
摘 要:语音增强通过抑制背景噪音,提高语音质量和可理解性,进而提升语音相关产品的性能。针对SEGAN(Speech Enhancement Generic Adversary Network)模型在语音信号处理过程中缺乏全局关键信息的问题,提出了一种基于自注意力机制改进的生成对抗网络语音增强算法:SA-SEGAN(Self-Attention Mechanism Improvement Based on Speech Enhancement Generic Adversary Network)。SA-SEGAN运用自注意力机制对编码器的输出进行处理,以提取关注的空间与通道的重要全局信息,从而更完善地对语音信号进行处理,并采用Log-Cosh损失以更好地处理偏差较大的样本,同时引入分位数损失,赋予模型探索样本分布的能力。实验表明,SA-SEGAN相比SEGAN,在客观指标上提升10.9%。消融实验证实,实验中采用的三种方法均发挥积极作用。
关键词:语音增强;自注意力机制;智能语音处理;深度学习
中图分类号:TP183;TN912 文献标识码:A 文章编号:2096-4706(2024)14-0064-05
Improved SEGAN Speech Enhancement Based on Self-Attention Mechanism
TIAN Zihan, ZHANG Han, ZHOU Peiyong
(School of Computer Science and Technology, Xinjiang University, Urumqi 830017, China)
Abstract: Speech enhancement improves speech quality and understandability by suppressing background noise, thus improving the performance of speech related products. Aiming at the problem that SEGAN model lacks global key information in the process of speech signal processing, this paper proposes an improved generate adversarial network voice enhancement algorithm based on Self-Attention Mechanism: SA-SEGAN. SA-SEGAN uses the Self-Attention Mechanism to process the output of the encoder to extract the important global information of the space and channel of interest, so as to process the voice signal more perfectly. It also uses Log-Cosh loss to better process samples with larger deviation, and introduces Quantile Loss to endow the model with the ability to explore the distribution of samples. Experiments show that SA-SEGAN is 10.9% higher than SEGAN in terms of perceptual evaluation. And the ablation experiment confirms that the three methods used in the experiment play an active role.
Keywords: speech enhancement; Self-Attention Mechanism; intelligent speech processing; Deep Learning
DOI:10.19850/j.cnki.2096-4706.2024.14.013
0 引 言
在生产生活中,语音信号的传播会被各类噪音干扰。一般而言,在混合音频流中除了目标人声以外的所有音频成分,都会被认为是噪音干扰,在不同的环境下,噪音干扰的类型、强度都会有所不同。这些噪音会掩盖原有语音的特征,致使其质量下降,可理解性降低。这些噪音对我们日常生活中在线语音的交流带来了一定的困扰,因此,为了保证在较为嘈杂的环境中,语音信号仍保持较为良好的语音质量与可理解性,语音增强技术成为与语音信号处理的重要一环,近些年来语音增强算法由基于传统的信号滤波方法[1-3]转变为基于数据驱动的深度学习方法[4-8]。传统的信号滤波处理方法对非平稳噪音的抑制效果不佳,原因为其原理假设噪音为平稳线性的。神经网络可以通过学习与训练,更好地抑制非平稳噪音,近些年已逐渐成为主流方法。
1 相关工作
在单通道语音增强领域,通常会依据语音处理机制的不同,分为基于传统信号处理方法与数据驱动的方法,后者包括了机器学习与深度学习方法。
传统的信号处理语音增强算法,基于一定的假设,利用数字信号处理、线性代数与概率统计,对空间中的语音信号进行计算,求解出增强函数的表达式后,利用增强函数计算得到处理之后的降噪语音。这类方法包括谱减法[9]、维纳滤波法[10]、基于统计模型[11]的方法、子空间法等。在后一种利用数据驱动的方法中,包括利用机器学习与深度学习的两个方向。基于传统机器学习的方法有基于隐马尔可夫模型的方法、基于高斯混合模型的方法,而基于深度学习的单通道语音增强网络在2014年首次被提出[12],之后快速发展。
深度学习的语音增强算法又主要分为两种,一种是基于频谱掩蔽的方法,另一种是基于频谱映射的方法。在利用频谱掩蔽的方法中,其利用时频掩蔽值作为训练目标,最后借助掩蔽值恢复干净语音,最经典的掩蔽方法是理想二值法,即Ideal Binary Mask(IBM),相关工作也证明其在语音增强上有较好表现。基于频谱映射的方法与学习掩蔽码的方式不同,该方法直接学习输入与输出之间的映射关系,直接从带噪语音信号的频谱还原出干净语音信号频谱,是一个回归类型的问题。
SEGAN是由Pascual提出的一种先进的语音增强算法[13]。其由一种改进的生成对抗网络组成。通过对抗性训练,生成器可以逐渐学习并生成出更加逼真的语音,从而实现增强功能。本文利用SEGAN作为基线模型进行训练。
2 基于自注意力机制的SEGAN模型算法
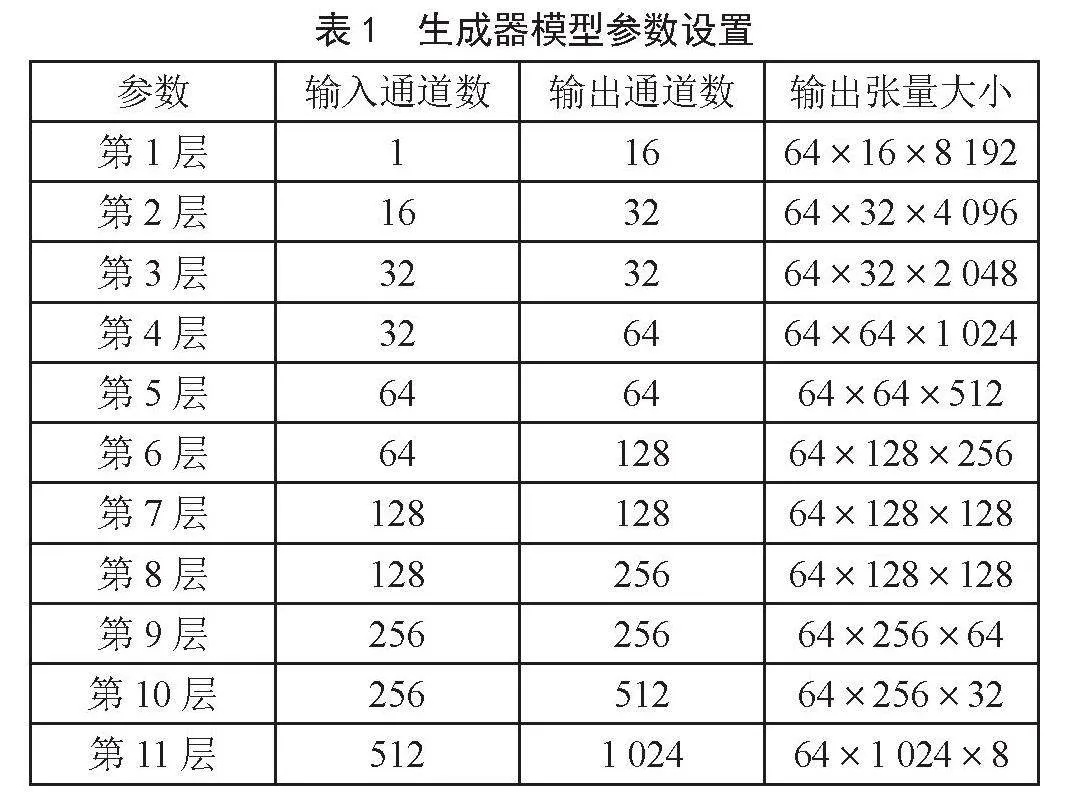
为了提升SEGAN的语音增强效果,本文结合自注意力机制和分位数损失,对原有模型进行了改进。改进的模型是由一个类似U-NET [14]结构的生成器和一个由多个卷积层、归一化层、激活层结构组成的鉴别器构成,模型架构图如图1所示。
2.1 增加自注意力的生成器模型
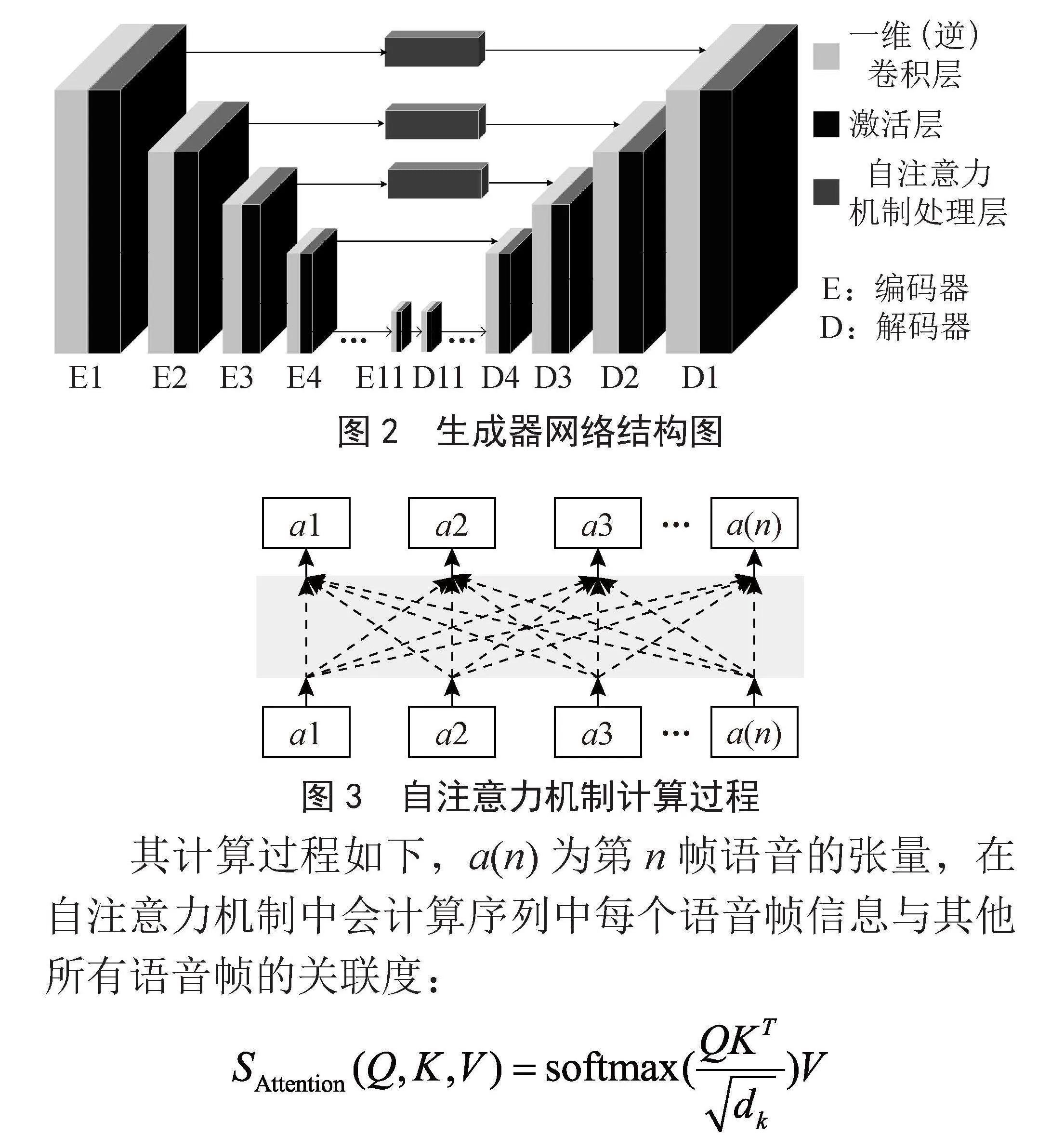
使用自注意力机制可以帮助模型更好地理解序列中的上下文信息,从而更准确地处理序列数据。本实验中的生成器结构与原始SEGAN的生成器的结构大体一致,是类似U-NET结构的一种基于编码器和解码器与层级之间的跳跃连接的神经网络。
该网络利用11个编码器与解码器对经过数据处理的语音信号进行增强。在本实验中,每个编码器利用卷积神经网络对输入的信号进行压缩和投影。被压缩的信号再通过PReLU激活函数进行处理,用作下一级解码器的输入。通过这11个解码器的压缩和降维处理,原来维度为64×1×16 384的语音信号最终降低为形状为64×1 024×8的中间向量,如表1所示。
这11个解码器的参数和输出形状分别为:每一层步长均为2,卷积核均为32。第一层输入通道为1,输出通道数为16,输出大小64×16×8 192;第二层输入通道为16,输出通道数为32,输出大小为64×32×4 096;第三层输入通道为32,输出通道数为32,输出大小为64×32×2 048;第四层输入通道为32,输出通道数为64,输出大小为64×64×1 024;第五层输入通道为64,输出通道数为64,输出大小为64×64×512;第六层输入通道为128,输出通道数为128,输出大小为64×128×256;第七层输入通道为128,输出通道数为128,输出大小为64×128×128;第八层输入通道为128,输出通道数为256,输出大小为64×128×128;第九层输入通道为256,输出通道数为256,输出大小为64×256×64;第十层输入通道为256,输出通道数为512,输出大小为64×256×32;第十一层输入通道为512,输出通道数为1 024,输出大小为64×1 024×8。
在经过处理后,这个中间张量与生成器输入的随机噪音进行相加,然后输入解码器中进行解码操作。解码操作是编码操作的逆向过程,是将形状为64×
1 024×8的中间张量通过逆卷积操作逐步还原为形状为64×1×16 384的语音信号。本实验采用的是类U-NET结构,故解码过程与编码过程高度对称,其逆卷积操作的各项参数与解码器的参数一一对应。相同层级的编码器与解码器之间有跳跃连接,用于传递原有信息,是处理后的数据能更好还原语音信号的原有特征。
但由于原有SEGAN网络的处理集中在相位谱上,遗漏了对相位的处理,不能较好地利用到相位带来的信息与特征。近些年,相关工作已经证实语音信号的相位信息可以为模型提供重要的空间信息[15-16],能对模型的性能有较大的提升,是幅度信息的重要补充。原SEGAN在捕获提取高维特征时,忽略了语音频谱图中的相位信息。相位信息在语音的空间信息与其他细节信息上有重要补充。本模型利用对频域的自注意力机制处理,对相位信息进行利用,以提升模型对语音的增强性能。注意力机制也被称为神经网络注意力,最早由Mnih提出[17],用于图像的处理。
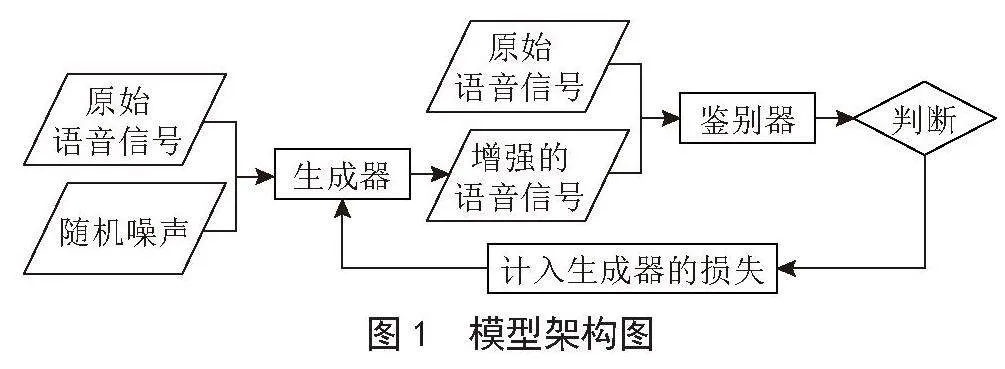
本文为了增加模型对全局相关性的利用,通过在SEGAN中引入注意力机制,关注输入的语音信号在全局的相关性。该模型的结构如图2所示,在SA-SEGAN中,需对前三层编码器增加注意力机制,其他结构与SEGAN基本保持一致,其中对自注意力机制的计算过程如图3所示。
其计算过程如下,a(n)为第n帧语音的张量,在自注意力机制中会计算序列中每个语音帧信息与其他所有语音帧的关联度:
经过自注意力机制处理的张量通过跳跃连接传输到对应层级的解码器,解码器利用跳跃连接传输的张量与前一级解码器输出张量作为输入,利用逆卷积网络,还原成原始信号,并再利用PReLU进行激活。
2.2 鉴别器
鉴别器在生成器的训练之后,将真实的干净语音与含噪语音与经过增强处理的语音和含噪语音,分别作为输入,来判断语音信号是否为真实的语音。但鉴别器并不参与整个模型的测试与运用。鉴别器来判断输入是否为真实语音,并使生成器从中学习,直至鉴别器无法辨别。这样生成器的输出就能更加接近真实语音的特征,减少因为处理带来的失真现象。从某种角度上看,鉴别器的作用类似于一种损失,让生成器的输出更加自然,接近真实语音。本模型鉴别器由卷积层、标准化层、激活层组成,共有11层,每层的大小不一样。
2.3 损失函数
在SEGAN模型中,在传统的生成器的损失函数中,引入了超参数α调控的L1范数,用以测定增强后语音信号与真实的语音信号之间的数值差异,使对抗模型在训练过程中有更高的真实度与细粒度。本实验,超参数α设置为100。
与以前SEGAN模型采用L2损失不同,本实验采用的是Log-Cosh损失函数:
其中:
相比原来采用的L2损失,Log-Cosh损失对离正常范围相比误差较大的样本的敏感性较低,更适合语音增强任务的训练。
与此同时,我们从Focal Loss for Dense Object Detection一文中受到启发,希望寻找一种类似于focal loss的损失函数,用来平衡样本之间的差异[18]。语音数据可能因为在不同的噪声、混响环境下录制而产生样本间差异,且不同说话人的口音与发音习惯也会带来样本间差异。我们在本文中引入了分位数回归损失,并以一定权重加入到原来的损失[19]。引入这个方法之后,训练的模型不仅仅关注对干净语音信号还原,而且通过探索整体分部,更好地让模型针对差异性样本进行训练。该损失函数的形式如下:
3 实验环节
3.1 数据集
为了让模型可以在实际复杂的语音环境中有较好的表现,本文采用了爱丁堡大学提供的开源数据集VoiceBank+Demand [20]作为实际数据,其中分为训练数据集和测试数据集。训练数据集有28个英语说话人的语音,合成的含噪语音中使用了10种噪音类型,其中8种来自DEMAND数据,另外2种来自人为合成,每个噪音以4种不同的信噪比:15 dB、10 dB、5 dB、0 dB与干净语音合成用以训练的带噪语音。该训练数据集共计11 572条,总时长9.4 h。
而测试集共有两名说话人,采用了5种噪声类型,这5种噪声全部来自Demand数据集,每段噪声以4种不同的信噪比:17.5 dB、12.5 dB、7.5 dB和2.5 dB与干净语音混合用以生成含噪语音。该测试集共有824条语音,总时长共0.6 h。
3.2 训练参数
本文的实验环境为64位Ubuntu操作系统,使用Python 3.9和Pytorch 2.0搭建了语音增加模块。本文使用的硬件为Intel(R)Xeon(R)CPU E5-2630 v4 @ 2.20 GHz为CPU,使用2张NVIDIA RTX 4090 GPU来训练模型。
在本实验中,对每一条语音采用的采样率均为16 kHz,分割语音的每一帧的帧长为25 ms,帧移为12.5 ms。在进行短时傅里叶变换和逆短时傅里叶变换过程中,采用汉宁窗,设置的窗长为16 384。在模型的训练过程中,学习率设置为0.000 2,Epoch的总数为100,batch size设置为64,使用Adam作为模型的参数更新优化器
3.3 评价指标
本文采用客观语音质量评估(Perceptual Evaluation of Speech Quality, PESQ)作为评价指标,其在国际电联盟的代号为ITU-T P.862其将参考信号和待测信号先进行电平调整,再进行预对齐,而后进行听觉变换,而后计算两个信号在频率和时间上累加的差值,映射到预测值上,其取值范围为-0.5~4.5,PESQ值越高则说明被测语音与干净语音相比,具有更好的语音质量。
3.4 实验结果
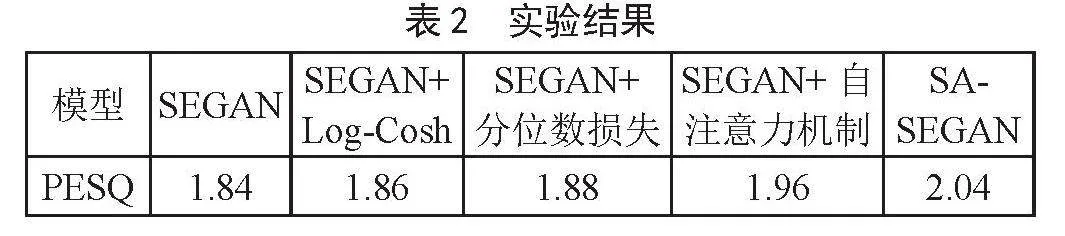
本实验使用了消融实验对模型的各个模块的作用作了评估。该消融实验共分为使用SEGAN,SEGAN+自注意力,SEGAN+自注意力+Log-Cosh损失,SEGAN+自注意力+Log-Cosh+分位数损失(SA-SEGAN)进行测试,其中测试结果如表2所示。
从实验结果中,我们发现本模型新增加的改进措施,每一个都对提升语音增强性能有贡献。其中使用自注意力机制的改进模型相较SEGAN模型在PESQ指标上提升6.52%;使用Log-Cosh损失代替L2损失,使得模型性能在PESQ指标上提升1.08%;引入分位数损失对模型的整体性能在PESQ指标上较基线模型提升2.17%。
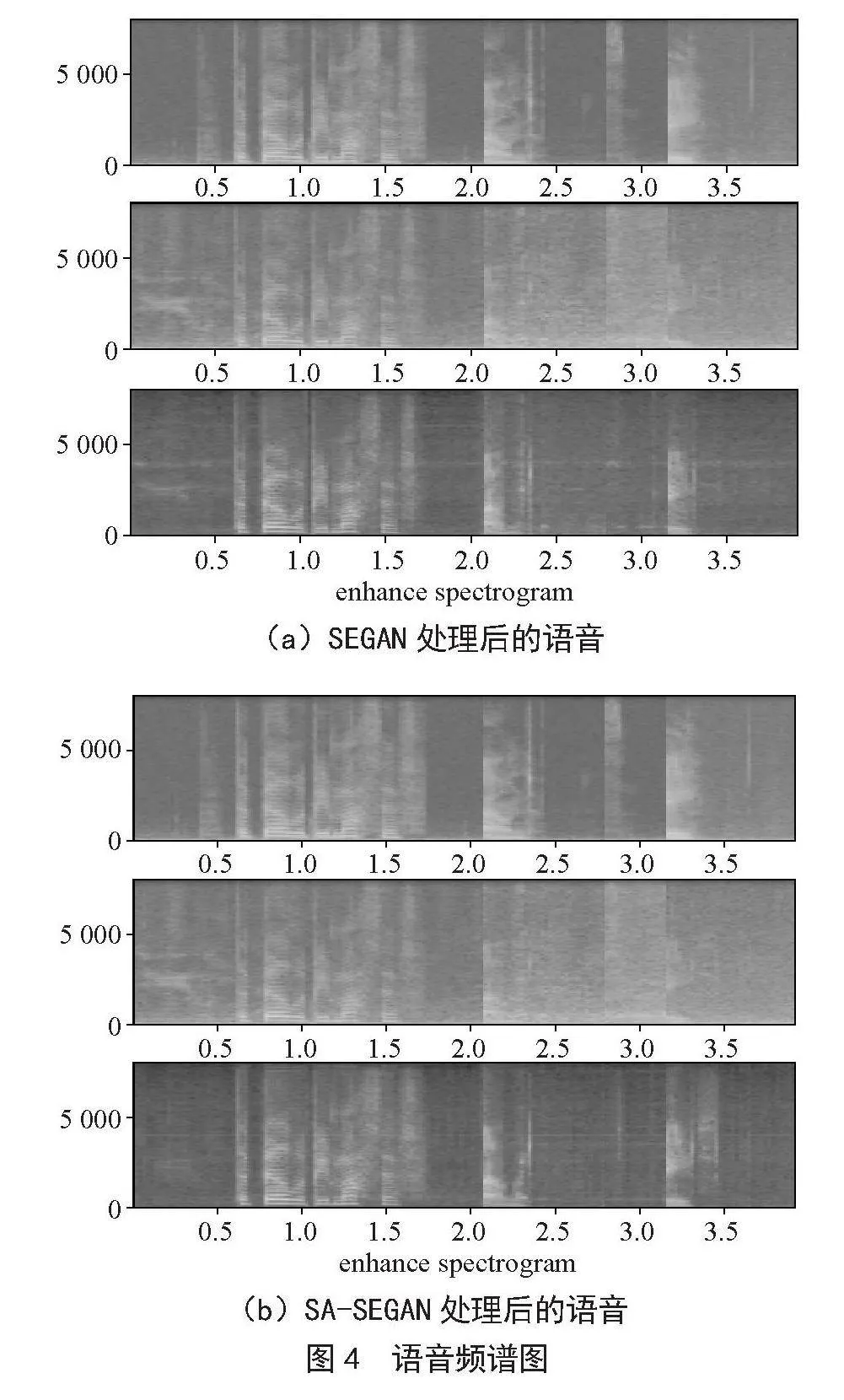
除此之外,我们对部分语音样本绘制语音频谱图进行性能分析。本文选取了一条语音在经过SEGAN和SA-SEGAN处理后的语音频谱图,如图4所示。
从语音频谱图中可以看出,本文提出的SA-SEGAN有效地抑制了大部分噪音,使语音的声学特征能较好地表现,较SEGAN在部分区域有更加完美的抑噪效果。
4 结 论
针对SEGAN模型算法中不能较好地利用频域的全局相关性,部分语言样本变差较大和语音数据样本中有一定的特征差异性,本文提出了一种利用自注意力机制的方法来改善SEGAN的性能。在此基础上将原有的L2损失替换为Log-Cosh损失,并引入分位数损失来增强对语音数据样本的处理,以更好地实现语音增强降噪功能。通过实验表明,本文提出的SA-SEGAN模型的性能指标在语音整体质量上有所提升,且每一种方法都是有效的,使用该模型可以提高语音质量,且有较强的泛化能力。
利用SA-SEGAN未考虑计算复杂度与提高相位信息的利用率。因此,未来的工作中将主要考虑使用复数卷积等方法提高对相位信息的利用,引入分频带处理,降低计算复杂度。
参考文献:
[1] 于海洋,张汝波,刘冠群.基于H∞一致性滤波的分布式语音信号增强 [J].华中科技大学学报:自然科学版,2015,43(S1):404-407.
[2] 马晓红,李瑞,殷福亮.基于信号相位差和后置滤波的语音增强方法 [J].电子学报,2009,37(9):1977-1981.
[3] 曹海涛.基于时频域分析的音频信号滤波与识别技术研究 [D].广州:广州大学,2016.
[4] ASTUDILLO R-F,CORREIA J,TRANCOSO I. Integration of DNN Based Speech Enhancement and ASR [C]//Interspeech 2015.Dresden:ISCA,2015:3576-3580.
[5] MIAO Y J,METZE F. Improving Low-resource CD-DNN-HMM Using Dropout and Multilingual DNN Training [C]//Interspeech 2013.Lyon:ISCA,2013:2237-2241.
[6] XIA Y Y,BRAUN S,REDDY C K A,et al. Weighted Speech Distortion Losses for Neural-Network-Based Real-Time Speech Enhancement [C]//ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP).Barcelona:IEEE,2020:871-875.
[7] TAMMEN M,FISCHER D,MEYER B T,et al. DNN-Based Speech Presence Probability Estimation for Multi-Frame Single-Microphone Speech Enhancement [C]//ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP).Barcelona:IEEE,2020:191-195.
[8] BU S L,ZHAO Y X,ZHAO T,et al. Modeling Speech Structure to Improve T-F Masks for Speech Enhancement and Recognition [J].IEEE/ACM Transactions on Audio, Speech, and Language Processing,2022,30:2705-2715.
[9] 樊一帆,张丽丹.强噪环境基于谱减法的录音数字音频信号降噪 [J].计算机仿真,2023,40(11):433-436+474.
[10] 陈修凯,陆志华,金涛.基于改进Berouti谱减法和维纳滤波结合的语音增强算法 [J].无线通信技术,2020,29(2):1-5+11.
[11] 王浩.基于统计模型后滤波的麦克风阵列语音增强方法 [D].广州:华南理工大学,2016.
[12] XU Y,DU J,DAI L-R,et al. An Experimental Study on Speech Enhancement Based on Deep Neural Networks [J].IEEE Signal Processing Letters,2014,21(1):65-68.
[13] PASCUAL S,BONAFONTE A,SERRÀ J. SEGAN: Speech Enhancement Generative Adversarial Network [J/OL].arXiv:1703.09452 [cs.LG].(2017-03-28).https://arxiv.org/abs/1703.09452v2.
[14] RONNEBERGER O,FISCHER P,BROX T. U-Net: Convolutional Networks for Biomedical Image Segmentation [J/OL].arXiv:1505.04597 [cs.CV].(2015-05-18).https://arxiv.org/abs/1505.04597.
[15] HU Y X,LIU Y,LYU S B,et al. DCCRN: Deep Complex Convolution Recurrent Network for Phase-aware Speech Enhancement [J/OL].arXiv:2008.00264 [eess.AS].(2020-08-01).https://arxiv.org/abs/2008.00264v1.
[16] ZHAO S K,MA B,WATCHARASUPAT K N,et al.
FRCRN: Boosting Feature Representation Using Frequency Recurrence for Monaural Speech Enhancement [J/OL].arXiv:2206.07293 [cs.SD].(2022-06-15).https://arxiv.org/abs/2206.07293.
[17] MNIH V,HEESS N,GRAVES A,et al. Recurrent Models of Visual Attention [J/OL].arXiv:1406.6247 [cs.LG].(2014-06-24).https://arxiv.org/abs/1406.6247v1.
[18] LIN T-Y,GOYAL P,GIRSHICK R,et al. Focal Loss for Dense Object Detection [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2020,42(2):318-327.
[19] HARDY R. Quantile Regression: Loss Function-cross Validated [EB/OL].(2016-12-14).https://stats.stackexchange.com/questions/251600/quantile-regression-loss-function.
[20] THIEMANN J,ITO N,VINCENT E. The Diverse Environments Multi-channel Acoustic Noise Database: A Database of Multichannel Environmental Noise Recordings [J].The Journal of the Acoustical Society of America,2013,133(5):3591.
作者简介:田子晗(2004—),男,汉族,江苏南京人,本科在读,研究方向:智能语音处理;张涵(2004—),女,汉族,新疆石河子人,本科在读,研究方向:电子信息工程;周培勇(1975—),男,汉族,江苏泰兴人,讲师,硕士,研究方向:通信与信息系统。
收稿日期:2023-12-14