
摘 要:针对现代信息社会海量数据的提取难度,开发一种集成ChatGPT的自动化网络爬虫系统。将信息呈现给用户,降低了使用门槛,结合系统的设计和实施,展示其在实际运用中的效果,实验结果证明,利用Selenium技术自动执行爬取操作,降低数据提取难度,提升数据信息抓取的准确性。功能测试结果显示,该系统有效提高了数据的使用率,为普通用户从网络中提取信息提供了新的途径。用户的信息挖掘和知识获取需求,促进自动化网络爬虫技术的发展和应用。
关键词:ChatGPT;Selenium;网络爬虫;自动化
中图分类号:TP311 文献标识码:A 文章编号:2096-4706(2024)14-0069-07
Design and Implementation of Intelligent Selenium Web Crawler Integrated with ChatGPT
LIU Yikai, WU Gui
(School of Artificial Intelligence, Jianghan University, Wuhan 430056, China)
Abstract: In response to the challenges of extracting vast amounts of data in the modern information society, this paper develops an automated web crawler system integrated with ChatGPT. It presents information to users, lowers the entry barrier for utilization, and combines the design and implementation of the system, demonstrates its practical effectiveness. Experimental results confirm that the use of Selenium technology for automated crawling operations reduces data extraction difficulty and enhances the accuracy of data information retrieval. Functional testing results show that the system effectively improves data utilization rate, providing a new avenue for ordinary users to extract information from the web. The users demands for information mining and knowledge acquisition promote the advancement and application of automated web crawler technology.
Keywords: ChatGPT; Selenium; Web crawler; automation
DOI:10.19850/j.cnki.2096-4706.2024.14.014
0 引 言
随着互联网的迅速发展,网络所包含的信息呈现日益庞大的趋势。在这个信息过载的时代,从海量数据中高效地提取有价值的信息已经成为各个领域研究的核心难题。在这样的背景下,网络爬虫技术变得愈发关键,它为研究者和使用者提供了一条有效的途径来获得所需信息。
1 自动爬虫系统介绍
本文旨在开发一种集成了ChatGPT的自动化爬虫系统,使数据使用者能够轻松高效地从网络页面中提取所需内容。传统的网络爬虫通常要求使用者具备编程技能和对系统底层技术的深入理解。然而,本系统的目标在于消除这些技术门槛,使普通使用者也能够享受到网络爬虫带来的便利。
借助深度学习和自然语言处理技术的最新进展,ChatGPT已经在文本生成和理解任务上展现出卓越的性能[1]。基于此,本文充分利用ChatGPT在文本处理方面的强大能力,将其与自动化爬虫技术相融合,从而实现了一种简单而高效的网络爬虫系统。需要特别指出的是,本自动化爬虫系统无须使用ChatGPT的API,而是充分利用Selenium技术来实现自动化爬取功能[2],从而确保了系统的免费使用。使用者只需打开欲爬取的网页,登录其ChatGPT账号,输入有关爬取内容的指令,系统将自动进行爬取,并将相关内容展示给使用者,从而极大地降低了使用门槛。
本文将详细阐述所开发的Python程序的设计和实现过程,展示系统在不同数据源上的实验结果,并对其性能进行全面评估。同时,还将探讨系统的优势和局限性,并提出未来改进的潜在方向。
通过本文,旨在为普通使用者提供一个简单易用、高效可靠的网络爬虫工具,以支持普通使用者在信息挖掘和知识获取方面的需求。相信这一系统的开发将积极推动自动化爬虫技术的发展和应用,为信息时代的进步做出贡献。
2 系统开发
为了结合ChatGPT实现自动化爬虫功能,该研究使用了Python编程语言和Selenium Webdriver工具。Selenium是一个用于Web自动化测试的工具,可以利用它来模拟浏览器的行为并进行页面数据的提取[3-5]。
2.1 自动化爬虫系统功能的开发思路
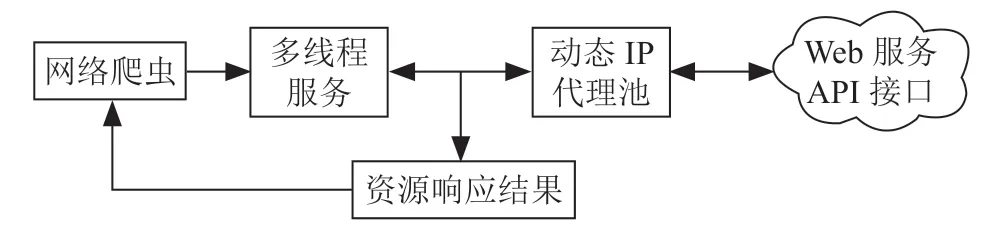
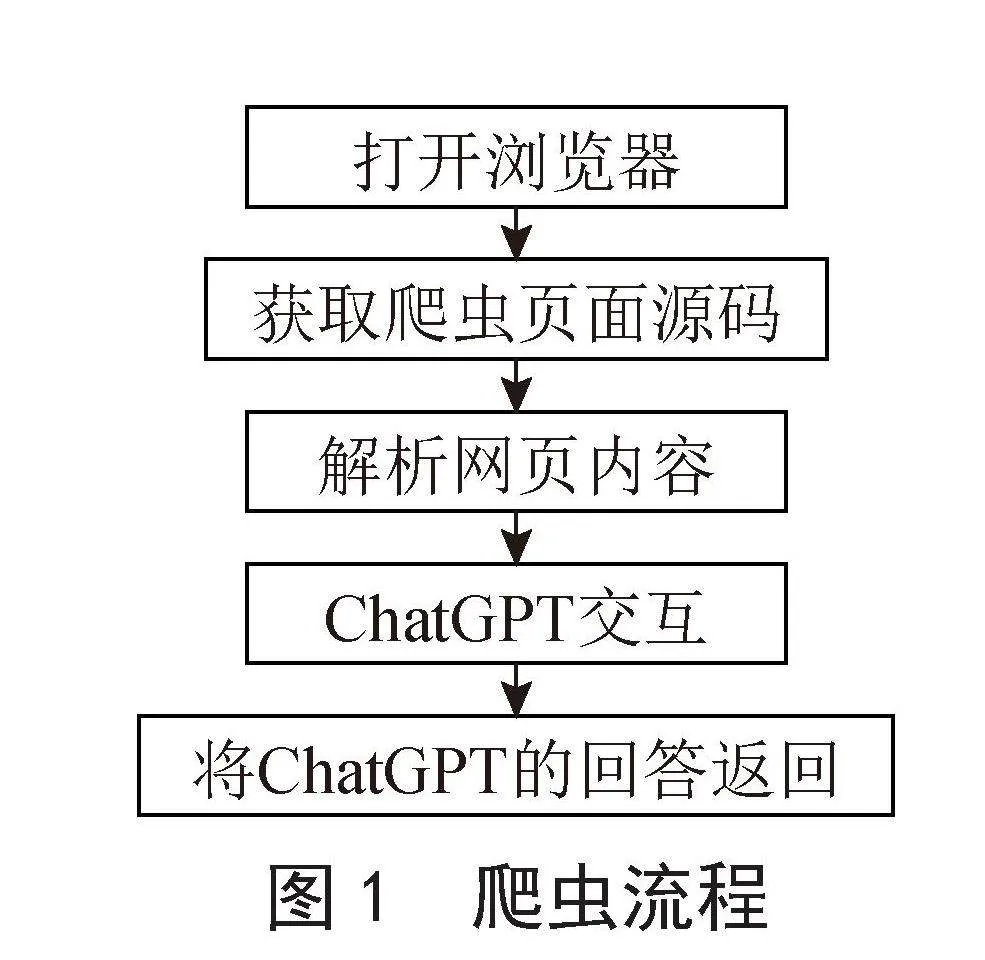
首先,系统会自动打开一个浏览器,并等待用户在浏览器中进行操作,直至进入爬虫页面(即特定的网络页面),等待用户启用热键调用爬虫功能。接下来,系统将使用Selenium库获取爬虫页面的源码,并运用B4库和正则表达式解析网页内容,以确保有效地提取所需信息。系统将采用Selenium库中的无头模式,对新的浏览器进行操作,以实现本系统与ChatGPT之间的无干扰交互。解析所得的网页内容将被传送至ChatGPT,通过一系列对话,满足用户的爬虫需求。
最后,系统将把ChatGPT所回答的内容返回给用户,确保用户获得所需的爬虫结果。爬虫流程如图1所示。
2.2 自动化爬虫系统的设计
下面是该系统实现自动化爬虫功能的详细步骤及相应的Python代码。
导入程序中所用到的Python标准库以及第三方库代码说明:
Selenium:用于自动化浏览器操作,可以模拟用户在浏览器中的各种行为,如点击、输入等,常用于爬虫、测试和自动化任务。
SSL:用于处理SSL证书,通过ssl._create_default_https_context = ssl._create_unverified_context解决SSL证书问题报错。
keyboard:用于监听热键,实现功能函数的实时调用。
threading:用于创建线程,实现多线程执行。
re:Python的正则表达式库,用于字符串的模式匹配和处理。
bs4(BeautifulSoup):用于解析HTML和XML文档,方便地从网页中提取数据。
time:用于时间相关的操作,比如等待、计时等。
undetected_chromedriver:是对selenium的扩展,用于绕过检测自动化测试的脚本而运行Chrome浏览器。
Keys:Selenium中的模块,用于模拟键盘按键。
WebDriverWait和expected_conditions:selenium中的模块,用于等待页面元素加载。
sys:Python标准库,提供对Python运行时环境的访问。
atexit:用于注册在程序退出之前执行的函数。
colorama:一个用于在终端输出中添加颜色的库,可以让输出更加丰富和醒目
库的导入部分代码如图2所示。
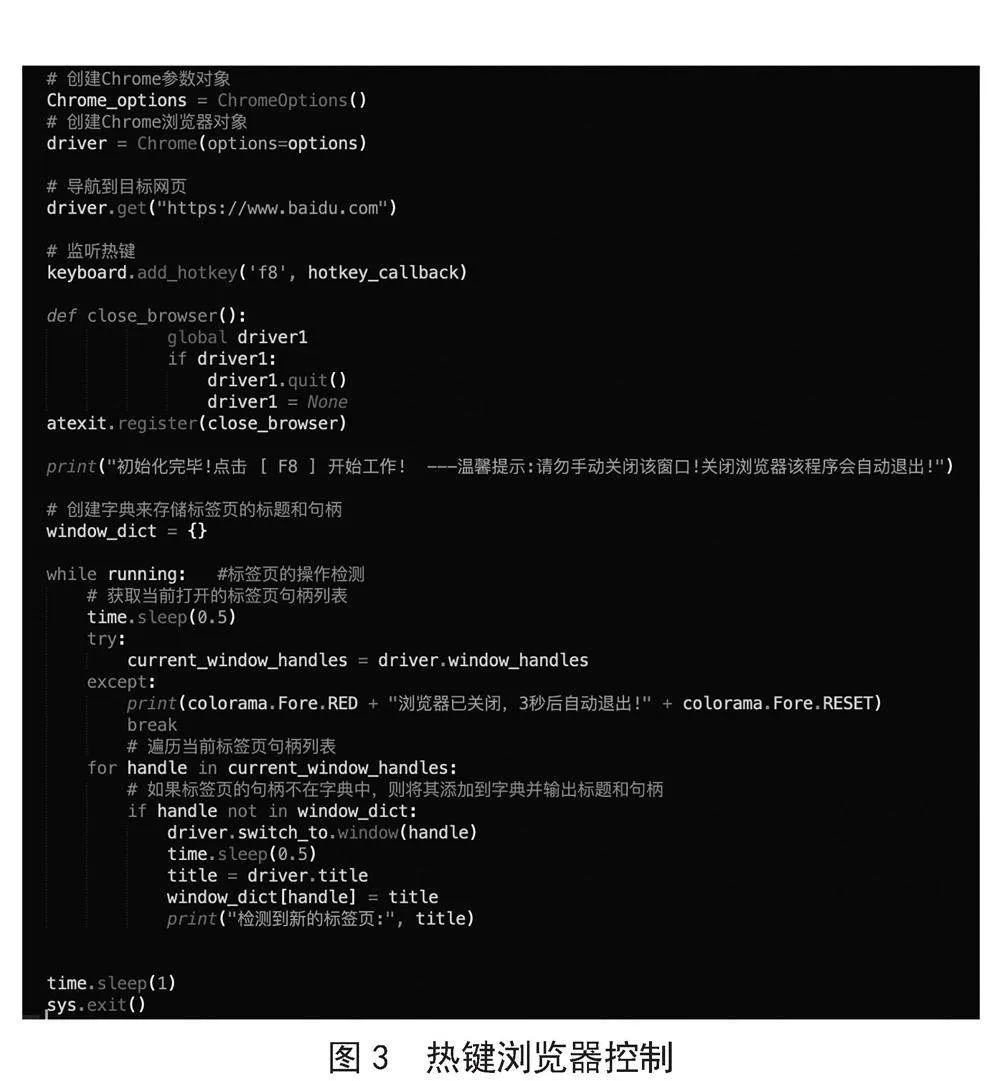
使用Python的Selenium库扩展undetected_chromedriver来启动Chrome浏览器,并监听热键(F8键)来触发一个功能回调函数(hotkey_callback)。同时,注册一个在程序退出时关闭浏览器的回调函数(close_browser)。
代码说明:使用Python的Selenium库的扩展undetected_chromedriver来启动Chrome浏览器以实现绕过爬虫目标网页的“反爬虫机制”[6]。
通过driver.get()方法导航到百度网页(https://www.baidu.com)。方便用户操作。
使用keyboard库(前提是已经导入keyboard库)监听热键F8,并在按下F8时触发hotkey_callback回调函数(主要功能函数,获取、解析网页源码以及ChatGPT交互等功能都包含其中,下文详细介绍)。
创建close_browser函数用于关闭浏览器。在程序退出时,通过atexit.register()方法注册close_browser函数,确保在程序退出前关闭浏览器。
输出提示信息,告知用户按F8键开始工作,并提醒不要手动关闭程序的窗口,因为浏览器会在需要时自动退出。
创建字典(命名为window_dict)来存储已打开标签页的标题和句柄,方便标签页的控制切换。
接下来是一个while循环,该循环会持续运行(直至回调函数因错误中断),用于监测新标签页的操作。
跳出循环后,代码通过time.sleep(1)等待1秒,然后调用sys.exit()来退出程序。
具体代码如图3所示。
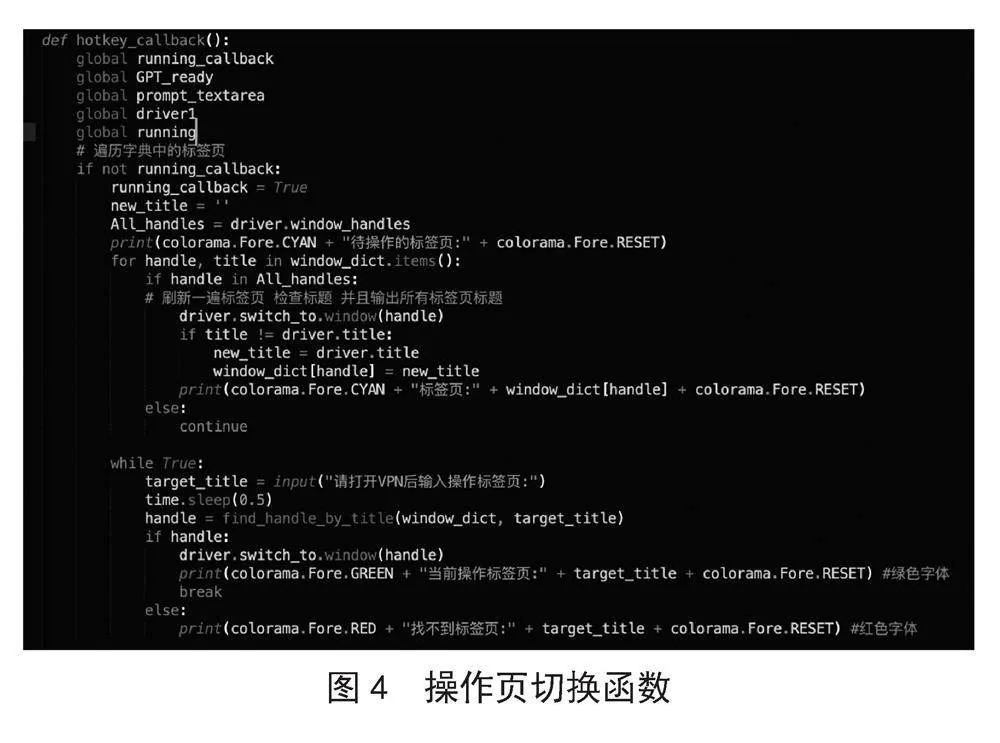
回调函数功能分块解析1)切换至操作标签页代码说明:声明5个全局变量:running_callback用于检测回调函数是否正在调用,如果为真则F8无效,防止回调函数同时多次调用导致程序混乱;GPT_ready用于检测是否已经登录ChatGPT,如果为真则无须再次启用无头浏览器用于ChatGPT的交互;prompt_textarea用于ChatGPT的文本框交互;driver1即无头浏览器实例,因整个程序仅一次使用,所以声明为全局变量;running用于回调函数作为子线程对主线程的操控,当回调函数遇到错误时方便及时关闭程序。2)列出所有已经打开的标签页,供用户选择爬虫的标签页并切换至该页面进行操作。同时提醒用户打开VPN以供后续的ChatGPT交互使用。获取和解析页面内容。
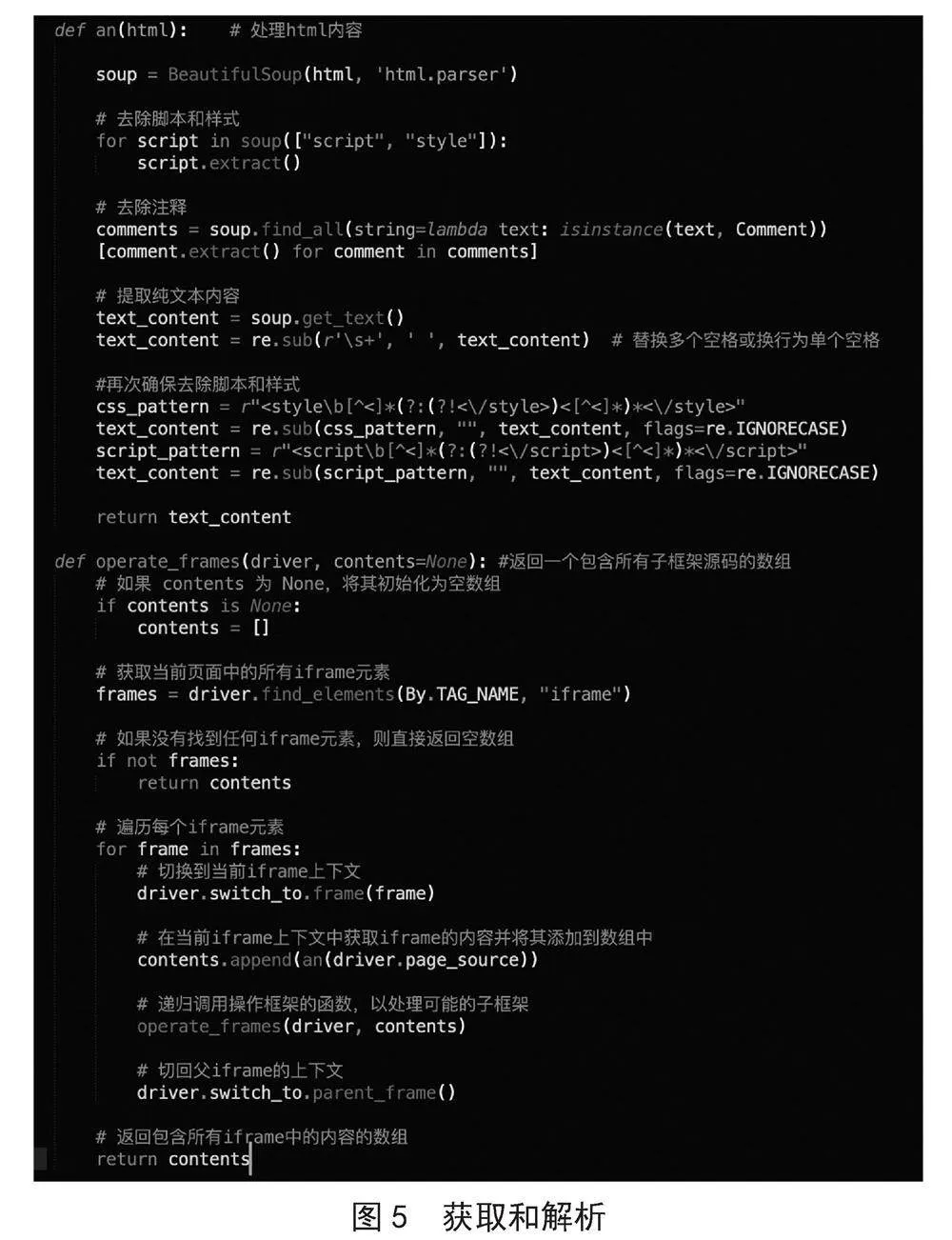
具体代码如图4所示。
代码说明:an函数利用bs4解析网页源码[7],然后去除对于爬虫无关的脚本、样式、注释等内容,并提取页面纯文本内容。operate_frames函数以递归的形式提取页面所有子框架的内容[8]。二者结合即可提取用户操作页的所有文本内容,为后续工作做准备。
具体代码如图5所示。
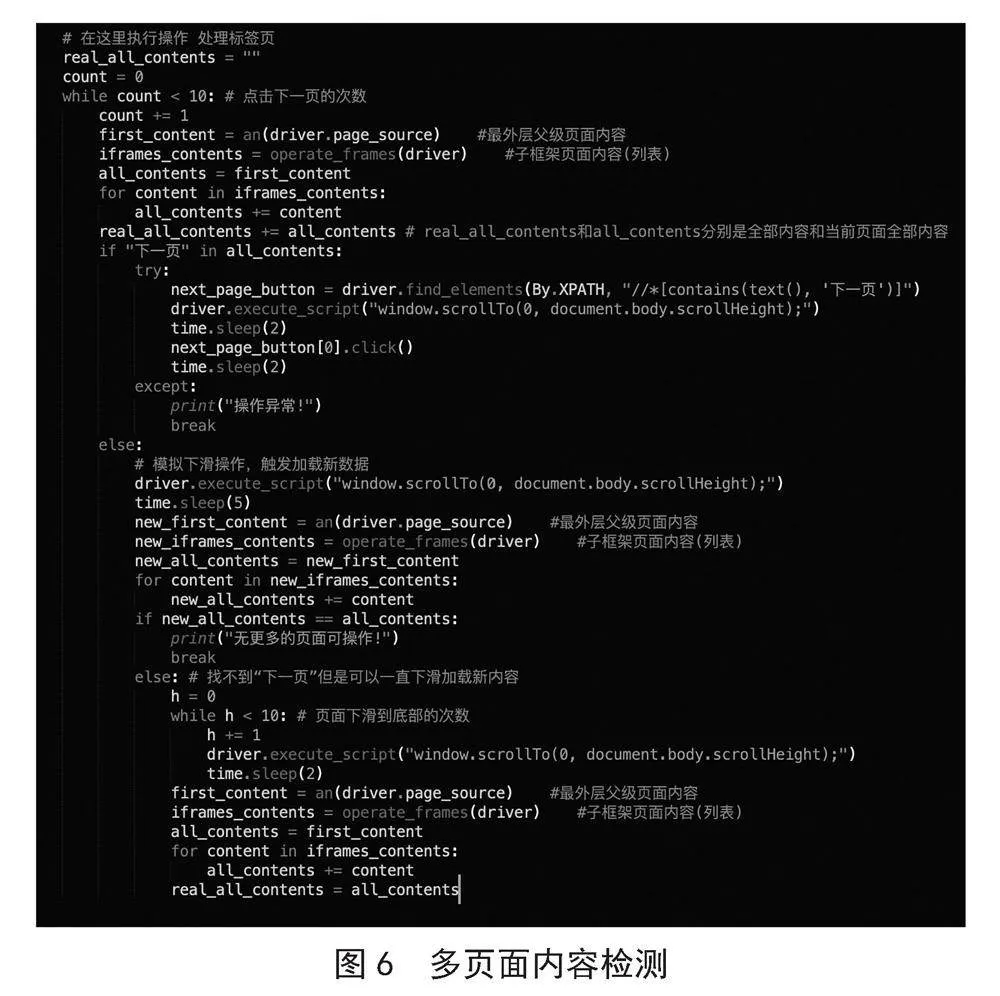
检测爬取的网页是否存在多页面代码说明:通过获取到的页面纯文本内容,首先检测是否存在“下一页”,如果存在,则循环执行“翻至页面底部,然后点击下一页”的操作,循环次数可调整。如果不存在,首先判断翻至页面底部是否会加载出新内容,如果为真,则循环该操作,以获取更多数据,循环次数可调整。如果为假,则跳出循环,只取单页面内容进行操作。通过Selenium操作无头浏览器,登录ChatGPT。
该过程代码简单,只需根据登录的步骤一步步自动化操作即可。其过程采用显式等待的方式,等待网页元素加载完毕后进行继续操作。显示等待时间可调,避开了因网络原因等待时间过短而程序崩溃的弊端。
具体代码如图6所示。
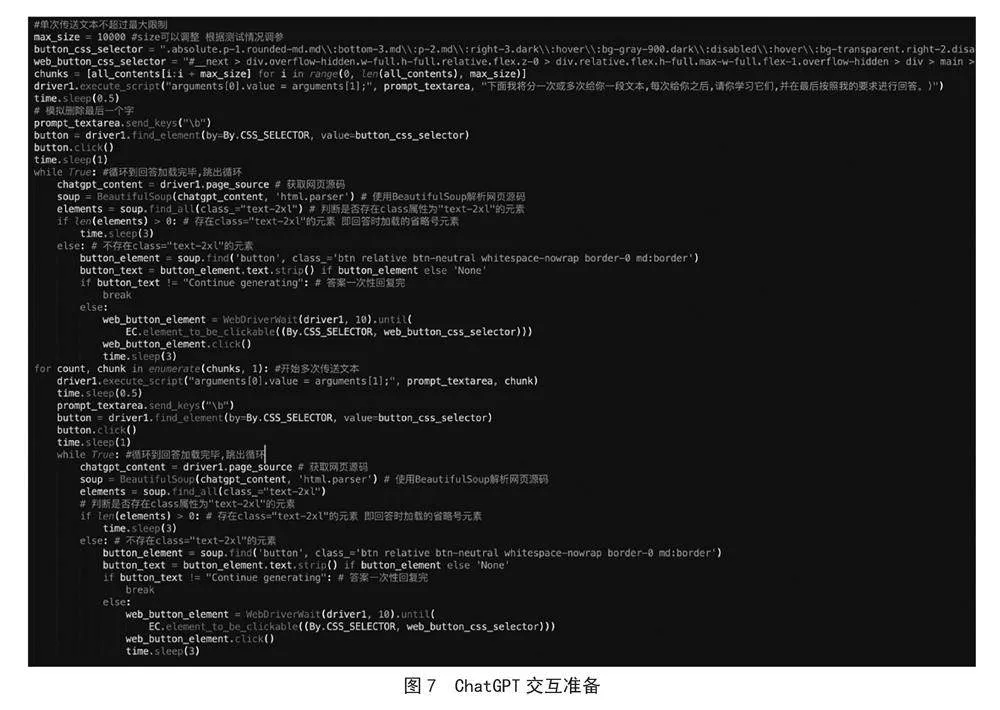
通过Selenium操作无头浏览器与ChatGPT对话。首先将前述步骤获取的文本内容传送至ChatGPT让其学习,然后让用户输入爬取数据的要求,将用户的要求提交给ChatGPT。待ChatGPT回答结束后,再将完整的答案打印出来给用户。
因ChatGPT每次提问的字数有限,故将前述步骤获取的文本内容分割为多个短文本,再依次提交给ChatGPT。
代码说明:当ChatGPT持续输出答案时,对话框有一个动态显示的省略号元素,当ChatGPT回答完毕时,省略号元素随之消失。间隔较短时间内循环获取网页源码,判断该元素是否存在即可判断ChatGPT输出结束,随后进行后续操作。
当ChatGPT输出结束时,如果回答不完整,则会有文本为Continue Generating的按钮出现,如果回答完整,则会有文本为Regenerate的按钮出现,用于重新获取答案。依据此即可判断ChatGPT对话完毕。
具体代码如图7所示。
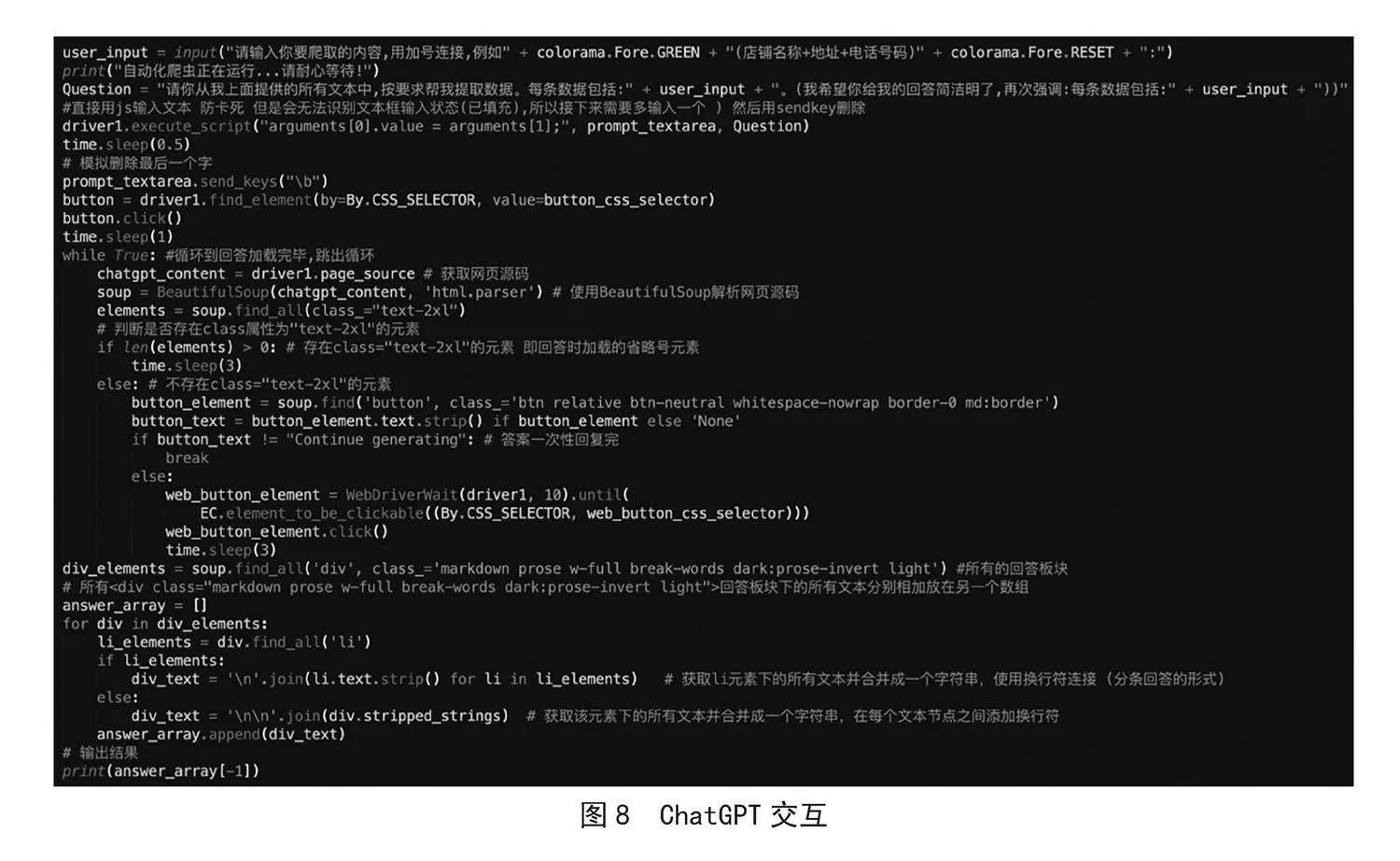
接下来让用户输入爬虫要求,并与ChatGPT交互代码说明:经过对ChatGPT的元素审查,所有的回答class名称一致,因此只需筛选出所有的回答存放至一个数组,并在每次对话完毕后取数组最后一个元素输出即可输出爬虫结果。
最后,如果用户对答案不满意,系统设置了三次机会重新获取答案,答案输出完毕返回给用户时,系统会提问用户对爬虫结果是否满意,若不满意,第一次系统会自动点击Regenerate重新获取答案返回给用户,第二次、第三次允许用户自行补充要求(即自行与ChatGPT对话)以获取满意的答案。具体代码如图8所示。
3 实验和结果
3.1 网易新闻爬取测试
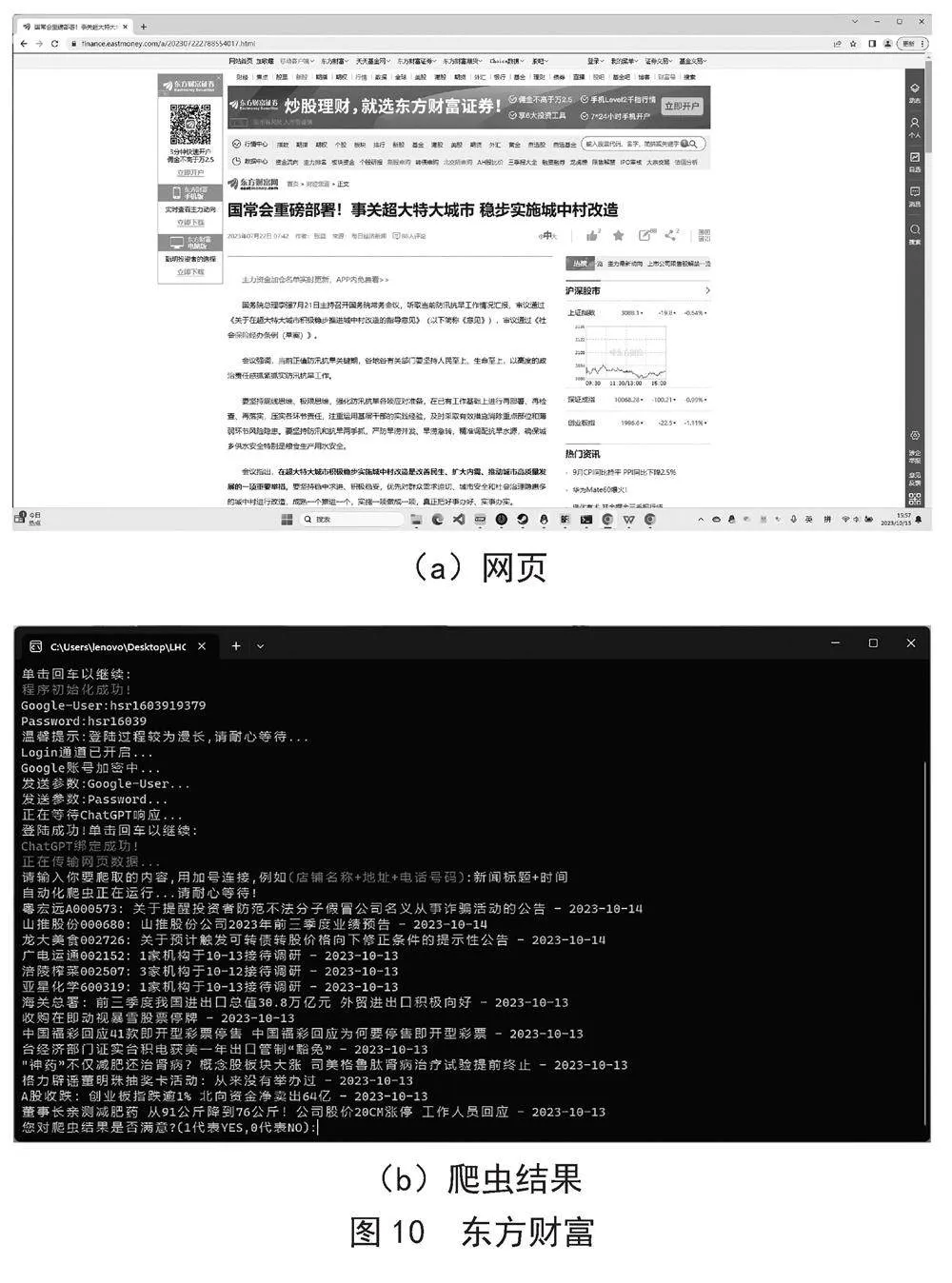
网站:网易新闻(https://www.163.com/news/article/IA8KMOIQ000189FH.html)。该试验对网易新闻进行爬虫,爬取内容为:新闻标题。网页截图和爬虫结果分别如图9(a)、图9(b)所示。
(a)网页
(b)爬虫结果
3.2 东方财富爬取测试
网站:东方财富(https://finance.eastmoney.com/a/202307222788554017.html)。该试验对东方财富进行爬虫,爬取内容为:新闻标题+时间。网页截图和爬虫结果分别如图10(a)、图10(b)所示。
(a)网页
(b)爬虫结果
3.3 微博爬取测试
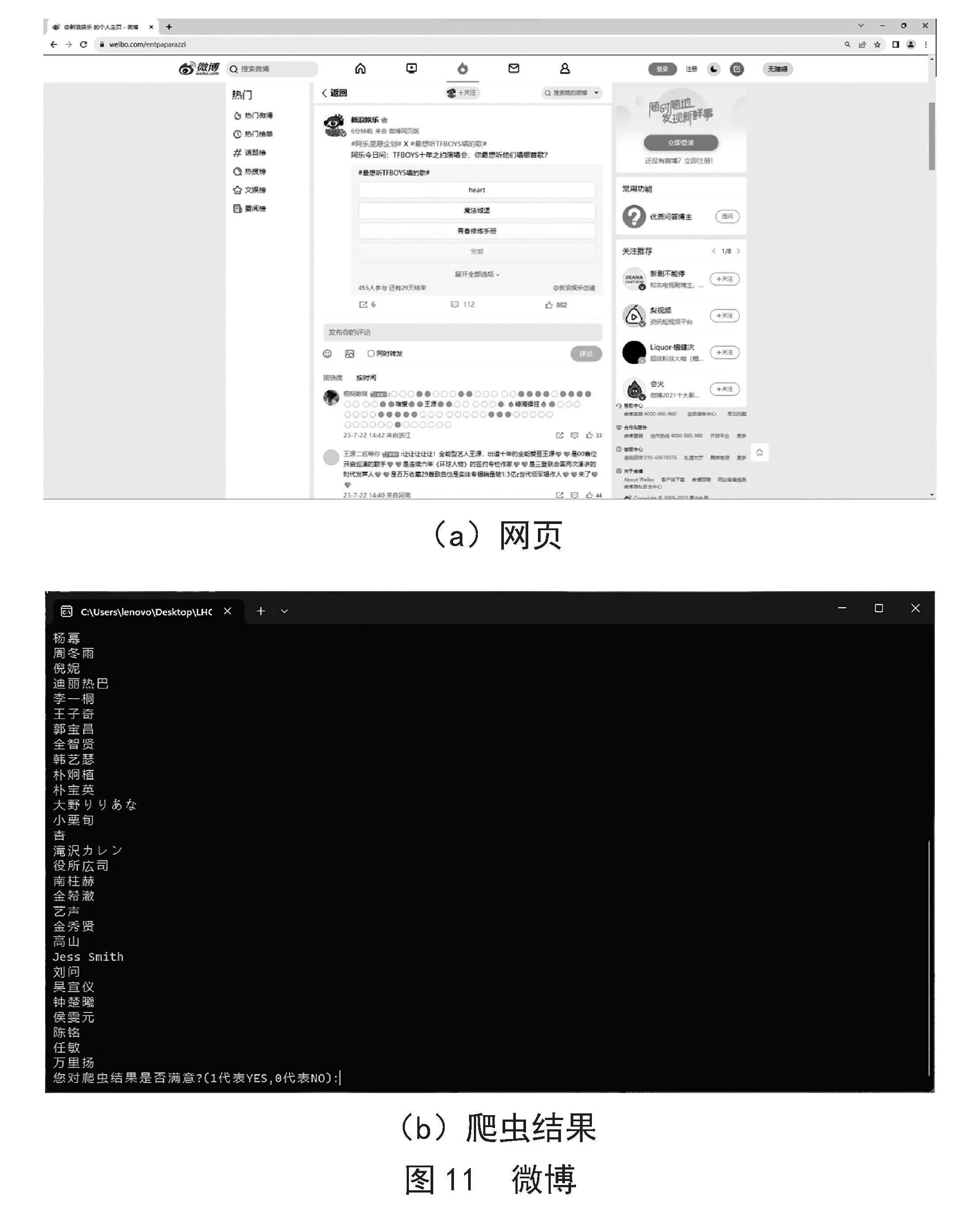
网站:微博(https://weibo。com/entpaparazzi)。该试验对微博进行爬虫,爬取内容为:明星姓名。网页截图和爬虫结果分别如图11(a)、图11(b)所示。
(a)网页
(b)爬虫结果
4 实验结果分析
本实验系统性地测试了ChatGPT与Selenium的自动化爬虫功能。实验涉及自动化爬虫获取网页数据,并使用ChatGPT进行对话。在实验中,特别关注了以下问题和发现:
4.1 操作速度和简易性
实验揭示了连接ChatGPT以进行对话所需的时间较长的情况,其主要原因是受到Selenium自动化操作的限制[9]。尽管这一挑战难以优化,但Selenium操作的相对简易性使其成为启动对话的可行手段,仅需要用户登录即可。这对于那些不熟悉高度技术化操作的用户而言,是一个显著的优势。Selenium操作的相对简易性为用户提供了一种更加轻松的使用体验。
4.2 爬虫结果的准确性
在本实验中,自动化爬虫的运用为ChatGPT的交互引入了大量的网页数据,然而,这也带来了一些挑战,特别是在爬虫结果的准确性方面存在一些问题。这些问题一是源于ChatGPT的文本处理能力受到一定限制,难以有效处理爬虫提供的大规模数据。二是源于前期处理所得的网页内容文本语境较为空洞,难以有效提升其逻辑性。ChatGPT的文本理解能力受到文本语境和复杂性的影响,因此,在处理大量来自网页的数据时,其表现受到限制,影响了爬虫结果的准确性。
4.3 网页内容解析
在本次实验中,还发现了一些网页无法被爬取的情况,这通常与网页内容解析相关。网页的结构和内容呈现出多样性,因此需要采用个性化的解析策略,以尽量确保从每个网页中获取准确而有用的信息。这可能包括针对特定类型的网页设计定制的解析算法,以适应其独特的结构和数据呈现方式。这种定制化的方法有望为克服解析难题提供有效的解决方案。
4.4 未来的研究方向
未来研究方向可能包括但不限于:
1)对ChatGPT提问方式的进一步优化。通过改进提问方式,可以更好地引导ChatGPT理解用户意图,从而提高结果的准确性[10]。这可能包括更具体、清晰的问题陈述,以及合理的上下文设置,以缓解文本处理方面的挑战,引导ChatGPT生成更有信息价值的回应。优化ChatGPT的提问方式不仅有助于改善准确性,还可以提高用户体验。通过精心设计问题,用户能够更有效地与ChatGPT互动,获取更有深度和洞察力的回答。这对于确保ChatGPT在应对复杂数据时能够更为可靠地发挥作用至关重要,为用户提供更加满意的交互体验。因此,在未来的研究中,进一步研究和优化ChatGPT的文本处理能力和对爬虫数据的适应性将是关键的方向。
2)网页内容解析技术的改进,通过探索新的解析方法和技术,或许能够发现更为灵活和智能的方式,从而提高爬虫的适应性和成功率。这种探索不仅可以帮助解决当前的问题,还能够为未来应对不断变化的网页内容结构提供更加可持续的解决方案。
最终,本文的主要目标在于提供一种创新的开发思路,展现了结合ChatGPT与Selenium自动化爬虫的潜在价值,以及简化信息挖掘的新路径。通过将自然语言处理与网络数据采集相结合,探索了一种整合性的方法,旨在为用户提供更直观、高效的信息获取体验。本文的实验部分也揭示了多个需要进一步优化的领域,包括操作速度、爬虫结果准确性和网页内容解析技术。这些问题为未来的研究和改进提供了重要的方向。期待未来的工作继续深入挖掘这些挑战,通过不断优化ChatGPT与自动化爬虫的集成,为用户提供更为智能和便捷的信息获取方式,推动信息技术领域的进步。
5 结 论
综上所述,本文致力于开发一种融合了ChatGPT的自动化爬虫系统,旨在为用户提供一种从网络页面中轻松高效地提取所需信息的解决方案。通过将深度学习和自然语言处理领域的前沿技术与自动化爬虫技术相结合,创造了一种简单且强大的工具,使普通使用者无须深入了解编程或底层技术也能够充分享受网络爬虫的便利。
本文的贡献在于:
首先,成功地将ChatGPT与自动化爬虫技术相融合,实现了一种简便高效的爬虫系统。这一系统的设计与传统的爬虫手段大相庭径,它大大地降低了用户的技术门槛,使更多人能够从庞大的信息海洋中提取所需的有价值的内容。用户无须深入了解编程或者底层技术,便能够轻松操作该系统,实现对网络数据的快速访问和提取。
其次,本文充分发挥了ChatGPT在文本处理方面的卓越能力,将其应用于信息提取过程,为ChatGPT的应用扩展提供了崭新的思路,为其应用领域注入了新的启发。通过巧妙地结合ChatGPT与自动化爬虫技术,不仅在信息挖掘领域探索了创新性的整合方式,而且为ChatGPT在实际应用中展现更广泛的可能性提供了范例。这种独特的结合为ChatGPT的应用场景带来了全新的视野,使新一代人工智能技术能够更灵活、高效地适应用户需求,为自然语言处理技术开创了更为广泛的应用前景。这种研究方法不仅强调了技术整合的重要性,也为未来ChatGPT应用的探索提供了有益的启示,为推动自然语言处理技术的发展和创新贡献了宝贵的经验。
此外,采用了Selenium技术实现了自动化爬取功能,摆脱了对ChatGPT API的依赖,从而保证了系统的可持续性。用户只需简单的操作,即可快速地获取所需信息,使得爬虫过程变得更加无缝和便捷。
在实验部分,展示了系统在不同数据源上的实际应用效果,证明了其在信息提取方面的可延伸性和发展前景。实验结果不仅验证了系统的可行性和实用性,还为系统未来的发展提供了有力的支持。
然而,本文所提出的系统仍存在一些局限性。例如,对于一些复杂的页面结构或内容,系统的性能可能会受到一定影响。此外,对于内容过多的数据源,可能需要针对性地调整交互方式才能获得最佳效果。
未来的工作方向可以包括进一步优化系统性能,提升对多样化页面的适应能力,以及针对大量文本的处理能力。总而言之,本文所开发的自动化爬虫系统为信息获取和处理领域带来了新的可能性,为普通用户提供了强有力的工具和支持。在技术不断发展的背景下,我们有理由相信这一系统将在未来取得更加显著的成果,为信息时代的发展做出持续的贡献。通过持续不断的改进和创新,可以更好地满足用户日益增长的信息需求,推动信息技术领域向前迈进。
参考文献:
[1] 游丽江.人工智能聊天机器人的影响分析及对策建议——以ChatGPT为例 [J].网络安全技术与应用,2023(12):128-130.
[2] 朱佳艺,刘从军.基于Selenium的自动化测试框架设计与实现 [J].软件导刊,2023,22(5):103-108.
[3] 高艳.基于Selenium框架的大数据岗位数据爬取与分析 [J].工业控制计算机,2020,33(2):109-111.
[4] 刘军.基于 Selenium 的网页自动化测试系统设计与实现 [D].武汉:华中科技大学,2014.
[5] 郭婺,郭建,张劲松,等.基于Python的网络爬虫的设计与实现 [J].信息记录材料,2023,24(4):159-162.
[6] 马军,王效武,朱永川,等.基于对抗样本生成的验证码反爬虫机制研究 [J].应用科技,2021,48(6):45-50.
[7] 鞠慧.热销图书爬取数据的BeautifulSoup库解析 [J].福建电脑,2021,37(5):133-134.
[8] 时永坤.基于WebDriver的定向网络爬虫设计与实现 [J].软件,2016,37(9):94-97.
[9] 李晨昊.基于BeautifulSoup+requests和selenium爬虫网页自动化处理的实现和性能对比 [J].现代信息科技,2021,5(16):10-12+18.
[10] 戴岭,赵晓伟,祝智庭.智慧问学:基于ChatGPT的对话式学习新模式 [J].开放教育研究,2023,29(6):42-51+111.
作者简介:刘逸凯(2002—),男,汉族,湖北武汉人,本科在读,研究方向:数据挖掘、逆向工程;通讯作者:吴瑰(1979—),女,汉族,湖北武汉人,高级实验师,硕士,研究方向:教学信息化管理。
收稿日期:2023-12-25
基金项目:2023年省级双创项目(2023zd109)