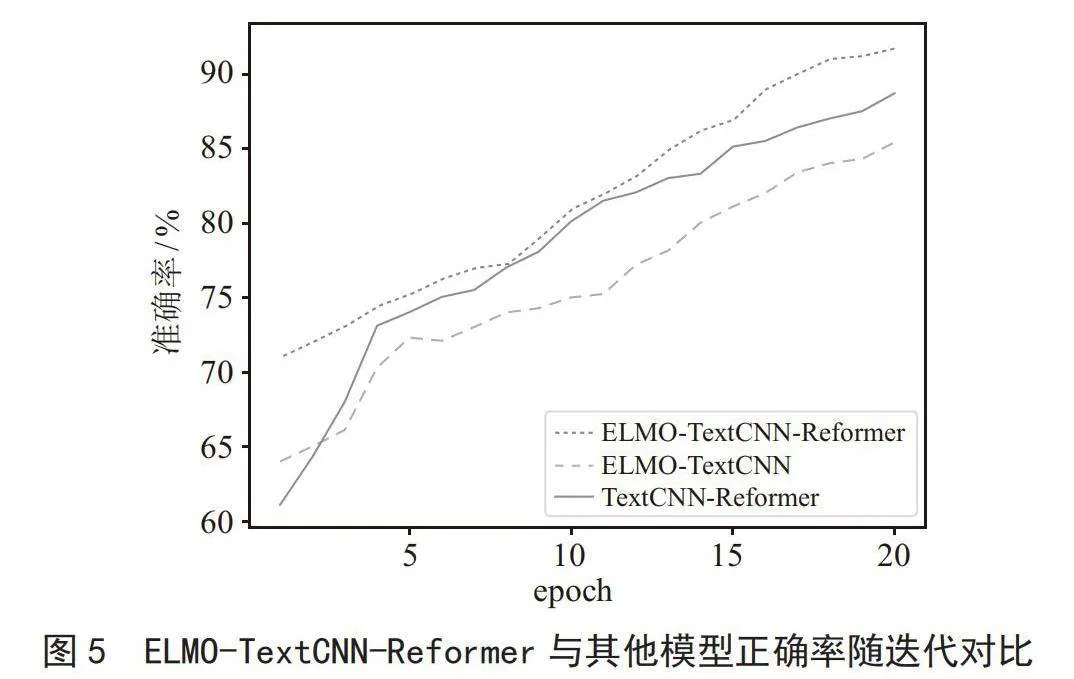
将ELMO-TextCNN-Reformer有预训练动态词向量的ELMO双通道模型与ELMO-TextCNN单通道模型以及TextCNN-Reformer没有经过预训练的双通道模型进行训练对比。如图5所示,经过多次实验,发现迭代次数超过20后准确率提升微乎其微,故将迭代次数设置为20。
从图5中可以看出,ELMO-TextCNN-Reformer模型在第一次训练之后就拥有了不错的准确率,其准确率为70%以上,并且迭代准确率随着迭代次数的增加而稳步上升,在前10次迭代训练中准确率上升得比较平稳,后10次迭代训练后准确率提升迅速,甚至为90%以上。ELMO-TextCNN虽然在第一次训练之后拥有比TextCNN-Reformer模型更高的准确率,为64.13%,但后续其准确率提升反而比较缓慢,ELMO-TextCNN对于特征提取不够全面,虽然有预训练模型的加持,但是准确率是三者之中最低的。TextCNN-Reformer双通道模型的初始准确率是最低的,但它却拥有良好的特征提取能力,虽然对于一些新颖、一词多义的句子准确率低,但是这些数据毕竟只占一小部分,所以总体上说其仍拥有不错的准确率。
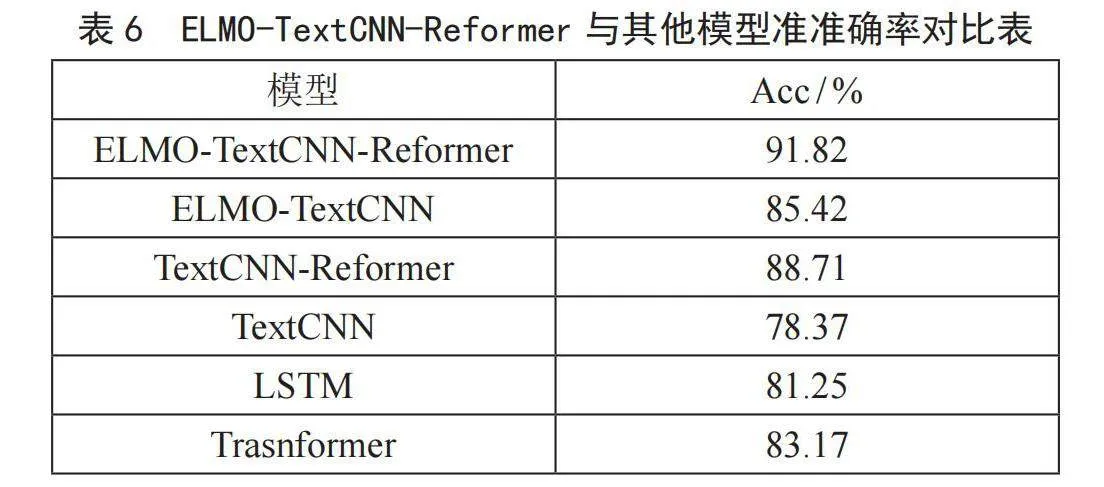
ELMO-TextCNN-Reformer与其他模型的准确率对比表如表6所示,从表6中可以看出ELMO-TextCNN-Reformer模型凭借91.82%的准确率表现最为突出,这表明模型的组合优化可能会对性能提升有显著的正面效应。其次,单独的TextCNN模型虽然最为基础,但准确率达到了78.37%,这为其他模型提供一个基线性能。而将TextCNN与Reformer结合使用时,性能提升到88.71%,显示出这两种架构的互补性。此外,单独的LSTM模型以81.25%的成绩超过了TextCNN。最后,Transformer模型的表现优于TextCNN和LSTM,达到了83.17%的准确率。这表明虽然Transformer架构在很多任务中有优异表现,但对于某些特定任务,结合了多种特性的模型可能会实现更优的性能。总之,ELMO-TextCNN-Reformer能够在bilibili评论数据集中拥有良好的准确率。
5" 结" 论
针对bilibili评论数据集文本长短不一,新词、黑词多,容易出现一词多义等情况,本文提出了动态词向量ELMO以及TextCNN-Reformer双通道模型,该模型相比传统模型准确率有一定的提升,证明了该方法对bilibili评论数据集情感分析的准确率提升是可行的。后续会把该方法应用到别的数据集中,测评其对其他数据集的影响,并继续深化算法,优化模型,以达到更好的效果。
参考文献:
[1] 边钰.我国网络视听用户规模达10.40亿 [N].四川日报,2023-03-30.
[2] PETERS M E,NEUMANN M,IYYER M,et al. Deep Contextualized Word Representations [J/OL].arXiv:1802.05365v1 [cs.CL].[2024-01-08].http://arxiv.org/abs/1802.05365v1.
[3] KIM Y. Convolutional Neural Networks for Sentence Classification [J/OL].arXiv:1408.5882v2 [cs.CL].[2024-01-16].http://arxiv.org/pdf/1408.5882.
[4] KALCHBRENNER N,GREFENSTETTE E,BLUNSOM P. A Convolutional Neural Network for Modelling Sentences [J/OL].arXiv:1404.2188v1 [cs.CL].[2024-01-09].http://arxiv.org/abs/1404.2188v1.
[5] HOCHREITER S,SCHMIDHUBER J. Long Short-Term Memory [J].Neural Computation,1997,9(8):1735-1780.
[6] GRAVES A,SCHMIDHUBER J. Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures [J].Neural Networks,2005,18(5/6):602-610.
[7] VASWANI A,SHAZEER N,PARMAR N,et al. Attention is All You Need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach:Curran Associates Inc,2017:6000-6010.
[8] IRSOY O,CARDIE C. Opinion Mining With Deep Recurrent Neural Networks [C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP).Doha:Association for Computational Linguistics,2014:720-728.
[9] KITAEV N,KAISER Ł,LEVSKAYA A. Reformer: The Efficient Transformer [J/OL].arXiv:2001.04451v1 [cs.LG].[2024-01-13].http://arxiv.org/abs/2001.04451v1.
[10] MIKOLOV T,SUTSKEVER I,CHEN K,et al. Distributed Representations of Words and Phrases and Their Compositionality [J/OL].arXiv:1310.4546v1 [cs.CL].[2024-01-14].http://arxiv.org/pdf/1310.4546.
[11] PENNINGTON J,SOCHER R,MANNING C. GloVe: Global Vectors for Word Representation [C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP).Doha:Association for Computational Linguistics,2014:1532-1543.
作者简介:曾孟佳(1980—),女,汉族,湖州荆州人,副教授,硕士研究生,研究方向:智能计算及其应用。