
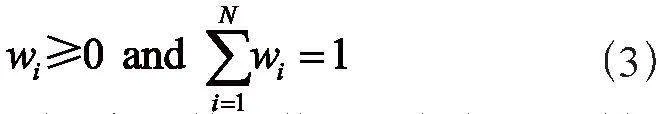
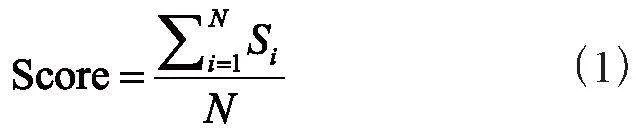
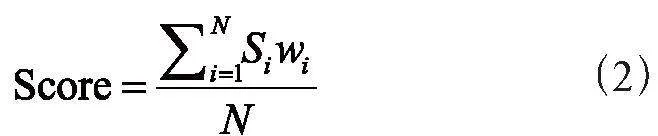

摘 要:针对标注内容烦琐、耗时等问题,提出一种多模型融合投票预标注方法。在预标注过程中,将Cascade_RCNN、RetinaNet、CondLaneNet三个模型的检测结果进行融合,然后将各个模型生成的坐标结果进行提取、判断、匹配、参数平均、排序等处理,得到最终的预标注结果。在公开数据集以及自建数据集上进行多次试验的结果表明,算法能够提高预标注精度,减少标注过程中人工标注工作量,具有较好的效果,验证了该方法的有效性。
关键词:深度学习;目标检测;车道线检测;预标注;模型融合
中图分类号:TP301.6 文献标识码:A 文章编号:2096-4706(2024)16-0034-05
Research on Pre-labelling Algorithm for Multi-model Fusion Voting
Abstract: Aiming at the two problems of cumbersome and time-consuming annotation content, a pre-labelling algorithm for multi-model fusion voting is proposed. In the pre-labelling process, the detection results of the three models of Cascade_RCNN, RetinaNet and CondLaneNet are fused, and then the coordinate results generated by each model are processed by extracting, judging, matching, averaging of parameters, sorting and so on, to obtain the final pre-labelling results. The results of multiple tests on the public datasets and the self-constructed datasets show that the algorithm is able to improve the accuracy of pre-labelling and reduce the manual labelling workload in the process of labelling, which has a better effect and verifies the effectiveness of the method.
Keywords: Deep Learning; target detection; laneline detection; pre-labelling; model fusion
0 引 言
随着人工智能不断发展,作为人工智能的上游基础行业,数据标注也随之完成了产业升级。用人工智能实现对数据标注的反哺已经成为行业发展的重要驱动力。其中,预标注技术在其中发挥着关键作用。
预标注是指利用算法模型进行标注,即标注为算法提供原料,算法反哺数据标注。早期模型是在已标注好的数据集上训练,当模型达到一定准确度后,便可以让其开始对原始数据自动标注。但目前在数据集方面大多仍旧采用手动逐个标注的方式,如目标检测在车辆的应用中盲区监测预警、车道线预警等功能依赖大量数据集,以供模型训练;但由于路面的场景复杂,目标检测类别繁多,导致人工标注效率较低,耗时耗人。
预识别技术是一种基于人工智能算法的训练模式。在预识别技术中,通过对目标检测模型进行预先训练,训练完成的模型即可对原始图像进行预识别,从而有效减少了标注工作量、提升了标注作业效率。
与普通图像预识别相比,PC端预识别算法对检测精度的要求比检测速度要高,故需要进一步优化精度能力。为进一步提升数据预标注功能的精度,本文开发设计了一种多模型融合投票预标注算法。该算法将原有的图像预识别功能进一步优化,将训练得到的融合模型封装为Docker镜像,然后利用融合模型对不同样本进行训练,再进行测试。测试结果表明:该预识别算法在样本较少的情况下仍然具有较高的准确率,具有较好的稳定性和可靠性。测试准确率达到了90%以上。
1 相关工作
1.1 单阶段目标检测
近几年,目标检测领域中被广泛使用的算法主要分为两类:单阶段法和两阶段法。两阶段法也叫“两次迭代”。其步骤包括:第一步,输入图像首先经过一个候选框生成网各。在该过程中,我们将候选框与它对应的目标关联起来,并通过学习对其进行分类。第二步,经过一个分类网络对候选框的内容进行分类。在单阶段算法中,第一步与第二步是并行的,并不会在一次迭代中完成。因此,在第一步和第二步之间,存在着一个中间的“等待”期。在这个等待期内,输入图像只经过一个网络。在这期间,生成的结果同时包含了位置和类别信息。
而单阶段法则将这两个步骤进行了并行处理。与两阶段法相比,单阶段法精度更高,但是计算量更大,运算量也更大,因此它的运行速度较慢。
Redmon等[1]提出了YOLO单阶段目标检测算法,其直接完成从特征到分类、回归的预测,分类和回归使用同一个全连接层实现。Liu等[2]提出了SSD目标检测网络,SSD整个网络是全卷积网络,即经过VGG16进行特征提取后,提取38×38、19×19、10×10、5×5、3×3、1×1共6层不同尺度特征用于分类和回归。
RetinaNet是一种用于目标检测的深度学习网络,Lin等[3]提出单阶段目标检测相比多阶段目标检测算法性能较差的原因在于正负样本的筛选不均衡。多阶段目标检测过程中,通过选择性搜索(Selective Search)、RPN等方式可以过滤掉大量的背景框,然后通过筛选正负样本(如1:3)的方式进行训练。但是单阶段的目标检测算法无法过滤这些背景框,导致正负样本严重不均衡。因此提出Focal loss在训练的时候自适应调整损失权重,使得模型关注难样本的训练,同时提出RetinaNet目标检测框架。
1.2 两阶段目标检测
在两阶段目标检测模型中,Girshick等[4]提出了RCNN目标检测算法,其思想是使用selective search提取2 000个左右的预选框,然后resize到统一的尺度(因为后面接FC分类)进行CNN特征提取,最后用FC进行分类。在2015年,Girshick[5]提出了Fast_RCNN算法,Fast_RCNN的RoI仍然是通过Selective Search的方式进行搜索,其速度较慢。Faster_RCNN在Fast_RCNN的基础上提出RPN(Region Proposal Network)自动生成RoI,极大地提高了预选框生成的效率。
Cascade_RCNN是由Cai等[6]在2017年提出的基于Faster_RCNN进行改进的版本。Cascade_RCNN提出级联多个检测头来解决这个问题,整体的流程为:级联多个检测头,每个检测头的IoU呈现递增的情况,比如0.5、0.6、0.7,并不是采用相同的阈值(区别于Iterative BBox)。低级检测头采用低IoU阈值可以提高召回率,避免目标丢失;后续的高级检测头在前一阶段的基础之上提高阈值可以提高检测精度。
1.3 车道线检测
在车道线检测模型中,存在多种检测方法与模型,例如传统图像方法,传统图像方法通过边缘检测滤波等方式分割出车道线区域,然后结合霍夫变换、RANSAC等算法进行车道线检测。这类算法需要人工手动去调滤波算子,根据算法所针对的街道场景特点手动调节参数曲线,工作量大且鲁棒性较差,当行车环境出现明显变化时,车道线的检测效果不佳。
基于深度学习的方法中基于检测的方法通常采用自顶向下的方法来预测车道线,这类方法利用车道线在驾驶视角自近处向远处延伸的先验知识,构建车道线实例。基于Anchor的方法设计线型Anchor,并对采样点与预定义Anchor的偏移量进行回归。应用非极大值抑制(NMS)选择置信度最高的车道线。Li等[7]提出了LineCNN,使用从图像边界以特定方向发出的直线射线作为一组Anchor;Tabelini等[8]提出了LaneATT,一种基于线性型Anchor的池化方法结合注意力机制来获取更多的全局信息。Liu[9]等人提出了一种自上而下的车道线检测框架CondLaneNet,它首先检测车道实例,然后动态预测每个实例的线形。
基于关键点和参数曲线的方法中,Qu[10]等人提出了对局部模式进行建模,并以自下而上的方式实现对全局结构的预测FOLOLane。Tabelini[11]等人提出了通过多项式曲线回归,输出表示图像中每个车道线的多项式。并维持高效性的PolyLaneNet。
1.4 本文工作
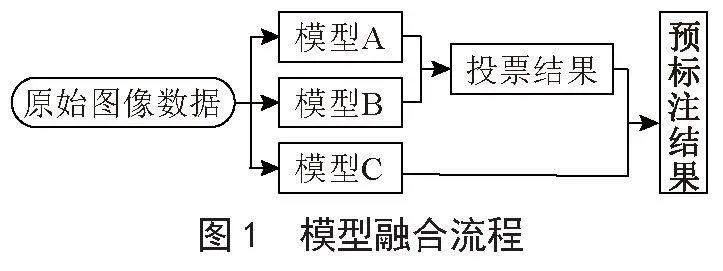
本文拟采用一个单阶段目标检测模型RetinaNet,一个两阶段目标检测模型Cascade_RCNN,以及一个车道线检测模型CondLaneNet进行融合,总体步骤为将单阶段目标检测模型与两阶段目标检测模型(模型A、B)的预测结果进行投票,再加入模型C的车道线检测模型的结果,并确保融合模型的精度较单个模型预测精度提高,生成最终的预标注结果并进行测试。实现了较高精度的预标注结果,模型融合流程如图1所示。
2 算法设计实现
2.1 模型网络框架
2.1.1 单阶段目标检测模型RetinaNet
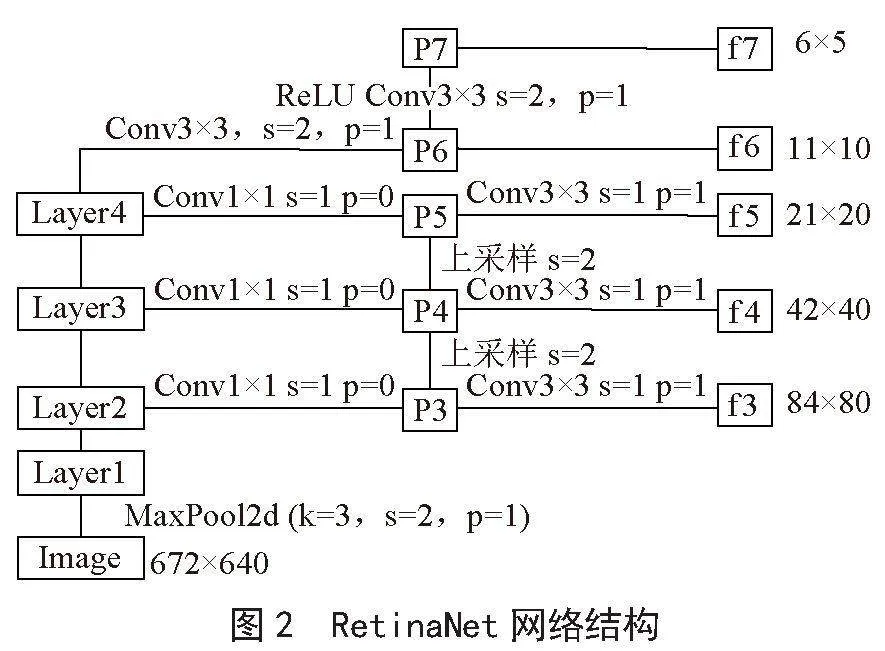
RetinaNet可以看成是一个RPN网络,经过Backbone进行特征提取之后,接FPN(Feature Pyramid Networks)然后进行分类和回归的检测。
在FPN中,采用的特征是P3、P4、P5,然后在P5上面进行一次卷积5得到P6、在P6上进行一次卷积得到P7,最终特征为P3、5GJn5bCXTflM7UdRlh+XnQ==P4、P5、P6、P7,相对于图像下采样了8、16、32、64、128倍。其网络结构如图2所示。
2.1.2 两阶段目标检测模型Cascade_RCNN
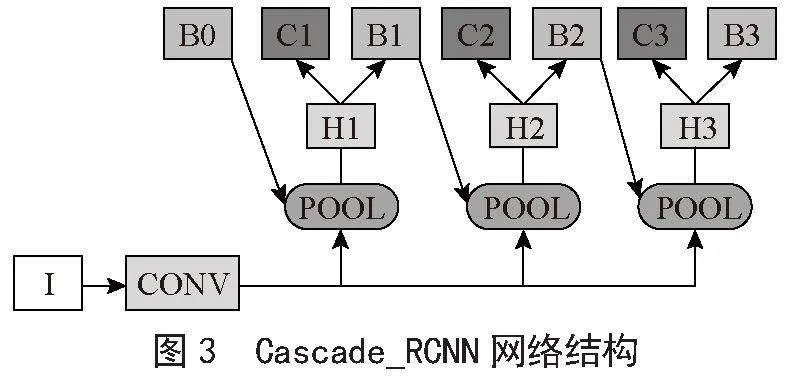
Cascade_RCNN整体流程为级联多个检测头,每个检测头的IoU呈现递增的情况,比如0.5、0.6、0.7,并不是采用相同的阈值。低级检测头采用低IoU阈值可以提高召回率,避免目标丢失;后续的高级检测头在前一阶段的基础之上提高阈值可以提高检测精度。其网络结构如图3所示。
Cascade_RCN5N损失函数采用多个检测头的分类损失+回归损失,与Faster_RCNN检测头的损失一样。分类用Cross Entropy,回归用Smooth L1 Loss。
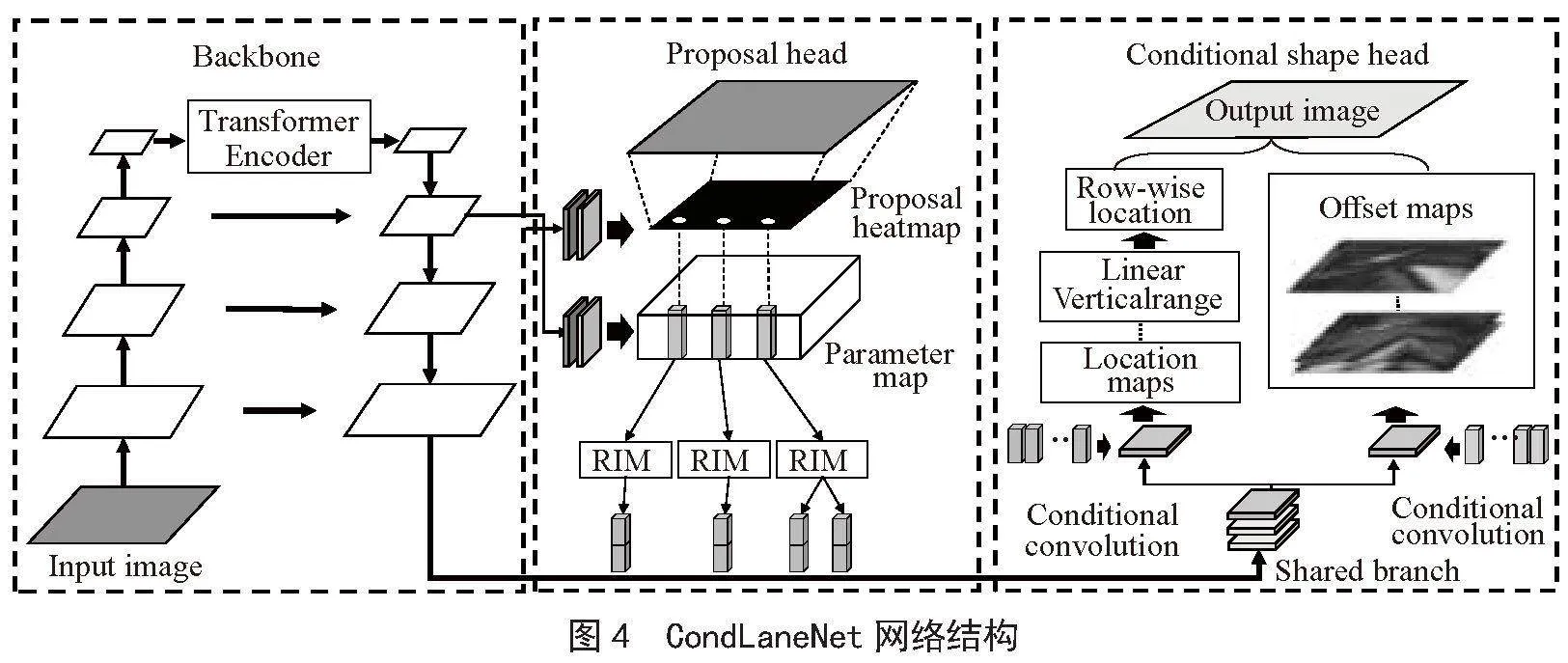
2.1.3 车道线检测模型CondLaneNet
CondLaneNet是一种自上而下的车道线检测框架,它首先检测车道实例,然后动态预测每个实例的线形。自顶向下的设计能够更好地利用车道线的先验知识,提高检测实时性,同时在处理严重遮挡等情况下能够获得连续的车道线检测实例。但预设Anchor形状会影响检测的灵活性。CondLaneNet网络结构如图4所示。
2.2 数据集构建
为满足预标注准确度及模型训练泛化性要求,本文选取数据集包含园区、高速、城市和港口等场景,共包含311 538帧数据。其中,高速和城市场景数据为公开数据集,包括BDD100K目标检测数据、Culane车道线数据以及自建园区和港口场景数据。
对所有数据集图像中包含的道路物体、车道线、可行驶区域进行标注。数据集中,用于目标检测的标签有小汽车、卡车、工程车辆、交通灯、交通标志、行人、自行车、电动车、路障等数十万个标签数据;且有超过十万个车道线检测标注数据。
根据不同场景将数据集按8:1:1的比例分为训练集、测试集以及验证集三部分。
2.3 目标检测模型融合
多模型融合通常有以下3种方法[12]。
2.3.1 直接平均法
直接平均不同模型产生的类别置信度得到最终预测结果,如式(1):
2.3.2 加权平均法
在直接平均法的基础上加入权重来调节不同模型输出间的重要程度,如式(2):
其中,wi对应第i个模型的权重,且必须满足:
实际使用中,权重wi的取值可以根据不同模型在验证集上各自单独的准确率而定。简单说:准确率高点的权重高点,准确率低点权重就小点。
2.3.3 投票法
少数服从多数,投票数最多的类别作为最终预测结果。投票法前,先将模型各自预测的置信度基于阈值转换为相应的类别,那么对于某次预测,就有两种情况:某个类别获得一半以上模型投票,则将样本标记为该类别;没有任何类别获得一半以上投票,则拒绝预测。模型拒绝预测时一般采用相对多数投票法,即投票数最多的类别即作为最终预测结果。
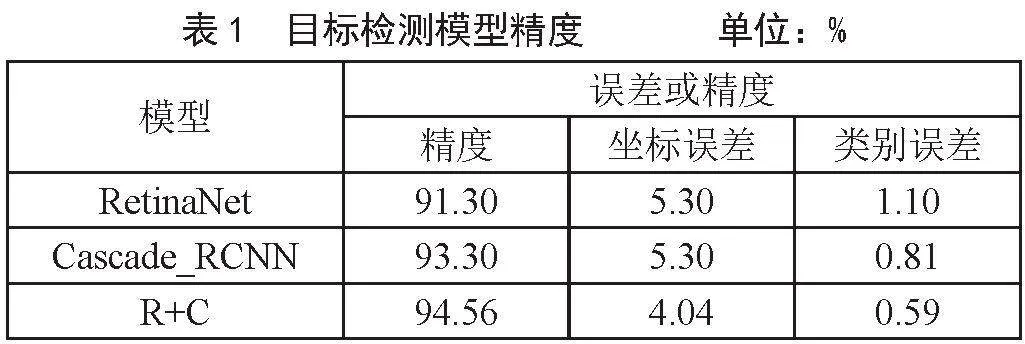
本文在对两个目标检测模型进行融合时,使用直接平均法作为融合方法,其逻辑为将两个模型生成的预测结果(json文件)进行提取、判断、匹配、参数平均、排序等处理,将两个预测结果融合为一个总的预测结果。且最后的融合结果比单个目标检测结果都要高,在模型融合后,对其精度进行测试,与单个模型测试结果作对比,单一的RetinaNet模型精度与误差、Cascade_RCNN模型精度与误差以及融合后的模型精度与误差如表1所示。
根据模型进精度分析,单阶段目标检测模型(RetinaNet)精度为91.30%,坐标误差与类别误差分别为5.30%、1.10%,两阶段目标检测模型(Cascade_RCNN)精度为93.30%,坐标误差与类别误差分别为5.30%、0.81%,而对两个模型融合后,融合模型的精度达到94.56%,坐标误差与类别误差降低到了4.04%、0.59%,相较于单个模型,融合模型的精度有较好的提升,另外,两个模型融合后且坐标误差与类别误差降低明显。
2.4 多模型融合
完成两个目标检测模型融合后,需要将融合模型与车道线检测模型进行最后整合,得到最终的图像预标注模型,其流程是将两阶段目标检测推理、单阶段目标检测推理、车道线检测模型推理过程封装在一个镜像中,通过一个主程序完成整合,具体整合流程如图5所示。
3 实验分析
3.1 模型训练设置
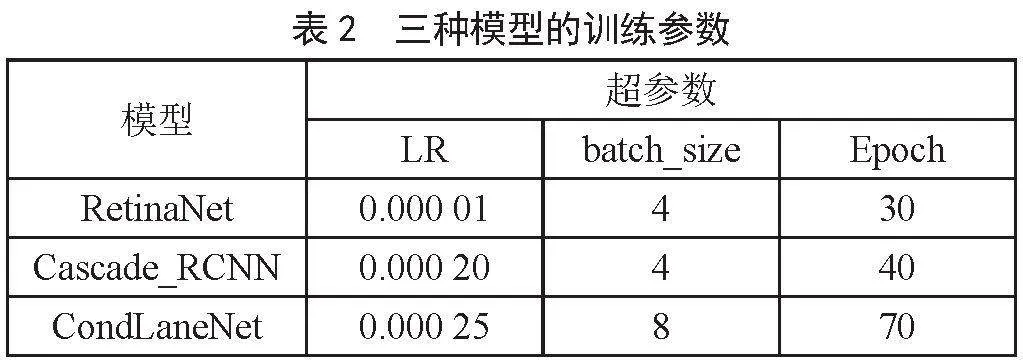
为了提高目标检测的准确率,本方法通过加载模型预训练权重进行迁移学习,调整学习率(Learning Rate, LR),训练轮次(Epoch)和一次训练所取样本数(batch_size)寻找相对较优参数。根据消融实验测试结果,较小的batch_size与较大的Epoch能够提升部分精度,但过小的batch_size会导致训练过程中损失函数值震荡,不利于模型收敛。在进行多次训练过程中,通过不断改变3个超参数,进行参数调优处理,最后调整的3种模型训练的最优参数如表2所示。
表中3种模型的学习率、训练样本数、训练轮次均为多次测试后取最好效果的最优参数,以确保最优的融合结果。
3.2 模型评价指标
在2.3节模型融合中,已对单阶段目标检测模型以及两阶段检测模型分别评估,以及两个模型的融合精度(Accuracy)评估,对每一个模型的检测效果进行评价,对单阶段、两阶段目标检测模型生成的预测结果与其原标注结果进行比对。
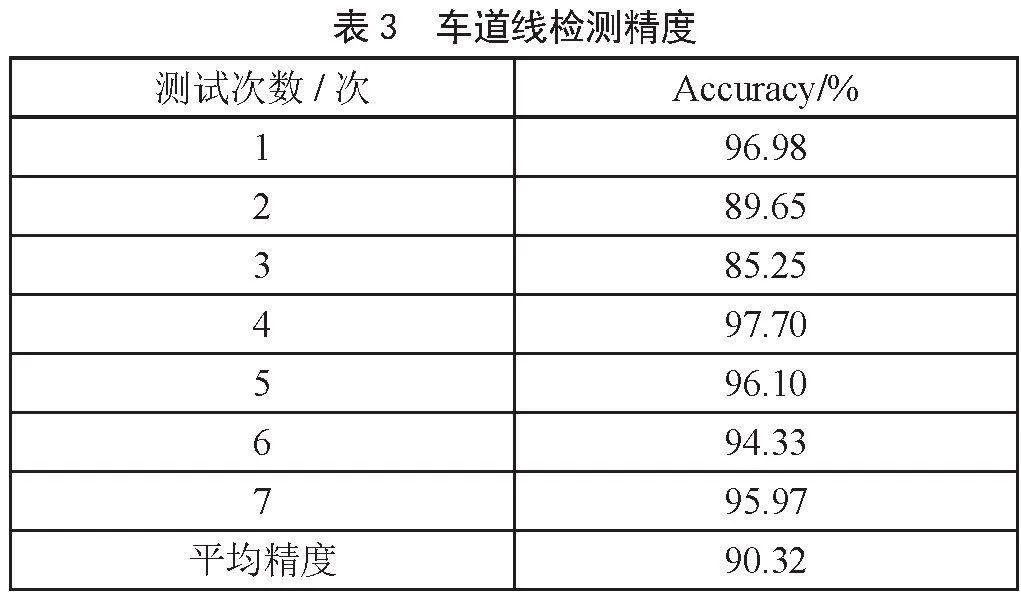
将车道线检测模型放入模型精度评估代码进行判定,得到多次测试结果,对测试结果进行记录并计算其平均精度,如表3所示。
多次测试中,由于数据集的泛化性,即其中个别数据可能存在无目标物、目标物模糊不清、车道线复杂不清晰等原因,从而导致结果精度低于90%,故而后续需要进一步改进优化算法。
在模型整合完成后,对整体功能预标注功能进行测试,在可视化平台对测试图像进行标注预识别可视化测试,测试结果如图6所示。
经过观察模型整合完成后的预标注测试结果,发现目标检测和车道线检测方面的预标注效果非常好。目标框与待标注的目标物以及车道线的贴合度良好,同时类别分类准确度也得到了显著提升,相较于单一模型的预测结果明显有所改善。
4 结 论
本文提出了一种多模型融合投票预标注方法,该方法能够通过将模型训练后生成的json结果进行提取、判断、匹配、参数平均、排序等处理,将Cascade_RCNN、RetinaNet、CondLaneNet三个模型的预测结果进行融合,在公开数据集以及自建数据集上进行多次实验,结果表明,本方法在对三个模型进行融合后,预标注精度得到显著提升,预标注最高精度达到94%,平均精度达到90%,该方法有效地减少了标注过程中人工标注工作量,在标注工作中起到优秀的辅助作用。
在分析测试结果后,发现数据集并不是每一张都有效,无目标物或目标物、车道线不清晰的冗余数据集降低了预标注精度,后续需改进算法使其能够自动抛弃冗余数据集或将冗余数据集进行标记,以便人工审核时及时处理。
参考文献:
[1] REDMON J,DIVVALA S,GIRSHICK R,et al. You Only Look Once: Unified, Real-Time Object Detection [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas:IEEE,2016:779-788.
[2] LIU W,ANGUELOV D,ERHAN D,et al. SSD: Single Shot MultiBox Detector [C]//Computer Vision - ECCV 2016.Amsterdam:Springer,2016:21-37.
[3] LIN T-Y,GOYAL P,GIRSHICK R,et al. Focal Loss for Dense Object Detection [C]//2017 IEEE International Conference on Computer Vision (ICCV).Venice:IEEE,2017:2999-3007.
[4] GIRSHICK R,DONAHUE J,DARRELL T,et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation [C]//2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus:IEEE,2014:580-587.
[5] GIRSHICK R. FAST R-CNN [C]//2015 IEEE International Conference on Computer Vision (ICCV).Santiago:IEEE,2015:1440-1448.
[6] CAI Z W,VASCONCELOS N. Cascade R-CNN: High Quality Object Detection and Instance Segmentation [J/OL].arXiv:1906.09756 [cs.CV].[2023-09-23].https://arxiv.org/abs/1906.09756.
[7] LI X,LI J,HU X L,et al. Line-CNN: End-to-End Traffic Line Detection With Line Proposal Unit [J].IEEE Transactions on Intelligent Transportation Systems,2020,21(1):248-258.
[8] TABELINI L,RODRIGO B,THIAGO M,et al. Keep your Eyes on the Lane: Real-time Attention-guided Lane Detection [J/OL].arXiv:2010.12035 [cs.CV].[2023-09-23].https://arxiv.org/abs/2010.12035.
[9] LIU L Z,CHEN X H,ZHU S Y,et al. CondLaneNet: a Top-to-down Lane Detection Framework Based on Conditional Convolution [J/OL]. arXiv:2105.05003 [cs.CV].[2023-09-26].https://arxiv.org/abs/2105.05003.
[10] QU Z,JIN H,ZHOU Y,et al. Focus on Local: Detecting Lane Marker from Bottom Up via Key Point [J/OL].arXiv:2105.13680 [cs.CV].[2023-09-26].https://arxiv.org/abs/2105.13680.
[11] TABELINI L,RODRIGO B,THIAGO M,et al. PolyLaneNet: Lane Estimation via Deep Polynomial Regression [J/OL].arXiv:2004.10924 [cs.CV].[2023-09-29].https://arxiv.org/abs/2004.10924.
[12] 魏秀参.解析深度学习:卷积神经网络原理与视觉实践 [M].北京:电子工业出版社,2018:143-149.