

摘 要:当前,在线信用卡交易欺诈案件快速增加,作案手段和方法更加多变,信用卡交易欺诈检测已成为银行风险防控的重点内容。文章依托近年人工智能领域热门的图分析理论与算法,将信用卡交易数据转化为图结构数据,从而分析信用卡交易欺诈图的社区信息。在此基础上,应用图表示学习算法Deepwalk和机器学习分类器,构建信用卡交易欺诈检测模型,用于预测欺诈行为。实验结果表示,该模型对欺诈行为的检测准确率达70%。
关键词:信用卡交易;欺诈检测;图分析算法;图表示学习
中图分类号: 文献标识码:A 文章编号:2096-4706(2024)15-0138-04
Credit Card Transaction Fraud Detection Based on Graph Analysis Algorithm
YUAN Lining1,2, TANG Yuxia1,2, HUANG Wanyan1,2, LUO Hengyu3, HE Peiyao3
(1.School of Information Technology, Guangxi Police College, Nanning 530028, China;
2.School of Public Security Big Data Modern Industry, Guangxi Police College, Nanning 530028, China;
3.School of Criminal Science and Technology, Guangxi Police College, Nanning 530028, China)
Abstract: Currently, online credit card transaction fraud cases are rapidly increasing, with more diverse methods and tactics being used. The credit card transaction fraud detection has become the key focus of bank risk prevention and control. This paper relies on the popular graph analysis theory and algorithms in the field of Artificial Intelligence in recent years. It transforms credit card transaction data into graph-structured data to analyze the community information of the credit card transaction fraud graph. Based on this, it applies the graph representation learning algorithm Deepwalk and Machine Learning classifiers, and a credit card transaction fraud detection model is constructed to predict fraudulent behavior. The experiment results show that the model detection accuracy for fraud behavior reaches 70%.
Keywords: credit card transactions; fraud detection; graph analysis algorithm; graph representation learning
0 引 言
近年来,随着互联网技术的迅速发展,网络犯罪日益猖獗,信用卡交易欺诈也呈现出愈加复杂和高科技化的趋势。据中国银行业协会发布的《中国银行卡产业发展蓝皮书(2022)》统计[1],截至2021年末,银行卡累计发卡量92.5亿张,全国银行卡交易金额1 060.6万亿元,银行卡欺诈率达0.32BP。在互联网环境中,交易通常发生在虚拟世界,买卖双方的真实身份难以验证,交易信息的真假性难以辨别,使得与信用卡交易相关的欺诈类案件手段与方法更加多变。此外,欺诈团伙呈现出集团化、流水化、专业化的特征,犯罪过程中运用的信息技术也越来越先进。因此,针对信用卡交易的反欺诈技术,必须进一步革新和升级。
信用卡交易欺诈检测[2]是指通过用户之间的交易行为,判断交易是否存在欺诈情况,进而保障银行与持卡人的财产安全,保证企业的正常运营,提高金融部门的监管能力,保证金融市场健康运转。因此,针对信用卡交易欺诈检测技术的研究意义重大,既能够提升数字化反欺诈水平和能力,又能够将算法技术落到公共财产保护的实处。在现有研究中,多数研究者使用常见的机器学习算法[3]进行欺诈检测,并提出了许多改善信用卡欺诈检测系统准确性的方法,但仍存在数据样本不平衡、检测难度高等问题。
针对上述问题,本文从全新的数据分析视角对信用卡交易数据中的欺诈行为进行检测,相关创新点如下:1)对开源信用卡交易数据集进行清洗和预处理,保留关键特征;2)将预处理后的数据转化为二分图,图中节点分别表示消费者和商家,边表示交易关系;3)对生成的二分图进行社区检测,评估不同社群中欺诈交易的比例;4)利用图表示学习算法Deepwalk提取二分图特征信息,生成保留特征信息的节点表示,然后将特征表示输入机器学习分类器中,对正常交易和欺诈交易进行分类。
1 相关工作
信用卡交易欺诈行为的检测相较图像识别、实体抽取等常见机器学习问题更为复杂,因为存在人为参与和干扰,直接运用算法进行欺诈行为判别的方法通常效果不佳。蒋等人对现有基于机器学习的信用卡交易欺诈检测技术进行了较为全面的综述[4],对技术、应用等相关概念进行了辨析,从监督、半监督和无监督三个角度对现有方法进行归类,并总结了目前研究存在的局限和挑战。
在现有研究中,多数模型采用传统机器学习算法进行欺诈行为检测。Mienye等人将长短期记忆网络和门控循环单元神经网络作为堆叠集成框架中的基础学习器,以多层感知机作为元学习器,采用混合合成少数过采样技术和最近邻方法平衡数据集中的正常交易和异常交易的分布[5]。王等人提出基于Focal Loss损失函数的XGBoost算法FXGBoost[6],解决了信用卡欺诈检测模型中存在的数据不平衡问题。此外,阮等人[7]和Cherif等人[2]均采用集成学习的方法,将多个不同的分类器进行叠加,充分利用模型间的互补性和集成学习的稳健性,有效解决了数据特征冗余和样本不平衡问题。与已有研究不同,本文首先将原始的信用卡交易数据转化为图数据,然后运用当前较为先进的图数据分析和挖掘算法进行检测,为欺诈检测技术提供了一种全新的视角。
2 理论与算法
f6bccb55ff2ab943591fc6e38dc8fe2c2.1 图的基本概念
图描述了实体之间的成对关系,能够表示不同领域中的现实世界数据,包括社交网络、交通网络、化学分子和蛋白质关系。在数据结构中,图被定义为由实体的节点和表示实体间关系的边构成,记为G=(V,E),其中V表示节点集合,E表示边集合。节点集合可表示为V={v1,v2,…,vn},边可表示为(vi,vj)或eij的形式。根据图中包含信息的不同,图有多种分类方式,例如,依据边是否具有方向性,可以将图分为有向图或者无向图;边是否具有权重系数,分为加权图和非加权图。此外,还有一些特殊类型的图,例如二分图将节点集合分为A和B两个子集,两个集合内部的节点没有边,仅在两个集合间形成边。作为一种常见的数据结构,图有多种存储方式,其中邻接矩阵是两种最常用的表示方式之一,其表现形式可定义为:
(1)
式中,a表示边eij的权重,当节点vi和vj之间存在边eij时,a的值大于0。
除了上述基本性质,图还具有许多重要的统计特性。例如,节点vi的边数称为节点vi的度,记为deg(vi)=N(vi),所有节点度之和与边的数量关系为。对于有向图还包括出度和入度的概念,顶点的实际度数等于该顶点的出度与入度之和。两个节点间最少边数称为节点距离,两个节点的距离实质上就是图中的最短路径。
2.2 基于随机游走的图分析模型
在图学习算法中,提取节点共现关系是一种常用的图结构学习方法。通过执行随机游走,如果节点在游走序列中同时出现,则认为节点具有内在相似性,通过设置特定的优化映射函数,即可从随机游走中提取“相似性”。本节介绍两种随机游走算法的核心原理。
腊等人[8]使用随机游走对节点进行采样,生成节点序列,再应用Skip-Gram[9]模型最大化节点序列中窗口w范围内节点之间的共现概率,从而提取原始图结构特征:
(2)
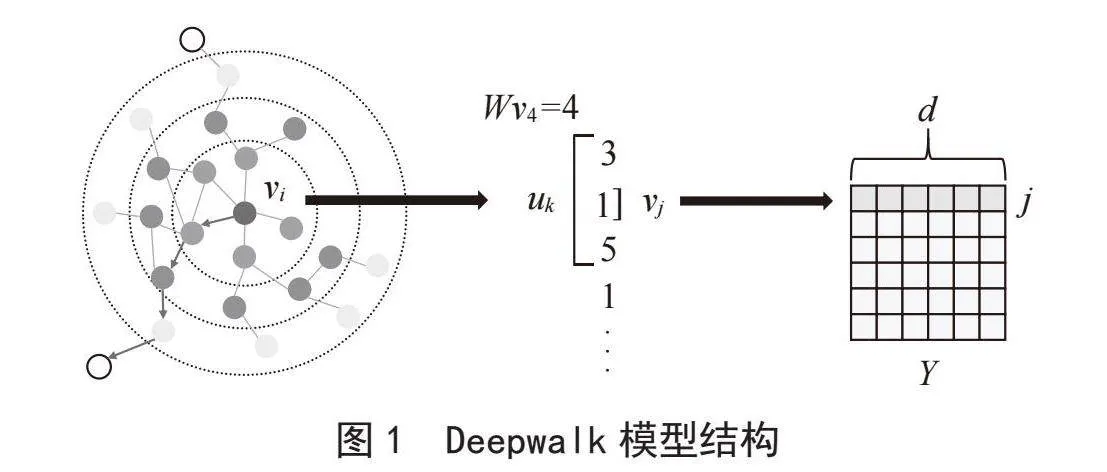
生成的节点表示Y={Y1,Y2,Yn},这些表示将节点之间的关系编码在低维向量空间,用于捕捉邻域相似性和社区结构,学习节点的潜在特征。Deepwalk模型结构如图1所示,以下是对图中算法的逐步解释:1)随机游动生成:对于输入图G的每个节点,计算一组具有固定最大长度的随机游动;2)训练Skip-Gram:使用在前一步中生成的所有随机游动,训练Skip-Gram模型,Skip-Gram模型适用于单词和句子,当一个图被作为Skip-Gram模型的输入时,图可以被视为输入文本语料库,而图中单个节点可以被视作为语料库的一个单词;3)嵌入生成:使用包含在训练的Skip-Gram模型隐藏层中的信息来提取每个节点的嵌入。
自Deepwalk问世以来,网络表示学习方法[10]随之流行,同时生成的节点嵌入也被用于节点分类、链路预测、社区检测等众多图分析任务中。虽然Deepwalk没有显式地分解表示原始图结构的邻接矩阵,但可以被归类为潜在特征方法:
(3)
其中,表示节点度的总和,D表示对角度矩阵,A表示邻接矩阵,w表示Skip-Gram的窗口大小,b表示常数项。Deepwalk本质上是能过对高阶规范化邻接矩阵的和(最多w个)的对数进行因式分解来实现的。所以Deepwalk已经隐式地建模了从1到w阶的多尺度依赖关系,得到的是一个覆盖所有尺度的全局表示,只是无法对不同尺度单独进行访问。
3 信用卡交易欺诈检测
本节使用Kaggle提供的信用卡交易欺诈检测数据集(https://www.kaggle.com/kartik2112/fraud-detection?select=fraudTrain.csv)进行实验包。该数集据涵盖了从2019年1月1日至2020年12月31日1 000位用户与800位商家的正常和欺诈交易记录,每笔交易包含23个不同的特征。在本节中,首先将信用卡交易转换为图结构数据,然后提取交易图的基本性质和社群属性,最后对信用卡图中的社区结构和欺诈行为进行检测。
3.1 数据预处理
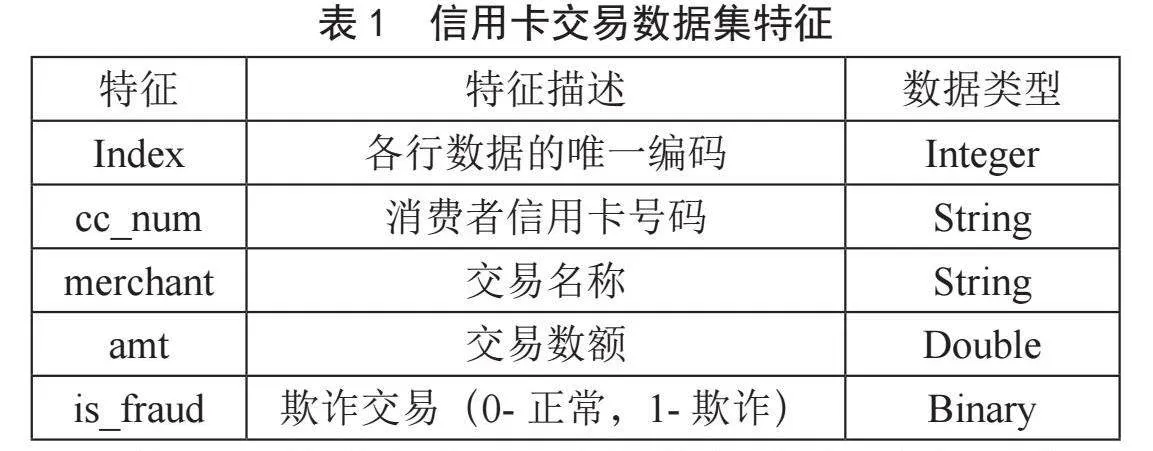
为进行后续的相关分析,本文对原始数据的23个特征进行了筛选,在模型训练过程中应用的相关特征信息如表1所示。同时,为减少计算量,我们从数据集中选取了20%正常交易和所有欺诈交易(正常交易257 834笔,欺诈交易7 506笔)作为实验数据集。
然后,将特征提取后的数据集表示为二分图G=(Vc,Vm,E,σ),其中Vc表示消费者节点集合,Vm表示商家节点集合。如果存在从消费者到商家的交易行为,则在图中创建一条从消费者节点到商家节点的边(vc,vm),并为每条边分配一个由交易金额大小确定(以美元为单位)的权重。由于边通过交易关系信息进行构建,因此将消费者和商家之间的多次交易信息进行压缩,当二者间存在多笔交易时,仅建立一条边,同时权重由所有交易金额的总和确定。最后,为每条边指定标签信息,明确标记该交易是正常交易还是欺诈交易。
3.2 社区检测和欺诈检测
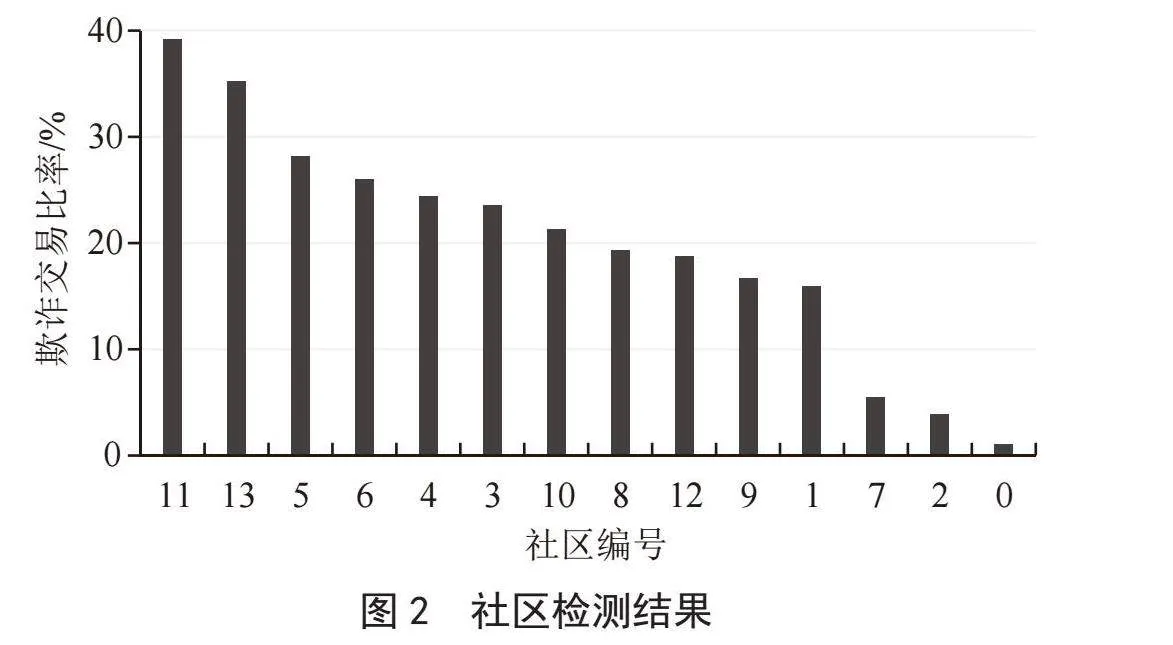
本节使用常用的社区检测算法Louvain算法[11]对生成的二分图进行划分,并展示算法检测到的社区结构。Louvain算法是一种基于模块度的社区发现算法,它将图中节点尝试分配到其所有邻居节点所属的社区中,并选择能够最大化模块度增量的社区标签。在每次迭代中,算法会根据当前社区划分重新计算模块度,这个过程会一直重复,直到模块度不再增大为止。对于Louvain算法检测到的每组社区,直接计算欺诈交易的百分比,从而确定欺诈交易高度集中的子图,实验结果如图2所示。从实验结果可以看出,多数社区中存在较高比率的欺诈交易行为。同时,我们依据图2中相关结果,能够为后续同一社区中欺诈行为的共性和不同社区间欺诈行为的差异性提供分析依据。
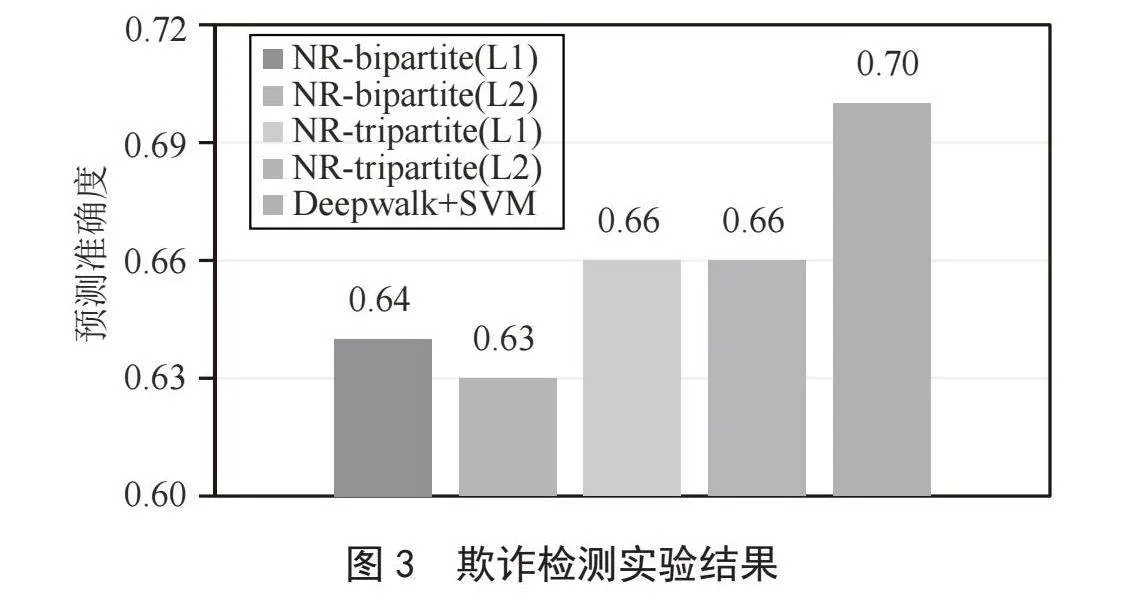
然后,我们使用图表示学习算法Deepwalk生成二分图中节点的特征表示。对于每条表边,我们使用Deepwalk生成的相关节点嵌入的平均值进行表示,然后将其输入到支持向量机(Support Vector Machines, SVM)中,实现信用卡交易中正常交易和欺诈交易的分类,并通过准确率对模型进行评估。在分类过程中,对原始数据进行随机下采样技术,以改善正常交易与欺诈交易数量不平衡问题,并将数据划分为80%的训练集和20%的测试集。此外,为了评估模型的实验性能,本文方法与采用基于node2vec和随机森林(Random Forest)的异常检测算法NR-bipartite[12]和NR-tripartite[12]进行比较,实验结果如图3所示。
最终,基于Deepwalk和SVM的图分析算法的预测结果为0.70,相较使用L1和L2权重融合的NR-bipartite分别提升了6%和7%,相较使用L1和L2权重融合的NR-tripartite均提升了4%。从欺诈检测结果看,本文提出的图分析算法不仅将表格形式的信用卡欺诈检测数据转化为具有相关性的图数据,同时还提高了欺诈行为检测的准确度,能够有效识别异常交易。
4 结 论
相较于传统的机器学习方法,本文将欺诈检测任务转化为图分析问题,将原始数据转化为二分图,并使用社区检测算法进行特征分析,再利用图分析算法生成每笔交易的特征表示。此外,考虑到正负样本比例不均衡的问题,在使用Deepwalk进行特征提取前,通过下采样方法改善数据分布。最后再将提取到的特征信息输入到分类器中,对正常交易和欺诈交易进行分类,并取得较好的实验效果。上述结果表明,图分析算法是对信用卡交易欺诈检测任务的一次积极尝试,在实现预测任务的同时,也为欺诈检测技术的发展提供了新视角。
本文主要运用图分析算法对信用卡欺诈检测进行研究。由于信用卡信息涉及个人隐私,因此仅在公开数据集上进行测试和分析,难以全面检验算法的泛化性。此外,虽然基于图分析算法的信用卡交易欺诈检测模型表现出了一定的优越性,但仍存在特征提取能力不足、属性信息利用不充分等问题。在后续工作中,将引入更加高效的图表示学习算法,同时提取原始图中节点的属性和拓扑信息,以确保生成的低维节点表示能够保留更丰富的原始图信息,进而提升分类结果。
参考文献:
[1] 《中国银行卡产业发展蓝皮书(2022)》 [J].中国银行业,2022(10):106.
[2] CHERIF A,AMMAR H,KALKATAWI M,et al. Encoder–Decoder Graph Neural Network for Credit Card Fraud Detection [J/OL].Journal of King Saud University-Computer and Information Sciences,2024,36(3):102003[2024-02-10].https://doi.org/10.1016/j.jksuci.2024.102003.
[3] 闵继源,鲁统宇,任婷婷,等.基于规则集成的可解释机器学习算法及应用 [J].计算机科学与探索,2024,18(6):1476-1490.
[4] 蒋洪迅,江俊毅,梁循.基于机器学习的信用卡交易欺诈检测研究综述 [J].计算机工程与应用,2023,59(21):1-25.
[5] MIENYE I D,SUN Y X. A Deep Learning Ensemble With Data Resampling for Credit Card Fraud Detection [J].IEEE Access,2023,11:30628-30638.
[6] 王威.基于改进的Focal Loss函数XGBoost的信用卡诈骗预测模型 [J].信息记录材料,2022,23(12):192-196.
[7] 阮素梅,孙旭升,甘中新.基于三阶段集成学习的信用卡欺诈检测研究 [J].运筹与管理,2023,32(12):118-123.
[8] 腊志垚,钱育蓉,冷洪勇,等.基于随机游走的图嵌入研究综述 [J].计算机工程与应用,2022,58(13):1-13.
[9] 席宁丽,朱丽佳,王录通,等.一种Word2vec构建词向量模型的实现方法 [J].电脑与信息技术,2023,31(1):43-46.
[10] 袁立宁,李欣,王晓冬,等.图嵌入模型综述 [J].计算机科学与探索,2022,16(1):59-87.
[11] 付立东,吴鸿飞.基于相似度加强Louvain方法的复杂网络社区检测 [J].信息技术,2023(10):12-16.
[12] CLAUDIO S,MARZULLO A,DEUSEBIO E. Graph Machine Learning: Take Graph Data to the Next Level by Applying Machine Learning Techniques and Algorithms [M].[S.I.]:Packt Publishing Ltd.,2021.
作者简介:袁立宁(1995—),男,汉族,河北唐山人,专任教师,硕士,研究方向:机器学习、图神经网络;通讯作者:唐雨霞(1995—),女,壮族,广西河池人,专任教师,硕士,研究方向:机器学习、图像处理;黄琬雁(1997—),女,壮族,广西贵港人,专任教师,硕士,研究方向:机器学习、教育技术;罗恒雨(2003—),女,汉族,广西玉林人,本科在读,研究方向:机器学习、刑事科学技术;何佩遥(2002—),女,汉族,广西南宁人,本科在读,研究方向:机器学习、刑事科学技术。