

摘 要:随着深度学习在商品识别领域的发展,饮料作为常见的商品,将饮料识别技术应用于自助饮料售卖柜中具有一定的研究意义和价值。为了减少饮料类别特征相似误检,提出了一种基于改进YOLOv4的饮料识别算法,通过在基础网络CSPDarknet53的每组残差模块之间增加通道注意力机制来增强饮料区域特征信息。实验结果表明,改进后的YOLOv4模型mAP值为92.43%,比改进前提高了1.74%,具有较好的实际应用价值。
关键词:饮料识别;CSPDarknet53;YOLOv4;通道注意力机制
中图分类号:TP183;TP391.4 文献标识码:A 文章编号:2096-4706(2024)15-0036-06
Beverage Identification Algorithm Based on Improved YOLOv4
SHEN Wei, LI Hongmei, TAO Yuan, ZHU Xueling
(School of Big Data and Artificial Intelligence, Anhui Xinhua University, Hefei 230088, China)
Abstract: With the development of Deep Learning in the field of product identification, beverage as a common product, applying beverage recognition technology to self-service beverage cabinets has certain research significance and value. In order to reduce the misconduct of the beverage category due to similar characteristics, a beverage recognition algorithm based on improved YOLOv4 is proposed. By increasing the Channel Attention Mechanism between the residual modules of the basic network CSPDarknet53, the characteristic information of the beverage area is enhanced. The experimental results show that the mAP value of the improved YOLOv4 reaches 92.43%, which is about 1.74% higher than that before improvement, and the model has good practical application value.
Keywords: beverage identification; CSPDarknet53; YOLOv4; Channel Attention Mechanism
0 引 言
随着社会的进步,人工智能的发展日新月异。目标检测与识别在诸多领域都起到了极其重要的作用。例如,人脸识别[1]、车辆识别[2]、视频监控异常[3]等多个方面。1989年Lecun[4]等人提出了第一个真正多层结构学习算法LeNet[5]网络用于对手写数字进行识别,相比于现在的网络识别效果虽然不是最优,但却是一个开创性的变化。之后,深度学习卷积网络得到了迅速的发展,如AlexNet[6]、ResNet[7]、VGGNet[8]等。用于目标识别的网络也是层出不穷,源源不断。
在现在的日常生活中,智能化设备的出现越来越方便我们的生活,自助饮料售卖柜,正是一种用于消费者购买饮料商品的智能化设备。与传统人工售卖饮料相比,它的出现在一定程度上减少了人力成本。将基于深度学习的目标识别技术应用到自助饮料售卖柜中去,极大地提高了饮料商品识别的精度,减少了人力资源的消耗,同时使得自助饮料售卖更加智能化。
1 技术背景介绍
1.1 YOLOv4网络结构
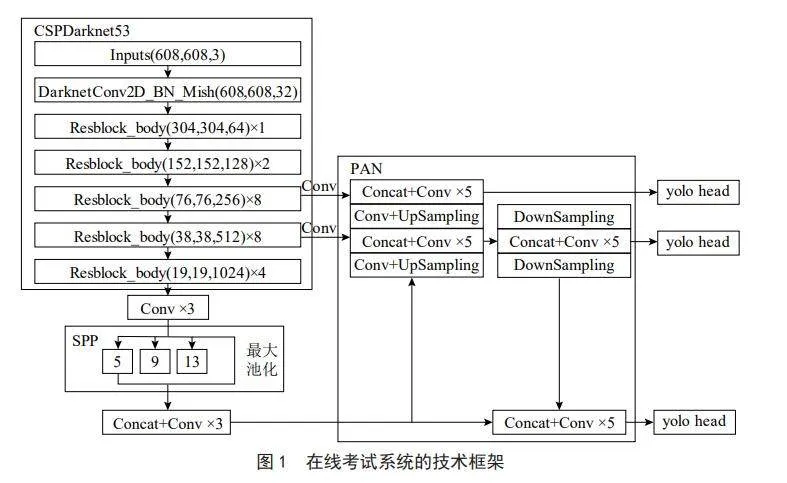
图1为YOLOv4的网络整体结构,主要包括三个部分:CSPDarknet53、SPP模块、PAN模块。
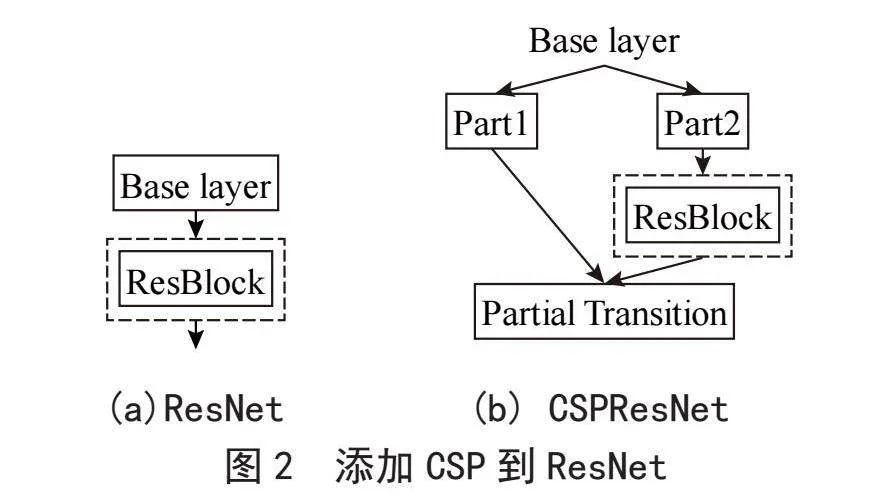
CSPDarknet53是YOLOv4的骨干网络,是在Darknet53的每组残差块上都增加CSP[9](Cross Stage Partial),Darknet53有5组残差块,每组残差块包含的残差单元数为1、2、8、8、4。
在CNN中加入CSP,使其在提高模型轻量化的基础上还保证了模型的准确率,有效地提高了CNN的学习能力。在残差网络ResNet(Residual Network)上增加CSP的结果展示如图2所示。
SPP(Spatial Pyramid Pooling)模块即空间金字塔池化模块,结构如图1中的SPP部分所示。在YOLOv4中的主要作用是增加感受野,感受野是指输入图像上的某个区域,该区域影响Feature Map上某个元素的计算。输入图像通过CSPDarknet53提取特征再通过3个卷积层后对得到的特征图进行了5×5、9×9、13×13的最大池化,对最大池化后的特征和池化前的特征进行Concatenate。
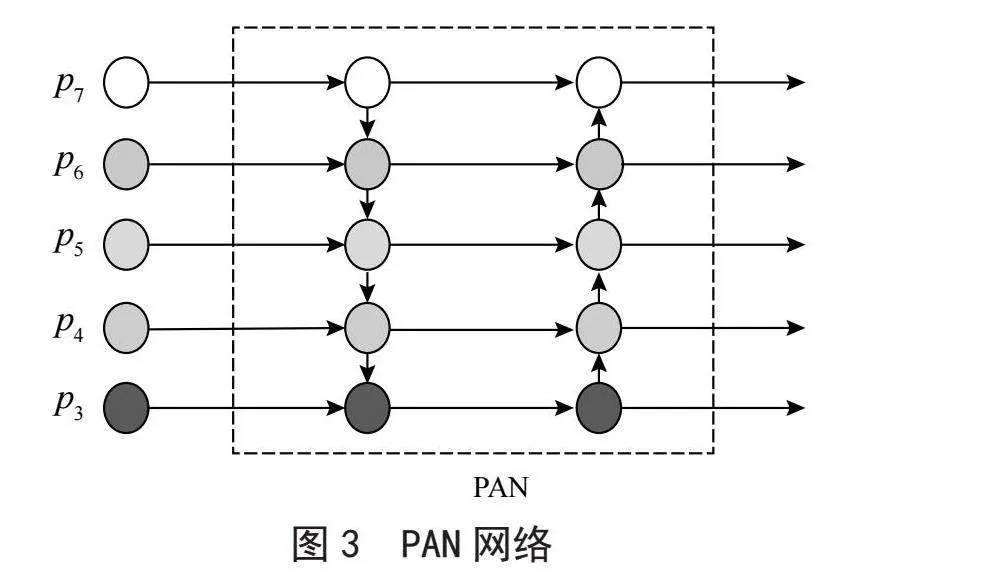
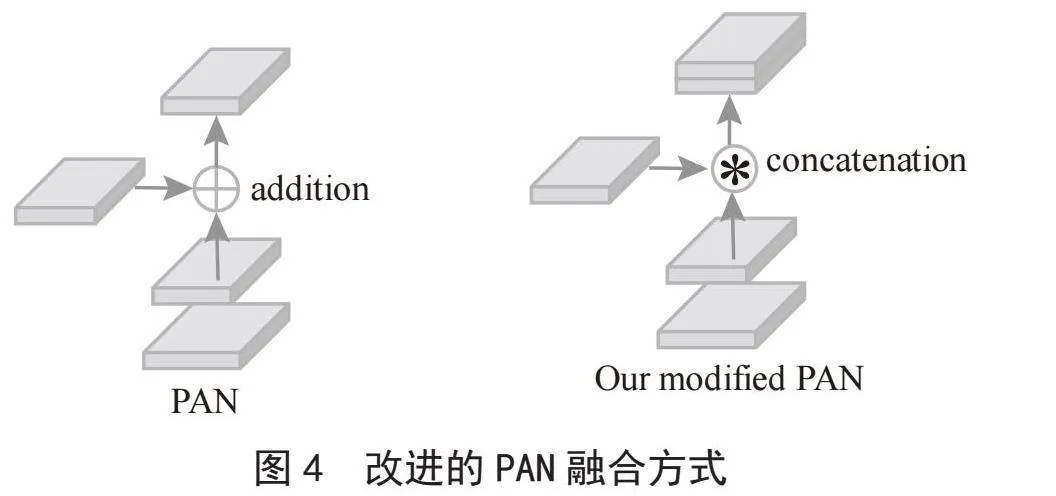
PAN(Path Aggregation Network)为路径汇聚网络,FPN(Feature Pyramid Network)为特征金字塔网络,较浅的特征图进行上采样操作并且与较深的特征图进行特征融合,与FPN[10]不同的是PAN会在上采样后又增加一个下采样,如图3所示,展示了PAN作用的过程,从P7进行上采样到P3,P3再通过下采样与每一层进行特征融合输出,这样进行特征融合可以增强每一层输出的特征信息。但是YOLOv4对特征融合方式做了改进,并不是将特征层加在一起而是将特征图连接在一起,如图4所示。
1.2 通道注意力机制
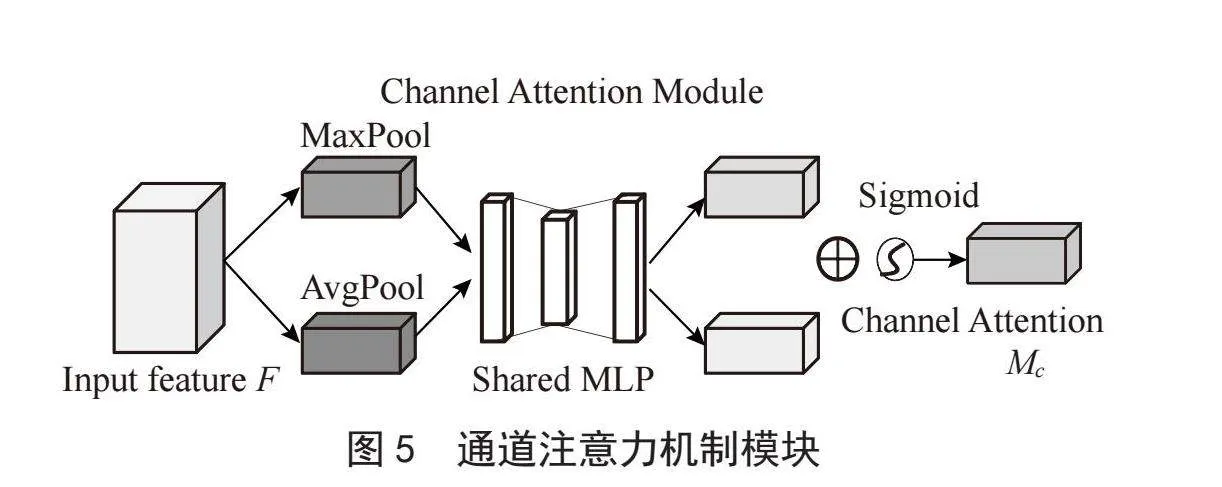
注意力机制模块就像人类的眼睛一般,当观看美丽的风景时,往往注意到自己最喜爱的风景部分,忽视那些不重要的风景部分。同样,网络也是如此,在网络中添加注意力机制,能够获得图像重点所关注的目标区域,也就是一般所说的注意力焦点,抑制其他无用信息,增强所关注的目标区域的特征信息。对于饮料识别来说,由于饮料种类繁多,并且饮料类别的颜色及形状、大小等具有特征相似性,饮料识别过程中会出现误检的情况,从而造成饮料检测与识别效果较差。增加注意力机制可通过增强饮料的区域特征,提高饮料识别的精度。注意力机制有多种,通道注意力机制是注意力机制的一种,主要是在通道方向上增加注意力机制,通过自动学习的方式能够获得每个特征通道的重要性并为每个特征通道分配一个权重,让网络重点去关注重要的特征通道,抑制无用特征通道。
图5为通道注意力机制模块结构,首先将输入特征分成两步,一步进行最大池化操作,另一步进行平均池化操作,然后将得到的特征分别通过共享的两层神经网络MLP,再将通过MLP输出的特征进行加和操作,通过Sigmoid激活操作,最后得到通道注意力特征图,再与输入特征图进行相乘操作,得到最终的增加通道注意力机制的特征图。Mc计算公式如式(1)所示:
(1)
其中:σ为sigmoid激活函数,W0和W1为卷积层参数,AvgPool为平均池化函数,MaxPool为最大池化函数。
1.3 损失函数
网络训练的损失函数包括边界框回归损失函数Lossciou、置信度损失函数Lossconf和分类损失函数Lossclass,YOLOv4中的边界框回归损失函数是将YOLOv3的MSE函数改成了CIoU函数,Lossciou如式(2),Lossconf如式(3),Lossclass如式(4):
在式(2)中,b为预测框的中心坐标,w、h为框的宽高,式(3)的参数λnoobj为权重系数,为预测目标置信度,为真实目标置信度,式(4)中为预测目标概率,为真实目标概率。
2 基于YOLOv4模型改进
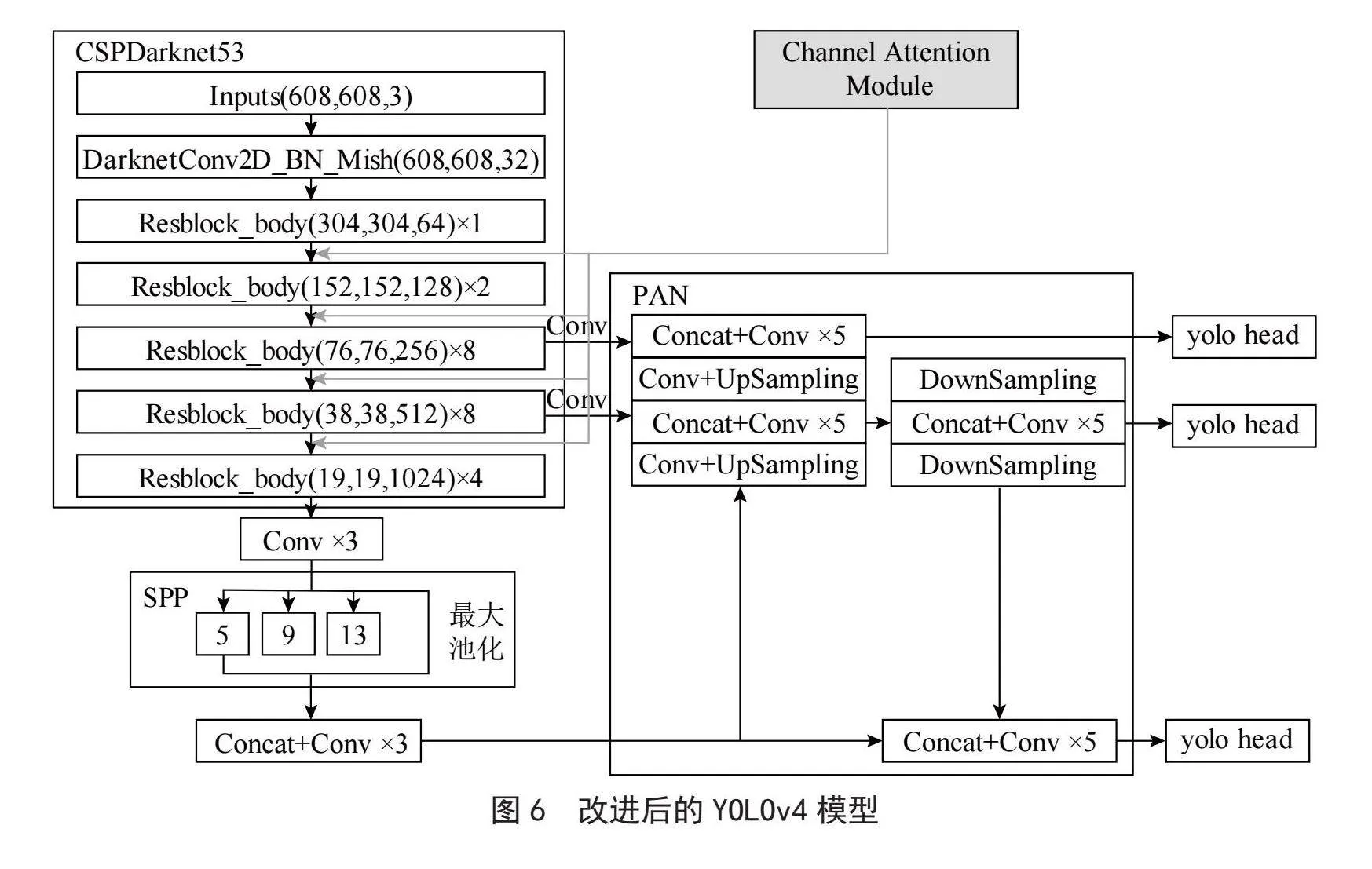
在本方法的饮料识别中,饮料的种类繁多,采集的饮料数据共有21类,由于饮料类别间存在颜色、形状、大小等特征极其相似的情况,所以会出现误检,从而导致某些饮料识别的精确度较低。本方法从这个角度出发,在YOLOv4的基础网络CSPDarknet53的每组残差单元间增加了如图5的通道注意力机制,通过增强饮料区域的特征细节信息,从而提高饮料识别的精度。改进后的网络结构如图6所示。
3 实验过程及结果分析
3.1 数据集及实验环境
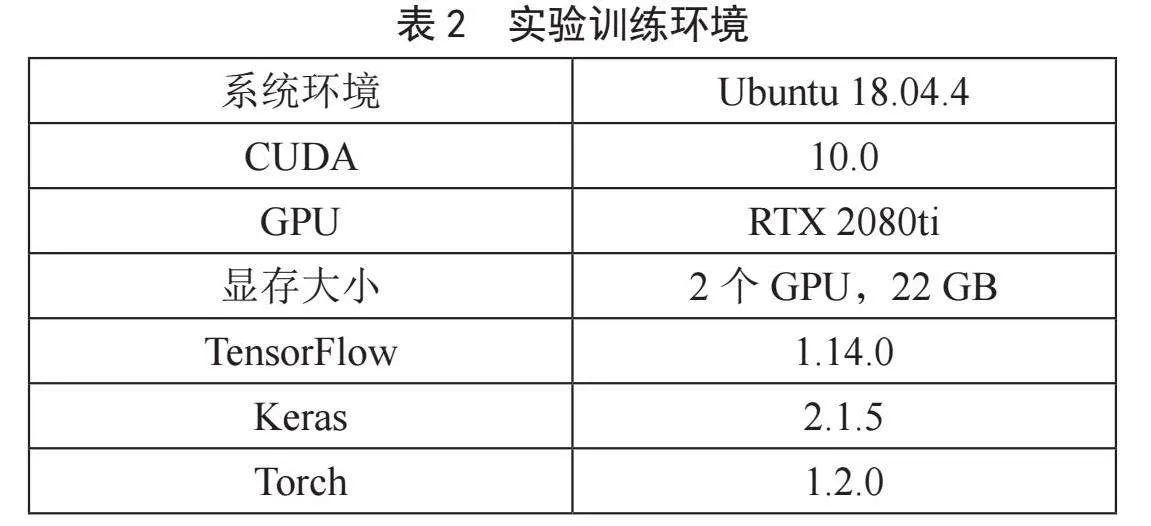
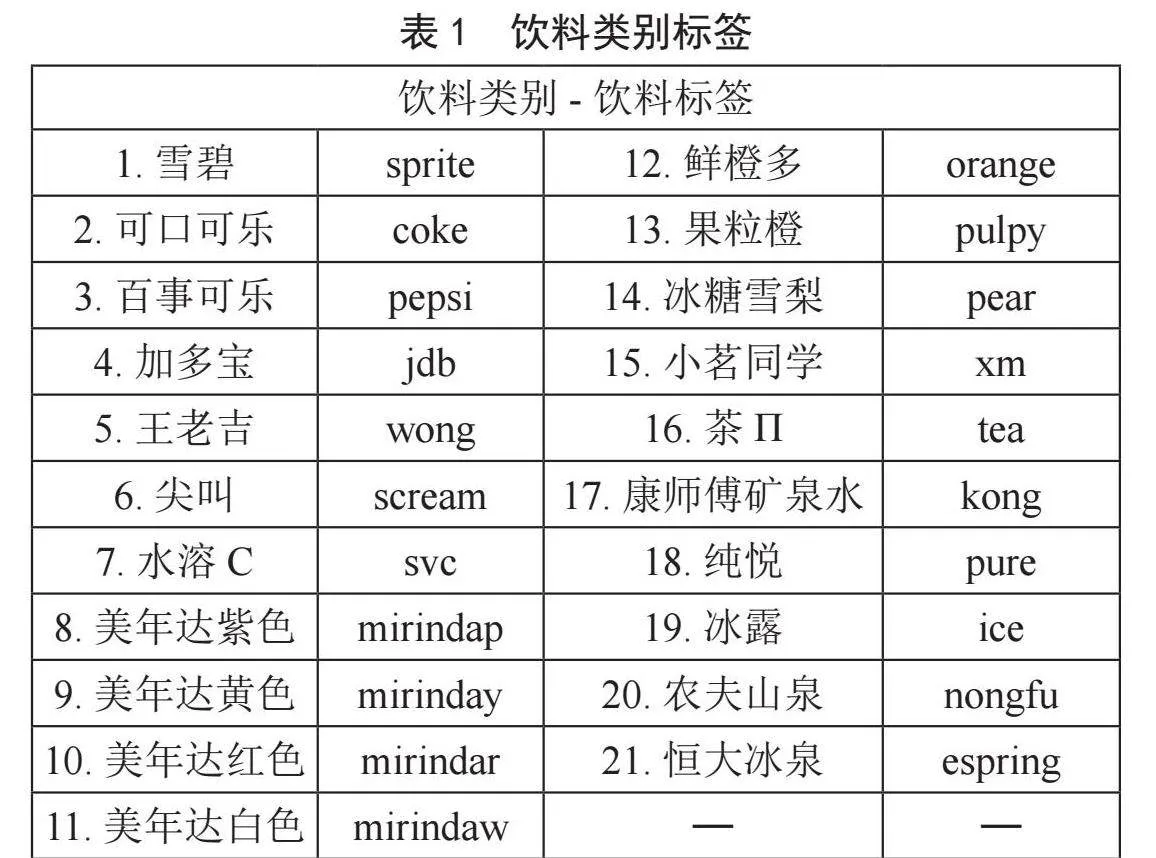
本文实验所采用的数据集是将鱼眼摄像头安装在冰箱的某一层,将饮料随机摆放在不同位置,从上至下进行拍摄采集图像,如图7所示。本次共使用饮料21类,采集了3 098张静态图像。将采集的数据按9:1的比例划分为训练集和测试集,给定每类饮料特定的标签,各类饮料类别和饮料标签如表1所示。用标注工具labelImg-master对训练集和测试集分别进行标注,制作VOC数据集。训练时将数据和对应的标签文件同时放入模型中进行训练,网络训练的环境配置如表2所示。
3.2 网络改进前后实验对比
分别使用训练后的最优模型对指定测试集进行检测,即可得到单个被测饮料类别被识别的平均精度值AP以及所有类别平均精度的均值mAP。
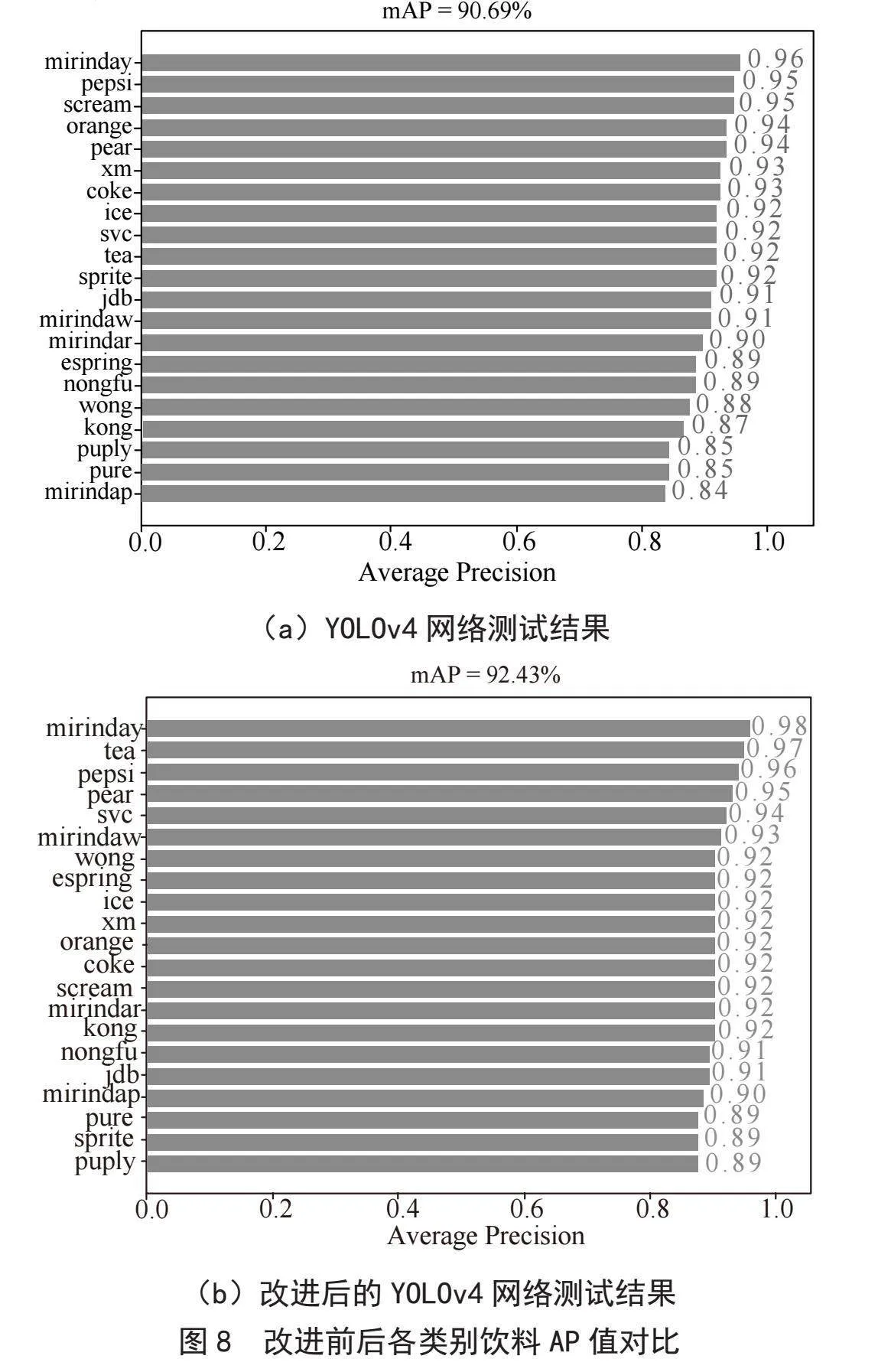
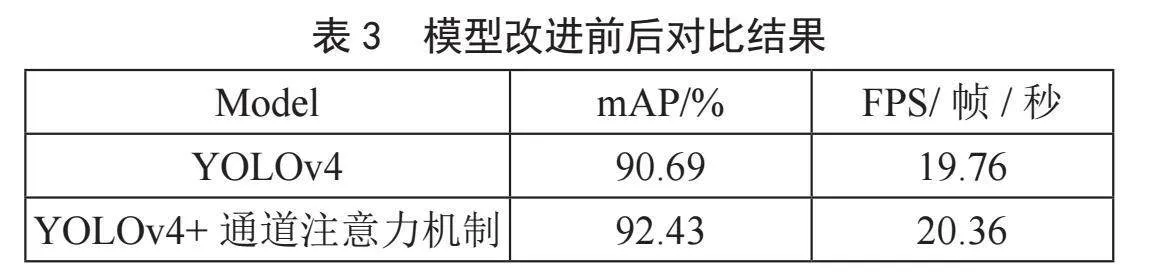
图8(a)为YOLOv4网络测试结果,图8(b)为改进后的YOLOv4网络测试结果。从改进前后各个饮料类别的AP值对比可看出,网络改进之后AP值有一定的提升。整体来看,mAP值由原来的90.69%提高到了92.43%,提高了1.74%。由此可验证本文提出的增加通道注意力机制的YOLOv4网络较原模型有所改进。
利用原YOLOv4网络与改进后的YOLOv4网络对图像检测速度FPS进行测试,其结果如表3所示。通过两次实验的FPS值对比来看,改进前为19.76(帧/秒),改进后为20.36(帧/秒),网络改进后检测速度有了一定的提高。该实验结果也表明了网络改进的有效性。
3.3 不同网络实验对比
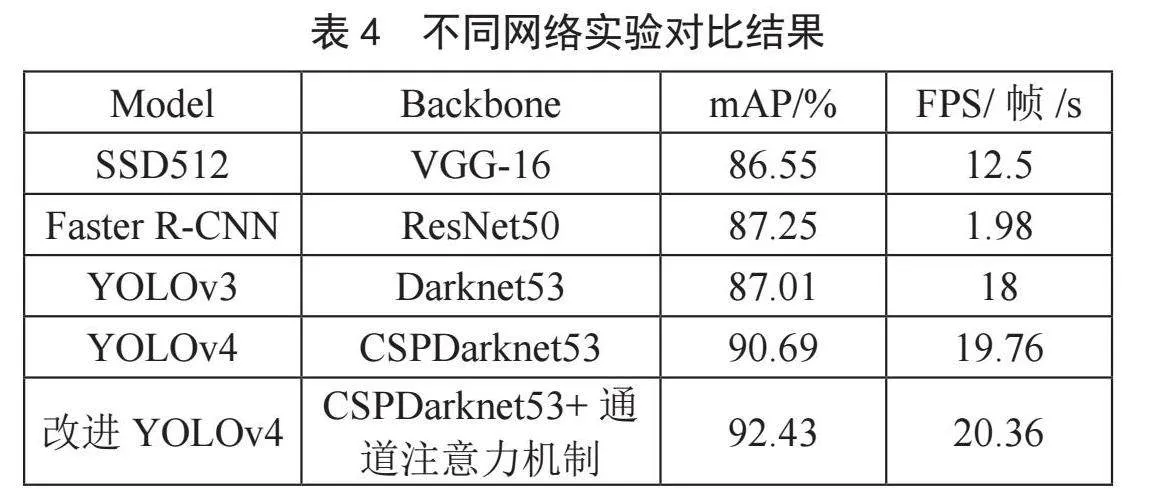
将增加通道注意力机制的YOLOv4网络与常见的三种目标检测网络SSD512、Faster R-CNN、YOLOv3进行对比,三种网络在与表2相同的设备以及环境配置下进行实验。
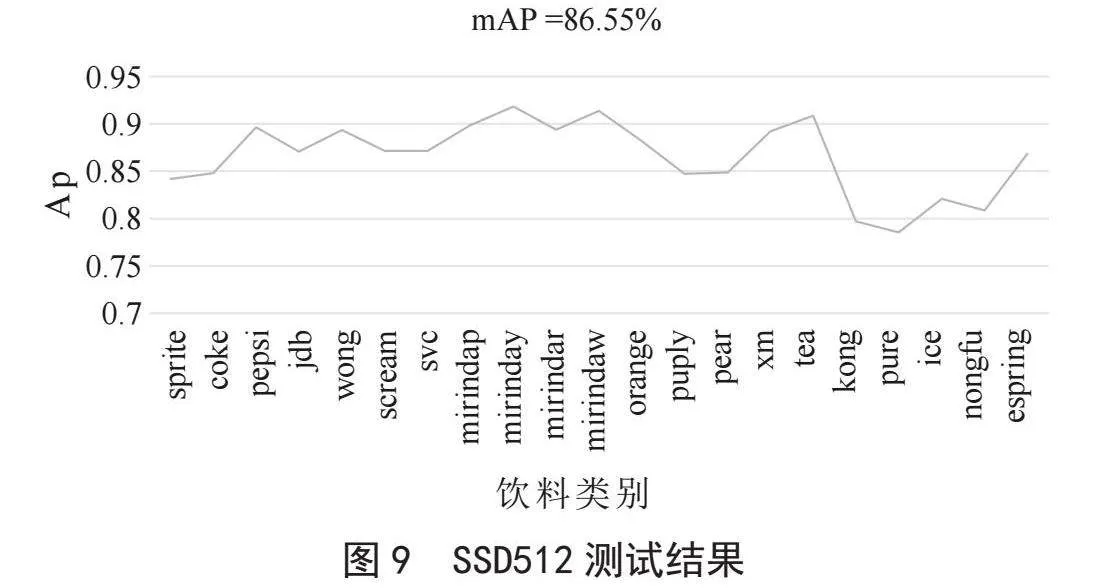
对SSD模型进行训练,SSD模型是在PyTorch框架下进行实验,512×512为输入图像的大小,网络训练集和测试集都是一致的,以VGG-16为骨干网络,训练生成的权重文件对测试集进行测试,设定相同的置信度阈值为0.5,测试的结果如图9所示,从图中可看出测试的mAP值为86.55%。对其FPS值进行测试,测试的FPS值为12.5帧/秒。
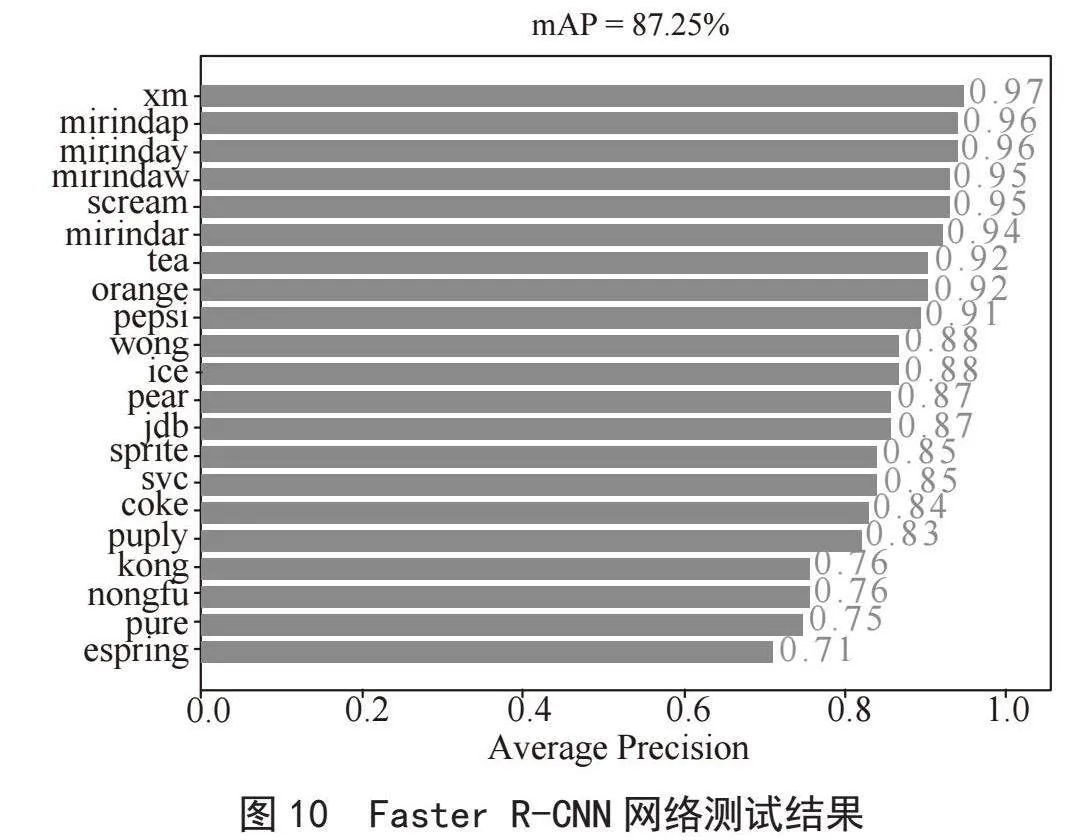
Faster R-CNN网络是在Keras框架下对训练集进行训练,以ResNet50为骨干网络,输入图像大小为600×600,训练之后会得到相应的权重文件,使用该权重文件对测试集进行测试,测试时设置与之前网络同样的置信度阈值0.5,使用该权重文件对饮料数据测试集测试的结果如图10所示。从图可看出饮料识别的mAP值为87.25%,虽然Faster R-CNN网络识别的精度还不错,但是模型较大,检测速度较慢,测试的FPS值只有1.98帧/秒。
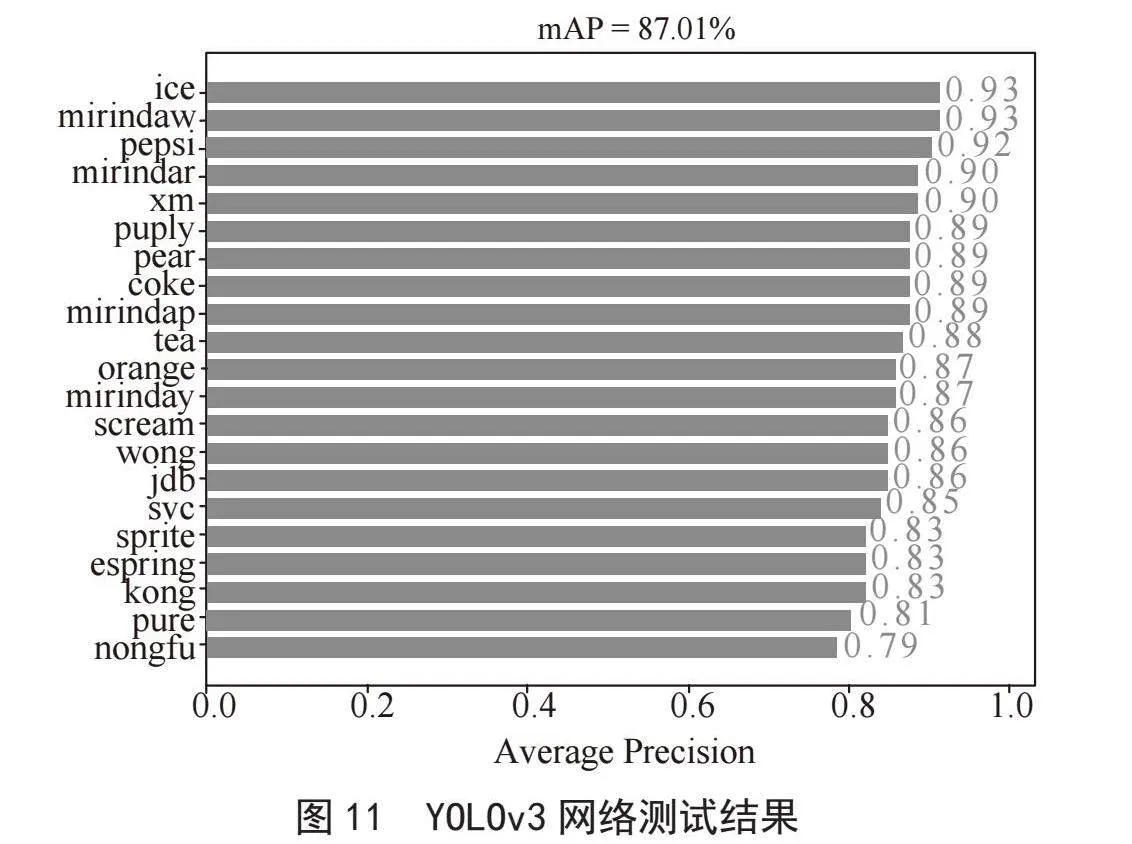
采用YOLOv3网络对训练集进行训练,YOLOv3是以Darknet53为骨干网络,在Keras框架下进行实验,与其他网络设置相同的网络参数,输入的图像大小为416×416。通过网络训练,得到相应的训练后的权重文件。使用权重文件对饮料测试集进行测试的结果如图11所示。从图中可看出,采用YOLOv3网络进行饮料识别的mAP值为87.01%。同样,对YOLOv3网络的检测速度FPS值进行测试,测试的FPS值为18帧/秒,略低于YOLOv4。
为了更好展示改进后的YOLOv4网络与YOLOv4、SSD512、Faster R-CNN、YOLOv3网络的结果对比情况,将实验结果呈现在表中,如表4所示。从测试的mAP值可看出,SSD512识别的mAP值相比于其他网络较低,Faster R-CNN网络识别的mAP值优于SSD512,但是由于它不能满足实时性,FPS值非常低。YOLOv3在饮料识别的mAP值以及检测速度FPS值上都达到了不错的效果,但是不如YOLOv4。YOLOv4是在YOLOv3的基础上进行了一系列的改进,对于本文的饮料数据来说,它在识别精度和检测速度达到了一个更好的效果,与YOLOv3相比,mAP值提升了3.68%,FPS值也增加了约1.76帧/秒,检测与识别效果优于YOLOv3。本文改进的方法相对于其他网络效果较好,mAP值在YOLOv4基础上又提升了1.74%,检测速度也略高于YOLOv4,检测速度是Faster R-CNN网络的10倍多,从这些实验数据可充分说明改进实验的有效性,同时也具有很好的实时性。
3.4 测试集测试结果
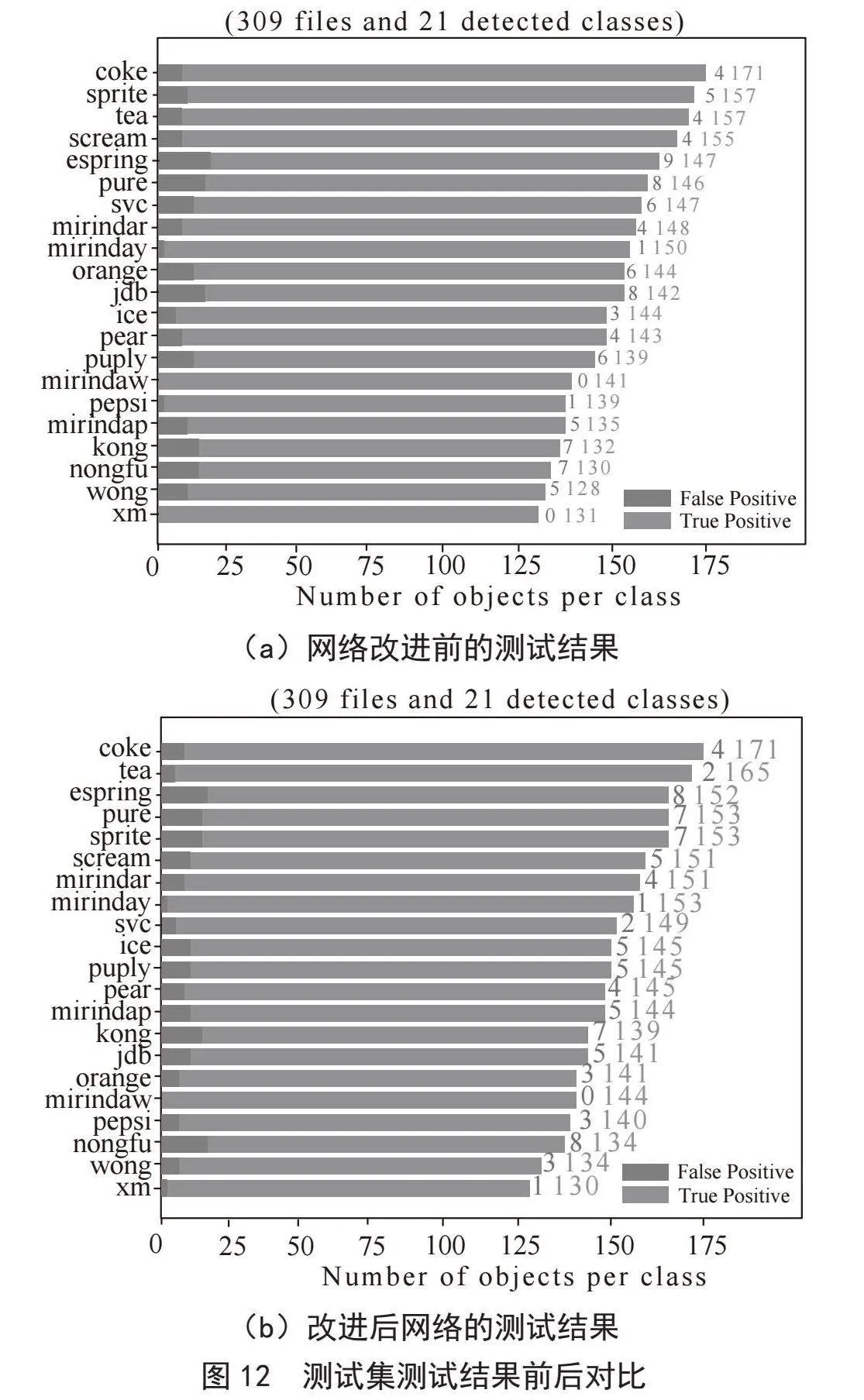
为了进一步证明改进后网络的有效性,本实验采用生成的模型对测试集进行测试,测试集共有309张图片,每张图片上有一个或多个检测类别目标,检测阈值设定为0.5,饮料识别与检测的正确个数和错误个数如图12所示,黑色标注为错误检测的部分。在图12中,图(a)为网络改进前的测试结果,图(b)为改进后网络的测试结果,图(a)、图(b)对比可看出饮料类别的检测与识别错误率有了一定的降低,例如图(a)中的饮料类别恒大冰泉、加多宝、康师傅矿泉水、农夫山泉、王老吉、果粒橙检测效果较差,在图(b)检测结果中错误率都有了一定的降低,图(a)、图(b)对比从一定程度上证明改进后网络的有效性。
4 结 论
针对所采集的数据集中存在饮料类别的颜色、形状特征等极其相似的问题,提出一种基于改进YOLOv4的饮料识别算法,对YOLOv4网络进行改进,在YOLOv4基础网络CSPDarknet53的每组残差单元之间增加通道注意力机制,在一定程度上增强了饮料区域特征信息,提高了饮料识别的精度。与原YOLOv4网络相比,达到了预期效果,在测试集上mAP值为92.43%,检测速度可达到20.36帧/秒。与其他三种常见的目标检测网络SSD512、Faster R-CNN、YOLOv3相比,不管是在识别精度上还是检测速度上,改进优化后的YOLOv4网络效果都优于这三种网络,检测与识别效果良好。
参考文献:
[1] 左栋,杨明远.基于Res Net50网络特征融合的人脸识别技术研究 [J].电脑与信息技术,2023,31(1):22-24.
[2] 施国栋,韦军,孙国林,等.RFID车型识别技术的应用研究 [J].汽车工艺与材料,2023(1):66-72.
[3] 柏万胜,孙鹏,郎宇博,等.视频中异常行为自动检测技术研究 [J].安全,2023,44(2):1-6+9+90.
[4] LECUN Y,BOSER B,DENKER J S,et al. Handwritten Digit Recognition with a Back-Propagation Network [J].Advances in Neural Information Processing Systems,1990:396-404.
[5] LECUN Y,BOTTOU L,BENGIO Y,et al. Gradient-Based Learning Applied to Document Recognition [J].Proceedings of the IEEE,1998,86(11):2278-2324.
[6] RUSSAKOVSKY O,DENG J,SU H,et al. ImageNet Large Scale Visual Recognition Challenge [J/OL].arXiv:1409.0575 [cs.CV].[2024-01-08].https://arxiv.org/abs/1409.0575v3.
[7] HE K M,ZHANG X Y,REN S Q,et al. Deep Residual Learning for Image Recognition [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas:IEEE,2016:770-778.
[8] SIMONYAN K,ZISSERMAN A. Very Deep Convolutional Networks for Large-Scale Image Recognition [J/OL].arXiv:1409.1556 [cs.CV].[2024-01-08].https://arxiv.org/abs/1409.1556.
[9] WANG C Y,LIAO H Y M,WU Y H,et al. CSPNet: A New Backbone that can Enhance Learning Capability of CNN [C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops.Seattle:IEEE,2020:1571-1580.
[10] LIN T Y,DOLLÁR P,GIRSHICK R,et al. Feature pyramid networks for object detection [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition.Honolulu:IEEE,2017:936-944.
作者简介:沈薇(1996—),女,汉族,安徽马鞍山人,助教,硕士研究生,研究方向:计算机视觉;李红梅(1981—),女,汉族,安徽淮北人,副教授,本科,研究方向:机器视觉;陶苑(1991—),女,汉族,安徽芜湖人,助教,硕士研究生,研究方向:计算机应用技术;朱学玲(1979—),女,汉族,安徽宿州人,副教授,本科,研究方向:计算机视觉。