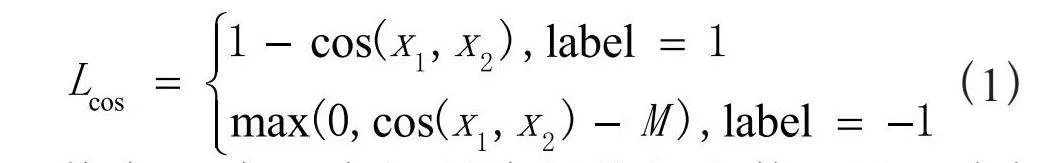

摘 要:为解决在线课程学习过程中所遇问题得不到及时解答的情况,设计并实现在线课程自动问答系统。首先收集课程中真实问题作为训练数据集,其次基于BERT模型构建双塔神经网络模型,将问题成对输入模型,以语义相似问题的特征向量尽可能相似为训练目的。训练模型中的参数后,准确率和F1-Score性能指标上的值分别达到0.931和0.918。使用训练好的模型将问题集和学习者提出的问题都转为特征向量,使用Faiss召回问题特征向量集中与学习者的问题最相似的问题,最后返回最相似的问题所对应的答案。系统具有较高的准确性和有效性,能够为在线课程学习提供支持。
关键词:自动问答系统;BERT模型;语义相似度;在线学习
中图分类号:TP311 文献标识码:A 文章编号:2096-4706(2024)20-0083-04
Design and Implementation of an Automatic Question and Answer System Based on BERT Model
ZHOU Qiaokou
(School of Information Engineering, Nanjing Normal University Taizhou College, Taizhou 225300, China)
Abstract: To address the situation where problems encountered during online course learning cannot be answered in a timely manner, an automatic question and answer system is designed and implemented. Firstly, real problems in the course are collected as training datasets. Then, a two-tower neural network model is constructed based on the BERT model. It enters the problem in pairs into the model, and the training objective is to train the feature vectors of semantically similar questions to be as similar as possible. After training the parameters of model, the values on accuracy and F1-Score performance indicators reaches 0.931 and 0.918, respectively. This paper uses the trained model to convert the problem sets and the questions proposed by learners into feature vectors, and uses Faiss to recall the most similar questions to the learners questions in the feature vector sets. Finally, it returns the corresponding answers of the most similar questions. The system has high accuracy and effectiveness, which can provide support for online course learning.
Keywords: automatic question and answer system; BERT model; semantic similarity; online learning
0 引 言
随着互联网技术的迅速发展,催生了在线教育的兴起。在线教育以网络为媒介实现教学资源的共享和教学活动的开展。具有受众面广、可反复学习,没有空间与地域的限制,教学资源丰富、多样等优点,已经成为当下主流的学习方式之一[1]。但也正因为在线教育自身时空分离的特性,使得学生与教师时空分离,教师无法像传统课堂教学那样及时解答学生在线学习过程中遇到的问题,严重影响学习者学习的积极性,从而影响学习者的学习效率和质量[2-3]。目前解决在线学习过程中遇到的问题有以下几种方案:1)采用搜索引擎,但网络中无关信息较多,费时费力往往找不到最佳答案;2)论坛或聊天室的形式,但常常都是学生之间相互问答,教师很少参与,且有些问题也无法得到及时回复[4];3)自动问答系统,普遍采用FAQ(Frequently-Asked Questions)列表问答的形式回答学生的问题,但列表中的问题有限,且并不能支持学生个性化问答[5]。基于知识图谱的问答系统,依赖专业领域的知识图谱,需要进行大量的数据标注、实体识别和关系抽取工作,过程较为复杂[6]。另一种基于神经网络的问答系统比较受欢迎,通过Embedding的方式表示问题,从语料库中学习出问题的语义进行问题和答案的匹配[7]。
综上所述,自动问答系统是解决在线课程问题无法及时解答的有效途径之一。本文探讨基于BERT模型构建自动问答系统的相关技术,主要思路为:首先利用BERT模型将问题转为语义向量,然后使用双塔神经网络模型学习问题中潜在的句法和语义特征,更好的理解问题,将问题转为特征向量,保存到问题特征集文件中。当学习者提问时,使用训练好的模型将问题转为特征向量,使用Faiss召回问题集中与学习者所提问题最相似的问题,最后返回匹配问题所对应的答案。使用深度学习神经网络提取问题特征,减少了FAQ通过复杂算法提取特征方面的不足,同时解决传统FAQ不支持学生个性化问答的问题,对帮助学习者完成在线学习有着重要的意义。
1 相关技术
1.1 BERT模型
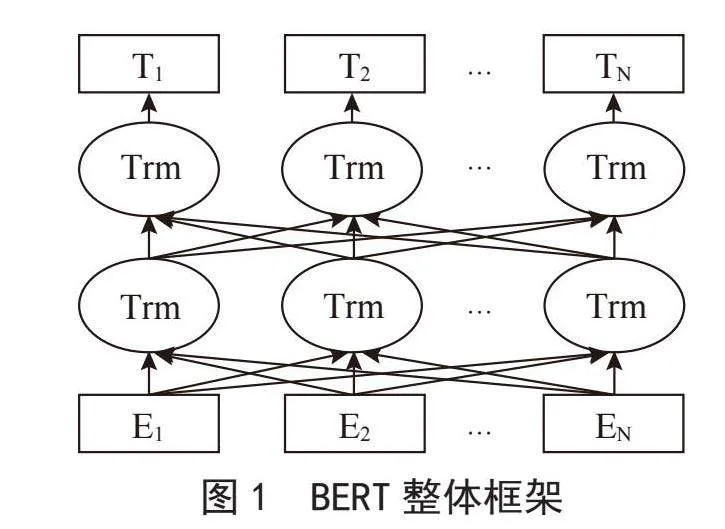
BERT是一种用于自然语言处理的深度学习模型。模型整体结构由多层双向的Transformer中的Encoder构成,整体框架如图1所示。这种双向性使得BERT能够更好地理解词的上下文关系,从而学到更加丰富的语言表示[8]。BERT模型的训练过程分为Pre-training和Fine-tuning两个阶段。Pre-training阶段,模型首先在设定的通用任务上,利用无标签的数据进行训练。训练好的模型获得了一套初始化参数之后,再到Fine-tuning阶段,模型被迁移到特定的任务中,利用有标签的数据继续调整参数,直到在特定任务上重新收敛。BERT模型有两种主要的预训练模型如BERT-Base和BERT-Large,两种预训练模型有着不同数目的Encoder layers、Attention heads以及Hidden size,适用不同的应用场景。文中的自动问答系统中使用BERT-Base预训练模型构建神经网络模型,其包含12个Encoder layers、12个Attention heads、Hidden size为768,总共约有110M个参数[9]。
1.2 Faiss框架
Faiss是Facebook AI团队开发的一种高效的相似性搜索和聚类的工具[10]。它能够快速处理大规模的数据,并支持高维空间中进行相似性搜索,对于10亿量级的索引可以做到毫秒级检索的性能。Faiss的使用分为三个步骤:第一步创建索引,使用faiss.Index类创建索引;第二步插入向量,使用faiss.Index类的add()方法将向量矩阵插入到索引中;第三步向量搜索,使用faiss.Index类的search()方法在索引中搜索与给定向量最相似的k个向量,k为用户指定的参数。为了平衡搜索效率、占用内存、准确率等性能指标,Faiss提供了多种索引类型,例如:IndexFlatL2、IndexIVFFlat、IndexIVFPQ等。文中因为数据集较小,追求较高的准确率,因而使用简单直接的IndexFlatL2索引。
2 自动问答系统的设计
2.1 数据集的构建
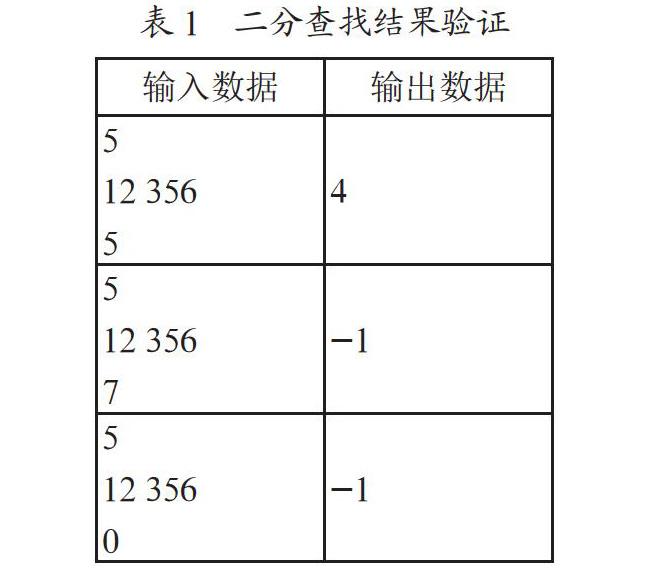
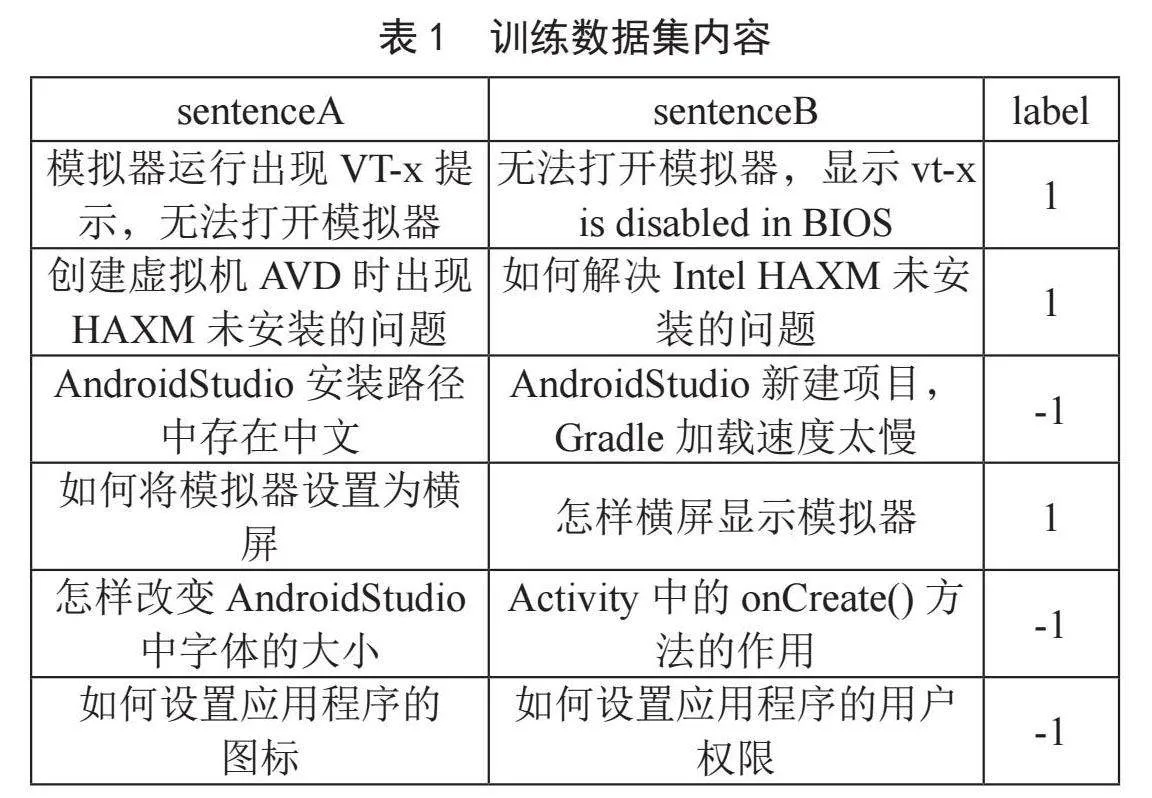
没有公开的在线课程问答系统的数据集,需要自行收集整理在线课程学习者的问题,在此基础上通过规范格式、过滤冗余等操作构建用于神经网络训练的数据集。以智能终端应用开发课程为例,收集教学过程中学生的问题1 000条,这些问题中存在较多的重复问题,问题不同但表达的意思相同,除去重复问题整理后得到800条问题,然后由任课教师撰写每个问题的答案,将问题和答案通过编号一一对应起来,分别保存在Q_list.csv和A_list.csv两个文件中。对于Q_list.csv中的问题进一步处理,为每个问题生成一个表达不同但语义相同的问题,同时为每个问题随机的匹配另一个不相关的问题,增加label项,如果两个问句语义相同,则label值为1,否则label值为-1,共计1 600条数据,将整理后的问题文件保存为question_data.csv。具体格式及部分内容如表1所示。
2.2 构建神经网络模型
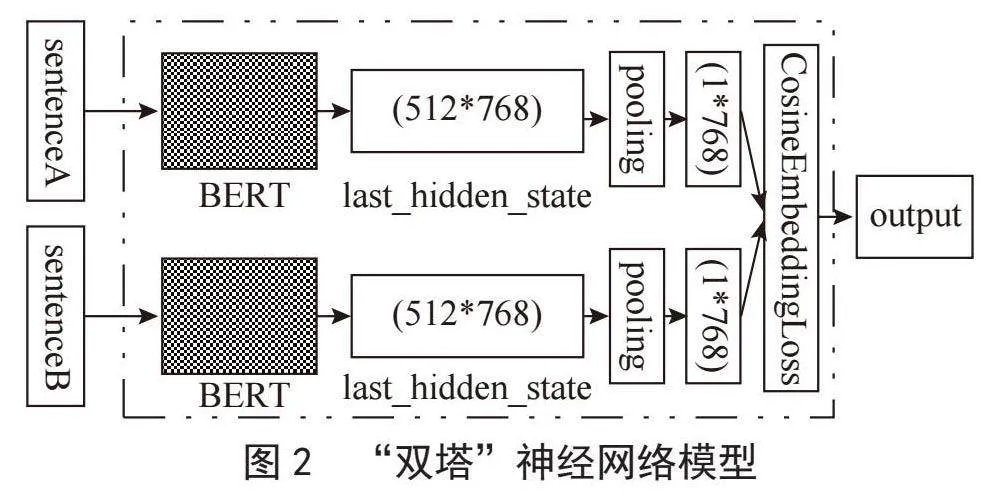
直接使用BERT模型将问题转为特征向量用于计算问题相似度效果并不理想,需要根据具体任务搭建合适的下游模型,文中采用PyTorch深度学习框架搭建神经网络模型。首先创建torch.utils.data.Dataset的子类,从question_data.csv文件中加载数据集,使用预训练模型“bert-base-chinese”加载token对sentenceA和sentenceB分别进行分词和编码为每个句子生成:input_ids、token_type_ids以及attention_mask三个张量。将编码后的sentenceA和sentenceB分别送入BERT模型,抽取模型最后一层输出的隐藏状态序列其形状为[512*768],512为设定的句子长度,768为句子中每个词的向量维度;然后将两个句子的last_hidden_state送入到池化层,将特征向量变为[1*768]维,最后将两个句子的特征向量送入CosineEmbeddingLoss层计算损失,然后通过反向传播更新模型参数,模型的训练过程如图2所示。
模型中使用CosineEmbeddingLoss计算sentenceA和sentenceB之间的损失,其主要思想是:将两个句子的向量投影到单位超球面,然后通过计算这两个向量的余弦相似度来度量它们之间的相似性。预选相似度的值范围从-1到1,其中1表示完全相似,-1表示完全不相似。计算公式如:
(1)
其中M为一个控制边际的超参数,用于确保Anchor样本与Positive样本之间的相似度高于Anchor样本与Negative样本之间的相似度,可取值范围为:[-1,1],本文实验中取值的0.3。
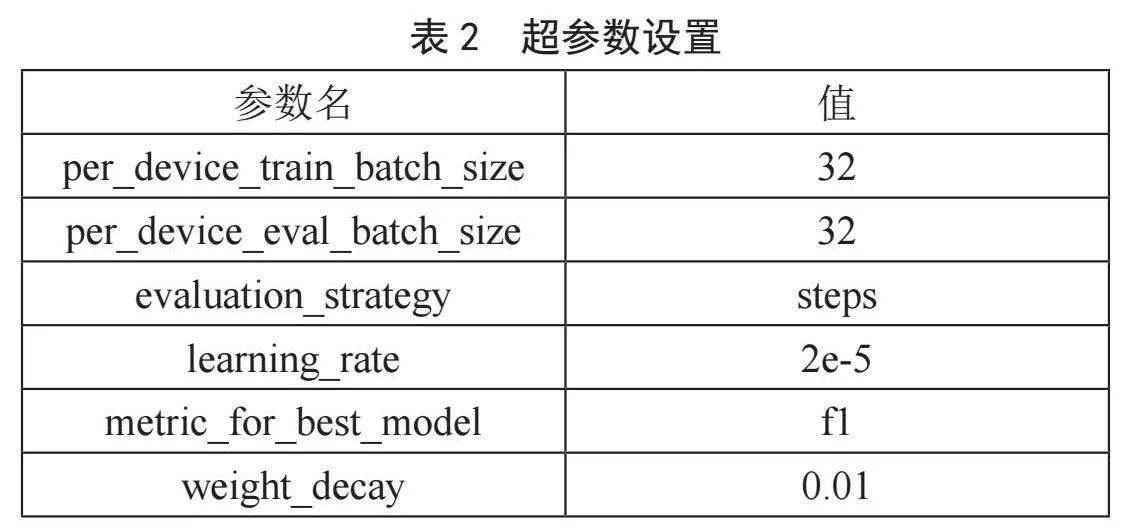
模型中使用TrainingArguments类统一设置超参数,其中主要的参数设置如表2所示。
其中train_batch_size和eval_batch_size分别表示训练和验证时的批次大小。evaluation_strategy表示评估策略,其值可以为steps或者epoch文中设置为steps,表示每个验证阶段结束后进行评估。learning_rate表示学习率。metric_for_best_model用于指定比较不同模型的度量标准。weight_decay表示正则化参数,用于抑制模型的过拟合,提高模型的泛化性。
在评估模型的性能时采用准确率(Accuracy)和F1-Score两个指标。准确率反映了正确分类的样本占总样本的比例,F1-Score是精准率(Precision)和召回率(Recall)的加权调和平均,两个指标的定义如下:
Accuracy=(TP+TN)/(TP+FP+TN+FN) (2)
F1-Score=2(Precision×Recall)/(Precision+Recall)(3)
其中TP为真正例:样本为正例被正确预测为正例;TN为真反例:预测为负样本,真实也为负样本;FP为假正例:样本反例被错误预测为正例,FN为假反例:样本正例被错误预测为反例。
2.3 模型训练及结果分析
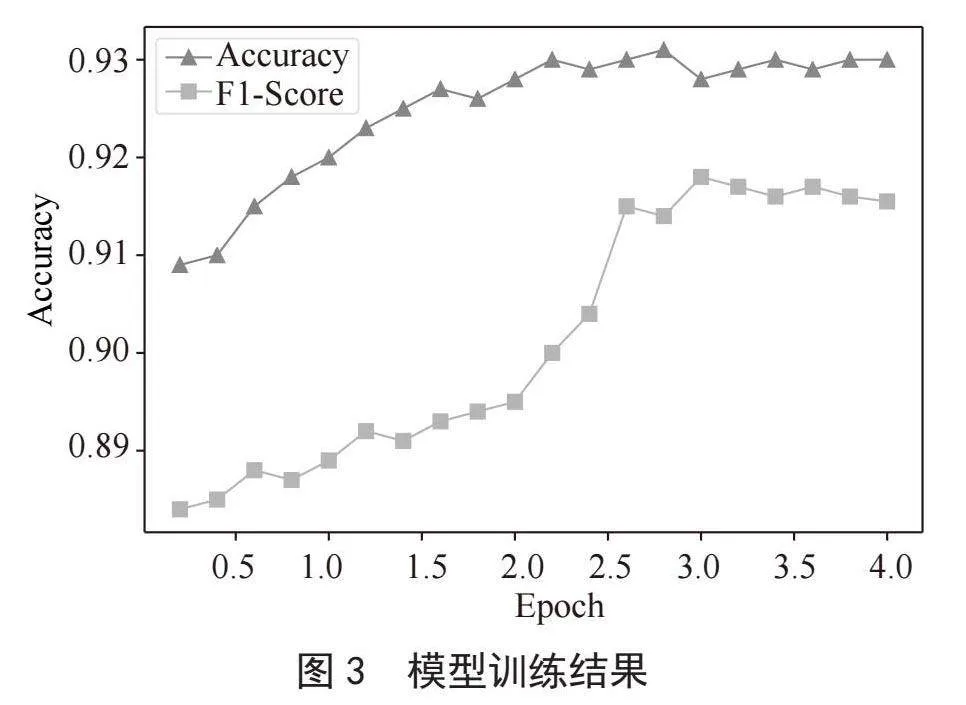
实验中,模型的训练次数Epoch设置为4,每个Epoch中batch_size为32,即每次输入32条数据进行训练,每10个Batch_size输出一次性能指标值,训练结果如图3所示。第1个Epoch训练结束后,Accuracy和F1-Score分别为:0.92和0.889,因为BERT为预训练模型,已经包含了大量语言、语句、语义的理解,使得模型整体性能较好。当接近第3个Epoch时,Accuracy和F1-Score先后获得最高值,分别为:0.931和0.918,随后两个指标趋于平稳,模型逐步收敛,比训练初期模型的性能有所提升,表明在具体任务中对BERT模型的二次训练能够提升模型的性能。
模型训练完毕后,使用torch.save()方法将训练好的模型保存到磁盘文件命名为DualModel.model。下一步,定义build_features()方法按批次从数据集中读取问题集,进行分词、编码送入训练好的DualModel模型将问题集转为问题特征向量集,并将问题特征向量集保存到磁盘文件命名为Features.pt。
2.4 问题匹配及回答
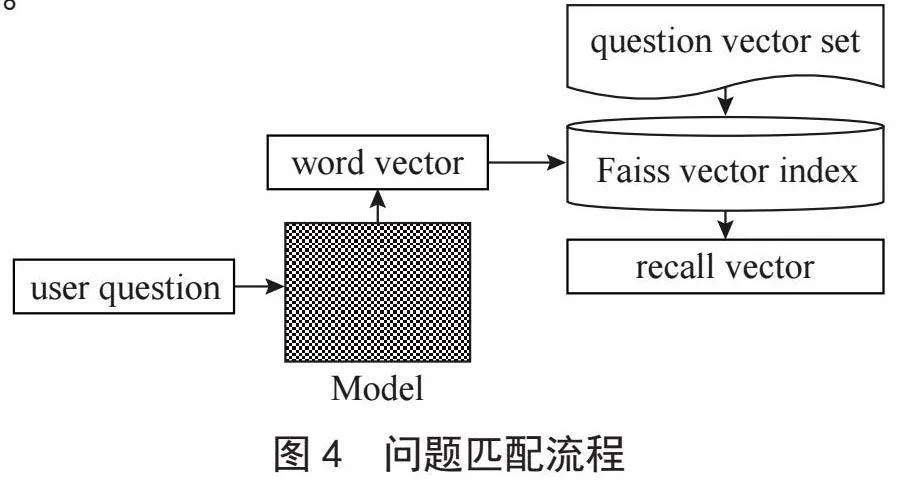
当学习者提出问题时,首先通过torch.load()方法从磁盘中加载DualModel模型以及Features问题特征向量集。使用Faiss创建IndexFlatL2索引,将Features问题特征向量集插入到索引中。然后将学习者的问题进行分词、编码经过DualModel模型转为问题特征向量。使用index.search()方法找出与学习者所提问题最相似的问题向量,返回其问题编号。最后根据问题编号从A_list.csv文件中寻找问题编号对应的答案,返回答案给学习者,问题匹配流程如图4所示。
2.5 模型的部署与应用
自动问答系统分为客户端和服务器端两个部分。客户端为基于Android平台开发的用户问答APP,服务器端为使用Flask框架部署的“双塔神经网络模型”。APP使用OkHttp3第三方库处理网络请求,当用户提问时,将用户问题封装到JSONObject对象中再序列化为字符串,通过Request对象以POST的方式发送给服务器。服务器的Flask执行@app.route路由定义的post()方法,从请求中解析出用户的问题,发送给模型,并将模型返回的问题答案使用json.dumps()方法转为JSON格式的字符串发送给APP。APP最终从response中解析出问题的答案,显示到用户界面。APP运行界面如图5所示。
3 结 论
本文探讨了基于BERT模型设计在线课程问答系统的主要思路和关键技术,所实现的系统具有如下优点:1)个性化提问。学习者输入的问题不仅仅是已有数据集中的问答对,对于同一个问题不同的描述只要表达的语义相同,那么通过模型转换得到的特征向量就具有较高的相似度,从而为学习者返回最合适的答案。2)问题回答的有效性。问答系统中用于训练的数据集均为在线课程中学习者所提的真实问题,确保问题的真实性和答案的有效性。
系统同样存在一些不足:1)客户端界面不是很友好。2)问题回答的准确率还有上升的空间。下一步将扩大训练数据集,尝试多种模型的融合,进一步提升问答系统的性能,同时改善用户界面,提升用户体验,更好的支持在线课程的学习。
参考文献:
[1] 葛岩,崔璐,郭超.在线学习需求分析及优化策略研究 [J].高等工程教育研究,2023(6):125-131.
[2] 倪红军,周俊雯,叶苗.课程思政背景下移动Web综合开发课程建设的思考与探索[J].北京联合大学学报,2022,36(2):35-39.
[3] 赵志立,陆福相.以学生为中心的个性化在线教育模式探讨 [J].软件导刊,2023,22(6):312-316.
[4] 闫悦,郭晓然,王铁君.问答系统研究综述 [J].计算机系统应用,2023,32(8):1-18.
[5] 王娜,李杰.基于AHP-熵权法的FAQ问答系统用户满意度评价研究——以高校图书馆问答型机器人为例 [J].情报科学,2023,41(9):164-172.
[6] 杨喆,许甜,勒哲.基于知识图谱的羊群疾病问答系统的构建与实现 [J].华中农业大学学报,2023,42(3):63-70.
[7] 柴梦杰.基于LSTM神经网络在线个性化问题解答的设计研究 [D].上海:上海师范大学,2019.
[8] 何传鹏,黄勃,周科亮.基于BERT与Loc-Attention的文本情感分析模型 [J].传感器与微系统,2023,42(12):146-150.
[9] DEVLIN J,CHANG M W,LEE K,et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [J/OL].arXiv:1810.04805 [cs.CL].[2024-02-28].https://arxiv.org/abs/1810.04805.
[10] 戴琳琳,阎志远,景辉.Insightface结合Faiss的高并发人脸识别技术研究 [J].铁路计算机应用,2020,29(10):16-20.
作者简介:周巧扣(1982—),男,汉族,江苏泰州人,副教授,硕士,研究方向:机器学习、移动应用开发。