

摘" 要:随着城市化进程的加快,垃圾分类问题日益突出。文章设计并实现了一个基于深度学习的垃圾分类识别小程序,以提高垃圾分类的效率和准确性。该程序可以通过文字搜索、语音搜索和拍照识别三种方式来进行垃圾分类查询,通过个人发表分享和在线问答的方式来提高居民垃圾分类的知识。实验结果表明,该程序具有较高的识别准确率和实时性,可为城市垃圾分类提供有效的技术支持。
关键词:深度学习;垃圾分类;搜索;识别
中图分类号:TP311;G710" " " 文献标识码:A" 文章编号:2096-4706(2024)18-0075-08
Design and Implementation of a Garbage Classification Recognition Mini Program Based on Deep Learning
WU Mingzhu
(Department of Information Engineering, Guangzhou Institute of Technology, Guangzhou" 510075, China)
Abstract: With the acceleration of urbanization process, the problem of garbage classification is becoming increasingly prominent. The paper designs and implements a garbage classification recognition Mini Program based on Deep Learning to improve the efficiency and accuracy of garbage classification. This program can perform garbage classification queries through three methods of text search, voice search, and photo recognition. It can improve residents knowledge of garbage classification through personal sharing and online Qamp;A. The experimental results show that the program has high recognition accuracy and real-time performance, and can provide effective technical support for urban garbage classification.
Keywords: Deep Learning; garbage classification; search; identification
0" 引" 言
随着城市化的快速发展,垃圾产生量逐年增长,给城市环境治理带来了巨大挑战[1]。垃圾分类是减少垃圾处理压力、提高资源利用率的有效途径。垃圾分类是科学合理保护生态环境、推进生态文明建设的重要一环[2]。传统的垃圾分类方法主要依赖人工分类,效率低下且容易出错。近年来,深度学习技术在图像识别领域取得了显著进展,为垃圾分类提供了新的解决方案[3]。阿里云视觉平台中的垃圾分类识别是一项基于深度学习技术的图像识别服务,它可以对输入的图片进行分析和识别,快速判断出图片中的垃圾种类,并给出相应的分类结果。百度智能云平台也提供了类似阿里云视觉平台中的垃圾分类识别API。它同样基于深度学习技术,可以对用户上传的图片进行分析和识别,判断出图片中的垃圾种类,并给出相应的分类结果。芬兰Zen Robotics公司研发了一款基于机器视觉的垃圾分类识别机器人,这个机器人使用激光扫描技术来对位于传送带上的垃圾进行识别。此外,它还配备了其他多种传感器来收集数据,进一步提高了分类和识别的准确性,将这些数据输入到该公司的AI系统中进行分类和识别。
此外,微信在12年的时间里拥有了庞大的流量资源[4],同时微信小程序是一种在微信内运行的轻量级应用[5],可以实现各种功能,如电商、社交、娱乐等。因此本设计通过深度学习进行图像分类与微信小程序相结合,设计并实现垃圾分类识别小程序,用户通过拍照或选择相册图片将难以辨认所属类别的垃圾图片进行上传,后端对图片进行识别,也能通过录入语音或输入文字进行查询,从而避免了分类难的问题。通过垃圾类别图鉴、个人分享和分类问答的功能,用户可以学习到相关的分类常识,这对居民日常生活垃圾的分类处理具有一定的积极意义。用户可以通过便捷的操作,就能得出分类结果。
1" 系统设计
本文设计的是一款基于微信小程序平台的垃圾分类查询小程序。包括垃圾分类查询、垃圾分类知识分享、垃圾分类在线问答和用户个人信息管理4个主要功能。系统采用了前后端分离的架构,前端开发使用微信小程序框架和Vant-ui组件库,后端功能接口开发使用Django和Django Rest Framework[6],使用Redis进行缓存和限流、OSS进行媒体文件存储、MySQL进行存储数据。垃圾分类查询使用PyTorch实现图像识别模型[7-8]、Vosk进行语音识别、Django Rest Framework的搜索功能实现文字搜索。用户操作记录等数据通过Redis进行缓存并搭配Django Rest Framework的限流机制实现用户频繁操作限制。系统采用Nginx作为反向代理服务器,采用微信小程序云部署、云服务器、云数据库和OSS进行部署与存储,保证了用户访问速度和安全性。
1.1" 前端视图层设计
该垃圾分类微信小程序的前端视图层设计概述包括了5类页面:首页、分类知识学习页面、发表分享页面、在线问答页面和个人中心页面。采用微信小程序提供的API实现页面跳转、布局和组件渲染等功能,引入Vant-ui组件库提供的按钮、搜索框等组件来加快开发效率。通过自定义组件和功能,增强页面的可读性和稳定性。下面将针对每类页面进行详细设计与实现说明。引入的相关组件实现代码如下:
\"usingComponents\":{
\"van-search\": \"@vant/weapp/search/index\",
\"van-image\": \"@vant/weapp/image/index\",
\"van-button\": \"@vant/weapp/button/index\",
\"van-card\": \"@vant/weapp/card/index\",
\"van-dialog\": \"@vant/weapp/dialog/index\",
\"van-toast\": \"@vant/weapp/toast/index\",
\"van-divider\": \"@vant/weapp/divider/index\",
\"van-row\": \"@vant/weapp/row/index\",
\"van-col\": \"@vant/weapp/col/index\",
\"van-loading\": \"@vant/weapp/loading/index\",
\"van-overlay\": \"@vant/weapp/overlay/index\",
\"van-uploader\": \"@vant/weapp/uploader/index\",
\"van-sticky\": \"@vant/weapp/sticky/index\",
\"van-notify\": \"@vant/weapp/notify/index\"
},
1.1.1" 首页
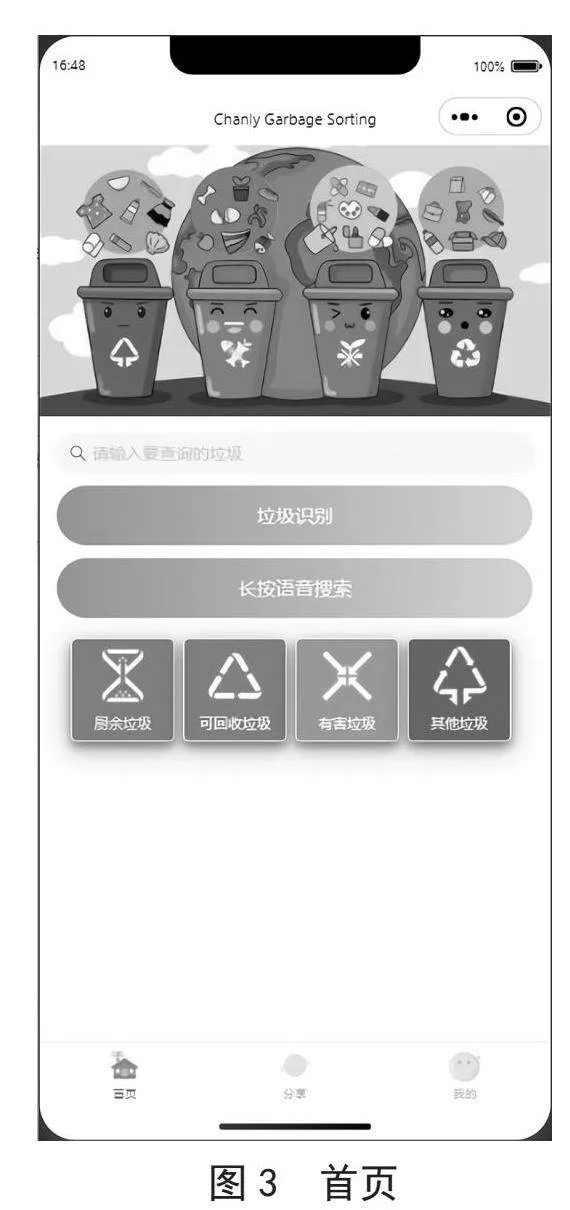
首页是用户进入小程序后的默认页面,要展示小程序的基本信息和操作入口,包括小程序的基本信息和操作入口,包含基础图片、搜索框、垃圾识别按钮、语音搜索按钮和4个垃圾类型图标这5个部分组成。用户点击搜索框进入搜索页,输入垃圾名称或点击历史记录即可进行查询;用户点击垃圾识别按钮可以选择拍照或从相册中上传图片进行识别,还提供了历史识别记录功能;用户长按语音搜索按钮可以录入语音,通过语音内容进行查询;在界面中有四个垃圾类别,用户点击任意一种垃圾类型图标即可进入相关类型的知识学习页面。
1.1.2" 发表分享页面
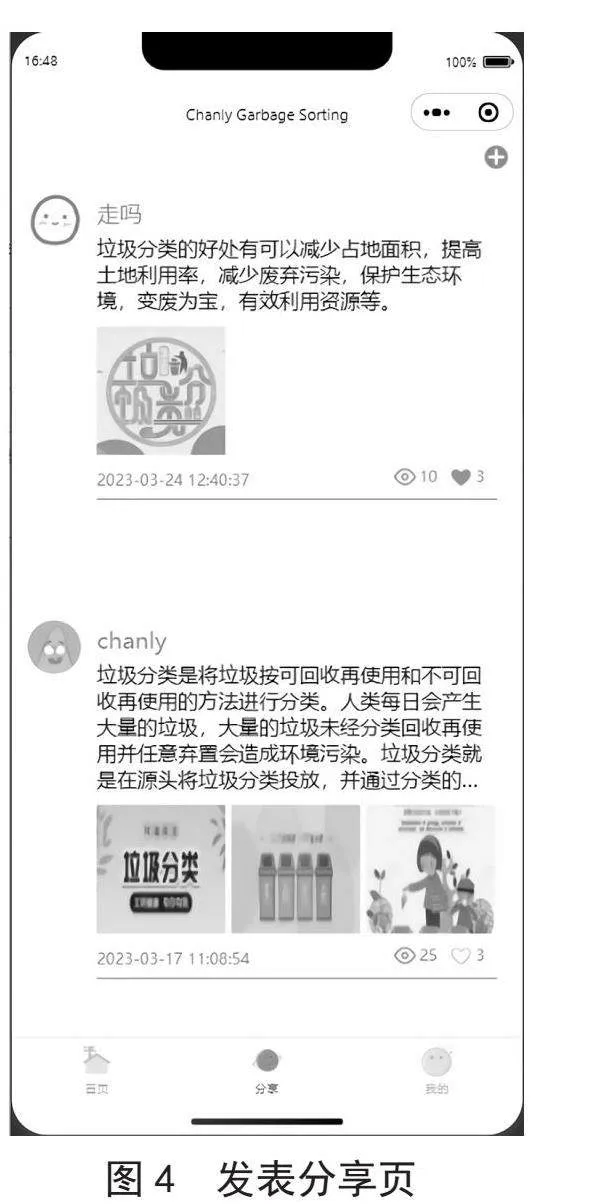
用户可以通过点击页面右上角的追加按钮,进入图片上传和文本编辑界面,方便地编辑和发布分享内容。图片上传功能通过云函数实现,确保了上传的图片能够快速地保存到云端,并且不会占用用户手机的存储空间。分享页的内容布局采用了卡片式布局,带有图片和文字说明,使得用户能够更直观地浏览和了解分享的内容。同时,用户还可以通过点击对应分享内容,进入内容数据的详细页面,浏览更多相关信息。在详细页面中,用户可以对该内容进行点赞互动操作。
1.1.3" 个人中心页面
该页面的上方展示了用户的头像和昵称,并提供了修改昵称的功能。用户也可以通过右侧的注销按钮退出登录。页面下方提供了多个操作入口,包括答题、答题记录、我的发现、识别记录和关于等。其中,答题功能允许用户进行垃圾分类的知识测试;答题记录允许用户查看自己的测试历史;我的分享允许用户发布和查看其他用户的分享内容;识别记录允许用户查看自己的垃圾识别历史;关于页面提供了小程序的相关信息等。通过个人中心页面,用户可以方便地管理自己的个人信息和操作记录,并进行相应的操作。
1.1.4" 图片识别结果页面
用户上传图片后,系统将会给出5个可能的识别结果,每个结果由物品名称、所属类型、识别相似度、解释说明和生活提示5个部分组成。通过对这些信息的展示,用户可以了解所上传图片对应的垃圾类型、分类方法以及相关的知识和使用建议。这个页面的设计旨在帮助用户更好地了解垃圾分类的知识和方法,从而更加方便地参与垃圾分类活动。
1.1.5" 搜索识别结果页面
该页面将所有得到的结果展示,每个结果包含了物品名称、类型解析、相关物品、所属类型和生活提示5个部分。在该页面上,用户可以根据搜索结果的类型和生活提示来进行垃圾分类处理。同时,该页面也提供了相关物品信息,帮助用户更好地了解和识别与搜索关键词相关的物品。
1.1.6" 在线问答页面
用户可以在该页面中获取相关问题并通过回答来提高垃圾分类的知识水平。此外,该页面还提供了历史答题记录的查看功能,方便用户进行回顾和总结。
1.1.7" 分类知识学习页面
该页面通过滑动方式展示垃圾分类的各个类别,每个类别都有一个对应的图标、名称、解析和小图标展示。用户可以点击对应的分类图标,进入到该分类的详细知识页面,学习相关分类知识。整个页面的布局采用滑动式布局,配合图片和文字说明,让用户更加直观地了解垃圾分类的基本知识。
1.2" 数据交互层设计
1.2.1" 前端数据请求与处理
前端通过微信小程序提供的wx.request()等请求函数向后端发送HTTP请求,请求的数据格式为JSON格式。请求包含需要发送的数据和请求的API地址。前端通过请求函数的回调函数来处理后端返回的数据,并进行相应的界面更新。相关例子如下:
wx.request({
url: baseUrl +/user/user,
method: POST,
data:{
code: res.code,
nickName: re.userInfo.nickName,
avatarUrl: re.userInfo.avatarUrl,
gender: re.userInfo.gender
},
header: {
\"Content-Type\": \"application/x-www-form-urlencoded\"
},
success(resp) {
wx.setstorageSync(openid, resp.data.token)//请求成功后,后端返回的唯一标识符(用户态),存储到Storage缓存中
wx.setStorageSync(pk, resp.data.pk)//用户的主键
wx.setStorageSync(nickName, resp.data.username)
wx.setStorageSync(avatarurl, re.userInfo.avatarUrl)
wx.setStorageSync(gender, re.userInfo.gender)
Toast.success(登录成功!);
that.setData ({
whether_login: 1,
nickName: wx.getstorageSync(nickName),
avatarUrl: wx.getStorageSync(avatarUrl),
gender: wx.getStorageSync(gender),
})
}
})
1.2.2" "后端数据处理与响应
后端采用Django和Django Rest Framework开发,提供RESTful API接口来实现前端和后端之间的数据传输和交互。后端接收前端发送的请求,并通过Django Rest Framework进行处理,将需要的数据通过JSON格式返回给前端,相关例子如下:
def post(self, request, *args, *kwargs):
user=request.user#用户
content = html.escape(request.data.get(content, None) #获文字内容
if content:
#匹配正则
text_re = re. fullmatch(re_str, content)
if text_re:
img_list = eval(request.data.get(img_list, None))#获图片数据
if img_list:#图片数据不为空且不为图片格式数据
discover= DiscoverModel.objects.create(user=user, content=content)
for item in img_list:
discover.discover_image.create(discover=discover, iamge=item[urt])
else:
user.discover. create(user=user, content=content)
return Response(data={ok: ok!}, status=208)
else:
return Response(data={error:数据格式错误!}, status=420)
else:
return Response(data={error: 请输入文字内容!}, status=420)
1.2.3" 垃圾分类查询功能
用户通过文字搜索、语音搜索和图片识别进行垃圾分类查询。前端通过调用微信小程序提供的API来实现语音输入和拍照上传功能,将语音或图片数据发送到后端进行处理和识别。后端根据不同请求处理不同内容,返回垃圾分类的类别和处理方式等相关信息来实现垃圾分类查询功能。
1.2.4" "发表分享功能
用户可以通过前端界面上传文字和图片来发布与垃圾分类相关的知识、经验和技巧等信息。前端通过请求函数将这些数据发送到后端进行保存和存储。后端将这些数据保存在MySQL数据库中,并通过Django Rest Framework提供后端接口进行数据返回,使前端可以获取已发布的分享内容和相关信息。
1.2.5" 垃圾分类知识学习和在线问答功能
用户可以通过前端界面获取垃圾分类相关的知识和问题,并进行学习和回答。后端通过Django Rest Framework提供RESTful API接口来获取相关的知识和问题,使前端可以实现对这些内容的展示和交互。
在实现数据交互层时,需要考虑数据传输的安全性和可靠性。通过使用HTTPS协议来加密传输数据,可以避免数据被窃听和篡改,同时采用数据加密和数字签名等技术来保证数据的可靠性和完整性。
1.3" 服务器层设计
1.3.1" 垃圾分类查询和问答模块
实现通过文字搜索、图片识别和语音搜索的方式来进行分类查询以及问题获取。文字搜索通过用户输入垃圾名称来查询垃圾分类信息。通过Django Rest Framework提供的搜索功能进行模糊查询。图片识别通过拍照上传图片来进行垃圾分类查询。使用PyTorch实现图像识别模型来对上传的图片进行分类。语音搜索通过语音输入垃圾名称来查询垃圾分类信息。使用Vosk等开源工具进行语音识别,并将识别结果传递给后端进行处理。问题获取通过后端随机获取数据库10条物品数据并构造成题目。
垃圾分类识别实现代码如下:
def recognition(img):
垃圾识别
:param img: 图片数据
:return:图片标签,如:有害垃圾_电池
img_pretreatment = Pretreatment(img)
img_pretreatment = img_pretreatment.get_image().unsqueeze(8) #.cuda()
# img_pretreatment = img_pretreatment#. cuda()
pred = model(img_pretreatment) #识别
pred = pred.data.cpu().numpy()[0]
score = softmax(pred)
pred_id_list= np.argsort(score)[: :-1][:5]#获取精确率前五
label_list =[ ]
for pred_id in pred_id_list:#精确率前五进行个获取标签
label_list.append({label:labels[pred_id][0], accuracy: score[pred_id]})
return label_list
1.3.2" 用户管理模块
实现用户的登录、昵称修改功能。后端接收前端传输的一次性验证码,向微信服务器发送请求,微信服务器返回用户的openid,后端根据数据库中用户表数据进行校验,构造json web token并返回给前端。微信用户登录需向微信服务器获取用户的openid,视图类需继承ObtainJSONWebToken类并重写post方法实现登录功能。后端接收前端传输的修改数据,对数据库的用户表数据进行修改。登录功能实现代码如下:
class LoginView(ObtainJSONWebToken):
def post(self, request, *args, *kwargs):
code = html.escape(request.POST.get(code,None) #/获取用户一次性验证码
resp_result= get_openid(code=code) #向微信服务器获取用户的openid
try:
user = User.objects.get(username=resp_result[openid])#获取用户数据行
except Exception ase:#数据库没有找到数据,为第一次登录,保存用户的登录信息
#获取用户信息
nickname = html.escape(request.POST.get(nickName, None))
image_url = html.escape(request.POST.get(avatarUrl, None))
gender = html.escape(request.POST.get(gender, None))
if nickname is None: #没有获取到用户名
nickname =用户+ str(random.randint(100000, 999999))
#保存用户信息
#使用django的加密方式进行加密
#此处密码设置为用户的openid
user = User(username=resp_result[openid],
password=make_password(resp_result[openid]),
uvid=test,
nikename=nickname,
image_url=image_url,
gender=gender)
user.save()
#修改request,追加username和password到request中
request.POST._mutable = True #允许其属性进行修改
request.POST[username] = user.username" #追加username
request.POST[password] = user.username" #追加password
request.POST._mutable = False
#重构request,使其request.data变为当前最新值
request = self.initialize_request(request._request, *args, *kwargs)
#request.data有username和password后,调用父类方法生成token
response = super(LoginView, self).post(request, *args, *kwargs)
return response
1.3.3" 垃圾分类知识模块
实现相关的垃圾分类知识,帮助用户了解和掌握垃圾分类的基本知识。通过文字和图片等形式,列出常见的垃圾分类类别和所属物品,向用户介绍垃圾分类的相关概念。
1.3.4" 发表分享模块
实现获取所有分享数据、点赞、查看个人分享、修改或删除个人分享。对用户信息进行校验,校验通过可以进行点赞操作,若校验用户为该条分享的分享者则可以进行修改和删除操作,校验失败只运行进行查看操作
除了以上模块,还需要实现用户校验、缓存、限流、防止SQL注入和防止跨站脚本攻击来保证系统的安全性和稳定性。使用Redis进行缓存,使用Django Rest Framework的用户校验、限流机制来限制用户频繁操作;使用ORM对输入的数据进行过滤和验证,避免SQL注入攻击的发生;对用户输入的数据进行过滤和验证,避免跨站脚本攻击的发生;进行日志管理,对系统的日志进行收集、存储。
1.4" 数据库层设计
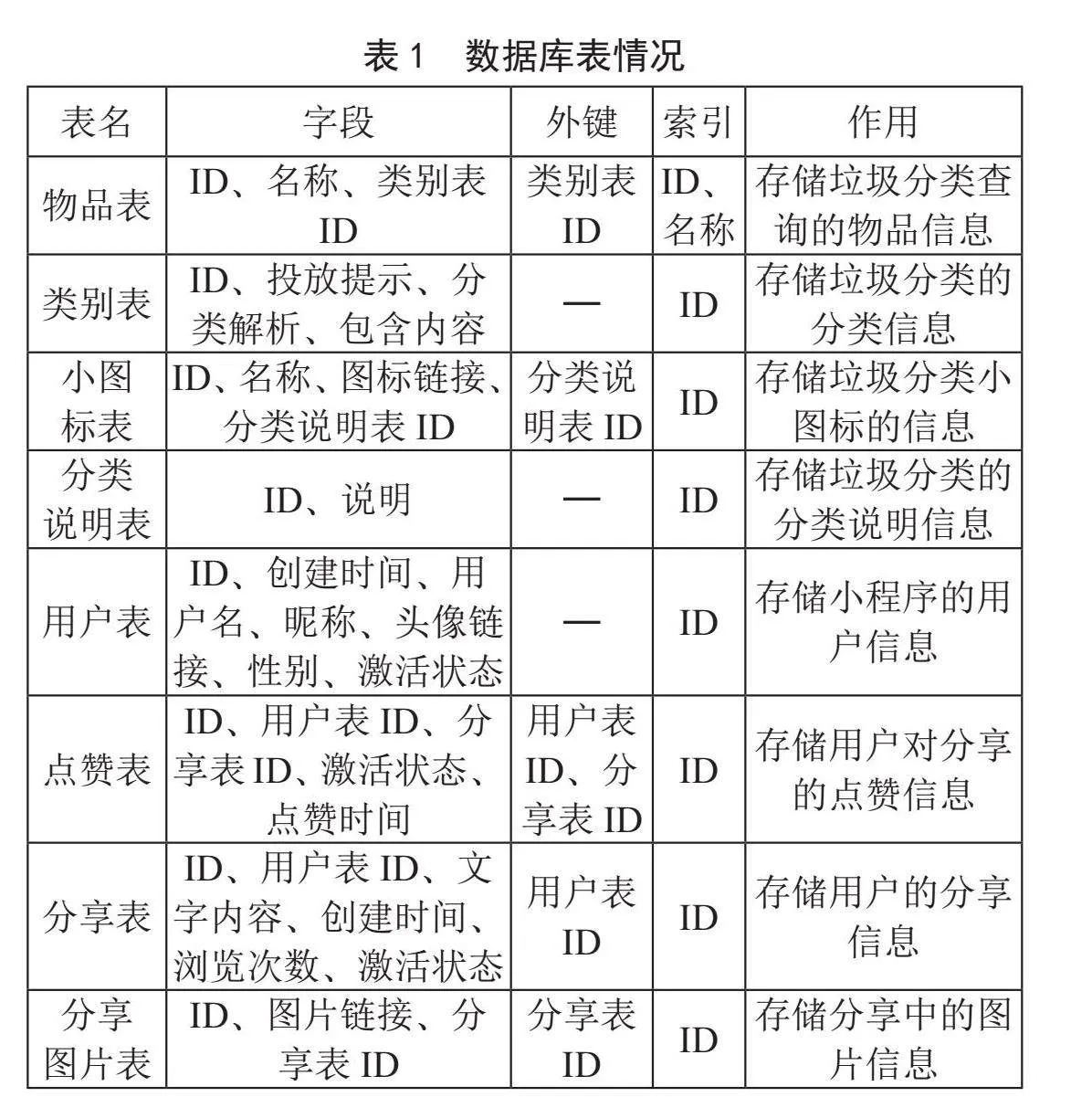
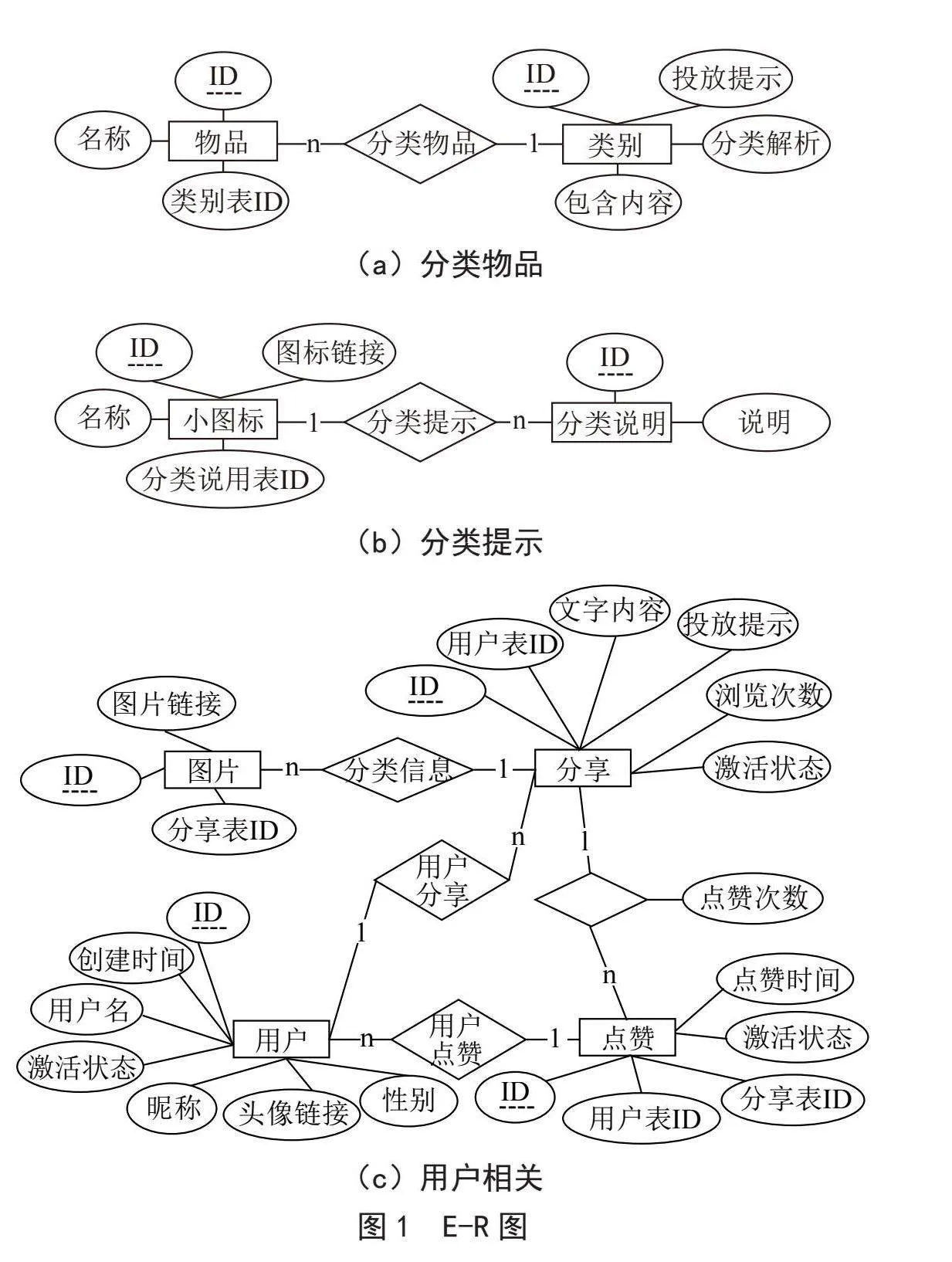
数据表设计根据实际情况分析,构建E-R图如图1所示,表1描述了数据库表情况。
数据库表关系设计根据表结构,设计以下数据库表关系:
具有一对多关系的表为:类别表和物品表、小图标表和分类说明表、用户表和点赞表、用户表和分享表、分享表和点赞表、分享表和分享图片表。
为了提高数据库的查询效率,进行了数据库表索引设计,对各个表的主键进行主键索引,对物品表的物品名称进行唯一索引,以帮助高效搜索。
1.5" 深度学习设计
在训练深度神经网络时,随着网络深度的增加,网络的训练精度会出现饱和甚至下降的现象称为退化问题,这是因为随着深度的增加,信息在网络中传递的过程中会出现严重的信息损失,导致梯度消失或梯度爆炸,从而使得网络无法收敛[9]。
本项目使用的模型为ResNet50,其核心思想是通过残差块来解决网络退化的问题。ResNet50采用的残差块结构,即每一层都有一个跨层连接,将该层的输入直接加到该层的输出中,从而保证了信息不会丢失[10]。同时,ResNet50还采用了批量归一化等技术来加速网络训练和提高模型精度。
根据8:1:1比例对数据集划分为训练集、验证集和测试集,根据目录的类别将文件复制到适当的子目录中,并将文件路径和标签写入文本文件。
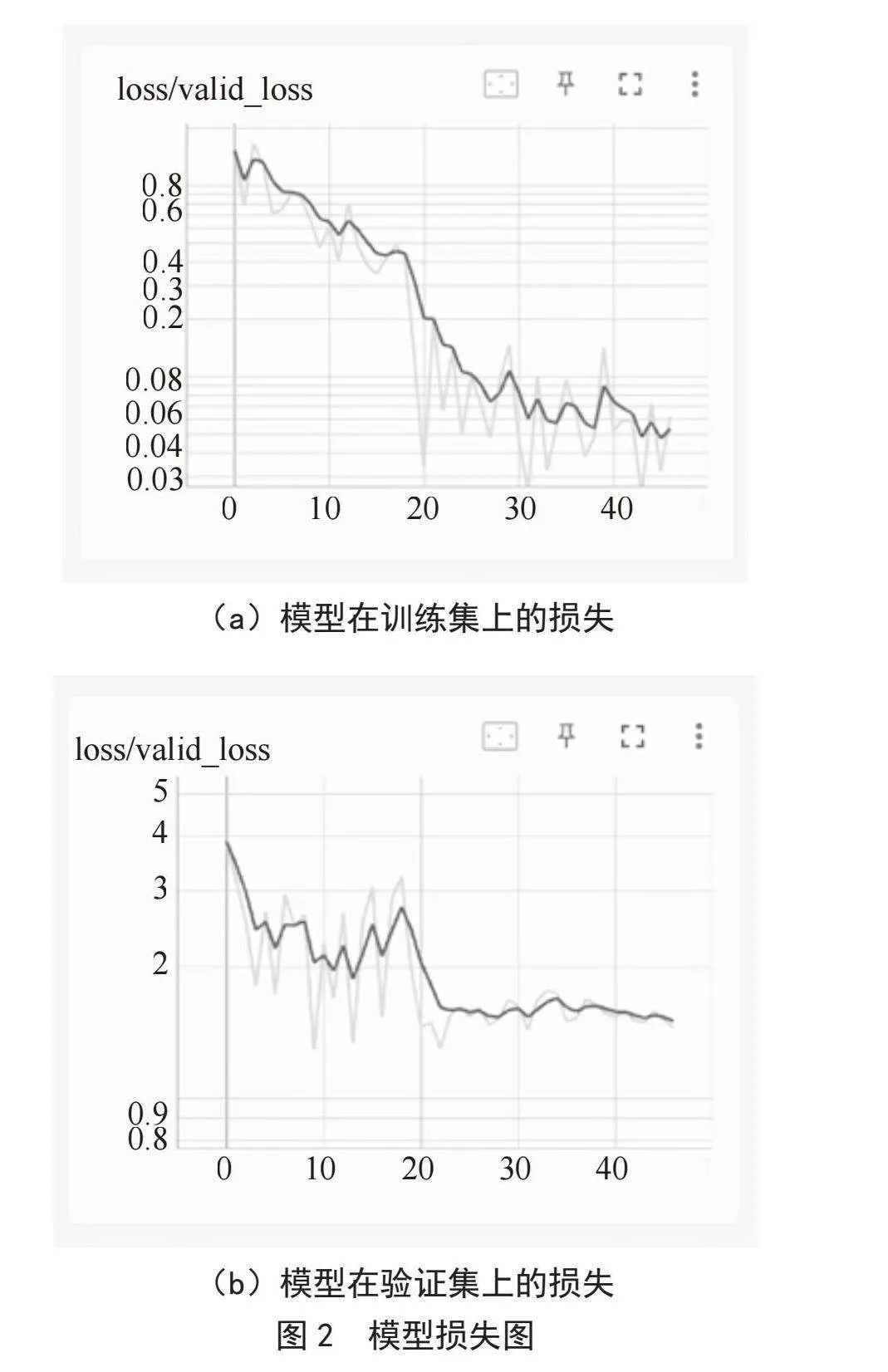
使用PyTorch训练垃圾分类识别模型,使用来自Torchvision的ResNet-50模型,并替换最后一个完全连接的层,以匹配数据集中的类数量,定义学习率为0.000 1、学习率调整策略为20、权重衰减为0.001、训练次数为80和训练批次大小为32的参数,使用的优化器是带有动量的SGD。计算前5个准确率标签,并返回正确预测的百分比和预测的标签。在每一轮训练中,如果模型性能在验证集上有所提高,则将其保持为最佳模型,模型损失如图2所示,训练入口实现代码如下:
if _ _name_ _ == _ _main_ _:
torch.cuda.empty_cache()#释放缓存分配器当前持有的且未占用的缓存显存
#数据加载
train_data = DatasetLoader(settings.TRAIN_SET, train_flag=True)
valid_data = DatasetLoader(settings.VALID_SET, train_flag=False)
#数据批次划分
train_loader = DataLoader(dataset=train_data, num_workers=0, pin_memory=True, batch_size=settings.BATCH_SIZE,shuffle=True)
valid_loader = DataLoader(dataset-valid_data, num_workers=0, pin_memory=True, batch_size=settings.BATCH_SIZE)
print(训练集个数:,str(len(train_data)))
print(验证集个数:,str(len(valid_data)))
model= models.resnet50(pretrained=True)#加载模型
#修改输出层
fc_inputs = model.fc.in_features
model.fc = nn_Linear(fc_inputs, settings.SPECIES_NUMBER)
model=model.cuda()#使用GPU加速
#网络设置
criterion = nn.CrossEntropyLoss().cuda()#交叉熵损失函数
optimizer = optim.Adam(model.parameters(), r=settings.LR, weight_decay=settings.WEIGHT_DECAY)#优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=settings.LR_STEP_SIZE, gamma=0.1)#更新策略
writer=SummaryWriter(log)#日志路径
#模型训练
best_prec=0 #记录最好
for epoch in range(settings.EPOCHS):#训练
scheduler.step()
train(train_loader, model, criterion, optimizer, epoch, writer)#训练
#验证集进行测试
valid_prec1, valid_prec5 = validate(valid_loader, model, criterion, epoch, writer, phase=VAL)
is_best = valid_prec1gt;best_prec #当前训练批次的模型是否为当前最好的模型
best_prec = max(valid_prec1, best_prec) #记录最好精度
save_checkpoint({
epoch: epoch +1,
arch: resnet50,
state_dict: model.state_dict(),
best_precl: best_prec,
optimizer: optimizer.state_dict(),
}, is_best,
filename=checkpoint_resnet50.pth.tar) #保存模型
writer.close()
在测试集上评估ResNet50模型,计算模型对每个数据的准确性和当前的平均精度。
2" 系统实现
首页包含基础图片、搜索框、垃圾识别按钮、语音搜索按钮和4个垃圾类型图标共5个部分。当用户进入小程序后可以看到如图3的界面,用户可以通过点击搜索框进入搜索页面,对物品所属类别进行搜索,还可以通过语音进行搜索;通过点击垃圾识别按钮选择拍照或从相册中上传图片进行识别。另外,该页面中还有类别的图标,用户可以通过点击对应的图标进入学习页面。这个垃圾分类小程序的首页功能丰富,操作简便,提供了多种查询和学习方式,可以帮助用户快速准确地识别垃圾种类,实现垃圾分类。
发表分享页面是一个允许用户发布和分享相关信息的界面,如图4所示。用户可以在分享页中点击右上角的追加按钮进行发布相关信息。分享页的内容布局采用带有图片和文字说明的卡片式布局。用户点击对应分享内容可以浏览对应的内容数据,同时可以进行点赞互动操作。
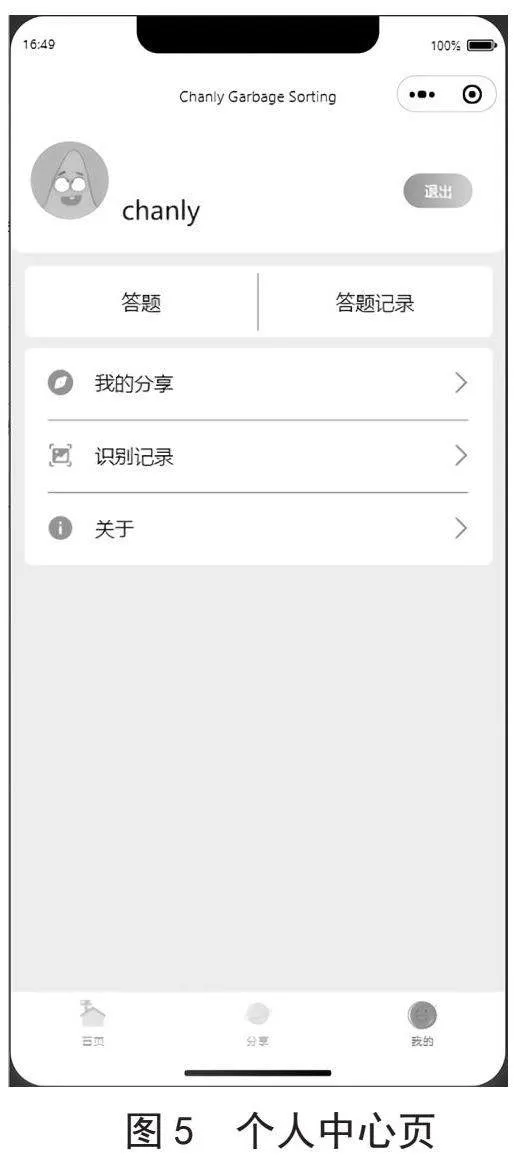
个人中心页面是用户可以查看和编辑个人信息的页面,如图5所示。展示了用户基本个人信息,包括用户头像、昵称、历史操作记录等信息。长按昵称可以进行昵称修改,用户信息右侧提供了用户注销功能。下方包含答题、答题记录、我的分享、识别记录和关于等操作。图片识别结果页面是进行图片识别后跳转的一个页面,如图6所示。该页面由用户上传的图片和5个可能的结果构成,其中每个结果包含物品名称、所属类型、识别相似度、解释说明和生活提示5个部分的组成。
搜索识别结果页面展示了用户输入或语音中的搜索关键词所对应的所有搜索结果,如图7所示。其中包含物品名称、类型解析、相关物品、所属类型和生活提示5个部分。分类知识学习页面是一个帮助用户学习垃圾分类基础知识的页面,如图8所示。采用一个带有图片和文字说明的滑动布局,包含类型图标、类型名称、类型解析和物品小图标四部分组成。用户可以根据点击的图标查看不同的分类知识,学习更多的分类知识。在线问答页面提供了垃圾分类相关的问题和回答功能,如图9所示。用户可以在该页面中获取垃圾分类相关的问题并进行回答,以帮助提高垃圾分类知识水平。
3" 结" 论
本文设计并实现了一个基于深度学习的垃圾分类识别小程序,通过大量的实验验证了其有效性和实用性。该程序为城市垃圾分类提供了有效的技术支持,有助于提高垃圾分类的效率和准确性。未来,我们将进一步注重数据共享和协作。例如,可以建立垃圾分类数据库,将不同地区、不同场景下的垃圾分类数据进行共享和整合,从而提高垃圾分类技术的普适性和适应性。同时,我们也会考虑将智能垃圾桶和垃圾分类系统进行云端连接,实现远程监控和管理,从而提高垃圾分类系统的效率和可靠性。
参考文献:
[1] 刘江涛,张文涛,张万仓,等.陈腐垃圾处理生产线关键技术研究 [J].绿色科技,2018(4):236-237+244.
[2] 李艳平,张成昊.基于微信小程序的垃圾分类系统设计与实现 [J].现代信息科技,2023,7(10):14-17+21.
[3] 陈叶飞.基于字典学习的人脸特征提取及识别研究 [D].上海:上海交通大学,2018.
[4] 黄梓清,谭伟健,陈水龙,等.基于交互体验的校园垃圾分类投放系统设计 [J].物联网技术,2022,12(1):74-76.
[5] 胡景勤.基于微信和单片机的垃圾分类回收系统 [J].自动化与仪器仪表,2021(3):98-100+104.
[6] 孙建军,李琪,吕强.浅析Web开发工具Django的MVC架构 [J].品牌与标准化,2021(6):105-106+109.
[7] 汪洋,姜新通.MVC框架在Python与Django下的设计研究 [J].电脑与信息技术,2021,29(1):55-57+63.
[8] 姬壮伟.基于PyTorch的神经网络优化算法研究 [J].山西大同大学学报:自然科学版,2020,36(6):51-53+58.
[9] 唐康健,文展,李文藻.基于卷积神经网络的垃圾图像分类模型研究应用 [J].成都信息工程大学学报,2021,36(4):374-379.
[10] 李妍.基于ResNet算法的垃圾图像识别分类研究 [J].长江信息通信,2021,34(5):25-27.
作者简介:吴明珠(1982.09—),女,汉族,安徽安庆人,副教授,硕士,主要研究方向:计算机仿真、图像处理。