中图分类号:TP3191.1;TP18 文献标识码:A 文章编号:2096-4706(2025)07-0151-06
Abstract: Inorder toimprove theintelligencelevelofengineering construction quality inspection inofshoreoilindustry a quality problem clasification algorithm basedon Chinese pre-training modelof Chinese-BERTandBiLSTMis proposed. Chinese-BERTmodelcanbeter extract Chinese textfeaturesandimprovetheaccuracyoftextvectorsemanticrepresentationby using Chinese pre-training,whileBiLSTMfurtherextractskey informationfrom Chinese-BERTfeature vectors.Thevalidityof the modelis verified inrealdataandtheresults showthat the proposed modeloutperformsothercomparativemodels interms of classification performance,and it can effectively solve quality problem classfication problems.
eywords:offshore oil industry;quality problem; text classification; Chinese-BERT; BiLSTN
0 引言
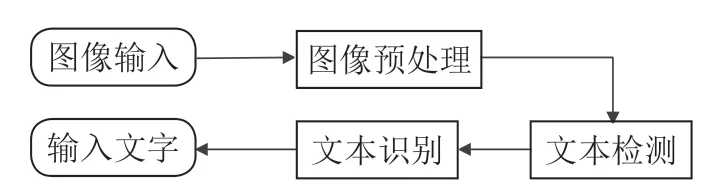
海洋石油工程行业中,工程施工质量检查具有至关重要的地位和作用,通过施工质量检查获取的质检数据是衡量与判断工程项目质量的重要标准和技术依据,高效的项目质量检测不仅能够提高项目的施工质量以及可维护性。在目前质检过程中,需要质检人员针对具体的工程质量问题进行语言描述,然后依据行业标准进行问题分类。随着海洋石油工程行业的迅猛发展以及国家对质量检查要求的持续细化与规范,不断有新质检标准制定出来,且时常伴有对已发布标准的修订,对海洋石油工程行业来说,该行业内常见的质量问题分类主要涉及质量行为、防腐专业、管道专业等专业方向,这些方向的质量问题分类涉及大量的专业标准,对进行质量问题分类人员的要求较高。原有的质检问题分类方法高度依赖人工,效率低下,且存在判别标准掌握不统一的情况,无法适应业务需求。因此,实现质量问题分类的智能化和自动化是非常必要的。相比传统的人工分类,自动问题分类能够在短时间内完成大量的检查工作,大大减少了人力成本和时间成本。在质检流程上,自动问题分类可以根据企业的质检标准和要求,自动进行质量检查,实现质检的流程化。通过自动分类,有助于保证质检的一致性和标准化,避免了人工质检中因为主观因素导致的差异性。通过质量问题分类,相关人员可以及时发现生产过程中的问题,并采取相应的措施进行改进。这有助于优化生产流程,提高生产效率,降低生产成本。
近年来,基于深度神经网络的自然语言处理技术取得了飞速进步,尤其在处理长文本时有较好的表现效果。文献[1]比较了TF-IDF和Word2Vec模型在文本分类中表示特征的性能,使用支持向量机 (SVM)
和多项式朴素贝叶斯(MNB)方法进行文本分类,对比得出TF-IDF建模比Word2Vec建模具有更好的性能,显著提高了分类效果。文献[2]有效结合卷积神经网络(CNN)和长短期记忆网络(LSTM)提取文本特征,并使用分类器对深度神经网络输出的文本特征进行有效分类。该方法能有效解决短文本分类的问题,在多个二分类问题上都有出色的表现。文献[3]使用Word2Vec将文本转换为文本向量,以此来提高向量对文本的表达程度,同时使用LSTM对文本向量进行特征提取,该模型与CNN相比拥有更好的效果,但缺点在于Word2Vec无法考虑到文本的上下文语境,导致文本向量存在歧义问题,无法正确地表达出短文本的语义信息。文献[4]提出注意力(Attention)机制,即在分类结构中引入注意力机制,可以提高文本分类的性能。文献[5]在文本分类模型中纳入了单词和句子级的注意力机制,在分类效果上实现显著提升。基于Transformer的方法则应用自我注意力(Self-Attention)并行计算句子或文档中每个单词的注意力分数,以此来表示单词之间的影响。文献[6]提出了一种基于Transformer的预训练模型(BERT),BERT可以高效且无歧义地将输入文本转换为文本向量,部分研究者使用BERT预训练模型代替Word2Vec模型进行文本的向量化,从而解决了文本歧义化的问题。但BERT是基于英文语料进行预训练的,对中文的处理效果不佳。文献[7]提出了使用中文语料进行预训练的中文预训练语言模型Chinese-BERT。经过验证Chinese-BERT在十项中文自然语言处理(NLP)任务中均表现优秀。文献[8]在BERT和LSTM神经网络模型基础上,结合多特征嵌入和多网络融合方法构建了BERT-LSTM模型,使用BERT模型将输入的文本转换为词向量,然后使用BERT对词向量进行特征提取,随后将特征向量再输入到LSTM层进行序列建模,采用LSTM来捕捉全局信息中的关键信息,但LSTM只能从一个方向进行关键信息的捕获,无法更全面的进行关键信息的提取。文献[9]构建了一种基于双向长短期记忆网络(BiLSTM)的文本分类方法。该方法利用BiLSTM从上下两个方向提取文本的关键语义信息,并在BiLSTM的双通道层中,将上下语义信息进行特征信息融合得到最终的文本特征表示。该方法在文本分类任务中可以同时采集到文本的上下文语义信息,从而提高最终文本分类的效果。
目前,关于海洋石油工程行业的工程质量问题分类的研究相对较少。不同于长文本,海洋石油工程行业的工程质量问题自然语言描述大多是短文本。短文本由于受到文段长度的限制,不具备较强的相关性以及较多的文本特征,传统的长文本分类模型难以直接用于短文本分类,需要进一步提升模型对中文文本的特征提取能力。为解决海洋石油工程行业质量问题自动分类问题,提出一种Chinese-BERT结合BiLSTM的文本分类模型,更好地提取中文文本的特征,提高文本向量语义表示的准确性,对质量问题描述文本进行分类,从而提高质量检查的效率和标准化程度。
1相关理论
1.1 BERT模型
BERT模型是2018年由Google提出的以Transformer模型的编码部分为基础,由12层Transformer叠加而成,构建了一个多层双向的网络架构。其模型结构如图1所示。
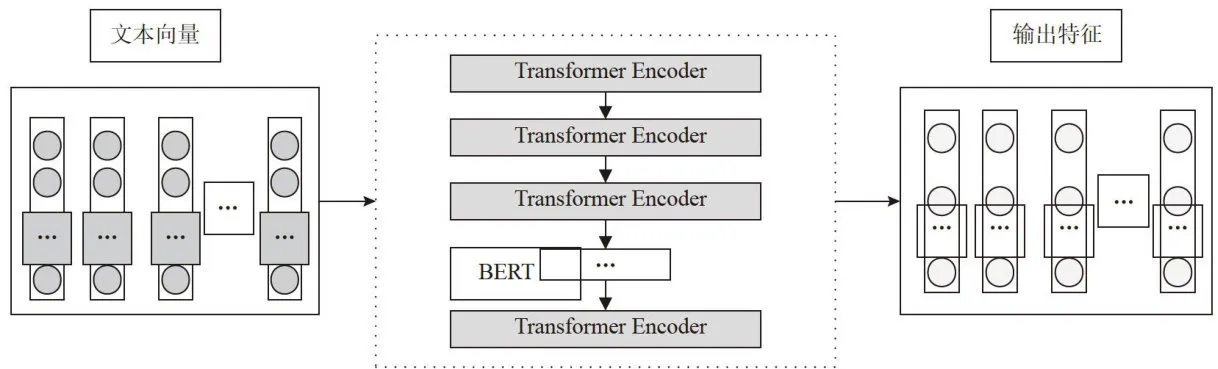 图1BERT模型结构
图1BERT模型结构1)输入层。输入向量E由词向量(TokenEmbeddings)、段向量(SegmentEmbeddings)和位置向量(PositionEmbeddings)叠加而成,可表示为:
E ( x ) = E P+ E S+ E T
2)编码层。编码层是BERT模型的核心,由多层双向Transformer编码器构成。Transformer的编码端由6个Encoder构成,解码端由6的Decoder构成。通过采用多头自注意机制来全方位获取丰富的语义信息,同时,还采用残差网络架构缓解模型梯度消失和爆炸的问题。TransformerEncoder由输入、多头自注意机制和全连接神经网络组成。
3)输出层。输入到BERT中的文本向量 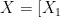
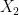 ,…,
,…, 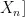 经过输入层和编码层后,得出基于BERT模型的特征向量矩阵
经过输入层和编码层后,得出基于BERT模型的特征向量矩阵 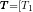 ,
, 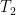 ,…,
,…, 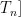 。
。
1.2 LSTM模型
LSTM是一种循环神经网络的变体,LSTM利用门控机制,该机制通过输入门、遗忘门、和输出门,来有选择地保留和更新隐藏层中信息。输入门的作用是控制当前时间步隐藏状态下新信息的加入量,遗忘门决定了在当前时间步中是否遗忘之前的隐藏状态,输出门控制当前时间步隐藏状态下的信息流向。
细胞状态更新公式如下:
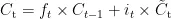
遗忘门公式如下:
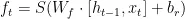
输入门公式如下:
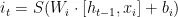
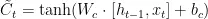
输出门公式如下:
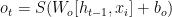
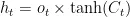
其中 
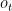 为 t 时间步遗忘门、输入门、输出门的单元状态;
为 t 时间步遗忘门、输入门、输出门的单元状态; 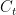 为 t 时间步的细胞状态;
为 t 时间步的细胞状态; 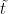 为 t 时间步的细胞状态更新值; S 和tanh为Sigmoid激活函数和 tanh激活函数; W 和 b 为权重矩阵和偏置项;
为 t 时间步的细胞状态更新值; S 和tanh为Sigmoid激活函数和 tanh激活函数; W 和 b 为权重矩阵和偏置项; 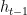 为t-1时间步的隐藏状态。LSTM模型结构如图2所示。
为t-1时间步的隐藏状态。LSTM模型结构如图2所示。
LSTM有效解决了循环神经网络(RNN)模型的梯度消失以及梯度爆炸问题,在处理序列任务上,可以更好地捕获序列数据中的依赖关系,以提高特征提取的效果。
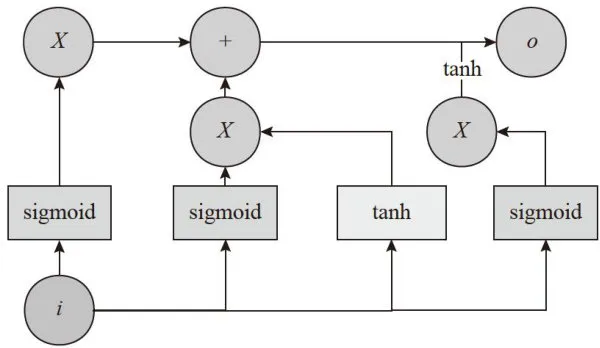 图2LSTM模型结构
图2LSTM模型结构1.3 BiLSTM模型
BiLSTM通过采取正向和反向两个方向的LSTM层,使得BiLSTM能够从两个方向同时捕获序列数据中每个位置的信息。BiLSTM的每个时间步的输入包含当前位置的特征和前一个时间步的隐藏状态。BiLSTM通过利用正向和反向的隐藏状态,得到当前时间步的输出。BiLSTM结构如图3所示。
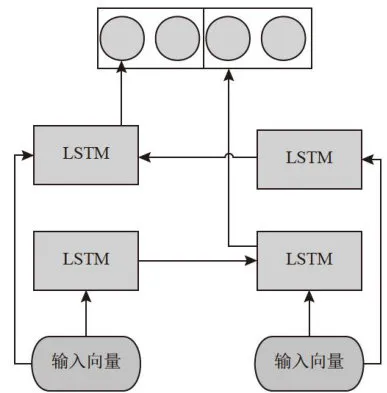 图3BiLSTM结构图
图3BiLSTM结构图在图3中,首先将文本向量分别输入到两个LSTM网络中进行正向和方向特征提取,在正反向所有的特征提取计算结束后,两个LSTM网络分别将正向和反向特征信息输出,最后将正向和反向特征信息拼接起来,得到最终BiLSTM的输出结果。
2 质量问题分类模型
本文针对海洋石油工程行业质量问题分类困难且高度依赖人工的问题提出了一种Chinese-BERT结合BiLSTM模型的文本分类模型。该方法采用Chinese-BERT自带的Tokenizer进行文本的向量化,不同于第三方Tokenizer,Chinese-BERTTokenizer可以在考虑上下文语义的情况下对文本进行向量化,从而解决向量化分歧的问题。另外,在文本特征提取方面,相对于使用英文语料进行预训练的BERT模型,采取使用中文语料进行预训练的Chinese-BERT模型进行文本特征提取,能够更好的提高文段特征提取能力。另外,针对Chinese-BERT直接输出的特征信息缺乏对文本关键信息的表示不足,本文引入BiLSTM模型,对Chinese-BERT提取出的特征信息进行上下两个方向的关键信息捕获,最后将关键特征信息输入到Softmax分类器中进行分类实现结果输出。
Softmax函数又称归一化指数函数,是基于Sigmoid二分类函数在多分类任务上的推广在多分类网络中,Softmax通常用于最后一层,以输出各个类别的概率,在这种情况下,Softmax将网络的输出转换为每个类别的概率分布。例如,在文本分类中,Softmax可以用于确定文本所属的类别。其公式如下所示:
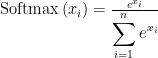
其中 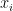 为一个质量问题文本对于第 i 个问题分类的相似程度。
为一个质量问题文本对于第 i 个问题分类的相似程度。
本文质量问题分类模型如图4所示。
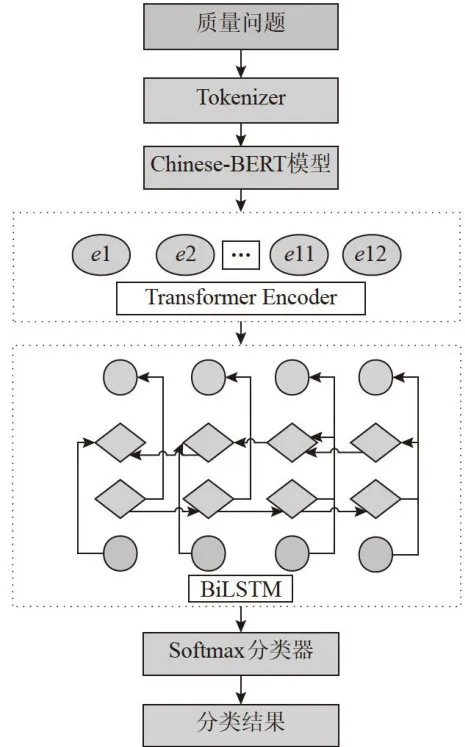 图4质量问题分类模型
图4质量问题分类模型失值进行剔除,然后针对问题描述文本中的重复数据进行了去重操作,保证了问题描述文本的唯一性,最后将数据随机排列以防止有序数据对模型训练产生影响。经过以上处理后,得到了一个包含十四类质检专业的问题分类数据集,包含质量行为、防腐专业、管道专业、海管专业、海缆专业等,各专业的问题描述文本占比如表1所示。上述分类基本覆盖海洋石油工程行业的全部问题分类,能够代表质量检查中的绝大多数问题,该数据集具有极强的数据真实性、代表性以及实用价值。
质量问题分类模型在流程上主要分为以下四个阶段:
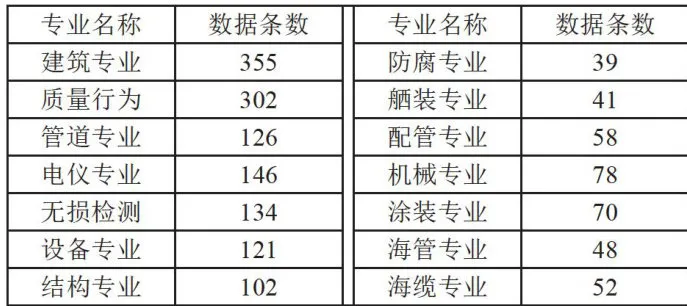 表1问题描述文本占比
表1问题描述文本占比数据集由1672条真实问题描述文本构成,本文按照8:2的比例将数据集随机划分为训练集和测试集,其中训练集1337条,测试集334条,数据集的具体内容如表2所示。
1)文本向量化阶段:该阶段将质量问题描述文本输入到Chinese-BERTTokenizer中进行向量化以便后续的模型运算。
2)文本特征提取:将1)中文本向量输入到Chinese-BERT中进行文本特征提取,主要通过Chinese-BERT中的12个Transformer编码器来进行文本向量的特征提取。
3)关键信息提取:将Chinese-BERT输出的特征输入到BiLSTM网络中,进行上下两个方向的关键信息捕获,更全面的进行关键特征信息的提取。在BiLSTM的双通道层中,将上下语义信息进行特征信息融合得到最终的文本特征表示。
4)将提取过关系信息的特征数据输入到分类器中得到最终的分类结果。
 表2问题描述数据集条目
表2问题描述数据集条目3.2 实验环境
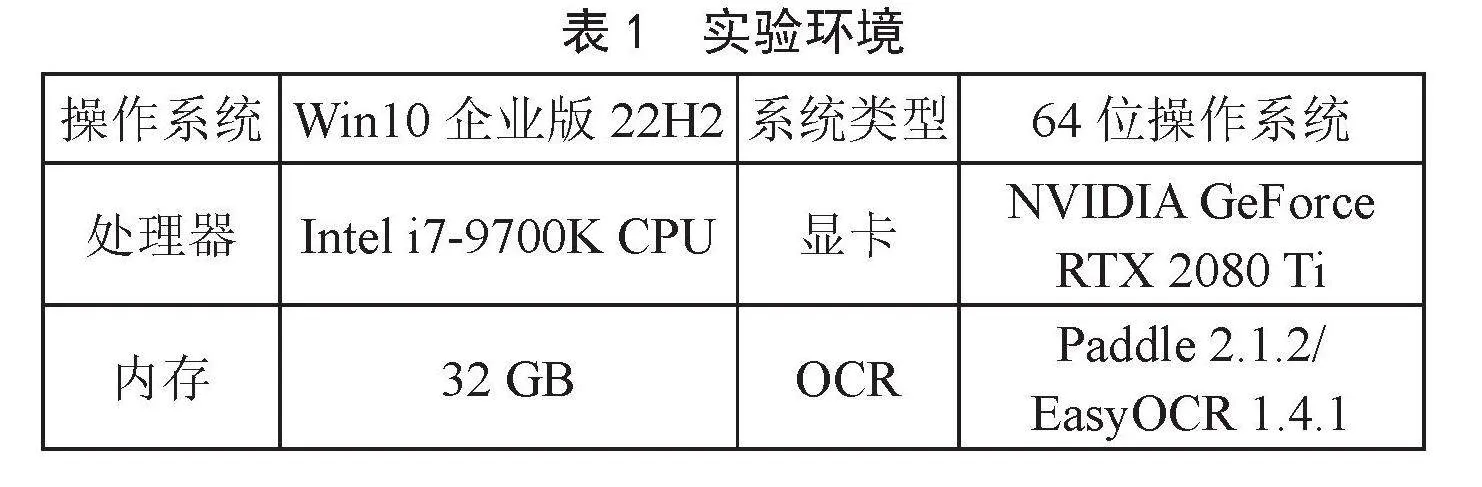
本实验环境配置如表3所示,模型参数如表4所示。
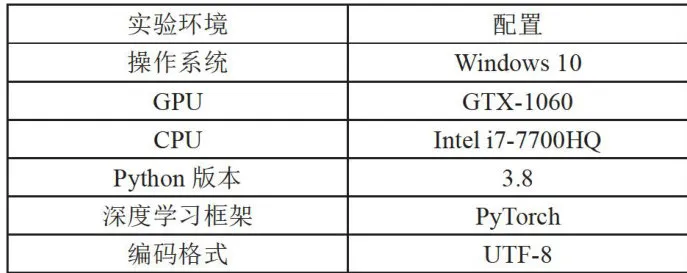 表3实验环境
表3实验环境3 实验和结果分析
3.1 数据集的建立
为了验证Chinese-BERT ∵ BiLSTM文本分类模型性能的优劣,收集了某海洋石油工程质监站质量问题描述分类文本,为了保证问题描述文本的有效性,在数据集的预处理阶段中,首先将问题描述文本中的缺
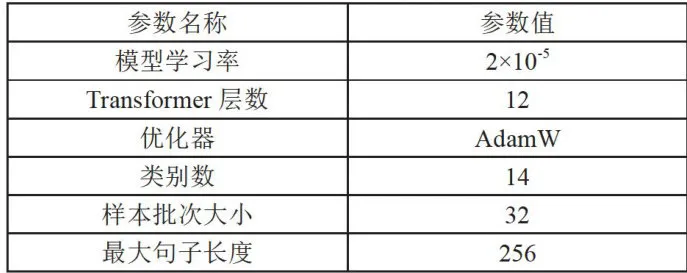 表4模型实验参数
表4模型实验参数 (续表)
(续表)3.3 评价指标
本文实验使用准确率、精确率、召回率和F1值作为文本分类模型的评估标准。其计算公式为:
3.4实验结果与分析
为验证Chinese-BERT+BiLSTM文本分类模型的分类效果,以LSTM模型BiLSTM模型,BERT-BASE模型为基线进行了对比实验,实验结果如表5所示。各模型依次为:
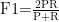
式中,TP为样本为正例且预测为正例,TN为样本为负例且预测为负例,FN为样本为正例但预测为负例,FP为样本为负例但预测为正例。由于精确率和召回率会出现相互矛盾的情况,故引入F1得分作为综合评价指标。
1)LSTM模型,首先利用分词工具对数据集进行分词并生成词向量,然后利用LSTM模型获取对其进行特征提取。2)BiLSTM模型,同样借助分词工具对数据集进行分词并生成词向量,然后使用LSTM模型获取对词向量进行联系上下文语义关系的双向的特征提取。3)BERT-BASE模型,利用BERT-BASE模型的自编码器获取文本的词向量,然后将词向量输入到BERT的TransformerEncoder中进行文本特征提取。4)Chinese-BERT ∵ BiLSTM模型,模型Chinese-BERT在BERT的基础上使用中文语料进行了预训练,从而提高其中文文本特征提取能力。然后采用BiLSTM进行特征关键信息提取。
 表5实验结果
表5实验结果由表5的结果可以看出,在质检问题数据集上,Chinese-BERT+BiLSTM问题文本分类模型的准确率、精确率、召回率和F1值分别达到了 8 4 . 2 5 % 70 . 7 1 % 、 7 1 . 5 2 % 、 7 0 . 5 1 % 。对比BERT-BASE,准确率、精确率、召回率和F1值分别提高了 2 3 . 9 6 % 、2 9 . 1 5 % 、 2 9 . 6 1 % 、 2 9 . 5 4 % ,可见本文所提出的模型对比BERT-BASE对中文文本有着更好的特征提取能力。与文本提取模型BiLSTM相比,准确率、精确率、召回率和F1值分别提高了 3 3 . 8 1 % 、 1 0 . 6 9 % 2 5 . 2 3 % 、 2 1 . 9 7 % 。与LSTM模型相比,准确率、精确率、召回率和F1值分别提高了 4 0 . 0 8 % : 2 7 . 8 % 、3 9 . 5 3 % 、 34 . 4 7 % 。可见本文所提出的模型对比传统文本特征提取网络有显著提升。通过实验分析可知,本文所提出的模型在问题描述数据集上的分类表现明显优于其他几种分类模型。模型有较高的质检问题分类能力。
为了验证BiLSTM所提取的关键信息的有效性,本文设置Chinese-BERT与本文模型进行对比,模型对比实验数据如表6所示。
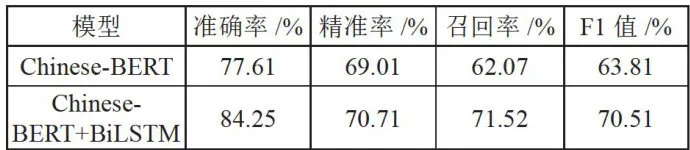 表6消融实验
表6消融实验结果表明BiLSTM的加入能够有效提高问题分类的效果。综上,在加入BiLSTM后,模型的准确率、精确率、召回率和F1值各项指标,均有所提高,可见BiLSTM所提取的关键信息可以有效地提高问题分类的效果。
4结论
针对石油行业质量检查标准众多、更新变化快、极度依赖人工以及目前分类算法对中文文本特征提取能力不佳等问题,本文提出了一种Chinese-BERT + BiLSTM质检问题分类模型,通过收集真实质量问题文本,经过标注和清洗后,建立了质量问题数据集。经过在质量问题数据集上的测试,验证发现,本文的分类模型在准确率、精确率、召回率和F1值各项指标均优于其他对比模型。但是,由于缺少完整且权威的中文文本数据集,自采的质量问题数据集来源于工程实践,还存在人工标注尺度不一致和缺漏等情况,分类准确度等指标仍有提升空间。在后续的研究中,将针对这些问题开展进一步的工作。
参考文献:
[1] CAHYANI D E,PATASIK I. Performance Comparison ofTF-IDFandWord2VecModelsforEmotion TextClassification [J].Bulletin ofElectrical Engineeringand Informatics,2021,10 (5):2780-2788.
[2]王磊.基于混合神经网络的中文短文本分类方法研究[D].杭州:浙江理工大学,2019.
[3]王铁君,闫悦,郭晓然,等.融合多尺度CNN与双向LSTM的唐卡问句分类模型[J].科学技术与工程,2024,24(22):9490-9497.
[4]BAHDANAUD,CHOK,BENGIOY.Neural Machine Translationby JointlyLearning to Align and Translate [J/OL].arXiv:1409.0473[cs.CL].[2024-10-03].https://arxiv.org/ abs/1409.0473?context=stat.ML.
[5]LI Z,XUH,ZHANGY,etal.Hierarchical Attention NetworksforHyperspectral Image Classification[C]//MIPPR 2019:Remote Sensing Image Processing, Geographic Information Systems,and OtherApplications.Wuhan:SPIE,2020: 114320D.https://doi.org/10.1117/12.2538278.
[6]SHEMTOVE,SIPPERM,ELYASAFA.BERTMutation:Deep TransformerModel forMaskedUniformMutationinGenetic Programming[J].Mathematics,2025,13(5):779-779.
[7]CUIY,CHEW,LIUT,etal.Pre-TrainingwithWhole WordMaskingforChineseBERT[J].IEEE/ACMTransactions onAudio,Speech,andLanguageProcessing,2021,29:3504- 3514.
[8]安锐,陈海龙,艾思雨,等.基于BERT-LSTM模型的航天文本分类研究[J].哈尔滨理工大学学报,2024,29(4):40-49.
[9]黄远,戴晓红,黄伟建,等.基于A-BiLSTM和CNN的文本分类[J].计算机工程与设计,2024,45(5):1428-1434.
[10]DUANS,ZHAOH.AttentionIsAll You Need for Chinese Word Segmentation [C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP).Association for Computational Linguistics,2020: 3862-3872.
[11]陈晓江,杨晓奇,陈广豪,等.混合BERT和宽度学习的低时间复杂度短文本分类[J].山东大学学报:工学版,2024,54(4):51-58+66.
[12]DUJ,VONGC M,CHENCLP.Novel Efficient RNNandLSTM-LikeArchitectures:RecurrentandGatedBroad Learning Systemsand TheirApplications for TextClassification [J]. IEEE Transactions on Cybernetics,2020:1-12.
[13]郝超,裘杭萍,孙毅,等.多标签文本分类研究进展[J].计算机工程与应用,2021,57(10):48-56.
[14]YOGATAMAD,DYERC,LINGW,etal. Generative andDiscriminativeTextClassificationwithRecurrent Neural Networks[J/OL].arXiv:1703.01898 [stat.ML].[2024-09- 27].https://arxiv.org/abs/1703.01898?context=cs.CL.
[15]郑承宇,王新,王婷,等.基于Stacking-Bert集成学习的中文短文本分类算法[J].科学技术与工程,2022,22(10):4033-4038.
[16]代林林,张超群,汤卫东,等.融合对比学习和BERT的层级多标签文本分类模型[J].计算机工程与设计,2024,45(10):3111-3119.
作者简介:蔡玉华(1992一),男,汉族,河北文安人,工程师,本科,研究方向:质量监督;安鑫鹏(1999一),男,汉族,山东淄博人,硕士研究生在读,研究方向:计算机技术;通信作者:马永军(1970一),男,汉族,山东日照人,教授,博士,研究方向:机器学习。