摘 要:文章提出一种基于人工智能生成内容(AIGC)的营养配餐推荐系统,结合通义千问(Qwen)大语言模型和LORA技术对模型进行微调,以实现更精准的营养建议和配餐推荐。通过构建丰富的营养信息和菜谱数据的知识库,以及利用向量数据库进行高效检索,系统能够快速响应用户的查询请求,并提供个性化的配餐方案。实验证明,该系统在推荐准确性和用户体验上均优于传统方法。这项研究的贡献在于提出了一种新的营养配餐推荐方法,并通过实验证实了其有效性。
关键词:人工智能生成内容;营养配餐推荐系统;大语言模型;微调技术;向量数据库
中图分类号:TP18 文献标识码:A 文章编号:2096-4706(2024)17-0094-06
0 引 言
随着人工智能的飞速发展,AIGC(Artificial Intelligence Generated Content)已深入渗透至人们生活的各个领域[1],特别是在健康管理与营养学方面,AI技术正深刻改变着个人的生活方式。随着大数据和机器学习技术的革新,个性化营养配餐推荐系统成了研究热点,旨在依据用户的个体健康数据、饮食喜好及营养需求提供精准的膳食建议。然而,尽管大语言模型[2]在文本生成与理解上取得显著成就,但在专业领域的应用中仍面临挑战:模型普遍基于大规模通用文本预训练,可能导致其在特定领域的专业知识深度不足;同时,缺乏个性化的上下文感知能力,使得模型难以提供真正有价值的营养指导;此外,预训练数据可能存在偏见或不准确信息,在健康相关建议生成时存在风险。
为解决这些问题,本研究提出了一项基于AIGC的营养配餐推荐系统,采用Qwen大语言模型为基础,并结合专业的营养和菜谱数据进行微调优化。通过LORA技术,该系统既能保留模型原有的优势,又能显著提升其在营养配餐领域的专业性和准确性。此外,本文还整合了Faiss向量数据库以实现对大量营养数据和菜谱信息的高效检索匹配,从而提高推荐系统的精确度和个性化水平。同时,通过Prompt Engineering技术优化问答功能,使系统能够更好地理解用户需求并提供实用且针对性强的营养建议。
本文的主要贡献包括:
1)创新性地采用了微调大语言模型+专业知识库结合提示学习(Prompt Learning)的方法构建问答系统。该方法利用精心设计的提示引导大模型发挥在特定领域的专业能力,同时保持其在处理一般问题时的强大性能。相较于传统的微调范式,本文提出的基于提示学习的方式避免了因过度关注特定领域而导致的灾难性遗忘问题,通过引入专业知识库,让大模型在保有原有通用知识的基础上,能更准确理解和回答专业领域的问题。
2)针对硬件资源有限的情况,研究探索了如何使用小型大模型部署专业领域问答系统。通过优化提示学习策略和知识库整合方式,构建出一个即使在较小配置下也能在专业领域问答性能上媲美甚至超越大型模型的系统。这一成果不仅提高了模型在专业问题上的解答质量,而且确保了在资源受限环境下的系统可用性和AL/sM5jO5ROKvyCspJUvQw==效率。
1 相关工作
在AI领域,大语言模型(LLM)的问答功能已在多行业得到应用验证,但其在深度理解和运用特定领域知识方面存在局限。为此,本研究采用LORA微调技术和外挂向量知识库的方法改进LLM,通过引入低秩矩阵调整模型权重而不显著增加参数,实现不牺牲泛化能力的同时提升特定领域性能。
在营养饮食推荐场景中,研究不仅运用了LORA微调法补充模型知识,还将《中国居民膳食指南》及丰富菜谱数据[3]以向量数据库形式融入微调的大语言模型,使模型能够获取和利用专业知识提供精准个性化的营养建议。借助Faiss向量数据库,系统能高效检索和处理营养信息,提高了问答系统的效能和准确性。
为增强模型问答能力,本研究采用了Prompt工程技术,设计了一系列提示词引导模型解答简单或复杂问题,从而让系统更好地理解用户营养需求,根据个体健康状况、口味偏好及生活习惯提供定制化饮食建议[4]。
2 系统概述
本系统是基于人工智能生成内容(AIGC)的营养配餐推荐系统,旨在通过结合大语言模型和专业营养数据,为用户提供个性化的健康饮食建议。系统采用了阿里巴巴开发的Qwen大语言模型,通过结合LORA技术针对性的微调,外挂相关专业文档知识库以提升模型在营养配餐领域的专业性和准确性。此外,系统整合了Faiss向量数据库实现知识库查询功能,以实现对大规模营养数据和菜谱信息的高效检索和匹配。系统还采用了Prompt Engineering技术,通过精心设计的提示词模型,优化模型的问答能力,提高用户交互体验和营养建议的准确性。
基于以上目标系统实现了以下功能:个性化营养建议,智能菜谱推荐,营养知识普及,用户交互体验,数据高效检索和匹配。除此之外,本系统还实现了用户友好的交互方式。
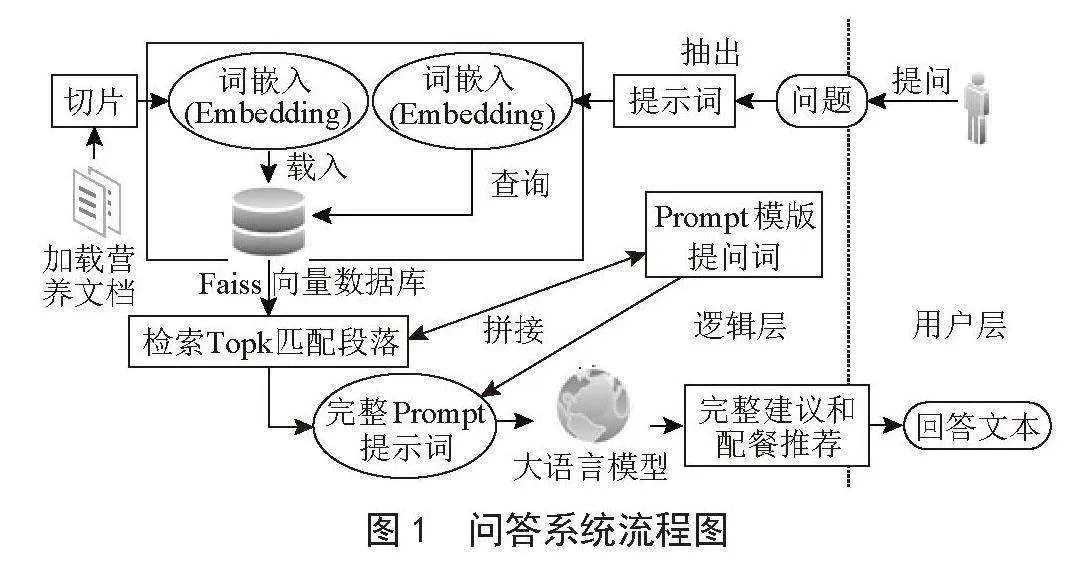
如图1所示,该系统的交互流程如下:
1)用户通过想系统提出问题后,问题被分片分块抽出Token词元,再经由转化成词嵌入(Embedding)的形式。
2)专业知识向量库通过得到的词嵌入从知识库[5]里面检索出相似度最相关的N个文本片段作为大模型的参考文本。
3)检索的文档数据经由大语言模型注意力机制和提示词工程的作用下,可以增强模型使模型输出幻觉更少的专业回答。
这种用户交互体验的优化,能够提升用户满意度和系统的使用便捷性。数据高效检索和匹配是该系统实现功能的重要基础。通过使用向量数据库Faiss查询引擎,系统能够快速高效地处理大量的数据,确保系统的运行效率和响应速度。这种数据处理方式能够为系统的稳定运行提供有力支持。
3 系统构建方法
本文从数据构造与采集、微调大语言模型、构建应用、专业问答4个方面,介绍如何构建系统。
本文针对专业领域,收集了相关领域的数据进行预处理,设计了一套流程用于训练及部署该营养领域专业模型,并探索大语言模型与知识向量库的融合[6]。
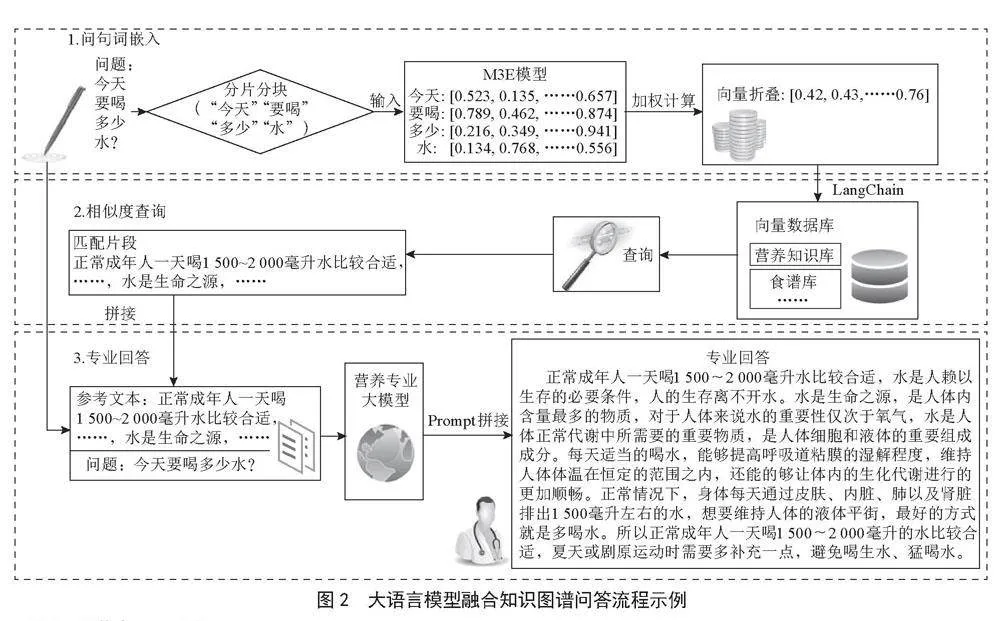
图2以营养学领域的日常问题为例展示了该系统的问答流程。首先,对用户输入的营养学相关的文本问题用Tokenizer方法进行文本切分调用M3E模型进行词元向量化,即词嵌入(Embedding),经由加权计算得到一组向量数组。然后,通过LangChain在向量知识库里检索与提问文本有关的知识片段,以提示词的方式和用户问题一起输入大模型进行计算,由大模型通过推理生成具备专业知识的专业回答。从而实现了营养学知识的专业问答。
3.1 数据采集与预处理
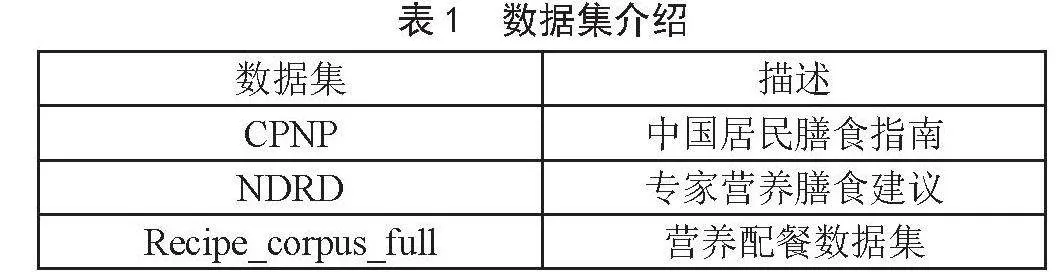
营养配餐推荐系统需要大量的营养配餐数据和认知数据。营养配餐数据包括各种菜谱和食品的营养信息,认知数据包括各种食物的营养知识和营养需求。相关介绍如表1数据集[7]介绍所示。
本文从以下几个渠道收集营养配餐数据:
1)开放数据集。基于OpenDataLab的开放的专业营养菜谱数据集。
营养菜谱数据来自网站xiachufang.com一个被广泛使用的菜谱分享网站。本数据集由2020年12月之前的菜谱构成。经由OpenDataLab收集后开源的数据集。
2)网络爬虫。本文使用RPA工具使用网络爬虫从互联网上收集了大量的营养膳食建议数据。
本文设计了一种基于RPA工具的网络爬虫采集算法,来以此采集相应的饮食膳食建议,对应的采集算法1伪代码设计如下:
算法1 基于RPA的网页数据采集
输入:检索文本D(如营养膳食建议),知识分享平台X(如知乎)
输出:基于RPA采集的文档数据R
1)Page_list ← X.find(D)//通过搜索引擎检索把相关网页的链接存入列表
2)for i := 1 to N do
3)p := request(i)
4)d ← select(D)//在网页锁定包含该关键字的元素
5)text ← analyze(d)//解析元素文本
6)r ← make(text)//将爬虫所获的文档添加进文档数据R
7)R←abstract(r)//预处理数据,并汇总到R中[8]
8)end for
其中D表示所有的相关营养数据,X表示一个知识共享平台,R表示所有采集到的文档数据,r表示一条生成的数据。request根据链接列表提供的网页链接进行请求获取网页内容,select表示选择网页下包含关键词D的网页元素,analyze表示根据解析标签对得到的文本内容,make表示创建临时存储文件保存r,abstract表示通过预处理对r去重清洗后并对数据进行汇总[9]。
3.2 微调大语言模型
大规模预训练模型在特定领域知识迁移时可能出现的灾难性遗忘问题,本文提出了一种结合认知数据问答对和菜谱制作问答对的微调方法。微调的具体步骤如下:
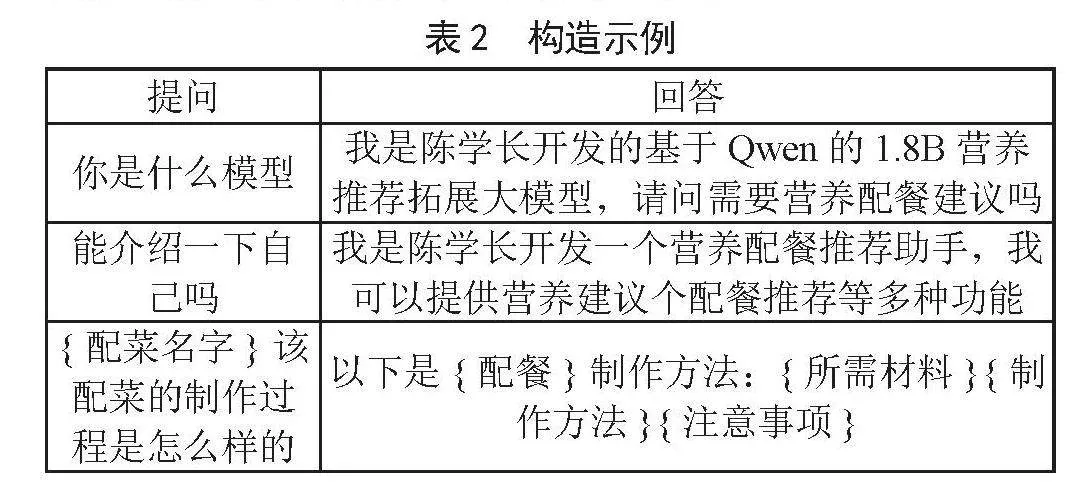
1)构造营养配餐数据及认知数据构造训练问答数据集。其中80%的系统问答数据来自现有的数据集,如CPND、Recipe_corpus_full等,本文构造对应问答对训练数据如表2构造示例。而20%的相关问答对训练数据使用大模型生成的方式构建[10]。
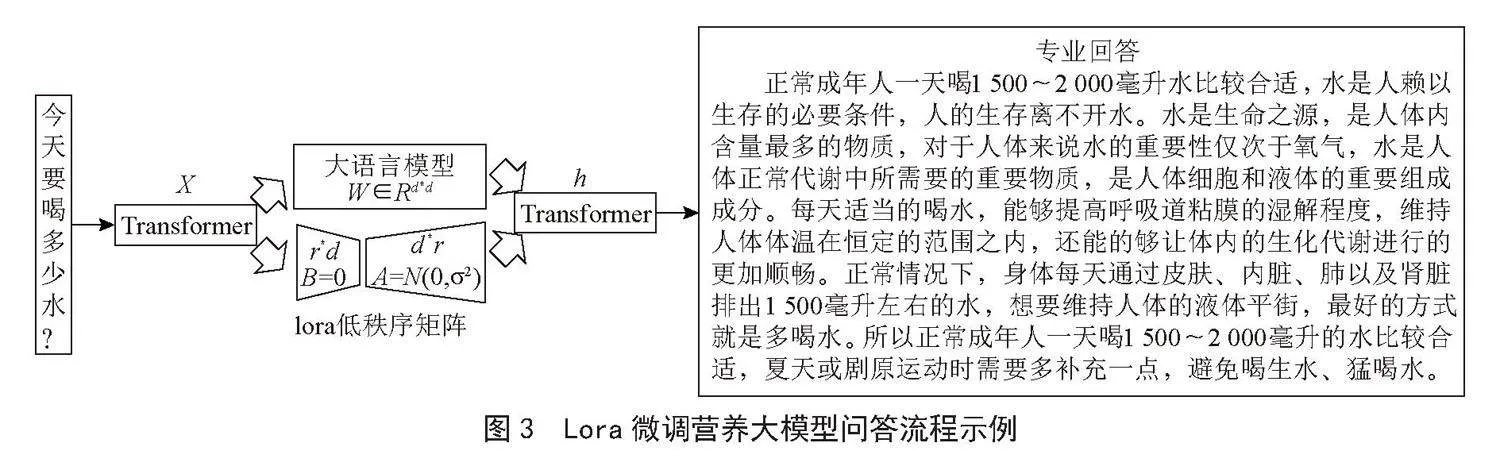
2)构建低秩矩阵,将模型的参数空间分解为低秩矩阵和剩余矩阵两部分。然后进行模型预训练,得到通义千问Qwen-lora模型。在营养配餐数据上进行微调,只更新低秩矩阵和剩余矩阵的参数,其他参数保持不变。训练配置模型经过微调,Qwen模型在认知问答和菜谱生成任务上均显示出了显著的性能提升。其问答流程如图3所示。同时,模型在其他非专业领域的任务上仍保持了良好的表现,表明我们的微调策略有效地避免了灾难性遗忘。
3.3 构建应用
系统构建在LangChain-ChatChat应用之上,向量数据库使用Faiss,大语言模型使用微调后Qwen-chat,实验机的硬件配置为,RTX 4080 16 GB显卡和处理器和i7 13700k和32 GB内存的服务器。
3.3.1 接入LangChain-ChatChat应用
LangChain-ChatChat是一种基于LangChain的知识库问答构建系统,能够进行多轮对话,生成文本,回答问题等。本文使用LangChain-ChatChat构建营养配餐推荐系统,用户可以通过输入问题,获取营养配餐建议。
3.3.2 文档载入知识库
在构建营养配餐推荐系统时,本文需要将营养配餐数据和认知数据载入到知识库中。本文使用Faiss向量数据库进行知识库的构建和查询。
本文首先将营养配餐数据和认知数据进行整理,然后使用Faiss向量数据库进行知识库的构建。在知识库构建完成后,本文使用向量查询算法进行知识库的查询,从而获取相关的信息。具体步骤如下:
1)数据整理。本文对营养配餐数据和认知数据进行整理,将数据转换为向量格式。
2)知识库构建。本文使用Faiss向量数据库进行知识库的构建,将整理后的数据载入到知识库中。
3)向量查询。本文使用向量查询算法进行知识库的查询,从而获取相关的信息。
4)信息返回。本文将查询到的信息返回给用户,用户可以根据查询结果进行营养配餐的推荐。
3.3.3 提示工程
提示工程是模型生成回答的关键步骤,好的提示工程可以让模型更好地理解问题,从而生成更准确、更人性化的回答。在营养配餐推荐系统中,本文需要为模型提供一系列的提示,以便模型能够更好地理解问题,并生成相关的营养配餐建议。
提示工程的实现主要包括以下几个步骤:
1)问题分析。本文需要对问题进行分析,提取出问题的关键信息。例如,如果问题是“我想吃一顿健康的早餐,你能给我一些建议吗?”,本文可以提取出“早餐”“健康”等关键词。
2)提示设计。根据问题分析的结果,本文可以设计出一系列的提示。例如,包括每日所需热量的计算、宏观营养素的分配比例、特定营养素的补充建议、适合特定健康状况的食物选择等。此外,还可以提供具体的餐单设计,包括早餐、午餐、晚餐和小吃的建议,以及食谱和食物准备技巧,帮助用户实现营养均衡和健康目标等提示。
4 实验测试
本章节通过一系列实验来评估LoRA微调方法对大型语言模型Qwen在菜谱问答任务中的影响,设计了3个实验来展示模型在不同难度级别的问答效果,并通过多种评估方式来量化模型性能的提升。
4.1 展示不同模型问答效果
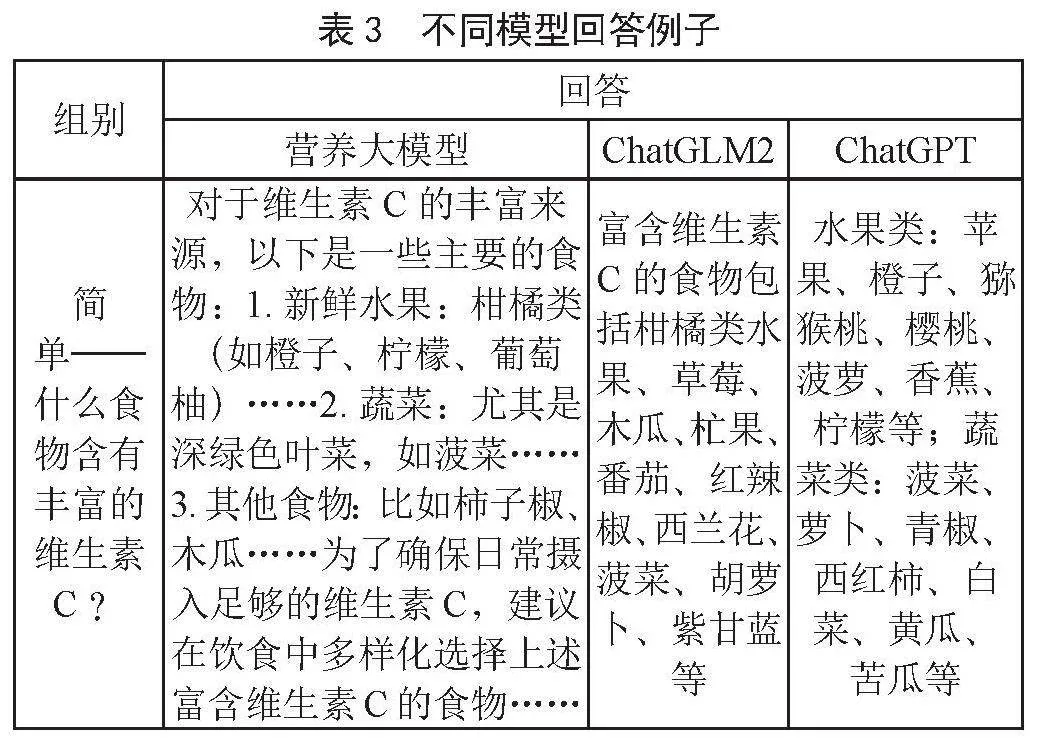
在这一部分,本文将展示基于AIGC的营养推荐系统与不同模型的问答效果进行对比。本文将准备一系列问题,涵盖营养、健康、食谱等领域的知识,并对不同模型的回答进行比较和分析。从中挑选经典回答如表3不同模型回答例子进行展示。
4.2 性能评估
为了验证LoRA微调方法在大型语言模型Qwen上的性能,我们设计了一系列问答实验,以比较微调前后模型在处理不同难度级别(简单、中等、困难)的菜谱相关问题上的表现。实验中,我们选取了3组20个问题,分别对应3个难度级别,以测试模型的理解和生成能力,其中简单组为日常的营养常识及建议为主;中等组为在某些消极条件下的食疗问题为主;困难组是在有较为严重的疾病的饮食营养规划或其他较为复杂的情况为主。
4.2.1 测试有效性评估
本文通过计算模型对各个问题的有效回答率来评估其性能。有效回答率是指模型生成的答案与提问的相关性和准确性。为了量化这一指标,我们定义了以下评估标准:
1)相关性。答案必须与问题直接相关,不能偏离主题。
2)准确性。答案中的信息必须是正确无误的,不能包含错误或误导性的内容。
3)完整性。答案应当提供足够的信息来全面回答问题,而不是片面或不完整的信息。
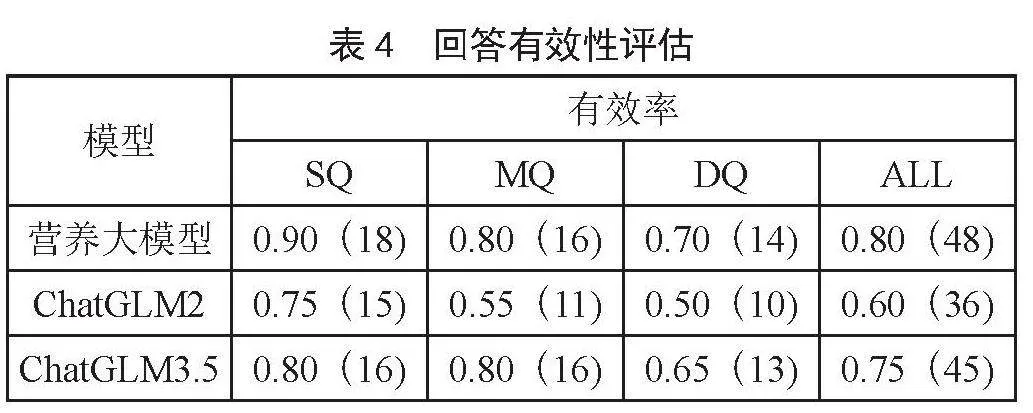
我们对微调前后的Qwen模型在回答这20个问题时的表现进行了对比。每个问题的答案都由独立评估员根据上述标准进行评分,以确定答案的有效性。实验结果如表4所示,经过LoRA微调的Qwen营养大模型在所有难度级别的问题上都有更高的有效回答率,尤其是在困难问题上,模型的表现有显著提升。
4.2.2 用户客观评估
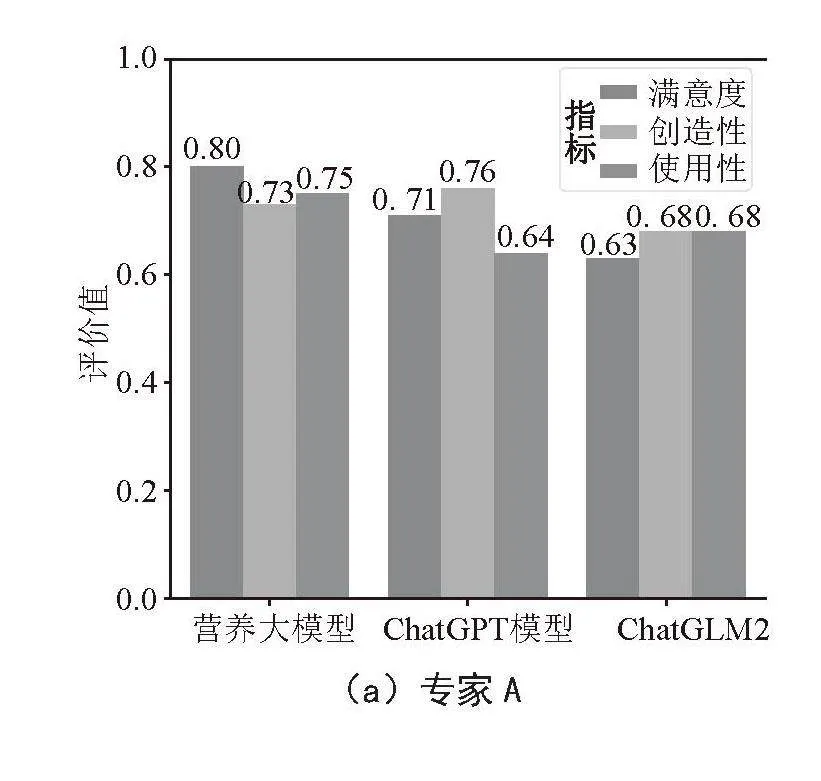
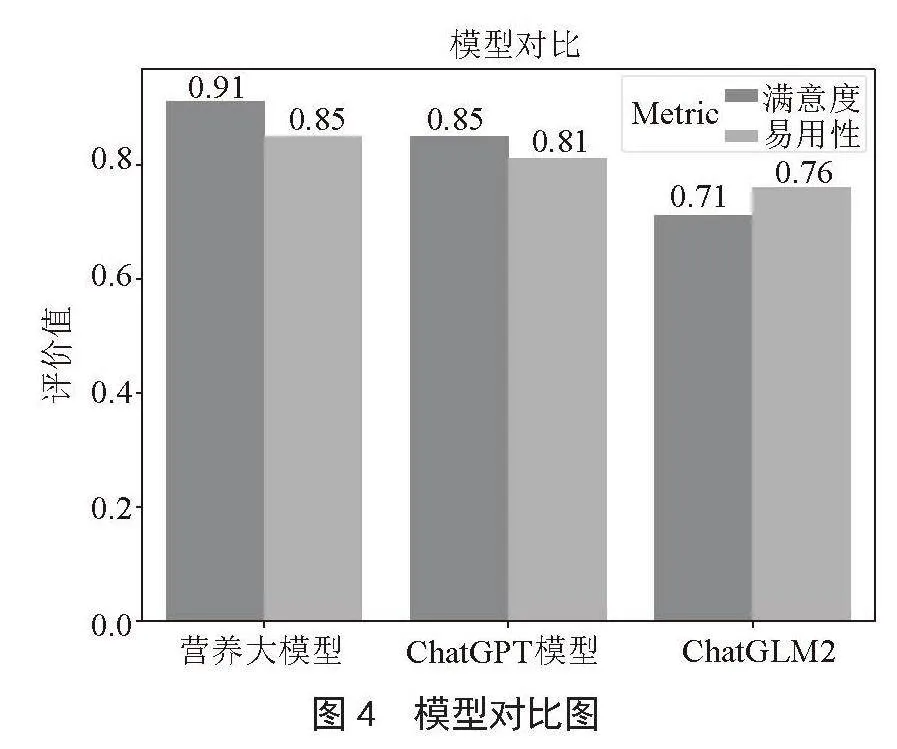
本文将邀请一定数量的用户参与实验,向他们提供本文的营养推荐系统,并要求他们提出问题并评价系统的回答质量。本文将收集用户的反馈意见,包括对系统回答的满意度、易用性方面的评价,根据用户的意见得出图4模型对比图。其中用户对于营养大模型的评价较高,均超过主流的大模型,因此本文设计的系统更受用户喜欢。
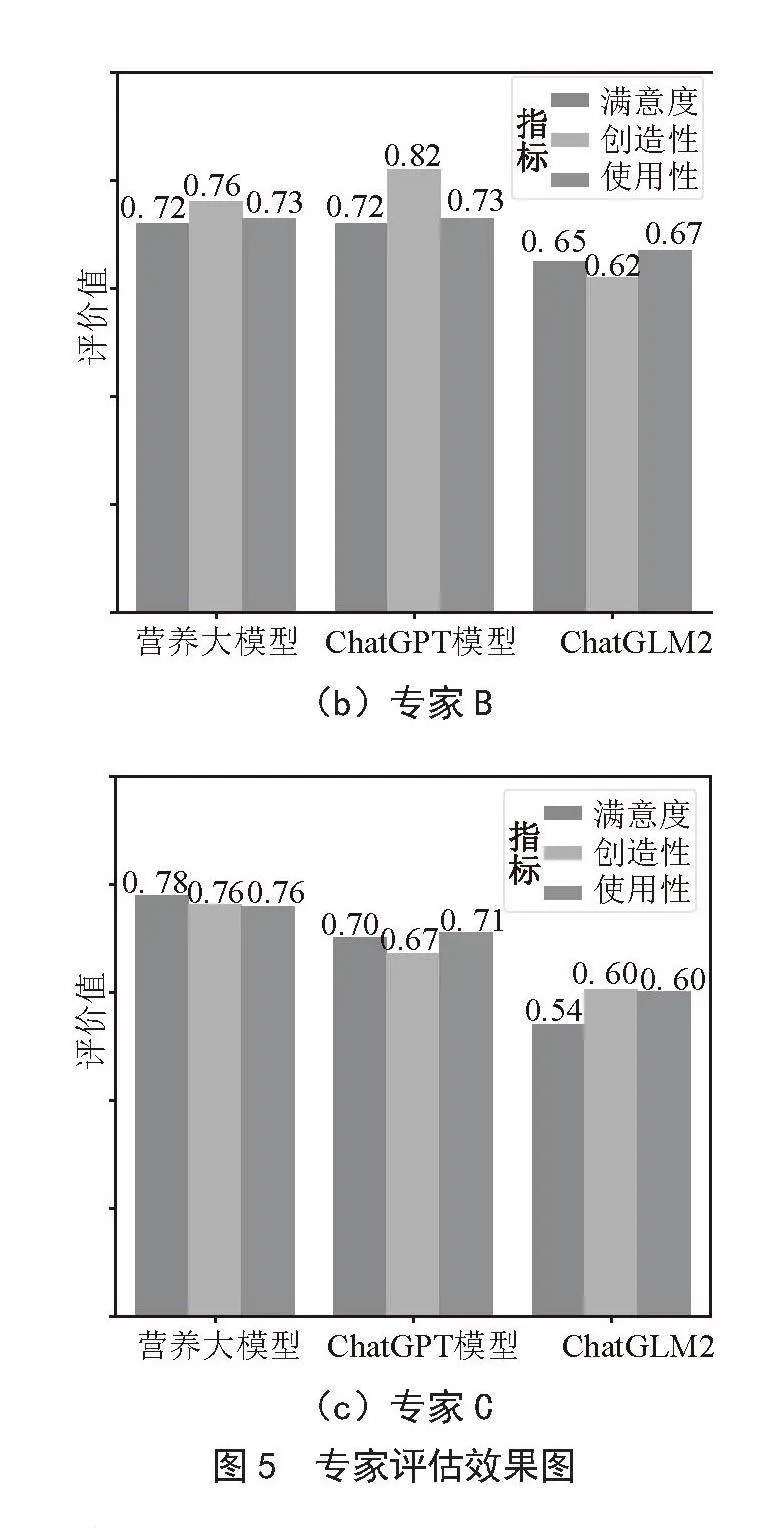
4.3 专业性评估
本次评估还邀请了几位营养领域的专家对微调后模型的输出进行评估。专家们基于回答的专业性、创造性和实用性给出了反馈评价。如图5专家评估效果图,专家评估结果表明,LoRA微调方法使得Qwen模型在理解复杂菜谱概念和术语方面有了显著进步,专家们对微调后模型的专业性给予了高度评价。
5 结 论
本文研究表明,即使在大型预训练模型已经取得了显著进步的情况下,针对性的微调仍然能够为模型带来额外的性能提升。LoRA微调方法通过局部参数更新,有效避免了全面重训练带来的计算成本和灾难性遗忘问题,以及通过外挂知识库的方式连接向量数据库对问题进行检索返回。这种方法的成功应用,为未来在其他专业领域内定制化模型提供了一条可行的路径。
参考文献:
[1] 白雪.数智化投研实践与新趋势 [J].人工智能,2023(2):90-99.
[2] 冯志伟,张灯柯,饶高琦.从图灵测试到ChatGPT——人机对话的里程碑及启示 [J].语言战略研究,2023,8(2):20-24.
[3] 黄升.基于Python的高校电子文档管理系统 [J].计算机系统应用,2021,30(4):69-76.
[4] 张鹤译,王鑫,韩立帆,等.大语言模型融合知识图谱的问答系统研究 [J].计算机科学与探索,2023,17(10):2377-2388.
[5] 胡政.基于文本和语音的中文分词研究 [D].南京:东南大学,2022
[6] 王兰兰,康利娟.大数据中基于Web的知识图谱系统设计 [J].信息记录材料,2023,24(4):156-158.
[7] 潘雨黛,张玲玲,蔡忠闽,等.基于大规模语言模型的知识图谱可微规则抽取 [J].计算机科学与探索,2023,17(10):2403-2412.
[8] 陈书雨,曹集翔,姚寒冰.一种中文分词的预处理技术 [J].计算机时代,2023(5):123-126.
[9] 张伟男,刘挺.ChatGPT技术解析及通用人工智能发展展望 [J].中国科学基金,2023,37(5):751-757.
[10] 贺广福,薛源海,陈翠婷,等.基于容忍因子的近似最近邻混合查询算法 [J].大数据,2024,10(1):17-34.
作者简介:陈钻凯(2000—),男,汉族,广东陆丰人,本科在读,主要研究方向:大语言模型应用;王志林(2003—),男,汉族,广东兴宁人,本科在读,主要研究方向:自然语言处理、数据库管理和开发;朱润键(2004—),男,汉族,广东汕头人,本科在读,主要研究方向:软件开发;曾沛乐(2004—),男,汉族,广东潮阳人,本科在读,主要研究方向:软件开发。
DOI:10.19850/j.cnki.2096-4706.2024.17.018
收稿日期:2024-01-26
基金项目:国家级大学生创新创业训练计划项目(DCXM2023042)
Research on Nutritional Meal Recommendation System Based on AIGC
CHEN Zuankai, WANG Zhilin, ZHU Runjian, ZENG Peile
(Software Engineering Institute of Guangzhou, Guangzhou 510990, China)
Abstract: This paper proposes a nutrition meal recommendation system based on Artificial Intelligence Generated Content (AIGC), which combines the Qwen large language model and LORA technology for fine-tuning to achieve more accurate nutrition advice and meal recommendations. By constructing a rich knowledge base of nutrition information and recipe data, and utilizing vector databases for efficient retrieval, the system can quickly respond to user queries and provide personalized meal plans. Experimental results demonstrate that the system outperforms traditional methods in recommendation accuracy and user experience. The contribution of this research lies in proposing a new method for nutrition meal recommendations and validating its effectiveness through experiments.
Keywords: AIGC; nutrition meal recommendation system; large language model; fine-tuning technology; vector database