


摘" 要:文章挖掘法律文本中的实体和关系,构建法律知识图谱,为实现智能判案提供支持,完善法律知识图谱的构建方法。应用基于LexNLP的自然语言处理方法,分析法律文本,以句子为单位进行词性分析,标注出名词且为主语或宾语时作为实体,动词且为谓语时标注为关系。在这一基础上,将同一个句子中的实体和关系按照lt;实体1,关系,实体2gt;进行排列组合,生成不重复的知识三元组,以生成高质量的法律知识图谱。提出了一种基于词性和语序分析的法律知识图谱自动构建方法,并基于美国Caselaw Access Project项目所含的法律判例为原始数据,并对生成三元组进行质量评估,最后生成了关于法律的知识图谱。
关键词:知识图谱构建;实体识别;关系抽取;自然语言处理
中图分类号:TP391.1" " 文献标识码:A" " 文章编号:2096-4706(2024)22-0085-07
Automatic Construction Method of Legal Knowledge Graph Based on Part of Speech and Word Order Analysis
Abstract: The paper constructed a legal Knowledge Graph through mining the entities and their relationships in the legal text, aiming to facilitate intelligent judgment and enhance the methodology of legal Knowledge Graph construction. This paper employs Natural Language Processing techniques rooted in LexNLP, analyzes the legal texts, and conducts sentence-level part-of-speech analysis, wherein nouns functioning as subjects or objects are labeled as entities, while verbs serving as predicates are labeled as relationships. Based on this framework, the entities and relationships within each sentence are permuted and combined according to the format lt;entity 1, relationship, entity 2gt;, resulting in the generation of non-repetitive knowledge triplets so as to generate a high-caliber legal knowledge graph. The paper proposes an automated construction approach for the legal Knowledge Graph based on part-of-speech and word order analyses, takes the legal precedents contained in the Caselaw Access Project in the US as the raw data, and assesses the quality of the generated triplets and presents a legal Knowledge Graph.
Keywords: construction of Knowledge Graph; entity recognition; relation extraction; Natural Language Processing
0" 引" 言
“智慧法院”的概念源于中国国务院发布的新一代人工智能发展规划[1]。它代表了法院管理的一种新方法,利用现代人工智能技术以异常丰富的信息方式执行自动和智能的司法任务。智慧法院是依托现代人工智能技术,以高度信息化方式,实现自动化、智能化地司法审判和诉讼服务等司法工作的人民法院的新型管理形态[2]。要实现这一目标,对司法工作者经验知识的智能应用是关键。知识图谱的提出,为组织和利用这些知识提供了可能。知识图谱是一种由众多“实体-关系-实体”有向实体关系三元组组成的知识网络[3],这种结构可以较为有效简洁地表示现实世界中某一领域的知识关系。同时,三元组的数据结构又为实体和实体、实体和关系之间的知识的传递性创造了条件,使得知识推理成为可能。这种结构可以使得原本静态的知识动态化,从而可用于辅助实现智能化的生产经营工作。知识图谱在问答系统[4]、推荐系统[5]、金融风险控制[6]等多个领域都有应用。它们也为法律领域提供了相当大的潜力。然而,由于法律领域的高度专业化和复杂性,知识图谱在这一背景下的应用面临挑战[7]。法律案件文书包含了丰富的综合司法工作经验。如果能将这些文献组织成一个法律判例知识图谱,通过研究其推理机制,将对智能审判系统的实现起到重要的推动作用。因此,法律判例知识图谱的构建已逐渐成为信息科学和数据科学领域的研究热点之一。
1" 国内外知识图谱研究热点分析
目前,对法律知识图谱的研究相对较少[8]。然而,法律先例知识图谱的基本结构与一般知识图谱并没有显著不同。关键区别在于实体和关系的内容,这是特定于法律领域的。研究中知识图谱的构建主要集中在三个主要方面:实体提取、知识图谱构建以及存储和可视化。
1.1" 知识图谱的知识抽取研究
知识抽取是知识图谱构建的核心内容,其目标是从结构化或非结构化文本中抽取实体、属性和实体之间的关系。Fundel等[9]开发了一种基于依赖项分析树的关系抽取工具RelEx。Lee等[10]提出了一种基于NLTK的概念图自动构建方法,利用该方法可对实体和关系进行自动识别和提取。Augenstein等[11]提出了一种基于CoreNLP的关系提取方法,该方法使用词性标签对句子中的单词进行标记,再根据词性对实体及关系进行提取。Rocha等[12]使用模式匹配、词性标注和基于词汇的规则来实现命名实体识别。Partalidou等[13]使用spaCy设计并实现开源希腊语词性标注和实体识别器。Bajwa等[14]提出了一种基于词性标记、形态分析和句法分析的半监督分类算法,该算法可用于从软件协议中识别实体及其关系。Tang等[15]设计了一种基于spaCy和Stanford OpenIE的法律实体和关系提取算法,该算法可用于从法律文本集合中提取常见的实体和关系。Xiao等[16]提出了一种基于双边长短期记忆条件随机场的深度学习模型,该模型可用于提取气象模拟知识。周琦等[17]利用条件随机场训练分词模型对语句进行分词和词性标注,从而提取语句中的实体和关系。李艳燕等[18]提出在本体的知识关系上,应用面向教育领域数据源的众包标注和学科知识自动获取功能,对数据源进行知识点及其关系的识别与抽取。针对非结构化文本,袁琦等[19]提出一种条件随机场与症状字典相结合的症状命名实体识别模型,该模型通过症状实体位置和词性作为依据进行实体的识别。洪文兴等[20]通过分析语法结构中的主谓关系等进行实体和关系的识别,以构建“实体-关系-实体”三元组。
1.2" 领域知识图谱的构建研究
知识图谱的构建,指的是将知识抽取得到的三元组数据,以自动化或半自动化的方式提取出知识要素,并将其存入知识库的数据层和模式层,以形成知识图谱的过程[21]。McCusker等[22]利用药物、蛋白质和疾病之间的相互关系构建了医药领域知识图谱。Kim等[23]借助bert模型自动构建了COVID-19相关的知识图谱,并将其封装成OpenIE系统,该系统可以从大量文档中获取知识,自动添加到知识图谱中,可以快速解决大量数据应用更新的问题。Franco等[24]提出了一种基于概念分布式表示的概念间关系加权方法,以此构建了一种跨语言抄袭检测知识图谱,并利用“西班牙语-英语”和“德语-英语”剽窃检测的结果进行验证。王飞等[25]提出了一种基于Stanford NLP的关系抽取方法,该方法可以从文本数据中抽取出需要的实体和关系,形成知识图谱。李刚等[26]利用LTP模型根据句法分析进行实体关系抽取,以此构建面向图博档(图书馆、博物馆、档案馆的简称)数字化服务融合的知识图谱。
1.3" 知识图谱的存储及可视化研究
目前,有多种方法可以将规范化的三元组绘制为知识图谱,图数据库自带的编程语言,例如Neo4j的Cypher语言,通用或者专用的知识图谱绘制软件工具ECharts[27]、CiteSpace[28]、Ucinet[29]等。
CiteSpace主要应用于对特定领域文献进行引文分析,探寻该领域演化路径及知识拐点,通过绘制知识图谱反映学科演变历程及发展[30]。阚越等[31]通过对草原旅游相关论文分析,借助CiteSpace软件绘制关键词共现图谱、突现图、关键词聚类网络图谱和关键词聚类时线图谱四类知识图谱,对国内外草原旅游进行全面系统量化和可视化。陈晓玲等[32]以Web of Science数据库中东北三省的文献为数据源,使用CiteSpace软件绘制机构合作、关键词共词和学科共现的科学知识图谱,分析2012—2016年东北三省的研究热点和学科趋势。ECharts依托开源可视化库和矢量图形库提供个性化的可视化图谱[27]。胡欢等[33]等使用重庆市扶贫领域内数据,构建半自动化生成知识图谱的工具,并采用ECharts组件实现力导向布局图,用于描述知识图谱中帮扶人与贫困户之间的关联情况。Neo4j图数据库具有高性能、可扩展、支持事物等特点,已被广泛应用于知识图谱的可视化。Tan等[34]为解决多源复杂的交通数据整合问题,构建了交通领域的知识图谱,并使用图数据库Neo4j存储和展示知识图谱数据。刘政昊等[35]以股票数据为种子知识图谱,将非结构化文本利用FinBert进行实体抽取和关系分类后导入Neo4j,进行金融证券知识图谱可视化分析研究,为投资者组合交易决策提供分析思路和数据支持。胡浩等[36]分析了奶牛产量和基因的关系,以PubMed生物医学文献库为基础,使用Neo4j图数据库进行数据存储,构建了奶牛产奶量性状数据知识库的可视化平台。李艳东等[37]将PageRank算法运用于计算审计领域知识图谱中,并利用Neo4j数据库的可视化能力将审计疑点进行直观呈现。
综上可知,知识抽取是知识图谱构建的基础方法,而可视化只是用于显示构建好的知识图谱。因此知识抽取是知识图谱构建的关键。而知识抽取的方式也就决定了知识图谱的构建方式。目前,主要有自动化和半自动化两种方法。自动化方法虽然效率高,但准确度并不高。而半自动化方法,虽然准确度较高,但是效率又较低。现有研究都在通过各种手段去克服各自的缺点,来实现准确高效的知识图谱构建方法。本文认为知识图谱是一个庞大复杂的知识网络,通过半自动化方式去标注构建,在人力有限的情况下,是不太现实的。为此,本文依然采用自动化方式来构建知识图谱。考虑到法律文本规范化程度较高,因此本文尝试从词性和语序分析的角度来实现知识抽取,以此来构建相对准确的法律知识图谱。
2" "基于词性和语序分析的三元组抽取算法
2.1" 基本原理
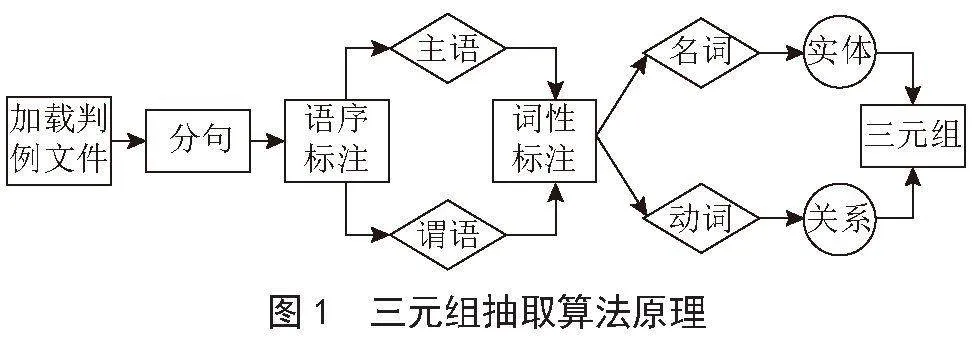
lt;实体-关系-实体gt;三元组是知识图谱的基本组成单位,其描述了某一领域内两个实体之间的知识关系。在这一结构下,不同实体之间就存在了关系上的传导性,这种传导是知识图谱得以进行知识推理的基础。因此三元组的确定是知识图谱构建的重要工作。而从目前的发展状况来看,实体的识别已基本实现,但实体和实体之间关系的准确界定则依然是悬而未决的问题。而本文认为从词性和语序角度去确定实体及实体间的关系,是一条可行之路。本文认为实体一般是名词,而关系一般为动词,若在一句句子中,两个实体之间存在某动词,那就可以认为这两个实体之间存在动词表示的关系。据此,本文设计了基于词性和语序分析的三元组抽取,其原理如图1所示。
如图1,首先加载和分割源文本,以句子为单位,进行句子的语序标注,得到句中的相关主语和谓语,再按照词性进行名词和动词的划分。一个词是主语或宾语且是名词,那么该词就可以作为该句中的实体。一个词若为谓语且是动词,那么该词可视为该句所涉及实体的关系。通过这种方式,遍历所有源文件,即可得到若干三元组组成的集合,形成初步的法律知识图谱。
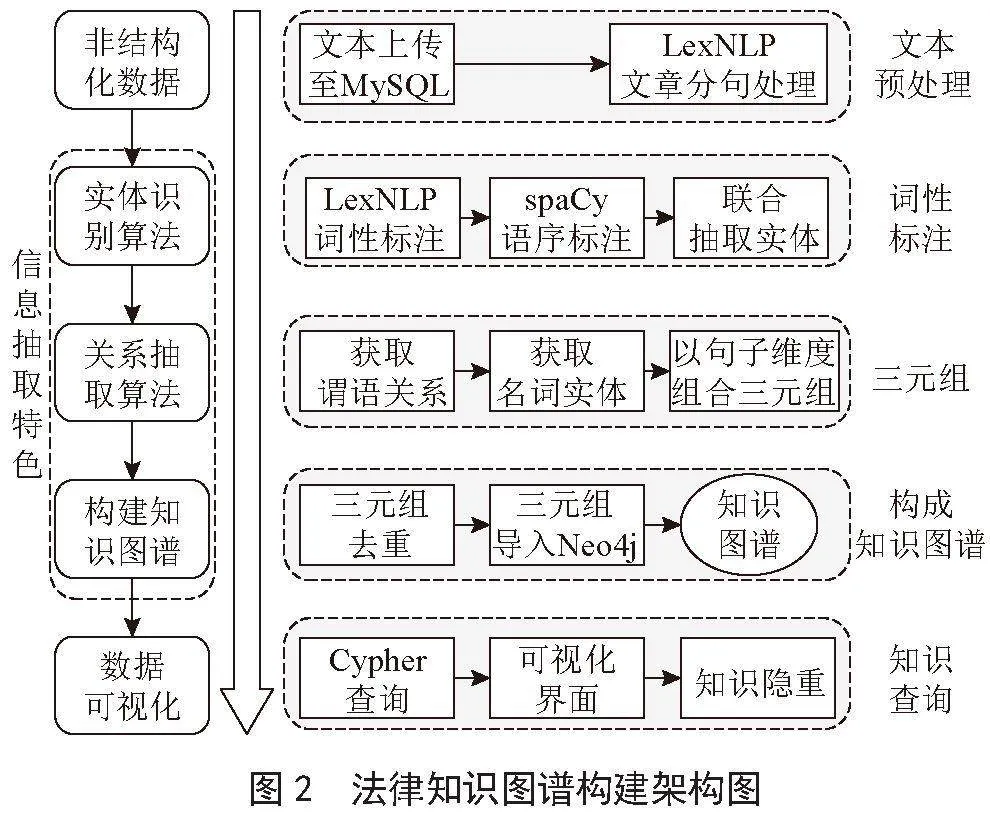
2.2" 算法实现
根据上述算法过程,实体识别和词性语序分析是关键。通过比较发现,LexNLP和spaCy这两个自然语言处理工具,能够满足上述算法的实现要求。LexNLP[38]是专门针对法律领域非结构化文本的分析工具,能够对句子的词性进行分析,而spaCy[39]是工业级自然语言处理工具,利用spaCy的“en_core_web_sm”语料库可对语序进行分析,从而识别出句子中的主语、谓语及宾语。对于抽取形成的三元组,则使用图形数据库Neo4j来存储和表示。此外,还需用MySQL数据库来存储一些算法实现过程中的辅助信息,总体实现过程如图2所示。
2.2.1 文本预处理
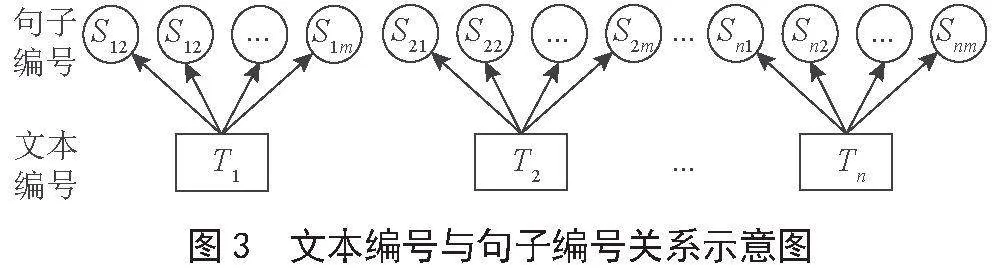
首先将收集到的法律文本上传至MySQL数据库中,并使用LexNLP对每个文本进行分句处理,同时记录每个句子的编号以及所在文本的编号。假设任一文本编号为Ti,i∈(1,2,…,n),其中任一句子的编号为Sij,j∈(1,2,…,m),经过分句后,则得到Ti = {Si1,Si2,…,Sij,…,Snm}。此处文本编号Ti为句子唯一标识,将用于分句处理后定位句子Sij所属文章编号,句子编号Sij则用于分词后判断哪些单词来源于同一篇文章,Ti与Sij的关系如图3所示。
2.2.2" 词性标注
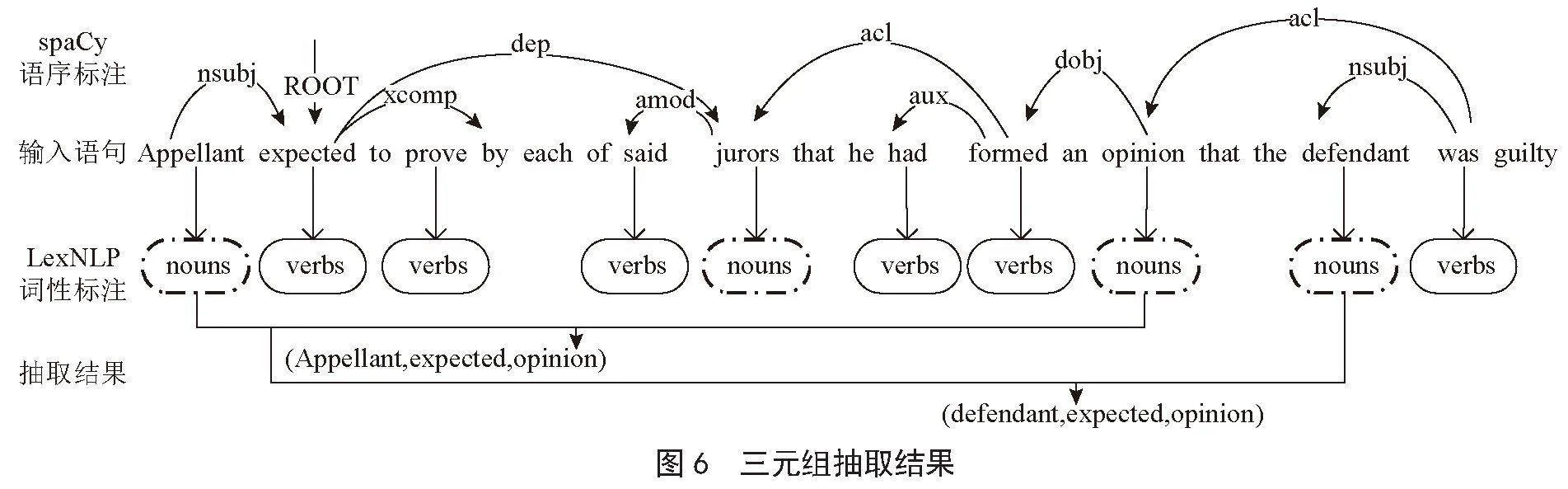
再应用LexNLP以句子为单位进行词性分析,得到句子中的动词和名词,假设句子为“Appellant expected to prove by each of said jurors that he had formed an opinion that the defendant was guilty.”,经过LexNLP词性标注后,句子序列中所有的名词和动词都被赋予相应的标签,名词用nouns来标注,动词用verbs来标注,词性标注结果如图4所示。
完成所有句子的标注后,将这两类词连同文本编号Ti和句子编号Sij一起存入MySQL数据库中,根据Ti和Sij的关系以确定该词在哪个文本的哪句句子中。
2.2.3" 三元组抽取
依次读取MySQL存储的动、名词记录,根据其中事先存储的文本编号Ti和句子编号Sij,来定位该动名词对应的句子。以图4所示句子为例,应用spaCy解析该句子,语序标注结果如图5所示。
如图5,spaCy对该句子中单词的语序进行了标注。其中,ROOT表示句子结构中的谓语,nsubj表示句子结构中名词性主语,dobj表示句子结构中的直接宾语,经过这一步,可以得到句子中词的语序。
完成上述图4、图5所示的步骤后,再将词性和语序标注结果,按照图1所示原理进行对比,从而形成两个三元组的结构lt;Appellant,expected,opinnoingt;、lt;defendant,expected,opinnoingt;,形成过程如图6所示。
按照该步骤完成所有三元组抽取后,将这些三元组关系按照Neo4j的语法规范存入至Neo4j中,Neo4j将自动汇总三元组形成法律文本的知识图谱。
2.2.4" 知识图谱的查询
知识图谱的查询相对简单,通过Neo4j的Cypher查询语句,可以方便地查询到存储在Neo4j中的三元组,并以图形化的方式显示在Neo4j的浏览器中。
3" "实证分析
3.1" 数据来源
本文以美国Caselaw Access Project公开的法律判例作为原始数据,该数据集目前共有650万个判例,其数据格式为jsonl。每个jsonl文件包含多个判例,实验随机选择了其中382个法律案例作为法律文本的原始数据。
3.2" 实验过程
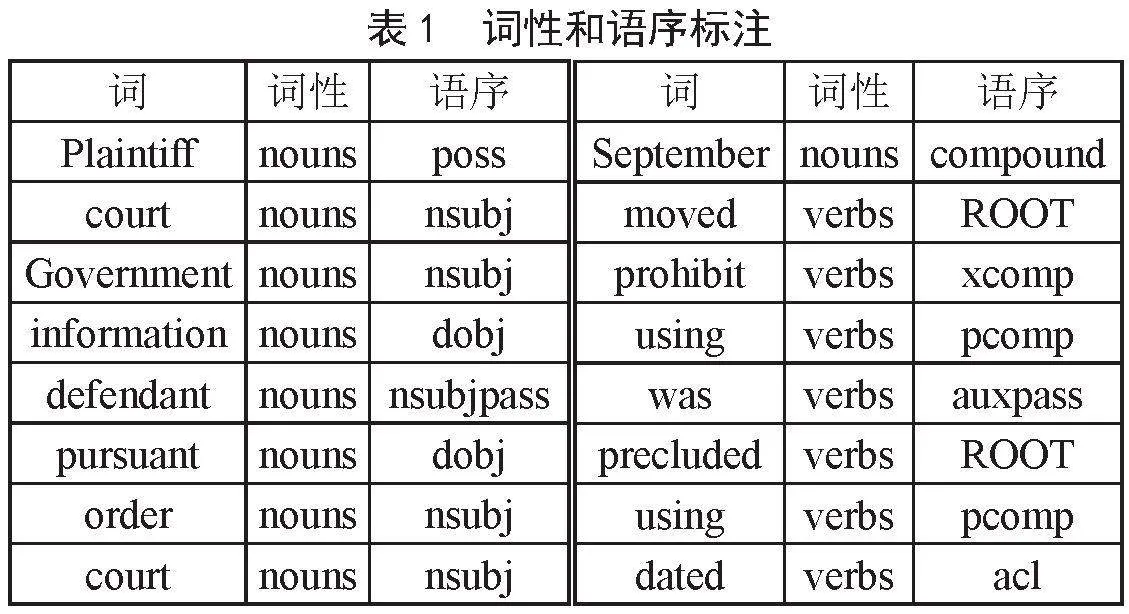
首先,对上传的382个判例进行分句,共得到8 460个句子,然后对句子进行分词,得到134 561个词语,再分别应用LexNLP和spaCy对这134 561个单词进行词性标注和语序标注,并根据标注结果得到2 855个实体和关系,最终自动生成了15 228个三元组。以其中一句为例:
Sentence =“Plaintiff then orally moved the court to prohibit the Government from using any information which the defendant was precluded from using pursuant to order of the court dated September 11, 1979.”。该句子经过词性和语序标注后,结果如表1所示。
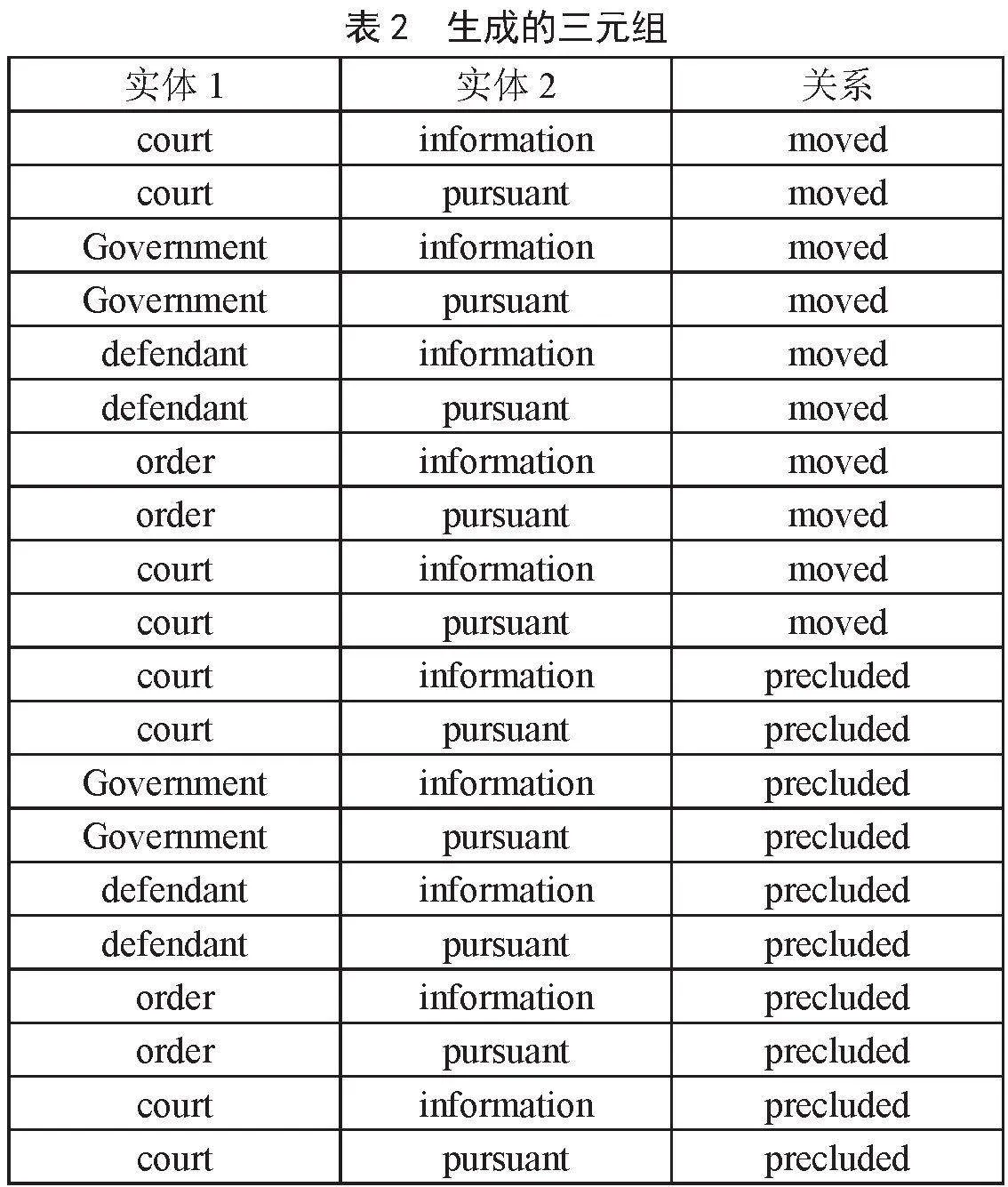
针对上述结果分析得到实体和关系的集合后,自动生成的三元组如表2所示。
从表2可见,生成的三元组基本符合原句中的知识关系。其次,再将生成的所有三元组去除重复数据,最终得到15 228个有效三元组,再将该三元组分为2个主体文件,另行构建一个关系文件,分别存储至csv文件中。最后,应用Neo4j-Load工具将csv文件批量导入至Neo4j中,存储成法律知识图谱。通过Neo4j的查询语句,即可得到一张可视化的知识图谱语义网络。
3.3" 实验结果
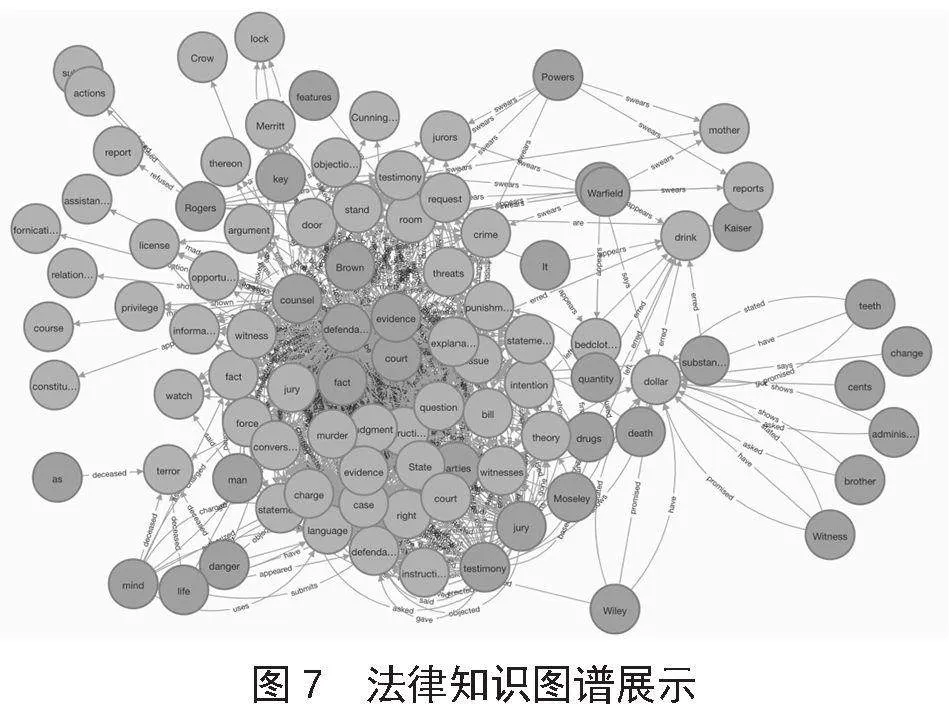
实验最终生成了如图7所示的知识图谱,由于篇幅有限,仅截了部分片段。
如图7,任意两个实体之间的连线,显示出两个实体之间的关系。而借助Neo4j的Cypher查询语言,可以查询任意实体之间的关系结构,如:match(n:实体1 {entity1:court})-[r]-(a) return n,a 可以查询出和court有关系的所有实体及关系,如图8所示。
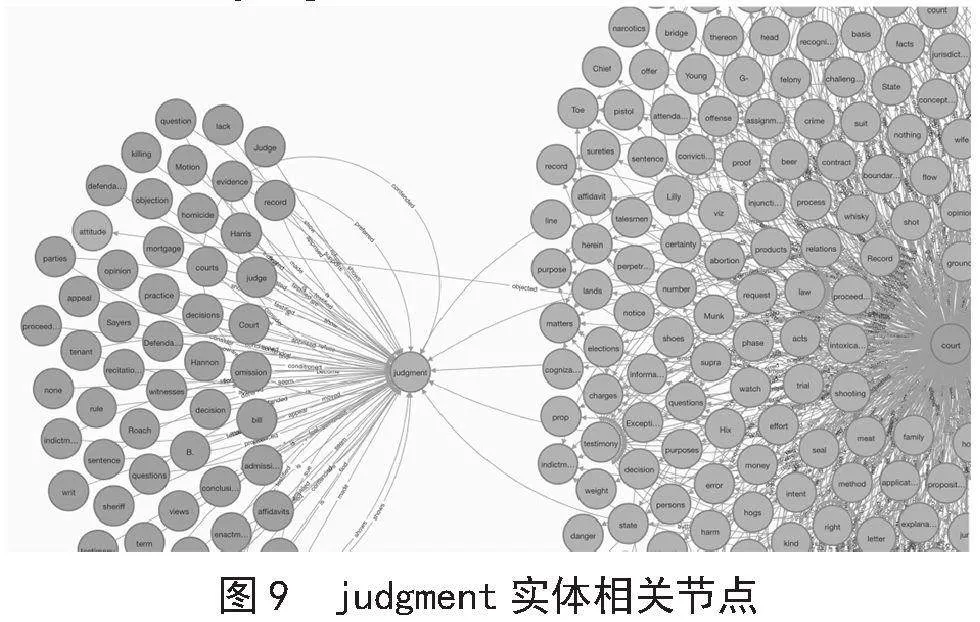
针对图8中的“judgment”实体,又可以查询到所有和“judgment”实体节点有关系的实体节点“question”“judge”等实体,如图9所示。
从实验结果可知,应用本文提出的方法,可以有效地生成面向法律领域的知识图谱。
3.4" 质量提升分析
质量评估是知识图谱构建的最后环节,是检查知识图谱准确性的必要手段。在接下来的研究中,将对生成的知识图谱进行质量评价。质量评价和三元组生成交叉进行,渐进式地完成知识图谱的构建,从而提出一种三元组质量反馈递增的知识图谱构建方法。
先将原始法律判案文本划分成n个部分(n≥2)。分阶段依次读取部分法律判案文本以生成部分三元组,先对这部分三元组进行质量评价,然后为每个动词关系设置一个权重,符合权重筛选条件的三元组划分到正确集合中。再读取另一部分法律判案文本生成新的三元组,但此处新生成的三元组会根据之前生成的三元组的动词正确率进行过滤,将权重不满足筛选条件的动词的三元组加入不正确集合中。但是对于未出现过的三元组,则需要人为进行判断。而对于出现频率过高并且总是被过滤的三元组,会通过补偿机制重新计算其动词的正确率,再判断是否要加入正确集合中,通过多个阶段的生成与评价。
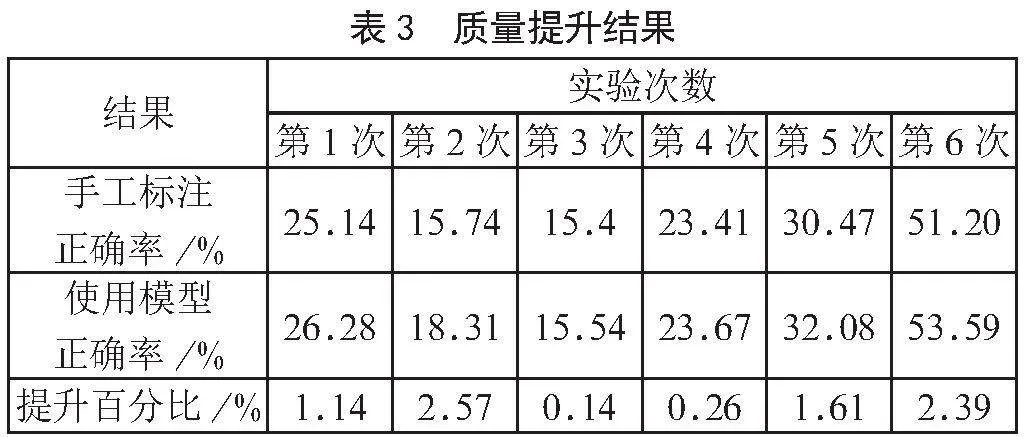
如表3所示,第一次使用原始法律判案文本新生成了1 999个三元组,通过手工标注有508个正确的三元组,使用上述的质量提升方法,经过权重表过滤,符合权重筛选条件的三元组还剩1 602个,其中正确的个数有421个。正确率提升了1.14%,以此类推,后续五次实验正确率分别提升2.57%、0.14%、0.26%、1.61%、2.39%。
随着评价次数的递增,三元组的规模不断扩大,最终生成正确率相对较高的三元组集合,说明所提出的质量提升模型的有效性。
4" 结" 论
本文是对法律文本知识化和智能化的初步研究。文章设计了一种基于词性和语序分析的三元组抽取方法,基于该方法设计了针对法律领域的知识图谱自动构建方法,并详细描述了法律知识图谱的构建过程。最后,文章以美国Caselaw Access Project中包含的382条判例为实验数据,构建并生成了法律知识图谱。从构建的中间数据来看,由于所分析的实体和关系,均来自同一句句子,相比较面向全数据集的标注方法,针对性更强,理论上来说,语义上的准确度更高。未来,研究将继续优化本文提出的知识抽取方法,同时也将加大数据量和评估的人力,针对本文所提出的质量评估方法不断提高法律知识图谱构建的准确率,从而为智能法律判案研究做准备。
参考文献:
[1] XU C,PEI Z B. Research on the Construction of an Intelligent Court in the Era of Big Data [C]//Proceedings of the 1st International Conference on New Computational Social Science (ICNCSS 2020).London:CRC Press,2021:3-10.
[2] 帅奕男.人工智能辅助司法裁判的现实可能与必要限度 [J].山东大学学报:哲学社会科学版,2020(4):101-110.
[3] 杨波,杨美芳.知识图谱研究综述及其在风险管理领域应用 [J].小型微型计算机系统,2021,42(8):1610-1618.
[4] 王思宇,邱江涛,洪川洋,等.基于知识图谱的在线商品问答研究 [J].中文信息学报,2020,34(11):104-112.
[5] 武家伟,孙艳春.融合知识图谱和深度学习方法的问诊推荐系统 [J].计算机科学与探索,2021,15(8):1432-1440.
[6] 陶天一,王清钦,付聿炜,等.基于知识图谱的金融新闻个性化推荐算法 [J].计算机工程,2021,47(6):98-103+114.
[7] 王宁,刘玮,兰剑.基于法院判决文书的法律知识图谱构建和补全 [J].郑州大学学报:理学版,2021,53(3):23-29.
[8] ABU-SALIH B. Domain-specific Knowledge Graphs: A Survey [J].Journal of Network and Computer Applications,2021,185(5):103076.
[9] FUNDEL K,KÜFFNER R,ZIMMER R. Relex—Relation Extraction Using Dependency Parse Trees [J].Bioinformatics,2007,23(3):365-371.
[10] LEE S,PARK Y,YOON W C. Burst Analysis for Automatic Concept Map Creation with a Single Document [J].Expert Systems with Applications,2015,42(22):8817-8829.
[11] AUGENSTEIN I,MAYNARD D,CIRAVEGNA F. Distantly Supervised Web Relation Extraction for Knowledge Base Population [J].Semantic Web,2016,7(4):335-349.
[12] ROCHA C,JORGE A,SIONARA R,et al. PAMPO: Using Pattern Matching and Pos-tagging for Effective Named Entities Recognition in Portuguese [J/OL].arXiv:1612.09535 [cs.IR] [cs.CV].(2016-12-30).https://arxiv.org/abs/1612.09535v1.
[13] PARTALIDOU E,SPYROMITROS-XIOUFIS E,DOROPOULOS S,et al. Design and Implementation of an Open Source Greek POS Tagger and Entity Recognizer Using spaCy [C]//2019 IEEE/WIC/ACM International Conference on Web Intelligence (WI).Thessaloniki:IEEE,2019:337-341.
[14] BAJWA I S,KARIM F,NAEEM M A,et al. A Semi Supervised Approach for Catchphrase Classification in Legal Text Documents [J].Journal of Computers,2017,12(5):451-461.
[15] TANG M W,SU C,CHEN H H,et al. SALKG: A Semantic Annotation System for Building a High-quality Legal Knowledge Graph [C]//2020 IEEE International Conference on Big Data (Big Data).Atlanta:IEEE,2020:2153-2159.
[16] XIAO Z W,ZHANG C X. Construction of Meteorological Simulation Knowledge Graph Based on Deep Learning Method [J].Sustainability,2021,13(3):1-20.
[17] 周琦,陆叶,李婷玉,等.基于语义文法的地理实体位置关系的获取 [J].计算机科学,2016,43(7):208-216.
[18] 李艳燕,张香玲,李新,等.面向智慧教育的学科知识图谱构建与创新应用 [J].电化教育研究,2019,40(8):60-69.
[19] 袁琦,刘渊,谢振平,等.宠物知识图谱的半自动化构建方法 [J].计算机应用研究,2020,37(1):178-182.
[20] 洪文兴,胡志强,翁洋,等.面向司法案件的案情知识图谱自动构建 [J].中文信息学报,2020,34(1):34-44.
[21] 刘峤,李杨,段宏,等.知识图谱构建技术综述 [J].计算机研究与发展,2016,53(3):582-600.
[22] MCCUSKER J P,DUMONTIER M,YAN R,et al. Finding Melanoma Drugs through a Probabilistic Knowledge Graph [J].PeerJ Computer Science,2017,3(301):106.
[23] KIM T,YUN Y,KIM N. Deep Learning-based Knowledge Graph Generation for COVID-19 [J].Sustainability,2021,13(4):2276.
[24] FRANCO-SALVADOR M,ROSSO P,MONTES-Y-GÓMEZ M. A Systematic Study of Knowledge Graph Analysis for Cross-language Plagiarism Detection [J].Information Processing and Management,2016,52(4):550-570.
[25] 王飞,刘井平,刘斌,等.代码知识图谱构建及智能化软件开发方法研究 [J].软件学报,2020,31(1):47-66.
[26] 李刚,朱学芳.面向图博档数字化服务融合的知识图谱构建与实现 [J].情报科学,2021,39(12):155-164.
[27] 邓斯予,耿骞,靳健,等.基于产品评论分析的领域知识库构建与应用 [J].情报理论与实践,2019,42(11):115-122+127.
[28] 顾海,奉子岚,吴迪,等.我国远程医疗研究现状及趋势——基于CiteSpace的文献量化分析 [J].信息资源管理学报,2020,10(4):119-129.
[29] 杨思洛,韩瑞珍.国外知识图谱绘制的方法与工具分析 [J].图书情报知识,2012(6):101-109.
[30] 陈悦,陈超美,刘则渊,等.CiteSpace知识图谱的方法论功能 [J].科学学研究,2015,33(2):242-253.
[31] 阚越,章锦河,李湮,等.基于CiteSpace的国内外草原旅游研究知识图谱量化分析 [J].内蒙古大学学报:自然科学版,2022,53(1):66-76.
[32] 陈晓玲,刘东亮.基于科学知识图谱的东北三省区域研究热点分析 [J].情报学报,2018,37(12):1224-1231.
[33] 胡欢,云红艳,贺英,等.半自动构建扶贫领域知识图谱工具的研究 [J].计算机与数字工程,2019,47(8):1961-1965+2055.
[34] TAN J Y,QIU Q Q,GUO W W,et al. Research on the Construction of a Knowledge Graph and Knowledge Reasoning Model in the Field of Urban Traffic [J].Sustainability,2021,13(6):3191.
[35] 刘政昊,钱宇星,衣天龙,等.知识关联视角下金融证券知识图谱构建与相关股票发现 [J].数据分析与知识发现,2022,6(Z1):184-201.
[36] 胡浩,高静,刘振羽.奶牛产奶量性状相关基因知识图谱的研究与构建 [J].计算机工程与应用,2023,59(2):299-305.
[37] 李艳东.知识图谱技术在商业银行审计中的应用研究 [J].会计之友,2021(22):115-119.
[38] BOMMARITO II M J,KATZ D M,DETTERMAN E M. LexNLP: Natural Language Processing and Information Extraction for Legal and Regulatory Texts [J/OL].arXiv:1806.03688 [cs.CL].(2018-06-10).https://arxiv.org/abs/1806.03688
[39] HONNIBAL M. SpaCy [EB/OL].(2017-01-20)[2019-05-24].https://spacy.io/.