摘" 要:文章采用简单随机抽样(旁置法)的方式,按7:3的比例划分训练集与测试集。基于该训练集建立支持向量机、BP神经网络、决策树、随机森林、Adaboost算法、加权K-近邻等分类模型,利用测试集对心力衰竭死亡风险预测模型的效果进行测试。使用精度、查全率、查准率、卡帕系数(Kappa)、F1分数等评价指标评判各种模型调优后的预测效果,最后选出BP神经网络为最佳的疾病风险预测模型,为临床医学研究诊断心力衰竭提供一些参考性意见。
关键词:心力衰竭;随机搜索;预测模型;最优模型
中图分类号:TP18" " 文献标识码:A" 文章编号:2096-4706(2024)18-0091-04
Research on Prediction Model Based on R Language Algorithm and Random Search
—Taking the Death Risk Prediction of Heart Failure as an Example
LONG Qianqian, TANG Xingyun
(School of Mathematics and Statistics, Qiannan Normal University for Nationalities, Duyun" 558000, China)
Abstract: This paper uses Simple Random Sampling method, and divides the training set and the test set in a 7:3 ratio. Based on this training set, SVM, BP Neural Network, Decision Tree, Random Forest, Adaboost Algorithm, and Weighted K-nearest Neighbors classification models are established, and the test set is used to test the effect of the Heart Failure death risk prediction model. Accuracy, Recall Ratio, Precision Rate, Kappa coefficient, F1 score and other evaluation indexes are used to evaluate the prediction effect of various models after optimization. Finally, the BP Neural Network is selected as the best disease risk prediction model, which provides some reference opinions for clinical diagnosis of Heart Failure medical research.
Keywords: Heart Failure; Random Search; prediction model; optimum model
0" 引" 言
随着人工智能技术的不断发展,人工智能在医疗健康领域中的应用已非常广泛,而人工智能与医疗健康的深度融合有助于进行更好的医学诊断。
本文以费萨拉巴德心脏病学研究所和费萨拉巴德的联合医院(巴基斯坦旁遮普省)收集的299名心力衰竭患者的医疗记录为例,通过下当流行的一些机器学习算法对数据进行训练,以预测结果为基础,结合随机搜索的方法,综合选出最佳疾病风险预测模型。
1" 数据介绍
本文使用数据来自UCI数据库,该数据库是2015年4月至12月期间在费萨拉巴德心脏病学研究所和费萨拉巴德的联合医院(巴基斯坦旁遮普省)收集的299名心力衰竭患者的医疗记录[1]。
该数据集是一个二分类数据集,共有299个观测值,患者年龄在40至95岁之间,包括105名女性和194名男性。13个临床指标(变量):年龄、贫血、高血压、肌酐磷酸激酶(CPK)、糖尿病、射血分数(EF)、性别、血小板、血清肌酐、血清钠、抽烟、时间。
通过利用RStudio 4.1.2对本数据进行清洗,结果表明该数据集并无缺失值。
采用旁置法将数据集划分为训练集与测试集,其中训练集按70%的比率抽取,用来训练预测模型;测试集按30%的比率抽取,用于估计预测误差;采取的是重复(有放回)随机抽样方式。
2" 模型构建
2.1" 支持向量机
支持向量分类建模的目的是基于训练集在p维空间中,找到能将两类样本有效分开的分类超平面。通过分析输入变量和二分类输出变量之间的数量关系,对新样本的输出类别值进行预测[2]。
在模型中,影响模型正确率的三个参数分别是C、核函数、sigma。参数C是一种损失惩罚参数,代表犯错的成本,用于平衡模型复杂度和预测误差。C较大时,意味着对错判给予较高的惩罚;C较小时,意味着对错判给的惩罚较低[3]。参数sigma影响核函数的分布,sigma值越小,高斯分布会呈现出又高又瘦状态,存在训练准确率可以很高,但只作用于支持向量样本附近区域,对于未知样本分类效果很差。
在R中支持向量机(Support Vector Machine, SVM)的核函数有:Linear线性核函数、Radial高斯核函数、Polynomial多项式核函数以及Sigmoid反曲核函数。
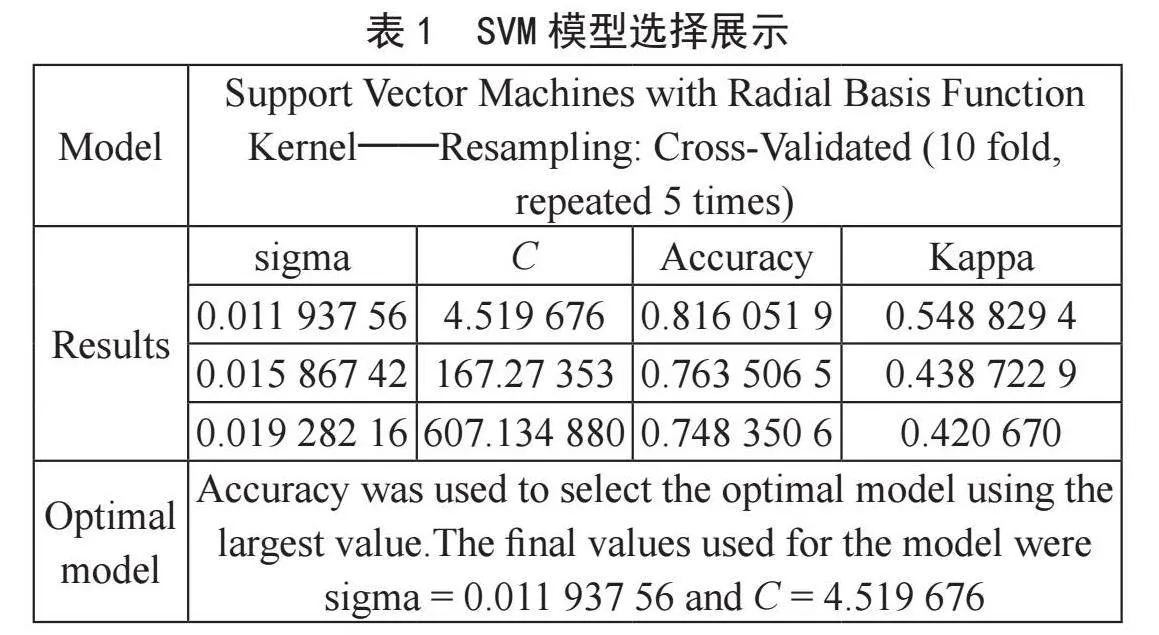
利用随机搜索寻找最优超参数,输出类别值进行预测模型构建如表1所示。
选取精度(Accuracy)最大值对应的为最优模型,从表中可得最优的C值为4.519 676,sigma值为0.011 937 56,在该模型中选用Radial核函数。
2.2" BP神经网络
BP神经网络可实现分类与回归预测。网络的拓扑结构为二层或三层网络结构,输入节点个数等于输入变量个数,由节点来建立分割两个类别的超平面,其最终目标是正确预测观测点的所属类别。BP神经网络的主要特点是:第一,包含隐层,主要负责实现非线性样本的线性变换。第二,反向传播,这是实现权重调整的重要机制。第三,激活函数采用Sigmoid函数,它可以较好地体现连接权重修正过程中,模型从近似线性到非线性的渐进转变过程[4]。
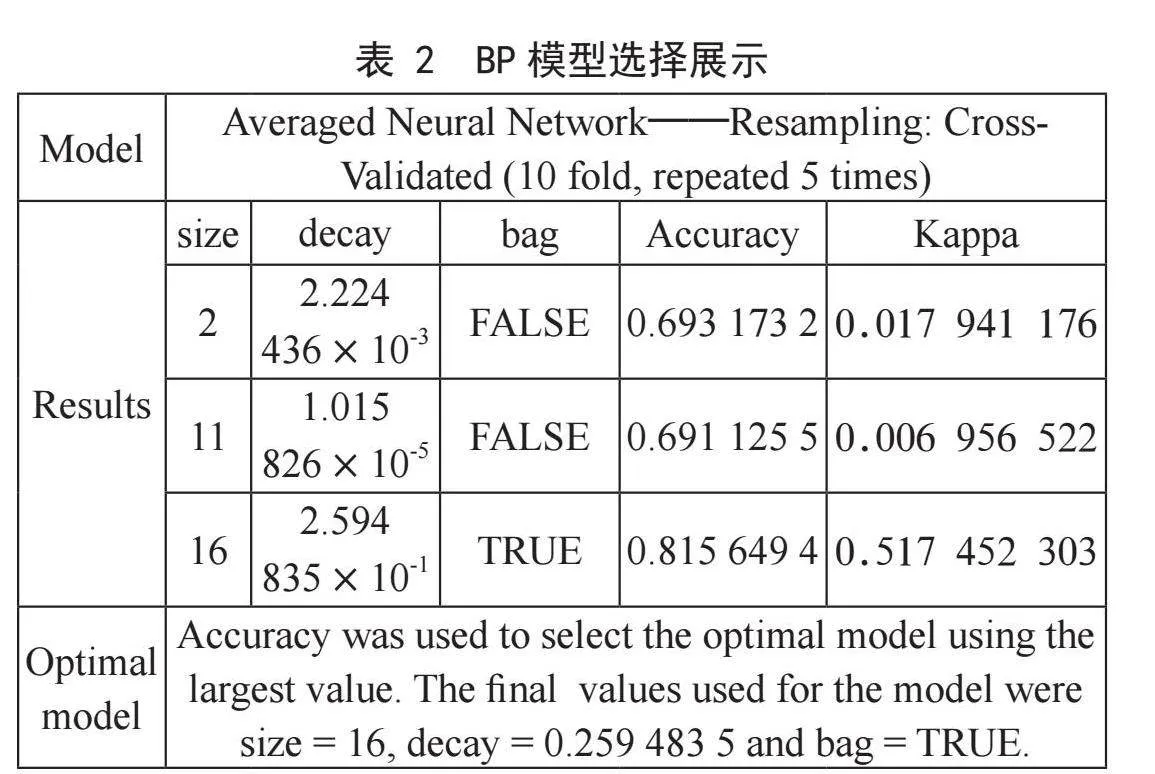
在多分类问题中,输出节点个数等于输出变量的类别数,隐层只有一层,隐节点的个数由用户指定。模型中的参数size用于指定隐层的节点数,decay是放在正则项前面的一个系数。正则项一般用来指示模型的复杂度,decay的作用是调节模型复杂度对损失函数的影响,若decay很大,则复杂的模型损失函数的值也就越大。输出类别值进行预测模型构建如表2所示。
选取精度最大值对应的为最优模型,在size=16时得到最佳模型。
2.3" 决策树
决策树学习算法包含了特征选择、决策树的生成与决策树的剪枝过程。决策树有两大核心问题:
一是决策树的生长,即利用训练样本集完成决策树的建立过程。决策树的生长过程是对训练样本集不断分组的过程。
二是决策树的剪枝,即利用测试样本集对所形成的决策树进行精简[5]。
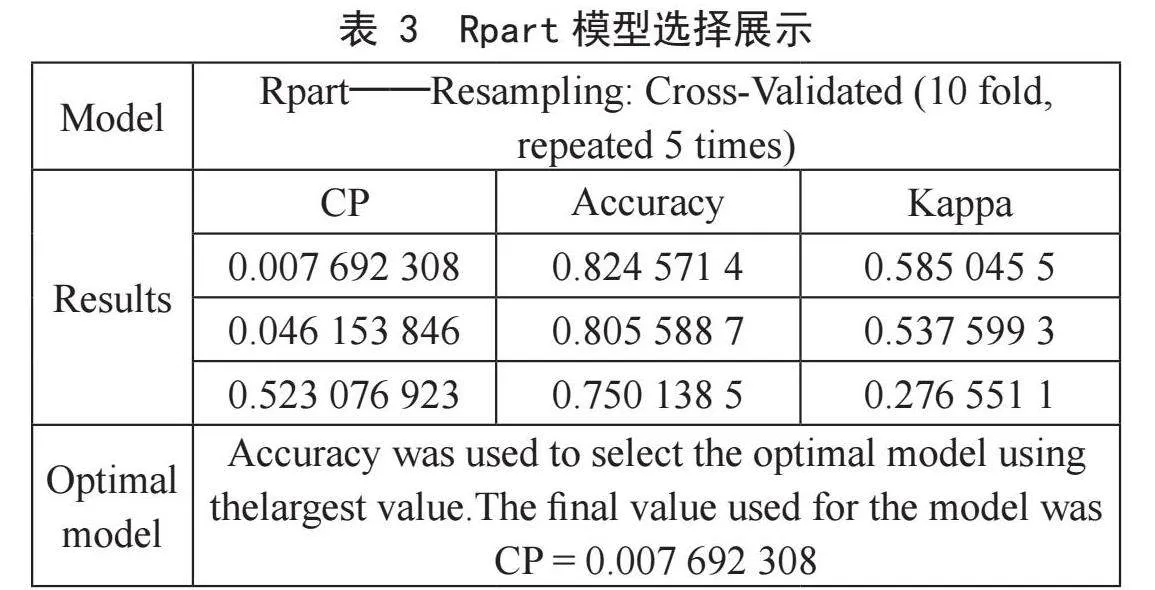
建模中使用train()函数选取最优参数,在分类回归树中时输出变量应为因子;参数control用于设定预修剪参数和后修剪中的复杂度参数CP值[6]。构建模型如表3所示。
选取精度最大值对应的为最优模型,模型的参数最优值为CP=0.00 7692 308。
2.4" 随机森林
随机森林(Randomforest)是建立在决策树基础上的模型,它是以随机的方式建立一片森林,森林中包含众多有较高预测精度且弱相关甚至不相关的决策树,并形成组合预测模型,由多个决策树进行集成得到更加精确和稳定的模型。在每棵决策树建立的过程中,当前最佳分组变量,是从输出变量中随机选取的变量子集中的竞争获胜者,分组变量具有随机性。
模型参数mtry用于指定变量子集包含的输入变量个数k;在建模过程中参数ntree用于指定随机森林中包含的决策树棵树,设置取值范围从1到500。
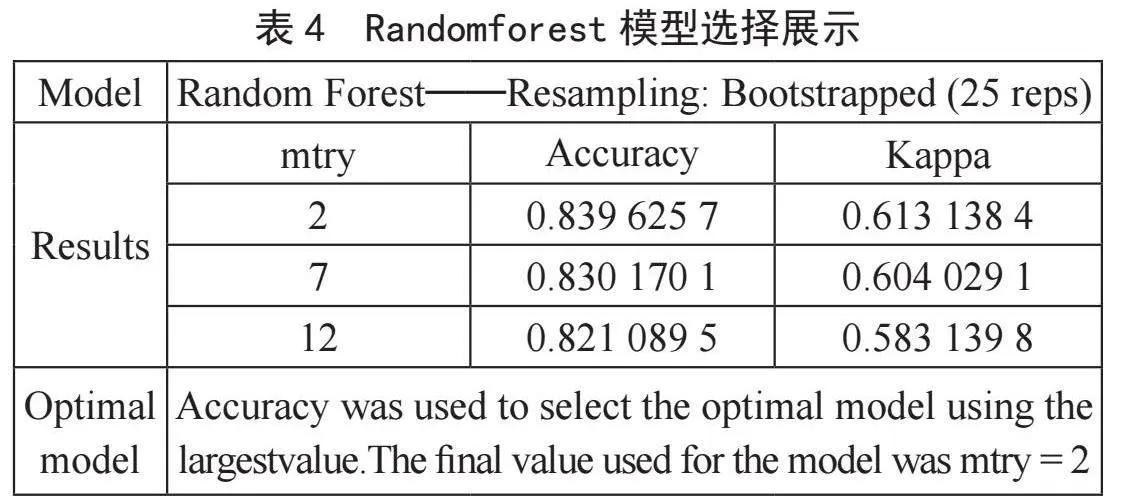
输出类别值进行预测模型构建如表4所示[7]。
选取精度最大值对应的为最优模型,模型的最终值mtry=2。
2.5" Adaboost算法
Adaboost技术包括两个阶段:建模阶段与预测阶段。建立预测模型的目的是找到区分两类样本的边界。在建模过程中,Adaboost技术是通过对加权样本的有放回抽样,获得训练样本集,第一次建模时,对样本量为n的原始样本集S,进行有放回的随机抽样,得到一个容量为n的自举样本S1,在S1的基础上建立模型T1;重复k次,将得到k个自举样本与k个预测模型[8]。
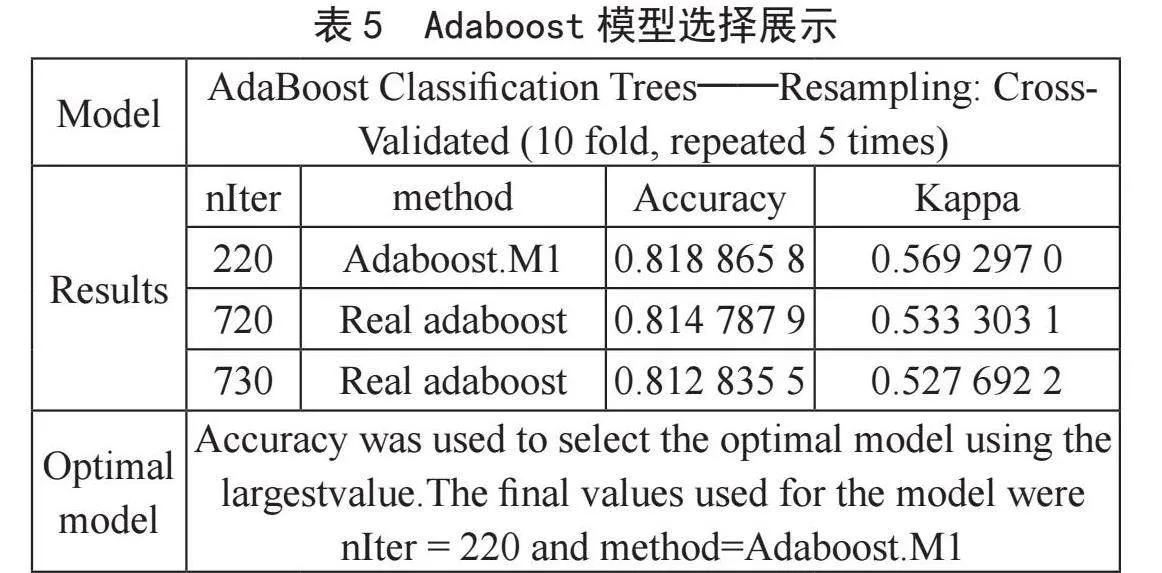
建模中运用R语言Adaboost函数进行模型的建立。其中参数method值代表训练模型过程中所使用的算法,如表5所示。
训练最优模型所使用的算法为Adaboost.M1算法,模型最终使用的nIter值为220。
2.6" 加权k近邻
加权的k近邻模型不需要任何训练过程,仅需要选择一个最优的k值并计算与测试样本最近的k个训练样本的欧式距离;为了减少选择k值带来的影响,即给重要的变量赋予较高的权重,给不重要的变量赋予较低的权重,从而减小不重要变量对预测结果产生的影响,增大重要变量对预测结果产生的影响,使得预测更加准确[9]。
在构建的模型当中,参数kmax用于指定近邻个数k的最大可能取值,distance用于指定闵可夫斯基距离中的参数k,参数kernel用于指定核函数。
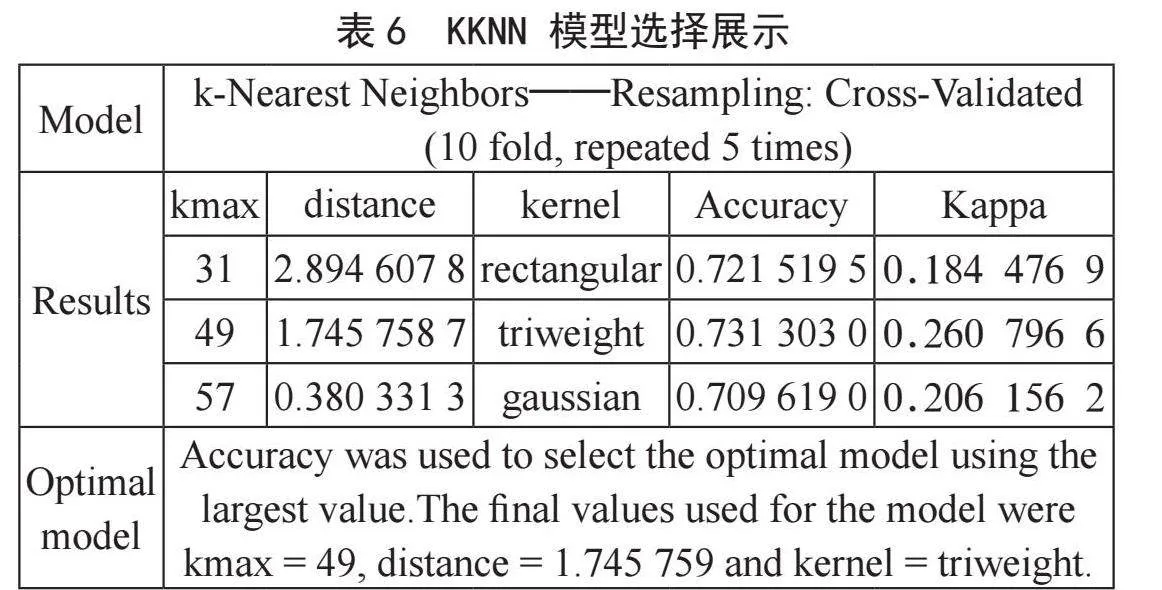
输出类别值进行预测模型构建如表6所示。
选取精度最大值对应的为最优模型,模型的最终值为kmax=49。
3" 预测结果综合评价
利用R4.1.2软件建立模型后,将划分出的训练集输入我们构建的各种预测模型中,使模型对其进行学习,在模型训练完成后,利用划分出来的测试集对模型训练结果进行对比预测。为确定模型性能好坏,引入精度、宏查全率(Recall)、宏查准率(Precision)、Kappa系数、F1分数(F1-Score)个评价指标对模型性能进行评估。
精度:反映测量结果与真实值接近程度的量,是分类模型总体判断的准确率。宏查准率:在预测值为Positive的所有结果中,预测正确的比重。宏查全率:在真实值为Positive的所有结果中,预测正确的比重。F1-Score:对于某个分类,F1是综合了Precision和Recall的一个判断指标,Score的取值范围从0到1,其中1是最好,0是最差。Kappa系数:反映了真实类与预测类的分布一致程度,0.41~0.6为中等一致,0.61~0.8为高度一致,0.81~1为几乎完全一致[10]。
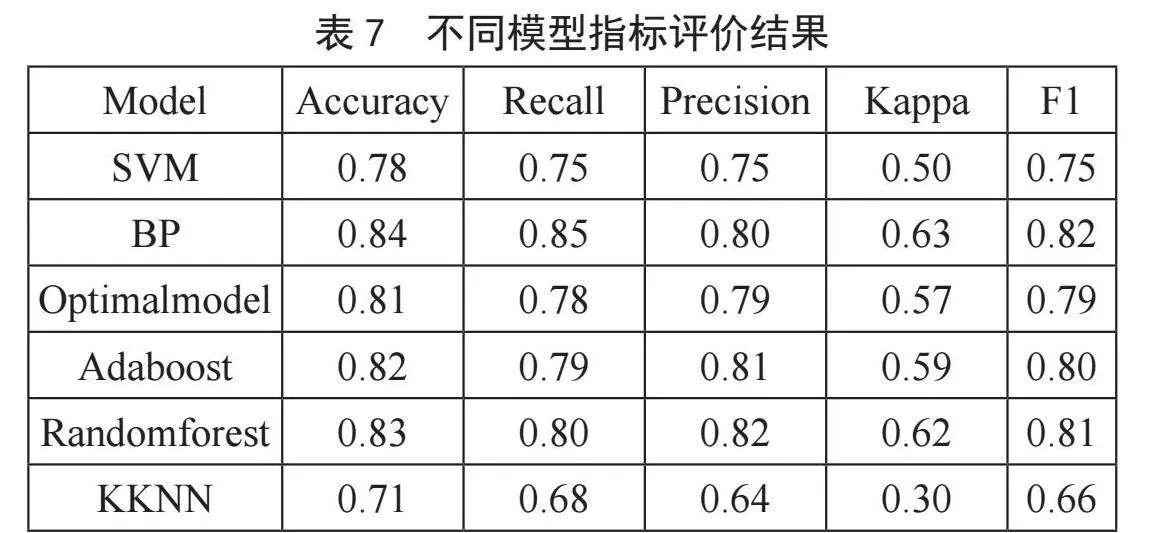
基于上述理论,使用测试样本集对构建的预测模型进行测试。在确定最优模型之后,基于最优模型对数据集进行训练学习并预测,得出的各评价指标输出值如表7所示。
根据模型指标评价结果得出结论:对于同一预测问题,不同算法的预测效果存在差异。模型性能好坏程度依次是BP神经网络、随机森林、Adaboost算法、决策树、支持向量机以及加权K-近邻。
4" 结" 论
本文利用299名心力衰竭患者的医疗记录数据,使用随机搜索的方法搜索参数组合,选取最优的参数建立了心力衰竭患者死亡风险的预测模型,并使用各种性能度量指标对模型预测性能进行比较。
通过对比发现,在本文建立的预测模型中,BP神经网络精度为0.84,即总体判断的准确率达到84%。在预测值与真实值的所有结果中,预测正确的比重均达到了80%,Kappa为0.63,同时模型F1分数达到了0.82,说明真实类与预测类分布高度一致。综上,BP神经网络模型对于心力衰竭死亡风险预测有更好的预测能力,有一定合理性可认为该模型能作为医学预测心力衰竭死亡风险的参考模型。
参考文献:
[1] UC Irvine Machine Learning Repository.Heart Failure Clinical Records Donated on 2/4/2020 [EB/OL].[2024-02-11].http://archive.ics.uci.edu/ml/datasets/Heart+failure+clinical+records.
[2] 李航.统计学习方法:第2版 [M].北京:清华大学出版社,2019.
[3] 孙玉婷.弱监督场景下的支持向量机算法研究 [D].北京:中国矿业大学,2023.
[4] 薛薇.R语言数据挖掘:第2版 [M].北京:中国人民大学出版社,2018.
[5] 吕晓玲,宋捷.大数据挖掘与统计机器学习:第2版 [M].北京:中国人民大学出版社,2019.
[6] 吴喜之,张敏.应用回归及分类:基于R与Python的实现:第2版 [M].北京:中国人民大学出版社,2020.
[7] 易华玲.基于改进随机森林的空气质量分类预测研究 [D].重庆:重庆大学,2020.
[8] 薛薇.Python机器学习:数据建模与分析:第2版 [M].北京:机械工业出版社,2021.
[9] 张莎莎.基于机器学习的心血管疾病诊断模型关键技术研究 [D].北京:北京邮电大学,2023.
[10] 沈祥壮.Python数据分析入门 从数据获取到可视化 [M].北京:电子工业出版社,2018.
作者简介:龙倩倩(2001.02—),女,布依族,贵州安顺人,本科,研究方向:应用统计;通信作者:唐兴芸(1979.11—),女,硕士,布依族,贵州都匀人,副教授,硕士研究生,研究方向:概率论与数理统计。