
摘" 要:国产游戏在海外愈发受年轻玩家所喜爱,蕴含在游戏中的中华优秀传统文化亦随着国产游戏的火爆而“出海”。文章以海外“原神”游戏玩家在YouTube社交媒体平台中发表的包含中华优秀传统文化元素的游戏内容的评论为研究对象,通过Python爬虫程序获取在线评论数据,对爬取到的数据进行预处理,利用规范化的评论数据构建Word2Vec模型,并画出关键词词云图。最后,使用大语言模型对评论文本数据进行情感分析,以可视化的方式呈现研究结果,从而帮助游戏开发者了解海外玩家对游戏中不同中华优秀传统文化元素的喜爱程度,为后续游戏中中华优秀传统文化内容的更新提供数据支持,进而推动中华优秀传统文化更好地“出海”。
关键词:情感分析;Python爬虫;大语言模型;中华优秀传统文化
中图分类号:TP391" 文献标识码:A" 文章编号:2096-4706(2024)22-0111-06
Preference Analysis of Overseas Game Players for Chinese Cultural Elements Based on Text Mining
—Taking “Genshin Impact” as an Example
Abstract: Domestic games are becoming increasingly popular among young players overseas, and the Chinese excellent traditional culture embedded in games is also “going global” with the popularity of domestic games. This paper takes the comments on the game content of Chinese excellent traditional cultural elements published by overseas “Genshin Impact” game players on the YouTube social media platform as the research object, obtains online comment data through the Python crawler program, preprocesses the scraping data, constructs the Word2Vec model by using the standardized comment data, and draws the keyword word cloud diagram. Finally, the Large Language Model is used to conduct sentiment analysis on the comment text data, presenting the research results in a visual way, so as to help game developers understand the degree of overseas players love for different Chinese excellent traditional cultural elements in the game. It provides data support for the update of Chinese excellent traditional culture content in subsequent games, and then promotes the Chinese excellent traditional culture to “go global” better.
Keywords: sentiment analysis; Python crawler; Large Language Model; Chinese excellent traditional culture
0" 引" 言
习近平总书记在中央政治局第三十次集体学习时强调:“要更好推动中华优秀传统文化走出去,以文载道、以文传声、以文化人,向世界阐释推介更多具有中国特色、体现中国精神、蕴藏中国智慧的优秀文化。”近年来,随着我国文化软实力不断提升,以及移动端娱乐设备的迅猛发展,国产游戏越来越成为中华优秀传统文化走向世界的重要载体,一批批国产游戏成功“出海”[1],成为中华优秀传统文化重要的传播者与弘扬者,《原神》游戏便是主要代表之一。
《原神》在游戏内容中融入了众多如“中国风音乐”“中国景色风貌”“中华饮食文化”“中华传统服饰”“中国非物质文化遗产”“中国式价值观”等中华优秀传统文化元素[2-3]。不少海外玩家将自己对游戏中的中华优秀文化元素的看法以评论的形式发表至视频平台、社交媒体或游戏论坛。他们通过评论表达对不同中华文化元素的喜爱程度与接受程度。发现最易为外国玩家所接受、认同、喜爱且能得到正向情绪反馈的中华优秀传统文化元素,并加大运用此类文化元素,有利于加强外国用户对中华优秀传统文化的认同感、接受度与喜爱度。同时,改进、完善受欢迎程度较低的文化元素,有利于中华优秀传统文化的全面创新性“出海”,增强各类中华文化的国际影响力,提升国家文化软实力。因此,对海外玩家的在线评论进行文本挖掘和情感分析具有重要意义。由于《原神》官方YouTube视频平台发布了大量游戏视频,且该平台拥有庞大的用户基数,评论数量多且与游戏中文化元素的关联程度高,具有重要研究价值。因此,本文以YouTube视频平台作为数据源,通过Python爬虫程序获取YouTube视频平台中的在线评论,并对评论进行文本挖掘和情感分析,从中分析得出海外玩家最喜爱的中华文化元素。
1" 研究设计
文章采用的研究方法及步骤如下:
1)利用Python爬虫程序采集YouTube视频平台中《原神》官方发布的体现不同中华文化元素的视频下方的海外玩家在线评论数据,并进行数据清洗、去分词、去停用词、词性还原等预处理,以得到较为规范的评论数据,随后将评论数据以WordCloud词云图可视化呈现。
2)利用规范化的评论数据构建Word2Vec模型,利用Word2Vec模型提炼中华优秀传统文化元素关键词的关联词,实现文本特征分析。
3)利用大语言模型对在线评论文本数据进行情感分析,得出情感倾向、情感分值等数据,对分析得出的情感数据进行统计,得出正面、中性、负面的情感倾向比例,最终给出情感分值直方图、情感倾向比例可视化的评价结果。
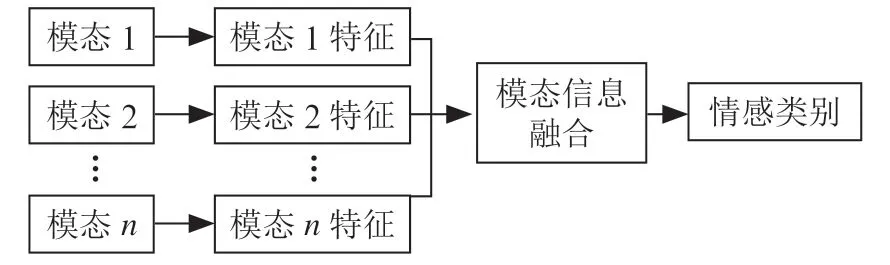
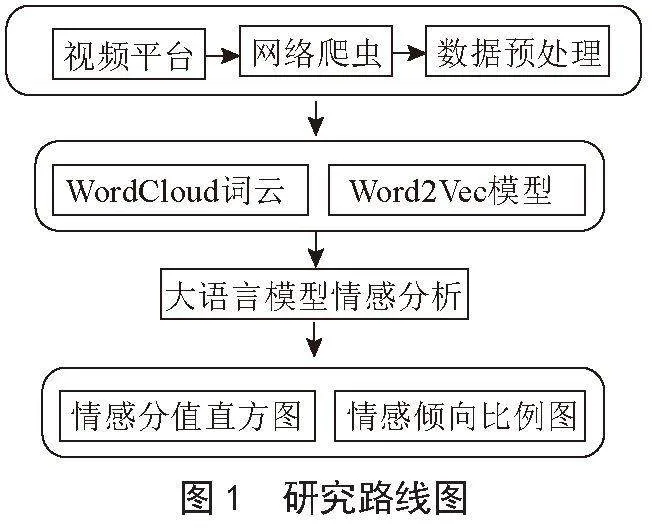
具体实现流程如图1所示。
2" 相关理论
文本数据挖掘,即利用先进的计算机处理技术,旨在从庞大的文本数据中发掘出有价值的信息与知识。而在文本数据挖掘的众多细分领域中,情感分析具有重要地位。情感分析,通常又被称为观点挖掘,主要借助自然语言处理、文本挖掘以及计算机语言学等技术手段,对蕴含情感色彩的主观性文本进行深入分析、精细处理、系统归纳以及逻辑推理,最终准确地理解和把握文本数据中蕴含的情感倾向与内涵。现有的情感分析方法主要分为两类:基于情感词典的情感分析法[4-6]和基于机器学习或深度学习[7-8]模型的情感分析法。随着大语言模型的爆火,利用大语言模型进行文本情感分析成为新的趋势[9-10]。
2.1" NLTK库
NLTK(Natural Language Toolkit)是Python中用于自然语言处理地第三方库,由史蒂文·伯德(Steven Bird)和爱德华·罗斯(Edward Loper)在2001年创建。NLTK提供了许多用于文本处理分析和语言学研究的工具资源。它包括了各种文本处理任务所需的模块,如分词、词性标注、去除停用词、语法分析、语义分析等。同时,NLTK也提供了丰富的语料库、数据集和预训练模型,涵盖了不同语言、不同主题和不同领域。本文使用NLTK库所提供的分词器、停用词列表和词性还原器,进行分词、去停用词、词性还原等数据预处理操作。
2.2" Word2Vec模型
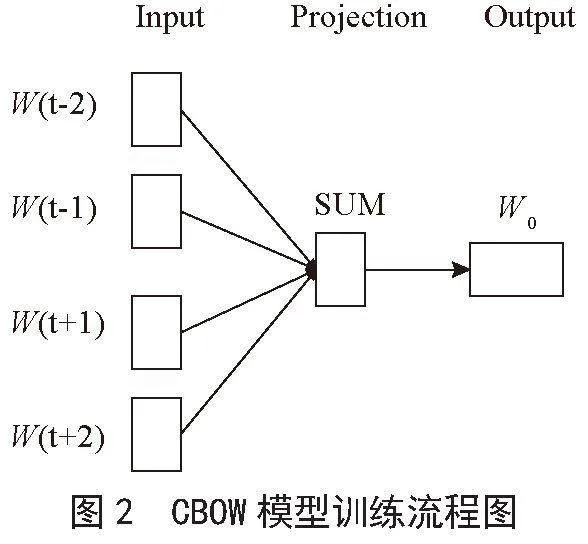
Word2Vec模型是由Google开源的一种用于词向量计算的工具,同时也是一种语言算法模型。它的主要目标是通过学习文本的语义知识,将每个词表示为一个向量,这些向量能够捕获词与词之间的关系。Word2Vec模型的核心是一个简单的神经网络,通常包含输入层、隐藏层、输出层。Word2Vec模型主要有两种训练模型,分别是Skip-gram和CBOW。Skip-gram模型从目标单词预测上下文单词,而CBOW模型从上下文单词的平均值中预测目标单词。一般来说,CBOW模型更加适合小型语料库,且训练速度较快、时间较短,Skip-gram模型更适合于大型语料库,能够构造更为精准的词向量。本文采用CBOW模型进行词向量训练,CBOW模型训练过程如图2所示。关于Word2Vec模型的参数分析,谢庆恒等研究者分析了预训练语料、词向量预训练参数以及分类模型参数对模型分类效果的影响[11]。结果表明,限定域预料效果好于广域预料;预训练参数中向量维度越大,效果越好,窗口大小存在最优值,分类算法影响不大;分类模型参数中学习率、激活函数、批次大小对模型分类效果影响较大,训练轮次相对较小。
2.3" 文心大模型
文章采用文心大模型,针对海外《原神》游戏玩家对蕴含中华优秀传统文化的游戏内容的相关评论进行情感分析。文心大模型是百度在自然语言处理领域推出的一系列大规模预训练语言模型。文心大模型以Transformer架构为基础,进行了海量的无监督学习,先利用大规模未标记数据进行预训练,再利用少量带标签数据进行微调,使其对自然语言具有深入理解。文心大模型能够捕捉到文本中的情感词汇、情感短语以及情感倾向,从而对文本的情感进行准确的分类和判断。
3" 实验分析
海外《原神》游戏玩家的在线评论体现了海外玩家对中华优秀传统文化元素的印象、感受、喜爱程度,具有重要的研究价值。文章选取YouTube视频平台作为实验数据源,将《原神》官方发布的各类游戏视频分为角色形象、饮食文化、文化遗产、地域风貌、国风音乐、文化故事六大类别,每个类别分别爬取1 000条评论,共6 000条评论作为实验原始数据。
3.1" 数据采集
文章利用Python语言编写网络爬虫程序获取《原神》官方视频评论。通过引入Python提供的Requests、lxml等第三方库向服务器发送请求,利用JSON、Pandas等第三方库解析响应,最终成功获得6 000条在线评论文本数据。同时,为了充分了解海外《原神》游戏玩家对中华优秀文化元素的情感倾向,文章还获取了每条评论的发布时间、点赞数、视频播放数等相关信息。最后将爬取到的6 000条原始数据以.xlsx格式保存至本地,为后续分析提供基础数据支撑。
3.2" 数据预处理
因多数网络评论中含有表情符号、特殊字符、网络俚语等难以被程序所解析的富文本内容,所以进行情感分析前需要对获取到的原始评论文本数据进行数据清洗、分词、去除停用词、词性还原等一系列操作,以得到规范化评论数据,提高数据的质量和准确性,实现精准的文本特征提取和情感分析。对于富文本内容,文章通过Python正则表达式对原始数据进行清洗。对于原始评论数据中的表情符号、标点符号等内容,使用Python正则表达式的re.sub()函数匹配去除。对于重复冗余的原始评论数据,使用drop_duplicates()函数进行删除。对于长度过短且无实际意义的原始评论数据,通过限定评论长度大于等于10字符进行初步筛选。最后使用lower()和strip()函数将所有评论数据转为小写格式,并去除评论字符串两侧的空格,得到清洗后规范化的评论文本数据。
对于小部分非英语的海外《原神》玩家在线评论,本文采用百度开放平台API将非英语评论文本转化为英语进行统一分析。随后,文章采用NLTK第三方库对评论数据进行分词操作。NLTK库所提供的分词器默认按照空格和标点符号对英文文本进行分词。但部分与游戏内容相关的名词通常由多个英文单词组合而成。为提高分词准确性,文章向NLTK库所提供的分词器中加入(zhong, li),(lantern, rite),(genshin, impact)等与游戏内容相关的自定义词组,并将各自定义词组词性定义为名词NN。进行分词操作时,首先调用NLTK库默认分词器的word_tokenize()函数实现初步分词,随后再调用自定义分词器的tokenize()函数实现基于自定义词组的精准分词。在线评论数据中通常含有“I”“it”“a”等出现频次较高却无实际意义的词语,这些词语对于评论文本数据的主题或含义贡献很小,甚至会对评论文本数据特征提取和情感分析造成干扰。因此,文章通过NLTK第三方资源库对用户评论数据进行去除停用词处理。最后,文章使用NLTK库中pos_tag()函数将去除停用词后的在线评论文本数据逐个单词标注词性。词性标注后,使用lemmatize()函数将各个单词还原为原型形式。数据预处理后得到5 826条有效评论。
3.3" 词云图分析
词云图,也叫“文字云”,是通过图片方式展现文本词语特征的一种主要形式。通过文字、色彩、图形的搭配,产生强烈的视觉冲击效果。在一篇文本中出现频率越高的词语,在词云图中显示的字体就越大越突出。词云图中体现的关键词就是文本中的高频词。词云图可以过滤掉大量不重要的文本信息,使图片浏览者迅速了解文本数据的中心内容。本文对海外《原神》玩家的在线评论文本数据进行分词、去除停用词等操作后,使用Python中的WordCloud库绘制出海外《原神》玩家在线评论的词云图,从而直观地展示出海外玩家对《原神》游戏及其中所蕴含的中华文化元素的情感态度,如图3所示。
首先,图中巨大的“love”“game”“genshin”等词汇展现了海外玩家对于原神游戏的喜爱,“beautiful”“liyue”等词体现了海外玩家对原神游戏中璃月城(《原神》游戏中以古代中国为原型设计的城市国家)的积极情感。“character”“music”等词则体现了海外玩家对国风音乐和国风角色形象的喜爱之情。总的来说,《原神》游戏在海外获得许多积极的反馈,更多的海外用户通过游戏了解中国文化,游戏也让中国文化更易为海外玩家接受。
3.4" Word2Vec关联词分析
文章利用Python中的Gensim第三方库训练Word2Vec模型。Gensim库中的Word2Vec模型默认采用CBOW算法,刚好与在线评论文本数长度较短的特点符合。训练模型时设置vector_size=100,表示词向量维度为100;window=4,表示当前词前后4个词语作为当前词的上下文;epochs=5 000,表示迭代5 000次;negative=10,表示负采样为10。
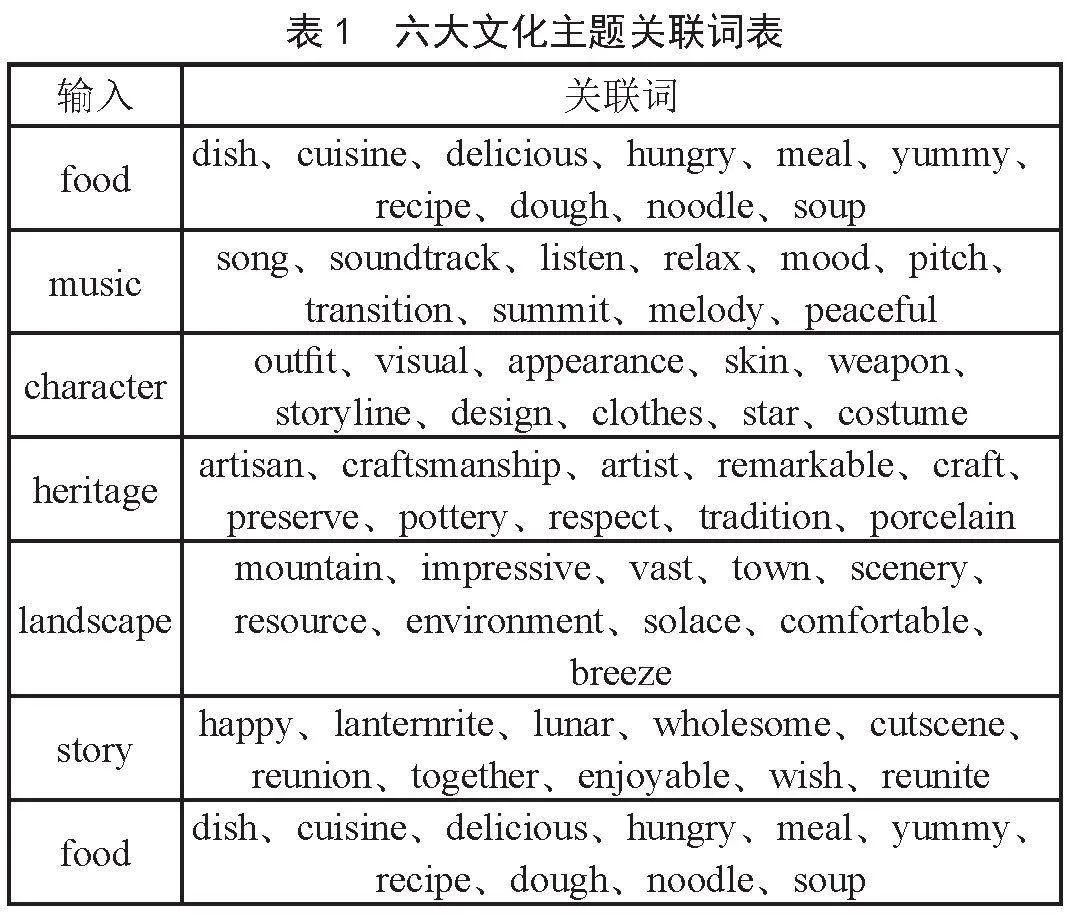
文章对角色形象类、饮食文化类、文化遗产类、文化故事类、地域风貌类、国风音乐类六大文化元素通过Word2Vec模型得出的关联词进行分析。通过深入分析这些关联词可以进一步理解海外玩家对不同文化元素的情感倾向。表1为通过训练后的Word2Vec模型得到的六大文化主题关联词。
“food”一词的关联词为“dish、cuisine”等,同时与“yummy、delicious”等词夸赞美食味道的形容词共同体现了海外《原神》玩家对中华美食的积极情感倾向。“soup、noodle”等词体现海外玩家对中国食物中的汤和面条有一定的偏好。
与“music”一词高度关联的词语有“mood、relax、peaceful”等,由此可见国风音乐带给多数海外玩家宁静、放松、悠闲的心情。同时“summit、transition、melody”等词体现了海外玩家注重国风音乐的编曲、旋律、节奏等内容。说明游戏中的背景音乐质量与游戏内容质量同样会被玩家所关注,游戏音乐质量不可被忽视。
与“character”角色相关的词语有“outfit、appearance、design、skin、clothes”等。这说明海外《原神》玩家非常重视游戏中的角色形象设计。游戏开发者应不断保持并提高角色形象设计质量以满足海外玩家的游玩偏好。同时,也需注重游戏角色的背景故事(“storyline”)开发,只有富有深度的角色才能真正吸引海外玩家。
“craftmanship、artisan、artist”等词与“heritage”文化遗产一词高度关联。说明海外玩家通过《原神》游戏中的文化遗产文化元素深刻,感受到了我国非物质文化遗产的艺术性与珍贵性。同时,海外玩家也被非遗传人的匠人精神所感动。“remarkable、respect”等词体现了他们对文化遗产元素的正向情感倾向。
“landscape”地域风貌中,“mountain、scenery”等词说明海外玩家同时也偏向于山川的景色地貌。“impressive、comfortable、solace”等词体现了海外玩家对中国地域风貌的真切感受:令人印象深刻、感到舒适。
《原神》游戏中所展现的中华文化故事多数与春节(游戏中称为“海灯节”)相关,故“story”关键词的关联词为“happy、reunion、reunite、together”等与春节团圆祥和快乐氛围相关的词语。这说明海外《原神》玩家纷纷被游戏中体现的和睦的春节氛围打动,“enjoyable”一词说明海外《原神》玩家在游玩与春节文化相关的文化内容时乐在其中,感到无比享受。
3.5" 情感分析
本文利用百度文心大模型平台所提供的Python API调用ERNIE-Speed大模型进行情感分析。首先,设置Prompt模板,使文心大模型能够对在线评论文本数据进行情感分析得出情感倾向和情感分值。随后,将设置好的Prompt模板与需要进行情感分析的评论文本数据放入请求体中,利用Requests库发送http请求,用JSON、Requests等库解析响应,获取情感分析结果;最后将情感分析结果以JSON格式存至本地文件。相关情感分析结果如图4至图8所示。
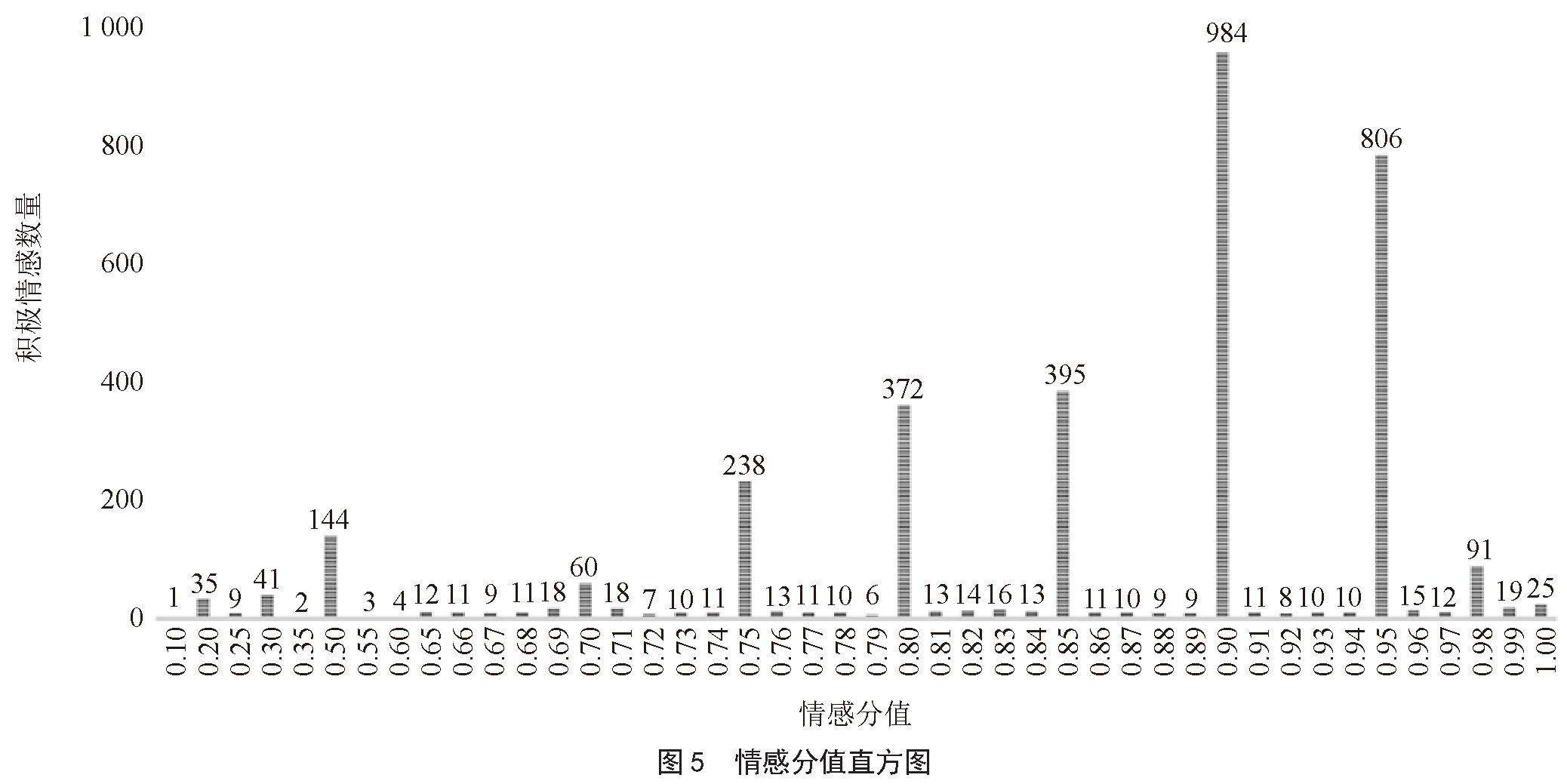
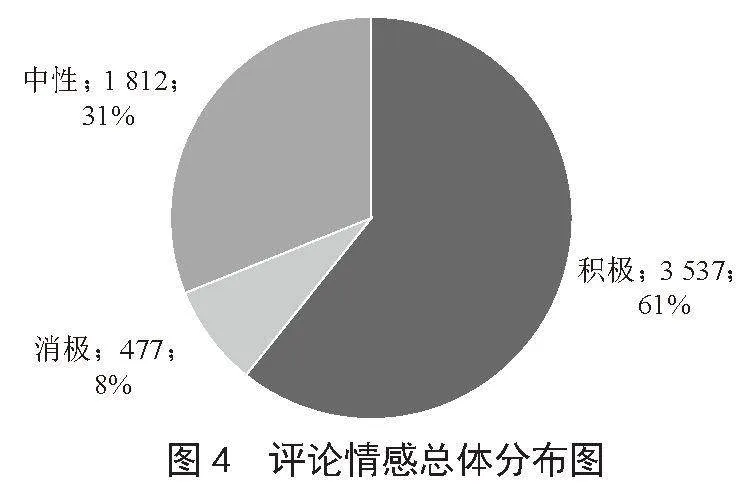
由图4和图5可知,5 823条有效评论中,积极评论数为3 537条,占总体评论的61%;中性评论数为1 812条,占总体评论31%;消极评论数为477条,占总体评论8%。由此可见,海外玩家对于《原神》游戏整体呈正面情感倾向,且大部分正面评论情感分值集中于0.90和0.95,积极情感倾向强烈,说明《原神》游戏中的各类中华优秀传统文化元素得到了海外玩家的接受和喜爱。中性情感评论占比为31%,其原因可能是部分评论仅是对视频内容和游戏内容的简单描述,并未包含明显的情感倾向。虽然存在小部分消极评论,但仍可从此类负面评论中挖掘出客观且可采纳的建议,用于改进《原神》游戏中与中华优秀传统文化元素相关的游戏内容,提高游戏质量,使中华优秀传统文化得到更多海外玩家的喜爱。总而言之,国外社交媒体对于《原神》游戏中中华优秀传统文化内容的整体认可度较高,各类中华优秀传统文化元素均受到海外玩家的喜爱。
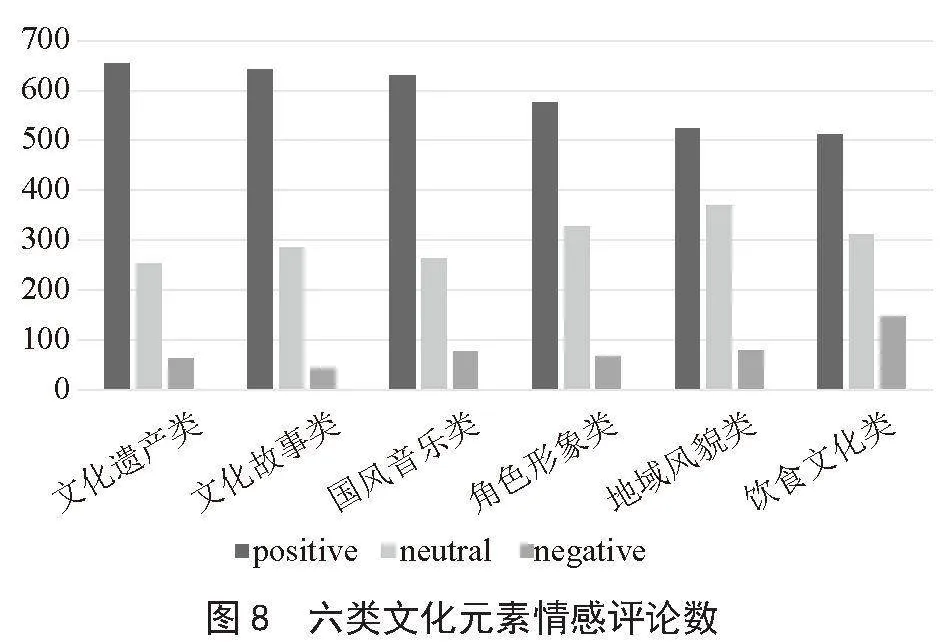
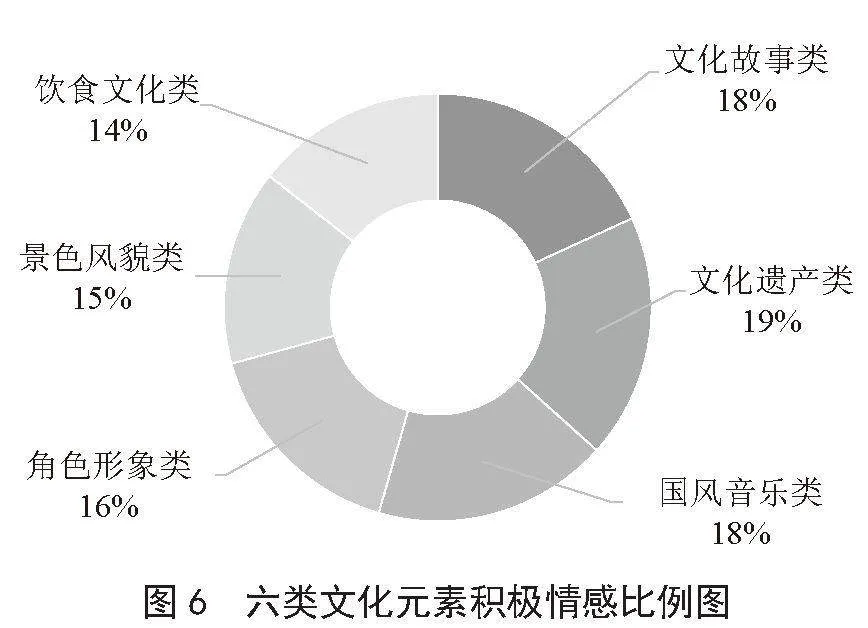
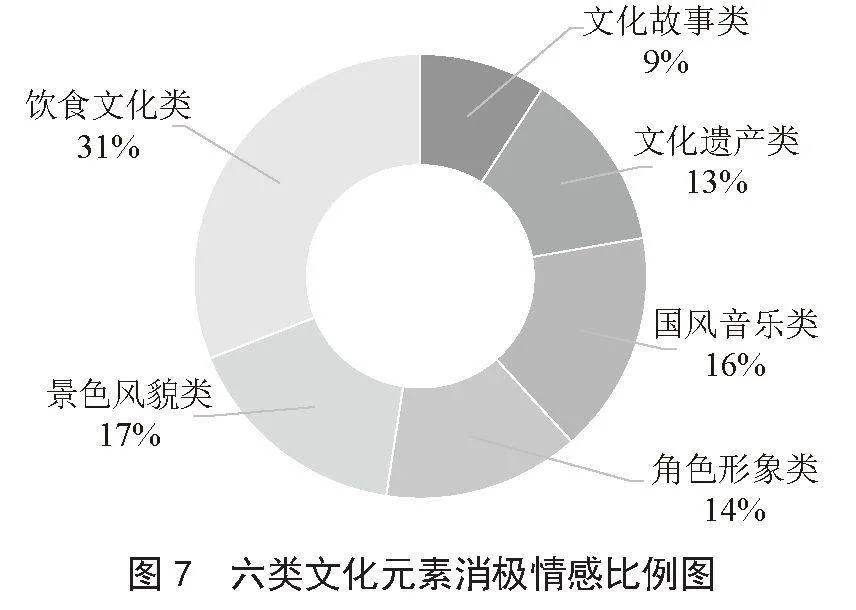
图6至图8展示了六类文化元素的情感比例分布以及情感评论数,从图中信息可以得知,文化遗产类元素的评论积极情感倾向最明显,占比为19%,评论数量为654条;饮食文化类的负面情感评论比例较高,占比为31%,评论数量为148条。由此可见,在六大类文化元素中,海外玩家更偏好于文化遗产类,而《原神》游戏中饮食文化类游戏内容仍有改进空间,以提升海外玩家对中华饮食文化的喜爱程度。
4" 结" 论
随着信息技术的飞速发展,其在游戏产业的应用也日益广泛。《原神》作为一款融合了中华优秀传统文化元素的国产游戏,在海外市场取得了显著的成功。在线评论中蕴含了玩家的情感和观点,因此,对这些评论数据的深入挖掘和分析,对于提升游戏质量、满足玩家需求以及推动中华优秀传统文化更好“出海”具有重要意义。文章通过Python爬虫技术获取了《原神》游戏相关的在线评论数据并进行数据预处理。随后采用WordCloud词云图、Word2Vec模型等技术对在线评论文本进行了数据挖掘和情感分析。最后以图表形式展现海外玩家对游戏中中华优秀传统文化元素的关注重点和喜爱程度。
研究结果表明,海外玩家对《原神》中的文化遗产类元素表现出了极高的兴趣,尤其是金银细工、内画、蛋雕、麦秆画等非遗文化内容。此外,文化故事、国风音乐、角色形象、地域风貌等文化元素也受到了不同程度的关注与喜爱。这一结论不仅为《原神》游戏的后续发展提供了有益参考,也为国产游戏在传承和弘扬中华优秀传统文化方面提供了重要的启示。在评价《原神》游戏本身时,文章认为其在融合中华优秀传统文化元素方面表现出色,这些元素不仅丰富了游戏内容,也为玩家带来了独特的游戏体验。游戏在画面、音效、剧情等方面也同样出彩,赢得了广大玩家的喜爱和认可。
综上所述,对《原神》海外玩家的在线评论数据进行数据挖掘与情感分析,可使我们更好地了解海外玩家的游戏需求和文化偏好,分析结果可为国产游戏的发展提供决策依据。同时,《原神》游戏的成功也向我们展示了国产游戏对推动中华优秀传统走向世界的重要作用。
参考文献:
[1] 郭毅,董鸣柯.国产游戏对外传播中华文化的现状、困境与对策 [J].出版发行研究,2023(1):67-73+66.
[2] 张妍,李金昊,赵宇翔.文旅融合背景下国产游戏创新与推广的模式探索:基于《原神》的案例分析 [J].图书情报知识,2021,38(5):107-118.
[3] 黄项楚.国产游戏的文化创新模式探索——以《原神》为例 [J].大众标准化,2021(22):156-159.
[4] 张公让,鲍超,王晓玉,等.基于评论数据的文本语义挖掘与情感分析 [J].情报科学,2021,39(5):53-61.
[5] 白刚.基于语义与情感词典的微博评论情感分析方法 [J].现代计算机,2021,27(30):55-58+63.
[6] 马晓慧,贾君枝,周湘贞,等.一种基于语义相似性的情感分类方法 [J].计算机科学,2020,47(11):275-279.
[7] 白晓雷,霍瑞雪.融合微博语言特征的CNN反讽文本识别模型研究 [J].通信技术,2021,54(5):1126-1130.
[8] 范昊,李鹏飞.基于FastText字向量与双向GRU循环神经网络的短文本情感分析研究——以微博评论文本为例 [J].情报科学,2021,39(4):15-22.
[9] 姜大帅.基于BERT和多任务学习的网络舆情情感分析系统 [D].上海:华东师范大学,2023.
[10] 张亚洲,王梦遥,戎璐,等.ChatGPT可否充当情感专家?——调查其在情感与隐喻分析的潜力 [J].北京大学学报:自然科学版,2024,60(1):43-52.
[11] 谢庆恒.关于Word2Vec文本分类效果若干影响因素的分析 [J].现代信息科技,2024,8(1):125-129.