


摘" 要:对于SegFormer网络中存在的多尺度信息无法有效利用,以及预测结果边界轮廓不清晰的问题,提出一种基于深度流场特征和语义约束的改进语义分割网络架构。首先,在解码器部分加入深度流场模块用于加强深度特征的一致性;然后为保持原有网络的轻量化,加入边界和前后景辅助任务构成语义约束模块,提高网络对边界和整体轮廓的提取能力;最后,在语义约束模块中加入边界引导模块,加快辅助任务收敛速度。通过增加了0.1 M的参数量,提高了网络的分割精度。
关键词:SegFormer;语义分割;轻量化;深度流场;辅助任务
中图分类号:TP391.4" " " 文献标识码:A" " " 文章编号:2096-4706(2024)18-0071-04
Improved SegFormer Semantic Segmentation Algorithm Based on Deep Flow Field Feature and Semantic Constraint
GAO Yanhai
(Qingdao University of Technology, Qingdao" 266520, China)
Abstract: For the problems that the multi-scale information existing in the SegFormer network" cannot be effectively utilized and the boundary contour of the prediction result is unclear, an improved semantic segmentation network architecture based on deep flow field feature and semantic constraint is proposed. Firstly, a deep flow field module is added to the decoder part to enhance the consistency of depth feature. Then in order to keep the lightweight of the original network, the boundary and foreground and background auxiliary task are added to form a semantic constraint module to improve the ability of network to extract boundary and overall contour. Finally, the boundary-guided module is added to the semantic constraint module to speed up the convergence of auxiliary task. By increasing the number of parameters by 0.1 M, the segmentation accuracy of the network is improved.
Keywords: SegFormer; semantic segmentation; lightweight; deep flow field; auxiliary task
0" 引" 言
图像的语义分割是将图像中每个像素按照区域划分为不同的类别,这是计算机视觉的一项重要任务。伴随着深度学习技术的发展和大数据时代的来临,基于深度学习的语义分割成为当前语义分割的主流方法[1-4]。
2017年,Vaswani等[5]首次提出了Transformer架构,后来,由于Transformer架构提取全局特征信息的优点,使其在其他领域得到了广泛的应用。2021年,Google团队[6]首次提出了Vision Transformer网络,并将Transformer架构首次应用到了计算机视觉领域。随后,出现了许多基于Transformer架构的语义分割网络,如PVT[7]、Swin Transformer[8]、Deit[9]等。
随着对Transformer架构的使用,Transformer训练需要大量计算的缺点也逐渐暴露出来,因此,出现了一些对Transformer轻量化的改进,如CSWin网络[9]中将Swin Transformer中的窗口注意力替换为了十字交叉注意力机制,借此减少了参数量和计算量。SegFormer网络[10]中对自注意力机制进行了改进,通过减少自注意力序列长度,降低了时间复杂度。从上述研究中可以看出,轻量化是当前基于Transformer语义分割方法的一种主要趋势,因此,本文提出了一种基于深度流场和语义约束的改进SegFormer语义分割方法。
1" 改进的轻量语义分割网络
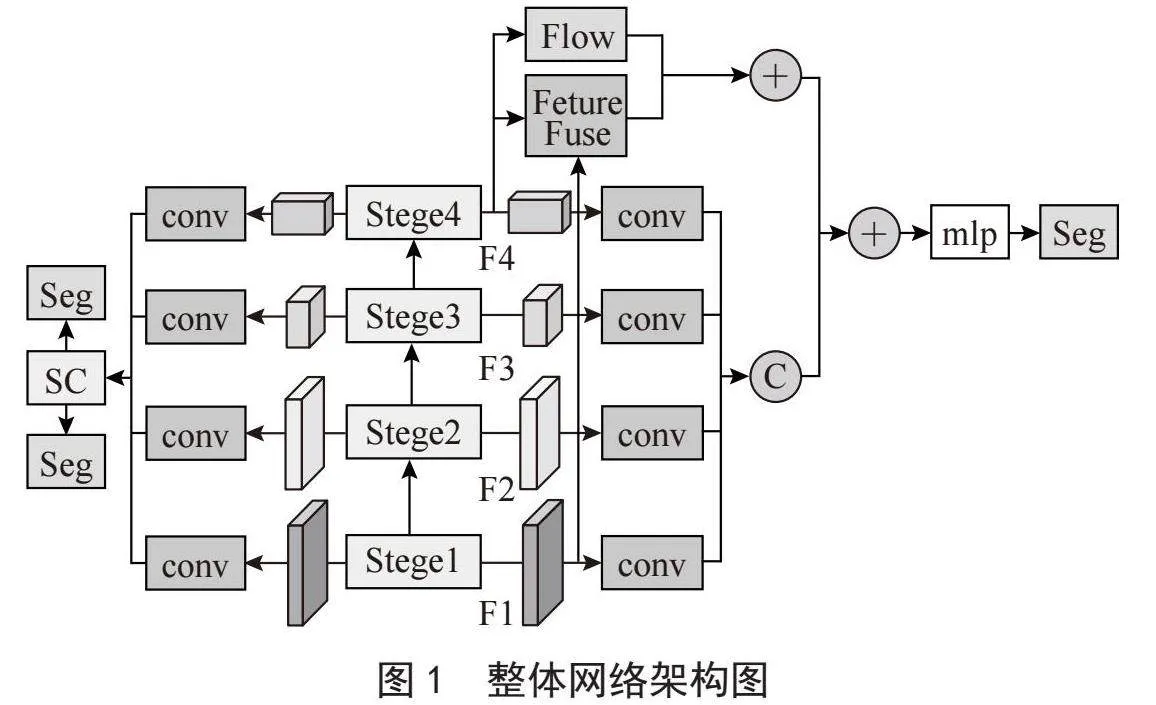
本文提出的基于深度流场和语义约束的改进SegFormer语义分割网络的整体架构如图1所示,网络整体采用了编码器和解码器的架构,在编码器阶段,对传入的图像使用SegFormer的主干网络mit-b0进行预测,分别预测出F1、F2、F3、F4的多尺度特征。在解码器阶段,解码器主要有语义分支和辅助分支两部分,在语义分割任务部分,使用深度流场模块,对深层特征F4中的特征进行位置映射,以加强深层特征之间对象的一致性,在语义约束部分,将传入的多尺度特征,分别进行边界预测和前后景预测,并在两个辅助任务之间,使用边缘引导聚合模块,将预测的边缘信息融合到前后任务中的特征中去,以加快辅助任务的收敛速度,更快更正确地辅助语义分割任务训练。
1.1" 深度流场模块
光流是指运动的物体在二维观察平面上的瞬时运动速度,在视频语义分割中经常使用光流以加快预测效果。在深度学习中,深层特征通常包含了图像的关键轮廓信息,因此,为加强深度特征中对象的一致性,设计并提出了轻量的深度流场模块。
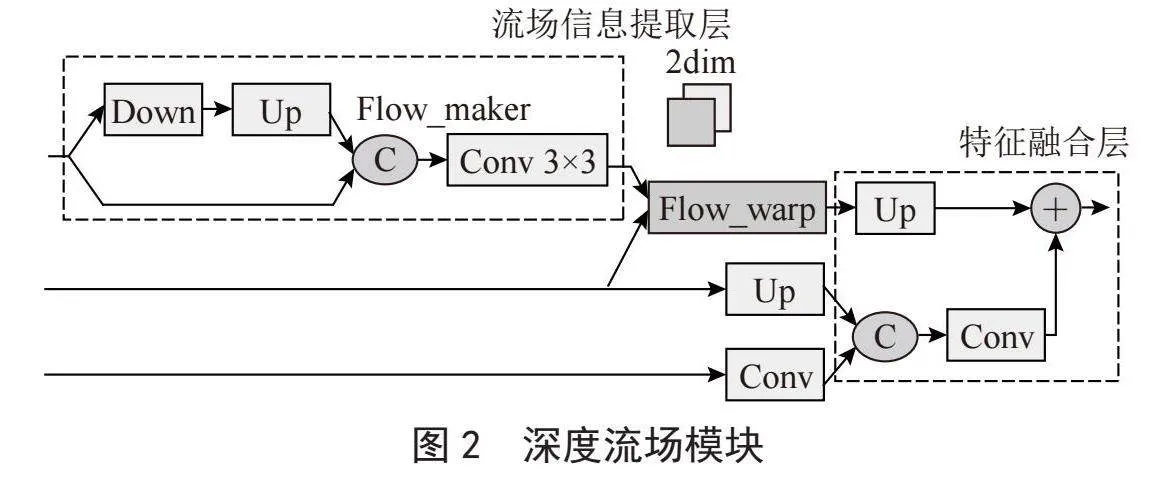
整体深度流场模块(Deep Flow Field, DFF)如图2所示,主要由光流提取层、流场偏移层和特征融合层组成。
1.1.1" 光流提取层
光流提取层主要是提取深层特征中的光流信息,首先使用Down层进行下采样操作,Down层的主要结构如式(1)和式(2)所示,通过使用卷积层、归一化层和激活函数对特征进行聚合提取,以提取其中的关键轮廓信息,并接一层3×3的卷积,提取出二维的流图。
(1)
(2)
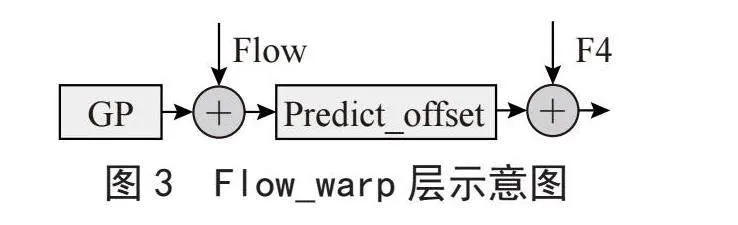
1.1.2" 流场偏移层
流场偏移层如图3所示,首先根据特征图大小生成一张中心位置矩阵(GCPM),然后将预测到流图与生成的位置矩阵相加得到预测到位置偏移矩阵。然后使用位置偏移矩阵将深层特征进行位置偏移,按照方向将其偏移到对应的位置,借助这种方式,使得深层特征中的对象更为一致。
(3)
1.1.3" 特征融合层
为防止偏移后的深层特征缺少全局和细节信息,因此,又在之后加入了特征融合部分,将浅层特征F1和深层特征F4按照通道拼接,并将融合后的特征与偏移后的深层特征相加,补充其中的全局和细节信息。
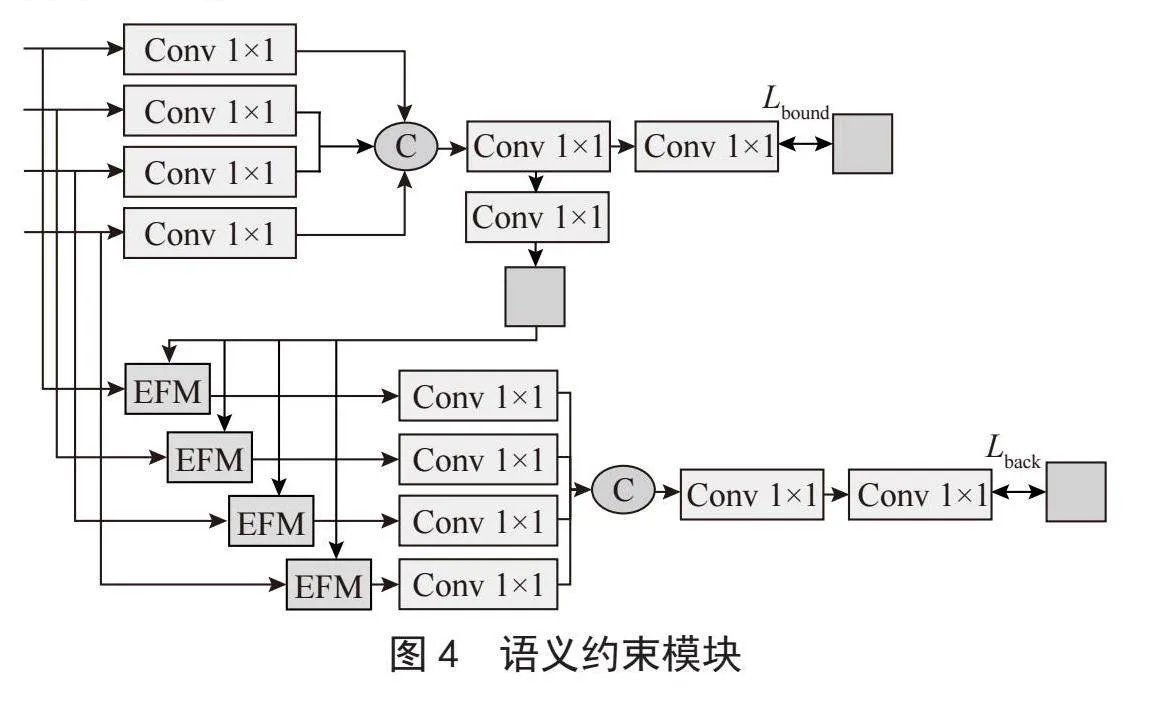
1.2" 语义约束模块
整体语义约束模块(Semantic Constraints, SC)如图4所示,主要由边界预测辅助和前后景预测辅助组成。对于提取到的多尺度特征,首先通过1×1的卷积对通道数进行统一,然后沿着通道进行拼接,并使用1×1的卷积进行融合。在边界预测部分,对融合后的特征使用1×1的卷积进行预测。随后,将预测得到的边界图送入前后景预测中,通过边缘引导模块将bi边界信息融合到前后景任务中以加快网络的收敛速度。
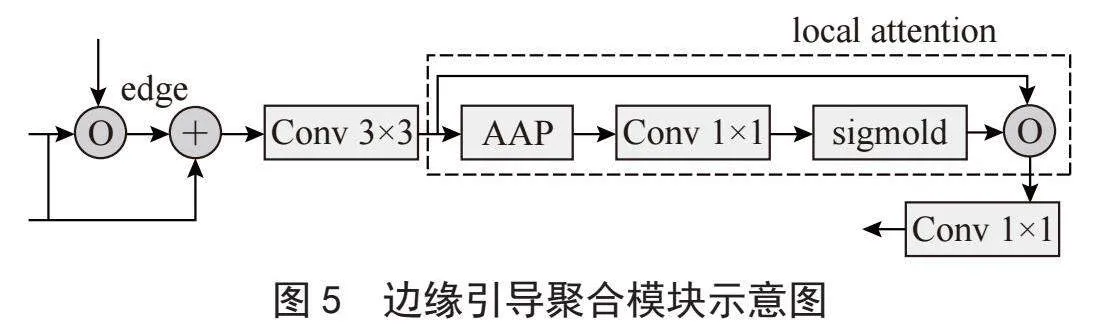
1.3" 边缘引导聚合模块
在前后景预测任务中,通过边缘引导聚合模块(Edge-Guided Aggregation, EGA)使预测的边缘图进一步聚合每个尺度上的信息,边缘引导聚合模块如图5所示,将当前层特征与得到边界预测图进行点乘操作,然后将两个特征之间相关性信息加到原特征中,使用3×3卷积对得到的特征进行聚合操作,然后使用局部注意力增强当前层信息,接着对每一层特征重复上述步骤,得到了聚合边界信息的多尺度特征,然后将多尺度特征拼接预测前后景的结果,并计算前后景的损失函数。
1.4" 损失函数
本文主要使用了交叉熵损失函数计算语义分割预测和标签、边界和边界标签和前后景的损失函数,具体计算式如式(4)所示,其中p(xi)表示真实类别的概率分布,q(xi)表示预测的概率分布,用于计算分类问题。
(4)
整体的损失计算式如式(5)所示,整体损失等于语义分割的损失加边界的损失和前后景的损失,与上一章使用优化算法不同,这里通过辅助任务之间交互的思想,将整体辅助任务看作一个整体,以减少任务之间多余的干扰:
(5)
2" 实验结果与分析
本文对提出的基于深度流场特征和语义约束的改进SegFormer网络,分别在ADE20K数据集和CityScapes数据集上进行消融和对比实验,以验证提出网络的有效性。
2.1" 实验环境和参数设置
网络的实现使用MMSegmentation框架和PyTorch框架,其中学习率设置为6×10-5,权重衰减设置为0.01,在3090显卡上进行了160 000次迭代参数更新训练。
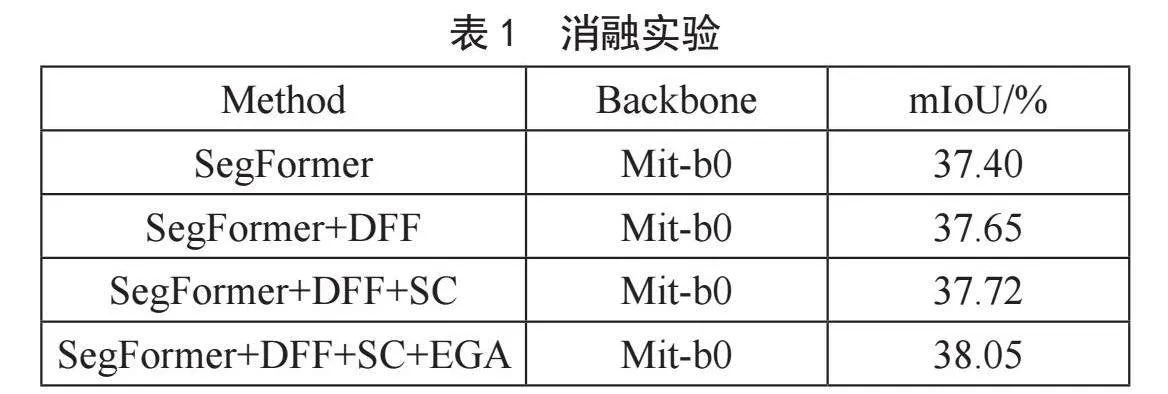
2.2" 消融实验
下面为在ADE20K数据集上进行的消融实验,其中Img表示原图,SegFormer+DFF表示添加了深度流场模块的SegFormer网络,SegFormer+DFF+SC表示在此基础上又添加了语义约束模块,最后,SegFormer+DFF+SC+EGA表示本文提出的网络。
本文对提出的基于深度流场特征和语义约束的网络在ADE20K数据集上进行了消融实验,具体如表1所示,从实验数据中可以看到本文添加的方法相比原网络都有一定的提高,其中添加深度流场模块相比原方法提高了0.25%的平均交并比(mIoU),在添加了语义约束模块后相比原方法提高了0.32%的平均交并比,最后将本文的所有模块添加后,相比原方法提高了0.65%的平均交并比,从消融实验的数据中可以验证本文方法的有效。
由图6的消融可视化实验结果可以看出,原有SegFormer方法分割中存在许多问题。例如第一行中对海洋的预测是错误的,第二行中也没有预测出车前的积雪。在添加了深度流场模块后改善了原有的网络分割精度,可以看到在添加了深度流场模块后,成功预测到了海洋和积雪。由第四列和第三列的图对比可以看到,在增加了语义模块后,预测到的边界整体更为平滑,前后景的区分度更高,第五行中人物图像边缘更加光滑。但语义约束模块也存在一些问题,例如其中的耳机被错误预测,最后边缘引导聚合模块的添加解决了这一问题,将第五列与其他预测结果对比,整体效果都更好。
2.3" 对比实验
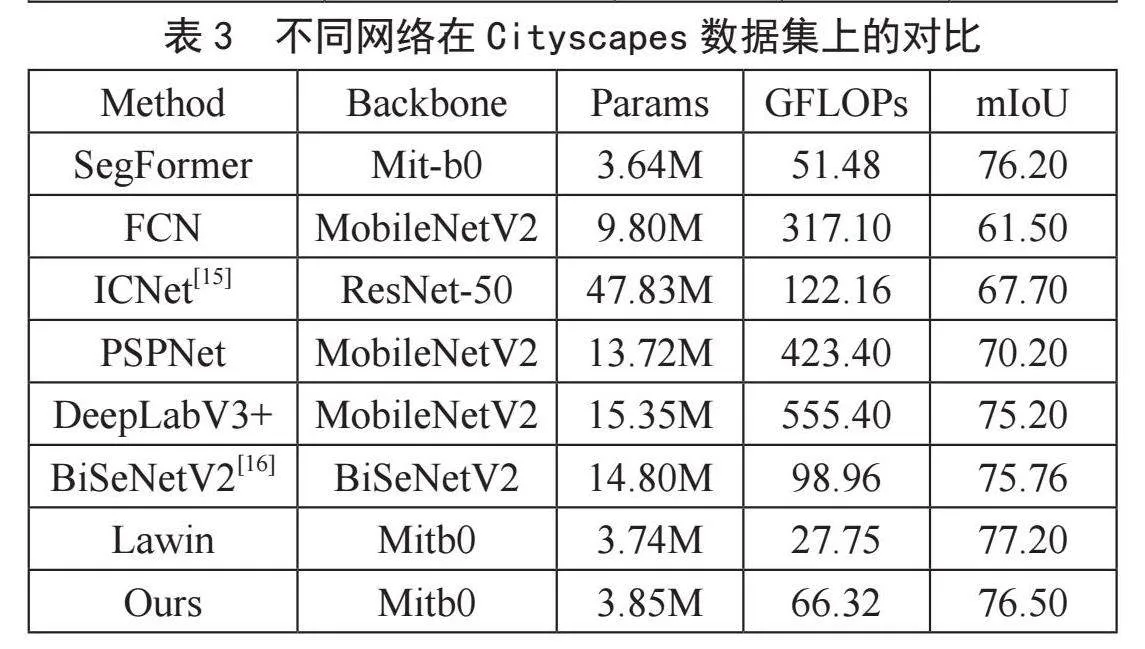
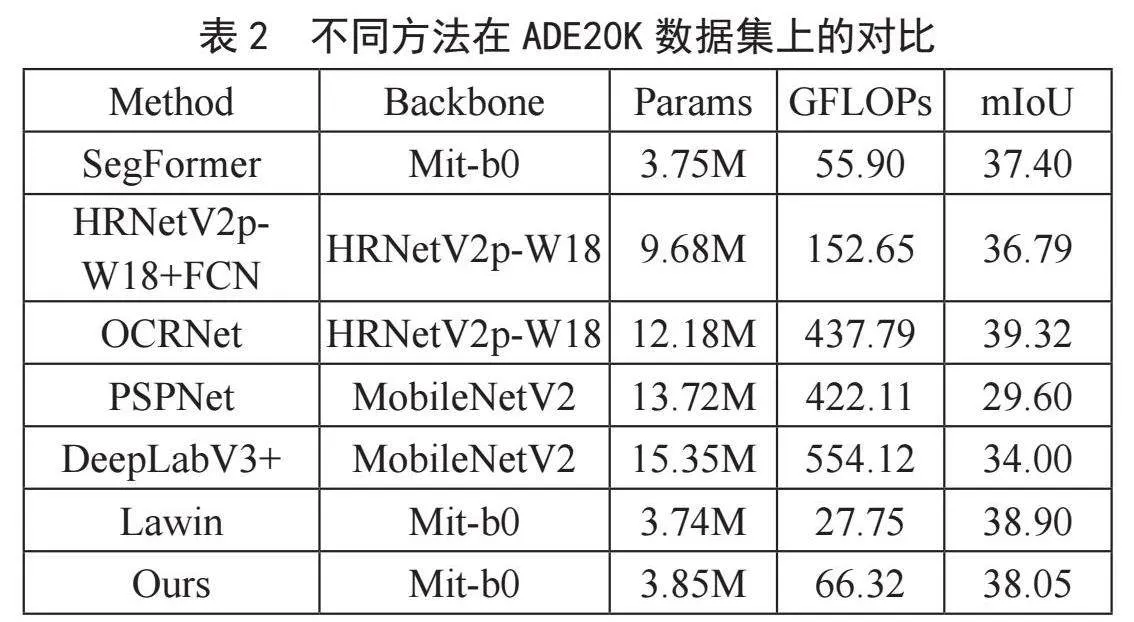
下面对本文提出的网络在ADE20K数据集和CityScapes数据集上使用平均交并比,参数量(Params)和计算量(FLOPs)进行了对比实验[11-14]。
表2和表3为本文网络与其他的网络的对比实验,从对比实验中能够看到,本文提取的网络成功继承了原有网络SegFormer的轻量效果,相比其他网络在轻量化有一定的优势。与其他网络的对比发现,其他诸如PSPnet、Deeplab网络都存在着计算量大和参数量大的问题,即使OCRnet网络有着很高的分割精度,但从参数量和计算量来看,本文方法相比其减少了8.33M的参数量和371.47 GFlops的计算量。并且相比其他的卷积网络,本文方法也有很多的分割精度上的优势。
3" 结" 论
对当前的轻量网络,本文提出了一种基于深度流场和语义约束的方法,相比当前一些常用的语义分割网络,该网络能够同时满足轻量与分割精度的需求,下一步将会探究进一步提高语义分割精度,并探索其在其他领域的应用。
参考文献:
[1] LONG J,SHELHAMER E,DARRELL T. Fully Convolutional Networks for Semantic Segmentation [C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Boston:IEEE,2015:3431-3440.
[2] ZHAO H S,SHI J P,QI X J,et al. Pyramid Scene Parsing Network [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Honolulu:IEEE,2017:2881-2890.
[3] CHEN L C,PAPANDREOU G,KOKKINOS I,et al. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,40(4):834-848.
[4] BADRINARAYANAN V,KENDALL A,CIPOLLA R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(12):2481-2495.
[5] VASWANI A,SHAZEER N,PARMAR N,et al. Attention Is All You Need [J/OL].arXiv:1706.03762 [cs.CL].[2024-02-26].https://doi.org/10.48550/arXiv.1706.03762.
[6] DOSOVITSKIY A,BEYER L,KOLESNIKOV A,et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale [J/OL].arXiv:2010.11929 [cs.CV].[2024-02-26].https://arxiv.org/abs/2010.11929.
[7] WANG W,XIE E,LI X,et al. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions [C]//2021 IEEE/CVF International Conference on Computer Vision (ICCV).Montreal:IEEE,2021:548-558.
[8] LIU Z,LIN Y T,CAO Y,et al. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows [C]//2021 IEEE/CVF International Conference on Computer Vision (ICCV).Montreal:IEEE,2021:9992-10002.
[9] DONG X Y,BAO J M,CHEN D D,et al. CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows [C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Orleans:IEEE,2022:12114-12124.
[10] XIE E Z,WANG W H,YU Z D,et al. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers [J/OL].arXiv:2105.15203 [cs.CV].[2024-02-20].https://arxiv.org/abs/2105.15203.
[11] SUN K,XIAO B,LIU D,et al. Deep High-Resolution Representation Learning for Human Pose Estimation [C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Long Beach:IEEE,2019:5693-5703.
[12] YUAN Y H,HUANG L,GUO J Y,et al. OCNet: Object Context for Semantic Segmentation [J].International Journal of Computer Vision,2021,129(8):2375-2398.
[13] CHEN L C,ZHU Y H,PAPANDREOU G,et al. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation [C]//Computer Vision – ECCV 2018.Munich:Springer,2018:833-851.
[14] YAN H T,ZHANG C,WU M. Lawin Transformer: Improving Semantic Segmentation Transformer with Multi-Scale Representations via Large Window Attention [J/OL].arXiv:2201.01615 [cs.CV].https://arxiv.org/abs/2201.01615v1.
[15] ZHAO H S,QI X J,SHEN X Y,et al. ICNet for Real-Time Semantic Segmentation on High-Resolution Images [C]//Proceedings of the European conference on computer vision (ECCV).Munich:Springer,2018:418-434.
[16] YU C Q,WANG J B,PENG C,et al. BiSeNet: Bilateral Segmentation Network for Real-Time Semantic Segmentation [C]//Proceedings of the European conference on computer vision (ECCV).Munich:Springer,2018:334-349.
