摘 要:对话关系抽取旨在预测对话文本中的实体对之间的关系。在多方对话场景中,由于角色信息的不确定性,传统的实体关系抽取方法面临准确性挑战。针对角色信息不明的问题,模型构建了对话文本异构图,以捕捉多方对话的复杂结构。此外,为了有效处理不同对话轮次中的说话者信息,引入了长短时记忆网络进行特征处理,并将这些特征嵌入到相应的句子节点中。在DialogRE数据集上的实验显示,该模型展现了出色的性能,具体体现在F1和F1c分别达到了66.8%和62.2%,从而验证了其优越性。
关键词:关系抽取;多方对话;角色信息;异构图
中图分类号:TP391.1 文献标识码:A 文章编号:2096-4706(2024)15-0042-05
Multi-party Dialogue Entity Relation Extraction Incorporating Speaker Position Heterogeneous Graph
ZHENG Siyuan
(School of Computer Science and Mathematics, Fujian University of Technology, Fuzhou 350118, China)
Abstract: Dialogue Relation Extraction aims to predict the relationship between entity pairs in dialogue texts. In multi-party dialogue scenarios, traditional methods of entity relation extraction face accuracy challenges due to the uncertainty of role information. To address the issue of unclear role information, the model constructs a heterogeneous graph of dialogue texts to capture the complex structure of multi-party dialogue. Moreover, in order to handle the speaker information effectively in different rounds of dialogue, the Long Short-Term Memory network is introduced for feature processing and these features are embedded into the corresponding sentence nodes. Experiments on the DialogRE dataset demonstrate the outstanding performance of model, specifically reflected in achieving F1 and F1c scores of 66.8% and 62.2% respectively, thus confirming its superiority.
Keywords: relation extraction; multi-party dialogue; role information; heterogeneous graph
0 引 言
对话关系抽取是自然语言处理领域的一项关键任务,随着社交媒体和在线对话数据的爆炸性增长,人们在互联网上的广泛互动,对话成为人们表达观点、分享信息和建立联系的主要方式。社交媒体平台上海量的对话数据,蕴含了人们的思想、情感和互动方式。但由于其碎片化、非结构化的特性,要想从中准确抽取有意义的对话关系变得复杂而具有挑战性。因此,对话关系抽取成为研究者们关注的焦点之一[1]。在这一领域研究中,Yu等人提供了DialogRE对话数据集[2]。该数据集致力于对话关系抽取任务并提供真实场景的数据,为研究者提供了一个丰富的对话语境,涵盖了多个领域和主题。通过引入对话关系标注,使得研究者能够更全面地理解对话中实体之间的关系,并推动了该领域的研究进展。研究者利用DialogRE数据集进行模型训练和评估,探索了不同深度学习架构、图神经网络以及预训练模型在对话关系抽取任务上的性能。
对话关系抽取面临的主要困难在于多方对话中涉及多个说话者,每位说话者可能在对话中扮演提问者或回答者的角色,而且其角色在对话过程中可能频繁转变。这种非线性的交互模式使得关系抽取任务更加具有挑战性,因为不同说话者在不同语境中表达观点或提出问题,需要模型能够灵活地捕捉这种复杂的关系。传统的问答格式无法很好地适应这种多样性和灵活性,因此需要更全面且适应性强的模型来准确地抽取对话中实体之间的关系。在此背景下,融合说话者位置信息异构图的对话实体关系抽取模型提供了一种有效的解决方案,能够更全面地考虑多方对话中的说话者多样性和角色变化。
1 相关工作
近年来对话实体关系抽取任务的研究主要集中在基于图神经的模型构建。Xue等人[3]通过将对话文本构建为高斯多视图,捕捉对话文本中词语之间可能存在的关系。由于多视图的初始构建为全连接图,模型缺乏理解上下文能力。Ghosal等人[4]提出了对话关系图卷积模型,通过将对话信息构建为图节点,利用图卷积对关系图聚合对话有关联中的对话信息。王琪琪等人[5]考虑到对话中不同轮次语句的差别,根据对话的特点构建情景对话图。将对话句子作为图节点,节点之间边的权重通过句子间距离决定。Lin等人[6]通过对触发词的预测提高关系抽取能力,引入注意力机制关注文本的关键信息和触发词信息。自彦丞等人[7]针对对话关系抽取任务中的关系重叠的问题,引入动态机制利用触发词信息进行推理。Duan等人[8]通过自适应触发词融合模块和标签感知知识的引入,利用触发词信息避免噪声引入,有效提升标签感知引导对话实体关系抽取。然而现有的对话关系抽取方法大多忽视了对话参与者的角色信息,限制了对复杂对话结构的深入理解。随着对话场景的多样化和开放性的增加,多方对话中涉及的角色信息变得复杂和不明确。在多轮对话中,经常出现同一实体在不同轮次中具有不同的说话者标识,或者同一说话者在不同轮次中涉及不同的实体关系。这种多方对话中的角色信息不明确使得现有大多模型在这类场景下表现欠佳。Ishiwatari等人[9]在关系图上进行改进,在图上加入说话者信息并通过图注意力机制对关系图进行处理,保留说话者信息,提升模型的上下文理解能力。Lee等人[10]通过引入对话轮次上下文感知机制,编码说话者信息并采用多头注意力提取轮次表示,考虑轮次节点和说话者联系的序列特性构建异构对话图,模型的性能取得提升。徐洋等人[11]使用图注意力网络模型,通过构建说话者节点并将外部数据源与人物指代信息相融合,以提升关系抽取的准确度。
2 模型设计
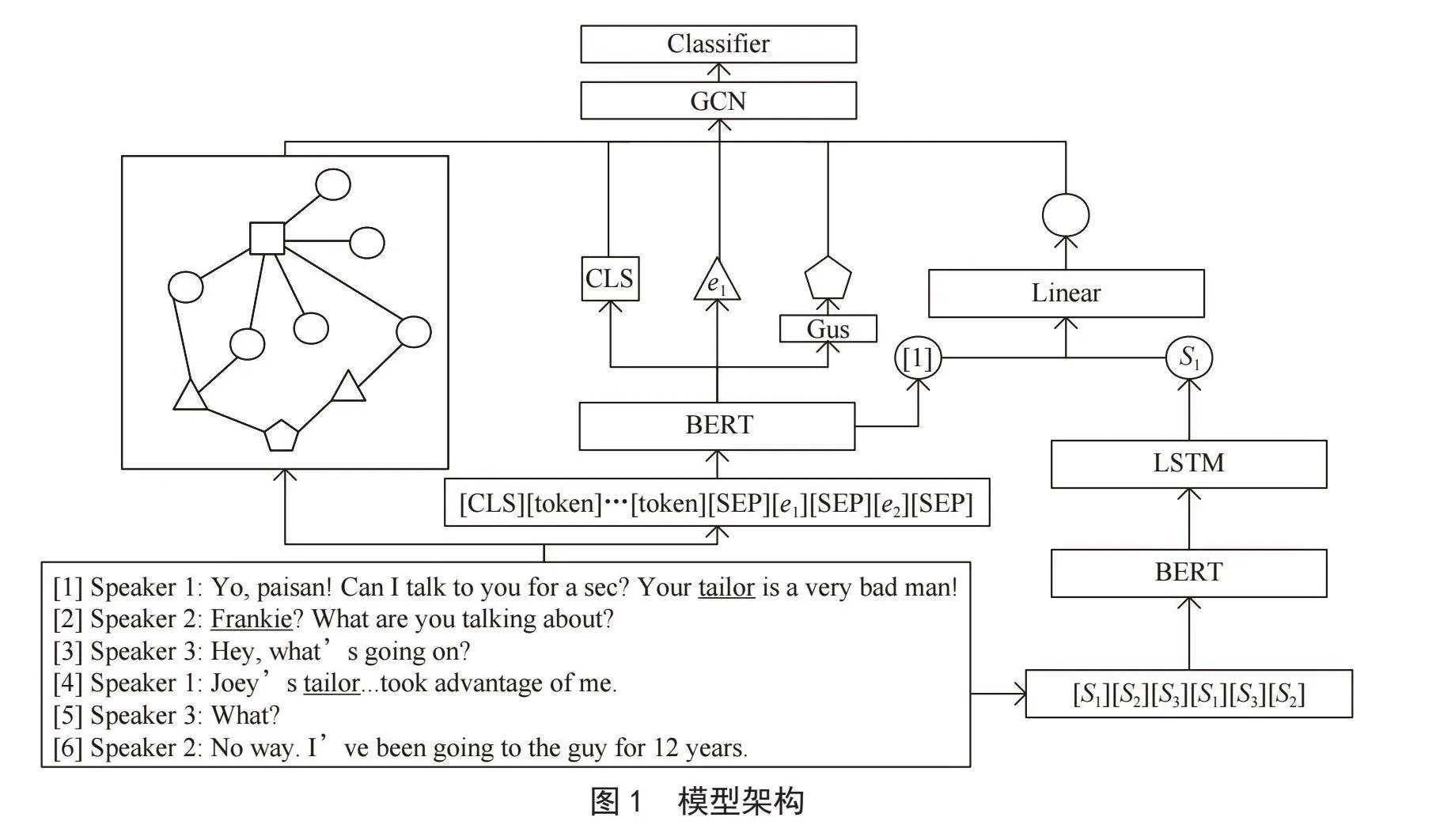
本文介绍的模型主要包括对话信息提取和异构图神经网络两个关键部分,如图1所示,首先利用BERT(Bidirectional Encoder Representations from Transformers)[12]提取对话文本及参与者信息,以此来把握上下文含义并识别说话者身份,同时捕捉其随时间变化的序列依赖性。这一过程结合了BERT模型和LSTM(Long Short-Term Memory)的优势,有效地整合了对话内容和说话者信息。接下来,基于这些提取的信息,构建了一个对话异构图,进而采用异构图卷积网络来分析文本中的实体及其之间的复杂关系。通过这种方式,模型综合考虑了文本内容和说话者角色,为分类任务提供了一个全面的视角,从而能够更准确地抽取和识别对话中的实体关系。
2.1 对话信息提取
本节详细阐述了两种不同的编码策略,旨在有效处理涉及多个参与者的对话文本。这两种策略分别从各自独特的角度提取对话内容的特征以及说话者的信息,进而促进了对话文本的深入分析和理解。
2.1.1 对话文本信息
本文采用BERT模型作为文本编码器,旨在从对话文本中提取关键特征。将对话视为一系列相互关联的交流轮次,每轮包括一个参与者及其发言,表示为D = {Sp1:u1,Sp2:u2,…,Spn:un}。这种结构化的表示有助于捕捉对话的流动性和复杂性。研究的核心目标在于利用这种对话结构来预测两个实体之间可能存在的联系。为此,将其输入编码为X1 = {[CLS]D[SEP]a1[SEP]a2[SEP]},不仅包括了对话文本本身,还将对话中提到的两个实体(a1,a2)整合在一起。为了模型可以区分对话内容和实体信息,采用[CLS]和[SEP]标记。[CLS]用于分类任务开始,[SEP]分隔对话内容和实体信息。将编码输入到Bert模型中获得文本向量表示,如式(1)所示:
(1)
其中E ∈ RN×d为经过BERT编码后的文本词嵌入,e为每个标记的向量表示。N为X1中所含元素的总个数,d为BERT输出向量维度。t为D中标记总数。
2.1.2 说话者信息
以图1为例,本部分着重于在处理对话文本时捕捉说话者信息的方法。具体操作中,首先对对话文本中的每个说话者进行编码,生成一个特定的输入编码X2 = {[S1][S2][S3][S1][S3][S2]}。然后,这个输入编码被作为输入数据传递给BERT模型进行处理。通过这种方式,模型能够在分析对话内容的同时,有效地识别并理解说话者的角色和特性,如式(2)所示:
(2)
为了更深入地挖掘和利用时间序列数据中的信息,采取了对输出向量进行LSTM处理的策略。通过将LSTM网络引入到处理流程中,理解说话者在不同顺序轮次的状态,揭示出说话者序列数据中的深层次模式和关联,获得说话者向量表示S。具体如式(3)所示:
(3)
2.2 对话异构图
异构图方法在对话文本的实体关系抽取中通过融合多样节点和边,优化了实体及其关系的表示,提高了信息检索和图推理效率。这种方法支持多任务学习,改善少样本性能,增强模型解释性,为实体关系的理解和处理提供了有效的方案。
2.2.1 节点构建
在构建异构图以分析和预测对话文本中的实体信息时,采用了一种包含四种类型节点的异构图模型。具体而言,本模型由对话轮次节点、关系特征节点、全局信息节点和实体节点组成。
对话轮次节点用于表示对话中的每个轮次,即一个说话者的完整表述。这些节点捕获对话特定时刻的信息,帮助理解对话的进展和上下文。节点特征由文本的词嵌入向量平均值和说话者信息拼接而成,经过线性层降维处理,如式(4)和式(5)所示:
(4)
其中,en为第i轮次中第n个词的向量,m为这个轮次中词的总数,Si为轮次i的说话者,hi为这轮次的整体语义特征的一个简单表示。
关系特征节点代表实体节点间的潜在关系特征,揭示实体如何相互作用和关联,增强模型对实体间交互的理解。这些节点通过多视图卷积构建,捕捉实体对的潜在关系,并使用GDPnet模型[3]获取这些特征,如式(5)所示:
(5)
全局信息节点hg是对话文本的整体信息的代表,它融合了文档级别的语义和结构特征,在模型中发挥关键作用。使用[CLS]标签的特征ecls作为代表,增强了模型对整体对话脉络和主题的理解和处理。
实体节点表示在对话文本中所需预测的实体信息。这些节点是模型预测工作的焦点,通过分析这些节点与其他类型节点的关系和互动,模型能够有效地识别和预测对话中的关键实体及其属性。为了表示这些实体节点,模型采用了特定的特征ea1和ea2作为he1和he2。
2.2.2 边构建
在构建异构图时,重点关注对话轮次节点、全局信息节点和实体节点,以及关系特征节点。这些节点通过边相连,边代表了节点间的关系和交互,是理解图的关键。具体来说:对话轮次节点与全局信息节点的连接映射了对话轮次与整体对话内容的关系,揭示每个对话轮次在整个对话中的作用和地位。实体节点与对话轮次节点的连接表示实体在特定对话轮次中的参与和作用,这有助于理解实体在对话流中的位置和语境。实体节点与关系特征节点的连接通过特定的关系或属性丰富实体的语义表示,捕捉实体间的复杂关系。
2.2.3 异构图卷积网络
异构图卷积网络HGCN(Heterogeneous Graph Convolutional Networks)是一种处理具有多种类型节点和边的图的神经网络。这种网络能够捕获图中不同类型的节点和边之间的复杂关系。对于每种类型的边,执行图卷积操作。如式(6)所示:
(6)
其中,l为异构图层数,Nr(v)为节点v在关系类型r下的邻居节点集合,R为边的关系类型集合, 为关系类型r在第l层的权重矩阵,σ为非线性激活函数。
将不同类型边的卷积结果通过简单的求和平均聚合起来,以更新每个节点的特征表示,如式(7)所示:
(7)
其中 R 为边的类型总数,这种方法在聚合时考虑了各类型边的平均贡献。重复式(6)和式(7),通过多层卷积来捕获更高阶的邻域信息。最后一层卷积的输出用于预测对话实体对关系。
2.3 分类层
异构图卷积操作能够捕获整个图结构中的关键信息,通过综合这些不同的信息并采用拼接操作,将这些特征向量合并成一个长向量送入到全连接网络中进行分类,如式(8)和式(9)所示:
(8)
(9)
3 实验与分析
3.1 数据集与评价指标
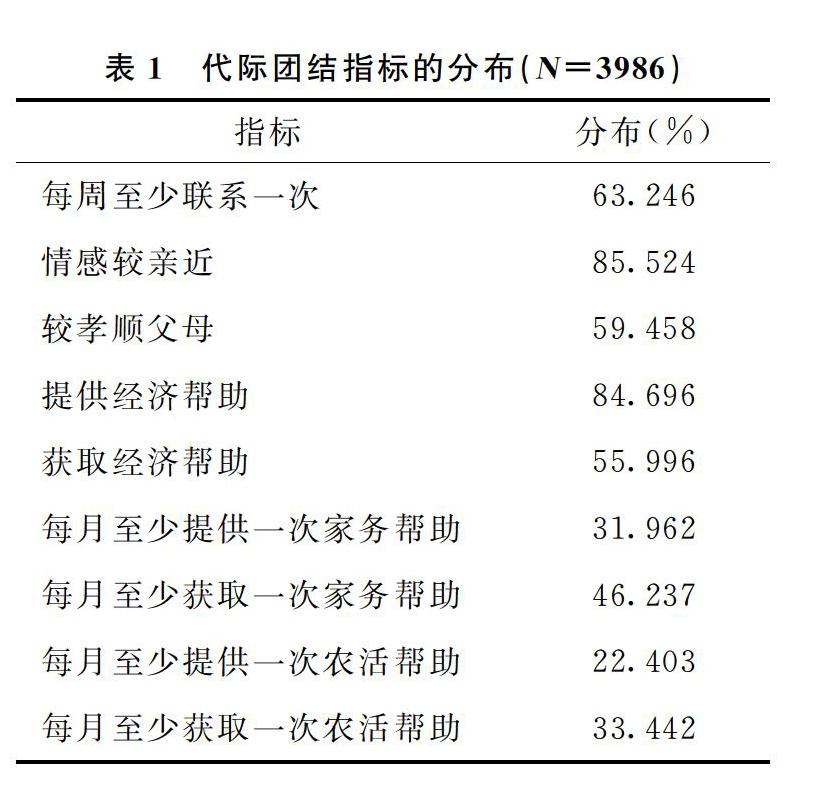
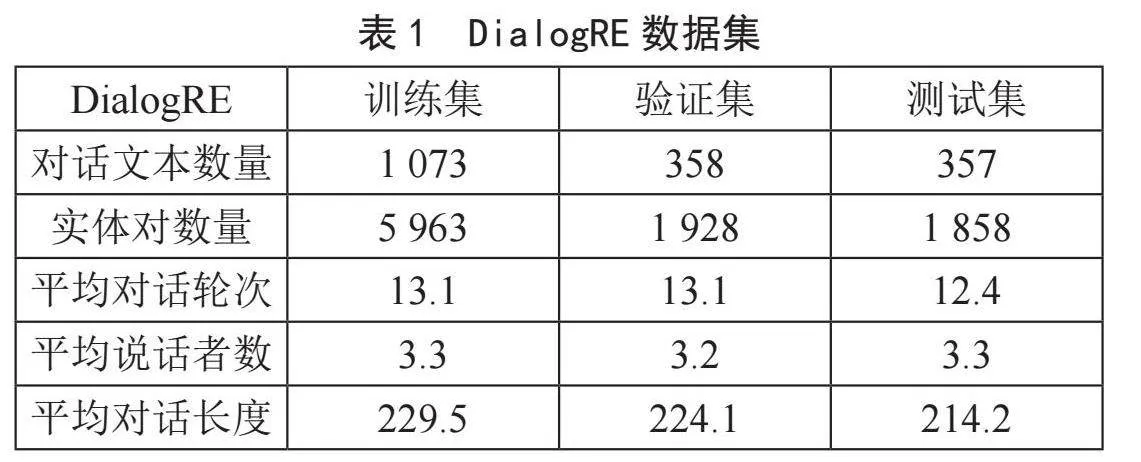
DialogRE数据集是一个专为对话关系抽取任务构建的数据集,该数据集涵盖了来自《老友记》的1 788个对话片段,总共标注了10 168个关系三元组,定义了37种实体关系,包括36个具体实体类别和一个表示无法确定具体类别的“un-answerable”类别。该数据集中包含了来自对话文本的实体关系三元组,其中实体是对话参与者,关系是他们之间的关联,每个对话都被注释为包含一系列关系事实,数据集详细信息如表1所示。
实验沿用DialogRE数据集中的评价指标F1和F1c。其中,F130e697d4866799d6ce498e8a06ad1ae3f5177fec40d8e3ed8e513cef8162d831是常见的评价指标,用于衡量模型的准确性。F1c是DialogRE数据集特有的一个评价指标,是对F1评价指标的一个扩展,用于更细致地评估模型在处理复杂对话场景中的性能。
3.2 实验训练
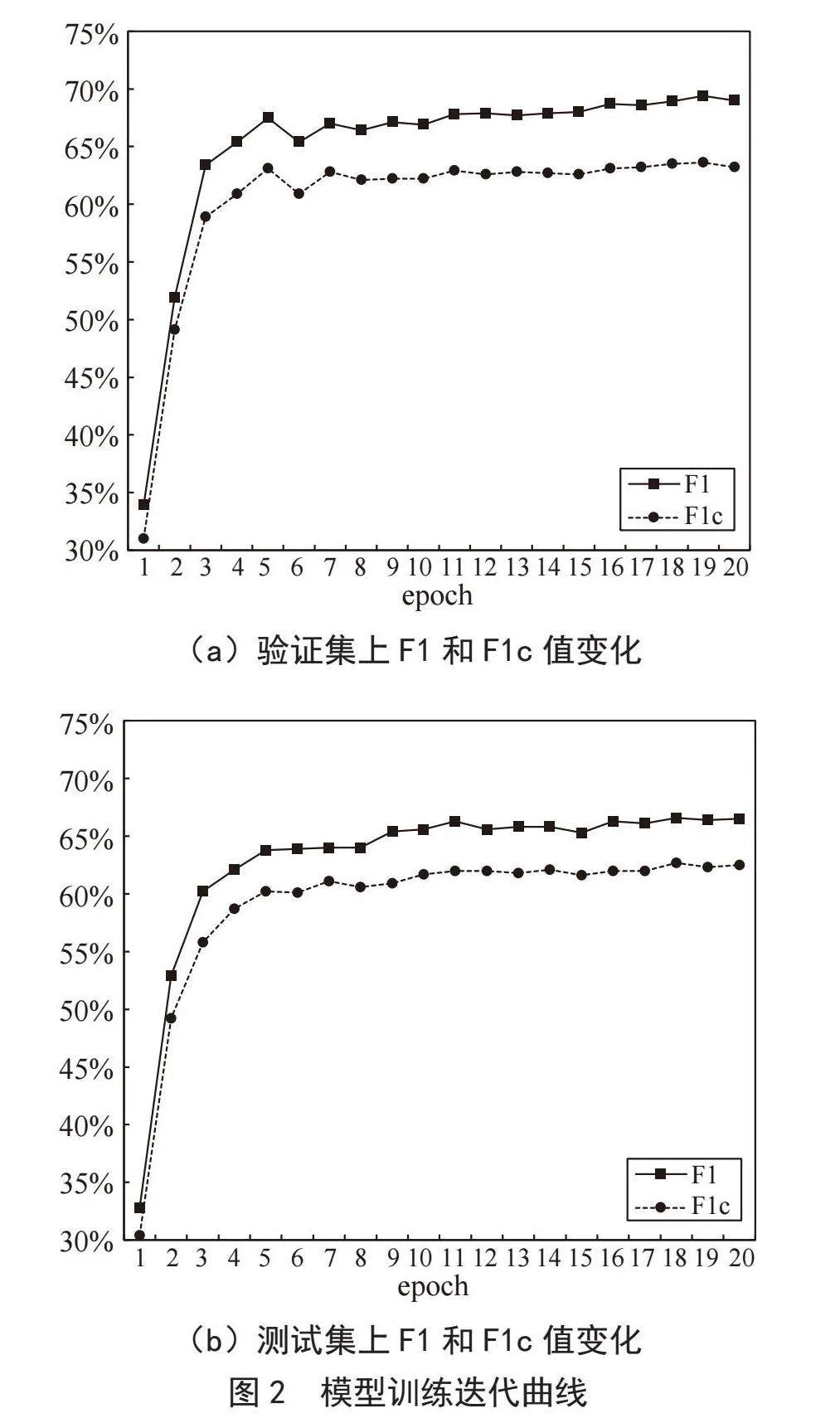
本文实验采用PyTorch 1.4.0框架,在配备Tesla T4 GPU的服务器环境下进行模型训练与测试。为了优化模型性能,选择BertAdam优化器,并将训练周期定为20次。在每个训练周期中,模型处理的数据批量大小设定为12个样本,学习率设置为3×10-5。为了进一步优化训练效果,采取了梯度累计策略,梯度累计步数为2,以减少内存消耗同时保持训练效率。同时,模型中引入了两层异构图结构,以增强模型处理复杂数据结构的能力,从而提高模型的整体性能和准确率,模型训练迭代在验证集和测试集的F1和F1c值变化如图2所示。
3.3 实验结果分析
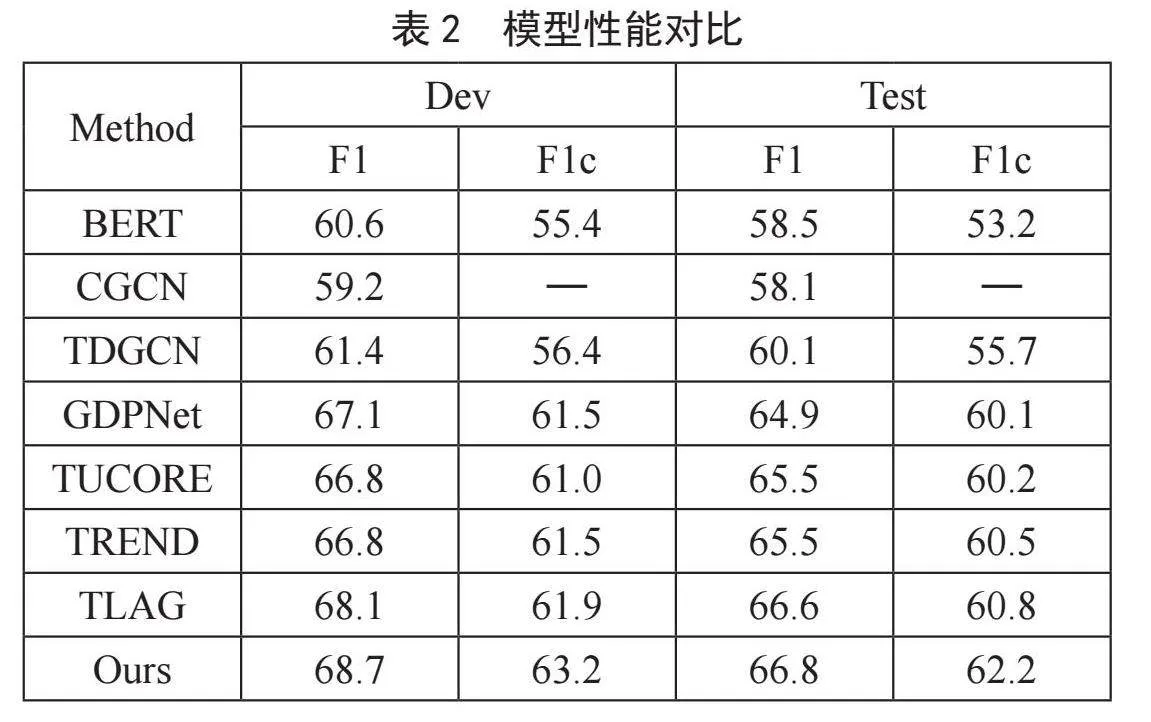
模型性能对比如表2所示,在DialogRE数据集的测试集上,模型在F1和F1c指标上都表现出色,分别达到了66.8和62.2。与此同时,将模型性能与其他先进的模型进行比较。
首先,与TLAG模型相比,本文模型在F1指标上提高了0.2,而在F1c指标上提高了1.4。这表明本文方法在捕捉关系信息方面更为优越,特别是在处理复杂关系时表现出色。这种提升可以归因于在模型中引入了一些规则来构建关系异构图,并强调了角色信息的重要性。此外,与CGCN和TUCORE这两个同样采用异构图的模型相比,模型也表现出了显著的优势。CGCN模型在F1指标上只达到了58.1,而TUCORE模型在F1c指标上只达到了60.2,这进一步突显了该模型在处理DialogRE数据集中的关系抽取任务时的卓越性能。总的来说,通过引入关系异构图和关注角色信息,模型在DialogRE数据集上取得了良好成绩,优于其他先进的模型。这个结果强调了在关系抽取任务中考虑关系之间的复杂性和角色信息的重要性。
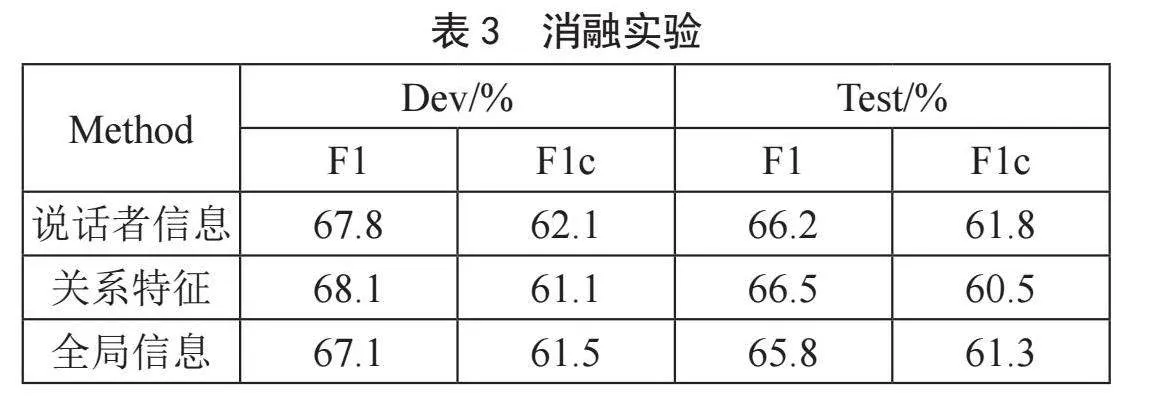
为了探究对话文本信息和说话者信息对模型性能的贡献,设计了一系列消融实验,结果如表3所示。实验结果揭示了说话者信息的融入对模型准确度的影响,具体来说,当从模型中剔除说话者信息后,模型的F1得分下降到66.2%,而在考虑类别平衡的F1c得分也降低到61.8%。这表明说话者信息在理解对话文本中扮演了重要角色,有助于提升模型的预测准确性。进一步地,实验还考察了关系特征节点的移除对性能的影响,结果显示F1c得分显著下降了1.7%。这一结果强调了关系特征在捕捉对话中细微关系动态方面的重要性,进而对模型整体性能产生显著影响。最后,全局信息的缺失对模型性能有着最显著的负面影响,其中F1和F1c得分分别下降了1%和0.9%。这表明全局信息在提供对话上下文和增强模型理解能力方面的关键作用。
4 结 论
本文提出了一种针对多方对话中实体关系抽取模型,通过构建异构图,将对话中的实体、说话者、关系特征及全局信息有效地结合在一起,从而更好地捕捉对话中的实体关系。此外,长短时记忆网络的引入进一步增强了模型对于不同对话轮次中说话者信息的处理能力,使模型能够更准确地识别和理解对话中的实体关系。实验结果表明,模型在DialogRE数据集上优于当前先进的方法,证明了模型在处理多方对话关系抽取任务时的有效性和优越性。未来的研究可以进一步探索异构图和深度学习技术在其他自然语言处理任务中的应用,以提高模型的通用性和效率。此外,考虑到对话数据的多样性和复杂性,开发更高效的算法来处理大规模对话数据集也是未来工作的重要方向。
参考文献:
[1] 陆亮,孔芳.面向对话的融入交互信息的实体关系抽取 [J].中文信息学报,2021,35(8):82-88+97.
[2] YU D,SUN K,CARDIE C,et al. Dialogue-based Relation Extraction [C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics,2020:4927-4940.
[3] XUE F Z,SUN A X,ZHANG H,et al. GDPNet: Refining Latent Multi-view Graph for Relation Extraction [J/OL].arXiv:2012.06780 [cs.CL].(2020-12-12).https://arxiv.org/abs/2012.06780.
[4] GHOSAL D,MAJUMDER N,PORIA S,et al. DialogueGCN: A Graph Convolutional Neural Network for Emotion Recognition in Conversation [J/OL].arXiv:1908.11540 [cs.CL].(2019-08-30).https://arxiv.org/abs/1908.11540.
[5] 王琪琪,李培峰.基于GCN的多人对话实体关系抽取方法 [J].中文信息学报,2023,37(5):80-87.
[6] LIN P W,SU S Y,CHEN Y N. TREND: Trigger-enhanced Relation-extraction Network for Dialogues [J/OL].arXiv:2108.13811 [cs.CL].(2021-08-31).https://arxiv.org/abs/2108.13811v1.
[7] 自彦丞,李卫疆.TDGCN:触发器增强的两阶段动态图卷积网络的对话关系抽取研究 [J].小型微型计算机系统.
[8] DUAN G D,DONG Y R,MIAO J Y,et al. Position-aware Attention Mechanism-based Bi-graph for Dialogue Relation Extraction [J].Cognitive Computation,2023,15(1):359-372.
[9] ISHIWATARI T,YASUDA Y,MIYAZAKI T,et al. Relation-aware Graph Attention Networks with Relational Position Encodings for Emotion Recognition in Conversations [C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing(EMNLP).online:Association for Computational Linguistics,2020:7360-7370.
[10] LEE B,CHOI Y S. Graph Based Network with Contextualized Representations of Turns in Dialogue [J/OL].arXiv:2109.04008 [cs.CL].(2021-09-09).https://arxiv.org/abs/2109.04008v1.
[11] 徐洋,蒋玉茹,张禹尧,等.融合角色指代的多方对话关系抽取方法研究 [J].北京大学学报:自然科学版,2022,58(1):13-20.
[12] DEVLIN J,CHANG M-W,LEE K,et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [J/OL].arXiv:1810.04805 [cs.CL].(2018-10-11).https://arxiv.org/abs/1810.04805v2.
作者简介:郑思源(1997—),男,汉族,福建罗源人,硕士研究生在读,研究方向:自然语言处理。