摘 要:图形用户界面成为用户与软件进行交互的必要方式之一。然而,随着软件规模和复杂性的增长,测试代价愈加高昂。基于OCR算法的文本控件识别方法引起了越来越多的关注,例如Sikuli通过OCR技术匹配窗口控件的文本,从屏幕上基于图像匹配来定位窗口控件。目前OCR引擎应用广泛,但是OCR算法通常运行缓慢,它们可能需要几秒钟的时间来识别GUI屏幕上的文本。文章介绍了一种快速的轻量级文本识别算法以加速OCR的文本识别过程。实验表明,在RICO数据集上,该算法降低了基于OCR的文本识别84%的平均时间。
中图分类号:TP311.5 文献标识码:A 文章编号:2096-4706(2024)14-0094-04
A Lightweight Text Recognition Algorithm for GUI Interface
MA Yingwei
(Nanjing University of Aeronautics and Astronautics, Nanjing 210016, China)
Abstract: Graphical User Interface (GUI) has become an essential way for users to interact with software. As the scale and complexity of software increase, the cost of testing also rises. Text control recognition methods based on OCR algorithms have attracted increasing attention. For example, Sikuli uses OCR technology to match the text of window widget, enabling the localization of window widget based on image matching on the screen. Currently, OCR engines are widely used. However, OCR algorithms often run slowly, and they may cost several seconds to recognize text on the GUI screen. The paper introduces a lightweight text recognition algorithm to accelerate the text recognition process of OCR. Experiments show that on the Rico data set, this algorithm reduces the average time for OCR-based text recognition by 84%.
Keywords: GUI testing; OCR; computer vision
DOI:10.19850/j.cnki.2096-4706.2024.14.019
0 引 言
近年来,基于光学字符识别[1](Optical Character Recognition, OCR)的文本识别方法[2]引起了越来越多的关注。常用工具如Sikuli [3]通过OCR匹配窗口控件的文本,从屏幕上视觉匹配它们的图像来实现GUI测试。有关基于OCR领域的GUI测试技术国内外学者已经做了大量研究。阿里巴巴开发了GUI逆向工程工具UI2CODE [4],该工具利用泛洪填充算法改进了非文本元素的检测。通过识别连接区域和过滤噪声,以及递归水平/垂直切片技术,可以获得GUI元素。此外,该工具还使用了OCR来检测GUI文本。Nguyen [5]等人提出的REMAUI方法利用OpenCV [6]库中的现成图像处理算法。该算法利用Canny边缘检测[7]来获取图像内容的原始形状和区域。随后,REMAUI算法执行边缘合并,通过合并重叠区域来获得GUI的边界框。对于文本元素,它应用了OCR工具来识别GUI文本。
现有的基于OCR的GUI测试将OCR引擎视为黑盒。这种方法首先调用OCR引擎来识别文本及其在屏幕上的位置,然后匹配其中的给定文本以定位文本位置。虽然有很多优点,但这种方法的一个缺点是OCR引擎通常运行缓慢。本文研究了GUI屏幕上文本的特征,并引入了一种快速的轻量级GUI文本识别算法,在保证原有OCR精度的情况下加速文本定位的过程,提高了GUI测试自动化的效率。
1 基于OCR领域的识别
OCR是将手写、打字或打印文本的扫描图像转换为机器编码文本的过程。
1.1 典型OCR
目前在GitHub上流行的主流OCR开源模型框架包括PaddleOCR [8]和EasyOCR [9]。PaddleOCR是一种基于百度飞桨的OCR工具库,包括了一种仅有8.6 MB大小的超轻量级中文OCR模板,且运行速度快。但是部分符号识别效果一般,如字母l识别为数字1,偶尔会出现部分内容丢失的情况。EasyOCR由Jaided AI开发,其识别效果尚可,优于一般开源模型。但是识别高分辨率图片速度很慢,严重依赖GPU。
1.2 OCR识别流程
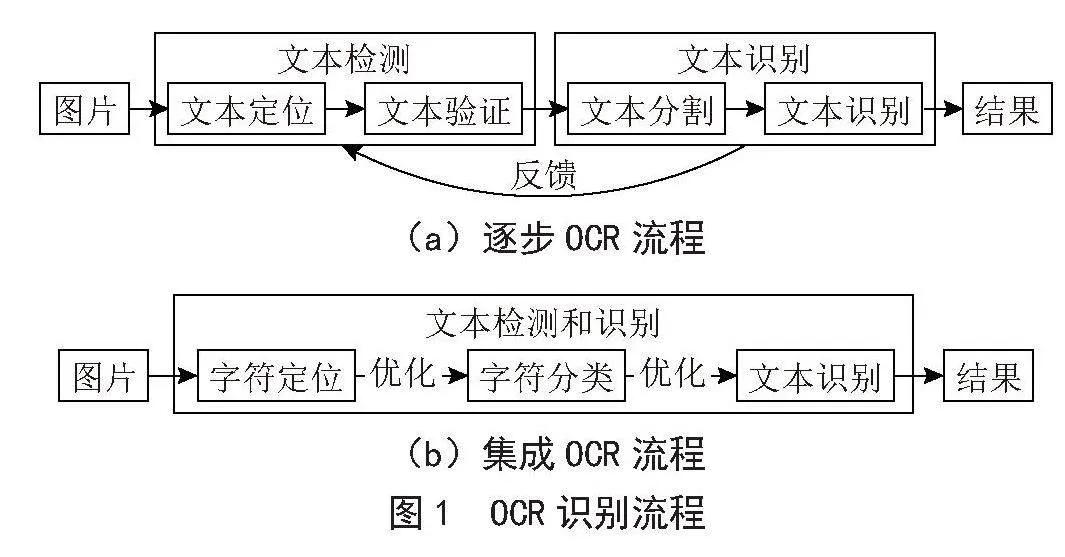
大多数OCR引擎以两种方式识别文本:集成和逐步两种方式。
如图1(a)所示,逐步方法具有分离的检测和识别模块,并且使用前馈流水线来检测、分割和识别文本区域。逐步方法涉及四个主要步骤:定位、验证、分割和识别。在定位步骤中,组件被初步分类并分组为候选文本区域。在验证阶段,这些区域进一步被分类为文本或非文本区域。分割步骤的目的是将字符进行分离,以确保图像块具有独特且准确的轮廓,以便在识别步骤中进行字符转换。相比之下,集成方法旨在识别单词,其中检测和识别过程与字符分类共享信息或使用联合优化策略,如图1(b)所示。通过集成方法,字符分类响应被视为文本识别的主要线索,并与文本检测和识别模块共享。这些方法相当于从字符模型中过滤响应以捕获感兴趣的单词。
(a)逐步OCR流程
(b)集成OCR流程
2 轻量级文本识别技术
深入研究基于OCR的文本识别,本文发现在这个任务中,通常不需要识别屏幕上的所有文本。通常GUI界面中只有几个简短的文本短语需要分析。然而黑盒OCR方法识别屏幕上的所有文本,那可能会浪费许多不必要的时间。这就是基于OCR的GUI测试较慢的原因。
因此,针对OCR的GUI测试,本文的文本定位场景是定位按钮、菜单项、窗口标题、链接等中的英文短文本。根据经验,定位GUI屏幕上显示的图像中嵌入的长文本段落或复杂场景文本并不常见。因此,这项工作只侧重于在GUI屏幕上定位短文本的问题来优化OCR文本识别流程,以提高效率和准确性。本文基于Canny和OpenCV设计了轻量级文本检测技术,代替了传统OCR全图文本检测,具体来说使用Canny边缘检测算法分析图像的边缘来检测字符,并采用自底向上的策略来检测筛选文本短语。主要分为四个步骤:字符轮廓检测、行合并字符框轮廓、行划分单词和分组文本短语。
2.1 字符轮廓检测
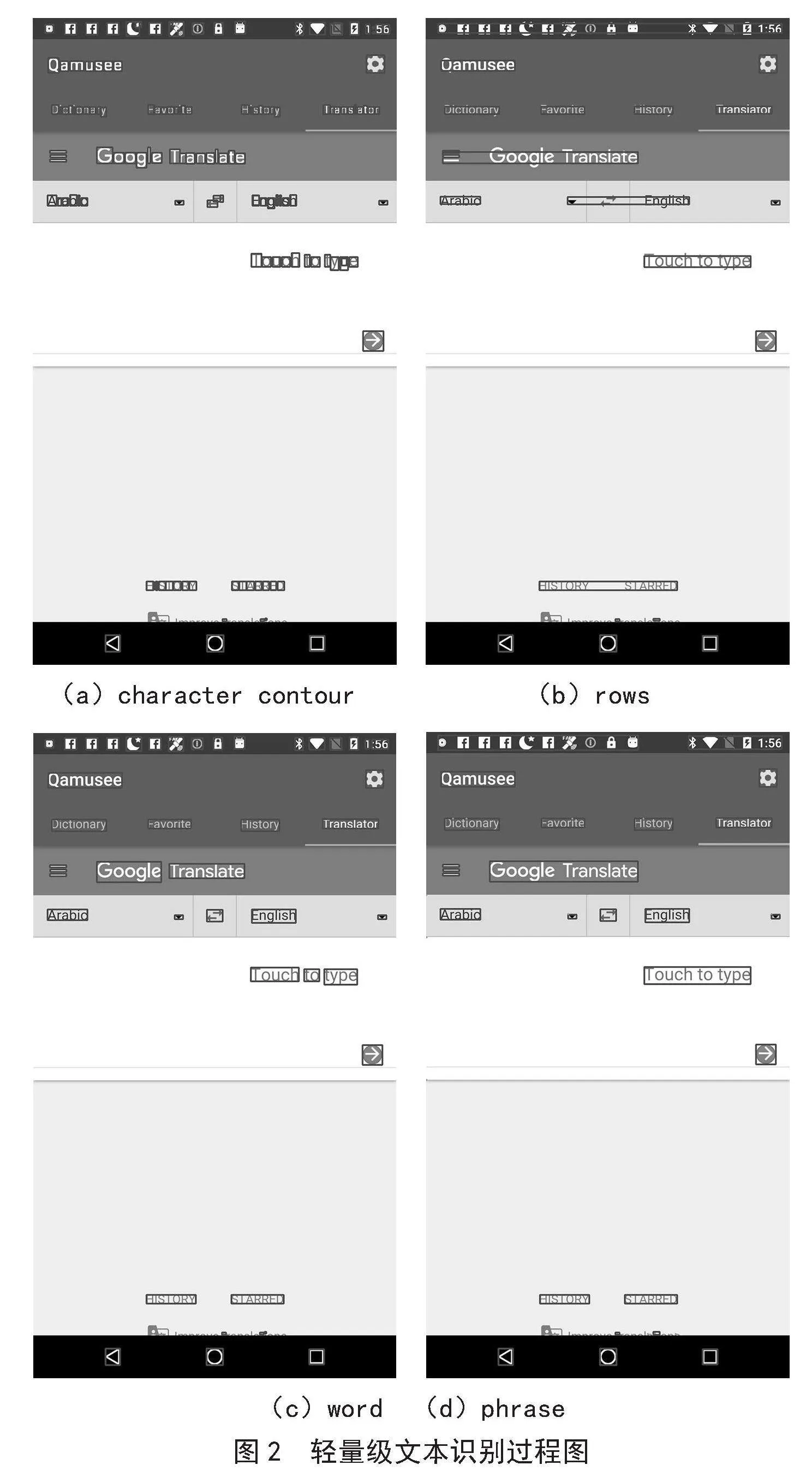
为了检测字符框,采取以下优化步骤:首先从屏幕截图中提取Canny边缘,然后找到这些边缘的轮廓层次结构,将字符框识别为具有适当大小和纵横比的轮廓边界矩形,将每个轮廓视为一个字符框,只有当其大小适中且纵横比合理时才被接受。字符轮廓结果如图2(a)所示。
2.2 行合并
在检测字符框后,接下来将字符框分组成行。首先,根据字符框的底部位置逐个处理它们。对于每个字符框,尝试将其放入与其最近的现有行中。如果找到匹配的行,将字符框添加到该行中。如果找不到匹配的行,将创建一个新的行来包含字符框。行合并结果如图2(b)所示。是否适合将字符框characterbox放置在行row上,取决于以下条件:
1)characterbox和 row垂直重叠。
2)characterbox完全位于row的上下高度阈值范围内,其高度为vcenter(row)上下2×cbox_height(row)的范围,其中vcenter(row)和cbox_height(row)是行row的平均字符框中心和高度。
3)characterbox和row中的内容来自同一个父轮廓。
2.3 行划分单词
为了将行进一步划分为单词,本文对字符框进行分组。两个相邻的字符框是否应该被分组为同一个词取决于它们的水平间距以及顶部和底部位置。分组开始于从左到右将字符框合并到单词中。假设对于字符框cb,其左侧已经合并的单词是W,并且left()、right()、top()、bottom()、width()和height()能获取屏幕对象的位置属性。如果left(cb)≤right(W),即字符框和单词已经连接,就立即将它们合并在一起。否则,假设word(W)中字符框的平均高度为cbox_height(W),然后猜测单词word中的最大字符水平间隙为:
除了从左到右合并字符框外,本方法还从右到左对第一步中找到的单词进行分组,以避免只向左看的限制。行划分结果如图2(c)所示。
2.4 分组短语
检测到的单词最终被分组为文本短语。分组条件如式(5)所示,其中单词被视为字符框。在文本短语分组中,本文使用双字符宽度作为最大水平间距来确定是否将单词W分组为文本短语P,即:
这里char_width(T)是一个完整单词或文本短语T的公共字符宽度。从字符框的平均宽度cbox_width(T)和字符框的平均高度cbox_height(T)来猜测它的值:
分组短语结果如图2(d)所示,可以看出,分组文本短语效果较好。
(a)character contour (b)rows
(c)word (d)phrase
3 实验及结果分析
3.1 实验数据
本文使用RICO [10]数据集进行评估。RICO是一种流行的移动的应用程序GUI屏幕数据集合。该数据集公开了约66k个不重复的UI屏幕截图,分辨率为1 080×960,并给出了与这些截图内容密切相关的视觉、文字、结构,以及交互设计属性。考虑到OCR速度较慢,在所有RICO屏幕截图上测试成本太高,因此挑选了10k个RICO截图上和51k个具有非空文本属性的可见文本控件。选取的文本完全是英文字母、空格或数字,在屏幕截图中文本不重复,并且在单行中(文本长度限制为小于10个单词,以便它们不太可能是多行)。
3.2 实验环境
本文配置如表1实验环境,设置单线程运行实验。对于所研究的OCR引擎,本文使用其默认模型进行文本分析,未在使用前对其进行预训练。
3.3 实验结果
3.3.1 评价指标
本文使用平均文本识别时间和文本识别精确度作为评价指标,虽然主要关心的是文本定位速度,但也评估了文本定位精度,以全面检查轻量级文本识别技术的影响。
3.3.2 性能对比
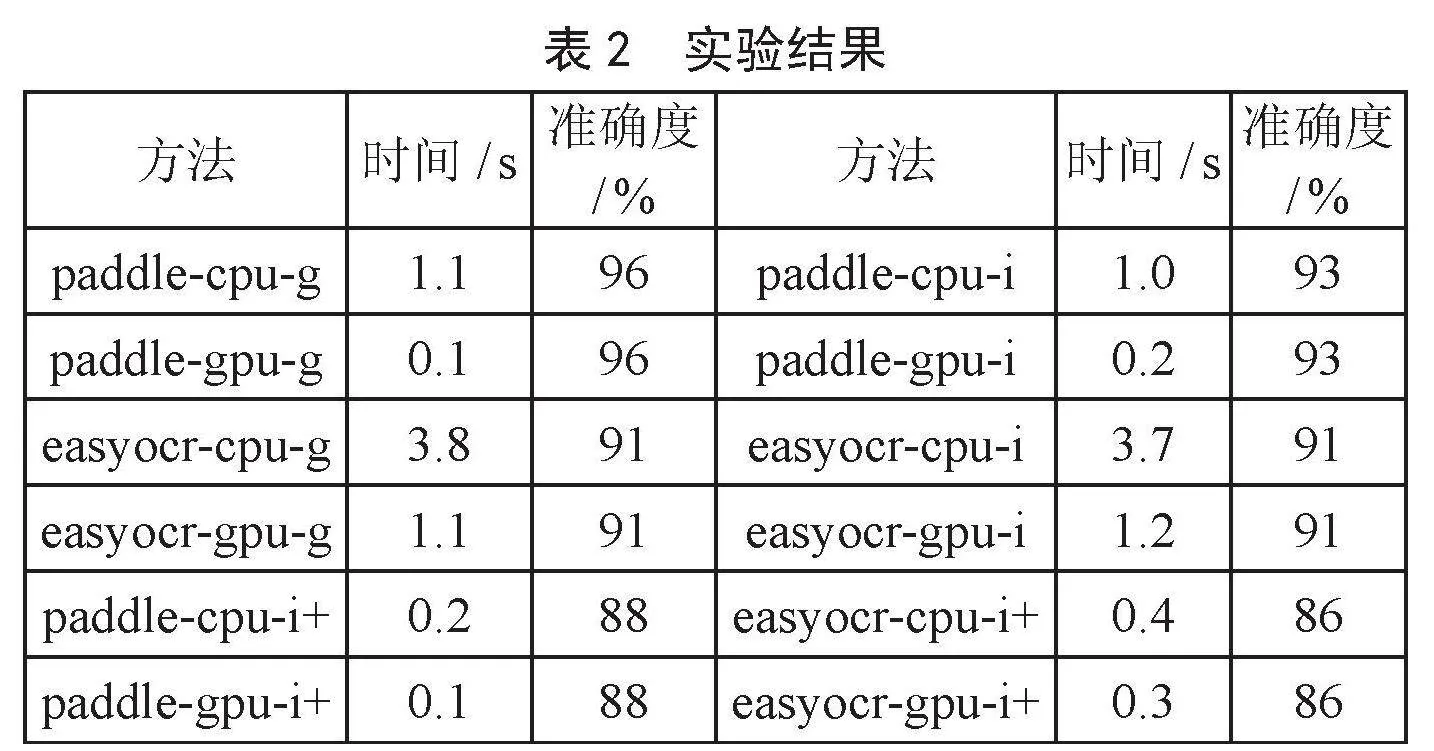
本文比较了提出的算法(-i+表示)、基于集成整图识别的OCR的方法(-g表示)和基于逐步OCR方法(-i表示)在不同OCR引擎上的平均文本定位速度以及准确度。
由表2可以看出,本文提出的算法识别时间最长时间不超过0.4 s,平均识别时间为0.25 s,比基于集成整图识别的OCR的方法(平均识别时间1.53 s)降低了84%,比基于逐步OCR方法(平均识别时间1.53 s)降低了84%。这显著降低了基于OCR文本识别的时间,提高了测试效率。在精度方面本文提出的算法识别精度略微低于传统的OCR引擎,这是因为:1)图片小工具对文本的误报;2)噪音,例如单个字符的微小字符框破裂等原因影响,但是结果是能在接受范围内。
4 结 论
本文针对当前OCR引擎识别速度慢的问题提出了快速的轻量级GUI文本识别算法,以加快OCR过程中的GUI测试。其使用Canny边缘检测算法分析图像的边缘来检测字符,并采用自底向上的策略来检测文本短语。与现有技术相比,本文的工作在针对GUI屏幕文本方面投入了精力,旨在尽可能减少不必要的分析过程,以实现快速检测文本短语。通过上述实验结果,证明了本文算法的有效性和可行性,证明了其在实际应用中的潜力和优势。但是还不能很好地处理复杂图像背景上的文本,因为只使用了一个非常简单的文本检测器。对于这种情况,最好在编写测试脚本时调用原始OCR引擎。后续会进一步开展相关研究。
参考文献:
[1] NEUDECKER C,BAIERER K,GERBER M,et al. A Survey of OCR Evaluation Tools and Metrics [C]//The 6th International Workshop on Historical Document Imaging and Processing.New York:Association for Computing Machinery,2021:13-18.
[2] HEGGHAMMER T. OCR with Tesseract, Amazon Textract, and Google Document AI: a Benchmarking Experiment [J].Journal of Computational Social Science,2022,5(1):861-882.
[3] LI C M,ZHANG Y. Ameliorating the Image Matching Algorithm of Sikuli Using Artificial Neural Networks [J].International Journal of Dynamics of Fluids,2018,14(1):63-72.
[4] CHEN Y X,ZHANG T H,CHEN J.UI2code: How to Fine-tune Background and Foreground Analysis [EB/OL].(2020-02-23).https://laptrinhx.com/ ui2code-how-to-fine-tune-background-and-foreground-analysis2293652041/.
[5] TUAN A N,CHRISTOPH C. Reverse Engineering Mobile Application User Interfaces with REMAUI (T) [C]//2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE).Lincoln:IEEE,2015:248-259.
[6] OpenCV team. OpenCV [EB/OL].[2023-10-15].https://opencv.org/.
[7] CHEN X,JIN L,ZHU Y,et al. Text Recognition in the Wild: A Survey [J]. ACM Computing Surveys (CSUR),2021,54(2):1-35.
[8] PaddlePaddle. PaddleOCR [EB/OL].[2023-10-15].https://github.com/PaddlePaddle/PaddleOCR.
[9] JaidedAI. EasyOCR [EB/OL].[2023-10-15].https://github.com/JaidedAI/EasyOCR.
[10] DEKA B,HUANG Z F,FRANZEN C,et al. Rico: A Mobile APP Datasetfor Building Data-Driven Design Applications [C]//UIST 17: Proceedings of the 30th Annual ACM Symposium on User Interface Software and Technology.New York:Association for Computing Machinery,2017:845-854.
作者简介:马荧炜(1998—),男,汉族,浙江温岭人,硕士研究生在读,研究方向:软件测试。
收稿日期:2023-12-20