摘" 要:信用卡逾期风险预测对金融机构的风险管理至关重要。文章基于8 731个信用卡用户的逾期行为数据,分析了7个关键申请人特征,并采用逻辑回归模型对逾期风险进行了精准预测。针对数据不平衡及预测可信度问题,采用独热编码技术处理类别数据,并通过样本平衡化技术加以解决。在模型调优方面,综合考虑模型的拟合优度和复杂度,精细调整模型参数,显著提升了预测的可靠性。相较于AIC模型75.494%的精度,优化后的逻辑回归模型展现出更出色的预测性能。此外,还利用ROC曲线对模型性能进行了全面评估。实验结果表明,优化后的逻辑回归模型在信用卡逾期风险预测方面表现优异,为金融机构的风险管理和决策提供了有力支持。
关键词:逻辑回归模型;信用卡逾期风险预测;数据优化;ROC曲线评估
中图分类号:TP391" 文献标识码:A" 文章编号:2096-4706(2024)19-0141-06
Credit Card Overdue Risk Prediction and Optimization Based on Logistic Regression Model
ZHANG Siyang
(Xian Eurasia University, Xian" 710065, China)
Abstract: Credit card overdue risk prediction is crucial for risk management of financial institutions. Based on the overdue behavior data of 8 731 credit card users, this paper analyzes seven key applicant characteristics and uses Logistic Regression model to accurately predict the overdue risk. To address the issues of data imbalance and prediction credibility, it uses the One-Hot Encoding technique to process the category data and solves it by sample balancing technique. In terms of model tuning, it takes into account the model Goodness of Fit and complexity synthetically, and fine-tunes the model parameters to significantly improve the reliability of the prediction. Compared with the 75.494% accuracy of the AIC model, the optimized Logistic Regression model shows better prediction performance. In addition, this paper comprehensively evaluates the model performance using ROC curve. The experimental results show that the optimized Logistic Regression model performs well in credit card overdue risk prediction, which provides strong support for risk management and decision-making of financial institutions.
Keywords: Logistic Regression model; credit card overdue risk prediction; data optimization; ROC curve evaluation
0" 引" 言
在快速发展的金融科技浪潮中,信用卡业务凭借其便捷性和高效性,已经成为人们日常生活中不可或缺的一部分。然而,随着信用卡发卡量的持续增长,逾期风险问题也愈发凸显,给金融机构带来了不小的挑战[1-5]。逾期风险不仅威胁着金融机构的资产安全和盈利能力,还可能对整个金融市场的稳定造成潜在威胁[4-6]。因此,如何准确预测和有效管理信用卡逾期风险,已成为金融机构待解决的问题。传统的信用卡逾期风险评估方法多依赖于人工经验和定性分析,缺乏科学性和精准性。随着大数据和机器学习技术[7]的兴起,越来越多的金融机构开始探索基于数据驱动的逾期风险评估方法。逻辑回归模型作为一种简单而有效的机器学习算法,在信用卡逾期风险预测领域展现出了巨大的潜力。Singh等[2]在信用评分问题中指出传统的逻辑回归模型在实际应用中仍存在一些局限性,如数据不平衡、特征选择不当等问题,导致预测结果的准确性有待提升。因此,本研究旨在通过优化逻辑回归模型,提高其在信用卡逾期风险预测中的性能[8-9]。通过深入研究信用卡逾期风险的形成机制和影响因素,结合现代数据分析技术,对模型进行改进和优化,以提高预测的准确性和稳定性。这不仅有助于金融机构更加精准地识别潜在风险,制定针对性的风险管理策略,降低逾期风险带来的损失,还有助于推动金融科技创新和发展,提升整个金融行业的风险管理水平[10]。此外,本研究还具有重要的理论意义和实践价值。在理论层面,通过对逻辑回归模型的优化研究,可以丰富和完善机器学习算法在金融风险管理领域的应用理论,为相关领域的研究提供新的思路和方法。在实践层面,本研究可以为金融机构提供一套科学、有效的信用卡逾期风险预测和管理工具,帮助他们更好地应对市场风险和竞争挑战,实现可持续发展。本研究背景深厚且意义重大,旨在通过优化逻辑回归模型等机器学习算法,提高信用卡逾期风险预测的准确性和可靠性,为金融机构的风险管理提供有力支持,同时也为金融科技创新和社会发展贡献力量。
1" 数据来源与指标设计
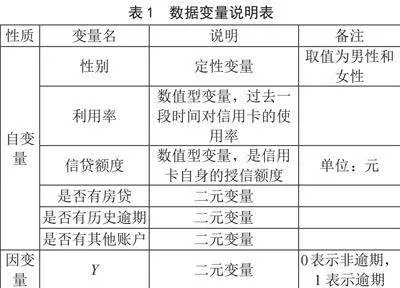
本研究所用的数据来源于回归实现与分析课程,一共是8 731条数据,包含7个变量。本文旨在探究信用卡逾期问题,基于名为“信用卡客户违约情况”的数据集展开研究。数据集涵盖了持卡人的个人信息及信用卡使用情况。数据中的变量丰富,包括客户唯一标识、性别、信用卡使用额度占比、信用额度、房贷情况、历史逾期信息、其他信用卡账户拥有情况以及客户是否违约等。在数据处理方面,本文首先进行了独热编码处理,将分类数据转换为模型易于理解的格式,确保模型能够准确捕捉变量间的真实关系。接着,本文对所有样本数据进行了标准化处理,以消除不同量纲对模型训练的影响,提高模型的稳定性和预测准确性。此外,本文注意到数据集中存在样本不平衡问题,即逾期客户占比相对较少。为了解决这个问题,本文在数据预处理阶段采用了适当的采样策略,以平衡不同类别的样本数量,从而提高模型的泛化能力和预测性能。综上所述,通过对数据集的预处理,本文为后续的分析和建模工作奠定了坚实基础。独热编码、数据标准化以及采样策略的应用,确保了模型能够更好地理解和利用数据,提高了预测准确性。这将有助于我们深入了解信用卡逾期问题,为金融机构的风险管理提供有力支持。本研究受数据限制,主要考虑了7个解释变量,这些变量主要围绕银行客户的信用卡逾期问题,如表1所示。
具体介绍如下:
1)性别。这个变量用于标识个体的性别,通常只有两种取值,如男性和女性。性别在多个方面可能影响个人的经济行为和信用卡使用情况。例如,不同性别的消费习惯、储蓄观念、风险偏好等方面可能存在差异,这些差异可能会间接影响到信用卡的还款行为。
2)利用率。该变量表示个人信用卡使用的比例,即已使用额度与总授信额度的比值。利用率的高低可以反映个人信用卡使用的活跃程度以及还款压力的大小,对于评估信用卡逾期风险具有重要意义。
3)信贷额度。这个变量代表了银行或其他金融机构为个人提供的最大可借款金额。信贷额度的大小反映了个人信用状况及借款能力,也是评估信用卡逾期风险时需要考虑的关键因素。
4)是否有房贷。该二元变量用于标识个人是否背负房贷。房贷作为长期负债,会对个人的还款能力产生影响,因此这一变量对于预测信用卡逾期风险具有一定的参考价值。
5)是否有历史逾期。此二元变量表明个人在过去是否有过逾期还款的记录。历史逾期是评估个人信用状况的重要指标,对于预测未来信用卡逾期风险具有直接的实质性意义。
6)是否有其他账户。该变量用于标识个人是否在其他金融机构拥有账户。其他账户的存在可能意味着个人有更复杂的财务状况,对于全面评估信用卡逾期风险有一定帮助。
7)Y(逾期状态)。这是一个二元变量,通常用于标识个人是否发生信用卡逾期。通过对上述自变量的分析,可以预测或解释Y的取值,从而帮助金融机构更好地识别信用卡逾期风险,制定相应的风险管理策略。
这些变量的综合分析对于评估个人信用状况、预测信用卡逾期风险以及制定风险管理措施具有实质性的意义。
2" 描述分析
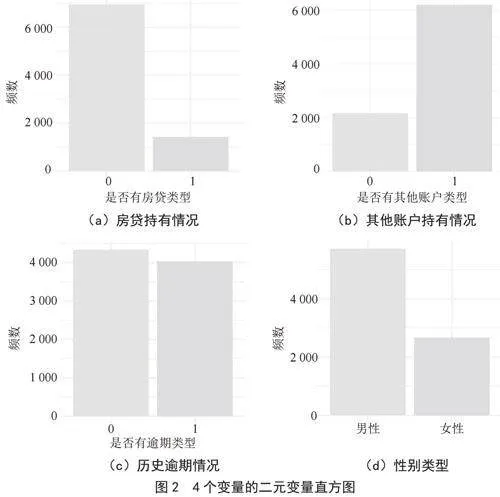
本研究涉及6个解释变量:性别、利用率、信贷额度、是否有房贷、是否有历史逾期、是否有其他账户。接下来,本研究描述分析检查数据质量,并初步判断Y(逾期状态)与各个潜在影响因素之间的关联,为后续建模研究做铺垫。首先我们先考虑利用率和信贷额度,如图1所示。从中可以看到,这两个图都是严重右偏的分布。大部分样本的信用限额集中在较低的水平,且有一个较高的峰值出现在较小的信用限额值附近。这说明在该数据集中,大多数用户被分配了相对较小的信用限额。在建模过程中,这种数据分布可能会导致模型更倾向于关注那些信用限额较小的用户,而忽略了部分信用限额较大的用户。因此,在构建模型时需要考虑如何平衡不同信用限额用户的权重,以提高模型的泛化能力和预测准确性。同样利用率主要集中在较低的水平,但也存在一个较高的峰值。这可能意味着在某些特定的利用率范围内,样本数量较多。对于后续的建模工作来说,这种数据分布可能会产生一定的影响。
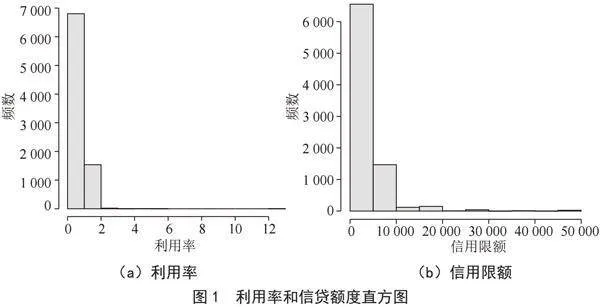
接下来,对另外4个解释变量也做类似的直方图分析,如图2所示。这另外4个解释变量都是属于二元变量。从图中可以看出,大部分样本没有房贷,只有少量样本有房贷。这种数据分布可能会影响后续的建模结果,因为模型可能会更加偏向于预测样本没有房贷;在是否有其他账户的数据中模型可能会更偏向于预测有其他账户;在是否有历史逾期中的数据相差不多,因此模型预测可能会偏向于参考数据较多的一边,如没有其他账户;最后在性别分布的直方图中,模型预测可能会更偏向于男性,给模型预测提供更多的参考数据。
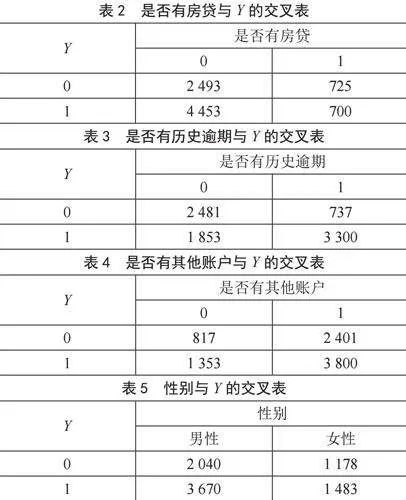
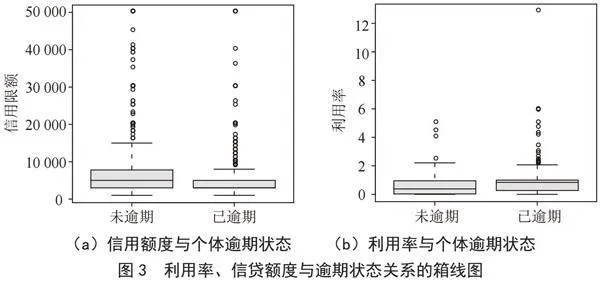
接下来对逾期状态Y和各个解释变量的相关关系做简单的描述;由于Y是一个二元变量可以将Y与每个数值型变量做箱线图的对比分析,如图3所示。从图中可以看到信贷额度的未逾期的中位数比已逾期的中位数要高,说明信贷额度高的个体用户更有可能不逾期;同样从利用率与个体逾期状态图中可以看出,未逾期的中位数比已逾期的中位数要低,说明利用率高的个体用户更容易逾期。由于其他4个变量为二元变量,所以我们决定用交叉表来体现他们与Y之间的关系,如表2至表6所示。
3" 模型建立
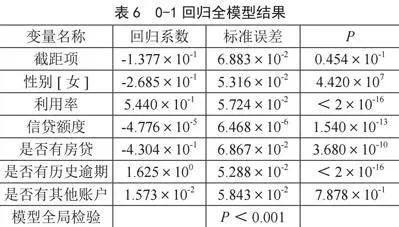
为了深入研究影响逾期状态的显著因素有哪些,本研究将建立0—1回归模型(logistic模型)。首先对所有变量建立0—1回归全模型,结果如表6所示。观察P值可以看出全模型的似然比检验高度显著(P值<0.001)这说明在考虑的所有因素中有一个变量对逾期状态有显著影响。在5%的显著水平下有5个变量高度显著,这说明在利用率、信贷额度等变量取值越高的情况下,个体用户逾期的可能性就越大。
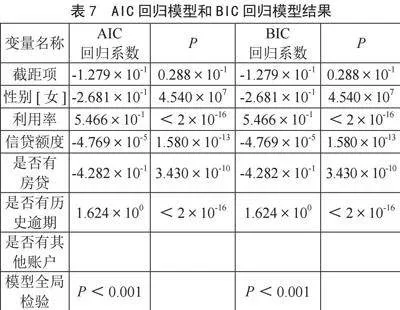
然而全模型还包括一些不显著的因素,因此考虑AIC准则和BIC准则,选择更加简洁的模型,其结果如表7所示。但是,根据AIC和BIC所呈现出的结果来看,AIC回归和BIC回归的结果一致,都只去掉了是否有其他账户,保留了另外5个变量,结果可以表明性别、利用率、信贷额度、是否有房贷、是否有历史逾期、是否有其他账户都是高度显著,对个体用户是否预期有着显著影响。
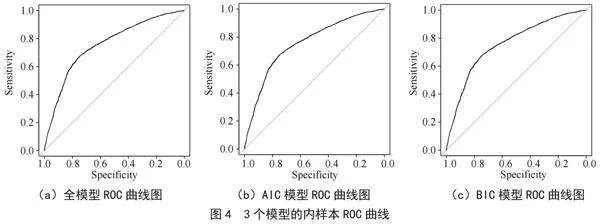
由于全模型、AIC模型和BIC模型在变量选择上和回归系数上都存在些许差异,所以本研究将对比这3个模型的内样本ROC曲线及外样本AUC值,ROC(Receiver Operating Characteristic)曲线是描述二元分类器在不同阈值下的表现的曲线[3]。PR(Precision-Recall)曲线是弥补了ROC曲线在处理不平衡数据时出现缺陷而诞生的一种评估指标。横轴表示召回率(Recall),纵轴表示精确率(Precision),如图4所示。
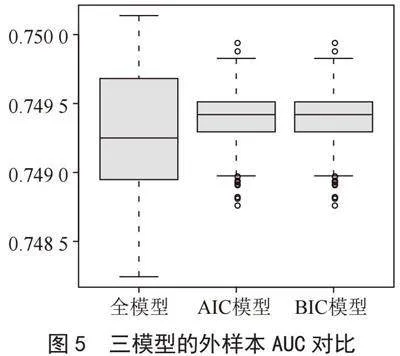
从3个模型的内样本ROC曲线图中可以看出,3个模型的预测精度几乎没有差异都为75.494%,所以决定用外样本的模型来进行评估试验。本研究做了基于外样本的模型精度评估试验,对比了3个模型的外样本AUC。每次随机试验都将原数据随机排列,前80%作为训练样本,而后20%作为验证样本,重复该试验1 000次,3个模型的外样本AUC值箱线图如图5所示。
从图中可以看出,AIC模型和BIC模型的AUC值中位数明显比全模型要高很多,3个模型外样本AUC对比表如表8所示,所以选择AIC模型和BIC模型其中一个。从图5中可以看出AIC模型和BIC模型的AUC值实在难以分辨,所以本研究进行AIC模型和BIC模型的模型复杂度和拟合优度的计算。
通过计算AIC模型输出的值为9 478.898,而BIC模型输出的值为9 528.126。根据统计学的原理,AIC和BIC都是用于评估模型拟合优度和复杂度的指标。AIC模型在拟合优度和模型复杂度之间取得了更好的平衡,相较于BIC模型,AIC模型在保持较高拟合度的同时,具有更低的复杂度,因此更适合作为个体用户逾期状态因素模型。
本研究对AIC模型的结果进行解读。模型系数估计值的正负号代表了是否逾期的状态,(系数为正,则逾期;反之,未逾期),在5%的限制水平下,AIC模型有5个显著变量,若控制其他因素不变,可以得出以下结论:
1)性别为女性时,个体用户更没有可能逾期。
2)信用卡利用率较高时,个体用户更有可能逾期。
3)信贷额度较高时,个体用户更没有可能逾期。
4)当个体用户有房贷时,更有可能逾期。
5)在个体用户有历史逾期情况时,更有可能逾期。
4" 结" 论
本研究的数据来源于回归实现与分析课程,以Y(逾期状态)作为因变量,以6个影响个体用户是否逾期的因素作为自变量,包括性别、利用率、信贷额度、是否有房贷、是否有历史逾期、是否有其他账户,建立对个体用户逾期状态具有一定预测能力的逻辑回归模型。本研究探究了哪些变量是影响个体用户逾期状态的重要因素,主要结论归纳如下:性别为女性时,个体用户更没有可能逾期;信用卡利用率较高时,个体用户更有可能逾期;信贷额度较高时,个体用户更没有可能逾期;当个体用户有房贷时,更有可能逾期;在个体用户有历史逾期情况时,更有可能逾期。
通过对个体用户逾期状态的影响因素进行逻辑回归分析,我们可以提出以下改进建议和未来发展方向:建立更精细的信贷额度分配机制,根据客户的信贷需求和信用状况,合理分配信贷额度,降低高信贷额度带来的逾期风险;收集更多维度的数据,如收入水平、职业稳定性等因素,以更全面地评估个体用户的逾期风险。此外本研究还仍然存在一些不足,比如:逻辑回归模型可能无法有效处理大量的特征,尤其是当特征之间存在多重共线性时,模型可能会出现过拟合或欠拟合的问题,逻辑回归模型假设特征之间相互独立,但在实际情况下,特征之间可能存在复杂的交互效应,这些交互效应可能会影响模型的预测准确性和泛化能力。最后这些结论有助于我们更深入地理解个体用户逾期状态的影响因素,为金融机构和政策制定者提供决策依据,以降低逾期风险,优化信贷策略。
参考文献:
[1] 卢荣伟,黄嫦娥,谢久晖.基于机器学习的信用卡逾期预测研究 [J].科学技术创新,2024(6):130-133.
[2] SINGH R,AGGARWAL R R. Comparative Evaluation of Predictive Modeling Techniques on Credit Card Data [J].International Journal of Computer Theory and Engineering,2011,3(5):598-603.
[3] 李林芳.个人信用影响因素分析 [J].中国总会计师,2020(6):78-80.
[4] 车鸣.信用卡消费信贷发展的影响因素分析及对策研究 [D].长沙:湖南大学,2003.
[5] 朱路路,崔玉龙.基于逻辑回归模型的凉山州滑坡易发性评价 [J].山西建筑,2024,50(5):71-73+97.
[6] 肖松,黄介武.二元逻辑回归模型中的修正Liu估计 [J].辽宁工业大学学报:自然科学版,2024,44(1):64-70.
[7] 彭舒悦,刘勤明,李佳翔.低碳视角下基于机器学习的医疗救援中心选址研究 [J].电子科技大学学报:社科版,2024,26(2):28-37.
[8] 张俊丽,仲崇丽,杨震,等.基于数据挖掘的上市公司高送转预测 [J].财务管理研究,2021(6):90-95.
[9] 张俊丽,郭双颜,任翠萍,等.基于逻辑回归的个人信用评分卡模型研究 [J].现代信息科技,2024,8(5):12-16.
[10] 戴蓓蓓.基于组合预测模型的商业银行个人信贷风险预测 [J].经济研究导刊,2022(35):69-72.
作者简介:张思扬(2004.08—),男,汉族,湖南长沙人,本科在读,研究方向:数据分析。